本文介紹采用高斯混合模型(GMM)和模糊C均值聚類(FCM)來進行網路流量例外檢測的方法,
原文來自IEEE,發表日期2013年,
原文鏈接:使用聚類技術和性能比較進行網路流量例外檢測|IEEE 會議出版物|伊 · X普洛爾
目錄
摘要
第一節:介紹
第二節:例外檢測方法
第三節:特征選擇和簡化
3.1 非負矩陣分解(NMF)
3.2 主成分分析(PCA)
第四節:聚類方法和改進
4.1 模糊高斯混合模型(GMM)
總結:
摘要
K-means聚類和高斯混合模型(GMM)是有效的聚類技術,模糊聚類比硬聚類更加靈活,并且由于使用模型聚類對資料進行自然處理,因此在入侵檢測方面非常實用,模糊c均值聚類法(FCM)是一種迭代的最佳演算法,通常基于最小二乘法來劃分資料集,具有較高的計算開銷,本文建議修改目標函式和距離函式,在保持聚類精度的同時降低FCM的計算復雜性,
本文提出了FCM聚類、GMM和特征變換相結合的方法,并且介紹了相關的測驗方法和聚類方法的比較,
第一節:介紹
不同的例外以不同的方式出現在網路中,因此設計一個有效的例外檢測系統需要從大量嘈雜、高維資料中提取相關資訊,區別正常和例外的網路行為的一般模型是困難的,基于模型的演算法在應用程式中也不可移植,網路流量的性質發生細微變化,模型也會不合適,因此,基于機器學習原理的非引數學習演算法是可取的,因此它們可以學習正常測量的性質,并自主的適應正常結構的變化,
例外資料檢測非常重要,因為資料中的例外轉化為各種應用領域中重要(且通常至關重要)可操作的資訊,例如,計算機網路中的例外流量模式可能意味著被黑客攻擊的計算機正在向未經授權的目的地發送敏感資料,例外 MRI 影像可能表示存在惡性腫瘤,信用卡交易資料中的例外可能表明信用卡或身份盜竊或航天器傳感器的例外讀數可能表示航天器某些部件存在故障,
例外資料檢測有很多技術,比如統計學,機器學習,資料挖掘和免疫啟發技術,聚類是用于例外檢測的機器學習技術之一,它基于這樣的假設:正常資料實體屬于大型和密集的聚類,而例外不屬于任何聚類或形成非常小或獨特的聚類,模糊聚類比硬聚類更靈活,對于離群值檢測非常實用,因為它考慮到了資料的性質,傳統的FCM聚類技術的優點是可以量化元素對檢測到的聚類的隸屬度,GK-FCM (古斯塔夫森-凱塞爾 FCM)可以生成適合資料形狀和位置的聚類,但是二者的計算復雜性很高,本文提出的對目標函式和距離函式的修改降低了計算復雜性,同時保持了分類的準確性,高斯混合模型(GMM)將資料分類具有指定平均值、協方差和混合比例的子類,它對簇大小的區分具有魯棒性,并且是FCM將資料實體分類為具有高斯分布的簇的一種實用方法,
第二節:例外檢測方法
例外檢測的方法大概有三種:分類、光譜分析和聚類,
聚類根據資料相似性對資料進行分類,這些相似性可通過距離函式(如歐幾里得函式,切比雪夫函式)來測量,好的集群應該具有內部相似性和相互差異性,
聚類可分為兩種型別:分層聚類使用以前建立的聚類來查找連續的聚類,磁區聚類根據迭代程式同時確定所有聚類,基于密度的演算法,如DBSCAN(基于密度的噪聲應用空間聚類),以及基于概率模型的技術,如AutoClass和K-means聚類也逐漸流行起來,
第三節:特征選擇和簡化
通常來說,資料集中許多維度(即特征)在生成模型時沒用,為了減少演算法復雜性,縮小尺寸很重要,當特征的原始單位和意義很重要且建模目標是識別有影響的子集時,特征選擇優于特征轉換,當存在絕對特征且特征轉換不恰當時,特征選擇成為減少尺寸的主要手段,
非負矩陣分解(NMF)和主成分分析(PCA)是廣泛應用的特征變換技術,
3.1 非負矩陣分解(NMF)
許多維度(特征)的原始資料所包含的實際資訊可能是重疊和相互關聯的,在大多數情況下,需要進行特征選擇以選擇獨立且不相關的變數,進行特征約簡以獲得其低階近似值并降低大型資料庫的計算復雜度,以及進行特征轉換以通過線性或非線性轉換組合不同的變數并形成顯著的特征,
給定一個非負m*n矩陣X和正整數k<min(m, n),NMF找到非負m*k矩陣W和k*n矩陣H,使X–WH的范數最小化,因此W和H是X的近似非負因子,W的k串列示X中變數的變換;H的k行表示X中原始n個變數的線性組合的系數,這些線性組合產生W中的轉換變數,由于k<X的秩,乘積WH提供X中資料的壓縮近似值,k的可能值通常由建模的背景關系決定,
3.2 主成分分析(PCA)
主成分分析使用正交變換將一組可能相關變數的觀測值轉換為一組稱為主成分的線性不相關變數值,每個主成分都是原始變數的線性組合,所有主成分相互正交,因此沒有冗余資訊,主成分的數量小于或等于原始變數的數量,此轉換的定義方式如下:主分量是空間中的單軸,將每個觀察投影到該軸上時,結果值將形成一個新變數,第二個主分量是空間中的另一個軸,垂直于第一個主分量,將觀測值投影到此軸上會生成另一個新變數,主成分分析對原始變數的相對比例敏感,
定義一個經驗平均值為零的資料矩陣XT,其中n行中的每一行表示實驗的不同重復,m列中的每一串列示特定的特征,X的奇異值分解為X=W∑VT,其中m×m矩陣W是協方差矩陣XXT的特征向量矩陣,矩陣∑是對角線上有非負實數的m×n矩形對角矩陣,n×n矩陣V是XTX的特征向量矩陣,PCA變換由:YT=XTW給出,如果我們想要一個降維表示,我們可以將X投影到僅由前L個奇異向量定義的降維空間中,∑L是一個矩形單位矩陣,X的奇異向量的矩陣W等價于觀測協方差C=X XT的矩陣的特征向量的矩陣W,
第四節:聚類方法和改進
傳統聚類方法將每個資料點分到一個簇,但模糊聚類可以分類為多個不同歸屬性的聚類,模糊聚類會生成精確的解決方案,并從某個或者一組輸入資訊中產生結果,其更加靈活,
本節介紹K-means聚類,高斯混合模型,FCM和GKFCM聚類方法,FCM和GKFCM都可以有效的生成集群,但開銷較大,然后建議對FCM進行修改(目標函式和距離函式),以簡化計算復雜性,還討論了通過非負矩陣因子化進行特征約簡和特征轉化的問題,
4.1 模糊高斯混合模型(GMM)
高斯混合模型是通過組合多變異正常密度組件而形成的,它們通常用于資料聚類,通過選擇最大化后概率的組件來分配組集,與 K 型聚類一樣,高斯混合建模使用迭次演算法,該演算法會收斂到本地最佳值,當聚類內部具有不同的大小和相關性時,高斯混合物建模可能比 k 型聚類更合適,
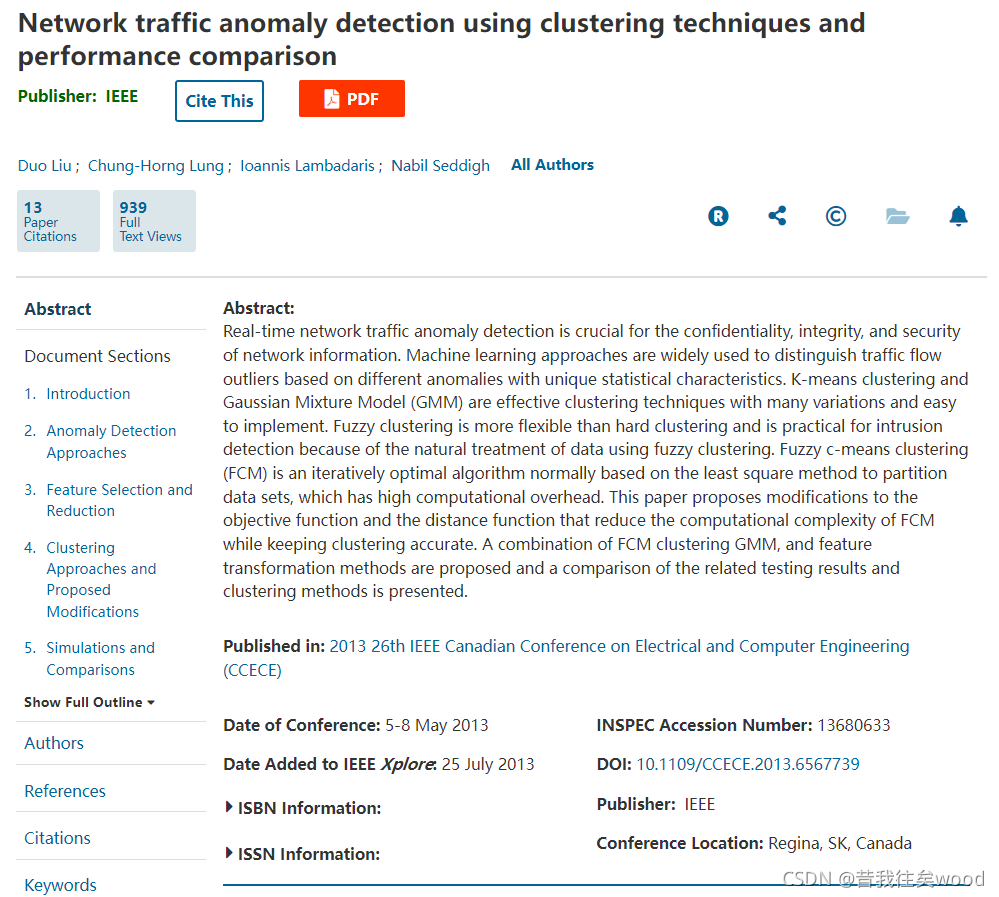
對于具有C聚類結構的D維資料集 x,每個聚類是高斯分布,引數μ(i),聚類 i 的密度為:
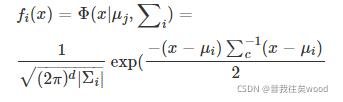
簇k的優先概率為a(k),混合密度是:
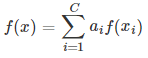
其中 x 和 μ 是 I-D 向量,Σ是一個D-D對稱的正定矩陣,我們可以根據混合密度定義新的距離函式,具體如下:
![]()
它像FCM 聚類中的物理距離一樣,具有相同的特征,因此,在距離轉換后,我們可以使用FCM程式實作基于聚類的高斯混合模型,聚類程序是一個迭次程序,以最小化目標函式,
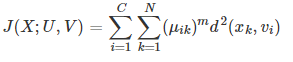
這里m:[1, ∞]是一個權重指數,決定集群的模糊性(模糊引數);值越大,模糊性越強,如果m=1,說明資料集是不模糊的,d是在上上式子定義過的,
迭次程序與傳統 FCM 相同,使用三次重復,直到滿足標準:通常達到預先配置的閾值,
總結:
本文的方法:FCM是靈活的聚類方法,可以量化元素對檢測到的聚類的隸屬度;GK-FCM可以生成適合資料形狀和位置的聚類;二者計算復雜性很高,所以改變目標函式和距離函式降低復雜性,GMM將資料分成子類,幫助FCM將資料分為具有高斯分布的簇,
有以下需要注意的知識:
(1)明白例外檢測(資料)的重要性,不僅是在計算機網路例外流量檢測,還有例外MRI影像檢測惡性腫瘤,信用卡交易資料例外表明身份盜竊,航天器傳感器資料例外表明部件損壞等等,
(2)聚類的假設:正常資料屬于大型和密集的聚類,例外不屬于或者屬于小而獨特的聚類,模糊聚類更加靈活,對于離群值檢測很實用,因為考慮到了資料的性質,
(3)聚類原理:根據資料的相似性,采用距離函式來度量,
(4)聚類方法分類:分層聚類和磁區聚類,
——分層聚類使用根據以前建立的聚類查找連續的聚類;
——磁區聚類根據迭代程式同時確定所有聚類;
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/323330.html
標籤:其他