作者主頁(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文網址:[人工智能-深度學習-23]:卷積神經網路CNN - CS231n解讀 - 卷積神經網路基本層級_文火冰糖(王文兵)的博客-CSDN博客
目錄
第1章 CS321n卷積神經網路簡介
1.1 CS321n的簡介
1.2 CS321n連接
第2章 卷積神經網路(CNNs / ConvNets)概述
2.1 卷積神經網路和常規神經網路的非常相似性
2.2 那么有哪些地方變化了呢?
2.3 常規神經網路回顧
2.3 卷積神經網路的基本結構
2.4 組成構建卷積網路的各種層
2.5 一個卷積神經網路的激活輸出例子,
第1章 CS321n卷積神經網路簡介
1.1 CS321n的簡介
CS321n是由李飛飛教授,Justin Johnson教師和Serena Yeung教授主講的計算機視覺識別課程,本課程本深入研究深度學習架構的細節,重點是學習這些任務的端到端模型,特別是影像分類,
在為期10周的課程中,學生將學會實作、訓練和除錯自己的神經網路,并詳細了解計算機視覺領域的前沿研究,
本文主要其對CNN文字講解的解讀,
1.2 CS321n連接
(1)英文鏈接
CS231n Convolutional Neural Networks for Visual Recognition
(2)中文連接
CS231n課程筆記翻譯:卷積神經網路筆記 - 知乎
(3)卷積神經網圖形解構
https://poloclub.github.io/cnn-explainer/
第2章 卷積神經網路(CNNs / ConvNets)概述
2.1 卷積神經網路和常規神經網路的非常相似性
它們都是由神經元組成,神經元中有具有學習能力的權重和偏差,
每個神經元都得到一些輸入資料,進行內積運算后再進行激活函式運算,
整個網路依舊是一個可導的評分函式
該函式的輸入是原始的影像像素,輸出是不同類別的評分,
在最后一層(往往是全連接層),網路依舊有一個損失函式(比如SVM或Softmax),并且在神經網路中我們實作的各種技巧和要點依舊適用于卷積神經網路,
2.2 那么有哪些地方變化了呢?
卷積神經網路的結構基于一個假設,即輸入資料是影像,
基于該假設,我們就向神經網路結構中添加了一些特有的性質,
這些特有屬性使得前向傳播函式實作起來更高效,并且大幅度降低了網路中引數的數量(卷積核),
2.3 常規神經網路回顧
神經網路的輸入是一個一維向量,然后在一系列的隱層中對它(一維輸入向量)做變換,
每個隱層都是由若干的神經元組成,每個神經元都與前一層中的所有神經元連接,但是在一個隱層中,神經元相互獨立不進行任何連接,
最后的全連接層被稱為“輸出層”,在分類問題中,它輸出的值被看做是不同類別的評分值(平方值通常在[0,1]之間,輸出值越大,是某個分類的可能性就越大,因此有時候也稱為輸出概率大小,
常規神經網路對于大尺寸影像效果不盡人意:
在CIFAR-10中,影像的尺寸是32x32x3(寬高均為32像素,3個顏色通道),因此,對應的的常規神經網路的第一個隱層中,每一個單獨的全連接神經元就有32x32x3=3072個權重,
這個數量看起來還可以接受,但是很顯然這個全連接的結構不適用于更大尺寸的影像,舉例說來,一個尺寸為200x200x3的影像,會讓神經元包含200x200x3=120,000個權重值,
而網路中肯定不止一個神經元,那么引數的量就會快速增加!顯而易見,這種全連接方式效率低下,大量的引數也很快會導致網路過擬合,
2.3 卷積神經網路的基本結構
神經元的三維排列,
卷積神經網路針對輸入全部是影像的情況,將結構調整得更加合理,獲得了不小的優勢,
與常規神經網路不同,卷積神經網路的各層中的神經元是3維排列的:寬度、高度和深度,這里的深度指的不是圖片數的第三個維度,即通道,也不是整個網路的深度,整個網路的深度指的是網路的層數,而是卷積核神經元的個數,每個卷積核神經元代表一組卷積輸出,
舉個例子,CIFAR-10中的影像是作為卷積神經網路的輸入,該資料體的維度是32x32x3(寬度,高度和深度),資料體的深度,是指圖片的通道數,
我們將看到,層中的神經元將只與前一層中的一小塊區域連接,而不是采取全連接方式,
對于用來分類CIFAR-10中的影像的卷積網路,其最后的輸出層的維度是1x1x10,因為在卷積神經網路結構的最后部分:將會把全尺寸的影像壓縮為包含每一種分類評分的一個向量(輸出向量),向量是在深度方向排列的,
下面是例子:
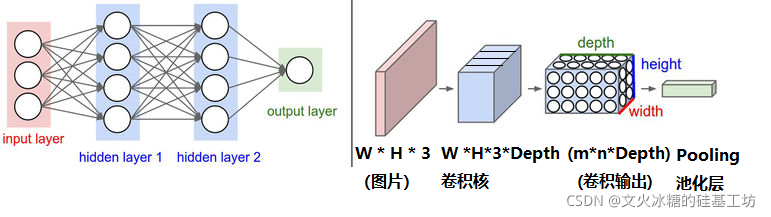
左邊是一個3層的神經網路,
右邊是一個卷積神經網路,圖例中網路將它的神經元都排列成3個維度,即3D(寬、高和深度/通道數),
卷積神經網路的每一層都將3D的輸入資料變化為神經元3D的激活資料并輸出,
在這個例子中,紅色的輸入層裝的是影像,所以它的寬度和高度就是影像的寬度和高度,它的深度是通道數3(代表了紅、綠、藍3種顏色通道),
藍色的是卷積核:Width * Height * Channels
卷積核的輸出:Width * Height * Depth, 注意此處的Width * Heigh與卷積核的With * Heigh不是一回事,
卷積神經網路是由層組成的,該網路將輸入的3D資料變換為3D的輸出資料,在變換程序中,雖然維度沒法發生變化,但是:
(1)每個維度方向上的長度得到的降低,
(2)三維維度方向的含義發生了變化,
- 輸入:長 * 寬 * 通道數,他們定義的是圖片三通道的像素值
- 卷積核:長 * 寬 * 通道數,長度和寬度比圖形小很多,用這個小卷積核過濾原始圖片的特征,
- 輸出:長 * 寬 * 深度,長 * 寬反映了某一個卷積核過濾處來的三通道圖片的特征,每個值代表一次卷積的輸出,深度反映的是,用多少個卷積核充當過濾器,來過濾整個圖片的特征,不同的卷積核,反映的不同方面的特征,比如,有些是顏色方面的特征,有些是圖形方面的特性,有些是大小方面的特征,
2.4 組成構建卷積網路的各種層
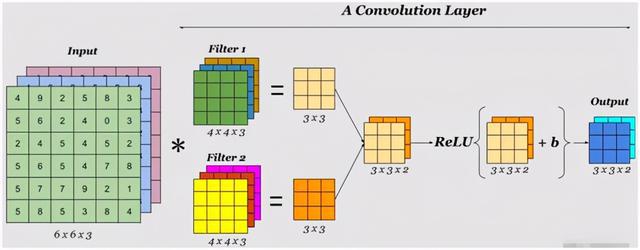
一個簡單的卷積神經網路是由各種層按照順序排列組成,網路中的每個層使用一個可以微分的函式將激活資料從一個層傳遞到另一個層,
卷積神經網路主要由三種型別的層構成:卷積層,匯聚(Pooling)層和全連接層(全連接層和常規神經網路中的一樣),通過將這些層疊加起來,就可以構建一個完整的卷積神經網路,
一個用于CIFAR-10影像資料分類的卷積神經網路的結構可以是:
[輸入層 -》卷積層 -》ReLU層 -》匯聚層 -》全連接層],如下圖所示:
- 輸入[32x32x3]存有影像的原始像素值,本例中影像寬高均為32,有3個顏色通道,
- 卷積層中,神經元與輸入層中的一個區域區域相連,每個神經元都計算自己與輸入層相連的小區域與自己權重的內積,卷積層會計算所有神經元的輸出,如果我們使用12個濾波器(也叫作卷積核),得到的輸出資料體的維度就是[32x32x12],卷積會把三個通道的資料進行整合(求和)
- ReLU層將會逐個元素地進行激活函式操作,比如使用以0為閾值的作為激活函式,該層對資料尺寸沒有改變,還是[32x32x12],
- 匯聚層在在空間維度(寬度和高度)上進行降采樣(downsampling)操作,資料尺寸變為[16x16x12],降采樣會對ReLU的特征輸出,進行進一步的降低size的采用,降低size的規則有:選擇某個小區域的最大特征輸出、某個小區所有的特征了平均值輸出等,
- 全連接層將會計算分類評分,資料尺寸變為[1x1x10],其中10個數字對應的就是CIFAR-10中10個類別的分類評分值,正如其名,全連接層與常規神經網路一樣,其中每個神經元都與前一層中所有神經元相連接,全連接就是利用前面各層發現的特征資料作為全連接分類的輸入,而不是原始的像素值作為輸入,然后進行分類,
由此看來,卷積神經網路一層一層地將影像從原始像素值變換成最終的分類評分值(概率輸出),
其中有的層含有引數,有的沒有,具體說來:
卷積層和全連接層(CONV/FC)對輸入執行變換操作的時候,不僅會用到激活函式,還會用到很多引數(神經元的突觸權值和偏差),
而ReLU層和匯聚層則是進行一個固定不變的函式操作,
卷積層和全連接層中的引數會隨著梯度下降被訓練,
這樣卷積神經網路計算出的分類評分就能和訓練集中的每個影像的標簽吻合了,
2.5 一個卷積神經網路的激活輸出例子,
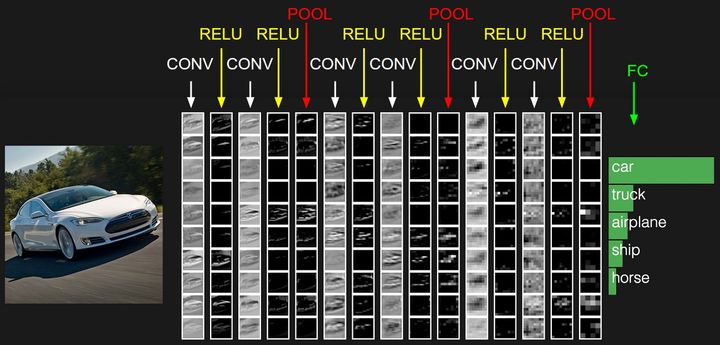
左邊的輸入層存有原始影像像素,右邊的輸出層存有類別分類評分,
在處理流程中的每個激活資料體是鋪成一列來展示的,因為對3D資料作圖比較困難,我們就把每個資料體切成層,然后鋪成一列顯示,
最后一層裝的是針對不同類別的分類得分,這里只顯示了得分最高的5個評分值和對應的類別,
作者主頁(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文網址:https://blog.csdn.net/HiWangWenBing/article/details/120799799
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/320976.html
標籤:AI