🍅 作者:不吃西紅柿
🍅 簡介:CSDN博客專家🏆、HDZ核心組成員💪、C站總榜前10名?
🍅 粉絲專屬福利:文末公號「資訊技術智庫」回復「資料」領取
🍅 如覺得文章不錯,歡迎點贊、收藏、評論
文末下載PDF
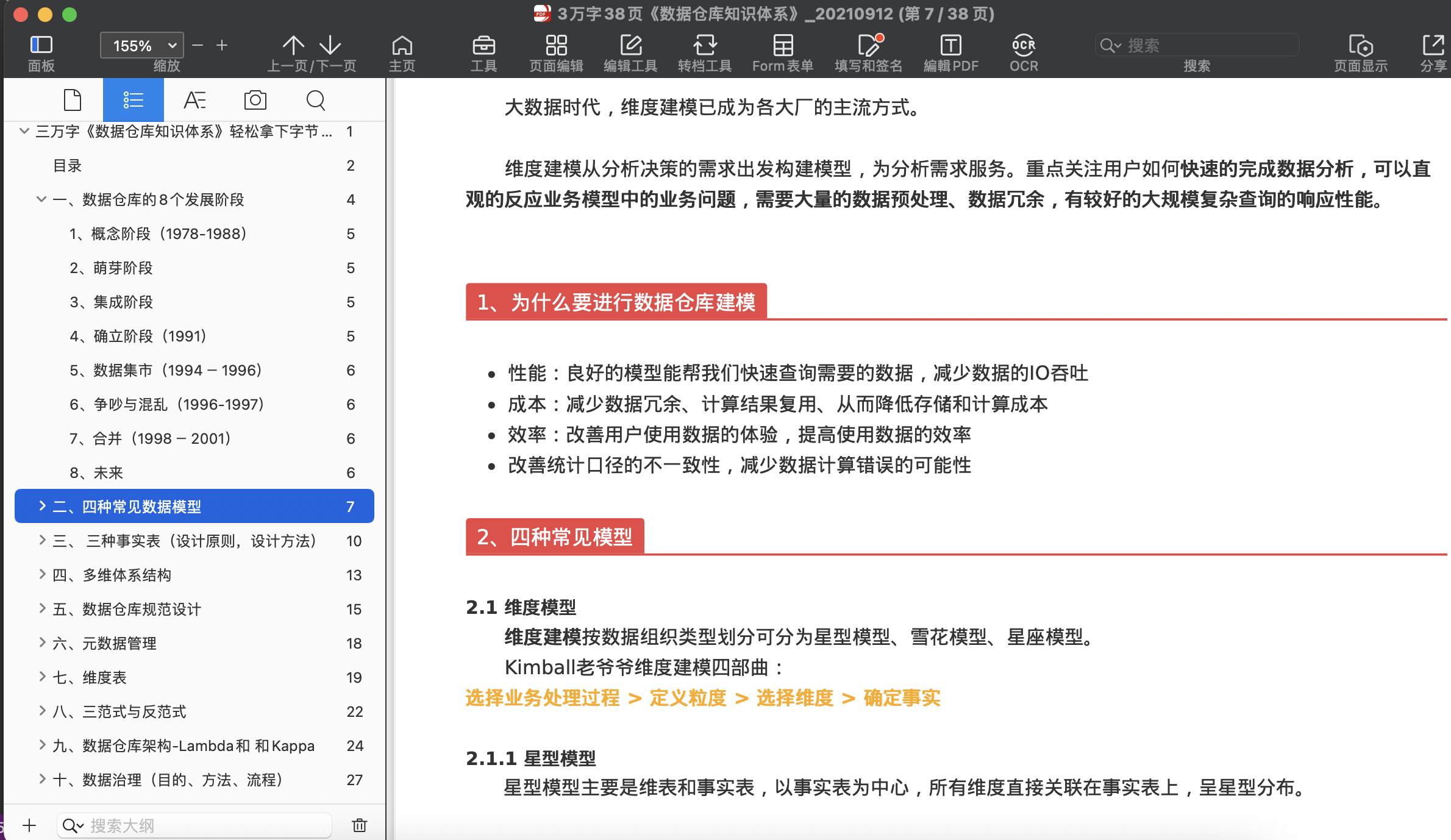
擁有本篇PDF,意味著你擁有一本完善的書籍,本篇文章整理了資料倉庫領域,幾乎所有的知識點,文章內容主要來源于以下幾個方面:
- 源于「資料倉庫交流群」資深資料倉庫工程師的交流討論,如《sql行轉列的千種寫法》,
- 源于群友面試大廠遇到的面試真題,整理投稿給我,形成《面試題庫》,
- 源于筆者在系統學習程序中整理的筆記和一點理解,
- 源于技術網站的優質文章和高贊答案,
本篇文章尤其適合初級程式員準備面試,以及作為作業中的指導手冊,對資深程式員來說也可夯實基礎,
當然,技術學習僅僅依靠一篇文章還是不夠的,可加入公眾號和技術交流群(聯系方式見文末),群里有很多資料倉庫領域資深大佬,大家經常在群里討論技術熱點問題、互相解決作業難題、安排內推、甚至有部門leader直接發出崗位邀請,「西紅柿🍅」也會持續更新優質文章,也歡迎熱愛學習總結的小伙伴有償投稿,共同推動中國資訊技術行業發展,讓我們一起加油吧!
1、資料傾斜表現
1.1 hadoop中的資料傾斜表現
- 有一個多幾個Reduce卡住,卡在99.99%,一直不能結束,
- 各種container報錯OOM
- 例外的Reducer讀寫的資料量極大,至少遠遠超過其它正常的Reducer
- 伴隨著資料傾斜,會出現任務被kill等各種詭異的表現,
1.2 hive中資料傾斜
一般都發生在Sql中group by和join on上,而且和資料邏輯系結比較深,
1.3 Spark中的資料傾斜
Spark中的資料傾斜,包括Spark Streaming和Spark Sql,表現主要有下面幾種:
- Executor lost,OOM,Shuffle程序出錯;
- Driver OOM;
- 單個Executor執行時間特別久,整體任務卡在某個階段不能結束;
- 正常運行的任務突然失敗;
2、資料傾斜產生原因
我們以Spark和Hive的使用場景為例,
在做資料運算的時候會涉及到,count distinct、group by、join on等操作,這些都會觸發Shuffle動作,一旦觸發Shuffle,所有相同key的值就會被拉到一個或幾個Reducer節點上,容易發生單點計算問題,導致資料傾斜,
一般來說,資料傾斜原因有以下幾方面:
1)key分布不均勻;
2)建表時考慮不周
舉一個例子,就說資料默認值的設計吧,假設我們有兩張表:
user(用戶資訊表):userid,register_ip
ip(IP表):ip,register_user_cnt
這可能是兩個不同的人開發的資料表,如果我們的資料規范不太完善的話,會出現一種情況:
user表中的register_ip欄位,如果獲取不到這個資訊,我們默認為null;
但是在ip表中,我們在統計這個值的時候,為了方便,我們把獲取不到ip的用戶,統一認為他們的ip為0,
兩邊其實都沒有錯的,但是一旦我們做關聯了,這個任務會在做關聯的階段,也就是sql的on的階段卡死,
3)業務資料激增
比如訂單場景,我們在某一天在北京和上海兩個城市多了強力的推廣,結果可能是這兩個城市的訂單量增長了10000%,其余城市的資料量不變,
然后我們要統計不同城市的訂單情況,這樣,一做group操作,可能直接就資料傾斜了,
3、解決資料傾斜思路
很多資料傾斜的問題,都可以用和平臺無關的方式解決,比如更好的資料預處理,例外值的過濾等,因此,解決資料傾斜的重點在于對資料設計和業務的理解,這兩個搞清楚了,資料傾斜就解決了大部分了,
1)業務邏輯
我們從業務邏輯的層面上來優化資料傾斜,比如上面的兩個城市做推廣活動導致那兩個城市資料量激增的例子,我們可以單獨對這兩個城市來做count,單獨做時可用兩次MR,第一次打散計算,第二次再最終聚合計算,完成后和其它城市做整合,
2)程式層面
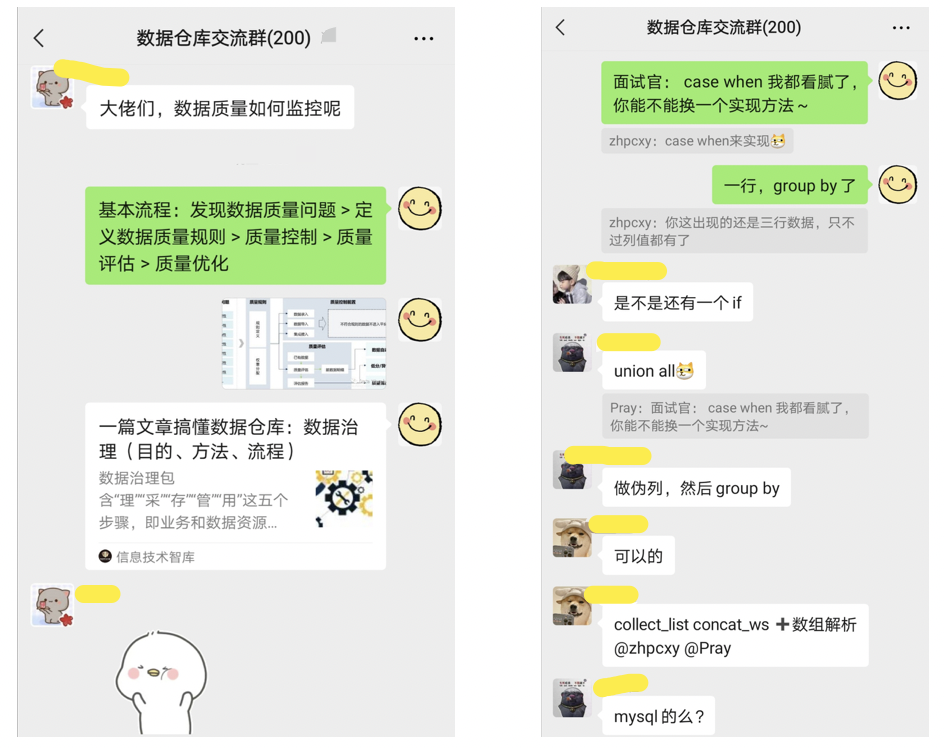
比如說在Hive中,經常遇到count(distinct)操作,這樣會導致最終只有一個Reduce任務,
我們可以先group by,再在外面包一層count,就可以了,比如計算按用戶名去重后的總用戶量:
(1)優化前
只有一個reduce,先去重再count負擔比較大:
select name,count(distinct name)from user;
(2)優化后
// 設定該任務的每個job的reducer個數為3個,Hive默認-1,自動推斷,
set mapred.reduce.tasks=3;
// 啟動兩個job,一個負責子查詢(可以有多個reduce),另一個負責count(1):
select count(1) from (select name from user group by name) tmp;
3)調參方面
Hadoop和Spark都自帶了很多的引數和機制來調節資料傾斜,合理利用它們就能解決大部分問題,
4)從業務和資料上解決資料傾斜
很多資料傾斜都是在資料的使用上造成的,我們舉幾個場景,并分別給出它們的解決方案,
一個原則:盡早過濾每個階段的資料量,
- 資料有損的方法:找到例外資料,比如ip為0的資料,過濾掉,
- 資料無損的方法:對分布不均勻的資料,單獨計算,
- hash法:先對key做一層hash,先將資料隨機打散讓它的并行度變大,再匯聚,
- 資料預處理:就是先做一層資料質量處理,類似于資料倉庫維度建模時,底層先處理資料質量,

添加公眾號「資訊技術智庫」:
🍅 硬核資料:20G,8大類資料,關注即可領取(PPT模板、簡歷模板、技術資料)
🍅 技識訓助:技術群大佬指點迷津,你的問題可能不是問題,求資源在群里喊一聲,
🍅 面試題庫:由各個技術群小伙伴們共同投稿,熱乎的大廠面試真題,持續更新中,
🍅 知識體系:含編程語言、演算法、大資料生態圈組件(Mysql、Hive、Spark、Flink)、資料倉庫、前端等,
👇👇送書抽獎丨技識訓助丨粉絲福利👇👇
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/317853.html
標籤:其他