這篇文章帶大家來做一個簡單的聊天機器人,碰巧遇到微軟Azure招募開發者,可以免費試用人工智能服務,果斷申請,
先決條件:
- 熟悉 Azure 服務和 Azure 門戶(也可以用其它的AI開放平臺)
- 擁有 Python 編程經驗
- 熟悉API呼叫
序言
首先需要了解一下做對話機器人需要涉及到的技術,可以看一下這個流程圖,
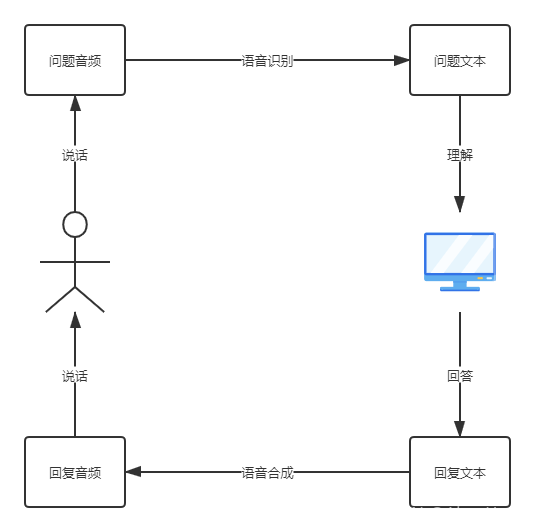
理清思路之后,我們發現涉及到的技術有三種:語音識別、對話式問答、語音合成,
簡單解釋一下這三個技術:
- 語音識別:準確地將口述語音聽錄為文本,功能演示
- 對話式問答:提取文本資訊,并將其轉化為一目了然的對話式答案
- 語音合成:將文本轉換為逼真的語音,功能演示
目前來說最流行的語音演算法主要是依賴于深度學習的神經網路演算法,深度學習的應用真正讓語音識別/合成達到了商用級別,
不過如果要自己做一個語音識別系統,從零開始訓練語言模型勢必會非常耗時,雖然有很多預訓練的模型,但是對于沒有深度學習基礎的同學來說還是比較困難,所以我們借助Azure的認知服務開源的語音服務API來是想這些功能,
首先需要使用你的 Microsoft 帳戶登錄到 Azure 門戶,
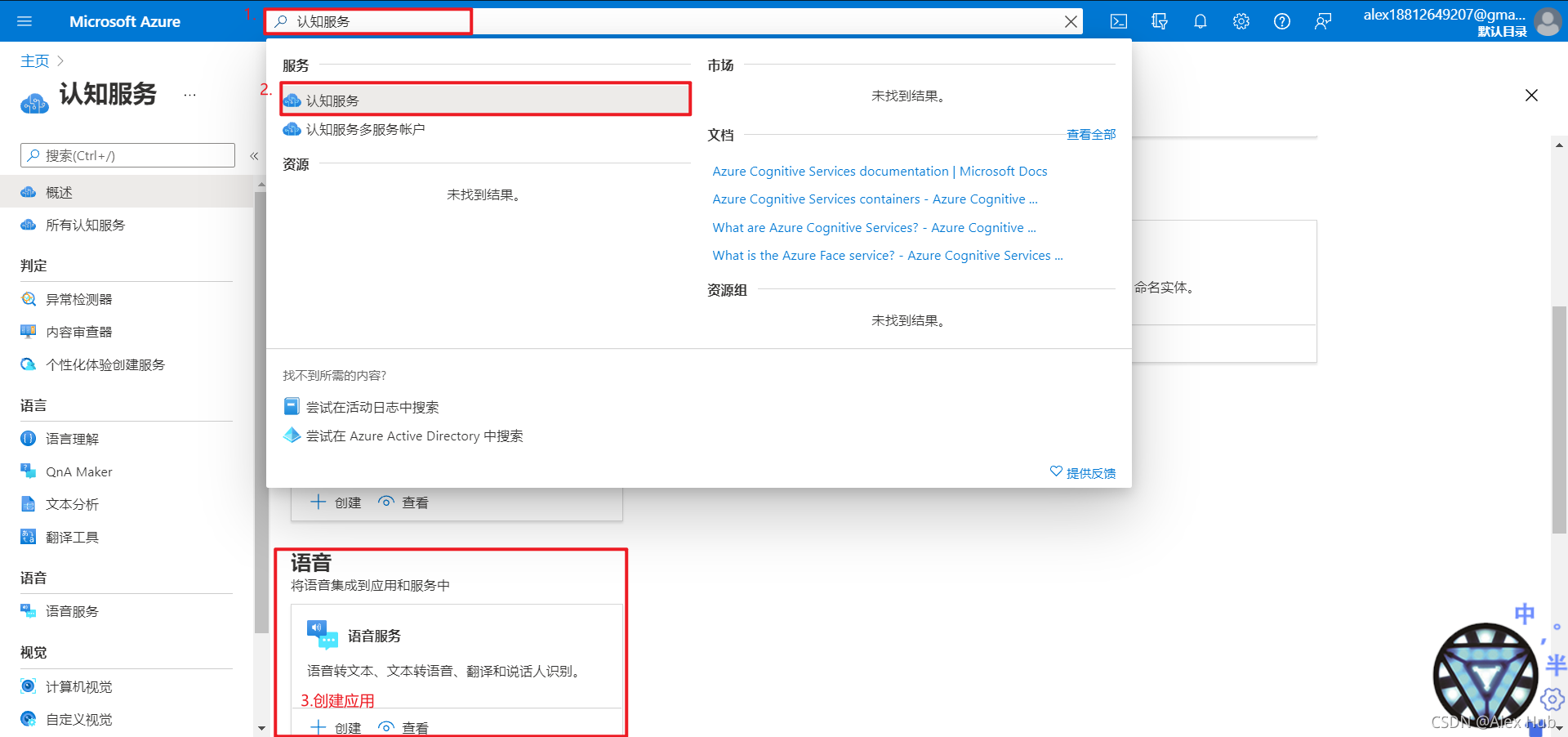
然后創建一個認知服務資源,
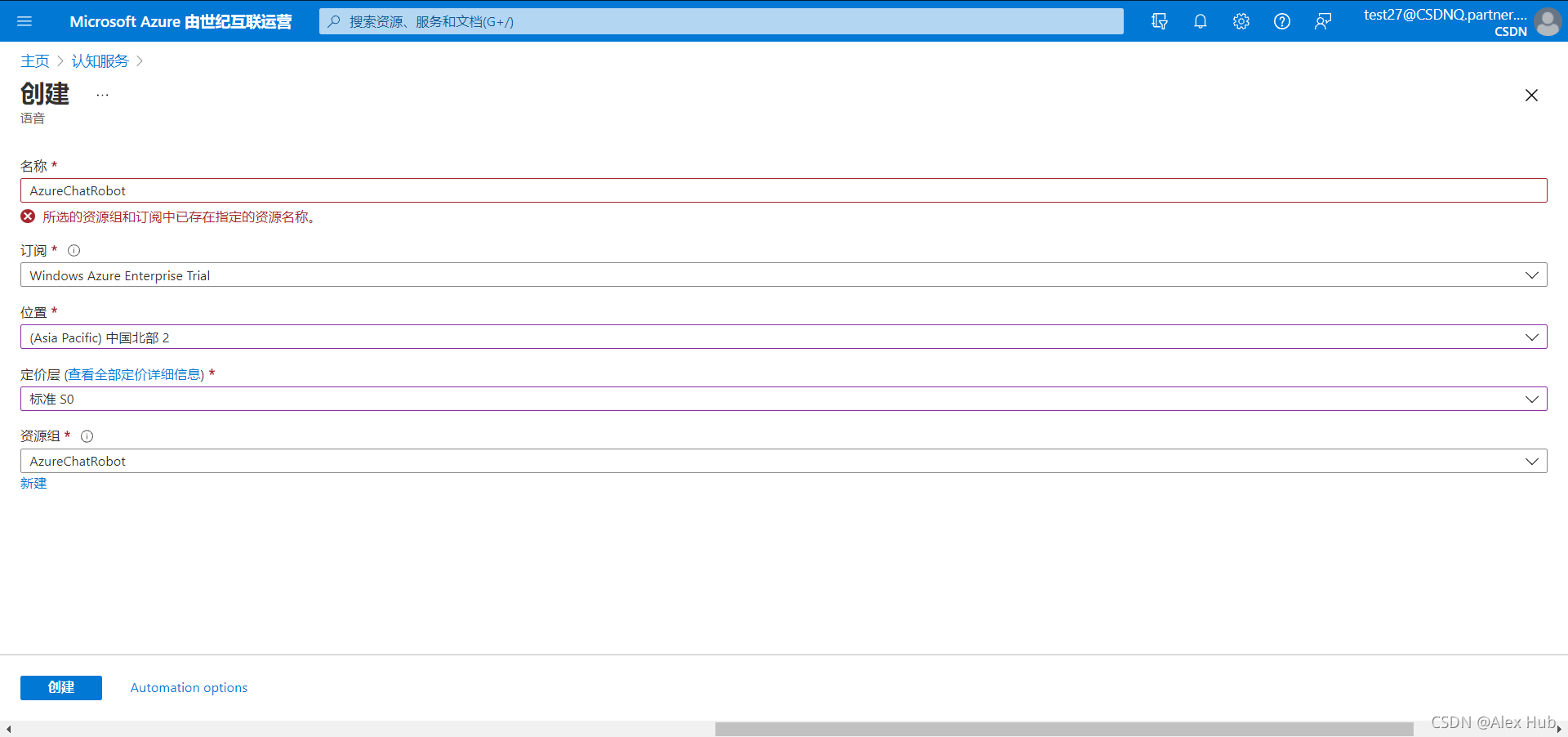
創建并且等待部署完成后,在左側窗格中的“資源管理”下,選擇“密鑰和終結點” ,
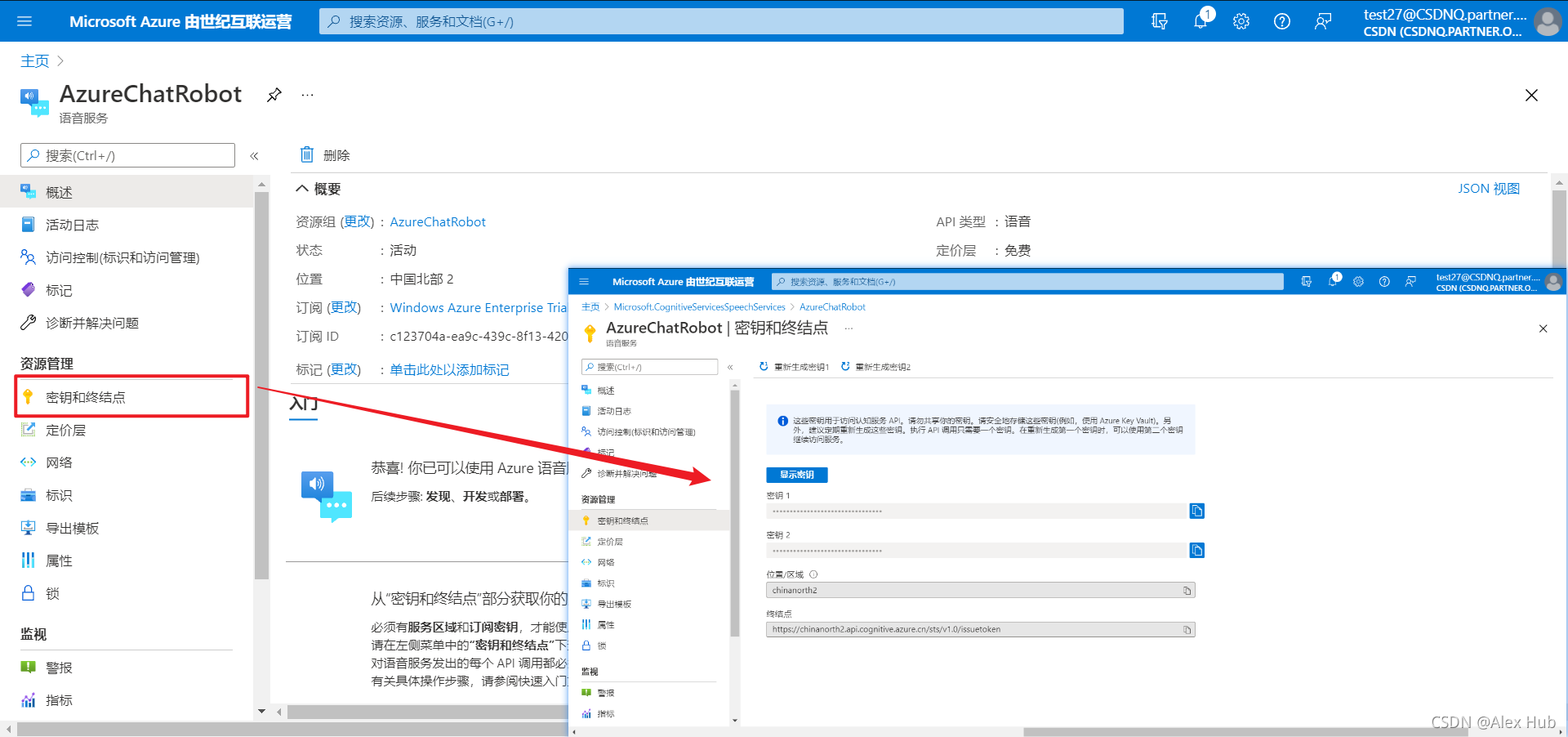
每個訂閱有兩個密鑰;可在應用程式中使用任意一個密鑰,
語音識別+語音合成
安裝和匯入語音 SDK
需要先安裝語音 SDK,然后才能執行任何操作,
pip install azure-cognitiveservices-speech
安裝語音 SDK 后,將其匯入到 Python 專案中,
import azure.cognitiveservices.speech as speechsdk
創建語音識別配置
若要使用語音 SDK 呼叫語音服務,需要創建 SpeechConfig, 此類包含有關訂閱的資訊,例如密鑰和關聯的位置/區域、終結點、主機或授權令牌,
import azure.cognitiveservices.speech as speechsdk
# 需要填入自己的密鑰和位置
speech_key, service_region = "YourSubscriptionKey", "YourServiceRegion"
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region,
speech_recognition_language="zh-cn")
# Creates a recognizer with the given settings
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
從麥克風識別
若要使用設備麥克風識別語音,只需創建 SpeechRecognizer(無需傳遞 AudioConfig),并傳遞 speech_config,
import azure.cognitiveservices.speech as speechsdk
def from_mic():
speech_config = speechsdk.SpeechConfig(subscription="<paste-your-speech-key-here>", region="<paste-your-speech-location/region-here>")
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
print("Speak into your microphone.")
result = speech_recognizer.recognize_once_async().get()
print(result.text)
from_mic()
錯誤處理
前面的示例只從 result.text 獲取已識別的文本,但要處理錯誤和其他回應,需要撰寫一些代碼來處理結果, 以下代碼評估 result.reason 屬性并:
- 輸出識別結果:speechsdk.ResultReason.RecognizedSpeech
- 如果沒有識別匹配項,通知用戶:speechsdk.ResultReason.NoMatch
- 如果遇到錯誤,則輸出錯誤訊息:speechsdk.ResultReason.Canceled
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(result.text))
elif result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(result.no_match_details))
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("Speech Recognition canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(cancellation_details.error_details))
語音合成
同樣,我們可以搭建一個語音合成的功能,
def speak(text_words):
speech_config.speech_synthesis_language = "zh-cn"
audio_config = AudioOutputConfig(use_default_speaker=True)
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
result = speech_synthesizer.speak_text_async(text_words).get()
# Checks result.
if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
print("Speech synthesized to speaker for text [{}]".format(text_words))
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("Speech synthesis canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
if cancellation_details.error_details:
print("Error details: {}".format(cancellation_details.error_details))
print("Did you update the subscription info?")
圖靈機器人服務構建聊天功能
對話式機器人現在已經成為相對成熟的AI解決方案,機器人以聊天的方式與用戶互動,比如edge自帶的小冰虛擬女友:
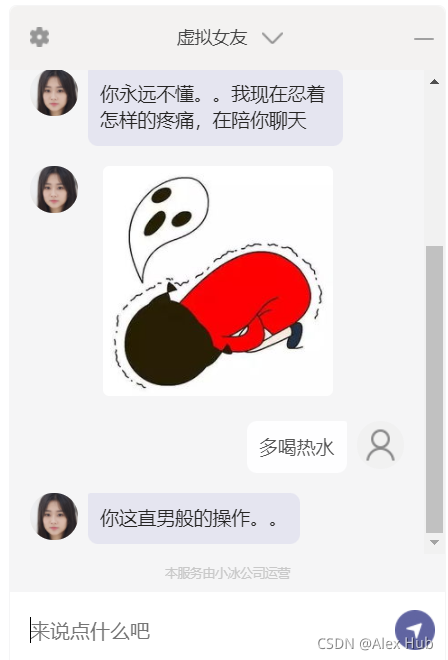
為了實作這種對話式的聊天功能,我們需要借助圖靈機器人開放平臺,通過圖靈機器人開放平臺,軟硬體產品開發者可快速為自己的產品接入一款具備個性化身份屬性特征、滿足不同場景多輪對話及背景關系對話的人工智能機器人,實作產品的對話式互動,
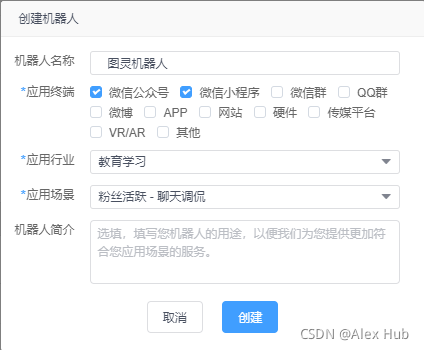
創建機器人
進入圖靈機器人管理控制臺后,點擊“創建機器人”,按要求填寫機器人名稱及應用資訊,即可完成創建,當前每個賬號只能創建5個機器人,
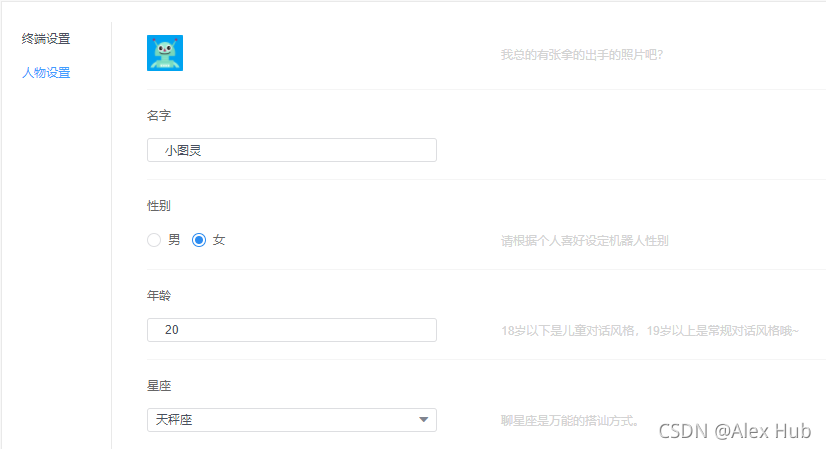
然后在機器人設定中可以定義機器人的一些屬性,
API接入
目前圖靈機器人API介面可呼叫聊天對話、語料庫、技能三大模塊的語料:
- 聊天對話是指平臺免費提供的近10億條公有對話語料,滿足用戶對話娛樂需求;
- 語料庫是指用戶在平臺上傳的私有語料,僅供個人查看使用,幫助用戶最便捷的搭建專業領域次的語料,
- 技能服務是指平臺打包的26種實用服務技能,涵蓋生活、出行、購物等多個領域,一站式滿足用戶需求,
編碼方式
UTF-8(呼叫圖靈API的各個環節的編碼方式均為UTF-8)
介面地址
http://openapi.turingapi.com/openapi/api/v2
請求方式
HTTP POST
請求引數
請求引數格式為 json
請求示例:
{
"reqType":0,
"perception": {
"inputText": {
"text": "附近的酒店"
},
"inputImage": {
"url": "imageUrl"
},
"selfInfo": {
"location": {
"city": "北京",
"province": "北京",
"street": "資訊路"
}
}
},
"userInfo": {
"apiKey": "",
"userId": ""
}
}
引數說明
| 引數 | 型別 | 是否必須 | 取值范圍 | 說明 |
|---|---|---|---|---|
| reqType | int | N | - | 輸入型別:0-文本(默認)、1-圖片、2-音頻 |
| perception | - | Y | - | 輸入資訊 |
| userInfo | - | Y | - | 用戶引數 |
perception
| 引數 | 型別 | 是否必須 | 取值范圍 | 說明 |
|---|---|---|---|---|
| inputText | - | N | - | 文本資訊 |
| inputImage | - | N | - | 圖片資訊 |
| inputMedia | - | N | - | 音頻資訊 |
| selfInfo | - | N | - | 客戶端屬性 |
注意:輸入引數必須包含inputText或inputImage或inputMedia!
inputText
| 引數 | 型別 | 是否必須 | 取值范圍 | 說明 |
|---|---|---|---|---|
| text | String | Y | 1-128字符 | 直接輸入文本 |
inputImage
| 引數 | 型別 | 是否必須 | 取值范圍 | 說明 |
|---|---|---|---|---|
| url | String | Y | 圖片地址 |
inputMedia
| 引數 | 型別 | 是否必須 | 取值范圍 | 說明 |
|---|---|---|---|---|
| url | String | Y | 音頻地址 |
selfInfo
| 引數 | 型別 | 是否必須 | 取值范圍 | 說明 |
|---|---|---|---|---|
| location | - | N | - | 地理位置資訊 |
location
| 引數 | 型別 | 是否必須 | 取值范圍 | 說明 |
|---|---|---|---|---|
| city | String | Y | - | 所在城市 |
| province | String | N | - | 省份 |
| street | String | N | - | 街道 |
userInfo
| 引數 | 型別 | 是否必須 | 取值范圍 | 說明 |
|---|---|---|---|---|
| apiKey | String | Y | 32位 | 機器人標識 |
| userId | String | Y | 長度小于等于32位 | 用戶唯一標識 |
| groupId | String | N | 長度小于等于64位 | 群聊唯一標識 |
| userIdName | String | N | 長度小于等于64位 | 群內用戶昵稱 |
?
輸出示例:
{
"intent": {
"code": 10005,
"intentName": "",
"actionName": "",
"parameters": {
"nearby_place": "酒店"
}
},
"results": [
{
"groupType": 1,
"resultType": "url",
"values": {
"url": "http://m.elong.com/hotel/0101/nlist/#indate=2016-12-10&outdate=2016-12-11&keywords=%E4%BF%A1%E6%81%AF%E8%B7%AF"
}
},
{
"groupType": 1,
"resultType": "text",
"values": {
"text": "親,已幫你找到相關酒店資訊"
}
}
]
}
引數說明
| 引數 | 型別 | 是否必須 | 取值范圍 | 說明 |
|---|---|---|---|---|
| intent | - | Y | - | 請求意圖 |
| results | - | N | - | 輸出結果集 |
intent
| 引數 | 型別 | 是否包含 | 取值范圍 | 說明 |
|---|---|---|---|---|
| code | int | Y | - | 輸出功能code |
| intentName | String | N | - | 意圖名稱 |
| actionName | String | N | - | 意圖動作名稱 |
| parameters | Map | N | - | 功能相關引數 |
results
| 引數 | 型別 | 是否包含 | 取值范圍 | 說明 |
|---|---|---|---|---|
| resultType | String | Y | 文本(text);連接(url);音頻(voice);視頻(video);圖片(image);圖文(news) | 輸出型別 |
| values | - | Y | - | 輸出值 |
| groupType | int | Y | - | ‘組’編號:0為獨立輸出,大于0時可能包含同組相關內容 (如:音頻與文本為一組時說明內容一致) |
Code
def chat(text_words=""):
api_key = "1dde879fa**********1ee88269f3852"
api_url = "http://openapi.tuling123.com/openapi/api/v2"
headers = {"Content-Type": "application/json;charset=UTF-8"}
req = {
"reqType": 0,
"perception": {
"inputText": {
"text": text_words
},
"selfInfo": {
"location": {
"city": "天津",
"province": "天津",
"street": "天津科技大學"
}
}
},
"userInfo": {
"apiKey": api_key,
"userId": "Alex"
}
}
req["perception"]["inputText"]["text"] = text_words
response = requests.request("post", api_url, json=req, headers=headers)
response_dict = json.loads(response.text)
result = response_dict["results"][0]["values"]["text"]
print("AI Robot said: " + result)
return result
匯總
最后,把語音識別、語音合成的代碼放在一起,再加上一個簡單的流程控制,所有的代碼加起來不超過一百行,一個能跟你聊天的機器人就完成了,
import json
import requests
import azure.cognitiveservices.speech as speechsdk
from azure.cognitiveservices.speech.audio import AudioOutputConfig
speech_key, service_region = "6d5afa148**********5d8801db8e408", "chinanorth2"
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region,
speech_recognition_language="zh-cn")
def record():
# Creates a recognizer with the given settings
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
print("Say something...")
result = speech_recognizer.recognize_once()
# Checks result.
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(result.text))
elif result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(result.no_match_details))
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("Speech Recognition canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(cancellation_details.error_details))
return result.text
def chat(text_words=""):
api_key = "1dde879f**********f1ee88269f3852"
api_url = "http://openapi.tuling123.com/openapi/api/v2"
headers = {"Content-Type": "application/json;charset=UTF-8"}
req = {
"reqType": 0,
"perception": {
"inputText": {
"text": text_words
},
"selfInfo": {
"location": {
"city": "天津",
"province": "天津",
"street": "天津科技大學"
}
}
},
"userInfo": {
"apiKey": api_key,
"userId": "Alex"
}
}
req["perception"]["inputText"]["text"] = text_words
response = requests.request("post", api_url, json=req, headers=headers)
response_dict = json.loads(response.text)
result = response_dict["results"][0]["values"]["text"]
print("AI Robot said: " + result)
return result
def speak(text_words):
speech_config.speech_synthesis_language = "zh-cn"
audio_config = AudioOutputConfig(use_default_speaker=True)
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
result = speech_synthesizer.speak_text_async(text_words).get()
# Checks result.
if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
print("Speech synthesized to speaker for text [{}]".format(text_words))
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("Speech synthesis canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
if cancellation_details.error_details:
print("Error details: {}".format(cancellation_details.error_details))
print("Did you update the subscription info?")
if __name__ == '__main__':
while True:
text = record()
if "退出" in text:
break
res = chat(text)
speak(res)
代碼地址:https://github.com/Matrix-King-Studio/IntelligentVoiceRobot
演示視頻:https://www.bilibili.com/video/BV1BU4y1F7s7/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/323278.html
標籤:其他
上一篇:多階段漸進式影像恢復 | 去雨、去噪、去模糊 | 有效教程(附原始碼)|【??CVPR 2021??】
下一篇:集群安裝搭建賽題決議