Stacking集成學習在各類機器學習競賽當中得到了廣泛的應用,尤其是在結構化的機器學習競賽當中表現非常好,今天我們就來介紹下stacking這個在機器學習模型融合當中的大殺器的原理,并在博文的后面附有相關代碼實作,
總體來說,stacking集成演算法主要是一種基于“標簽”的學習,有以下的特點:
用法:模型利用交叉驗證,對訓練集進行預測,從而實作二次學習
優點:可以結合不同的模型
缺點:增加了時間開銷,容易造成過擬合
關鍵點:模型如何進行交叉訓練?
下面我們來看看stacking的具體原理是如何進行實作的,stacking又是如何實作交叉驗證和訓練的,
一.使用單個機器學習模型進行stacking
第一種stacking的方法,為了方便大家理解,因此只使用一個機器學習模型進行stacking,stacking的方式如下圖所示:
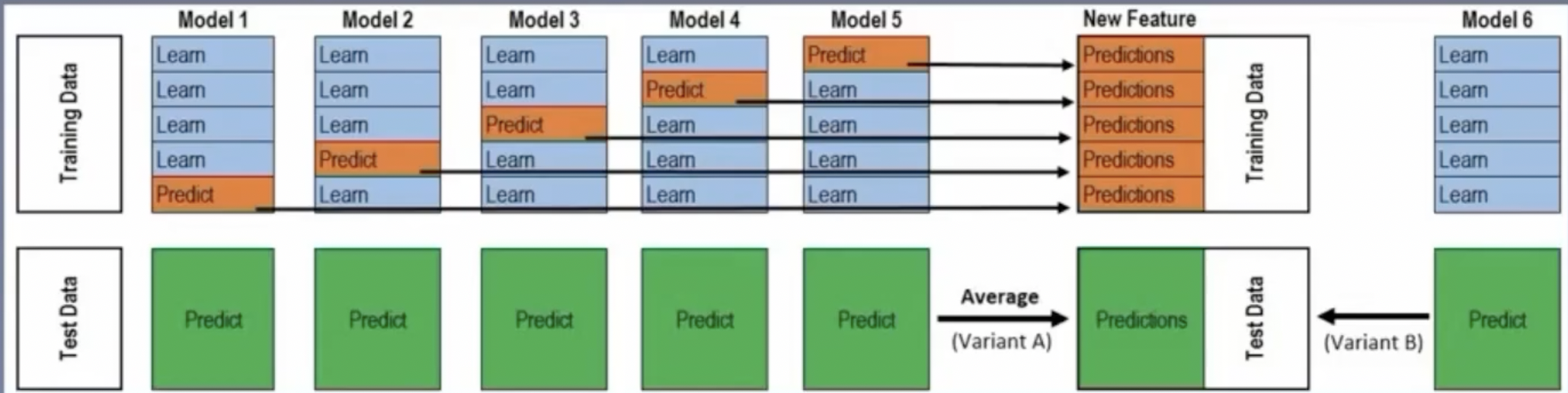
我們可以邊看圖邊理解staking程序,我們先看training data,也就是訓練資料(訓練集),我們使用同一個機器學習model對訓練資料進行了5折交叉驗證(當然在實際進行stacking的時候,你也可以使用k折交叉驗證,k等于多少都可以,看你自己,一般k=5或者k=10,k=5就是五折交叉驗證),也就是每次訓練的時候,將訓練資料拆分成5份,其中四份用于訓練我們的模型,另外剩下的一份將訓練好的模型,在這部分上對資料進行預測predict出相應的label,由于使用了5折交叉驗證,這樣不斷訓練,一共經過5次交叉驗證,我們就產生了模型對當前訓練資料進行預測的一列label,而這些label也可以當作我們的新的訓練特征,將預測出來的label作為一列新的特征插入到我們的訓練資料當中,
插入完成后,將我們新的tranning set再次進行訓練,得到我們新,也是最后的model,也就是圖中的model6,這樣就完成了第一次stacking,對于testing set而言,我們使用model 1/2/3/4/5分別對圖中下面所對應的testing data進行預測,然后得到testing set的新的一列feature,或者稱之為label,
這樣,我們就完成了一次stacking的程序,
然而,我們不僅可以stacking僅僅一次,我們還可以對當前訓練出來的模型再次進行stacking,也就是重復剛才的程序,這樣我們的訓練集又會多出一個新的一列,每stacking一次,資料就會多出一列,但是如果僅僅用一個模型進行stakcing,效果往往沒有那么好,因為這樣我們的資料和模型并不具備多樣性,也就無法從數學上保證我們資料的“獨立性”,樹模型比如bagging能夠達到很好的效果,包括我們的stacking,模型的多樣性越大,差異越大,集成之后往往會得到更好的收益,這個在數學上有嚴格的證明的,可以通過binomial distribution的方法來證明,大家了解即可,
因此這里介紹,如何使用多個機器學習模型進行stacking,這種方法在機器學習競賽當中也更加常見,
二.使用多個機器模型進行stacking
使用多個機器學習模型進行stacking其實就是每使用一個模型進行訓練,就多出一個訓練集的feature,也就是將訓練集多出一列,如下圖所示:
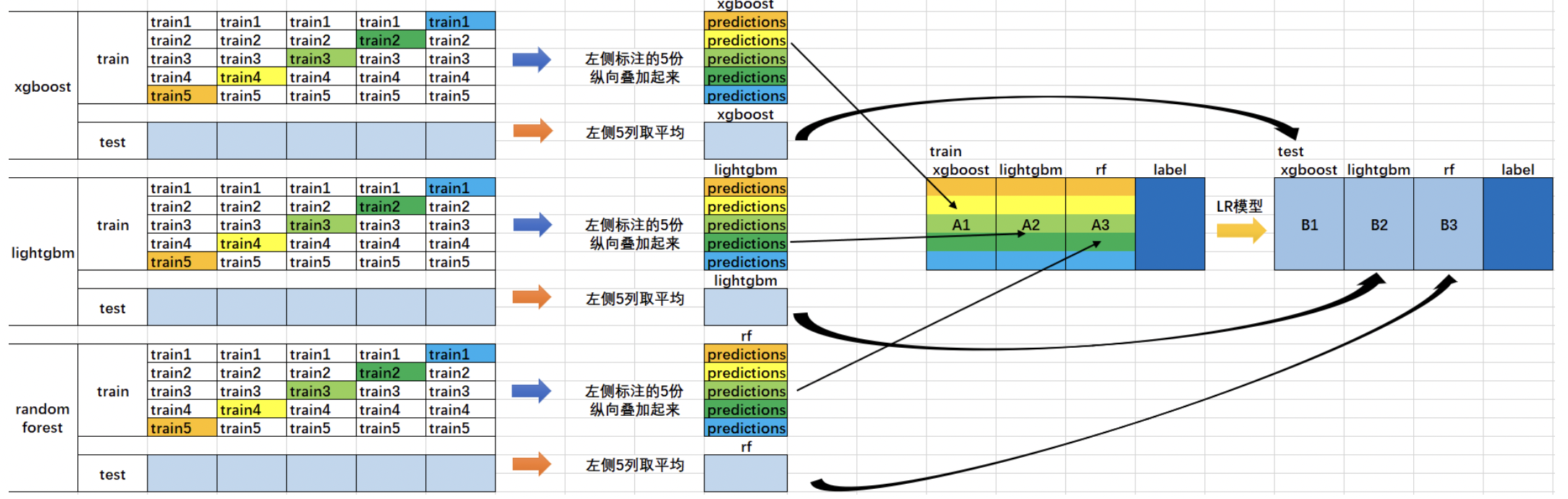
在這張圖當中,我們使用了xgboost,lightgbm,random forest分別對同一個資料集做了訓練,xgboost訓練完后,trainning set多出一列,lightgbm訓練完成后,又多出一列random forest訓練完成后,又多出一列,因此我們的traning set一共多出了三列,這樣我們再用多出這三列的資料重新使用新的機器學習模型進行訓練,就可以得到一個更加完美的模型啦!這也就是多個不同機器學習模型進行stacking的原理,同時 ,我們也可以對多個機器學習模型進行多次堆疊,也就是進行多次stakcing的操作,
三.stacking模型代碼實作(基本實作)
由于sklearn并沒有直接對Stacking的方法,因此我們需要下載mlxtend工具包(pip install mlxtend)
# 1. 簡單堆疊3折CV分類,默認為3,可以使用cv=5改變為5折cv分類 from sklearn import datasets iris = datasets.load_iris() X, y = iris.data[:, 1:3], iris.target from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import RandomForestClassifier from mlxtend.classifier import StackingCVClassifier RANDOM_SEED = 42 clf1 = KNeighborsClassifier(n_neighbors=1) clf2 = RandomForestClassifier(random_state=RANDOM_SEED) clf3 = GaussianNB() lr = LogisticRegression() # Starting from v0.16.0, StackingCVRegressor supports # `random_state` to get deterministic result. sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3], # 第一層分類器 meta_classifier=lr, # 第二層分類器,并非表示第二次stacking,而是通過logistic regression對新的訓練特征資料進行訓練,得到predicted label random_state=RANDOM_SEED) print('3-fold cross validation:\n') for clf, label in zip([clf1, clf2, clf3, sclf], ['KNN', 'Random Forest', 'Naive Bayes','StackingClassifier']): scores = cross_val_score(clf, X, y, cv=3, scoring='accuracy') print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
輸出:
3-fold cross validation: Accuracy: 0.91 (+/- 0.01) [KNN] Accuracy: 0.95 (+/- 0.01) [Random Forest] Accuracy: 0.91 (+/- 0.02) [Naive Bayes] Accuracy: 0.93 (+/- 0.02) [StackingClassifier]
畫出決策邊界:
# 我們畫出決策邊界 from mlxtend.plotting import plot_decision_regions import matplotlib.gridspec as gridspec import itertools gs = gridspec.GridSpec(2, 2) fig = plt.figure(figsize=(10,8)) for clf, lab, grd in zip([clf1, clf2, clf3, sclf], ['KNN', 'Random Forest', 'Naive Bayes', 'StackingCVClassifier'], itertools.product([0, 1], repeat=2)): clf.fit(X, y) ax = plt.subplot(gs[grd[0], grd[1]]) fig = plot_decision_regions(X=X, y=y, clf=clf) plt.title(lab) plt.show()
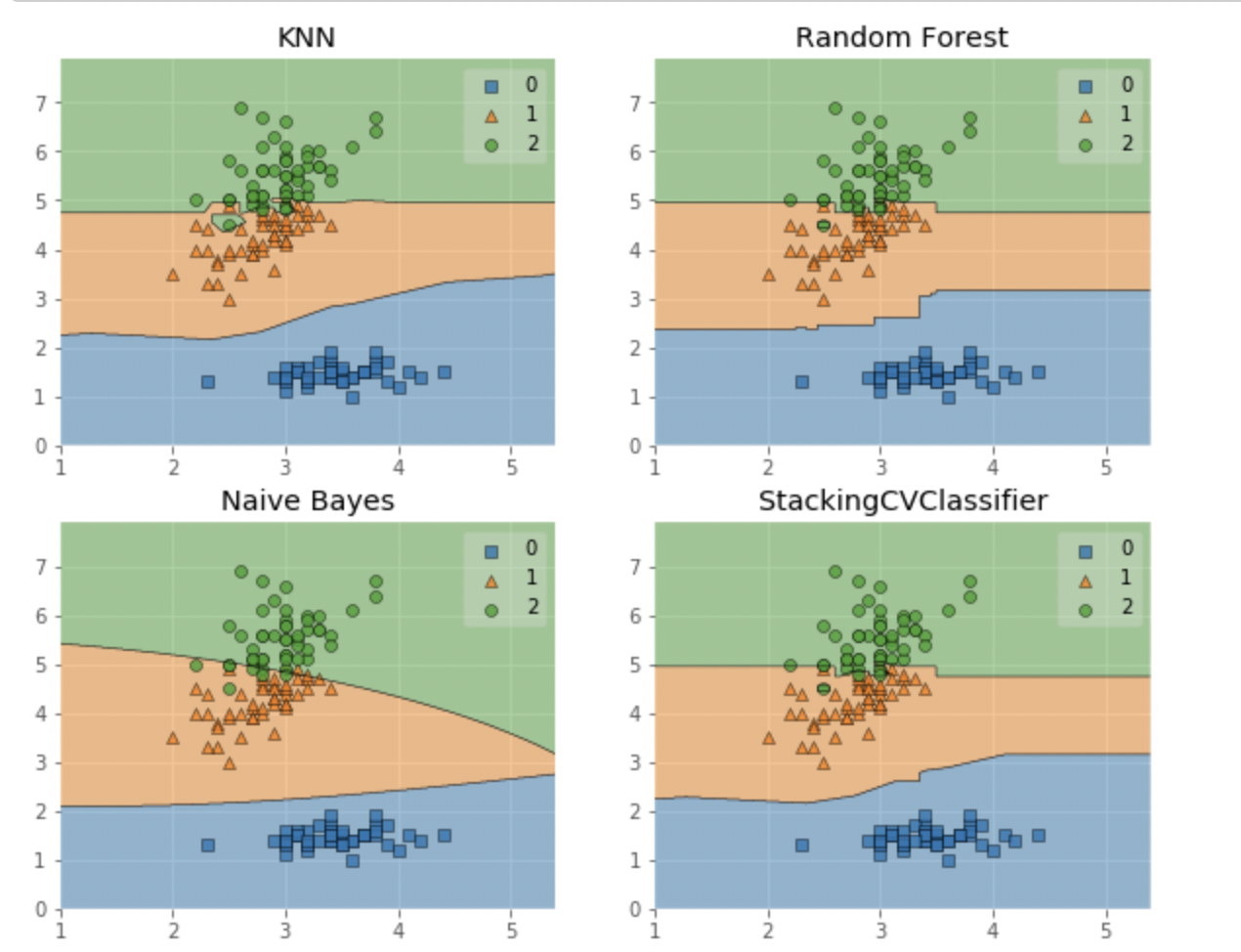
如果想要更加清楚地指定,我們的多個機器學習學到的資料輸出的概率(假設我們的label為概率),是否會被平均,按照多個模型的平均值來變成我們的訓練資料的列(個人不太推薦這么干,因為一旦平均之后,其實就缺失了一些模型差異性的資訊和特征,這樣在某些情況下反而得不太好的結果),因此我們使用以下的代碼:
# 使用概率作為元特征 clf1 = KNeighborsClassifier(n_neighbors=1) clf2 = RandomForestClassifier(random_state=1) clf3 = GaussianNB() lr = LogisticRegression() sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3], use_probas=True, average_probas = False, meta_classifier=lr, random_state=42) #average_probas = False 表示不對概率進行平均 print('3-fold cross validation:\n') for clf, label in zip([clf1, clf2, clf3, sclf], ['KNN', 'Random Forest', 'Naive Bayes', 'StackingClassifier']): scores = cross_val_score(clf, X, y, cv=3, scoring='accuracy') print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
輸出:
3-fold cross validation: Accuracy: 0.91 (+/- 0.01) [KNN] Accuracy: 0.95 (+/- 0.01) [Random Forest] Accuracy: 0.91 (+/- 0.02) [Naive Bayes] Accuracy: 0.95 (+/- 0.02) [StackingClassifier]
四.Stacking配合grid search網格搜索實作超引數調整
# 3. 堆疊5折CV分類與網格搜索(結合網格搜索調參優化) from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import GridSearchCV from mlxtend.classifier import StackingCVClassifier # Initializing models clf1 = KNeighborsClassifier(n_neighbors=1) clf2 = RandomForestClassifier(random_state=RANDOM_SEED) clf3 = GaussianNB() lr = LogisticRegression() sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3], meta_classifier=lr, random_state=42) params = {'kneighborsclassifier__n_neighbors': [1, 5], 'randomforestclassifier__n_estimators': [10, 50], 'meta_classifier__C': [0.1, 10.0]} grid = GridSearchCV(estimator=sclf, param_grid=params, cv=5, refit=True) grid.fit(X, y) cv_keys = ('mean_test_score', 'std_test_score', 'params') for r, _ in enumerate(grid.cv_results_['mean_test_score']): print("%0.3f +/- %0.2f %r" % (grid.cv_results_[cv_keys[0]][r], grid.cv_results_[cv_keys[1]][r] / 2.0, grid.cv_results_[cv_keys[2]][r])) print('Best parameters: %s' % grid.best_params_) print('Accuracy: %.2f' % grid.best_score_)
輸出:
0.947 +/- 0.03 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 10}
0.933 +/- 0.02 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 50}
0.940 +/- 0.02 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 10}
0.940 +/- 0.02 {'kneighborsclassifier__n_neighbors': 1, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 50}
0.953 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 10}
0.953 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 50}
0.953 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 10}
0.953 +/- 0.02 {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 10.0, 'randomforestclassifier__n_estimators': 50}
Best parameters: {'kneighborsclassifier__n_neighbors': 5, 'meta_classifier__C': 0.1, 'randomforestclassifier__n_estimators': 10}
Accuracy: 0.95
得到最后最好的引數如上,當然如果,你想要更好的搜索引數,可以使用貝葉斯搜索引數,或者隨機引數搜索法,對引數進行搜索,
結語:在這篇博文當中,我論述了stacking的原理和python的代碼實作,希望大家讀完后會有識訓,如果覺得看了有識訓的同學,請在下方點個贊,推薦一下,謝謝啦!
參考文獻:
1.https://github.com/Geeksongs/ensemble-learning/blob/main/CH5-%E9%9B%86%E6%88%90%E5%AD%A6%E4%B9%A0%E4%B9%8Bblending%E4%B8%8Estacking/Stacking.ipynb
2.https://www.cnblogs.com/Christina-Notebook/p/10063146.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/320905.html
標籤:其他