概述
本文基于 “KubeSphere & Friends 2021 Meetup 北京站” 分享主要內容整理而來,詳細內容建議觀看視頻,本文有一定刪減,
作者:胡濤(Daniel),馬上消費金融高級云平臺研發工程師,
本次分享主要分為四個部分:
- 什么是 AI 中臺
- 為何需要 KubeSphere
- KubeSphere 的引入
- 二次開發和參與社區
什么是 AI 中臺
首先簡單介紹一下背景,關于我們是誰?
馬上消費金融股份有限公司(簡稱“馬上消費”)是一家經中國銀保監會批準,持有消費金融牌照的科技驅動型金融機構,截止 2020 年底,注冊資本金達 40 億元,注冊用戶已突破 1.2 億,累計發放貸款超過 5400 億元,累計納稅近 33 億元,公司技術團隊人數超過 1000 人,
我們的技術類部門架構大致如下:
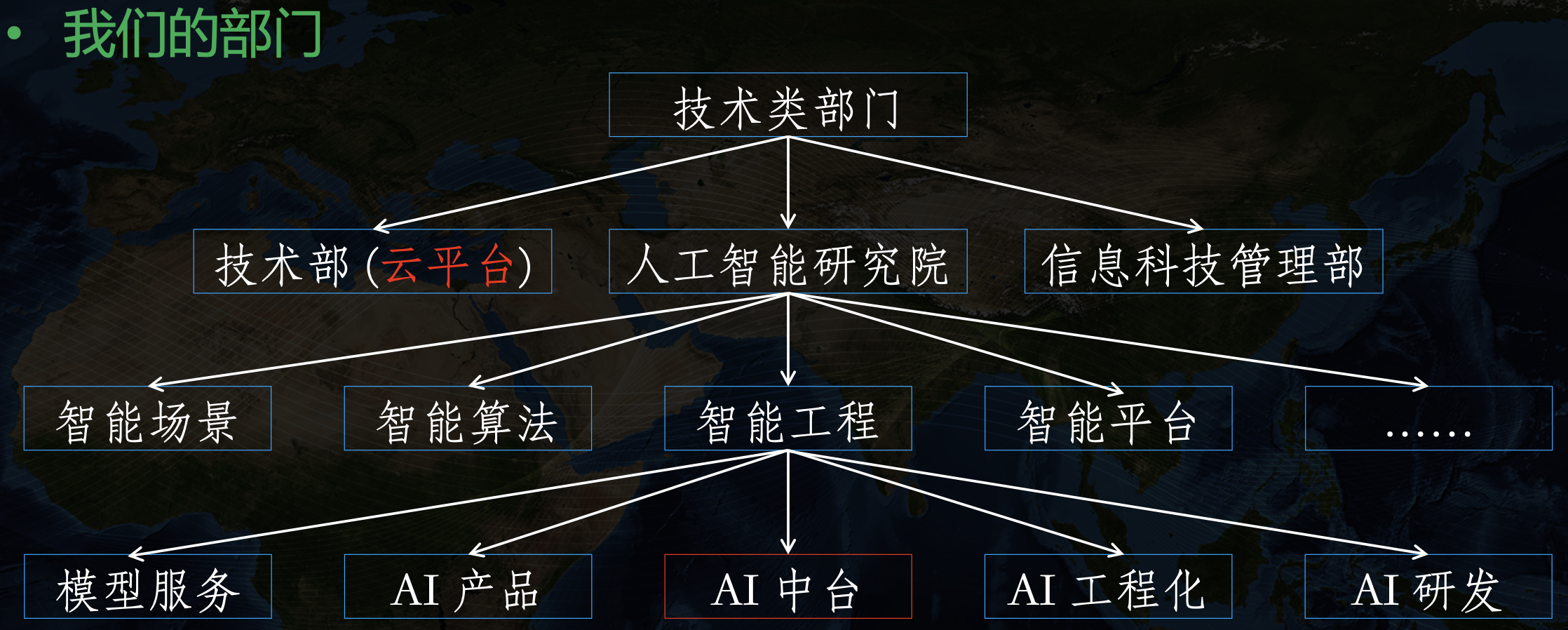
可以看到 AI 中臺團隊隸屬于“人工智能研究院”大部門下,與負責“云平臺”的技術部中間有一個很高的部門墻,也因此,AI 中臺所需要的底層云計算相關技術并不能很好的依賴于技術部,兩邊有不同的考核機制、目標、痛點,所以 AI 中臺團隊需要自己搭建底層云平臺,這也是我們引入 KubeSphere 的一個重要原因,
我們這邊主要開發的產品如下,AI 中臺是作為三大中臺之一,在公司內部運行在金融云之上,但是由于 AI 中臺需要考慮對外輸出,而金融云暫時沒有這個規劃,所以 AI 中臺也需要獨立的云方面的解決方案,換言之 AI 中臺本身必須是一個完整的容器云 + AI 架構,

目前產品主頁大致長這樣:
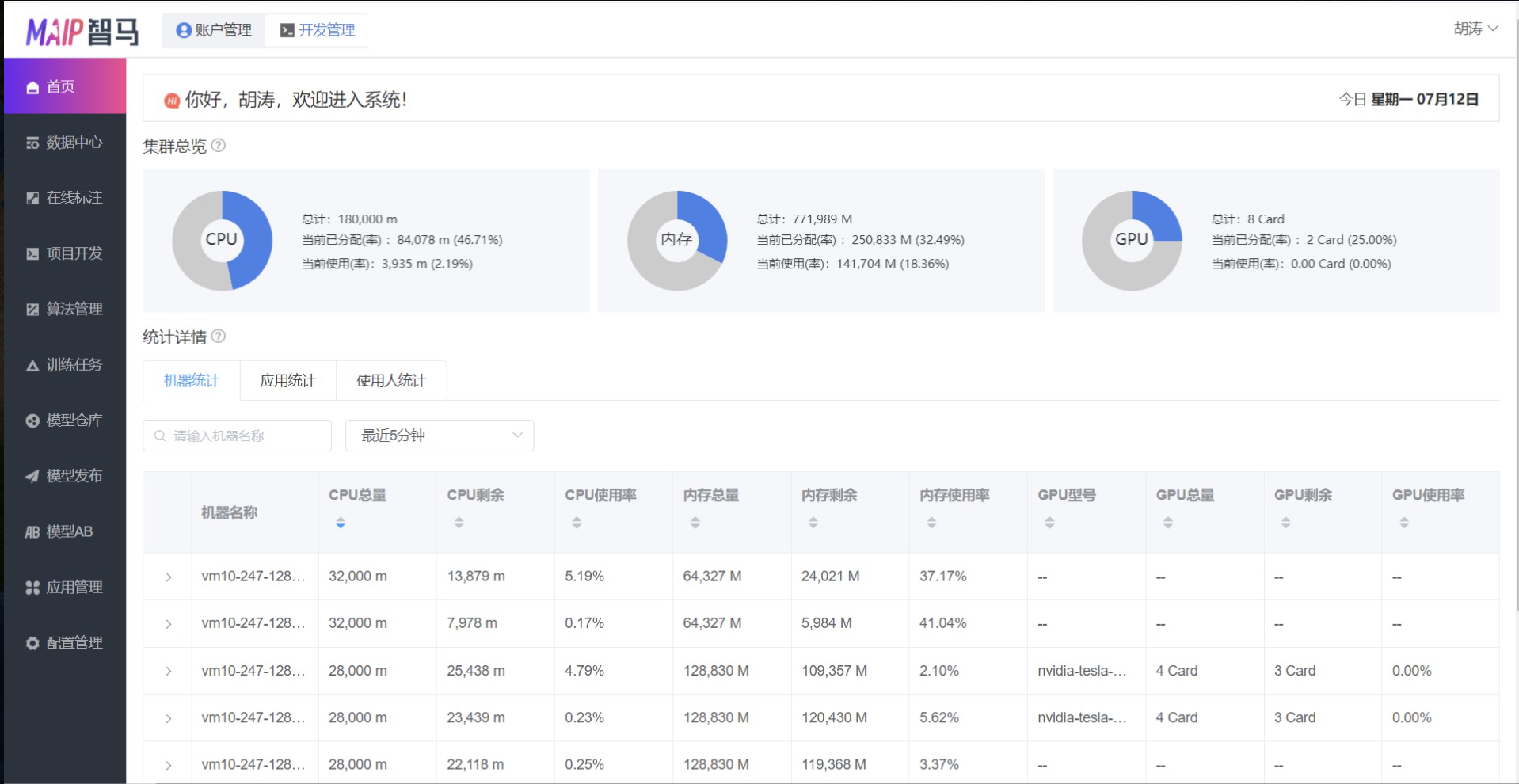
首頁主要展示的是監控相關資訊,這些都來自 Promethues,另外從左邊可以看到我們的九大功能模塊:資料中心、在線標注、專案開發、演算法管理、訓練任務、模型發布、模型 AB、應用管理等,監控資訊相對來說還是比較粗糙,上面三個圈部分是集群緯度的整體資訊,包括 CPU、記憶體、GPU 整體資訊,下面是機器緯度、應用緯度、使用人緯度分別的匯總資訊,另外我們也保留了原生的監控頁面:
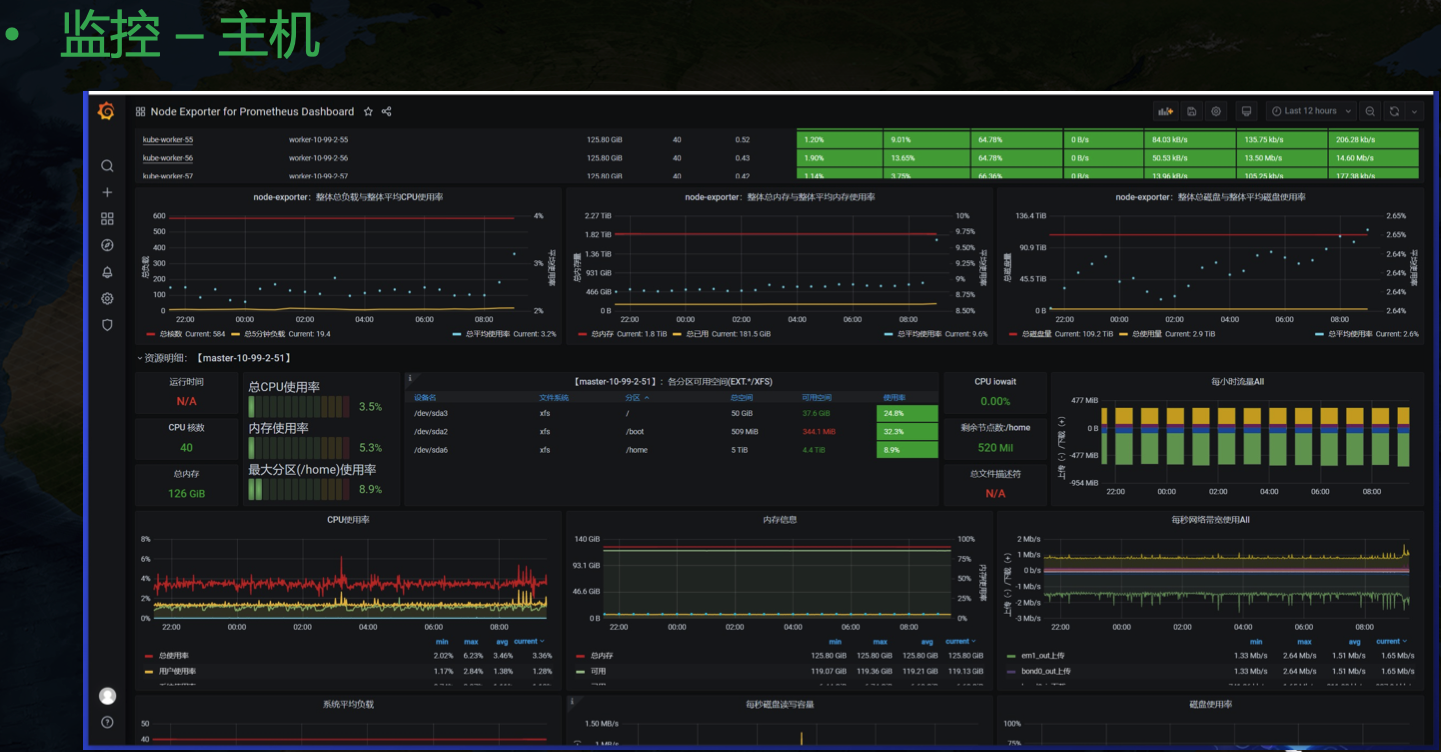
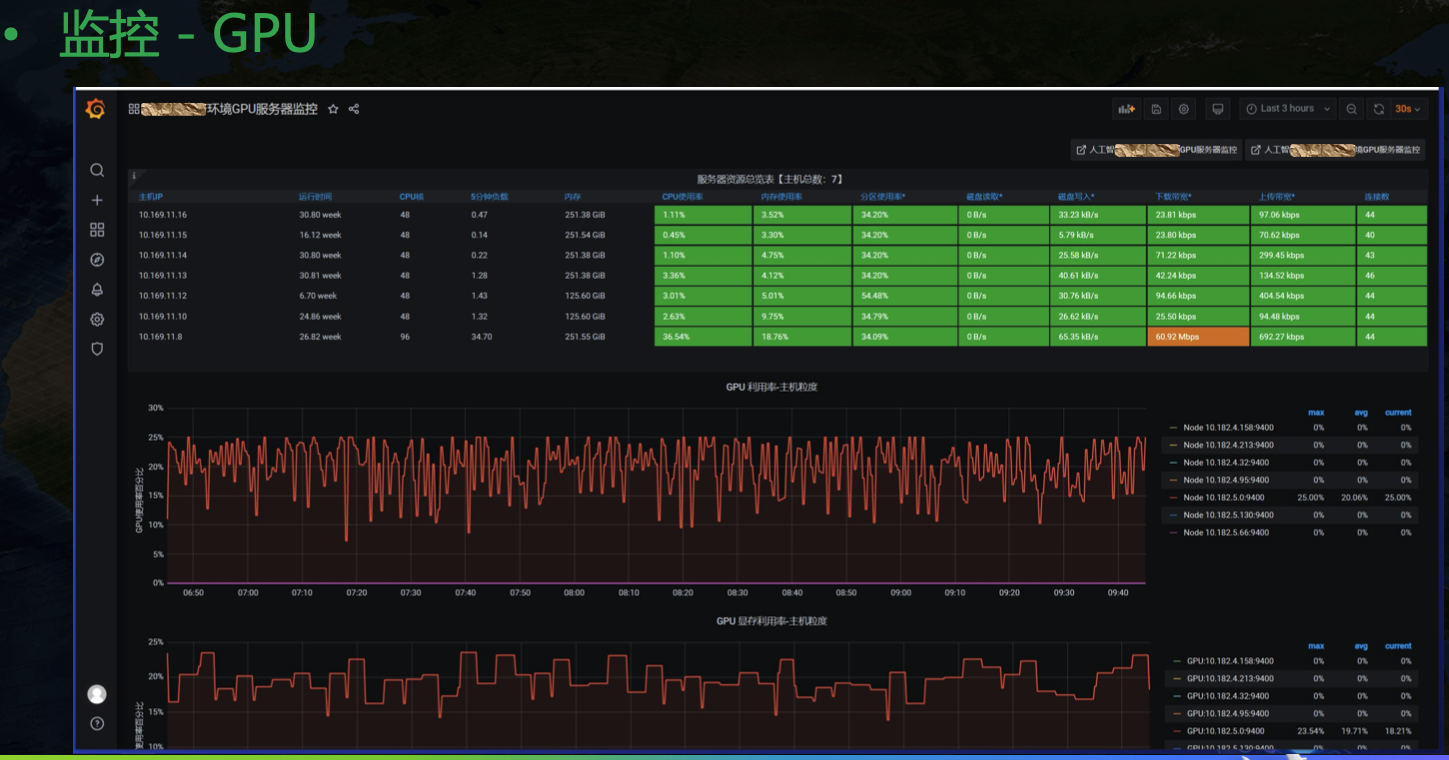
目前 grafana 社區并沒有一個合適的 GPU 緯度展示模板,NVIDIA 也只給了一個主機緯度的相對粗糙的 Dashboard,目前我們用的 GPU Dashboard 是自己開發的,還有一個呼叫鏈緯度的監控:
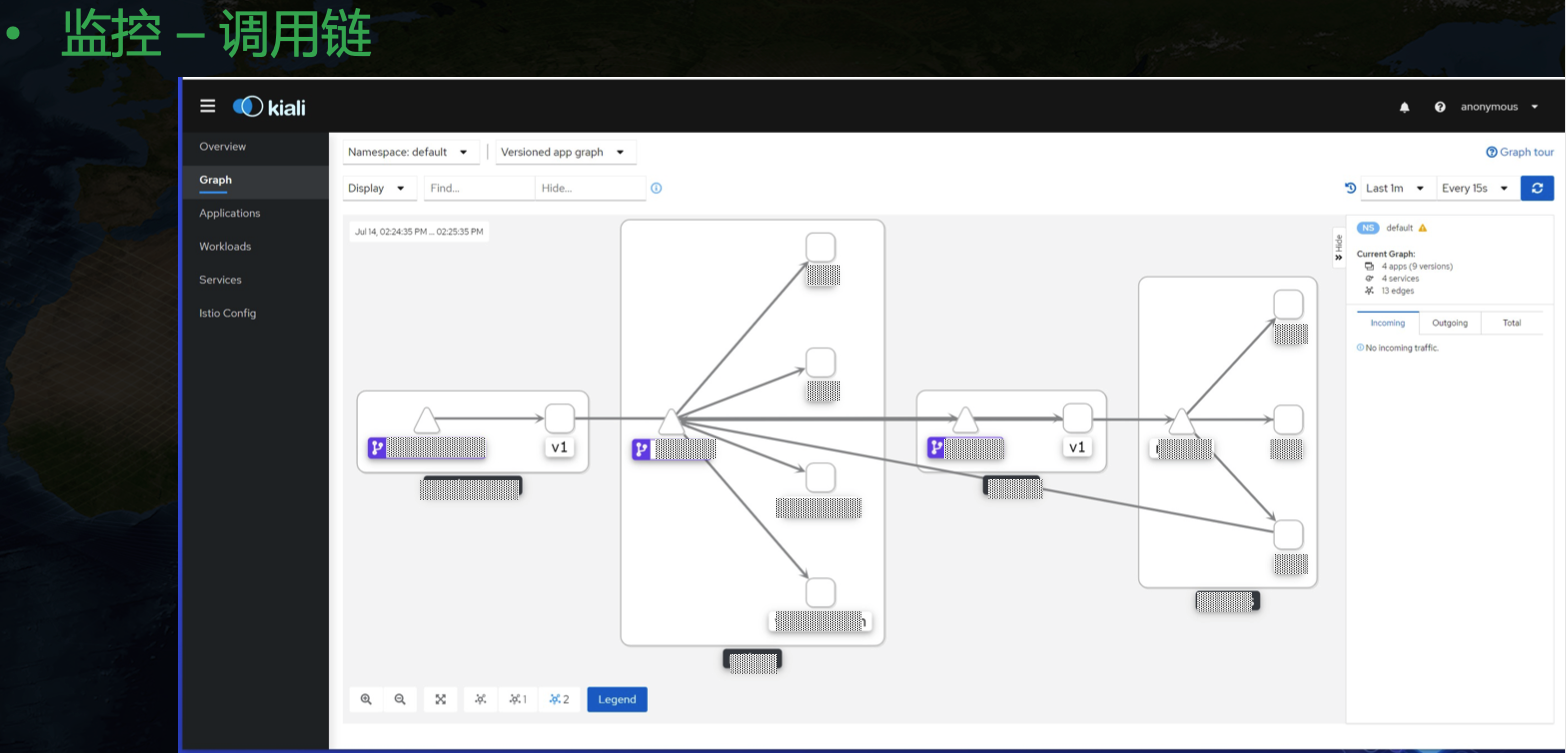
另外日志我們也是用的原生 kibana 來展示,對應的工具鏈是 Fluent Bit + Elasticsearch + Kibana,
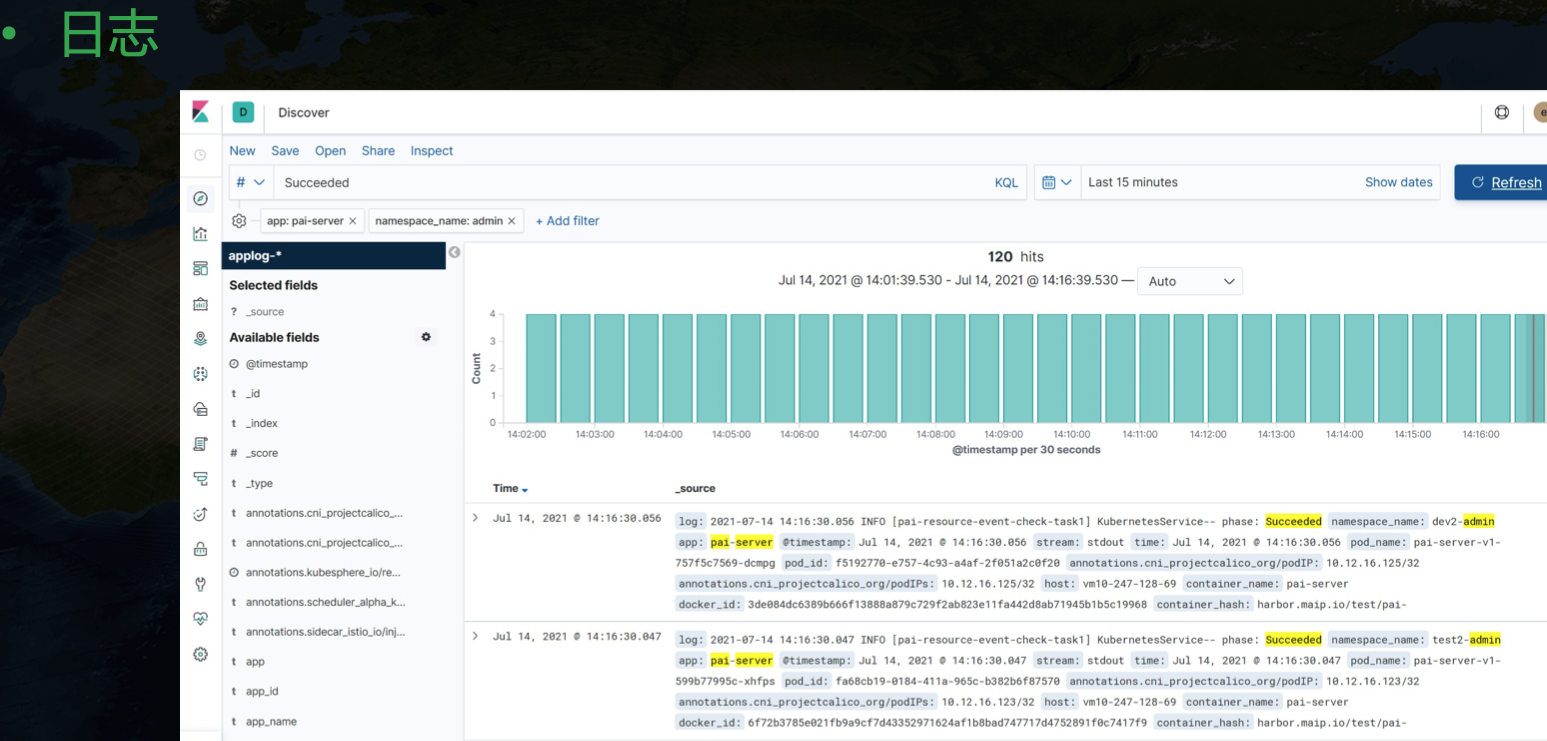
日志這里可以看到一個額外的資訊,我們可以根據 app 緯度來聚合,也就是一個應用下的不同 Pod 產生的日志可以匯總展示,這里其實是簡單地根據 pod 的 label 來實作的,將每個 Pod 打上應用相關的 label 資訊,然后采集日志時將這個屬性暴露出來,就能在展示時針對性匯總,在中臺發布的應用有一個日志跳轉按鈕,轉到 kibana 頁面后會帶上相關引數,實作該應用下全部日志聚合展示的功能,
到這里可以看到整個中臺雖然看起來功能還算齊全,但是面板很多,日志監控和主頁分別有各自的入口,雖然可以在主頁跳轉到日志和監控頁面,但是這里的鑒權問題、風格統一問題等已經很不和諧,但是我們團隊主打的是 AI 能力,人手也有限,沒有太多的精力投入到統一 Dashboard 開發上,日志監控等雖然必不可少,但也不是核心能力,這也是引入 KubeSphere 的一個重要原因,后面還會詳細談到為什么引入 KubeSphere,
再介紹下整個中臺的底層架構:
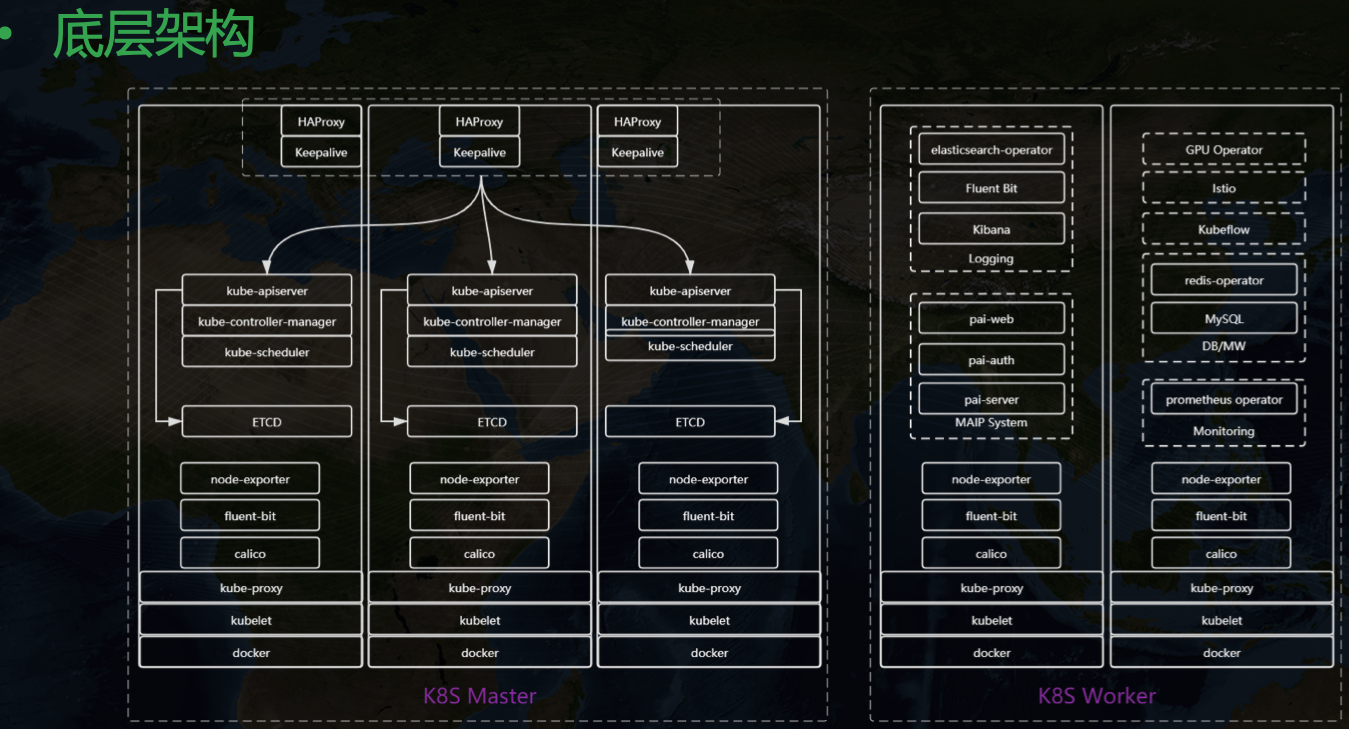
整個中臺構建在 Kubernetes 之上,在引入 KubeSphere 之前大致長這樣,三主多從,
另外在網路上我們做了三網隔離支持,也就是業務、管理、存盤可以分別使用不同的網卡,假如用戶現場有多張網卡,
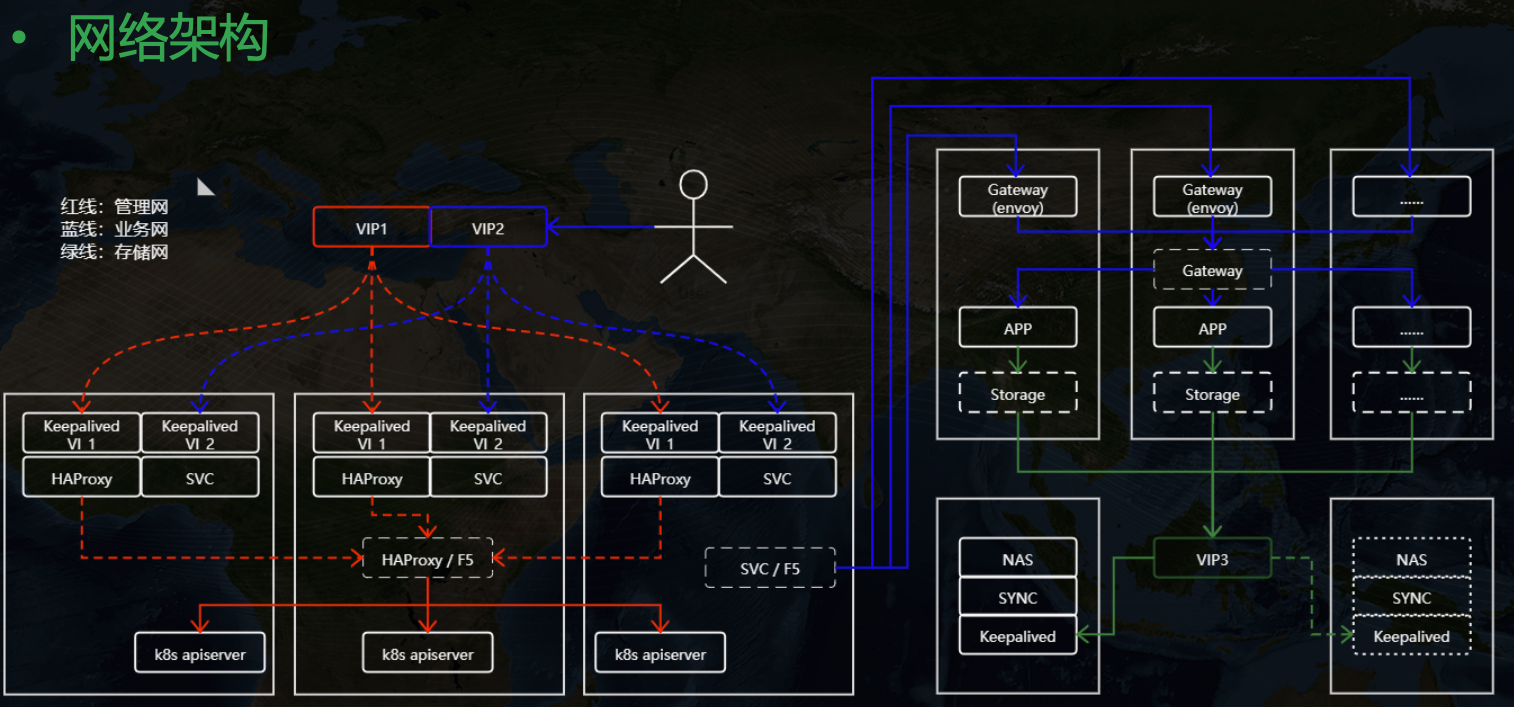
關于三網隔離這里不贅述,后面我會專門寫一篇博文來介紹這里的實作細節,
為什么需要 KubeSphere
接下來聊一下為什么需要 KubeSphere,
我們使用 Kubernetes 會面臨諸多問題與挑戰,比如:
- 學習成本高:Kubernetes 引入了諸多新概念,要掌握 Kubernetes 達到生產落地的能力需要不少的學習時間,這里還會涉及到網路、存盤、系統等方方面面知識,不是隨便一個初級開發人員花時間就能掌握的,
- 安裝部署復雜:目前雖然已經有了 kubeadm 等一系列半自動化工具,可以接近一鍵部署環境,但是要搭建高可用生產集群,還是需要花不少精力深入掌握工具的各種配置細節,才能很好落地應用,
- 功能組件選型復雜:要落地一套容器云并不是部署 Kubernetes 就夠了,這里還有日志、監控、服務網格、存盤等一系列相關組件需要落地實施,每一個方向都是涉及一系列可選方案,需要專門投入人力去學習、選型,
- 隱形成本高:就算部署了 Kubernetes,后期的日常運維也需要專業的團隊,對于一般中小公司來說一個 Kubernetes 運維團隊的人力成本也是不小的開支,很多時候花錢還招不到合適的人,往往會陷入部署了 Kubernetes,但是出問題無人能解決的尷尬境地,通過重裝來恢復環境,
- 多租戶模式實作復雜,安全性低:在 Kubernetes 里只有簡單的 Namespace 隔離,配合 Quota 等一定程度上實作資源隔離,但是要 to C 應用還遠遠不夠,很多時候我們需要開發一套權限管理系統來適配企業內專有的賬號權限管理系統來對接,成本很高,
- 缺少本土化支持:Kubernetes 一定程度上可以稱為云作業系統,類比于 Linux,其實 Kubernets 更像是 kernel,我們要完整使用容器云能力,要在 Kubernets 之上附加很多的開源組件,就像 kernel 上要加很多的開源軟體才能用起來 Linux 一樣,很多企業,尤其是國企,會選擇購買 Redhat 等來享受企業級支持,專注于系統提供的能力本身,而不想投入太多的人力去掌握和運維系統本身,Kubernetes 本身也有這樣的問題,很多企業并不希望額外投入太大的成本去使用這套解決方案,而是希望有一個類似 Redhat 系統的 Kubernetes 版本來簡單化落地,而且希望免費,
而我們 AI 中臺所面臨的技術與挑戰如下:

我們涉及的技術堆疊很廣,AI 方向的,云計算方向的,還有工程開發的,也就是 Java + 前端等,但是我們的人力很稀缺,在云方向只有 2 個人,除了我之外另外一個同事擅長 IaaS 方向,在網路、存盤等領域可以很好 cover 住,所以剩下的容器方向、監控日志等方向,在大公司可能每個方向一個團隊,加一起大幾十號人做的事情,這邊只有我一個人了,所以我再有想法,有限的時間內也做不完一個平臺,所以我也在尋找一個現成的解決方案,可以把自己解放出來,能夠把精力投入到 AI 相關能力的建設上,比如模型訓練等的 Operator 開發上,而不是整體研究日志監控組件和 Kubernetes 最佳部署實踐等,
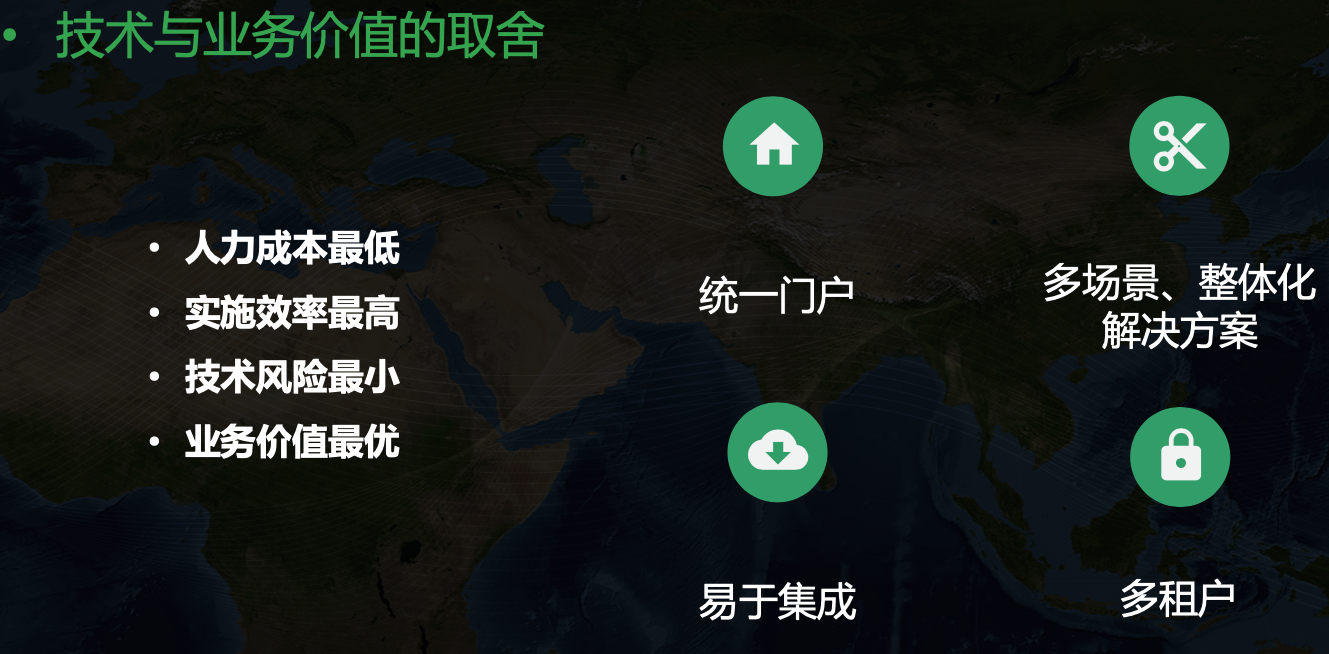
KubeSphere 提供的統一門戶、多租戶、多場景整體化解決方案正好能解決我的很多痛點,KubeSphere 的架構大致如下

不同于 OpenShift 的解決方案,KubeSphere 對 Kubernetes 沒有侵入,而是基于 Operator 模式來拓展,這種方式也是我個人比較推崇的,
KubeSphere 的引入
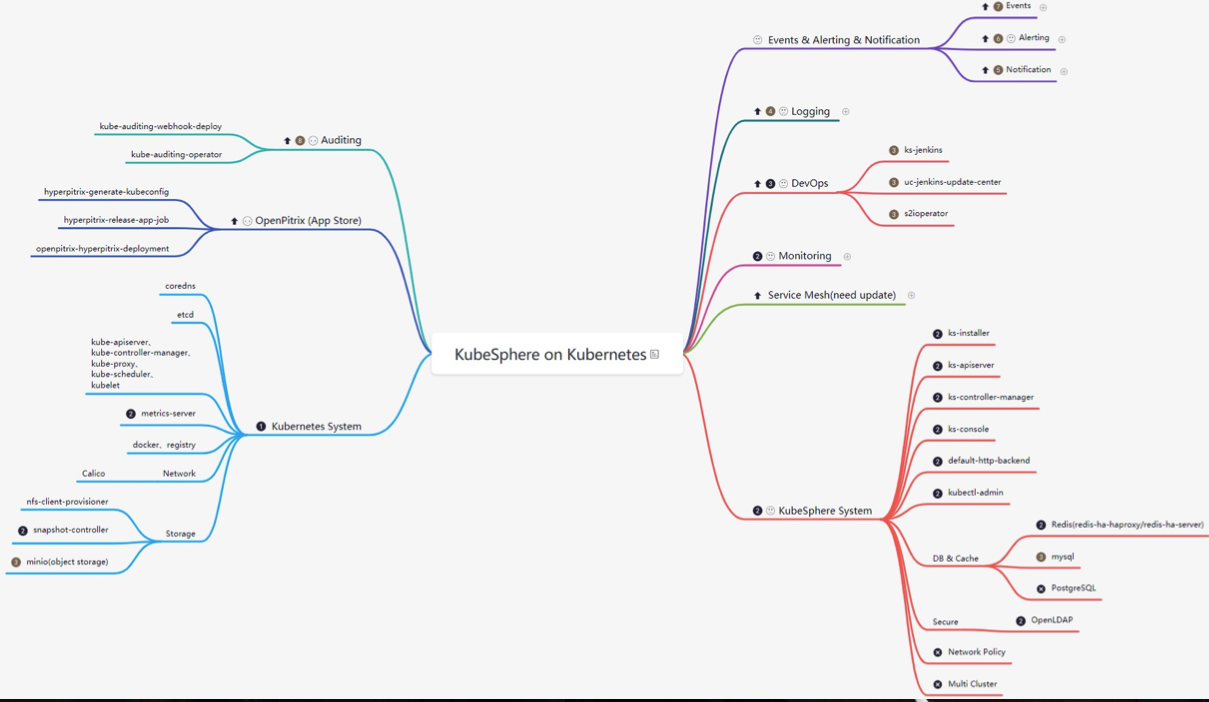
KubeSphere 里組件不少,面對這樣一個復雜軟體,我的方式是通過思維導圖來梳理里面的所有組件,然后最小化部署,看下集群里有些啥,然后可插拔組件一個個開啟,看下多了哪些組件,這樣一個個模塊去梳理,最終實作對整個平臺架構整體掌握的目的:
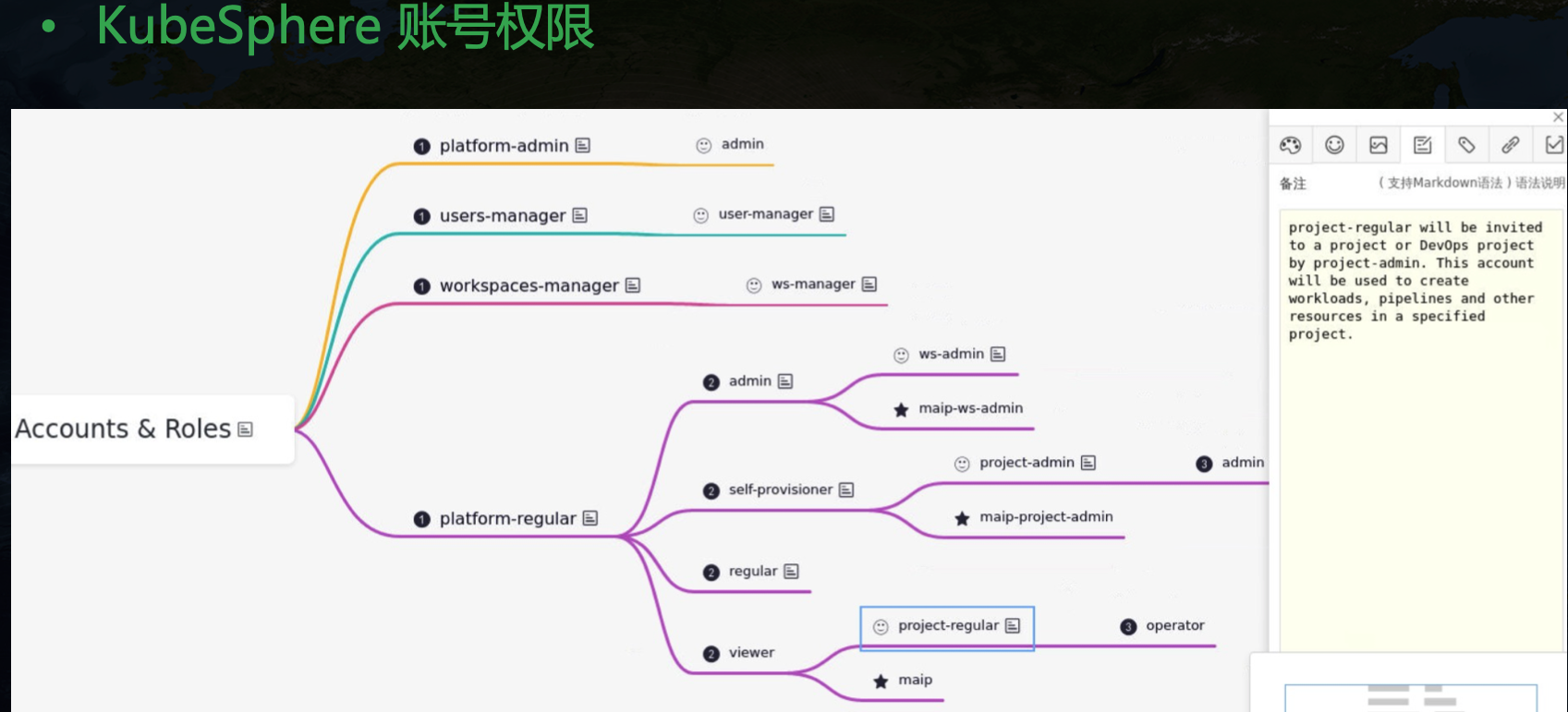
KubeSphere 頁面如下:
后面介紹下 KubeSphere 的部署架構:
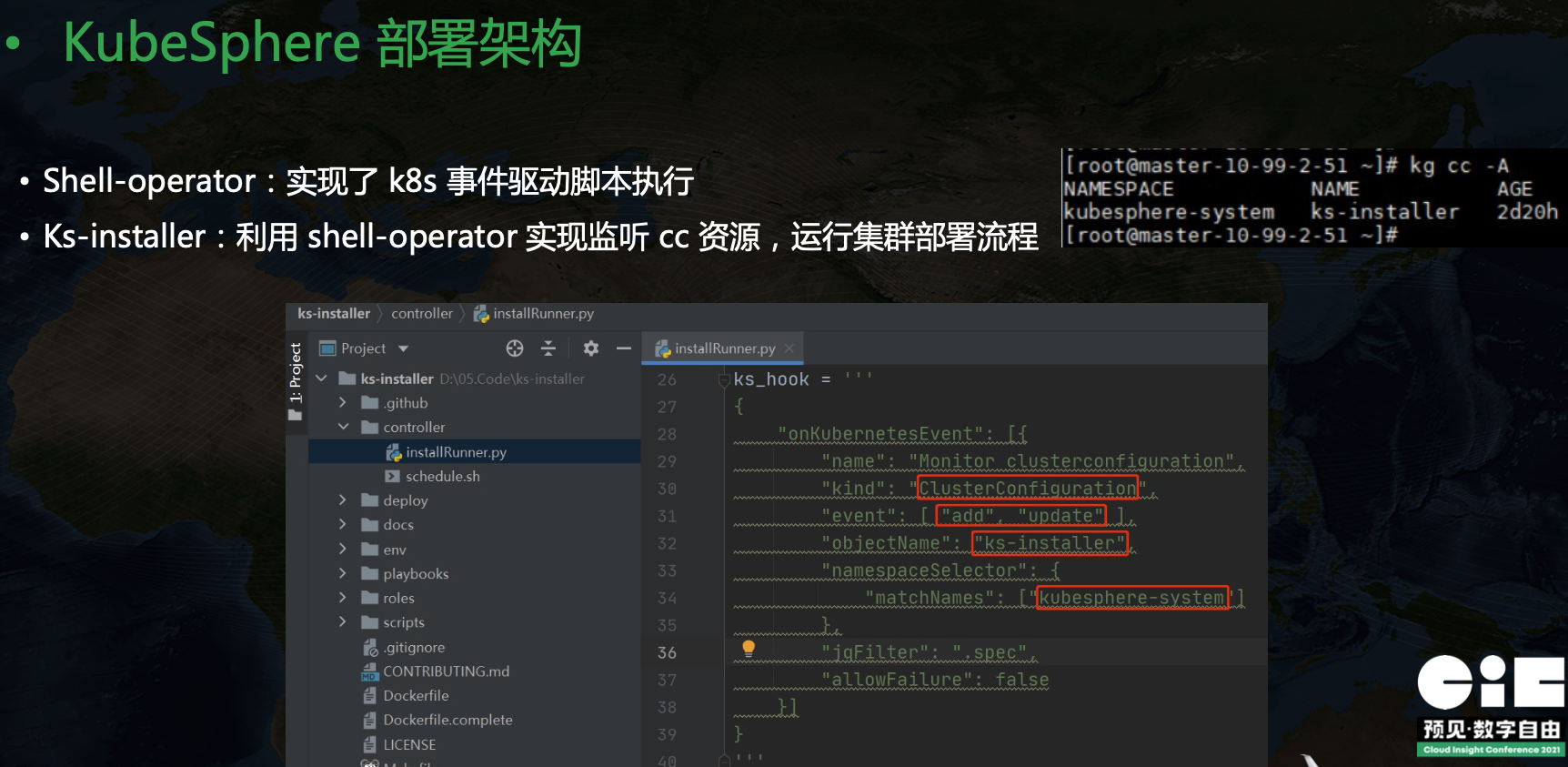
在 KubeSphere 里可以看到一個叫做 kubesphere-system/ks-installer 的資源,簡寫 cc,全稱是 ClusterConfiguration,里面維護了集群的配置資訊,我們在 ks-installer 里可以看到一個 ks-hook 配置,里面定義了 kind ClusterConfiguration,event add update,objectName ks-install,namespace kubesphere-system 等資訊,這里也就是告訴 shell-operator 當 cc 發生變更的時候要觸發相關代碼執行,ks-installer 的核心原理是利用 shell-operator 來監聽 cc 資源的變更,然后運行集群部署流程,
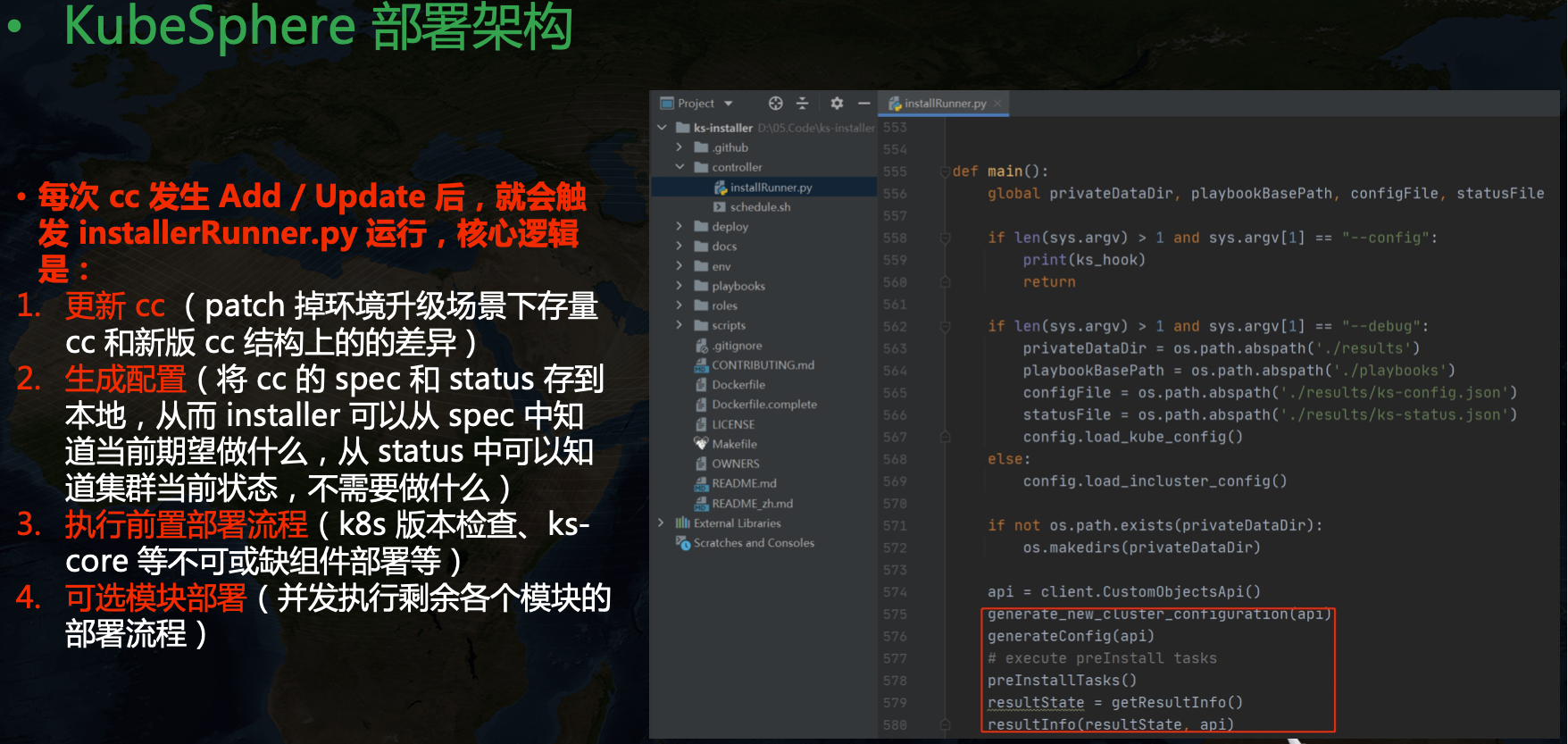
每次 cc 發生 Add / Update 后,就會觸發 installerRunner.py 運行,核心邏輯是:
- 更新 cc (patch 掉環境升級場景下存量 cc 和新版 cc 結構上的差異)
- 生成配置(將 cc 的 spec 和 status 存到本地,從而 installer 可以從 spec 中知道當前期望做什么,從 status 中可以知道集群當前狀態,不需要做什么)
- 執行前置部署流程(K8s 版本檢查、ks-core 等不可或缺組件部署等)
- 可選模塊部署(并發執行剩余各個模塊的部署流程)
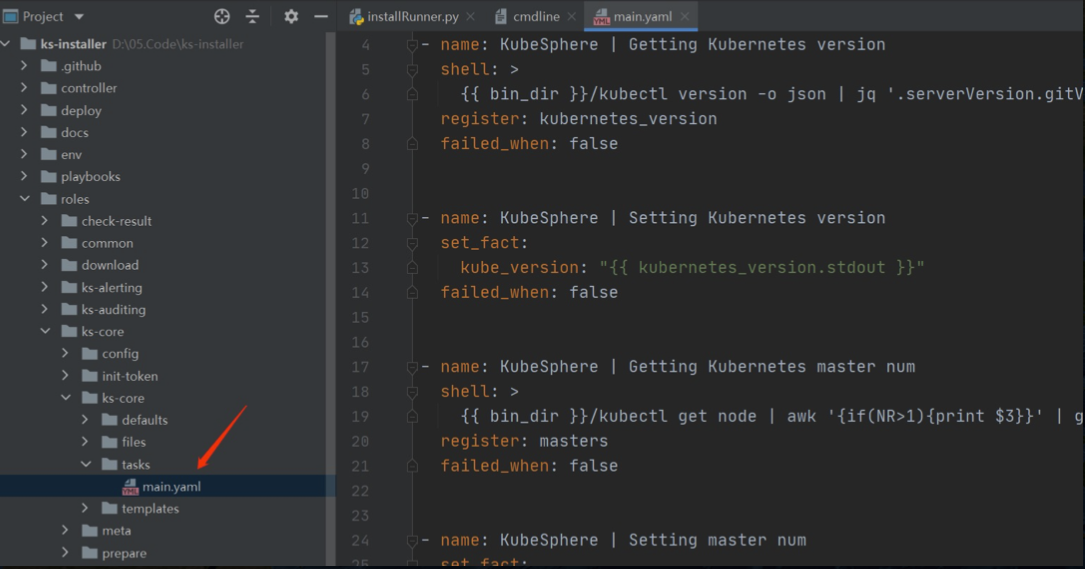
然后再看下為什么配置里的變數可以被 ansible 識別,如下所示,在 env 里指定里 ks-config.json 和 ks-status.json 兩個檔案,ks-installer 運行的時候會將 cc 的 spec 和 status 分別存到這兩個檔案里,這樣 ansible 執行的時候就可以獲取到集群的期望狀態和實際狀態了,
每個 playbook 的入口邏輯都在 main.yaml 里,所以接著大家可以在每個模塊里通過 main.yaml 來具體研究每個模塊的部署流程,串在一起也就知道了整個 KubeSphere 是怎么部署起來的了,
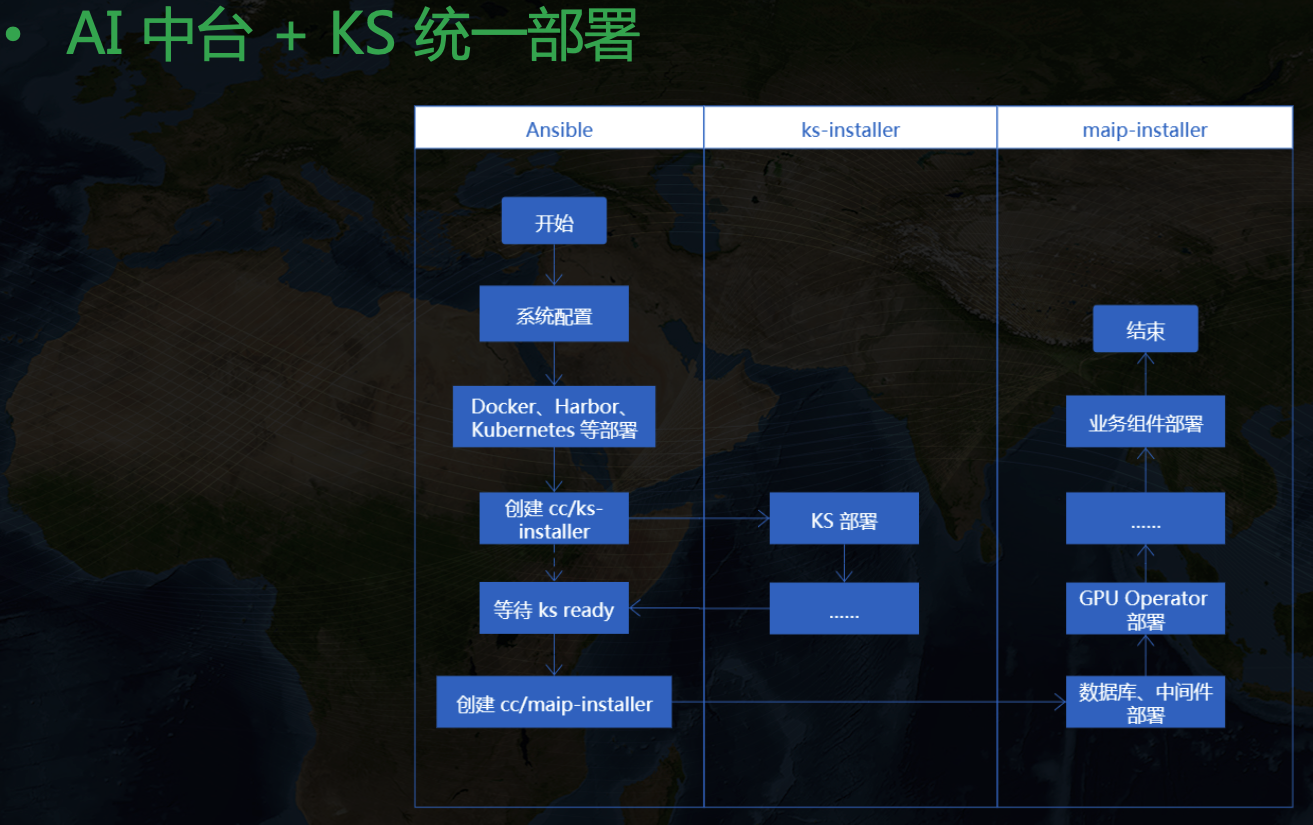
然后 KubeSphere 和中臺本身的一堆組件怎么一起部署呢?
我們也參考 KubeSphere 的部署模式,加了一個 mail-installer 的 cc,然后按照下面流程來完成整個中臺的部署:
二次開發與參與社區
接著聊下參與社區的問題,

對于新手推薦看下下面兩個資料,里面有一些很好的前人總結,可以避免一些不必要的坑,
很多人在玩社區的程序中可能會有如下一些問題:
- 不擅長英語描述問題怎么辦?
- 提了 Issue 沒人理怎么辦?
- Pr 沒有人給 Review 怎么辦?
- 與 Reviews 意見分歧怎么辦?
最后針對這些問題聊下我的一些思考,
- 不擅長英語描述問題怎么辦?
其實很多開源社區別看上面都是英文,背后有相當比例的中國人飆“中式英語”,你勇敢去說,各種語法錯誤其實一點關系也沒有,互相能理解意思,交流的目的也就達到了,另外借助谷歌翻譯等平臺,其實有個一兩千詞匯量就完全夠用了,在開源社區沒有必要追求完美英語,
- 提了 Issue 沒人理怎么辦? Pr 沒有人給 Review 怎么辦?
社區是一個異步協作等程序,和在公司里團隊開發不一樣,互相喊一聲就能彼此聽見,及時反饋,參與社區的人都是手上有自己的本職作業,很多時候兩三天上 Github 看一下也無可厚非,如果你不是很著急,還是可以耐心多等幾天,如果確實有需要,也可以給相關人員發個郵件,或者在微信群等及時通訊途徑去艾特對應人員,不過不是很推薦,
- 與 Reviews 意見分歧怎么辦?
有時候玩開源就是這樣,大家有自己不同的想法,誰也說服不了誰,一般大家產生分歧的是兩個都能滿足需求的實作方式哪個更優,其實滿足需求的方案都是可接受的方案,如果你能說服 reviewer,這也是一種能力,如果不能,就接受另外一種方式,比較也是實作需求了,能用就行,不要因為這種“爭辯”而對開源活動失去信心,協作開發本身就充滿了“爭論”與“妥協”,不會一切完全按照某個人的意愿走下去,
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/323000.html
標籤:其他
上一篇:模板大全