1 最優化概論
(1) 最優化的目標
最優化問題指的是找出實數函式的極大值或極小值,該函式稱為目標函式,由于定位\(f(x)\)的極大值與找出\(-f(x)\)的極小值等價,在推導計算方式時僅考慮最小化問題就足夠了,極少的優化問題,比如最小二乘法,可以給出封閉的決議解(由正規方程得到),然而,大多數優化問題,只能給出數值解,需要通過數值迭代演算法一步一步地得到,
(2) 有約束和無約束優化
一些優化問題在要求目標函式最小化的同時還要求滿足一些等式或者不等式的約束,比如SVM模型的求解就是有約束優化問題,需要用到非線性規劃中的拉格朗日乘子和KKT條件,這里我們僅介紹無約束優化,有約束優化放在后面的章節講解,
(3) 線性和非線性規劃
線性函式是指目標函式和約束都為線性的優化問題,非線性規劃是指目標函式和約束有一個為非線性的優化問題,線性規劃一般在運籌學(經濟模型、圖論網路流等)中有重要運用,而非線性規劃在機器學習中有著重要的運用,我們把主要目光放在非線性規劃,
(4) 凸優化和非凸優化
按照斯坦福 Boyd 教授(撰寫凸優化圣經《convex optimization》的那位)的觀點,優化問題的分水嶺不是線性和非線性,而是凸和非凸,這句話側面說明了凸優化做為一種特殊的優化問題,顯得非常重要,尤其是在機器學習領域,那么為什么凸優化會如此重要呢?首先我們拉看什么是凸函式,凸函式的定義如下:
① \(Ω\)為凸集,如果對任意的\(x_1,x_2 \in Ω\)以及每一個\(α(0\leqslant \alpha \leqslant 1)\),有 \(f(αx_1+(1-\alpha)x_2)<=αf(x_1) + (1-α)f(x_2)\),則稱定義在凸集上的函式\(f\)是凸的(convex),
② \(Ω\)為凸集,如果對每一個\(α(0<α<1)\)以及\(x_1,x_2 \in Ω\)且\(x_1\neq x_2\),有\(f(αx_1+(1-α)x_2)<αf(x_1) + (1-α)f(x_2)\)則稱\(f\)是嚴格凸的(strictly convex),
以下展示了幾個凸函式的影像例子,從幾何角度看沒如果圖形中兩點的連線處處都不在圖形的下方,則函式是凸的,或者做為二維空間中的函式,如果函式的圖形是碗狀的,這個函式就是凸的,

那么凸函式有什么神奇的性質值得我們為之興奮呢?我們有定理:\(f\)是至少含有一個內點的凸集\(Ω\)上的凸函式,當前僅當\(f\)的Hessian矩陣\(\bm{H}\)在整個\(Ω\)上是半正定的,
此處Hessian矩陣正是函式的曲率概念在\(\R^n\)上的推廣,凸函式在每個方向上都有正(至少是非負)的曲率,如果一個函式的Hessian矩陣在一個小區域內是半正定的,則稱該函式是區域凸的;如果Hessian矩陣在這個區域內是正定的(但不妨礙我說\(\bm{H}\)在整個\(Ω\)上是半正定的,細品),則稱這個函式是嚴格區域凸的(locally strictly convex),
以下插入一下函式極值點的必要和充分條件的介紹:
函式極值點的必要和充分條件
而我們對于任意一個無約束優化問題,函式的最值是要滿足一階必要條件和二階必要條件的,
一階必要條件: 設\(Ω\)是\(\R^n\)的一個子集并且\(f\)是\(Ω\)上的函式,如果\(\bm{x}^*\)是\(f\)在\(Ω\)上的相對極小點,那么對\(\bm{x}^*\)點處的任意一個可行的方向\(\bm{d}∈\R^n\),有\(?f(\bm{x}^*)\bm{d}>=0\),一個非常重要的特殊情形發生在當\(\bm{x}^*\)在\(Ω\)內部時(\(\bm{x}^*\)是\(Ω\)的內點,\(Ω=\R^n\)就對應這種情形),在這種情況下,從\(\bm{x^*}\)發散出去的每個方向都是可行方向,因此對所有的\(\bm{d}∈\R^n\),都有\(\nabla f(\bm{x}^{*})\bm{d}>=0\),這就意味著\(\nabla f(\bm{x}^*)=0\),
二階必要條件: 設\(Ω\)是\(\R^n\)的一個子集并且\(f\)是\(Ω\)上的函式,如果\(\bm{x}^*\)是\(f\)在\(Ω\)上的相對極小點,那么對\(\bm{x}^*\)處的任意一個可行方向\(\bm{d}∈Ω\),有:
① \(?f(\bm{x}^*)\bm{d}>=0\)
② 如果\(?f(\bm{x}^*)\bm{d}=0\),那么\(d^T?^2f(\bm{x}^*)\bm{d}>=0\)
同樣的,我們在無約束情形下,設\(\bm{x}^*\)是集合\(Ω\)的內點,并且設\(\bm{x}^*\)是函式\(f\)在\(Ω\)上的一個內點,那么:
① \(\nabla f(\bm{x}^*)=0\)
② 對所有\(\bm{d}\),\(\bm{d}^T?^2f(\bm{x}^*)\bm{d}\geqslant0\)(這個條件等價于說明Hessian矩陣\(\bm{H}\)是半正定的)
二階充分條件:稍微加強一下二階必要條件的條件②,我們就能得到\(\bm{x^*}\)是相對極小點的條件:
① \(?f(\bm{x}^*)=0\);
② \(\bm{H}(\bm{x}^*)\)正定,
那么\(\bm{x}^*\)是\(f\)的一個嚴格相對極小點(因為嚴格正定,不存在Hessain矩陣\(\bm{H}\)特征值為0的困擾)
而上面說了,如果Hessian矩陣在這個區域內是正定的,則稱這個函式是嚴格區域凸的(locally strictly convex),故我們看出上面說的的二階充分條件要求在每個點\(\bm{x}^*\)處的函式是嚴格區域凸的,
推廣之,設\(f\)是定義在凸集\(Ω\)上的凸函式,那么使函式達到極小值的點集\(Γ\)是凸集,并且\(f\)的相對極小點也是全域極小點,
這下大家應該知道凸函式的好處了,凸函式沒有“坑坑洼洼”,相對極小就是全域極小,這樣找到相對極小點就可以收功,便于設計出高效的優化演算法,如我們求解SVM中的SMO演算法(SVM是個凸優化問題),而有很多“坑坑洼洼”的函式想要找到全域極小點是NP-hard問題,只能采用遺傳演算法、退火演算法這類啟發式演算法進行求解,我們在深度學習中的大多數函式(可以把帶激活層的神經網路當成一個嵌套的函式)是非凸的,不過我們找到這類函式的全域最小值意義不大,一般我們找到區域極小擬合程度就足夠好,從而可以解決我們的問題了,因此,在神經網路中我們一般不采用啟發式演算法來優化,多是采用隨機梯度下降、擬牛頓法、動量法等“更正統”的優化演算法來找到區域最優解以近似全域最優解,
2 不使用導數的無約束優化——Fibonacci 搜索(也稱黃金分割搜索)
(1) 線搜索演算法
在一條已知的直線(只有一個變數)上確定極小點的程序,被稱為線搜索(line search),對于一般不能決議地求極小值的非線性函式,這一程序實際上是采用一些巧妙的沿直線搜索的方法來實作的,這些線搜索技巧實際上就是求解一維極小化問題的方法,因為高維問題最終是通過進行一系列逐次線搜索來求解的,所以這些線搜索方法是非線性規劃演算法的基石,
(2) 黃金分割搜索
求解線搜索問題的一個最普遍的方法是本節所描述的斐波那契搜索方法,一旦解的范圍已知,黃金分割搜索是一種有效找出單變數函式\(f(x)\)的最小值的方式,我們假設\(f\)是一個單峰函式,在區間\([a,b]\)上具有相對極小,選擇區間內的兩點\(x_1\)和\(x_2\),使得\(a<x_1<x_2<b\),我們將使用新的更小的區間替換原始區間,根據以下法則該區間可以繼續括住極小值,如果\(f(x_1)\leqslant f(x_2)\),則在下一步中保持區間\([a, x_2]\),如果\(f(x_1)>f(x_2)\),則保持\([x_1, b]\),如下圖所示,
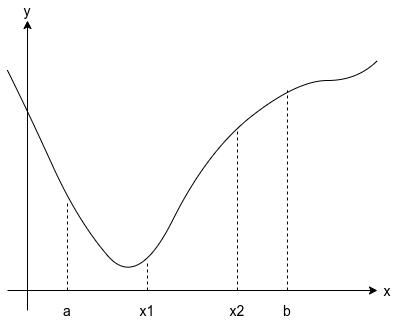
不過,我們如何將\(x_1\)和\(x_2\)放置在區間\([a,b]\)上呢?我們在選擇\(x_1\)和\(x2\)時有兩個標準:
(a) 關于區間保持對稱(由于我們不知道極小在區間的哪一側)
(b) 選擇\(x_1\)和\(x_2\)使得不管在下一步中使用哪種選擇,\(x_1\)和\(x_2\)都是下一步中的某個采樣點,為了簡化討論,我們以\([a,b]=[0, 1]\)為例子,可以推廣到其他區間,即要求\(x_1 = 1 - x_1\)(關于區間中心對稱),\(x_1 = x_2^2\),如下圖所示,如果新區間為\([0, x_2]\),標準(b)保證原始的\(x_1\)將會在下個區間中變為\(x_2\),因而僅僅需要進行依次函式求值,即\(f(x_1g)\),(這里\(g\)為\(x_2\)的初始值)同樣,如果新的區間為\([x_1, 1]\),則\(x_2\)變為新的"\(x_1\)",這種重用函式求值的能力意味著在第一步后,每步僅需要目標函式的單次求值,每輪迭代演示如下:
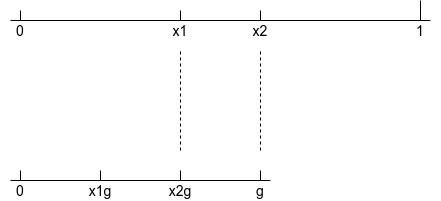
根據上圖所示,我們需要選擇黃金分割搜索的比例,即\(x_2\)所放置的位置, 舊區間和新區間的比例為\(1/g = (1+ \sqrt{5})/2\),即黃金分割,這樣,每輪放置的\(x_1 = 1-g=(1+ \sqrt{5})/2,x_2 = g = ( \sqrt{5} ? 1)/2=0.618\),如下圖所示:
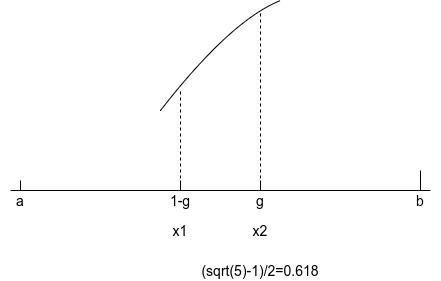
下面我們采用黃金分割演算法求
在區間\([0,1]\)上的最小值:
import numpy as np
import math
def gss(f, a, b, k):
g = (math.sqrt(5)-1)/2
# 計算x1和x2
x1 = a + (1-g)*(b-a)
x2 = a + g*(b-a)
f1, f2 = f(x1), f(x2)
for i in range(k):
if f1 < f2 :
# 依次更新b, x2, x1
b = x2
x2 = x1
# 這里代碼設計的很巧妙,b是已經更新后的新b
x1 = a + (1-g)*(b-a)
f2 = f1
f1 = f(x1)
else:
a = x1
x1 = x2
x2 = a + g*(b-a)
f1 = f2
f2 = f(x2)
y = (a+b)/2
return(a, b), y
if __name__ == '__main__':
a, b = 0, 1
k = 15
(a,b), y = gss(lambda x: x**6-11*x**3+17*x**2-7*x+1, a, b, k)
print("(%.4f, %.4f)"%(a, b), y)
演算法的運行結果如下:
(0.2834, 0.2841) 0.28375198388070366
可以看到函式\(f(x)=x^6-11x^3+17x^2-7x+1\)在區間\([0,1]\)上的最小值在\(0.2834\)到\(0.2841\)之間,可以近似為\(0.28375\),
3 使用一階導數的無約束優化——梯度下降法
設\(f\)是多元函式,\(\bm{x}^{(t)}\)和\(\bm{x}^{(t+1)}\)都是向量,梯度下降法的迭代式為:
\[\bm{x}^{(t+1)} = \bm{x}^{(t)}-η?f(\bm{x}^{(t)}) \]這里\(η\)是優化演算法的迭代步長,在機器學習領域一般稱為學習率,學習率做為機器學習演算法的一個重要的超引數,其大小對機器學習模型的學習效果有著重要影響,太小了迭代演算法可能根本無法收斂,太大了可能產生震蕩而錯過極小值,
下面我們采用梯度下降演算法求函式
的最小值(采用Pytorch框架求梯度):
import numpy as np
import math
import torch
#x.grad為Dy/dx(假設Dy為最后一個節點)
def gradient_descent(x0, k, f, eta): #迭代k次,包括x0在內共k+1個數
# 初始化計算圖引數
x = torch.tensor(x0, requires_grad=True)
for i in range(1, k+1):
y = f(x)
y.backward()
with torch.no_grad():
x -= eta*x.grad
x.grad.zero_() #這里的梯度必須要清0,否則計算是錯的
x_star = x.detach().numpy()
return f(x_star), x_star
# 多元函式,但非向量函式(指回傳值為向量)
def f(x):
return 5*x[0]**4 + 4*x[0]**2*x[1] - x[0]*x[1]**3 + 4*x[1]**4 - x[0]
if __name__ == '__main__':
x0 = np.array([1.0, -1.0])
k = 25 # k為迭代次數
eta = 0.01 # ita為迭代步長
minimum, x_star = gradient_descent(x0, k, f, eta)
print("the minimum is %.5f, the x_star is: ( %.5f, %.5f)"\
% (minimum, x_star[0], x_star[1]))
該演算法運行結果如下:
the minimum is -0.44577, the x_star is: ( 0.52567, -0.41689)
可以看到,演算法最終收斂到點\(x^*=( 0.52567, -0.41689)^T\),最小值為\(-0.44577\),
(注意,這里的求導操作采用的Pytorch內置的Autograd工具,關于Autograd工具的使用,請查閱Pytorch官方檔案(地址: https://pytorch.org/tutorials/beginner/basics/autogradqs_tutorial.html),這里不再贅述,Pytorch中的Autograd求梯度采用的是反向傳播演算法(類似與動態規劃從后往前逐步計算導數),后面我們在講解多層感知機的時候會學習這個演算法,這里會呼叫tensor.backward()這個API使用即可,
4 使用二階導數的無約束優化——牛頓法
(1) 引例:牛頓法求方程的根
我們現在有個問題是求函式的,為了找到函式\(f(x)=0\)的根,給定一個初始估計\(x^{(0)}\),畫出函式\(f\)在\(x^{(0)}\)點的切線,用切線來近似函式\(f\),求出其與\(x\)軸的交點做為函式\(f\)的根,但是由于函式\(f\)的彎曲,該交點可能并不是精確解,因而,該步驟要迭代進行,
從下面的幾何影像中我們可以推出牛頓方法的公式,
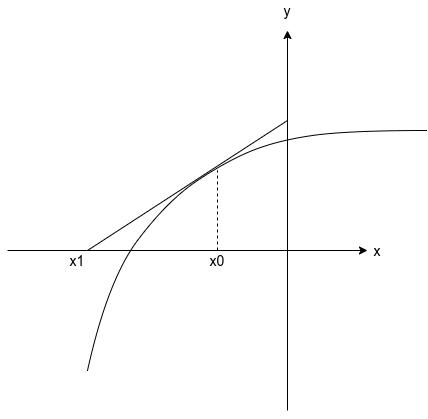
\(x^{(0)}\)點的切線斜率可由導數\(f^{'}(x^{(0)})\)給出,切線上的一點是\((x^{(0)}, f(x^{(0)}))\),一條直線的點斜率方程是\(y-f(x^{(0)}) = f^{'}(x^{(0)})(x-x^{(0)})\),因而切線和\(x\)軸的交點等價于在直線中令\(y=0\):
求解\(x\)得到根的近似,我們稱之為\(x^{(1)}\),然后重復整個程序,從\(x^{(1)}\)開始,得到\(x^{(2)}\),等等,進而得到如下的牛頓法迭代公式:
\[\left \{ \begin{aligned} & x^{(0)} = 初始估計\\ & x^{(t+1)} = x^{(t)} - f(x^{(t)})/f^{'}(x^{(t)}) \\ \end{aligned} \right. \]下面我們采用牛頓法求方程
\[f(x) = x^3 + x - 1 = 0 \]的根如下:
import numpy as np
import math
import torch
#x.grad為dy/dx(假設dy為最后一個節點)
def newton(x0, k, f): #迭代k次,包括x0在內共k+1個數
# 初始化計算圖引數
x = torch.tensor([x0], requires_grad=True)
for i in range(1, k+1):
# 前向傳播,注意x要用新的物件,否則后面y.backgrad后會釋放
y = f(x)
y.backward() # y.grad是None
# 更新引數
with torch.no_grad():
x -= torch.divide(y, x.grad)
x.grad.zero_() # 清空梯度,使下一輪建立新的計算圖,否則因為backward釋放資源下一輪再backward出錯
#注意x.grad不能是0,否則要出錯使g(x)/x.grad變為none
return x.detach().numpy()[0]
if __name__ == '__main__':
f = lambda x: x**3 + x - 1
x0 = 1.0
res = newton(x0, 10, f)
print(res)
該演算法運行結果如下:
0.6823278
可以看到,最終方程的根收斂到0.6823278
(2) 牛頓法求多元函式極值
牛頓法的基本思想是利用一個二次函式區域地近似要極小化的函式\(f\)(對于\(f\)是多元函式的情況,即在某個特定的點用一個曲面去近似函式),然后求出這個近似函式的精確極小點,例如在\(\bm{x}^{(t)}\)附近我們用\(f\)的二階泰勒展開式來近似\(f\),即:
\[f(\bm{x})≈q(\bm{x})=f(\bm{x}^{(t)})+?f(\bm{x}^{(t)})(\bm{x}-\bm{x}^{(t)})+\frac{1}{2}(\bm{x}-\bm{x}^{(t)})^T\bm{H}(\bm{x}^{(t)})(\bm{x}-\bm{x}^{(t)}) \]求上式右端的極小點,即使用上面介紹的牛頓法求解方程\(q^{'}(x)=0\),
即
這樣,我們通過求使得\(q\)的導數為零的點來計算\(f\)極小點\(\bm{x}\)的一個估計值\(\bm{x}^{(t+1)}\),于是可以得到:
\[\bm{x}^{(k+1)} = \bm{x}^{(t)} - \bm{H}^{-1}(\bm{x}^{(t)})?f(\bm{x}^{(t)}) \quad (修正后可能引入阻尼因子η) \]這就是牛頓法的迭代式,如果目標函式單峰,在區間中具有極小值,則使用極小值附近的初始估計開始牛頓方法的計算,這將會收斂到極小值\(\bm{x}^*\),不過,直接使用矩陣求逆演算法復雜度較高(矩陣求逆演算法見《Introduction to algorithms》矩陣運算一章), 我們這里采用直接求解方程\(\bm{H}(\bm{x}^{(t)})\bm{v} = -?f(\bm{x}^{(t)})\),并令\(\bm{x}^{(t+1)} = \bm{x}^{(t)} + \bm{v}\), 這樣可以提高計算效率(雖然復雜度仍然是\(O(n^3)\),但常數階減少了),下面我們采用牛頓法求多元函式
\[f(\bm{x}) = 5x_1^4 + 4x_1^2x_2 - x_1x_2^3 + 4x_2^4 - x_1 \]的極值演算法如下:
import numpy as np
import math
import torch
from torch.autograd.functional import hessian
from torch.autograd import grad
# 多元函式,但非向量函式
def f(x):
return 5*x[0]**4 + 4*x[0]**2*x[1] - x[0]*x[1]**3 + 4*x[1]**4 - x[0]
#x.grad為Dy/dx(假設Dy為最后一個節點)
def gradient_descent(x0, k, f, alpha): #迭代k次,包括x0在內共k+1個數
# 初始化計算圖引數
x = torch.tensor(x0, requires_grad=True)
for i in range(1, k+1):
y = f(x)
y.backward()
# 1階導數可以直接訪問x.grad
# 高階倒數我們需要呼叫functional.hession介面,這里回傳hession矩陣
# 注意,Hession矩陣要求逆
H = hessian(f, x)
with torch.no_grad():
# 如果為了避免求逆,也可以解線性方程組Hv = -x.grad,使x+v
# v = np.linalg.solve(H, -x.grad)
# x += torch.tensor(v)
x -= torch.matmul(torch.inverse(H), x.grad)
x.grad.zero_()
x_star = x.detach().numpy()
return f(x_star), x_star
if __name__ == '__main__':
x0 = np.array([1.0, 1.0])
k = 25 # k為迭代次數
eta = 1 #
alpha = 0
# 基于牛頓法的推導,在最優解附近我們希望eta=1
minimum, x_star = gradient_descent(x0, k, f, alpha)
print("the minimum is %.5f, the x_star is: ( %.5f, %.5f)"\
% (minimum, x_star[0], x_star[1]))
該演算法運行結果如下:
the minimum is -0.45752, the x_star is: ( 0.49231, -0.36429)
一般而言牛頓法因為利用了二階導數資訊,收斂速度比一階方法比如梯度下降法要快,
不過牛頓法需要計算Hessian矩陣\(\bm{H}\)的逆,需要\(O(n^3)\)的時間復雜度,\(n\)在這里是變數的維度,在機器學習模型里就是需要優化引數的個數,后來出現了牛頓法的近似版本——擬牛頓法BFGS,
(3) 擬牛頓法求多元函式極值
Broyden-Fletcher-Goldfarb-Shanno(BFGS)演算法具有牛頓法的一些優點,但沒有牛頓法的計算負擔,擬牛頓法所采用的方法(BFGS是其中最突出的)是使用矩陣\(\bm{M}^t\)近似逆,迭代地近似更新精度以更好地近似\(\bm{H}^{-1}\),
BFGS的近似的說明和推匯出現在很多關于優化的教科書中,包括Luenberger和葉蔭宇編著的《Linear and nonlinear programming》第10章,當Hessian逆近似\(\bm{M}^t\)更新時,變數的最后更新為:
觀察公式可知,如果矩陣\(\bm{M}^t\)是\(f\)的Hessian矩陣的逆,這一公式就是牛頓法的迭代公式,如果\(\bm{M}^k= \bm{I}\)(單位矩陣),這一公式對應最速下降法,這里我們選取\(\bm{M}^t\)做為Hessian矩陣逆的近似,不過,即使如此,BFGS演算法必須存盤Hessian逆矩陣\(\bm{M}^t\),需要\(O(n^2)\)的存盤空間,使BFGS不適用于大多數具有百萬級引數的現代深度學習模型,
5、組合優化和 NP-Hard 問題介紹
以上我們討論的連續問題的求解演算法,這些問題最大的特點就是我們要優化的變數都是連續型的數值,然而還有一類問題是離散(組合)優化問題,這類問題 要優化的變數常常都是離散的整數,比如最短路徑問題、0-1背包問題、旅行商問題(TSP)、哈密頓回路、歐拉回路、網路流問題等,這類問題有些和離散資料結構,比如樹、圖等有關,這些問題在計算機科學領域有些得到了經典的專用演算法,如解決單源最短路徑的Dijkstra演算法、多源最短路徑的Floyd-Warshell演算法;解決網路流問題的Ford-Fulkerson演算法等,時間復雜度相對較低;但有些問題沒有經典的專用演算法,需要寫成線性規劃(常常是整數規劃)的形式進行解決,這樣演算法的時間復雜度往往很高,甚至多項式時間內不可解,
這類問題有些可以在多項式時間內給出解法,如0-1背包問題、歐拉回路問題、網路流問題等,有些在多項式時間內不可解,如旅行商問題(TSP)、哈密頓回路等,(有趣的是,歐拉回路和哈密頓回路極其相似,歐拉回路是使一次性經過所有邊的步數最小,哈密頓回路是使一次性經過所有點的步數最小,但歐拉回路在多項式時間內可解,哈密頓回路則不然)我們一般把在多項式時間內無法找到全域最優解的問題稱為NP-Hard的,一般神經網路想找到全域最優解就是NP-Hard的,不過我們常常用區域最優解來近似全域最優解,這樣就已經能取得不錯的擬合效果了,故如何將問題表述成線性規劃形式可參見《Introduction to algorithms》第29章;具體的P問題、NP問題、NPC問題(NP完全問題)、NP-Hard問題的關系可參見《Introduction to algorithms》第34章,
知名程式庫和原始碼閱讀建議
(1) Scipy
Python 的科學計算庫 Scipy 封裝了包括線性規劃在內的很多優化演算法,熟練使用Scipy也是機器學習工程師的必備技能之一,除此之外,在數學建模類似的比賽中Numpy+Scipy+Scikit-learn+Matplotlib等的組合也是可以媲美Matlab的一大殺器,
檔案地址:https://docs.scipy.org/doc/scipy/index.html
原始碼地址:https://github.com/scipy/scipy
你如果想進一步在運籌學領域發展(包括不限于凸優化、組合優化、圖論、 動態規劃、近似演算法等)從事諸如美團物流法研發工程師等崗位,那么你可以進一步接觸大規模優化工具,比如CPLEX,Gurobi,Xpress等商業優化求解器(演算法包)其實,運籌學和控制論無處不在,強化學習的核心—Bellman-Ford方程就源于最優控制和動態規劃,
(2) CPLEX
檔案地址:https://www.ibm.com/analytics/cplex-optimizer
原始碼地址:不開源
(3) Gurobi
檔案地址:https://www.gurobi.com/
原始碼地址:不開源
(4) Xpress
檔案地址:https://www.fico.com/en/products/fico-xpress-optimization
原始碼地址:不開源
自動求導和計算圖是深度學習的精華,它是數學和工程的結合,是一個藝術品,熟練掌握Tensorflow和Pytorch等框架的自動求導機制非常重要,尤其是后面搭建神經網路模型的時候方便debug,后面我們會詳細介紹自動求導機制所用到的反向傳播演算法的底層實作,這里大家可以先通過閱讀官方檔案和原始碼的方式熟悉下,(Tensorflow和Pytorch的核心原始碼都是C++,需要一定的C++甚至 CUDA 的基礎(因為涉及到GPU并行加速))
(5) Pytorch
檔案地址: https://pytorch.org/
原始碼地址:https://github.com/pytorch/pytorch
(6) Tensorflow
檔案地址: https://tensorflow.google.cn/
原始碼地址:https://github.com/tensorflow/tensorflow
最后,Pytorch 也好,Tensorflow 也罷,它們所采用的自動求導機制都是數值求導,最終只能求出導數的數值,假如說我想知道一個給定函式的符號求導的導函式決議式呢?或者說我給定一個函式式子,想知道這個式子的不定積分決議式是什么樣的呢?(尤其是在完成數學作業的時候,尤其是高數O(∩_∩)O 哈哈~)這個時候就像你鄭重推薦Python的符號計算庫sympy,這玩意有多厲害大家自己下去研究了,我曾經試過它成功積出了21年大學生數學競賽最后一道壓軸題的一道積分,最后每一項都一模一樣,,,閱讀它的原始碼也會讓你體會到與數值計算不同的另一個世界——符號計算世界的魅力,
(7) sympy
檔案地址: https://www.sympy.org/en/index.html
原始碼地址:https://github.com/sympy/sympy
參考文獻
- [1] Luenberger D G, Ye Y. Linear and nonlinear programming[M]. Reading, MA: Addison-wesley, 1984.
- [2] Boyd S, Boyd S P, Vandenberghe L. Convex optimization[M]. Cambridge university press, 2004.
- [3] Timothy sauer. 數值分析(第2版)[M].機械工業出版社, 2018.
- [4] Cormen T H, Leiserson C E, Rivest R L, et al. Introduction to algorithms[M]. MIT press, 2009.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/320910.html
標籤:其他
上一篇:學習Socket筆記