學習總結
(1)y=Ax,矩陣A起到線性變換的作用,將x的N維度映射為M維度,即為一種空間變換的函式,而神經網路是想尋找一種非線性變換的空間函式,而可以通過多個線性變換層(下面栗子就是每次線性后加個非線性激活函式sigmoid),通過找到最優的權重,來組合起來,從而模擬非線性變換,
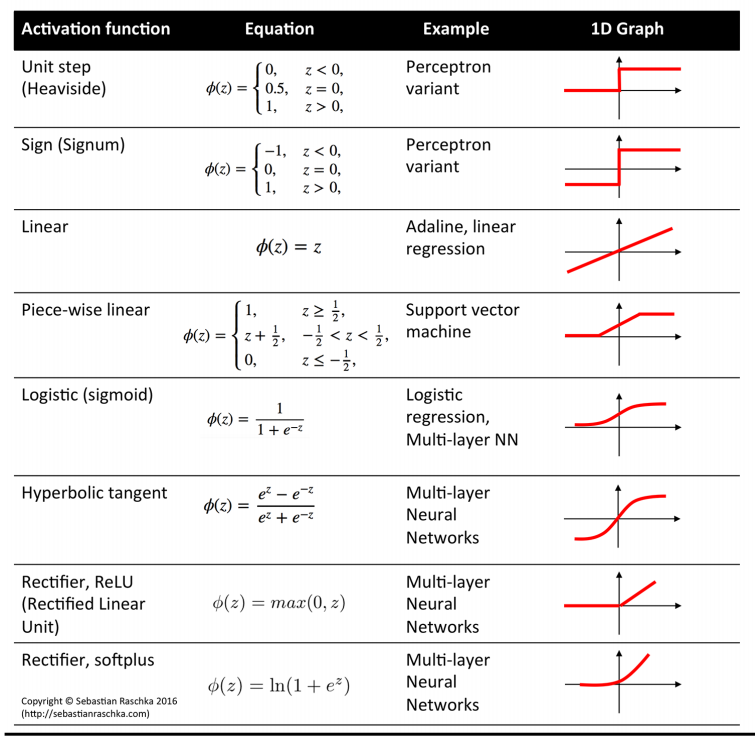
(2)relu取值范圍也是0到1,但是如果input是小于0的則relu值為0(輸出0是有風險的,因為后面可能會算ln 0,所以如果前面用的其他的激活函式,注意最后一個一般改為sigmoid激活函式,這樣就能輸出0到1之間數),
文章目錄
- 學習總結
- 一、和一維特征的區別
- 二、激活函式
- 三、糖尿病預測
- Reference
一、和一維特征的區別
之前的一維特征input,只有一個x和權重w相乘,多維的情況則是xi依次與逐個wi相乘(ps:每行x都這樣算,每行即每個樣本),可以用向量形式表示:
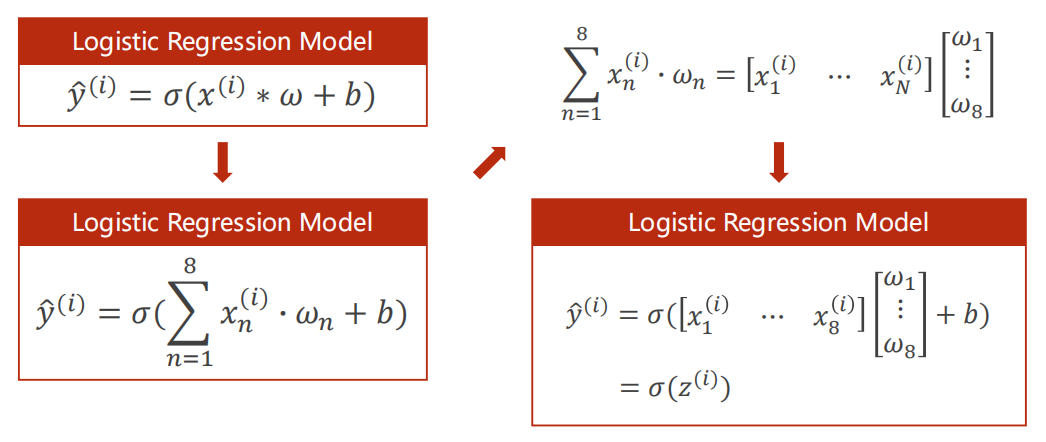
sigmoid函式對向量中每個元素都sigmoid一次,
繼續上面運算,改為矩陣運算(便于利用cuda運算):

稍微復習:y=Ax,矩陣A起到線性變換的作用,將x的N維度映射為M維度,即為一種空間變換的函式,而神經網路是想尋找一種非線性變換的空間函式,而可以通過多個線性變換層(下面栗子就是每次線性后加個非線性激活函式sigmoid),通過找到最優的權重,來組合起來,從而模擬非線性變換,
而需要設定多少層,每層怎么設定,一般需要超引數搜索,
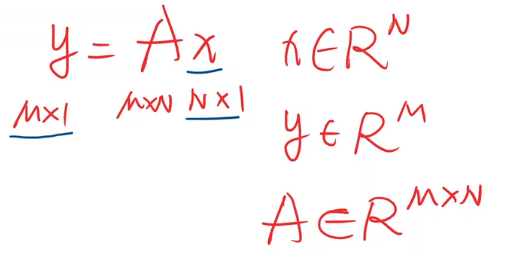
ps:隱層越多,學習能力越強,但也不一定好,因為會學習到資料中的噪聲,所以學習能力需要泛化能力,大學和高中的學習也是這樣的思想,不需要死扣書本,而是需要學習讀檔案和基礎架構的理念(泛化能力強),
二、激活函式
relu取值范圍也是0到1,但是如果input是小于0的則relu值為0(輸出0是有風險的,因為后面可能會算ln 0,所以如果前面用的其他的激活函式,注意:最后一個一般改為sigmoid激活函式,這樣就能輸出0到1之間數),
三、糖尿病預測
多層線性層,詳見注釋,
# -*- coding: utf-8 -*-
"""
Created on Mon Oct 18 10:18:24 2021
@author: 86493
"""
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# 這里的type不用double,特斯拉GPU才double
xy = np.loadtxt('diabetes.csv',
delimiter = ' ',
dtype = np.float32)
# 最后一列不要
x_data = torch.from_numpy(xy[: , : -1])
# [-1]則拿出來的是一個矩陣,去了中括號則拿出向量
y_data = torch.from_numpy(xy[:, [-1]])
losslst = []
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = nn.Linear(9, 6)
self.linear2 = nn.Linear(6, 4)
self.linear3 = nn.Linear(4, 1)
# 上次logistic是呼叫nn.functional的Sigmoid
self.sigmoid = nn.Sigmoid()
# 這個也是繼承Module,沒有引數,比上次寫法不容易出錯
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
# 使用交叉熵作損失函式
criterion = nn.BCELoss(size_average = False)
optimizer = torch.optim.SGD(model.parameters(),
lr = 0.01)
# 訓練,下面沒有用mini-batch,后面講dataloader再說
for epoch in range(10):
y_predict = model(x_data)
loss = criterion(y_predict, y_data)
# 列印loss物件會自動呼叫__str__
print(epoch, loss.item())
losslst.append(loss.item())
# 梯度清零后反向傳播
optimizer.zero_grad()
loss.backward()
# 更新權重
optimizer.step()
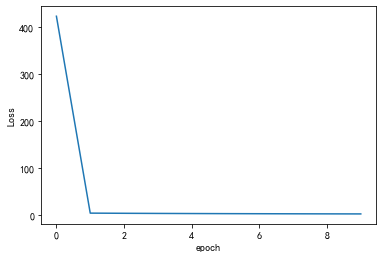
# 畫圖
plt.plot(range(10), losslst)
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.show()
Reference
(1)PyTorch官方檔案https://pytorch.org/docs/stable/_modules/torch
(2)b站視頻:https://www.bilibili.com/video/BV1Y7411d7Ys?p=10
(3)吳恩達網易云課程:https://study.163.com/my#/smarts
(4)劉洪普老師博客:https://liuii.github.io/
(5)激活函式:http://rasbt.github.io/mlxtend/user_guide/general_concepts/activation-functions/#activation-functions-for-artificial-neural-networks
(6)激活函式演示:https://dashee87.github.io/data%20science/deep%20learning/visualising-activation-functions-in-neural-networks/
(7)pytorch官方檔案,非線性激活函式:https://pytorch.org/docs/stable/nn.html#non-linear-activations-weighted-sum-nonlinearity
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/323314.html
標籤:AI