我無法使用 Python 的 xml.etree.ElementTree 庫從 XML 中提取(名稱、值)對,其中 name == 'mykey'。我想要的偽代碼是:
if (name.text == 'mykey'):
print value.text
值將是 mykey 的值,在本例中為 XX111。
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE charles-session SYSTEM "https://www.charlesproxy.com/dtd/charles-session-1_2.dtd">
<charles-session>
<header>
<name>Content-Length</name>
<value>10804</value>
</header>
<header>
<name>Date</name>
<value>Wed, 13 Oct 2021 22:02:42 GMT</value>
</header>
<header>
<name>mykey</name>
<value>XX111</value>
</header>
<header>
<name>Accept-Language</name>
<value>en-US;q=1.0, el-US;q=0.9</value>
</header>
我可以列印 'mykey' 文本,但我不知道怎么說“現在在 'mykey' 之后給我值的文本。
for name in root_node.iter('name'):
if re.match(r'mykey', name.text):
print(name.text)
uj5u.com熱心網友回復:
獲取該元素所在的元素值和行號。
請查看代碼注釋以進行解釋:
# Data setup
from io import StringIO
xml_data="""\
<?xml version="1.0" encoding="UTF-8"?>
<charles-session>
<header>
<name>Content-Length</name>
<value>10804</value>
</header>
<header>
<name>Date</name>
<value>Wed, 13 Oct 2021 22:02:42 GMT</value>
</header>
<header>
<name>mykey</name>
<value>XX111</value>
</header>
<header>
<name>Accept-Language</name>
<value>en-US;q=1.0, el-US;q=0.9</value>
</header>
</charles-session>
"""
現在獲取要查找的元素及其值。
# define the root
root = ET.parse(StringIO(xml_data)).getroot()
# based on xpath get the key and its value
for each in root.findall(".//header"):
if "mykey" in each[0].text:
print(each[1].text)
從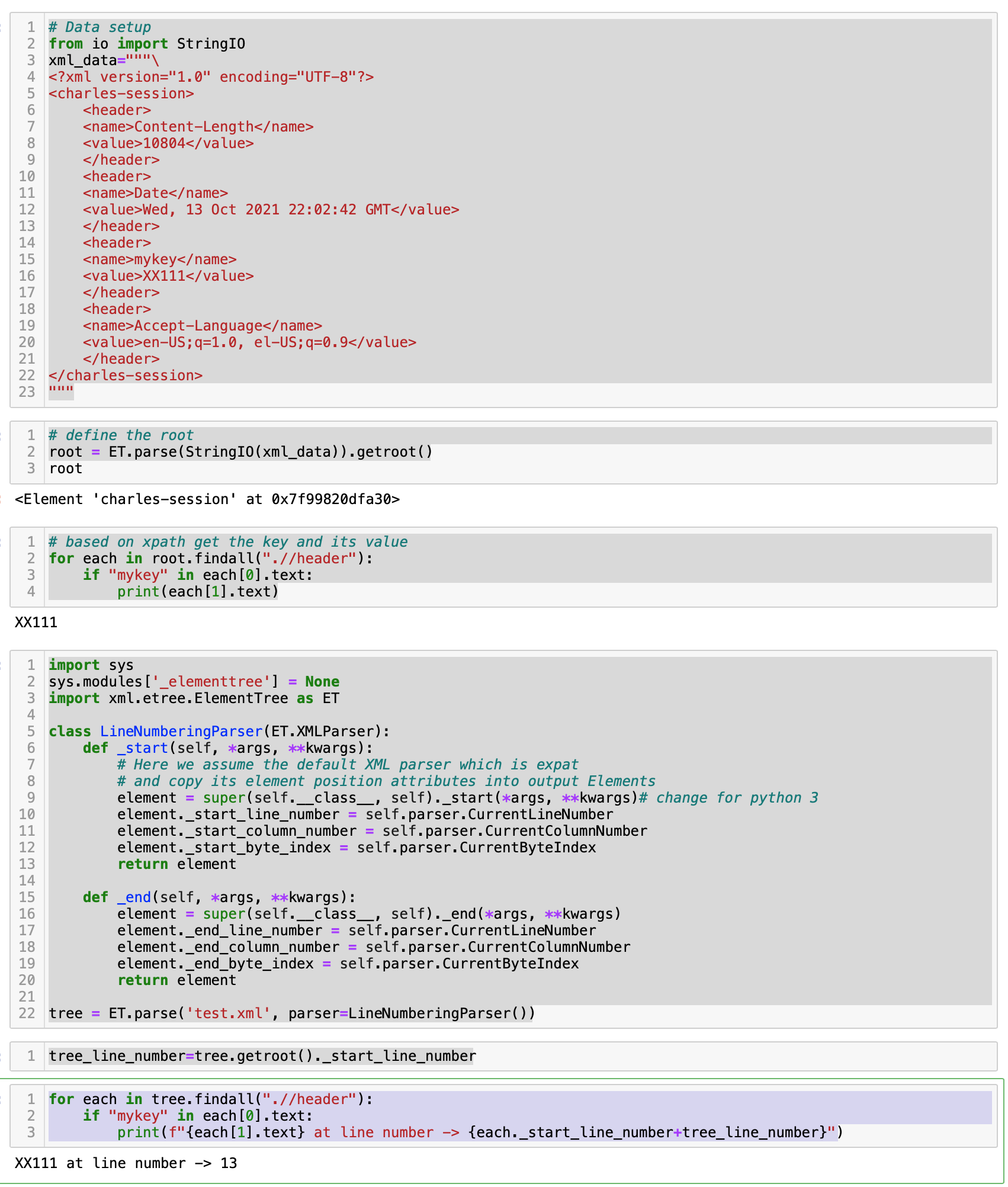
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/321715.html