參考自:大資料技能競賽之hadoop完全分布式集群搭建(三)
練習內容:
- 安裝并配置Hadoop相關環境;
- 相關組態檔,并確定master為namenode,slave1和slave2為datanode;
- 配置Yarn運行環境;
- 設定Yarn核心引數;
- 格式化HDFS,開啟Hadoop完全分布式集群,
1. 將對應軟體包解壓到指定路徑/usr/hadoop:
在master、slave1、slave2上操作以下三個步驟:
- 創建 /usr/hadoop 目錄:
mkdir /usr/hadoop - 切換至hadoop安裝包所在目錄:
cd /usr/package/ - 解壓縮至指定路徑:
tar -zxvf hadoop-2.7.3.tar.gz -C /usr/hadoop
2. 配置Hadoop環境變數
在master、slave1、slave2上操作:
vim /etc/profile
=== 添加以下內容 ===
#HADOOP_HOME
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
使檔案生效:source /etc/profile
3. 配置Hadoop運行環境hadoop-env.sh
在master、slave1、slave2上操作:
- 切換至Hadoop環境目錄:
cd /usr/hadoop/hadoop-2.7.3/etc/hadoop - 修改hadoop-env.sh內容:
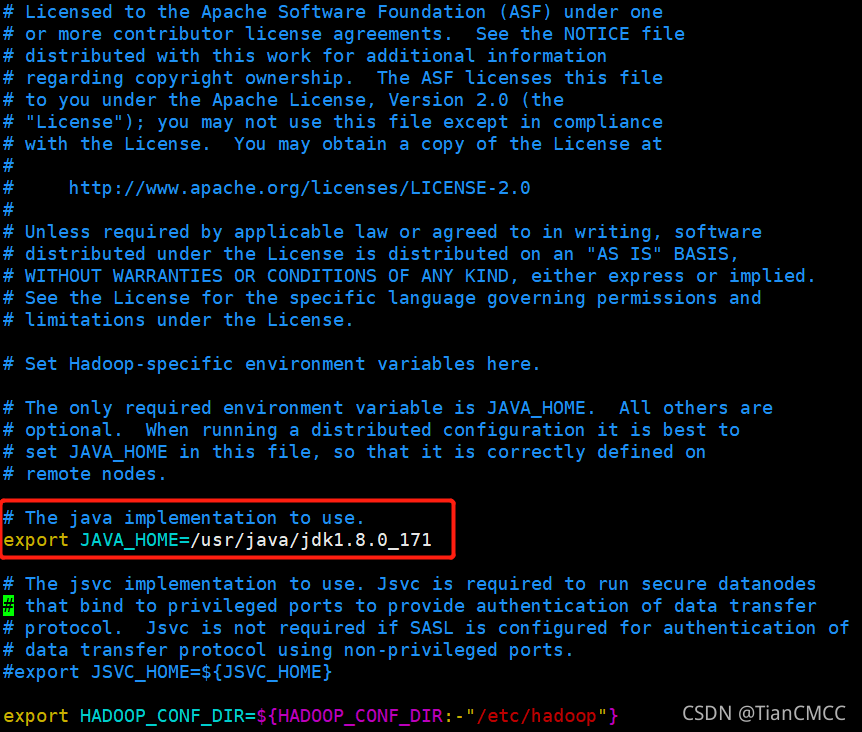
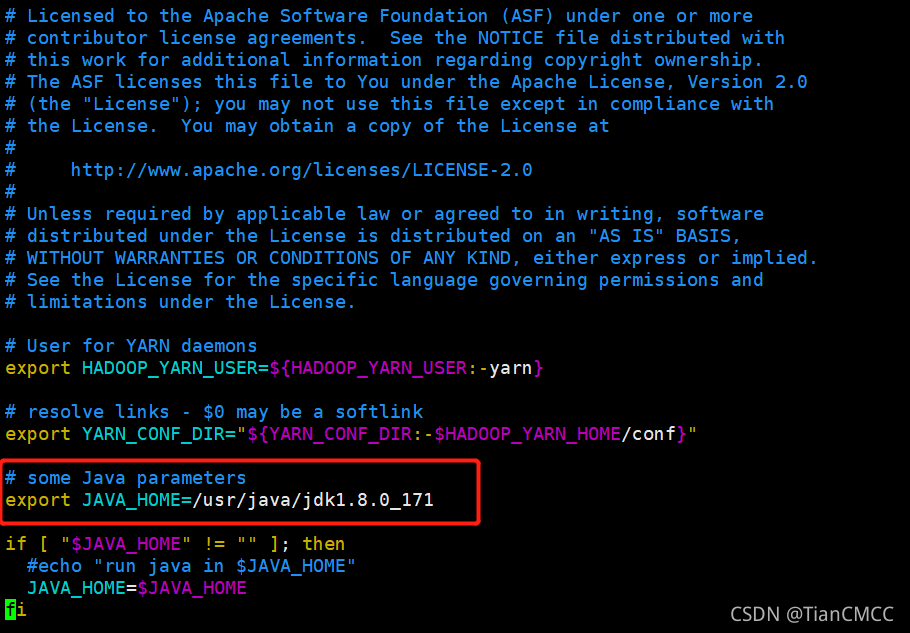
vim hadoop-env.sh - 將第25行處修改為當前的JAVA_HOME路徑(集群基礎配置中JAVA_HOME路徑):
export JAVA_HOME=/usr/java/jdk1.8.0_171
4. 設定全域引數,指定NN(NameNode)的IP為master(映射名),埠為9000:
在master、slave1、slave2上操作:
修改 core-site.xml 檔案(還是在 /usr/hadoop/hadoop-2.7.3/etc/hadoop 路徑下)
vim core-site.xml
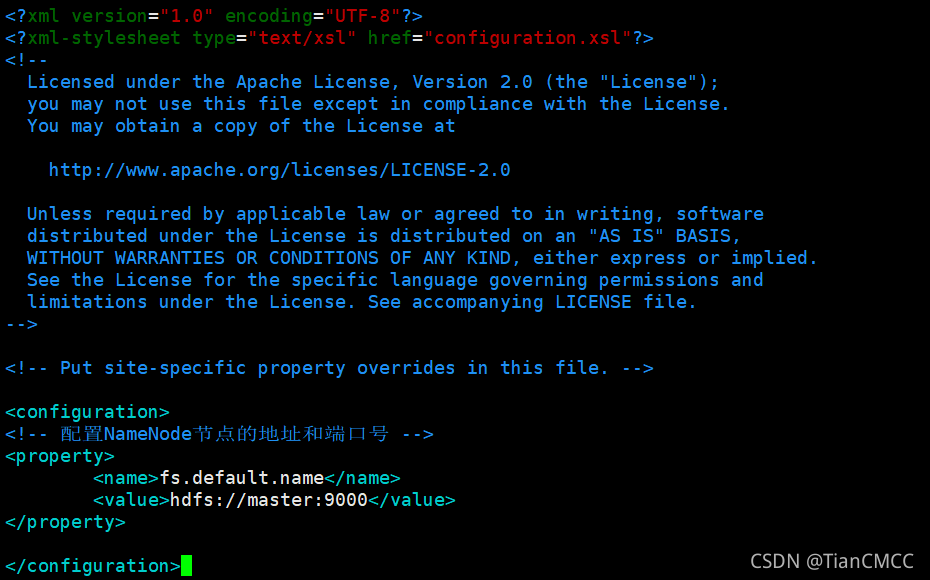
在<configuration></configuration>中添加如下內容
<!-- 配置NameNode節點的地址和埠號 -->
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
5. 指定存放臨時資料的目錄為hadoop安裝目錄下/hdfs/tmp(絕對路徑):
在master、slave1、slave2上操作:
還是修改 core-site.xml 檔案,
vim core-site.xml
(hadoop安裝目錄: /usr/hadoop/hadoop-2.7.3)
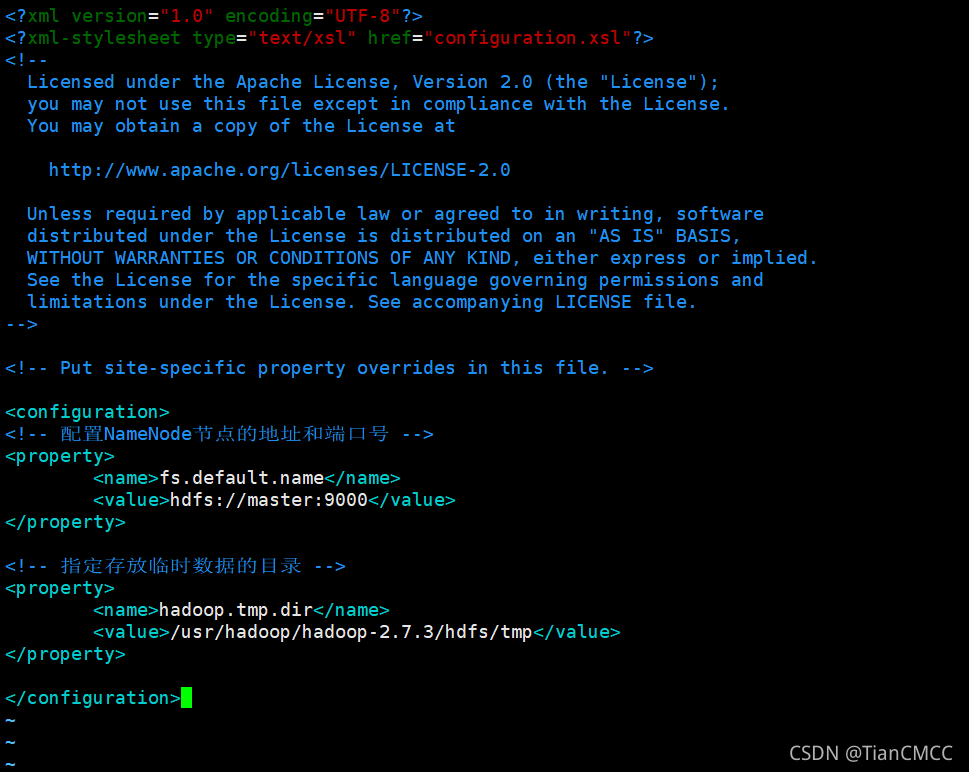
在<configuration></configuration>中添加如下內容 :
<!-- 指定存放臨時資料的目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.7.3/hdfs/tmp</value>
</property>
6. 設定HDFS引數:
在master、slave1、slave2上操作:
修改 hdfs-site.xml 檔案以設定HDFS引數:
vim hdfs-site.xml
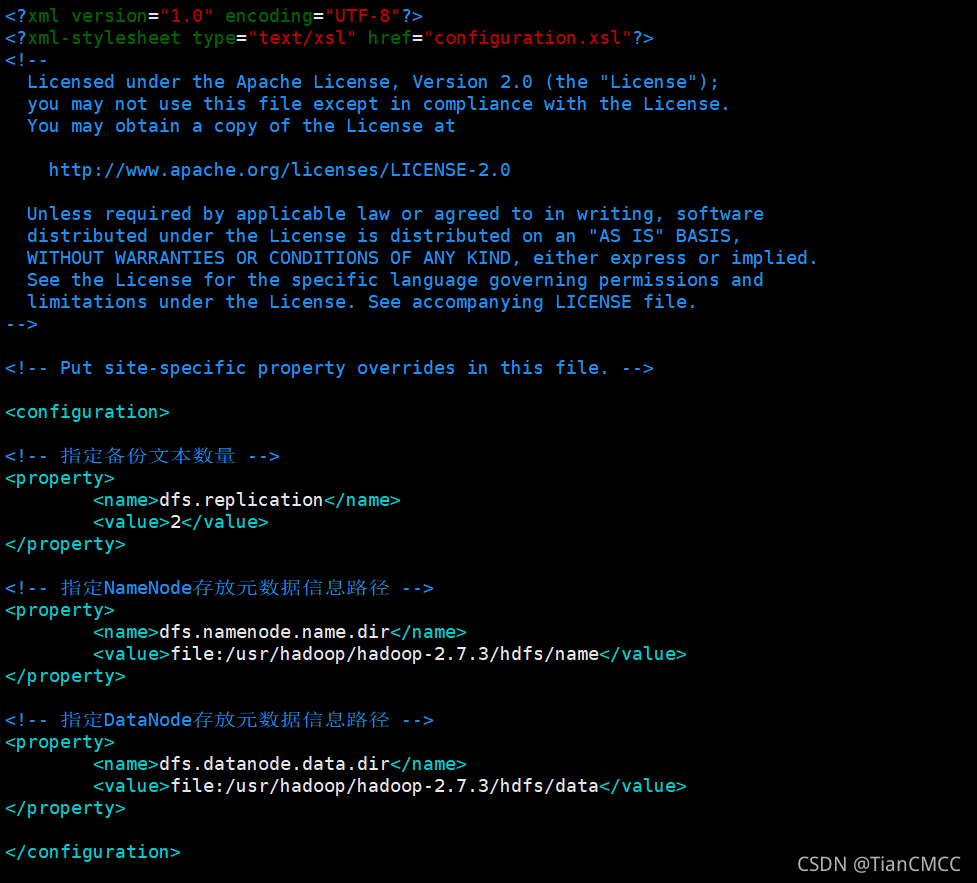
- 指定備份文本數量為2:
<!-- 指定備份文本數量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
- 指定NameNode存放元資料資訊路徑為hadoop目錄下/hdfs/name:
<!-- 指定NameNode存放元資料資訊路徑 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/name</value>
</property>
- 指定DataNode存放元資料資訊路徑為hadoop安裝目錄下/hdfs/data:
<!-- 指定DataNode存放元資料資訊路徑 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/data</value>
</property>
7. 設定YARN運行環境:
在master、slave1、slave2上操作:
vim yarn-env.sh
修改yarn-env.sh中的第23行為JAVA_HOME路徑:
export JAVA_HOME=/usr/java/jdk1.8.0_171
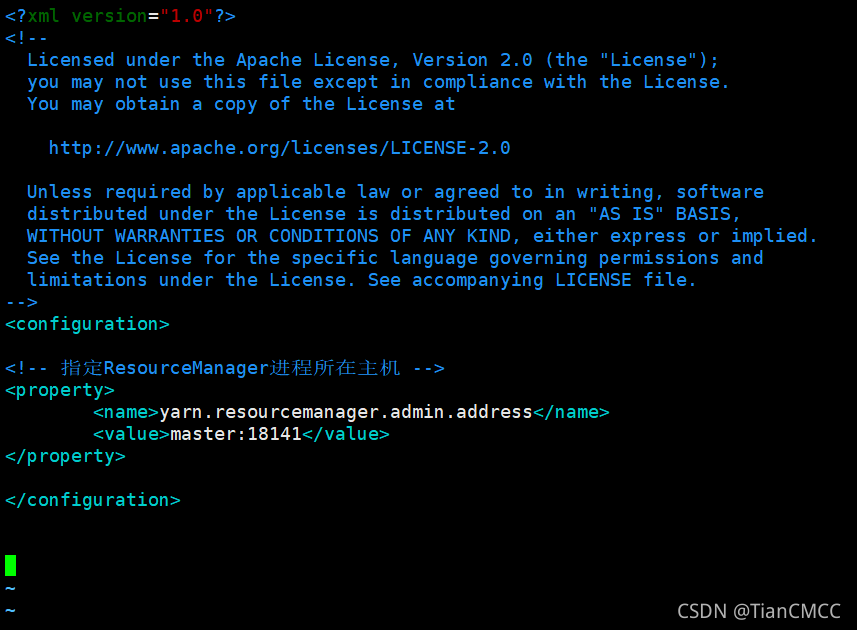
8. 設定YARN核心引數,指定ResourceManager行程所在主機為master,埠為18141:
在master、slave1、slave2上操作:
vim yarn-site.xml
在<configuration></configuration>中添加如下內容 :
<!-- 指定ResourceManager行程所在主機 -->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
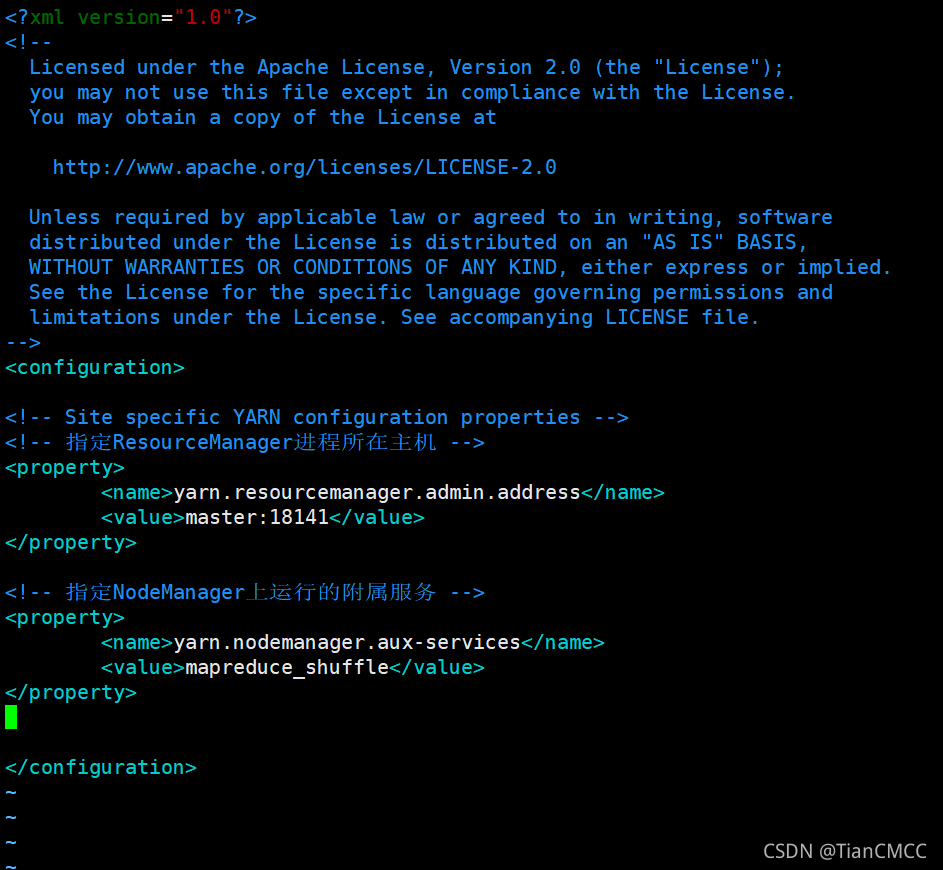
9. 設定YARN核心引數,指定NodeManager上運行的附屬服務為shuffle:
在master、slave1、slave2上操作:
vim yarn-site.xml
在<configuration></configuration>中添加如下內容 :
<!-- 指定NodeManager上運行的附屬服務 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
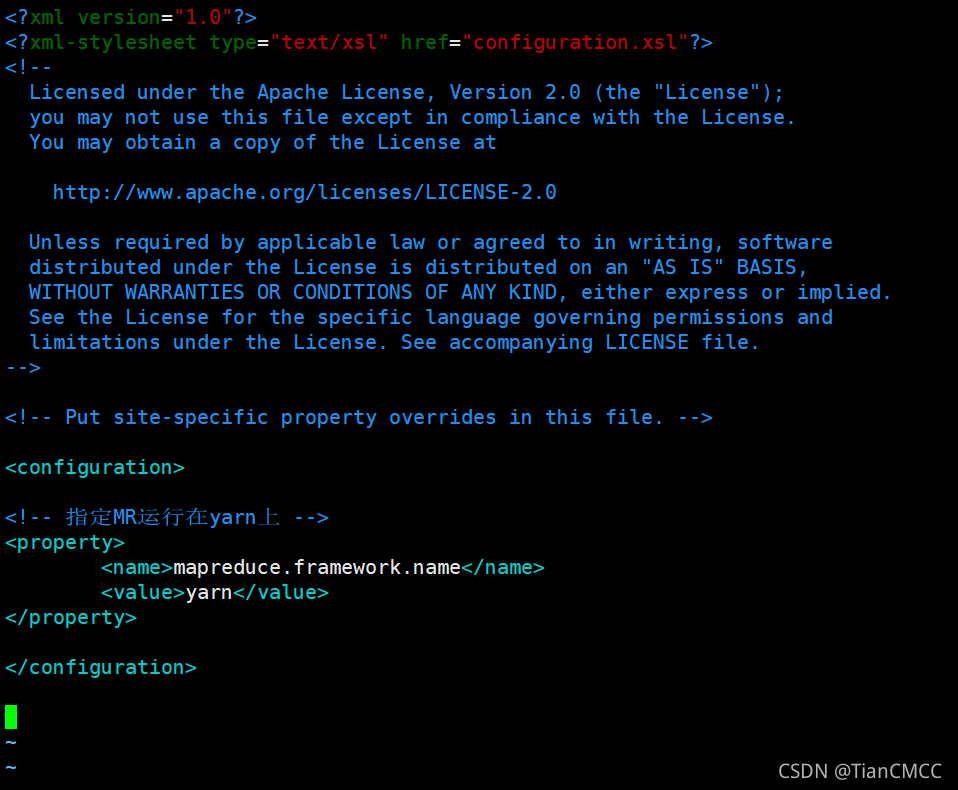
10. 設定計算框架引數,指定MR運行在yarn上:
在master、slave1、slave2上操作:
Hadoop集群中沒有mapred-site.xml這個檔案,因此需要把mapred-site.xml.template復制為mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
在<configuration></configuration>中添加如下內容 :
<!-- 指定MR運行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
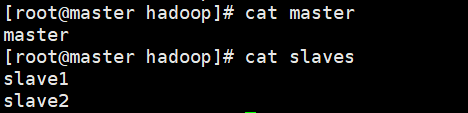
11. 設定節點檔案,要求master為主節點; slave1、slave2為子節點:
在master、slave1、slave2上操作:
還是在 /usr/hadoop/hadoop-2.7.3/etc/hadoop 路徑下,修改master、slaves檔案:
vim master
=== 寫入 ===
master
vim slaves
=== 寫入 ===
slave1
slave2
12. 檔案系統格式化:
在master上操作:
hadoop namenode -format
出現以下界面即代表格式化成功:

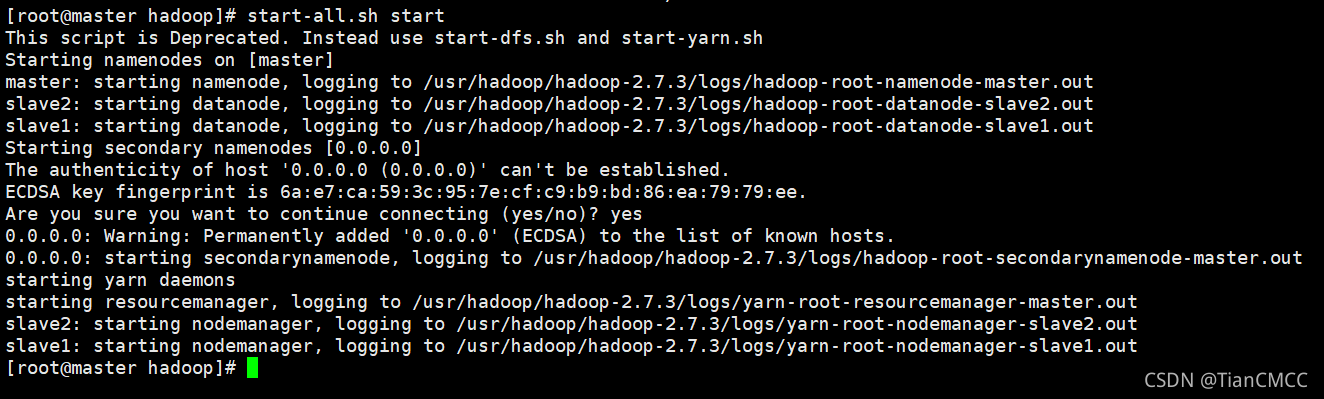
13. 啟動Hadoop集群:
在master上操作:
start-all.sh start
然后輸入 yes 即可啟動:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/319660.html
標籤:其他
上一篇:list構建資料庫父子關系