
目錄
1 問題重述
2 思路分析
2.1 第一問
2.2 第二問
2.3 第三問
2.4 第四問
3 代碼效果
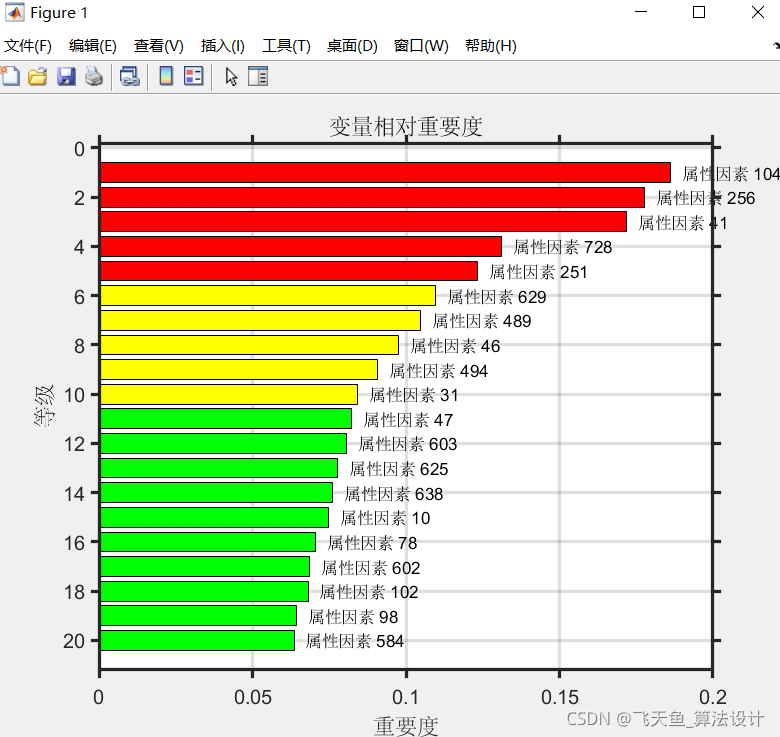
3.1 第一問 重要性分析
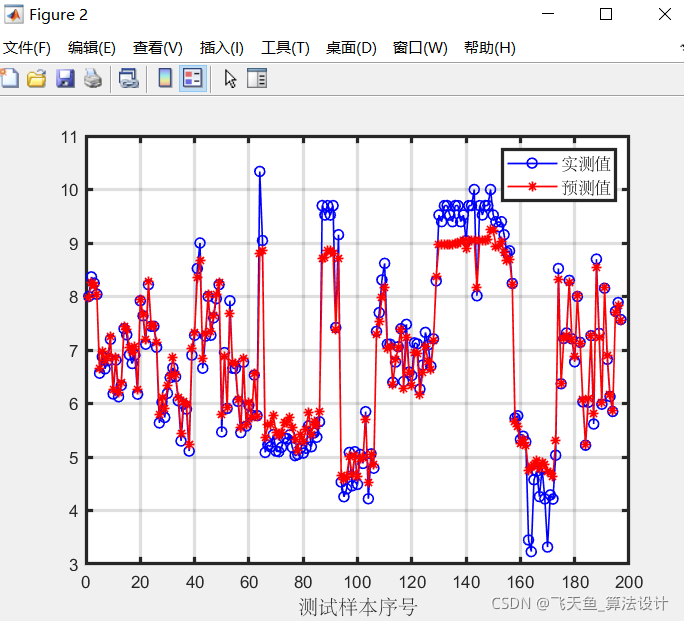
3.2 第二問 預測結果(資料在作業區點開相應變數可以看到)
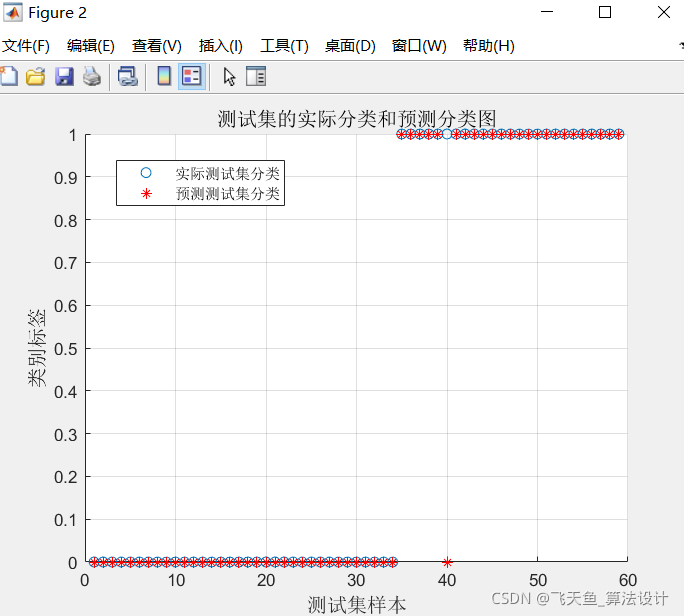
3.3 第三問 支持向量機二分類結果
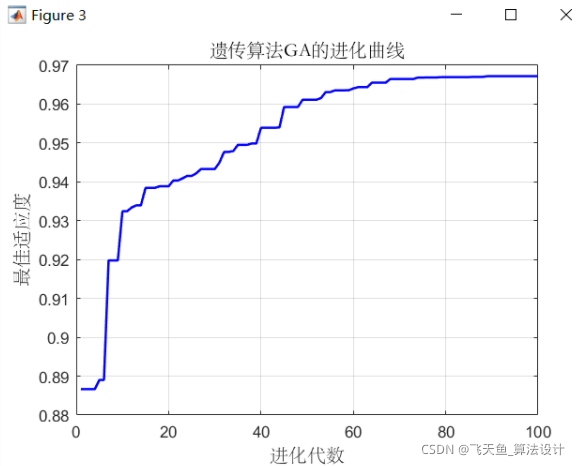
3.4 BP神經網路結合遺傳演算法尋優結果
1 問題重述
問題1. 根據檔案“Molecular_Descriptor.xlsx”和“ERα_activity.xlsx”提供的資料,針對1974個化合物的729個分子描述符進行變數選擇,根據變數對生物活性影響的重要性進行排序,并給出前20個對生物活性最具有顯著影響的分子描述符(即變數),并請詳細說明分子描述符篩選程序及其合理性,
問題2. 請結合問題1,選擇不超過20個分子描述符變數,構建化合物對ERα生物活性的定量預測模型,請敘述建模程序,然后使用構建的預測模型,對檔案“ERα_activity.xlsx”的test表中的50個化合物進行IC50值和對應的pIC50值預測,并將結果分別填入“ERα_activity.xlsx”的test表中的IC50_nM列及對應的pIC50列,
問題3. 請利用檔案“Molecular_Descriptor.xlsx”提供的729個分子描述符,針對檔案“ADMET.xlsx”中提供的1974個化合物的ADMET資料,分別構建化合物的Caco-2、CYP3A4、hERG、HOB、MN的分類預測模型,并簡要敘述建模程序,然后使用所構建的5個分類預測模型,對檔案“ADMET.xlsx”的test表中的50個化合物進行相應的預測,并將結果填入“ADMET.xlsx”的test表中對應的Caco-2、CYP3A4、hERG、HOB、MN列,
問題4. 尋找并闡述化合物的哪些分子描述符,以及這些分子描述符在什么取值或者處于什么取值范圍時,能夠使化合物對抑制ERα具有更好的生物活性,同時具有更好的ADMET性質(給定的五個ADMET性質中,至少三個性質較好),
2 思路分析
2.1 第一問
第一問,根據題意,ERa_activity中一般采用plC50來表示生物活性值,因此輸出指標選用plC50列就行,Molecular_Descriptor有729個影響因素指標,需要根據各指標對活性值的重要性進行排序,再得出前20以內最重要的因素,
模型分析:
從重要性分析角度,可選用的模型為隨機森林對袋外資料的重要性分析方法,BP神經網路敏感性分析MIV方法,BP網路輸出層各節點的權值占比方法等,從關聯性角度,也可考慮灰色關聯分析等,需要注意的是,主成分分析降維所得變數為重組型,即改變了原始變數,因此PCA不適用第一問,
相關代碼(代碼包提供算例資料,換自己資料就行了)
基于隨機森林的變數重要性分析
2.2 第二問
先明確本題核心為預測應用,即采用第一問中的前20個最重要的指標構建預測模型,分別對IC50和plC50預測,第一種思想,可對IC50和pIC50以及相應的20個變數,分開構建兩個資料集表格,即建立兩個預測模型,然后單獨對兩個輸出指標預測,第二種思想,根據第一問的20個最重要因素和pIC50指標建立預測模型,然后對plC50預測,最后再根據題意給出的負對數關系,由預測的pIC50計算出IC50的值即可,需要注意的是,實際問題中的實測值和負對數處理的值,雖然本質不同,但由于對數處理前后的線性關系被改變,因此,采用第一種思想分開預測,可對比看哪種方式的預測精度較好,從而得出預測模型合適的資料構建方法,接下來對參考的預測模型做介紹:
1 BP神經網路預測,適合處理非線性擬合問題,需要注意的是,由于BP神經網路初始的權值閾值引數隨機化,因此BP神經網路預測的結果具有隨機性,需要多次運行BP,保存一個較好的BP模型,再實作對指定因素的預測輸出,另外,由于BP神經網路初始的引數具有隨機性,對模型精度影響較大,也可以考慮用遺傳演算法,粒子群演算法,灰狼演算法等經典的優化方法(新穎的方法如麻雀搜索演算法2020,天鷹優化器,2021)優化BP神經網路引數,再做預測,
2 隨機森林預測,隨機森林是利用多棵樹對樣本進行訓練并預測的一種分類器,也可以用于非線性回歸預測問題,隨機森林的優勢在于快速處理大量資料,并且可以評估變數的重要性(這在2.1第一問已分析),同樣的,隨機森林RF模型的初始葉子數目,森林大小,根深度fboot等引數對隨機森林預測模型的精度影響較大,可以采用遺傳演算法,粒子群演算法,鯨魚優化演算法等方法優化隨機森林的引數取值,獲取最優的隨機森林模型,再實作對指定資料的預測,
3 支持向量機預測(SVR模型,區分于SVM分類),以及遺傳演算法,灰狼演算法,布谷鳥演算法等優化支持向量機的懲罰因子C與和引數g引數進行預測,
4 極限學習機ELM預測,極限學習機的訓練過只需要求解輸出權重,對于大量資料而言,訓練速度相當快,但是存在隱含層節點過高,造成計算機資源冗余,泛化性能不好等問題,使用遺傳演算法優化極限學習機的效果較好,
相關代碼(代碼包提供算例資料,換自己資料就行了)
1 BP神經網路預測和對指定輸入資料預測
2 遺傳演算法優化BP神經網路預測和對指定輸入資料預測
3 粒子群演算法優化BP神經網路預測和對指定輸入資料預測
2.3 第三問
先明確本題核心為五個獨立的分類問題,即分別對Caco-2、CYP3A4、hERG、HOB、MN五個預判指標,建立各自的01二分類模型即可,可用演算法如下:
1. 支持向量機SVM分類,SVM是一種按監督學習方式對資料進行二元分類的廣義線性分類器,分類精度受初始的懲罰因子C與核引數g的影響較大,可以結合遺傳演算法,粒子群演算法,灰狼演算法,麻雀搜索演算法等方法優化支持向量機做分類,在構建好支持向量機分類模型,進行訓練與測驗后,可以對指定的輸入特征預測其標簽,獨立分開做五個指標的訓練測驗和預測標簽三步,即可完成第三問,
2. 其他分類模型,比如BP神經網路,遺傳演算法優化BP神經網路,極限學習機等,注意這些方法的原理都是基于one-hot編碼,由于0為無效位,所以將EXCEL中的01改成1和2類,再讀取到程式中進行分類模型的訓練和測驗,預測指定標簽型別,即可完成任務,
3. 長短期記憶網路LSTM分類,LSTM建立的是非線性模型,可作為復雜的非線性單元用于構造大型的分類器,注意實作LSTM分類,要求MATLAB版本在2018a及以上,
相關代碼(代碼包提供算例資料,換自己資料就行了)
基于粒子群演算法優化支持向量機分類和對指定特征資料預測
2.4 第四問
第一種方法,優先考慮活性值最大,求化合物活性最高對應的相應引數的取值或者范圍,在得到幾組較高活性的引數搭配后,通過將幾組最佳引數回帶到第三問分類器并預測型別的方法進行篩選,從而得出滿足五個ADMET性質較好的引數取值,這種情況下,第一步活性最大,是常規的非線性模型和智能優化演算法的結合優化問題,需要結合2.2預測應用模型,以最常用的BP神經網路為例,在訓練和測驗BP神經網路精度后,以BP神經網路的輸出最大值(活性plc50值最大)作為智能優化演算法的適應度函式,第一問的前20個最重要作為優化引數,即可求解,相關的智能優化演算法,可以用遺傳演算法,粒子群演算法,參考文獻較多,實作起來容易,在得到較好的引數后,結合第三問的分類模型,再代入分類器來預測這些最佳引數的性質,從而篩選得到優先考慮活性值最大且滿足ADMET中相關的幾個性質較好的描述符(自變數)最優值,
相關代碼(代碼包提供算例資料,換自己資料就行了)
代碼鏈接:https://pan.baidu.com/s/10Yik2OFaqmSlyrFSFRun2A 提取碼:1111
第二種方法,根據化合物活性最高且盡可能使得第三問的五個ADMET性質較好,來求得對應的相應引數的取值或者范圍,這個是多目標優化問題,需要結合非線性回歸預測模型,分類模型以及多目標智能優化演算法(采用NSGAII)求解組合優化問題,需要結合2.2預測應用模型,以及第三問的五個指標分類器,以最常用的BP神經網路和支持向量機為例,在訓練和測驗BP神經網路精度后,以BP神經網路的輸出最大值(活性,plc50值最大)作為NSGAII演算法的第一個目標,第三問的五個ADMET性質作為其他優化目標,并自行選定相關分子描述符(即自變數),即可求解,相關的智能優化演算法,可以用多目標遺傳演算法NSGAII,多目標粒子群演算法MPSO,多目標灰狼優化演算法MGWO,其中,NSGAII演算法參考文獻較多,實作起來容易,
相關代碼(代碼包提供算例資料,換自己資料就行了)
代碼鏈接:https://pan.baidu.com/s/10Yik2OFaqmSlyrFSFRun2A 提取碼:1111
3 代碼效果
3.1 第一問 重要性分析
3.2 第二問 預測結果(資料在作業區點開相應變數可以看到)
3.3 第三問 支持向量機二分類結果
3.4 BP神經網路結合遺傳演算法尋優結果
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/319625.html
標籤:AI
上一篇:編程之旅前言
下一篇:《攻防世界》學習筆記——web篇