1. 奇異值分解(SVD)
(1)奇異值分解
已知矩陣\(\bm{A} \in \R^{m \times n}\), 其奇異值分解為:
\[\bm{A} = \bm{U}\bm{S}\bm{V}^T \]其中\(\bm{U} \in \R^{m \times m}\),\(\bm{V} \in \R^{n \times n}\)是正交矩陣,\(\bm{S} \in \R^{m \times n}\)是對角線矩陣,\(\bm{S}\)的對角線元素\(\bm{s}_1, \bm{s}_2,..., \bm{s}_{\min(m,n)}\)是矩陣的奇異值,
(2) 奇異值分解的求解
而求矩陣的奇異值的演算法非常簡單,對于實數域下的矩陣\(A\),我們只需要求\(A^TA\)的特征值和特征向量,其特征向量歸一化后即右奇異向量\(\bm{v}_1,\bm{v}_2,...,\bm{v}_n\),其特征值開根號即對應的奇異值\(\bm{s}_1, \bm{s}_2,..., \bm{s}_{\min(m,n)}\), 然后由等式
\[\bm{A}\bm{v}_1=s_1\bm{u}_1, \\ \bm{A}\bm{v}_2=s_2\bm{u}_2, \\ ..., \\ A\bm{v}_{\min(m,n)} = \bm{s}_{\min(m,n)}\bm{u}_{\min(m,n)}\]依次計算出相應的\(\bm{u}_i\)向量的值,
至于特征值的計算,采用 QR 演算法,此處不予介紹,這里可以直接呼叫 np.linalg.eig()函式實作,以下給出奇異值計算代碼實體(此處僅為知識演示,具體的工業級別的奇異值計算演算法要復雜得多,參考 Golub 與 Van Loan《矩陣計算》)
import numpy as np
def svd(A):
eigen_values, eigen_vectors = np.linalg.eig(A.T.dot(A))
singular_values = np.sqrt(eigen_values)
#這里奇異值要從大到小排序,特征向量也要隨之從大到小排
val_vec = [] #存盤奇異值-特征向量對
for i in range(len(eigen_values)):
val_vec.append((singular_values[i], eigen_vectors[:, i]))
val_vec.sort(key = lambda x:-x[0])
singular_values = [ pair[0] for pair in val_vec]
eigen_vectors = [ pair[1] for pair in val_vec]
# 在計算左奇異向量之前,先要對右奇異向量也就是特征向量組成的基正交化
# 不過linalg.eig回傳的是已經正交化的,這一步可省略
# 由等式Avi = siui(vi是右奇異向量, ui是左奇異向量)
# 依次計算左奇異向量
U = np.zeros((A.shape[0], A.shape[1]))
for i in range(A.shape[1]):
u = A.dot(eigen_vectors[i])/singular_values[i]
U[:, i] = u
# 給U加上標準正交基去構造R3的基
for i in range(A.shape[1], A.shape[0]):
basis = np.zeros((A.shape[0], 1))
basis[i] = 1
U = np.concatenate([U, basis], axis=1)
eigen_vectors = [vec.reshape(-1, 1) for vec in eigen_vectors]
eigen_vectors = np.concatenate(eigen_vectors, axis=1)
return U, singular_values, eigen_vectors
if __name__ == '__main__':
# 例一:普通矩陣
A = np.array(
[
[0, 1],
[0, -1]
]
)
# 例二:對稱矩陣
# A = np.array(
# [
# [0, 1],
# [1, 3/2]
# ]
# )
U, S, V = svd(A)
print("我們實作的演算法結果:")
print(U, "\n", S, "\n", V)
print("\n")
print("呼叫庫函式的計算結果:")
# 呼叫api核對
U2, S2, V2 = np.linalg.svd(A)
print(U2, "\n", S2, "\n", V2)
對普通矩陣\(\left(\begin{matrix}0 & 1 \\0 & -1\end{matrix}\right)\)運行該演算法的結果為:
我們實作的演算法結果:
[[ 0.70710678 0.70710678]
[-0.70710678 -0.70710678]]
[1.4142135623730951, 0.0]
[[0. 1.]
[1. 0.]]
呼叫庫函式的計算結果:
[[-0.70710678 -0.70710678]
[ 0.70710678 -0.70710678]]
[1.41421356 0. ]
[[-0. -1.]
[-1. 0.]]
可以看到結果基本符合,此處矩陣\(\left(\begin{matrix}0 & 1 \\0 & -1\end{matrix}\right)\)的奇異值為0.41421和0,此處我們發現普通矩陣的奇異值可以為0,
對對稱矩陣\(\left(\begin{matrix}0 & 1 \\1 & \frac{3}{2}\end{matrix}\right)\)運行該演算法的結果為:
我們實作的演算法結果:
[[-0.4472136 0.89442719]
[-0.89442719 -0.4472136 ]]
[2.0, 0.5]
[[-0.4472136 -0.89442719]
[-0.89442719 0.4472136 ]]
呼叫庫函式的計算結果:
[[-0.4472136 -0.89442719]
[-0.89442719 0.4472136 ]]
[2. 0.5]
[[-0.4472136 -0.89442719]
[ 0.89442719 -0.4472136 ]]
可以看到結果基本符合,此處矩陣\(\left(\begin{matrix}0 & 1 \\0 & -1\end{matrix}\right)\)的奇異值為2和0.5,此處我們發現,對稱矩陣的奇異值必為正,不可能為0,
(2)奇異值的應用1:推薦系統
在推薦系統中,我們常定義用戶-評分矩陣,表示用戶對商品的打分,這個矩陣我們稱為共現矩陣,
而這就迫切地需要我們設計矩陣分解演算法,為每一個用戶和視頻生成一個隱向量,將用戶和視頻定位到隱向量的表示空間上,并滿足距離相近的用戶和視頻表示興趣特點接近,
在推薦系統的應用場景下,我們企圖使用矩陣分解演算法將\(m\times n\)維的共現矩陣\(\bm{R}\)分解為\(m \times k\)維的用戶矩陣和\(k*n\)維的物品矩陣(的轉置)相乘的形式,其中\(m\)是用戶數量,\(n\)是物品數量,\(k\)是隱向量,\(k\)的大小決定了隱向量表達能力的強弱,\(k\)越小,隱向量包含的資訊越少,模型的泛化程度越高;反之,\(k\)越大,隱向量表達能力越強,泛化程度相應降低,此外,\(k\)的取值還與矩陣分解的求解復雜度直接相關,應用中,\(k\)的取值要經過試驗多次找到一個推薦效果和工程開銷的平衡,具體的形式如下圖所示:
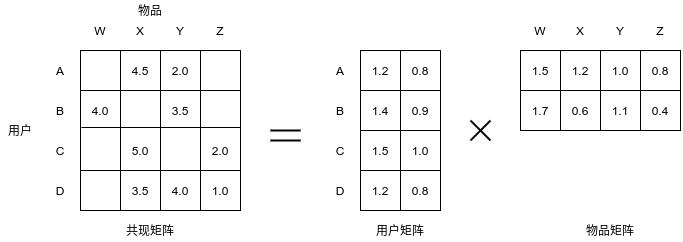
采用什么方法來進行矩陣分解呢?由矩陣分析的知識可得,特征值分解只能作用于方陣,顯然不適合于分解用戶-物品矩陣,我們在這里采用矩陣的奇異值分解以得到用戶和物品的隱向量,
已知\(\bm{M}\)是矩陣\(m\times n\)的矩陣,則一定存在一個分解\(\bm{M} = \bm{U}diag(λ_1, λ_2,..., λ_n)\bm{V}^T\),其中\(U\)是\(m*m\)的正交矩陣,\(V\)是\(n\times n\)的正交矩陣,\(diag(λ_1, λ_2,..., λ_n)\) 是 \(m \times n\)的對角陣, 我們取對角陣 \(diag(λ_1, λ_2,..., λ_n)\)中較大的\(k\)個元素做為隱含特征,洗掉\(diag(λ_1, λ_2,..., λ_n)\)中的其他維度及\(U\)和\(V\)中對應的維度,矩陣\(M\)被分解為\(M=U_{m*k}diag(λ_1, λ_2,..., λ_k)V_{k*n}^T\),至此完成了隱向量維度為\(k\)的矩陣分解, 如果我們呼叫np.lialg.svd()函式介面,那我們可以將奇異值分解表述如下:
import numpy as np
if __name__ == '__main__':
M = np.array(
[
[0, 4.5, 2.0, 0],
[4.0, 0, 3.5, 0],
[0, 5.0, 0, 2.0],
[0, 3.5, 4.0, 1.0]
]
)
U, S, V_T = np.linalg.svd(M)
k = 2 # 取前2個奇異值對應的隱向量
# 分別列印物品向量和用戶向量
Vec_user, Vec_item = U[:,:k], V_T[:k, :].T
print(Vec_user, "\n\n", Vec_item)
該演算法對運行結果為:
[[-0.55043774 0.1361732 ]
[-0.26216705 -0.86775439]
[-0.52483774 0.4552962 ]
[-0.5939967 -0.1454804 ]]
[[-0.12135946 -0.63908086]
[-0.83093848 0.43821815]
[-0.50855715 -0.61619448]
[-0.19021762 0.14087178]]
可以看到我們由共現矩陣成功得到了用戶向量和物品向量,
然而,運在推薦系統中的傳統奇異值分解存在兩點重大的缺陷:
- 奇異值分解要求原始共現矩陣是稠密的,而互聯網場景下用戶非常少,用 戶-物品的共現矩陣非常系數,如果使用 SVD,就必須對缺失的元素值進行填充,
- 傳統奇異值分解的計算復雜度達到了\(O(mn^2)\)的級別,這對于商品數量動輒上百萬,用戶數量往往上千萬的互聯網場景來說根本不可接受, 所以,傳統奇異值分解不適用于解決大規模稀疏矩陣的矩陣分解,因此,梯度下降法成為了矩陣分解的主要方法,這部分內容我們會在推薦系統專欄中進行講解,
(3)奇異值的應用2:矩陣的低秩近似和資料降維
將矩陣的奇異值分解形式\(\bm{M} = \bm{U}\bm{S}\bm{V}^T\)中的對角陣進一步寫成多個子矩陣的和,我們有:
\[\bm{A} = \bm{U}\bm{S}\bm{V}^T=\bm{U} \left( \begin{matrix} s_1 & & \\ & \ddots & \\ & & s_r\\ & & \\ \end{matrix} \right) \bm{V}^T \\ =\bm{U} \left( \left( \begin{matrix} s_1 & & \\ & & \\ & & \\ & & \\ \end{matrix} \right) + \left( \begin{matrix} & & \\ & s_2 & \\ & & \\ & & \\ \end{matrix} \right) + \left( \begin{matrix} & & \\ & & \\ & & s_r\\ & & \\ \end{matrix} \right) \right) \bm{V}^T \\ =s_1\bm{u}_1\bm{v}_1^T+s_2\bm{u}_2\bm{v}_2^T+... + s_r\bm{u}_r\bm{v}_r^T \]注意,這里\(\bm{u}_1\)和\(\bm{v}_1\)是做外積,運算得到一個矩陣, 也就是說,\(m\times n\)的矩陣\(\bm{A}\)可以寫成秩為1的矩陣和,即:
\[ \bm{A} = \sum_{i=1}^{r}s_i\bm{u}_i\bm{v}_i^{T} \]我們將這個性質稱為 SVD 的低秩近似性質,
在介紹 SVD 的底秩近似的應用前,我們先介紹資料降維的思想,降維的思想是將資料投影到低維空間,假設\(\bm{a}_{1},\bm{a}_2...,\bm{a}_n\)都是\(m\)維向量(在資料科學的應用中, 一般\(m\)遠小于\(n\),想想為什么),降維的目標是使用\(n\)個\(p\)維的向量替換原本的\(n\)個\(m\)維的向量,其中新向量的維度\(p<m\),同時最小化該程序引入的誤差,
那么 SVD 其實天然可以用于降維,我們定義矩陣\(A\)的秩\(p\)近似,將矩陣\(A\)的奇異值分解保留前\(p\)項,即:
也就是其低秩近似形式保留前\(p\)項,
\[\bm{A}_p= \sum_{i=1}^{p}s_i\bm{u}_i\bm{v}_i^{T} \]這個式子也可以看做\(\bm{A}\)的最優最小二乘近似形式,即:
\[\bm{A}_p= \underset{\bm{B}}{\text{argmin}}||\bm{A} ? \bm{B}||_F \]這里,\(\bm{B}\)的大小和\(\bm{A}\)一樣,\(\bm{B} \in \bm{\R}^{m\times n}\)(但是\(rank(\bm{B})\leqslant p\)),\(F\)指F范數,這里的F范數可以推廣到任意的酉不變范數\(||\bm{A} ? \bm{B}||_U\),不過在常規的使用中,大家就使用\(F\)范數就夠了,
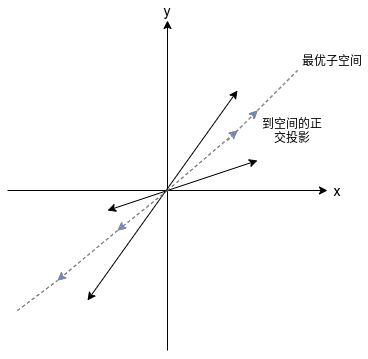
矩陣最優近似是有著幾何解釋的,空間\(<\bm{u}_1,...,\bm{u}_p>\)由左奇異向量\(\bm{u}_1,...,\bm{u}_p\)長成,這是對于\(\bm{a}_1,...,\bm{a}_n\)的\(p\)維子空間在最小二乘意義上的最優近似,\(\bm{A}\)的列\(\bm{a}_i\)在該空間上的正交投影對應\(\bm{A}_p\)的列,換句話講,一組向量 \(\bm{a}_1,\bm{a}_2,...,\bm{a}_n\)找到其最優的最小二乘\(p\)維子空間的投影(最小二乘后面會介紹,這里暫時理解不了也沒關系)就是矩陣最優的秩\(p\)近似矩陣\(\bm{A}_p\),
比如,我們要找到最優的一維子空間擬合資料向量\((3,2)^T,(2,4)^T,(-2,-1)^T,(-3,-5)^T\), 4 個向量近似指向相同的一維子空間,我們想找出這個子空間,該空間能夠使向量投影到子空間的平方誤差和最小,然后我們找出投影向量,投影向量組成的矩陣就是我們要求的近似矩陣\(\bm{A}_p\),
如下圖所示:
演算法如下:
import numpy as np
from sklearn.decomposition import PCA
def approximation(A, p):
U, s, V_T = np.linalg.svd(A)
B = np.zeros(A.shape)
for i in range(p):
B += s[i]*U[:,i].reshape(-1, 1).dot(V_T[i, :].reshape(1, -1))
return B
if __name__ == '__main__':
# 例一:
# A = np.array(
# [
# [0, 1],
# [1, 3/2],
# ]
# )
# 例二:
A = np.array(
[
[3, 2, -2, -3],
[2, 4, -1, -5]
]
)
# p為近似矩陣的秩,秩p<=r
p = 1
B = approximation(A, p)
print(B)
#最終得到的矩陣秩
print(np.linalg.matrix_rank(B))
(注意,numpy 內置的 SVD 函式回傳的是\(V^T\)而不是\(V\),我就在這兒犯過錯,,, 導致后面求出來的近似矩陣不對/(ㄒoㄒ)/~~)
最終對例一矩陣\(\left(\begin{matrix}0 & 1 \\1 & \frac{3}{2}\end{matrix}\right)\)運行演算法的結果如下:
[[0.4 0.8]
[0.8 1.6]]
1
該矩陣的四個列向量對應原始資料向量的投影向量,可以看到這四個向量線性相關, 且最終得到的矩陣的秩為1,
最終對例二矩陣\(\left(\begin{matrix}3 & 2 &-2 &-3 \\2 & 4 & -1 & -5 \end{matrix}\right)\)運行演算法的結果如下:
[[ 1.99120445 2.59641446 -1.16885153 -3.41876737]
[ 2.73456571 3.56571418 -1.60521001 -4.69506988]]
1
該矩陣的四個列向量對應原始資料向量的投影向量,可以看到這四個向量線性相關, 且最終得到的矩陣的秩也為1,
也就是說我們的演算法對這兩個矩陣都達到了我們低秩近似的效果,因為降維后這兩個矩陣的四個向量同屬于一個一維子空間,我們只需要一個維度就可以區分這四個向量了,因此我們達到了資料降維的效果,
(3)奇異值的應用3:壓縮
矩陣的奇異值分解可以用于壓縮矩陣資訊,我們注意到矩陣的展開式
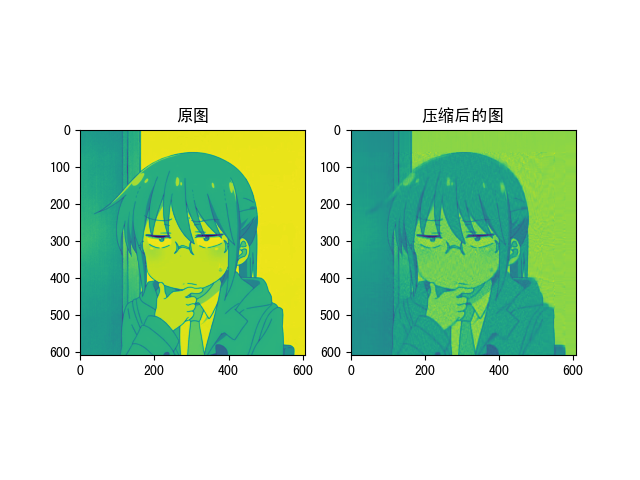
\[\bm{A} = \sum_{i=1}^{r}s_i\bm{u}_i\bm{v}_i^{T} \]中,每一項使用兩個向量\(\bm{u}_i\),\(\bm{v}_i\),以及一個數字\(s_i\)定義,如果\(\bm{A}\)是一個\(n\times n\)矩陣,我們可以嘗試矩陣\(\bm{A}\)的有損壓縮,及扔掉求和后面的幾項,它們具有較小的\(s_i\),也就是說對資料的存盤而言顯得“無關緊要”,就這樣,我們可以保留前\(p\)項,將矩陣的\(p\)秩近似做為矩陣的壓縮結果,\(p\)越多則近似矩陣對矩陣的近似程度越高,壓縮程度越低;\(p\)越少則近似矩陣對矩陣的近似程度越低,壓縮程度越高,每一項包括\(\bm{u}_i\)向量、\(\bm{v}_i\)向量和一個數字\(s_i\),總共需要\(2n+1\)個數字保存或者傳輸,例如,當\(n=8\)時,矩陣由\(64\)個圖片定義,但是我們可以傳輸或者保存矩陣的第一項展開,僅僅使用\(2n+1=17\)個數字,如果大量資訊可以由第一項捕捉, 例如,當第一個奇異值比其他的奇異值大得多的時候,以這種方式處理可能節省\(75\%\)的空間,
演算法如下:
import numpy as np
from sklearn.decomposition import PCA
import cv2 as cv
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif']=[u'SimHei']
mpl.rcParams['axes.unicode_minus']=False
def approximation(A, p):
U, s, V_T = np.linalg.svd(A)
B = np.zeros(A.shape)
for i in range(p):
B += s[i]*U[:,i].reshape(-1, 1).dot(V_T[i, :].reshape(1, -1))
return B
if __name__ == '__main__':
img = cv.imread("chapter12.特征值和奇異值/12.4.SVD的應用/12.4.3.影像壓縮/img.jpeg", flags=0)
img_output = img.copy()
# p為近似矩陣的秩,秩p<=r,p越大影像壓縮程度越小,越清晰
p = 50
img_output = approximation(img, p)
fig, axs = plt.subplots(1, 2)
axs[0].imshow(img)
axs[0].set_title('原圖')
axs[1].imshow(img_output)
axs[1].set_title('壓縮后的圖')
plt.savefig('chapter12.特征值和奇異值/12.4.SVD的應用/12.4.3.影像壓縮/result.png')
plt.show()
最終圖片的壓縮效果:
知名程式庫和原始碼閱讀建議
SVD 演算法有很多優秀的開源甚至分布式的實作,這里推薦幾個專案:
(1) Gensim
Gensim 是一個采用 Python 和 Cpython 實作的自然語言庫,提供了很多統計自然語言處理演算法的實作,也包括我們這里提到的 SVD 演算法,
檔案地址:https://radimrehurek.com/gensim/
原始碼地址:https://github.com/RaRe-Technologies/gensim.git
(2) Spark-MLlib
Spark 除了包含 GraphX,它還包括了機器學習庫 MLlib,其中就有奇異值分解的分布式實作,
檔案地址:https://spark.apache.org/mllib/
原始碼地址:https://github.com/apache/spark
參考文獻
- [1] Timothy sauer. 數值分析(第2版)[M].機械工業出版社, 2018.
- [2] Golub, Van Loan. 矩陣計算[M]. 人民郵電出版社, 2020.
- [3] 深度學習推薦系統[M]. .2020
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/319597.html
標籤:其他
上一篇:二叉樹的遍歷
下一篇:二叉樹的遍歷