目錄
CTF 逆向總結
題目型別總結:
匯編操作類總結:
ASCII碼表類總結:
逆向、腳本類總結:
堆疊、引數、記憶體、暫存器類總結:
函式類總結:
IDA等軟體類總結:
演算法類總結:
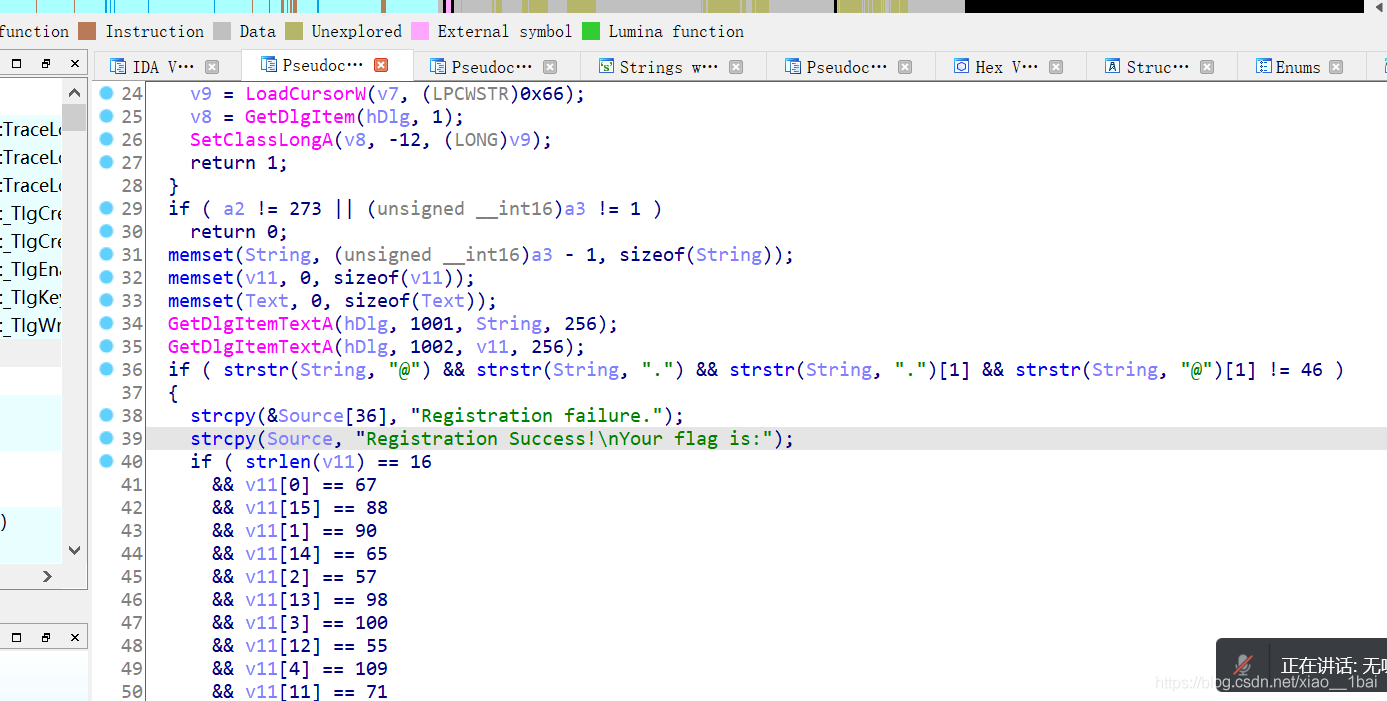
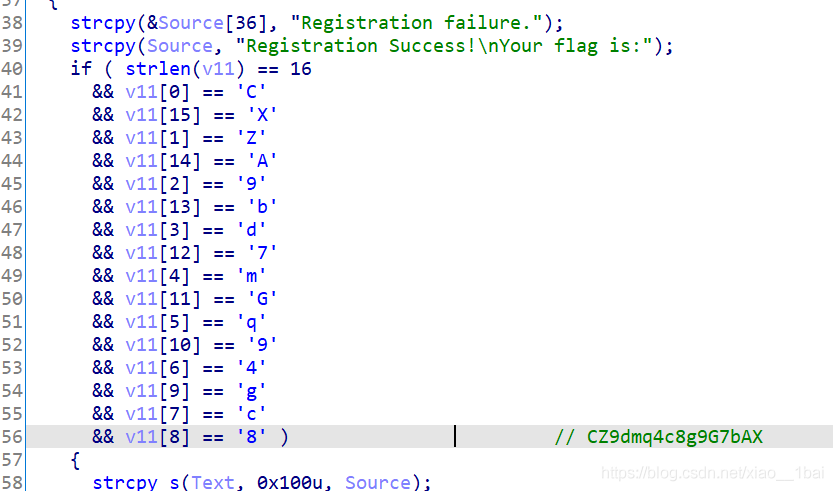
main函式主邏輯分析(C語言)
不能正常運行的exe檔案型別:
bugku 逆向入門:(實際TxT檔案、不能直接運行)
攻防世界的csaw2013reversing2:(運行亂碼、int3斷點考察、函式積累、不能直接運行)
攻防世界parallel-comparator-200:(.c檔案、大小寫字符轉換演算法、函式積累、相同異或為0演算法積累、執行緒操作積累、不能直接運行)
攻防世界tt3441810:(實際TXT檔案、不能直接運行、出人意料的flag、可列印字符過濾演算法積累)
main演算法邏輯平鋪型別:
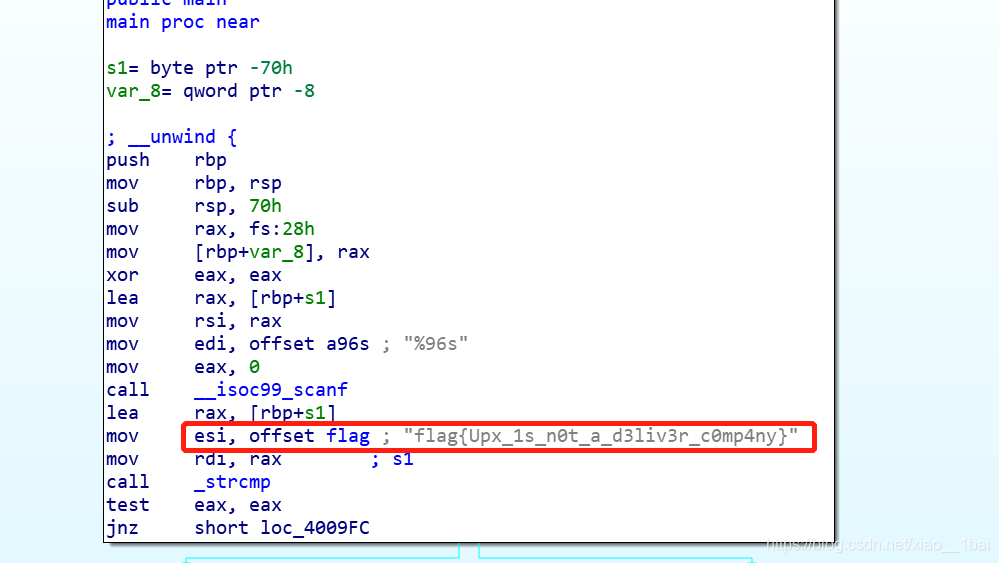
攻防世界逆向入門題Hello, CTF:(簡單比較)
攻防世界open-source:(argv[]外部呼叫輸入引數)
攻防世界logmein:(地址小端存放與正向)
BUUCTF的reverse2:(原flag簡單操作)
攻防世界666:(函式邏輯封裝,函式名稱暗示)
攻防世界Reversing-x64Elf-100:(函式邏輯封裝、地址小端存放與正向、二維陣列演算法積累)
攻防世界EasyRE:(堆疊地址連續小字串變數、堆疊中過渡變數反序字串、/x7f截斷字串、運算子優先級注意)
攻防世界re-for-50-plz-50:
攻防世界IgniteMe:(函式邏輯封裝、大小寫字符轉換演算法)
main函式與迷宮結合型別:
攻防世界maze:(高低位分割數、函式邏輯封裝、迷宮結合)
main函式與游戲結合型別:
攻防世界gametime:(游戲通關生成flag、)
main函式與數學演算法結合:
攻防世界notsequence:(楊輝三角演算法、函式邏輯封裝、IDA對char型(byte)的4*計數)
main函式中嵌入大量冗余代碼,拆分代碼混淆:
攻防世界Newbie_calculations:(非預期行為、不能直接運行、題目描述暗示、堆疊地址連續小陣列、c語言寫腳本、不同系統的特殊數、負數作回圈條件)
函式邏輯封裝型別:
攻防世界的no-strings-attached:(函式名稱暗示,GDB動態除錯,小端)
攻防世界answer_to_everything:(函式名稱暗示、函式邏輯封裝、出人意料的flag、題目描述暗示)
攻防世界secret-galaxy-300:(函式名稱暗示、題目描述暗示、字串拆分演算法積累)
攻防世界simple-check-100:(IDA動態除錯、GDB動態除錯)
攻防世界re1-100:(函式邏輯封裝、出人意料的flag、非預期行為)
攻防世界elrond32:(argv[]外部呼叫輸入引數符合條件、函式邏輯封裝、遞回呼叫演算法)
main函式中有與本地檔案相關的操作型別:
攻防世界getit:(IDA、GDB動態除錯)
main函式主邏輯分析(C++)
main函式中嵌入大量冗余代碼,拆分代碼混淆:
攻防世界dmd-50:(函式積累、地址小端存放與正向、涉及加密、出人意料的flag)
攻防世界crazy:(函式名稱暗示、地址賦值演算法積累、非預期行為、出人意料的flag)
無main函式分析(C語言)
主邏輯平鋪一函式內:
攻防世界Mysterious:(地址小端存放與正向,出人意料的flag)
攻防世界流浪者:(多層交叉參考查看、函式邏輯封裝、范圍演算法積累、函式積累)
攻防世界srm-50:
攻防世界hackme:(可變引數混淆、隨機抽取比較、取特定位數演算法)
帶殼題目型別
脫殼后邏輯平鋪:
攻防世界simple-unpack脫殼:(工具脫殼)
攻防世界Windows_Reverse1:(工具脫殼、不能直接運行、暫存器傳參、地址差值+陣列組合遍歷字串、字符ASCII碼做索引、ASCII碼表相關)
攻防世界Replace:(工具脫殼、解題逆向模板、>> 和 % 運算子演算法積累、正向爆破)
花指令題目型別
自定義函式自修改:
攻防世界BABYRE:(函式名稱暗示、IDA熱鍵重新反匯編、IDA動態除錯、堆疊地址連續小陣列)
2021年10月廣東強網杯,REVERSE的simplere:(迷宮結合、涉及加密、)
系統函式函式自修改:(HOOK,通常兩次修改系統函式,一次改成自定義機器碼,一次改回正常)
攻防世界EASYHOOK:(非預期行為、函式積累、手動機器碼)
安卓java類逆向分析
java邏輯平鋪:
攻防世界Guess-the-Number:(代碼截斷重寫)
RC4解密腳本:
INT3斷點:
IDA獲取地址內容命令嵌入:
CTF 逆向總結
工具脫殼:
值傳統的用工具壓縮的檔案,可以直接用工具來解壓縮,即脫殼,
非預期行為:
指解題中出現與預想結果不符合的一系列非預期行為,這基本說明了在中間或前面存在其他自己還沒分析的操作,
執行緒操作積累:
指解題代碼中設計多執行緒的交叉,阻塞,共享記憶體等操作,由于執行緒知識積累較少,所以每次都要積累,
不同系統的特殊數:
指解題中遇到考察特定位數系統中特定的數的真實值的時候,需要辨認出對應的值才能繼續解題,如:32位系統中100000000就是0了
題目型別總結:
題目描述暗示:
指題目給出的描述中有解題的大方向思路,以及對解題程序中出現的一些疑惑點的解釋,
不能直接運行:
指解題中下載的附件無法正常運行,可能是對外界本機環境又要求,需要檔案相關操作等,也可能是脫殼后地址混亂,需要修復匯入表或梳理地址,還有可能是演算法混淆,增加了運算時間,
游戲通關數生成flag:
指與游戲相關的可執行檔案中,不是存盤型flag,而是與用戶輸入相關的生成型flag,且以通關數生成flag,通常這種型別的題目改一下判斷條件就可以全部通關獲取flag了,
迷宮結合:
指解題程序中有類似于迷宮的每一步不能碰點或每一步必須符合在1維或多為字串上的落點,如:*A**********.***.....**.....***.*********..*********B**
這稱之為與迷宮結合型別,演算法走迷宮過于耗時,通常整理出迷宮維數后手動來走,
匯編操作類總結:
int3斷點考察:
int 3是斷點的一種,代碼執行到此次會拋出例外,因為這不是我們在OD之類的除錯器下的斷點,所以OD之類的除錯器不會處理該斷點的例外,而是交給系統處理,而系統的處理方式往往是強制退出,所以我們在動態除錯中要改為nop,不然后面的代碼就沒法執行,
手動機器碼:
指解題程序中遇到類似自修改代碼的操作,
如HOOK原型:
byte_40C9BC = 0351;
dword_40C9BD = (char *)sub_401080 - (char *)lpAddress - 5; ;跳轉到sub_401080地址處
這樣寫是因為匯編語言JMP address被編譯后會變成機器指令碼,E9 偏移地址,偏移地址=目標地址-當前地址-5(jmp和其后四位地址共占5個位元組),所以前面直接用E9,這里直接用偏移地址就省去編譯生成機器碼那一步,
ASCII碼表類總結:
字符ASCII碼做索引:
指解題中遇到如:*v1 = byte_402FF8[(char)v1[v4]]; 之類的字符做陣列索引的運算式,
其中v1[v4]逐個取input_flag的單個字符,這個字符的ascii碼作為偏移繼續在byte_402FF8[]陣列中尋址,(PS:這不是Python中list.index()函式可以用字符查找對應索引!)
ASCII碼表相關:
指解題中遇到.data資料節中跟蹤變數陣列時顯示的有大量0FFh這種不可識別字符后又有連續的可列印字符,
因為ASCII編碼表里的可視字符就得是32往后了, 所以凡是位于32以前的數統統都是迷惑項,都會被顯示成0FFh甚至亂碼,不會被索引到的,然后后面32之后就有連續的字串,這種就是ASCII碼表,
逆向、腳本類總結:
解題逆向模板:
第一步確定Flag字符數量,第一個紅框處得到flag數量是35,
第二步找到已確定的比較字串作為基點來反推flag字符,
第三步找出邏輯中與flag直接相關的部分,該部分可以正向爆破或者從尾到頭的反向邏輯,然后找到與flag沒有直接關聯的部分,該部分無需逆向邏輯,直接正向流程復現即可,
正向爆破:
指解題中采用列舉正向爆破的方法,讓flag中的每一個字符遍歷常用的字符(ascii碼表中32-126),帶入原偽代碼中加密演算法(不用逆向),如果成功,就把這個flag存入,
C語言寫腳本:
指解題中對于不需要逆向邏輯的單純去除冗余代碼演算法的題目,需要仿寫去除冗余代碼后的邏輯,由于只是仿寫,所以原本的偽代碼很難用python復現,這時就需要復制粘貼修改成C語言腳本了,
代碼截斷重寫:
指解題中flag生成與用戶輸入無關,可以單獨截斷提取出flag生成的函式或邏輯,然后運行截斷程式輸出flag,
出人意料的flag:
指在題目中獲取到了flag,但是這個flag可能長得不像flag,或者flag還要經過進一步的腦洞處理,而不是常規的解密處理,
堆疊、引數、記憶體、暫存器類總結:
堆疊地址連續小陣列:
指一些本來應該是大陣列的變數被IDA識別成分割成兩個或多個連續地址的小陣列來使用,可以通過查看堆疊中的地址排列或回圈中的回圈數大于單個陣列空間來發現,也是需要更加細致才能分析出來,
堆疊地址連續小字串變數:
指一些本來應該是大字串的單個變數被IDA識別成分割成兩個或多個連續地址的小字串變數來使用,可以通過查看堆疊中的地址排列來發現,也是需要更加細致才能分析出來,
堆疊中過渡變數反序字串:
指一些題目本來取輸入的字串變數的最后一位,但是IDA插入了過渡變數來使分析變得困難,如v5 = (char *)&v11 + 7;這里v11就是過渡變數,指向輸入字串input_flag的第16位,所以這里v5指向輸入字串input_flag的最后一位,堆疊中地址又是從下到上,高位到低位的,所以反序操作標志是v6 = *v5--;
地址小端存放與正向:
指字串數字等在記憶體中是反向存放的,如v7 = ‘ebmarah’,如果用地址來取的話要反向,如果用陣列下標來取的話才是正向,
高低位分割數:
指一些本來應該是兩個小型別變數的數被IDA識別成一個大型別然后分成高位和低位來使用,需要更加細致才能分析出來,
可變引數混淆:
指解題中IDA偽代碼顯示出來的引數數量超出,不符合邏輯,也不知道多附加了什么操作,查看反匯編才發現并沒有傳入那么多的引數,原偽代碼中之所以有那么多引數是因為C語言的可變引數的特性,有些引數顯示了但是并沒有用上,
地址差值+陣列組合遍歷字串:
指解題中遇到地址減地址的操作如:v4 = input_flag - v1; 然后通過陣列組合如:v1[v4],
這里V1作為地址和v4作為陣列v1[v4]執行的是v1+v4的操作,就是v4+v1=input_flag,因為陣列a[b]本質就是在陣列頭地址a加上偏移量b來遍歷陣列的,所以這里是一種遍歷input_flag的新操作,
暫存器傳參:
指解題中涉及暫存器作為引數傳入,但是有時候IDA無法反匯編出暫存器引數的傳入,解題中發現例外如:傳入引數為input_flag,但是比較的卻是另一個變數,這時就可能是暫存器傳參了,要通過查看匯編代碼來發現,
/x7f截斷字串:
/x7f可以阻斷字串,在IDA中會把一個長字串分隔成兩行的短字串,如:xIrCj~<r|2tWsv3PtI /x7f zndka
argv[]外部呼叫輸入引數符合條件:
指解題中需要使用命令列傳入引數,
如:int main( int argc, char *argv[] )
$./a.out testing1 testing2
應當指出的是,argv[0] 存盤程式的名稱,argv[1] 是一個指向第一個命令列引數的指標,*argv[n] 是最后一個引數,如果沒有提供任何引數,argc 將為 1,否則,如果傳遞了一個引數,argc 將被設定為 2,
函式類總結:
函式邏輯封裝:
指關鍵邏輯被封裝成自定義函式,需要自己雙擊跟進并總結出函式作用,需要通過動態除錯驗證猜想的作用,
函式名稱暗示:
指題目給出的自定義函式名稱有含義,可以概括該函式的大致作用,來給總結函式作用提出一些方向性的指導,
函式積累:
指題目中有沒做筆記的函式需要終點重溫和積累一下,
IDA等軟體類總結:
GDB動態除錯:
指使用GDB來進行ELF檔案的動態除錯,
IDA動態除錯:
指使用IDA來進行ELF或windows檔案的動態除錯,
IDA熱鍵重新反匯編:
指解題中必須使用IDA熱鍵對處理過或未處理的的錯誤反匯編代碼重新分析,以至生成新的正確的反匯編代碼,多用在混淆和花指令區,
IDA熱鍵a生成陣列:
指解題中對IDA零散的單個字符可以使用熱鍵a生成陣列,即長字串,如果中間沒有截斷,則可以正常生成字串,
IDA對char型(byte)的4*計數:
指解題中雖然IDA偽代碼顯示的 i 是 int 型,但是計算的時候通常會變成 4*i ,這通常會具有干擾性,所以我們要知道這是IDA默認把 i 當成byte型別即可,4*i 和 int 型的 i 是一樣的,
單層交叉參考查看:
指在解題中只能確定一些少量的被呼叫函式,這些函式可能是自定義函式也可能系統函式,通過IDA的function call或Ctrl+x操作來查看改函式被誰呼叫,從而找到主邏輯所在的函式,
多層交叉參考查看:
指在解題中一開始獲得的是比較深層次的被呼叫函式,需要多次查看交叉參考才能鎖定最終的主邏輯所在函式,
演算法類總結:
main演算法邏輯平鋪:
指主要演算法代碼都在main函式中,不涉及解題演算法之外的其它操作,而且代碼邏輯平鋪、顯而易見,沒有把關鍵邏輯分成自定義函式形式,不需要頻繁跟進函式,
范圍演算法積累:
指解題中有涉及用戶輸入的范圍內判斷以及逆向演算法時對于范圍處理的程序中值得注意和積累的地方,
地址賦值演算法積累:
指解題中涉及對關鍵字串如用戶輸入字串的操作,原代碼中會先把輸入字符的地址賦值給變數,即讓一個變數指向輸入字串然后再開始修改,這是兩步操作,需要辨認,
二維陣列演算法積累:
指解題中涉及二維陣列,用戶輸入與二維陣列要取的下標相關,逆向時要明確是二維陣列邏輯以及一維在哪里確定,舉例如: *(char *)(v3[i % 3] + 2 * (i / 3)) - *(char *)(i + a1) != 1
字串拆分演算法積累:
指解題中IDA對多個連續的字串按打亂的順序以下標的方式分別按多組賦值,這種字串拆分賦值的方式需要動態除錯或耐性的一個個跟蹤分析才能梳理清楚,
相同異或為0演算法積累:
指解題中遇到特定異或為0的條件則可以采用上面的定律,如: *result = (108+argument[1]) ^ argument[2] = 0 即 argument[2]=(108+argument[1]) 因為相同異或才為0
可列印字符過濾演算法積累:
指解題中遇到flag等關鍵字符在內的混雜的大量字符中,要通過多層過濾來一步步生成flag的演算法,可列印字符范圍內可用演算法如:if ord(i)>=32 and ord(i)<=125:
大小寫字符轉換演算法:
指解題中有一些演算法范圍波動比較少,看似邏輯相關,實際上只是大小寫的ASCII值轉換而已,
遞回呼叫演算法:
指解題中遇到函式內遞回呼叫自己,傳入引數也會在呼叫時修改的演算法,當需要用python仿寫遞回演算法時可以通過超范圍的回圈來實作遞回,因為設定同樣的條件,遞回不滿足時仿寫的回圈也會退出,
楊輝三角演算法:
指解題中遇到對傳統數學演算法的代碼實作,辨認的特征是通過關鍵代碼判斷是否符合楊輝三角演算法的特性,如:在一維中用(n*(n+1)/2的前n行總數來遍歷到特定行,又如:2^n來求第n行的和等,通常涉及等差、等比數列,
>> 和 % 運算子演算法積累:
指解題中遇到 >> 和 % 運算子的操作,>> 運算子其實是不帶余數的除法 / 演算法,單取整數部分,% 運算子其實是不帶整數的求余運算,單取余數部分,
如: v6 = (v5 >> 4) % 16 是除以16后的整數部分, v7 = ((16 * v5) >> 4) % 16 是乘16后除16再取16內的余數,也就是直接取16內的余數,一個取整數,一個取余數,所以他們的逆向演算法就是16 * v6 + v7
運算子優先級注意:
指解題中應該要準確判斷長運算式的優先級順序,寫腳本中也應該盡可能使用括號來固定優先級,否則會出現結果的錯誤,
負數作回圈條件:
指解題中遇到負數作回圈條件的情景需要明白這不是死回圈,而是正數大回圈,如:while(-1) ,在32位里 -1 就是 FFFFFFFF,就是100000000 - 1,所以這一下子就轉正了!如果是while(-a2),所以就回圈100000000 - a2次,
涉及加密:
指題目中存在加密,可能是傳統的MD5、RSA或base64等,也可能是非傳統的加密方式,
隨機抽取比較:
指在解題中以亂數做基準,取各個對應的字符進行比較,其實就是在相同的字符中取隨機但同樣的位來比較,所以逆向是要順序取,
取特定位數演算法:
指解題中遇到源代碼有__int8這樣的限制,這是取前8位,python中可以使用&0xff這種方法,因為&在Python中是邏輯與運算,所以與的時候就保留了前8位,如:flag+=chr((v12^v15)&0xff),取前16,32位都可以套用這個方法,
main函式主邏輯分析(C語言)
不能正常運行的exe檔案型別:
bugku 逆向入門:(實際TxT檔案、不能直接運行)
直接去掉.exe后綴用記事本打開,直接搜索bugku,無果,看到檔案開頭:
是base64加密的圖片,于是用在線網址(http://tool.chinaz.com/tools/imgtobase/)解密得到二維碼:(掃碼即得flag)
攻防世界的csaw2013reversing2:(運行亂碼、int3斷點考察、函式積累、不能直接運行)
win32無殼,那么既然是windows的直接雙擊運行一下看看:
這個就是亂碼的flag了,亂碼有好多種,base64加密等等這些,我們一個個排除,先扔入IDA中查看偽代碼,要先看C或C++偽代碼再分析反匯編結構圖最后才看反匯編文本!!!!
main主函式偽代碼如圖:

那么解題關鍵就在前面了:
memcpy_s(lpMem, MaxCount, &unk_409B10, MaxCount);//這個是復制函式,把&unk_409B10處的字串賦值給lpMem,分析后可知這是亂碼的flag,雙擊跟蹤&unk_409B10也可以看到是彈框中輸出的亂碼,
if ( sub_40102A() || IsDebuggerPresent() ) //這是判斷函式,如果判斷是除錯器運行就執行這個解密
{
__debugbreak();
sub_401000(v3 + 4, lpMem);//這個雙擊跟蹤進去后發現是一個運算函式,那么只能是解密演算法所在了
ExitProcess(0xFFFFFFFF); //解密后就退出了,就沒有后面的彈框了,需要我們自己想辦法,
}
分析完了,我們開始解題,也是好幾種方法:
1:靜態除錯:根據sub_401000的解密演算法自己仿照C語言或python腳本解密,因為引數都可以跟蹤到,
2:動態除錯:在onllydbg中進入解密流程內,解密后查看暫存器或跳轉到messageboxA中進行彈出即可,
這里我用的動態除錯:按照流程看完C語言偽代碼后我們來看反匯編結構圖:
有了前面分析基礎就看懂得多了:loc_4010B9:是彈框函式所在,loc_401096:是解密函式所在,最左邊那個應該是冗余代碼,loc_4010EF和loc_4010CD: 都是退出函式所在,
注意這里loc_401096有個int 3;這是斷點的一種,代碼執行到此次會拋出例外,因為這不是我們在OD之類的除錯器下的斷點,所以OD之類的除錯器不會處理該斷點的例外,而是交給系統處理,而系統的處理方式往往是強制退出,所以我們在動態除錯中要改為nop,不然后面的代碼就沒法執行
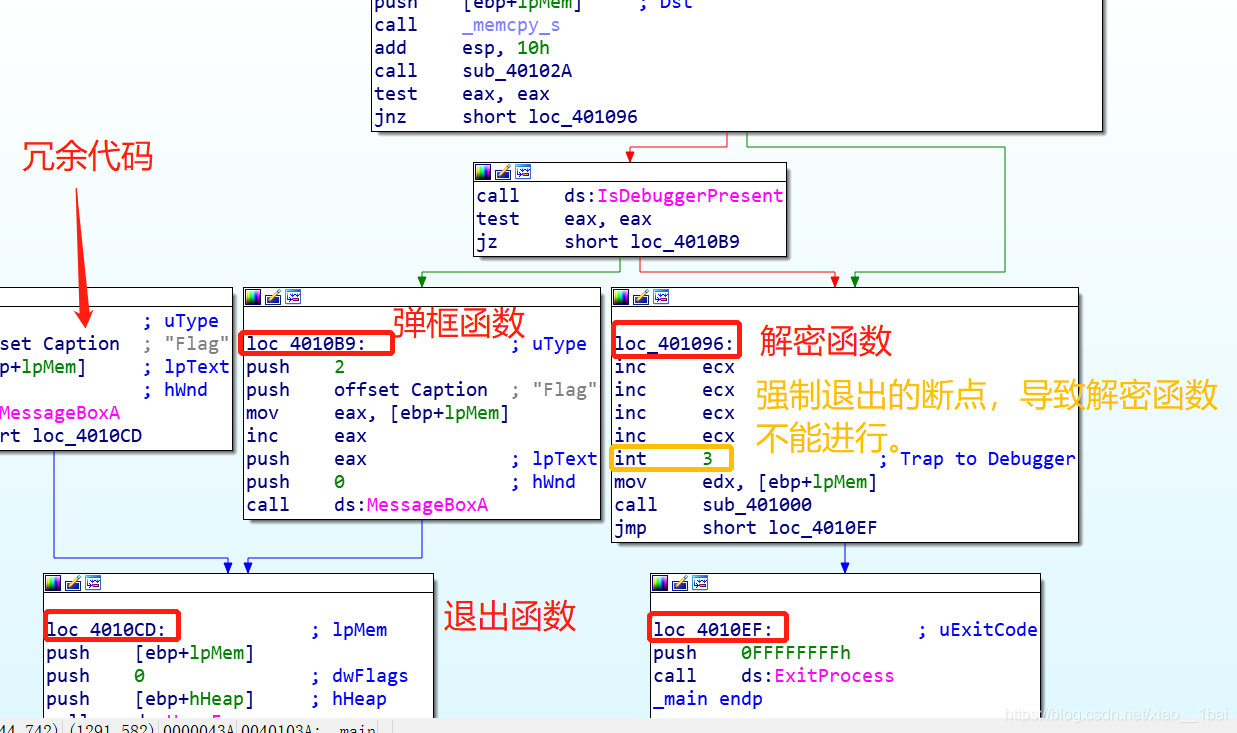
那么我們上onllydbg修改int 3;斷點為nop:
可以看到我改了幾個地方:
1:
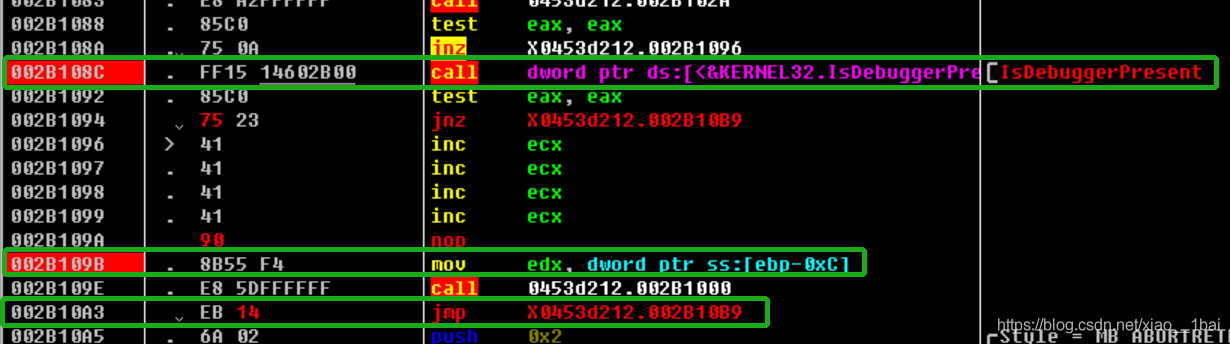
002B1094的 jz short loc_4010B9改成jnz short loc_4010B9,雖然我也不知道為什么我用onllydbg除錯還是進不去解密函式,可能onllydbg被認為不是除錯器吧,
2:
002B109A 的int 3;斷點強制退出被我改成了002B109A nop,標識空操作,避免退出,
3:
002B10A3的 jmp 0453d212.002B10EF改成jmp 0453d212.002B10B9 因為這里原來解完密后就退出的,我把它轉到原來loc_4010B9:的messageboxA函式去作為彈框內容輸出了,(ps:我本來是跳轉到最IDA反匯編結構圖的左邊那個冗余函式的,因為我看它也是MessageboxA函式,結果彈出個空框,對比后才發現它比第二個MessageboxA少了幾行代碼,原來是個坑,難怪,),當然也可以解完密之后下斷點讀取暫存器內容也行,
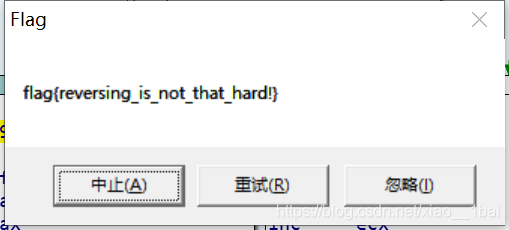
這樣就彈出flag了:
攻防世界parallel-comparator-200:(.c檔案、大小寫字符轉換演算法、函式積累、相同異或為0演算法積累、執行緒操作積累、不能直接運行)
下載附件,一個.c后綴的檔案,devc++中查看代碼,
這里犯下第一個錯誤:混淆代碼太多,執行緒一開始沒學,簡單學了后發現也和解題邏輯沒有太大關系,可以把執行緒劃分為系統函式這一塊:
#include <stdlib.h>
#include <stdio.h>
#include <pthread.h> //linux的執行緒庫 ,所以要在linux中才可運行
#define FLAG_LEN 20
void * checking(void *arg) {
char *result = malloc(sizeof(char));
char *argument = (char *)arg;
*result = (argument[0]+argument[1]) ^ argument[2]; //對 first_letter、 differences[i]、 user_string[i]進行簡單操作
return result;
}
int highly_optimized_parallel_comparsion(char *user_string)
{
int initialization_number;
int i;
char generated_string[FLAG_LEN + 1];
generated_string[FLAG_LEN] = '\0';
while ((initialization_number = random()) >= 64); //無用回圈
int first_letter;
first_letter = (initialization_number % 26) + 97; //initialization_number從0~25取值 +97后ASCII對應小寫的a~z
pthread_t thread[FLAG_LEN]; //創建陣列型的執行緒識別符號 ,20執行緒句柄
char differences[FLAG_LEN] = {0, 9, -9, -1, 13, -13, -4, -11, -9, -1, -7, 6, -13, 13, 3, 9, -13, -11, 6, -7}; //定義20個元素的char陣列
char *arguments[20]; //定義20個char型的指標陣列
for (i = 0; i < FLAG_LEN; i++) {
arguments[i] = (char *)malloc(3*sizeof(char)); //每個指標指向3個char位元組劃分的陣列頭
arguments[i][0] = first_letter; //first_letter由于 initialization_number = random()而未確定
arguments[i][1] = differences[i]; //已確定
arguments[i][2] = user_string[i]; //用戶輸入字符,未確定
pthread_create((pthread_t*)(thread+i), NULL, checking, arguments[i]); //呼叫上面checking函式對arguments三位元組陣列進行簡單操作
}
void *result; //定義一個陣列,用上面的異步執行緒賦值
int just_a_string[FLAG_LEN] = {115, 116, 114, 97, 110, 103, 101, 95, 115, 116, 114, 105, 110, 103, 95, 105, 116, 95, 105, 115}; //定義一個20個元素的陣列
for (i = 0; i < FLAG_LEN; i++) {
pthread_join(*(thread+i), &result); //阻塞執行緒,讓執行緒一個個執行
generated_string[i] = *(char *)result + just_a_string[i]; //把 just_a_string陣列加到result中 賦值給 generated_string陣列
free(result);
free(arguments[i]);
}
int is_ok = 1;
for (i = 0; i < FLAG_LEN; i++) {
if (generated_string[i] != just_a_string[i]) //這里比較generated_string和 just_a_string陣列,而generated_string陣列在前面賦值中= *(char *)result + just_a_string[i],所以result等于0才行
return 0;
}
return 1;
}
int main()
{
char *user_string = (char *)calloc(FLAG_LEN+1, sizeof(char)); //分配21個字符空間,除去0結尾就是20個字符
fgets(user_string, FLAG_LEN+1, stdin); //獲取用戶輸入
int is_ok = highly_optimized_parallel_comparsion(user_string);
if (is_ok)
printf("You win!\n");
else
printf("Wrong!\n");
return 0;
}
關鍵代碼判斷有兩條:(所以result是要為0了,因為0加任何數都為0,)
generated_string[i] = *(char *)result + just_a_string[i];
if (generated_string[i] != just_a_string[i])
給result賦值的陳述句中唯一不確定的就是argument[0],也就是 first_letter = (initialization_number % 26) + 97:
*result = (argument[0]+argument[1]) ^ argument[2]; //對 first_letter、 differences[i]、 user_string[i]進行簡單操作
在這里我查了很多資料,很多人直接用108代替argument[0],也有人用first_letter的范圍97~122來批量計算,這里我兩種都說:
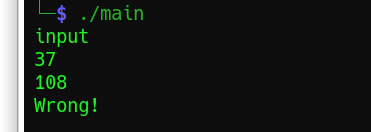
第一種:108,這里也是犯下的第二個錯誤,以前就聽過rand是偽亂數,要用srand生成亂數種子才行,不然產生的亂數串列都是一樣的,而單獨產生的亂數也不會在亂數串列用隨意取值,而是固定的第一次這個值,第二次那個值,所以這里我們可以直接修改源代碼除錯,列印出first_letter的值,
(PS:linux中C語言要使用gcc main.c -lpthread -o main編譯方法來編譯帶pthread.h庫的檔案)
while ((initialization_number = random()) >= 64);
printf("%d\n",initialization_number); //列印initialization_number
int first_letter;
first_letter = (initialization_number % 26) + 97;
printf("%d\n",first_letter); //列印first_letter
結果可以看到,一個37,一個108,所以108就是除錯過來的:
知道108后寫腳本,這里犯下第三個錯誤:
因為源代碼是*result = (argument[0]+argument[1]) ^ argument[2] = 0 即 *result = (108+argument[1]) ^ argument[2] = 0 即 argument[2]=(108+argument[1]) 因為相同異或才為0.(一開始我并不清楚這個邏輯,這里也可以說是一個演算法積累了)
first_letter=108
differences=[0, 9, -9, -1, 13, -13, -4, -11, -9, -1, -7, 6, -13, 13, 3, 9, -13, -11, 6, -7]
flag=""
print(''.join([chr(first_letter+i) for i in differences])) //這里借鑒了別人的博客,用的是串列的[ ]決議式,的確不錯!也可以作為總結!
第二種方法就是從97~122的first_letter開始批量爆破計算,腳本:
differences=[0, 9, -9, -1, 13, -13, -4, -11, -9, -1, -7, 6, -13, 13, 3, 9, -13, -11, 6, -7]
for i in range(97,123):
flag=""
print(i)
for a in differences:
flag+=chr(i+a)
print(flag)
可以看到,能形成有文字含義字串的就是108了:
攻防世界tt3441810:(實際TXT檔案、不能直接運行、出人意料的flag、可列印字符過濾演算法積累)
下載附件,照例扔入exeinfope中查看資訊:
說是TXT檔案,???記事本打開看一下:
一下子懵住了,腦袋沒轉過來,查看了資料說Flag就混雜在這些十六進制里,winhex64打開看一下:
結果winhex64的文本顯示不了字符,我還是看不出來什么,(換ASCII編碼也是一樣)
結果發現他們使用IDA打開的:
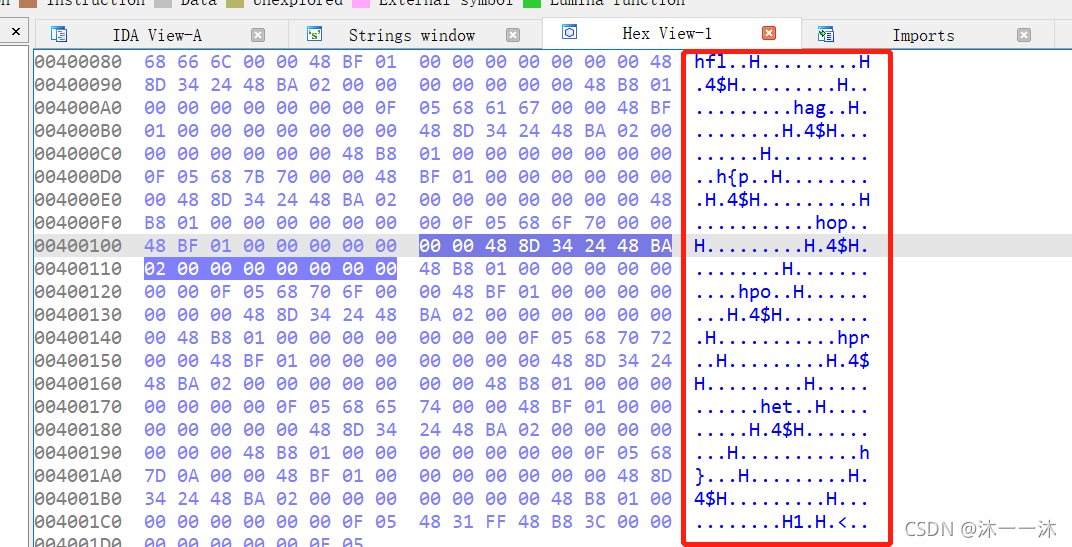
終于有一點字符了,之前了解過點字符是因為IDA識別不了不可列印字符,所以這里要寫腳本過濾,像雜項或密碼學一樣的:(32~125是可顯示字符)
key1=''' //這里積累第一個經驗,多行的字串可以用三引號,雖然我知道這個三引號,但是我要用時我還真想不到它,
hfl..H.........H
.4$H.........H..
.........hag..H.
........H.4$H...
......H.........
..h{p..H........
.H.4$H.........H
...........hop..
H.........H.4$H.
........H.......
....hpo..H......
...H.4$H........
.H...........hpr
..H.........H.4$
H.........H.....
......het..H....
.....H.4$H......
...H...........h
}...H.........H.
4$H.........H...
........H1.H.<..
.......
'''
flag=""
for i in key1:
if ord(i)>=32 and ord(i)<=125: //過濾在可列印字符范圍內的字符
flag+=i
print(flag.replace('.','').replace('HH4$','').replace('HHh','')) //這里是我一層層看邏輯過濾的,因為出現多個. 、HH4$和HHh,所以這些都要過濾掉,
結果:

可以看到flag了,但是提交時說只提交{}內的部分,就是poppopret,這種提交方式已經見怪不怪了,
main演算法邏輯平鋪型別:
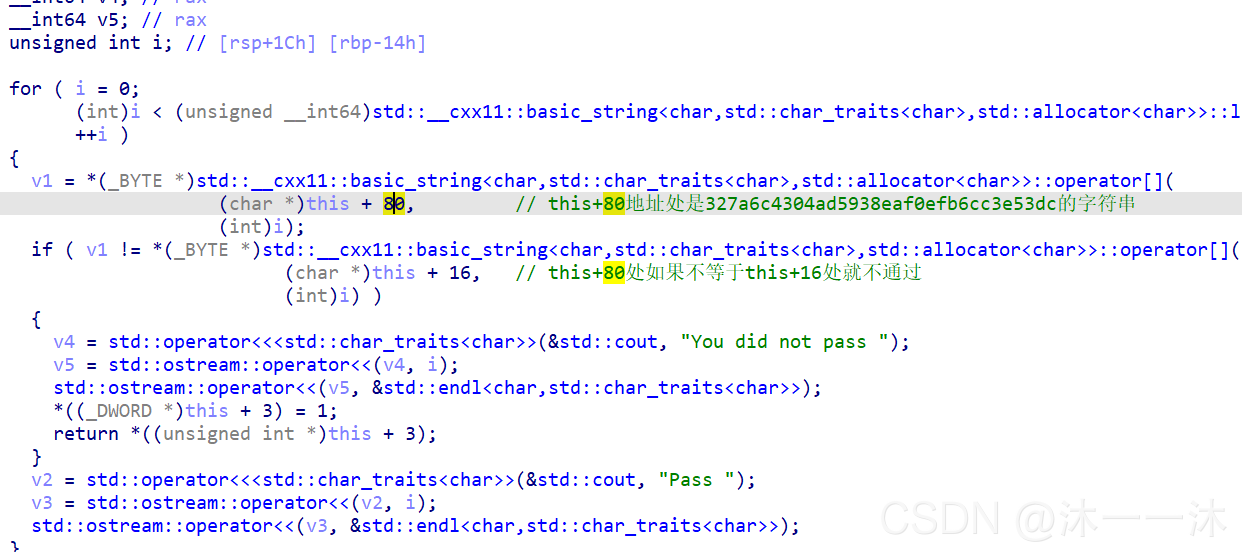
攻防世界逆向入門題Hello, CTF:(簡單比較)
對匯編不太熟悉,只能分析偽代碼:
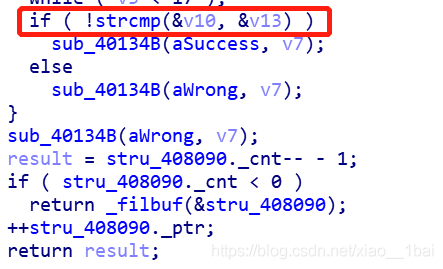
偽代碼顯示用用戶輸入的v10和v13比較,sub_40134B是我在OD中認定的字串輸出函式puts,
所以終于找到了v13這個被比較變數了,查看與它相關的操作:
![]()
一個復制函式,那么那個a4~開頭的就是我們要找的了,雙擊跟蹤:

資料域發現一串十六進制字符,解碼得到flag,
攻防世界open-source:(argv[]外部呼叫輸入引數)
#include <stdio.h>
#include <string.h>
int main(int argc, char *argv[]) {//外部呼叫輸入引數
if (argc != 4) {//輸入三個引數,因為第一個是程式自己的名稱
printf("what?\n");
exit(1);
}
unsigned int first = atoi(argv[1]);
if (first != 0xcafe) {//第一個引數的十六進制為0xcafe
printf("you are wrong, sorry.\n");
exit(2);
}
unsigned int second = atoi(argv[2]);
if (second % 5 == 3 || second % 17 != 8) {//第二個引數滿足條件我口算有42,余數是不足才補的數,不是整除后剩的數,也就是5*9余3
printf("ha, you won't get it!\n");
exit(3);
}
if (strcmp("h4cky0u", argv[3])) {//第三個引數直接就是h4cky0u
printf("so close, dude!\n");
exit(4);
}
printf("Brr wrrr grr\n");
unsigned int hash = first * 31337 + (second % 17) * 11 + strlen(argv[3]) - 1615810207;//這里的結果hash與前面輸入引數有關,鄙人不才,曾一度想修改原始碼不輸入引數直接輸出這句話,當然,沒有引數的這句話就會報錯,
printf("Get your key: ");
printf("%x\n", hash);
return 0;
}
一開始第二個條件停了會,畢竟做題經驗太少了,atoi回傳的是字串的整形,0xcafe是十六進制,整形和十六進制比較C語言內部會進行進制轉換:
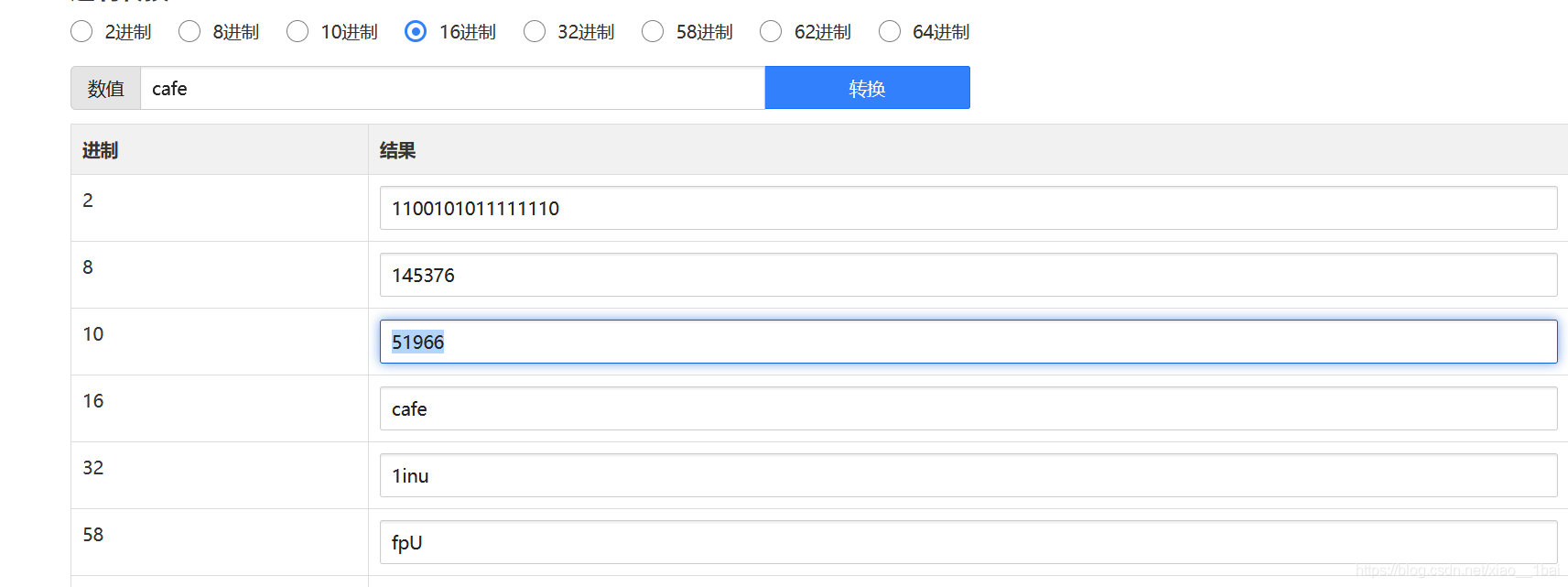
所以到此所有引數都解出來了,第一個是51966,第二個是42,第三個是h4cky0u.在kali虛擬機中編譯,命令列接受引數執行即可:
gcc 1.c
./1.c 51966 42 h4cky0u
后來看別人做法還發現了其他解法,第一個是直接修改原始碼,其實也對,原始碼在手當然是充分利用原始碼的優勢才對,直接把hash輸出陳述句替換成:
unsigned int hash = 0xcafe * 31337 + (second % 17) * 11 + strlen(argv[3]) - 1615810207;
即可,反正C語言內部會自己轉換,記得把第二個0xcafe處的判斷陳述句用/**/注釋掉即可,
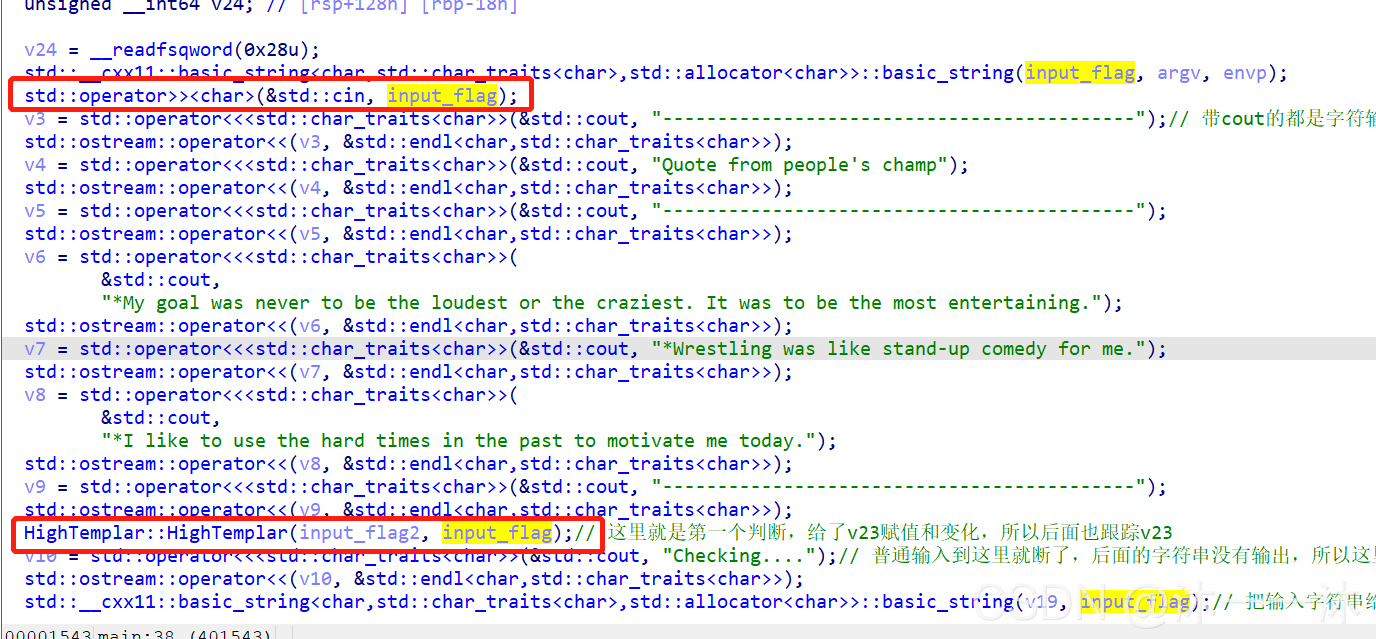
攻防世界logmein:(地址小端存放與正向)
ELF的linux檔案,在kali虛擬機中查看位數,是64位,扔到64位IDA中查看資訊,主要查看偽代碼:

很常規的題型,關鍵輸入判斷如下:
![]()
在IDA中v7按R鍵轉換為v7 = ‘ebmarah’; (_BYTE *)&v7表示將原本是_int64型別的v7轉換地址形式,轉成byte型地址形式來實作1位一位讀取字串,
這里還要注意的是這里的記憶體是小端存放的,也就是說我們要逆著來比較v7的字串,然后直接上python腳本:
key1=":\"AL_RT^L*.?+6/46"
key2="ebmarah"[::-1]
key3=""
for i in range(len(key1)):
key3+=chr(ord(key2[i%7]) ^ ord(key1[i]))
print(key3)
BUUCTF的reverse2:(原flag簡單操作)
一進門看到這個,還以為真的這么簡單,認為offset flag就是flag地址,直接跟蹤結果是假的flag,一開始還以為是提交格式有問題,比如多了個空格或者復制錯了什么啊,果然還是太年輕了,見識少,就是假的flag,
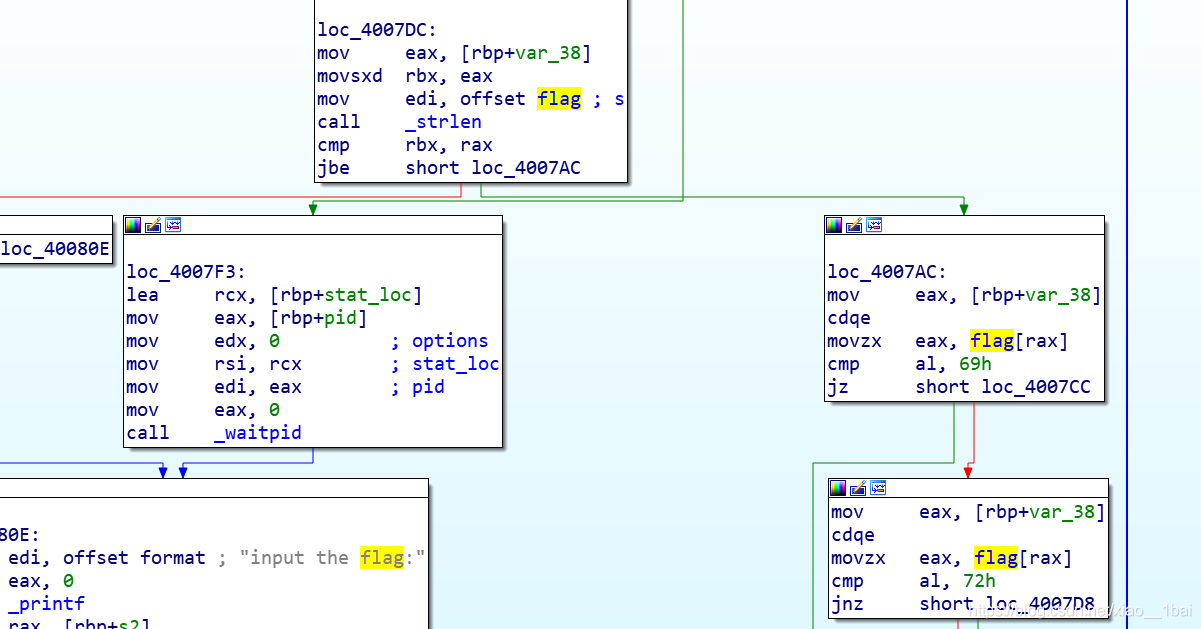
查看偽代碼(由于匯編能力比較差):
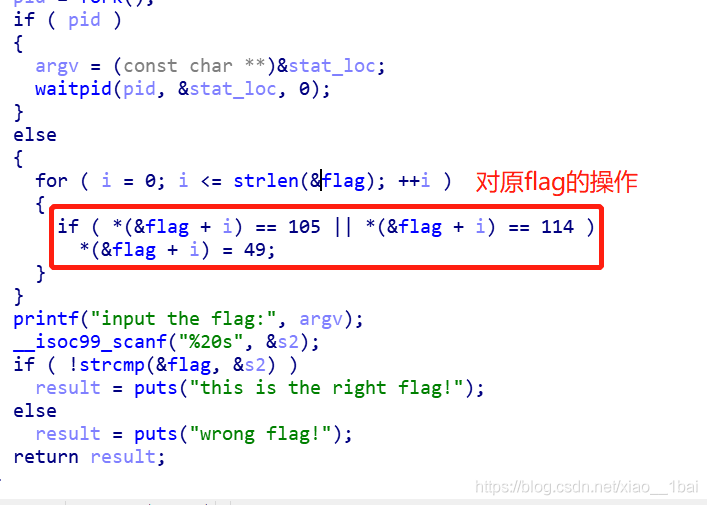
可以看到前面有對flag內容的替換,就是把ASCII碼等于105和114的替換成ASCII碼49,直接寫腳本:
flag="{hacking_for_fun}"
for i in range(len(flag)):
if((ord(flag[i])==105) or (ord(flag[i])==114)):
flag=flag.replace(flag[i],chr(49))
print(flag)
寫腳本時一開始還有點問題,順便記在這里提醒一下自己:
一開始寫成flag="{hacking_for_fun}"[::-1],受了以前的小端順序影響,這里我們看到的就是從601081到601091的地址順序,也就是已經按小端的來了,所以不用再反序,還有就是flag.replace()這種python字串內置函式都是暫時的,要想保留改變還是要用賦值陳述句賦值成:flag=flag.replace(flag[i],chr(49))
攻防世界666:(函式邏輯封裝,函式名稱暗示)
64位ELF檔案,無殼,扔入IDA64中查看偽代碼,因為有main函式,所以直接main函式:
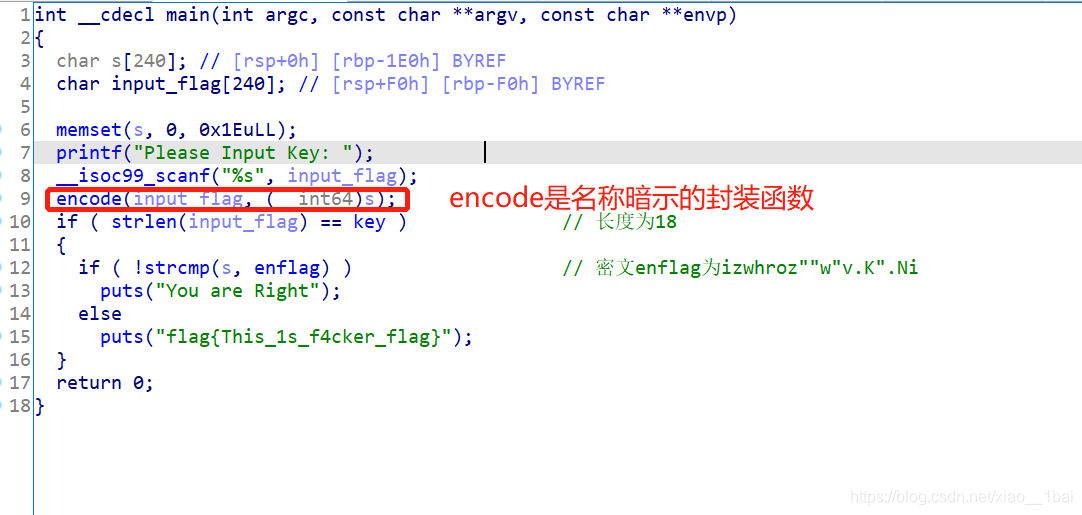
判斷題目型別,flag是與用戶輸入有關的明文密文加密型,給了密文(雙擊跟蹤),那么根據加密邏輯函式用密文逆向邏輯解出明文即可,加密邏輯如下:
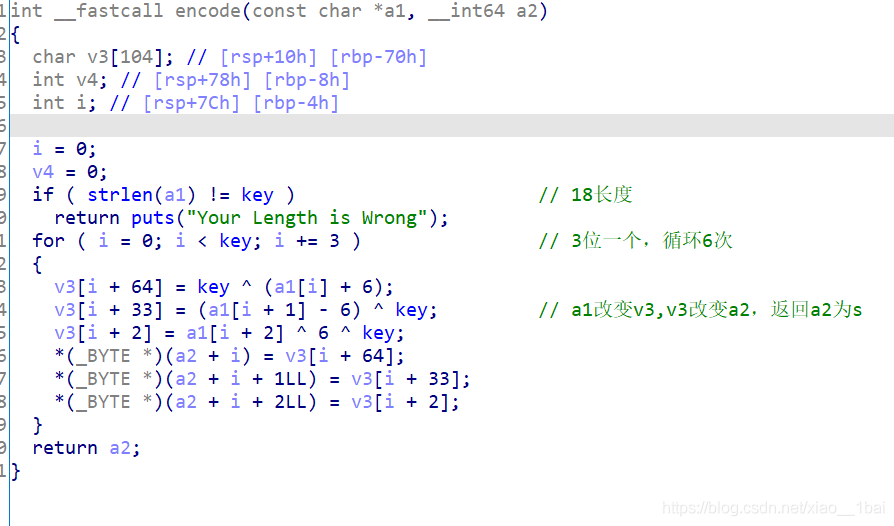
這邏輯挺簡單的,所以直接上腳本即可:
a2="izwhroz\"\"w\"v.K\".Ni"
key=18
v3=""
flag=""
#print(len(a2))
for i in range(0,18,3):
v3=a2[i]
flag+=chr((ord(v3)^key) - 6)
v3=a2[i+1]
flag+=chr((ord(v3)^key) +6)
v3=a2[i+2]
flag+=chr((ord(v3)^key)^6)
print(flag)
攻防世界Reversing-x64Elf-100:(函式邏輯封裝、地址小端存放與正向、二維陣列演算法積累)
64位ELF檔案,無殼,扔入64位IDA中,有主函式從主函式開始:(PS:這里犯下第一個錯誤,我一開始以為沒有主函式,跳到start函式中去分析了,結果有個堆疊指標錯誤,但是我還不會調,迷惘了,后來一看才發現原來有主函式)
跟蹤進入判斷函式并分析代碼:
__int64 __fastcall sub_4006FD(__int64 a1)
{
int i; // [rsp+14h] [rbp-24h]
__int64 v3[4]; // [rsp+18h] [rbp-20h]
v3[0] = (__int64)"Dufhbmf"; //這里犯下第二個錯誤,我以為是普通字串,在記憶體中應該小端順序反序才對,結果是陣列,陣列的話從首地址開始的確是正序的了,吸取經驗,以后要是不確定是不是反序就直接雙擊跟蹤看記憶體即可,
v3[1] = (__int64)"pG`imos";
v3[2] = (__int64)"ewUglpt";
for ( i = 0; i <= 11; ++i )
{
if ( *(char *)(v3[i % 3] + 2 * (i / 3)) - *(char *)(i + a1) != 1 ) //這里犯下第三個錯誤,一開始沒看見最左邊的取地址符*的范圍是一整個(char *)(v3[i % 3] + 2 * (i / 3)),搞到腳本撰寫出來障礙,這里應該這樣理解,(char *)(v3[i % 3]取這v3[0]、v3[1]、v3[2]、中的第幾個完整陣列,+ 2 * (i / 3)是為了在確定的v3[0]、v3[1]、v3[2]中繼續深入取對應陣列的字符進行操作,這里的逆向邏輯也簡單,就是*(char *)(v3[i % 3] + 2 * (i / 3)) - 1 = *(char *)(i + a1)
return 1LL;
}
return 0LL;
}
分析完畢,腳本:
key1="Dufhbmf"
key2="pG`imos"
key3="ewUglpt"
flag=""
key4=[key1,key2,key3]
for i in range(12):
flag+=chr(ord(key4[i%3][(2*int(i/3))]) -1)
print(flag)
攻防世界EasyRE:(堆疊地址連續小字串變數、堆疊中過渡變數反序字串、/x7f截斷字串、運算子優先級注意)
64位ELF檔案,無殼,照例扔入IDA64中查看資訊,有Main函式就看main函式:(PS:下面被我注釋了一下內容,不過不影響)
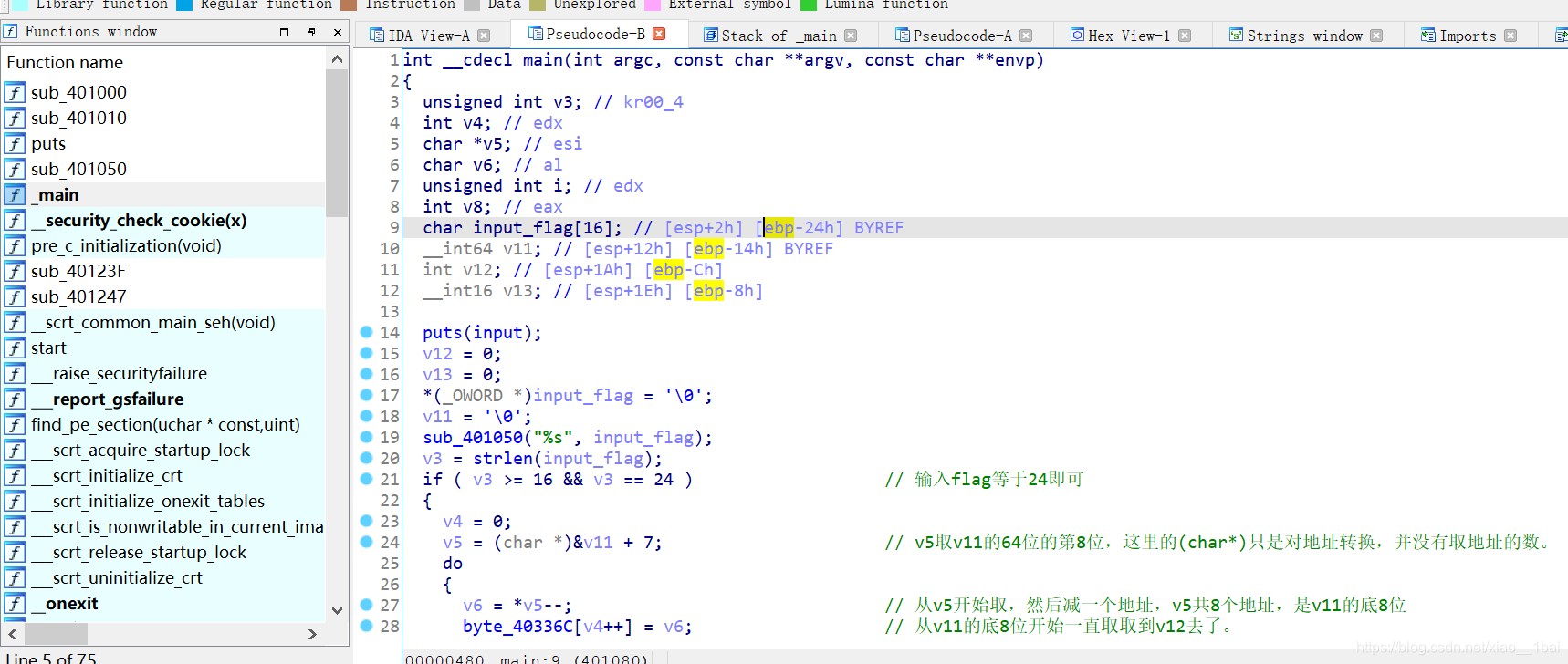
照例分析代碼:
puts(input); //這里名稱被我重命名過,判斷依據是程式運行時的Input字串在這里被參考,所以這里是輸出函式
v12 = 0;
v13 = 0;
*(_OWORD *)input_flag = '\0';
v11 = '\0';
sub_401050("%s", input_flag);
v3 = strlen(input_flag);
if ( v3 >= 16 && v3 == 24 ) // 這里兩個條件其實是多余的,輸入flag等于24即可
{
v4 = 0;
v5 = (char *)&v11 + 7; // v5取v11的64位地址下面的7位地址處,這里的(char*)只是對地址轉換,并沒有取地址的數,也就是說v5還是地址,而且是以char型別8位為單位的地址,而且后7位剛好是input_flag開始的24個位元組范圍的末尾,就是我們輸入24位元組flag的最后一個,(一個字符8位)
PS:這里之所以是v11地址的下面7位處是因為這是在main函式內的堆疊,堆疊是從下到上的(從高地址到底地址),堆疊變數都是從第一個分配地址往下劃分記憶體的,后面會再講~
do
{
v6 = *v5--; // 從v5開始取,然后減一個地址(一次減8位),v5現在是input_flag的起始地址開始的24位元組的末尾指標了,也就是指向用戶輸入字串的最后一個字符,這里回圈24次,符合前面我們輸入input_flag長度為24的判斷條件,
byte_40336C[v4++] = v6; //這里把v6的值也就是我們inpu_flag末尾位置的值開始,一個個賦值給v4開頭,這就造成了v4是我們輸入24位flag的反向字符,后續對v4陣列操作也是對用戶輸入的24字符flag的反向操作,
}
while ( v4 < 24 );
for ( i = 0; i < 24; ++i )
byte_40336C[i] = (byte_40336C[i] + 1) ^ 6;// 賦完值之后有對自身進行異或操作,進一步修改,注意這里是我們輸入的24位字符的反向陣列
v8 = strcmp(byte_40336C, aXircjR2twsv3pt); // 異或完后簡單的比較,aXircjR2twsv3pt雙擊跟蹤后一個被/x7f截斷的字串,前18位是xIrCj~<r|2tWsv3PtI,發現不滿足24位后再查看才發現后面還有,第19位是/x7f,20~24是zndka,這里留個心眼,/x7f可以阻斷字串
if ( v8 )
v8 = v8 < 0 ? -1 : 1;
if ( !v8 )
{
puts("right\n");
system("pause");
}
}
return 0;
}
分析完了,附上圖回顧一下以前犯錯的思路,給自己日后提個醒:
犯下第一個錯誤是對關鍵陣列地址修改的地方不敏感,一開始我只看到了對v4陣列異或的代碼,沒有注意到前面的反序操作:
for ( i = 0; i < 24; ++i )
byte_81336C[i] = (byte_81336C[i] + 1) ^ 6;
結果逆向邏輯出來后的flag是反的,大概長這樣:}NsDkw9sy3qPto4UqNx{galf,可能還是能看出來是反的flag,單要是換其他字串就不一定了,所以我們應該要注意前面還有對v4操作的代碼,也要分析:(分析在前面)
if ( v3 >= 16 && v3 == 24 )
{
v4 = 0;
v5 = (char *)&v11 + 7;
do
{
v6 = *v5--;
byte_81336C[v4++] = v6;
}
while ( v4 < 24 );
犯下第二個錯誤就是對堆疊不熟練,就是基于對前面v4陣列操作的分析,才發現這里有個堆疊操作讓v4陣列反向獲取用戶輸入的字串:
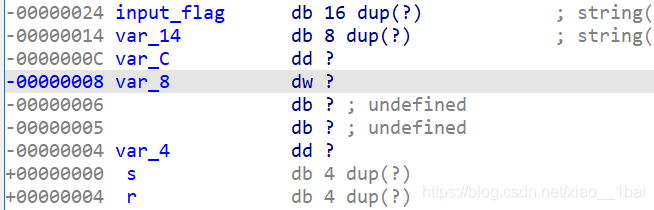
之前在IDA權威指南中了解過堆疊視圖,這里v11是var_14,input_flag就是我們輸入24位字串的首地址,這里給了一個混淆就是v11,前面v5 = (char *)&v11 + 7;就是在v11地址往下取7位char型別,就是0D地址了,剛好在var_C前面,
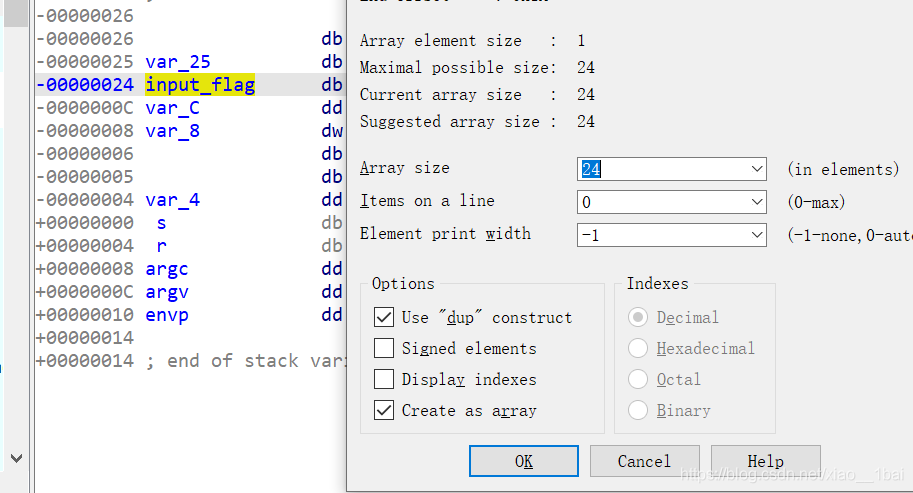
input_flag首地址24到var_C前面0D處就是完整的24位input_flag地址,所以v5就是取input_flag最后一個字符,這里v11的過渡作用混淆了我,我們可以直接在堆疊中把v11洗掉,改input_flag為24位字串,這里也就解釋了v4陣列取input_flag反向字符的原因了:
犯下第三個錯誤是在寫腳本中發現的,減號的優先級高于^符號:
下面腳本中 flag+=chr((ord(data[i]) ^ 6)-1) #要是寫成chr((ord(data[i]) ^ 6 - 1)那就GG了,由于優先級不同所以結果會不同,給的警示是最好什么都用括號括起來,畢竟這種優先級問題是很難發現的,還以為是自己邏輯梳理錯誤呢,
data="xIrCj~<r|2tWsv3PtI\x7Fzndka"
flag=""
for i in range(24):
flag+=chr((ord(data[i])^6)-1)
print(flag)
print(flag[::-1])
結果:
攻防世界re-for-50-plz-50:
32位ELF檔案,無殼,照例扔入IDA32中查看偽代碼,有main函式看main函式:(圖中有點注釋,不過不影響)
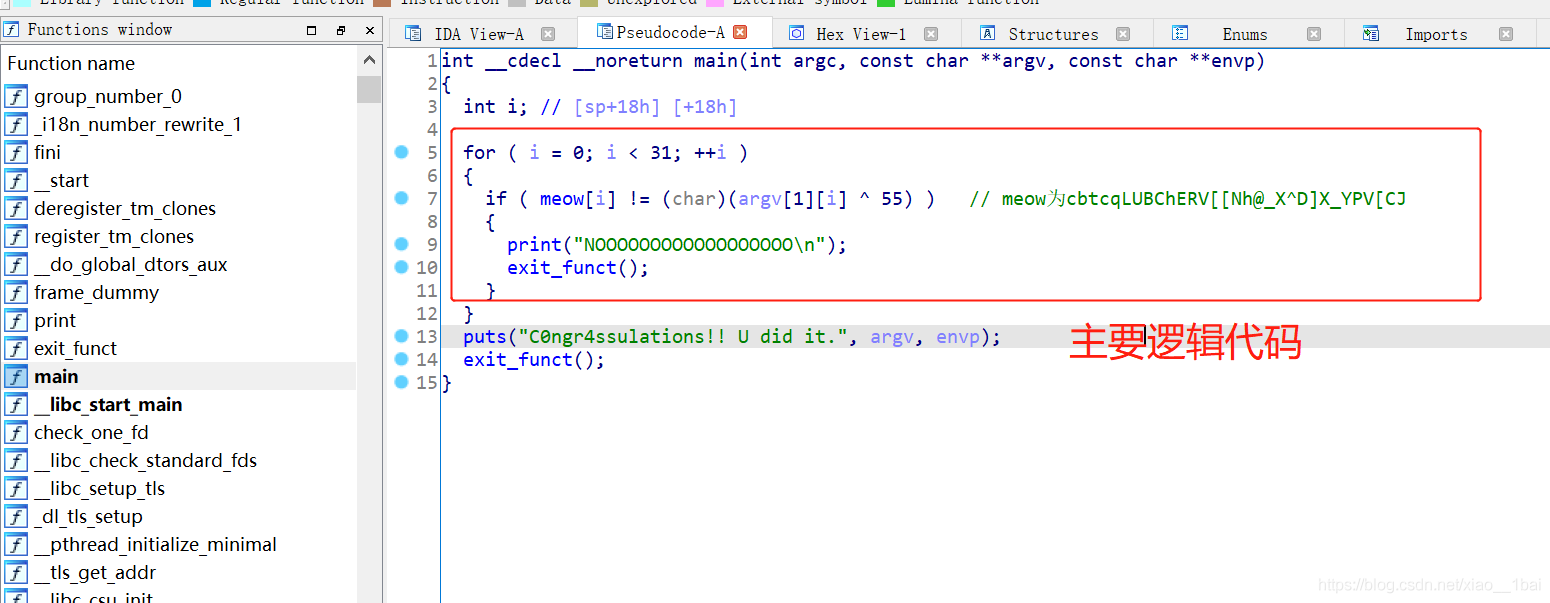
meow雙擊跟蹤是cbtcqLUBChERV[[Nh@_X^D]X_YPV[CJ ,右邊 argv[ 1 ][ i ]是命令列傳入的引數:(下面是我以前的筆記)
int main( int argc, char *argv[] ) :
(還可以寫成int main( int test_argc, char *test_argv[] ) )
呼叫時:
$./a.out testing1 testing2
應當指出的是,argv[0] 存盤程式的名稱,argv[1] 是一個指向第一個命令列引數的指標,*argv[n] 是最后一個引數,如果沒有提供任何引數,argc 將為 1,否則,如果傳遞了一個引數,argc 將被設定為 2,
所以邏輯很簡單,就是傳入引數后異或的值與本身存在的陣列比較,也就是說題目型別是與用戶輸入相關的非存盤型flag:
key1="cbtcqLUBChERV[[Nh@_X^D]X_YPV[CJ"
flag=""
for i in range(len(key1)):
flag+=chr(ord(key1[i])^55)
print(flag)
![]()
攻防世界IgniteMe:(函式邏輯封裝、大小寫字符轉換演算法)
32位windows檔案,無殼,照例扔入IDA32中查看偽代碼資訊,有Mian函式看Main:
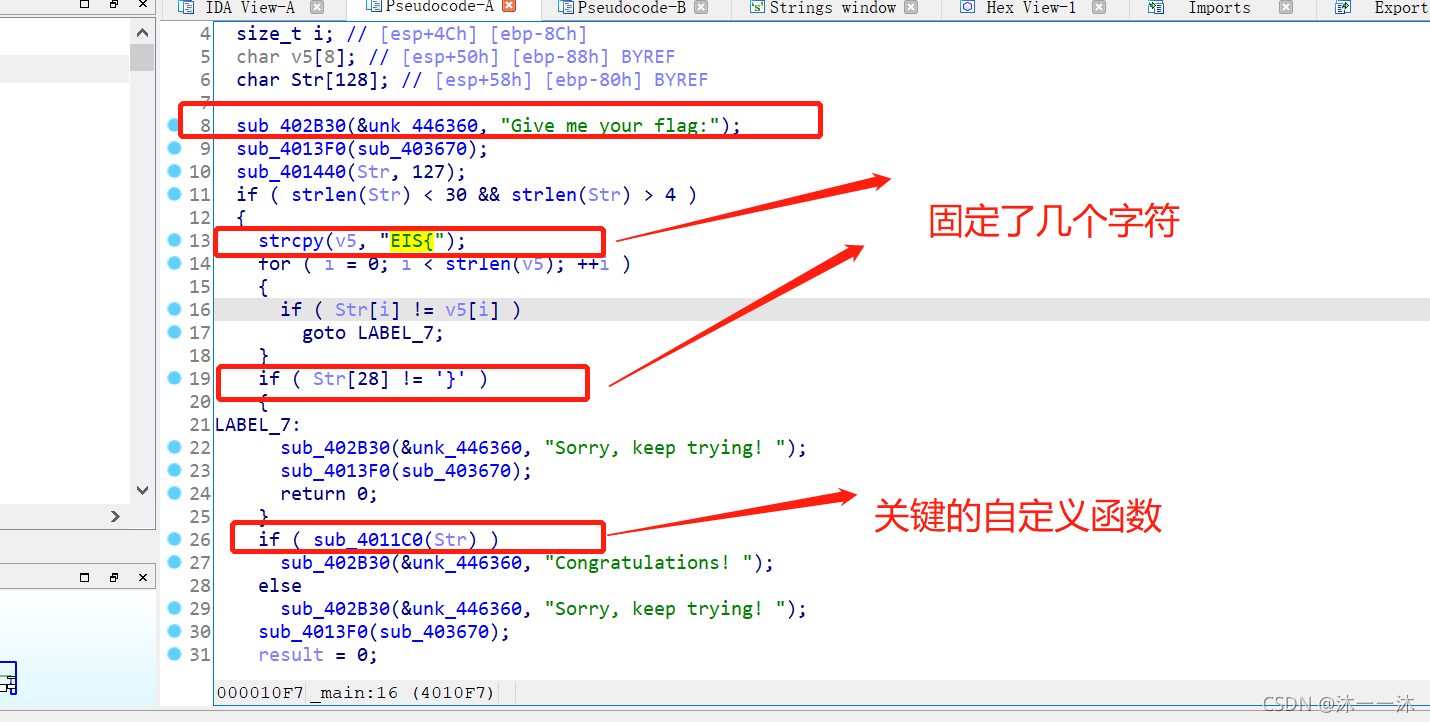
由初始資訊可以知道,前4個是EIS{ ,最后一個是 },判斷函式在 if 那里,雙擊跟蹤sub_4011C0(Str)函式:
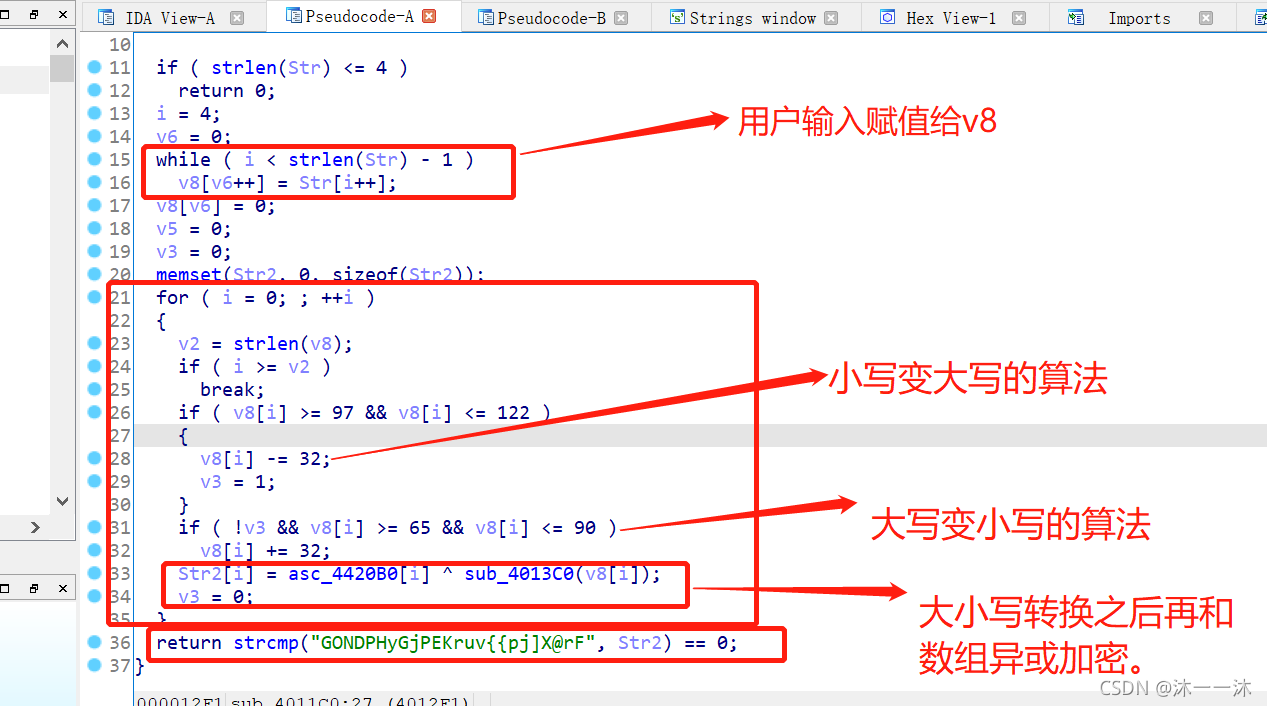
可以看到結果字串有了,是GONDPHyGjPEKruv{{pj]X@rF,逆向邏輯有了,是簡單的一次回圈加判斷,這里注意一下不帶花括號的判斷是只判斷緊接著的下一條陳述句而已,
最后這里Str2[i] = asc_4420B0[i] ^ sub_4013C0(v8[i]);用到了asc_4420B0[i]陣列來異或,在IDA中嵌入腳本列印一下:
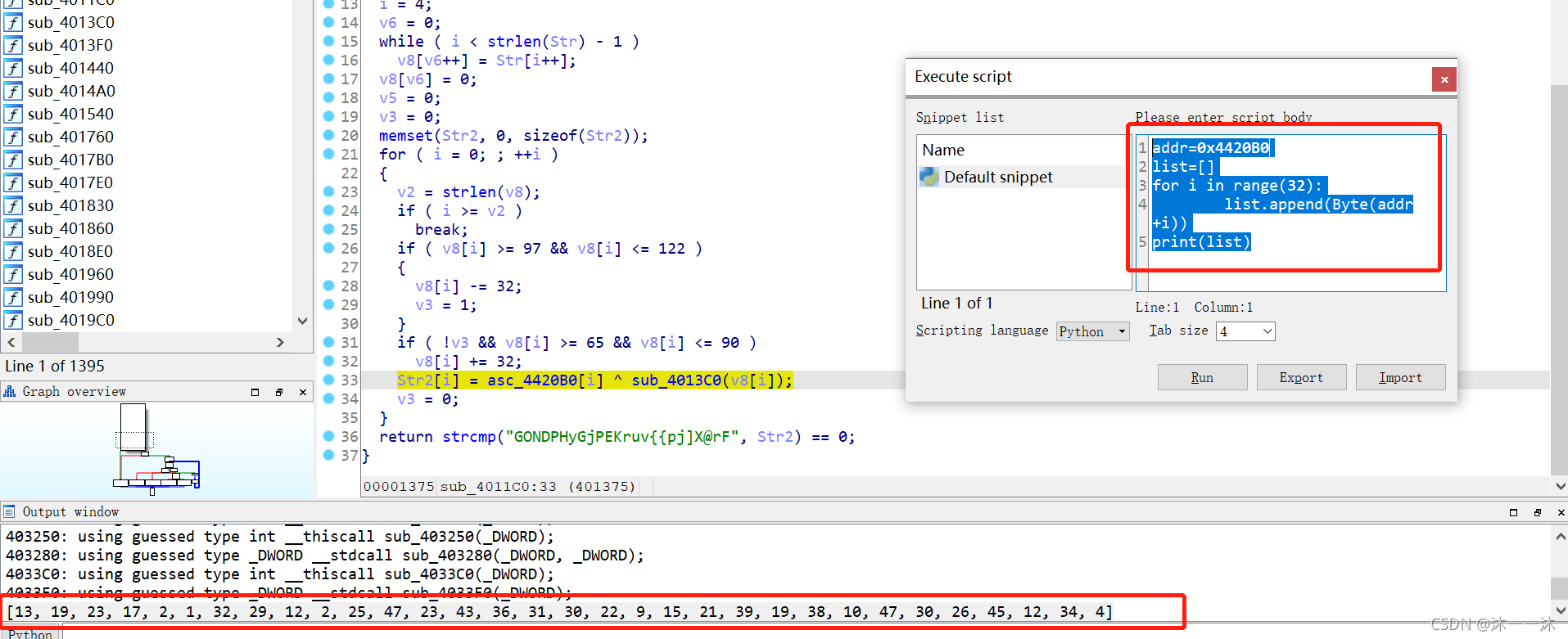
寫逆向邏輯腳本:
key1="GONDPHyGjPEKruv{{pj]X@rF"
list1=[13, 19, 23, 17, 2, 1, 32, 29, 12, 2, 25, 47, 23, 43, 36, 31, 30, 22, 9, 15, 21, 39, 19, 38, 10, 47, 30, 26, 45, 12, 34, 4]
flag=[]
v3=0
for i in range(len(key1)):
flag.append(((ord(key1[i])^list1[i])-72)^85)
if flag[i] >= 65 and flag[i] <= 90:
flag[i]+=32
elif flag[i] >= 97 and flag[i] <=122:
flag[i]-=32
print(''.join([chr(i) for i in flag]))
print(len(''.join([chr(i) for i in flag]))) #也可以用map(chr,flag)遞回裝換成字符
main函式與迷宮結合型別:
攻防世界maze:(高低位分割數、函式邏輯封裝、迷宮結合)
64位ELF檔案,無殼,先扔入IDA中查看偽代碼:
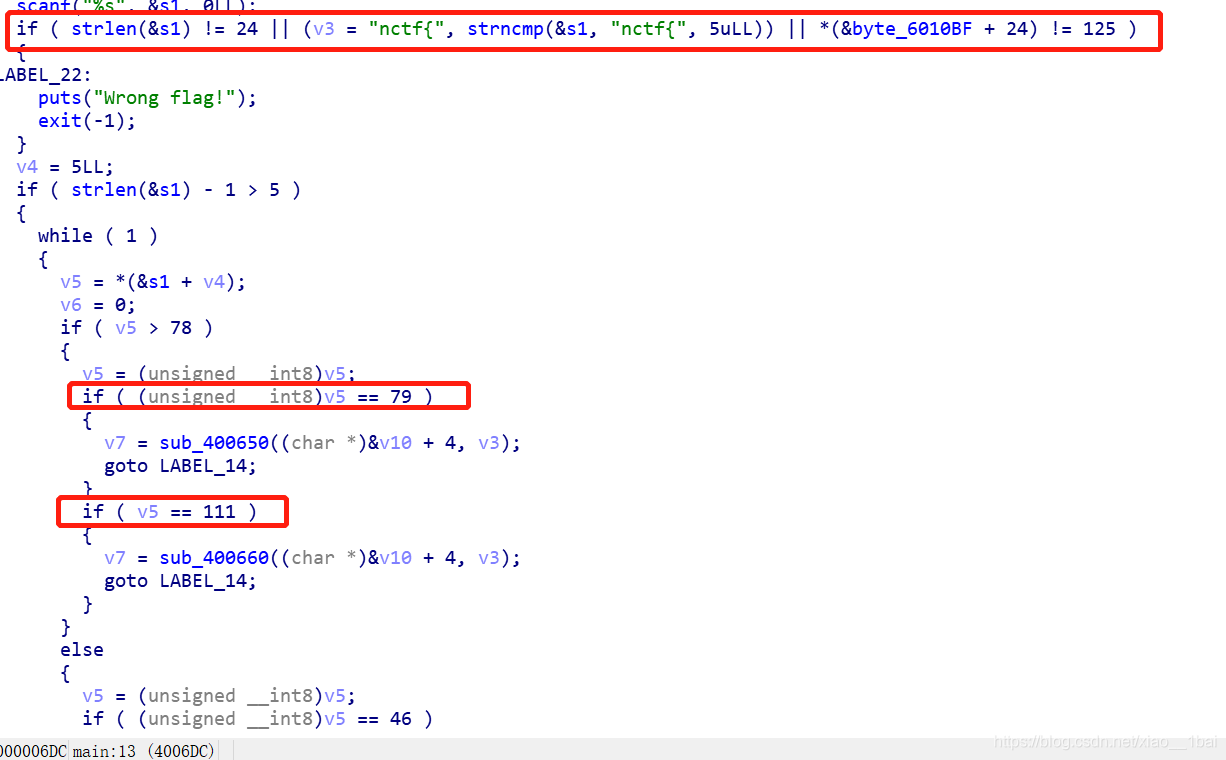
從這里犯下第一個錯誤,我竟然對第一個判斷陳述句的!=125的125不知所云,還去查了ASCII表,對后面的79,46這些竟然也想查,真的得給自己個一巴掌,flag基本都是字符和數字混合,而且在IDA里數字轉ASCII字符直接快捷鍵R啊!!!!
然后判斷題目型別是本身就有的存盤型flag還是用用戶輸入一個個生成的生成型flag,答案是后者,那gdb除錯就沒法用了,直接靜態分析代碼即可,
轉了字符后基本就明白了,現在開始代碼分析了:
puts("Input flag:");
scanf("%s", &input_flag, 0LL);
if ( strlen(&input_flag) != 24 || strncmp(&input_flag, "nctf{", 5uLL) || *(&byte_6010BF + 24) != '}' ) //這里要求輸入的flag是24個字符,且前5個和最后一個都確定了,一開始的125真的搞得我都不知道啥意思,后面的Oo.0也是如此
{
LABEL_22:
puts("Wrong flag!");
exit(-1);
}
v3 = 5LL;
if ( strlen(&input_flag) - 1 > 5 )
{
while ( 1 )
{
singleflag = *(&input_flag + v3); // 這里v3是從5開始遞增的數,目的是從第5個字符開始判斷是否符合下述條件
v5 = 0;
if ( singleflag > 78 ) //這里給個范圍,ASCII碼大于78的劃為第一類
{
singleflag = (unsigned __int8)singleflag;
if ( (unsigned __int8)singleflag == 'O' ) //如果第一個取O
{
v6 = sub_400650((_DWORD *)&v9 + 1); // 這里犯下第二個錯誤,64位的v9分成取高底32位元組其實是分到r14和r15兩個暫存器的,底32位在r14,高32位在r15才有后面根據暫存器的分開操作,因為在兩個不同暫存器中,
goto LABEL_14;
}
if ( singleflag == 'o' )//如果第一個取o
{
v6 = sub_400660((int *)&v9 + 1); // 有符號32位高位元組操作,r15暫存器,_DWORD就是int就是32位,
goto LABEL_14;
}
}
else
{
singleflag = (unsigned __int8)singleflag;
if ( (unsigned __int8)singleflag == '.' )//如果取到.
{
v6 = sub_400670(&v9); // 無符號底位元組32位操作,r14暫存器
goto LABEL_14;
}
if ( singleflag == '0' )
{
v6 = sub_400680((int *)&v9); // 有符號底位元組32位,r14暫存器
LABEL_14:
v5 = v6;
goto LABEL_15;
}
}
LABEL_15:
if ( !(unsigned __int8)sub_400690((__int64)asc_601060, SHIDWORD(v9), v9) )
goto LABEL_22;
if ( ++v3 >= strlen(&input_flag) - 1 ) //在flag范圍內v3加1,對應前面singleflag取第6、7、8~個一個個比較
{
if ( v5 ) //如果flag取完了,且sub_這些函式沒有回傳flase,也就是沒有越界,就可以判斷是否抵達終點了
break;
LABEL_20:
v7 = "Wrong flag!";
goto LABEL_21;
}
}
}
if ( asc_601060[8 * (signed int)v9 + SHIDWORD(v9)] != '#' ) //判斷是否為#這個終點,
goto LABEL_20;
v7 = "Congratulations!";
LABEL_21:
puts(v7);
return 0LL;
}
第二個錯誤看IDA反匯編結構圖,底雙字在r14暫存器,高雙字在r15暫存器:
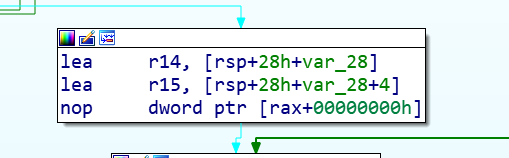
這里犯下的第三個錯誤就是對sub_400650、sub_400660、sub_400670、sub_400680、sub_400690、asc_601060、這些IDA自己命名的函式不敢去看!總是覺得自己看不懂,害怕!!!后來才發現其實不應該害怕的!!要逼自己一把!!!
bool __fastcall sub_400650(_DWORD *a1)
{
int v1; // eax
v1 = (*a1)--;
return v1 > 0;
}
bool __fastcall sub_400660(int *a1)
{
int v1; // eax
v1 = *a1 + 1;
*a1 = v1;
return v1 < 8;
}
bool __fastcall sub_400670(_DWORD *a1)
{
int v1; // eax
v1 = (*a1)--;
return v1 > 0;
}
bool __fastcall sub_400680(int *a1)
{
int v1; // eax
v1 = *a1 + 1;
*a1 = v1;
return v1 < 8;
}
這四個函式點開之后是對傳入引數+1 -1操作而已,真的不難,而且附帶回傳的比較后來查資料說是判斷有沒有越出迷宮邊界,false就是越出了,就不用玩了,為true就是沒越出,繼續玩,
(unsigned __int8)sub_400690((__int64)asc_601060, SHIDWORD(v9), v9) //主函式中的樣式
__int64 __fastcall sub_400690(__int64 a1, int a2, int a3) //雙擊后中的函式樣式
{
__int64 result; // rax
result = *(unsigned __int8 *)(a1 + a2 + 8LL * a3);
LOBYTE(result) = (_DWORD)result == ' ' || (_DWORD)result == '#';
return result;
}

這里sub_400690點進去分析后的(__int64)asc_601060如圖是一串字串,后來知道了是迷宮的圖,sub_400690函式里傳入v9的有符號高雙字r15暫存器,和v9底雙字的r14暫存器,然后運算運算式result = *(unsigned __int8 )(a1 + a2 + 8LL * a3); 就是在asc_601060字串陣列內取字符而已,
可以看出a3*8,所以這是8個字符為一行,也就是說r14暫存器的底雙字表示行,r15高雙字表示列,+1-1分別對應著向上向下,向左向右移動,(因為這里把2維的迷宮平鋪成1維了,所以向上向下走要變*8才行)
O是左移,o是右移,0是下移,.是上移
所以這里可以寫出asc_601060的迷宮圖形:
******
* * *
*** * **
** * **
* *# *
** *** *
** *
********
現在分析最后一段:
這里就是看最后跳出的flag末尾時是不是到了#這個字符,如果是就表示通關,
所以是:右下右右下下左下下下右右右右上上左左
就是o0oo00O000oooo…OO
main函式與游戲結合型別:
攻防世界gametime:(游戲通關生成flag、)
32位無殼,運行一下程式看看主要資訊:
說實話我一開始沒看懂怎么玩,所以扔入IDA32中查看偽代碼資訊,有main函式看Main函式:
哇,眼花繚亂,代碼太多了,
這里積累第一個經驗,游戲題一定要玩懂才行:
沒那么難玩的,如果游戲文字跳轉太快看不清,很難玩,就看著反匯編代碼來玩,用OD等動態除錯器在游戲結束時保持最后界面,以此來用最后結束時的界面資訊根據偽代碼判斷在哪里退出的,從而找到第一個判斷函式,
上OD動態除錯:
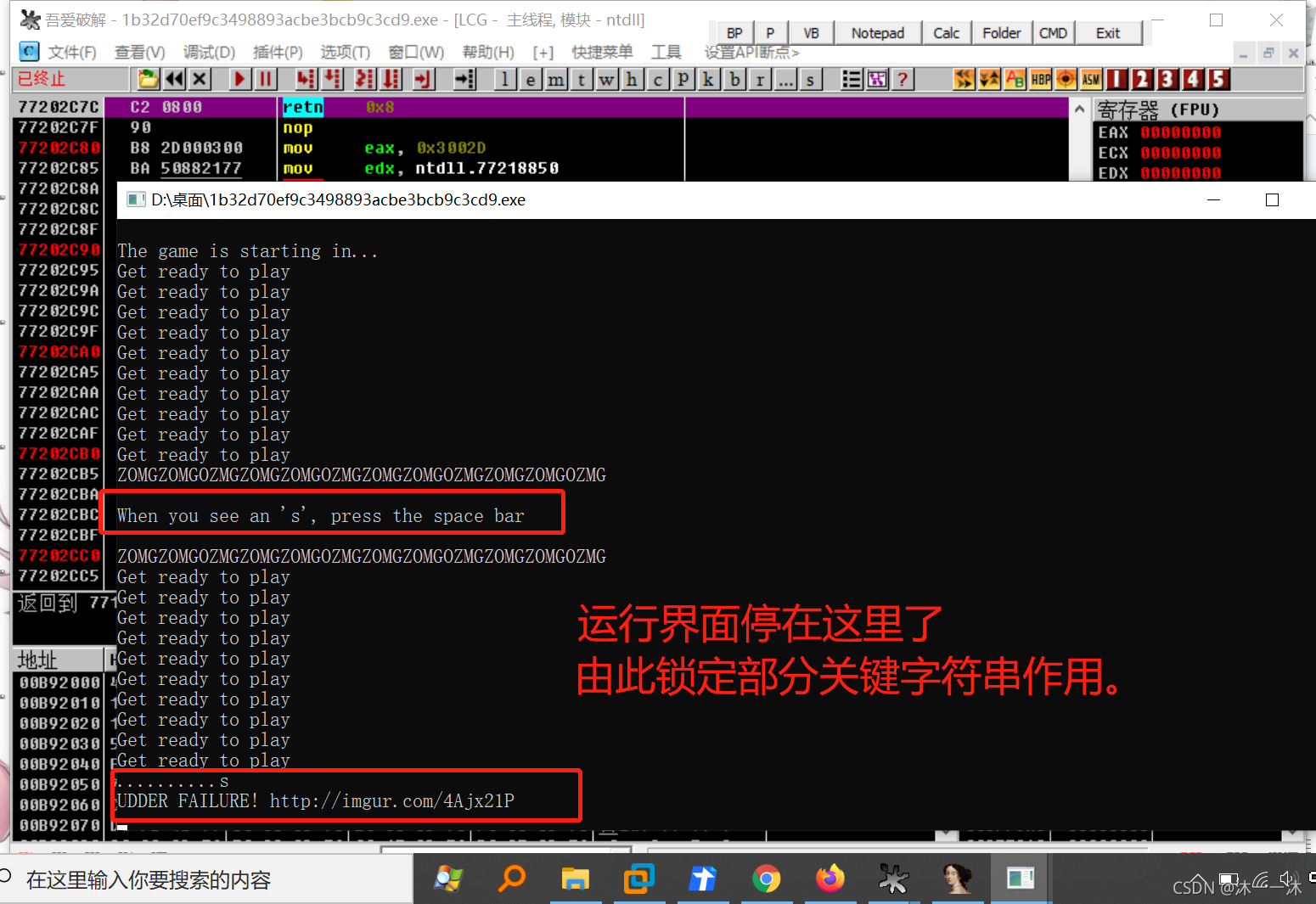
終于可以看清游戲規則了,出現s就按空格,不然就退出:(后面還有按x和m的),在IDA偽代碼中查看對應資訊:

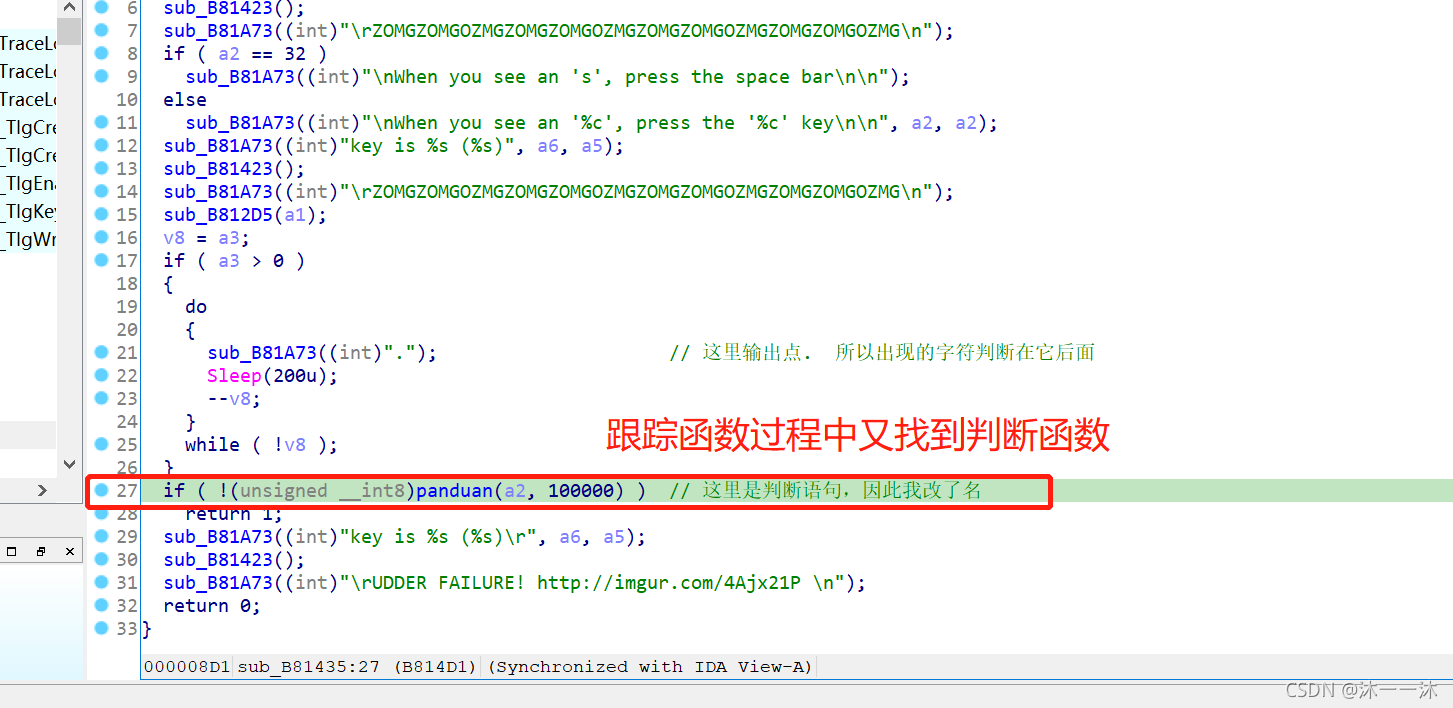
結合剛才結束界面的回顯資訊,進一步縮小了判斷函式的范圍,
然后這里積累第二個經驗:
游戲類題目,有些是存盤型flag,就是flag本來就在那里,你解出游戲就會顯示,而有一些是與用戶輸入相關的生成型flag,就是用戶通關的每一步影響著flag的生成,比如通一關給一部分flag這樣,
這道題明顯是后者,但是生成型flag中又要看輸入到底怎么影響flag生成,如果是那種以通關數生成flag的話,我們改一下判斷條件就可以全部通關了,但如果是那種通關的時候要靠用戶輸入字符,并考輸入的對應字符來生成甚至是加密后再生成一部分flag的話,這種題就要一個個找到對應的通關字符然后再逆向邏輯才行,
而這題比較簡單,是只判斷通關數即可生成flag,為什么我會知道呢,其實我猜的,(笑~) 所以我們用OD修改判斷條件即可,
看判斷函式的反匯編代碼:
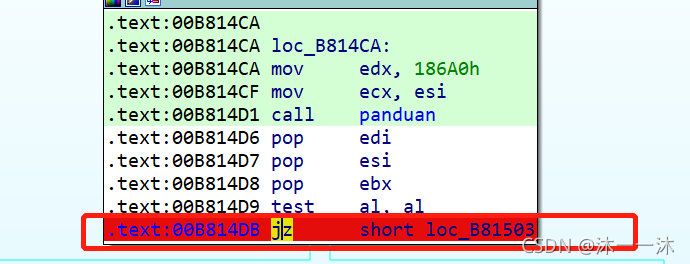
在OD中修改對應記憶體地址的反匯編代碼,你也可以直接用IDA修補反匯編代碼除錯:
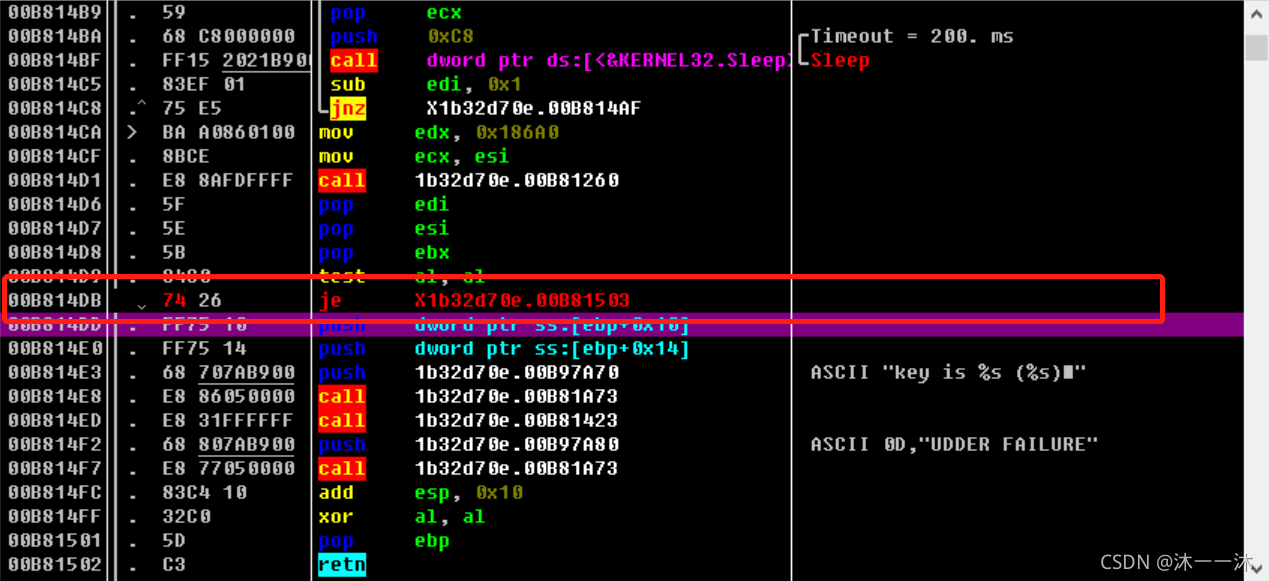
前面一切正常,因為但是后面出了問題:
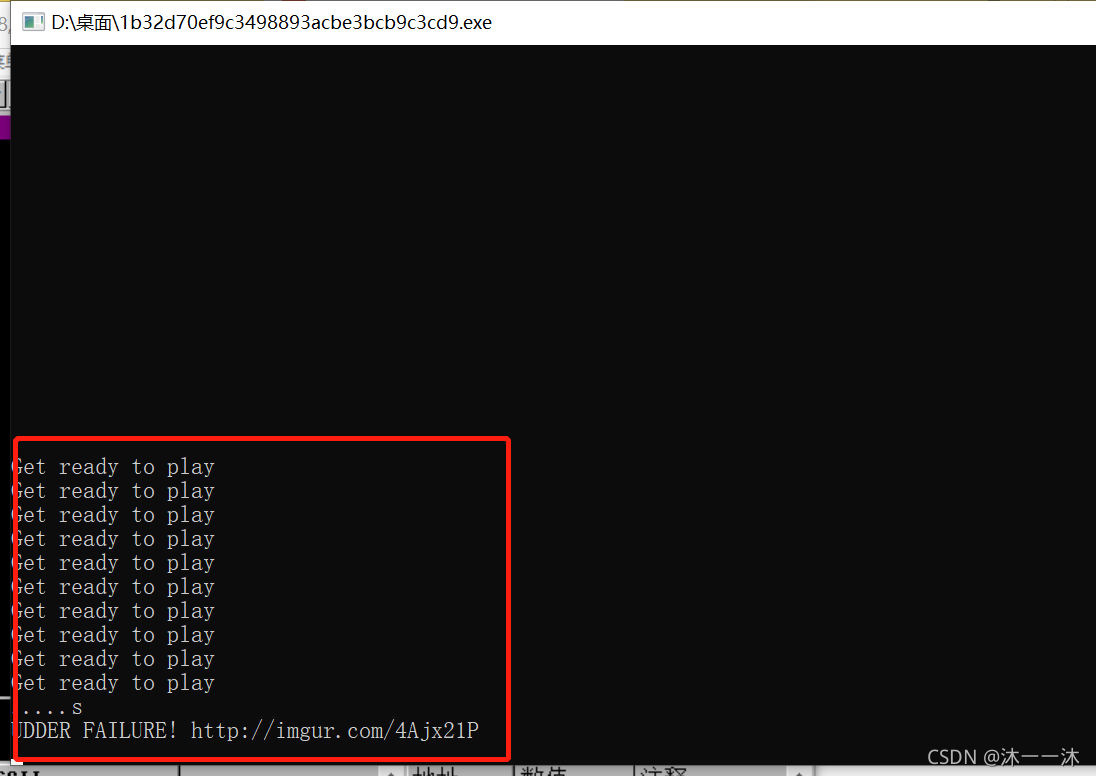
前面正常是因為下面三個都是同一個判斷函式:
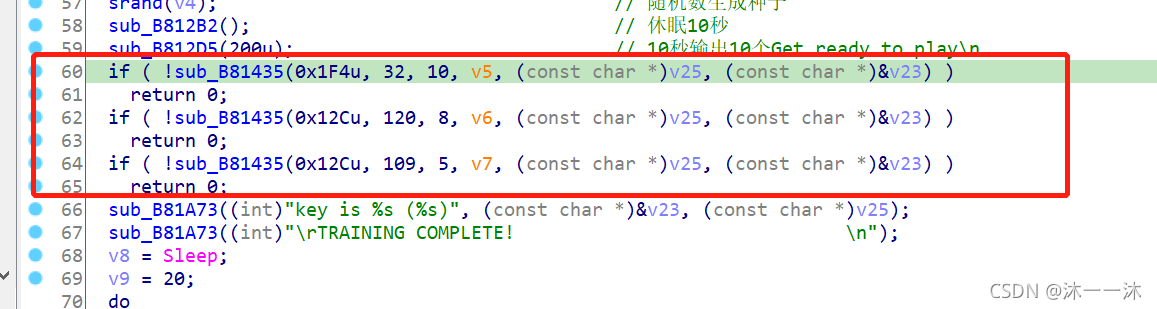
后面出錯就去后面找,發現還有三個判斷函式:
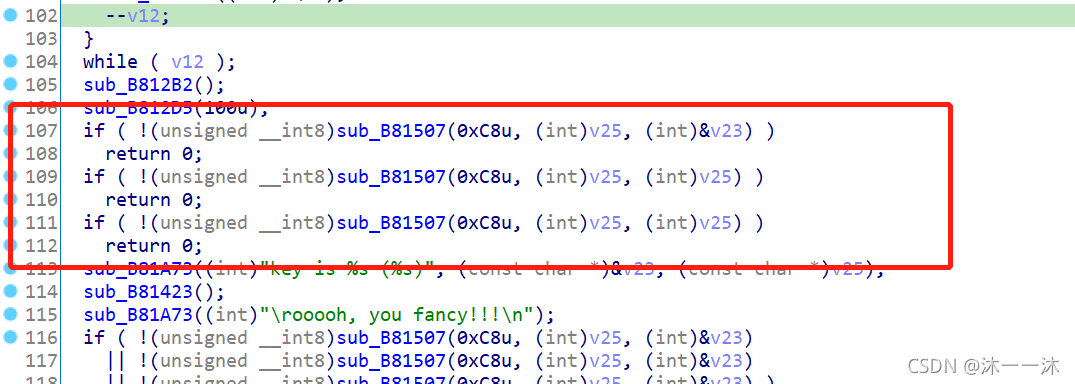
老樣子雙擊跟蹤找匯編代碼:
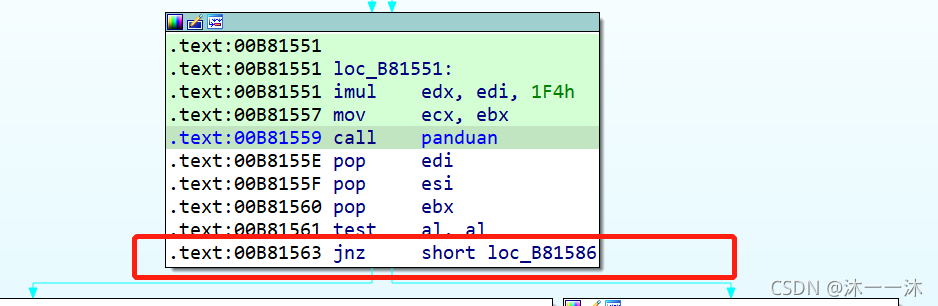
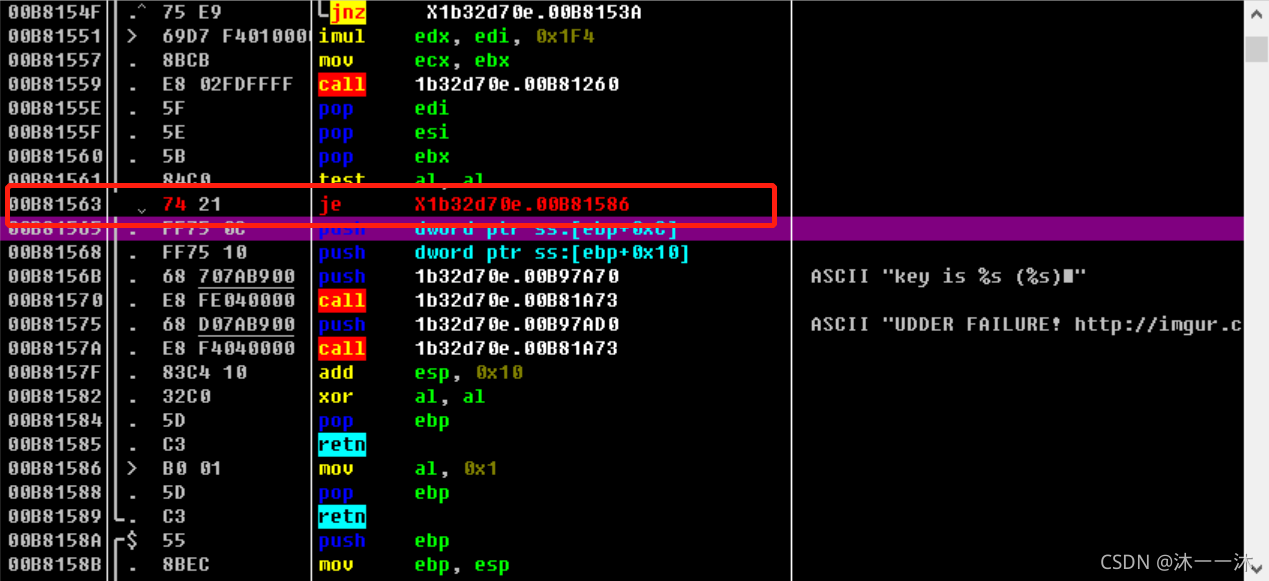
繼續運行程式,成功輸出:
main函式與數學演算法結合:
攻防世界notsequence:(楊輝三角演算法、函式邏輯封裝、IDA對char型(byte)的4*計數)
無殼,32位ELF檔案,照例扔入32位IDA中查看偽代碼,有Main函式看main函式:
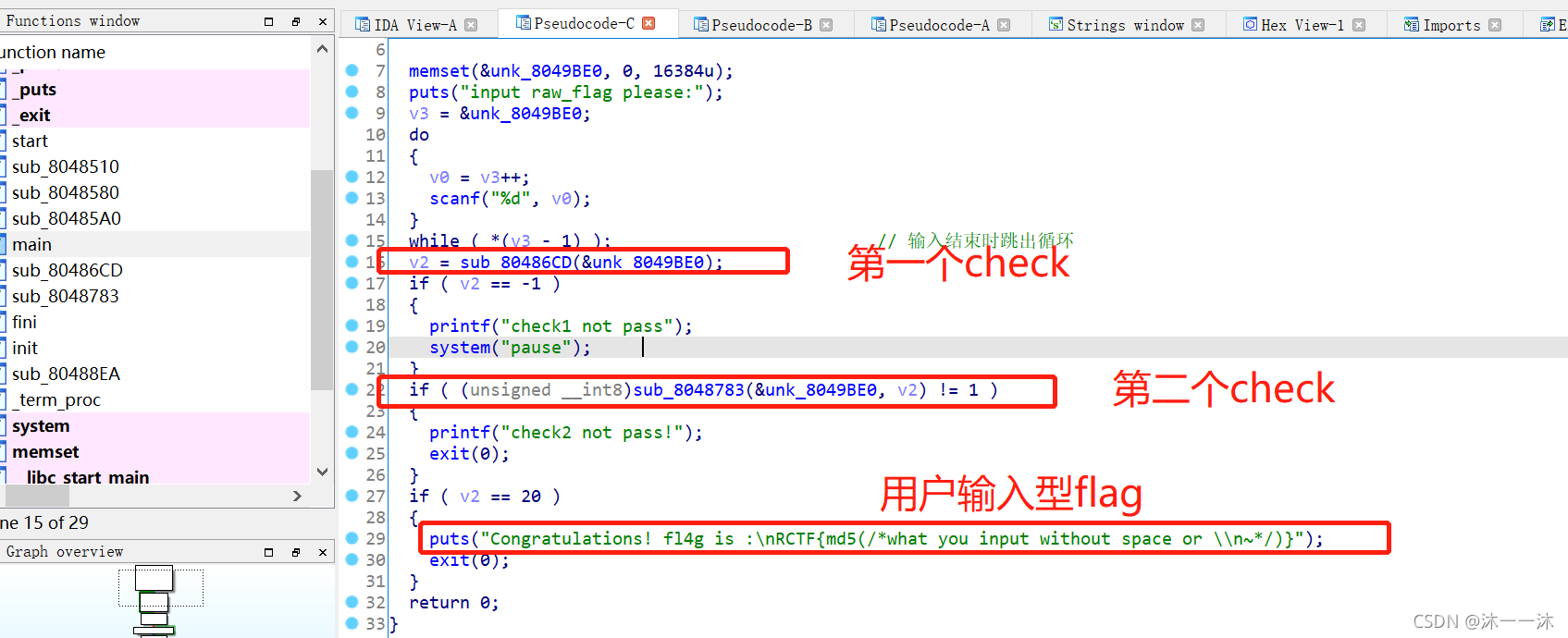
題型是與用戶輸入有關的生成型flag,邏輯是經過兩個check,分析第一個check函式v2 = sub_80486CD(&unk_8049B
E0):
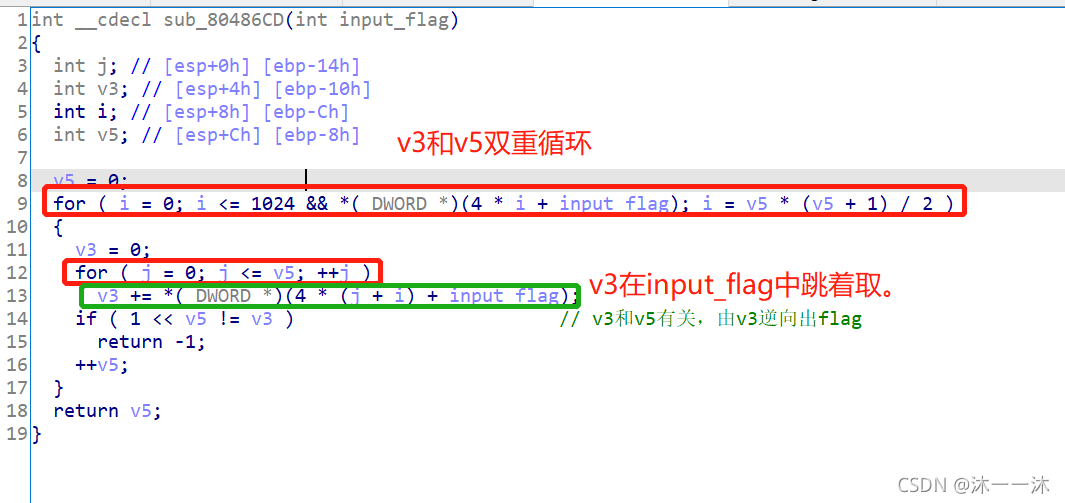
這里一開始我沒看懂,按照反向逆向邏輯來看雙重回圈的話我得知道v5的值,但是這里并沒有,所以我在主函式處發現了v2=20,但是又不確定v2在第二個check函式里有沒有改變過,結果是沒有,
所以v5=v2=20,有了v5的值就可以進行反向第一個check中雙層回圈中的 for ( j = 0; j <= v5; ++j )回圈了,

可是之后我還是逆向不了,我知道v3的個數和v5一樣,可是v3 += *(_DWORD *)(4 * (j + i) + input_flag)這句代碼標識v3是在input_flag中跳著取的啊,那這個邏輯逆向起來就相當麻煩了,我不會,(哭~)
查了資料才發現這是楊輝三角,演算法逆向題,沒辦法,只能跟著wp走了,并附上我自己的見解:
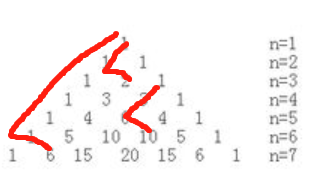
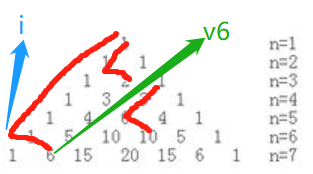
首先這里積累第一個經驗,附上楊輝三角決議:
[1] #0 /1 |2^0=1
[1, 1] #1 /2 |2^1=2
[1, 2, 1] #3 /3 |2^2=4
[1, 3, 3, 1] #6 /4 |2^3=8
[1, 4, 6, 4, 1] #10 /5 |2^4=16
[1, 5, 10, 10, 5, 1]
[1, 6, 15, 20, 15, 6, 1]
[1, 7, 21, 35, 35, 21, 7, 1]
[1, 8, 28, 56, 70, 56, 28, 8, 1]
[1, 9, 36, 84, 126, 126, 84, 36, 9, 1]
[1, 10, 45, 120, 210, 252, 210, 120, 45, 10, 1]
.
.
這樣來看楊輝三角第一批特征:(n是行號且從0開始)
(1)最左邊代表行號,0就是第0行,(行號從0開始)
(2)第1個字符在陣列(第一行到當前行組成的陣列)中的位置,#后的數字,(n*(n+1)/2,n是行號且從0開始)
(3)一行的有幾個數字 /后的內容,(n+1,n是行號從0開始)
(4)整行的和,|后的內容,是2的行號次方,(2^n,n是行號且從0開始)
.
.
.
.
這樣來看楊輝三角第二批特征:
第n行數字的和為2^(n) ,行號從0開始
1=2^(0-0), 1+1=2^(1-0), 1+2+1=2^(2-0), 1+3+3+1=2^(3-0) ,1+4+6+4+1=2^(4-0), 1+5+10+10+5+1=2^(5-0),
.
.
斜線上數字的和等于其向左(從左上方到右下方的斜線),拐角上的數字,(在圖中以用紅線標好)
1+1=2,1+1+1=3,1+1+1+1=4,1+2=3,1+2+3=6,1+2+3+4=10,1+3=4,1+3+6=10,1+4=5
接下來重新分析check1函式代碼:(考察楊輝三角第二批特性中的第n行數字和)
這段代碼check1函式的作用是檢測每一行求和結果是否為2^k(k從0開始),可以抽象成一個二維結構,有[k] 行(第一行k=0),每行開頭為第k*(k+1)/2個數,
int __cdecl sub_80486CD(int input_flag)
{
int j; // [esp+0h] [ebp-14h]
int v3; // [esp+4h] [ebp-10h]
int i; // [esp+8h] [ebp-Ch]
int v5; // [esp+Ch] [ebp-8h]
v5 = 0; //這里積累第二個經驗:通過v5的0、1、2、3……然后退出回圈中 i 運算式的前幾個值0、1、3、6、10……可以發現問題,因為這不是遍歷或者有規律的遍歷(每次檢查第四個),而且v5 * (v5 + 1) / 2 是等引數列的公式,結合前面的邏輯逆向麻煩性,由此要知道考的是演算法,
for ( i = 0; i <= 1024 && *(_DWORD *)(4 * i + input_flag); i = v5 * (v5 + 1) / 2 ) //等引數列公式 i,這里4*i應該只是為了迎合int型別,IDA可能默認i是char的byte型別了,
{
v3 = 0;
for ( j = 0; j <= v5; ++j ) //這里積累第三個經驗:在楊輝三角那里,每一行的數的總和等于2的以該行號的次方,行號從0開始算起,
v3 += *(_DWORD *)(4 * (j + i) + input_flag);
if ( 1 << v5 != v3 ) // 所以這里v5是行上數的個數,這里1 << v5就表示2的v5次方,就是2的行號次方(從0開始), v3 += *(_DWORD *)(4 * (j + i) + input_flag)中i是v5行前的楊輝三角的個數,因為我們是一維排列楊輝三角的,所以只能用(4 * (j + i)這種運算式來遍歷第v5行上的v5+1個數(楊輝三角行從0開始!),這里4*i應該只是為了迎合int型別,IDA可能默認i是char的byte型別了,
return -1;
++v5; //v5的0、1、2、3,是楊輝三角對應行上的個數,遞增數列,
}
return v5;
}
接著分析check2函式的代碼:(考察楊輝三角第二批特性中的斜線上的數字和)
int __cdecl sub_8048783(int input_flag, int k_20)
{
int v3; // [esp+10h] [ebp-10h]
int v4; // [esp+14h] [ebp-Ch]
int i; // [esp+18h] [ebp-8h]
int v6; // [esp+1Ch] [ebp-4h]
v6 = 0;
for ( i = 1; i < k_20; ++i ) //這里i總0、1、2……這樣連續遞增
{
v4 = 0;
v3 = i - 1; //這里v3從0、1、2、這樣連續遞增,
if ( !*(_DWORD *)(4 * i + input_flag) ) //這里4*i應該只是為了迎合int型別,IDA可能默認i是char的byte型別了,
return 0;
while ( k_20 - 1 > v3 )
{
v4 += *(_DWORD *)(4 * (v3 * (v3 + 1) / 2 + v6) + input_flag); //這里積累第四個經驗:這里等引數列運算式v3 * (v3 + 1) / 2前面說過了,是楊輝三角的第一批特征中第N行前面的個數,v6從0開始遞增,表示取楊輝三角v3行的v6列的值,而在這個回圈中v3是變換的,也就是取得楊輝三角的行是變化的,而v6在此一個該回圈中是固定的,所以可以看成是取每一行(v3)的同一個列(v6)
++v3;
}
if ( *(_DWORD *)(4 * (v3 * (v3 + 1) / 2 + i) + input_flag) != v4 ) //這里由于前面回圈++v3后表明行號向下了一行,而 i 從1開始,v6從0開始,所以 i 永遠比 v6大1,v6 比 i 多一列,所以這里可以看作[0]-[k-1]行的 [v6] 列求和等于[k]行的 [i]
return 0;
++v6;
}
return 1;
}
所以答案很明顯了,是楊輝三角的前20行就是答案,這里積累第5個經驗,寫楊輝三角生成腳本:(代碼標注很詳細了,希望對自己日后有幫助!)
def triangles():
s=[1] #這里s[1]作為楊輝三角函式起始值
while True: #無限回圈生成楊輝三角
yield s #每次回傳一行的楊輝三角串列
s.append(0) #給楊輝三角下一列擴充一個數的空間,因為每一行比上一行多1個
s=[s[i-1]+s[i] for i in range(len(s))] #覆寫生成楊輝三角行串列,滿足楊輝三角的下一行的第n個數等于上一行的第n和n-1的和
n=0 #設定計數器,因為只列印前20行
flag=''
for i in triangles(): #每次獲取從triangels函式的yield回傳的一行串列
#print(i) #列印每一行楊輝三角
flag+=''.join(map(str,i)) #回傳通過指定字符連接序列中元素后生成的新字串,以str為間隔,默認為逗號,而串列就是逗號間隔的
n+=1
if n==20:
break
import hashlib
flag=hashlib.md5(flag.encode()).hexdigest() #這里把flag的串列流變成了位元組流,就去掉了串列保留了每個元素了,然后直接加密
print("RCTF{"+flag+"}")
結果:

main函式中嵌入大量冗余代碼,拆分代碼混淆:
攻防世界Newbie_calculations:(非預期行為、不能直接運行、題目描述暗示、堆疊地址連續小陣列、c語言寫腳本、不同系統的特殊數、負數作回圈條件)
32位無殼,照例扔入IDA32中查看資訊:
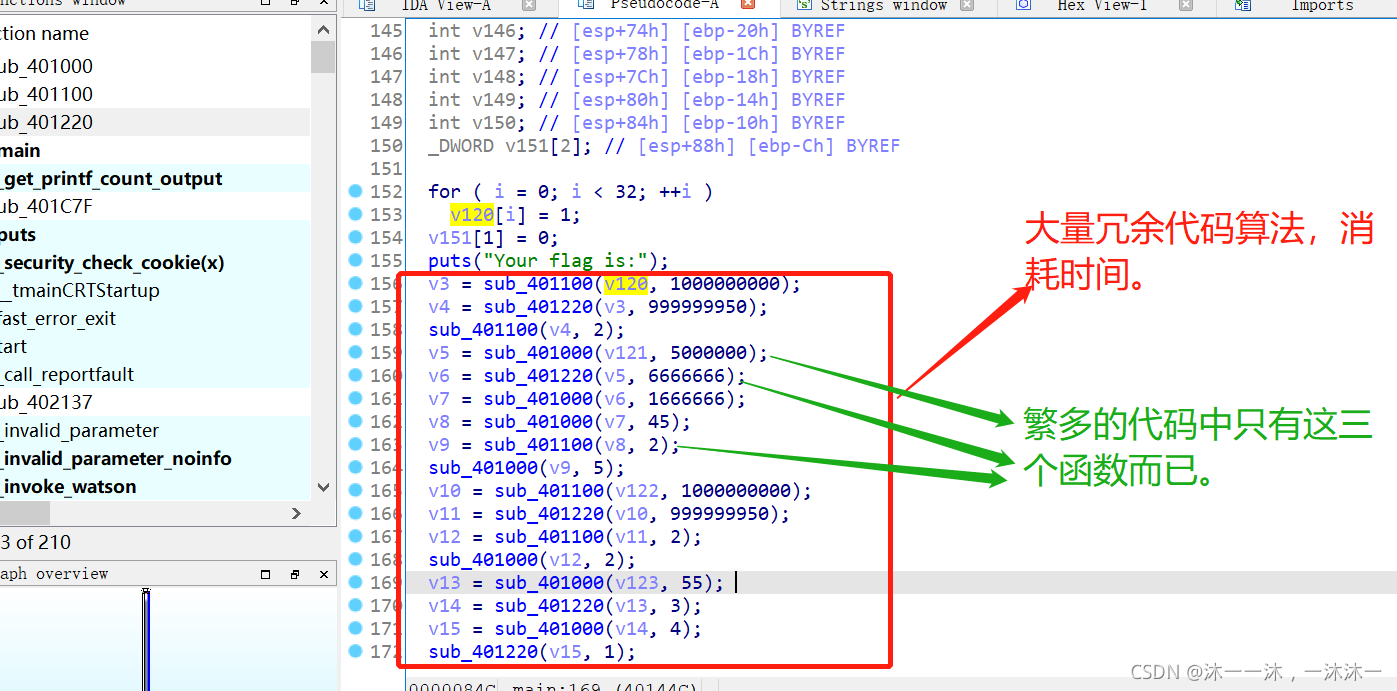
浮上眼前的是一堆自定義函式,而且數量很多,嚇傻了,快速瀏覽并隨便點進函式看來一下,函式代碼還多,以為是混淆,但是又想不出是什么混淆,
運行程式看一下:
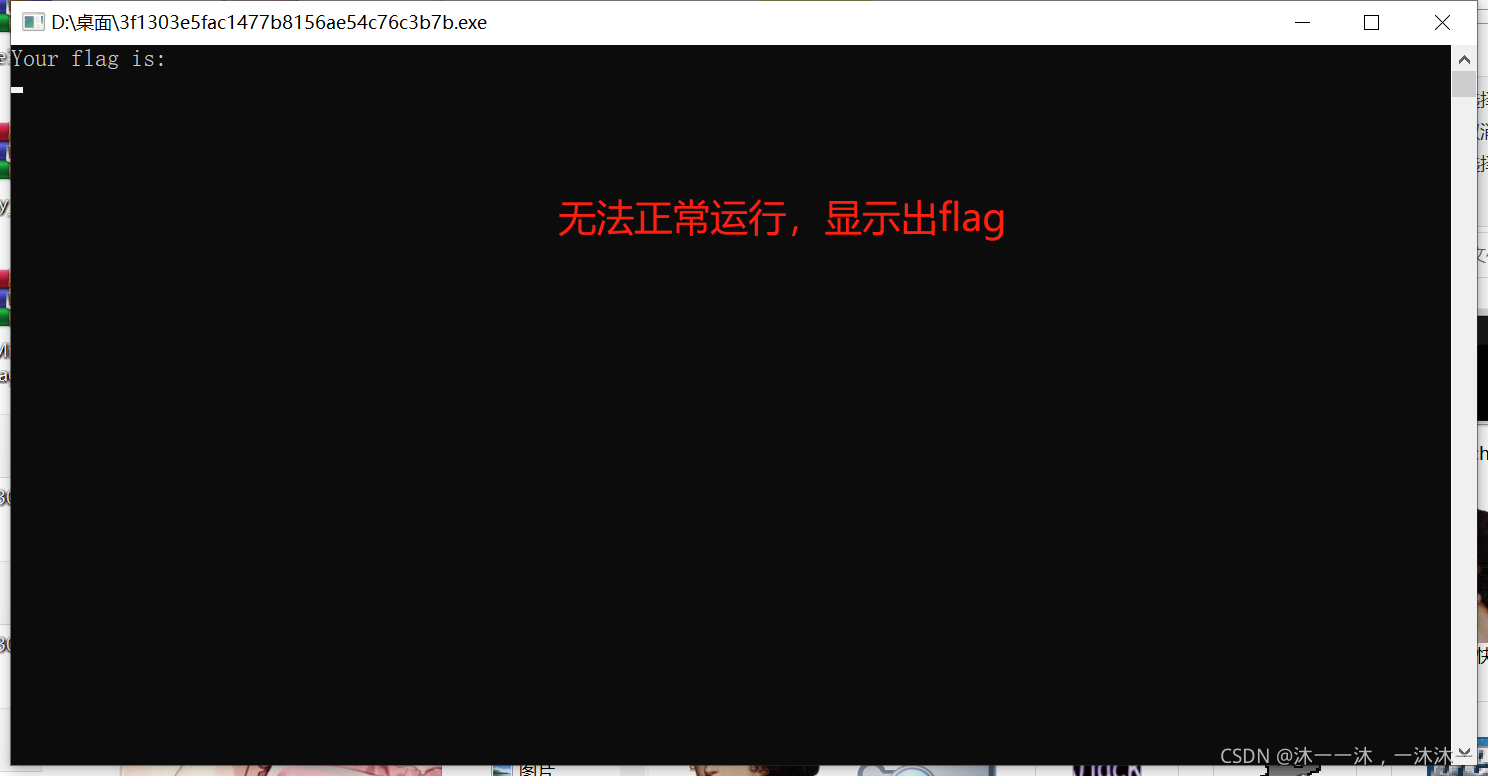
輸入也輸入不了,還以為是程式的什么限制,更慌了,后來查了資料才決定定下心來好好分析,
首先回顧一下以前積累的經驗:
復雜代碼本質應該是簡潔的,這樣才叫出題,
仔細一看,發現繁多的代碼結果只有三個函式,sub_401100函式、sub_401000函式、sub_401220函式,
加上運行程式時輸入不了不是因為程式有問題,每一個意料之外的事情都有它存在的道理和程序,不要總是懷疑題目本身,繁多的代碼和巨大的數字大概率是有很多沒用的冗余代碼占用了程式運行的時間,才導致沒有游標可以輸入,
最后一行代碼應該就是前面運行完后輸出的flag:
該偽代碼中沒有輸入,時間到了就會輸出flag,但是要修改前面的無用代碼,題目是Newbie_calculations,這種題目暗示要注意,表示往運算方面去想函式,
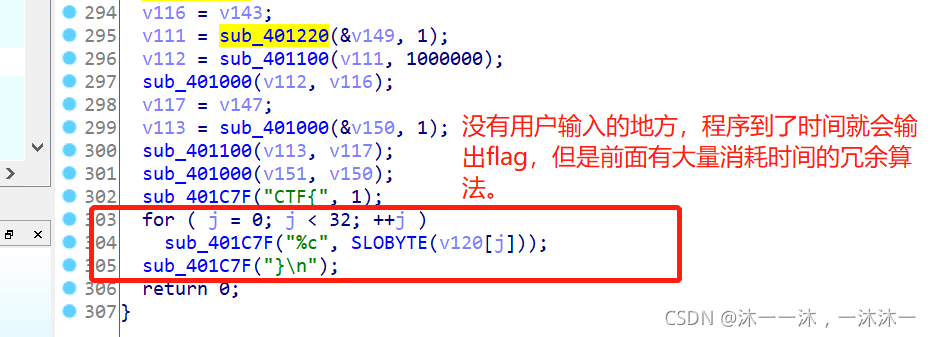
現在開始重新分析,從最開頭的顯示字串開始:

分析第一個sub_401100函式:(這里傳入引數被我改名了,簡單的傳入引數相乘)
_DWORD *__cdecl sub_401100(_DWORD *v120, int _1000000000) //回傳v120,故只看對v120的操作
{
int v3; // [esp+Ch] [ebp-1Ch]
int v4; // [esp+14h] [ebp-14h]
int v5; // [esp+18h] [ebp-10h]
int v6; // [esp+18h] [ebp-10h]
int v7; // [esp+1Ch] [ebp-Ch]
int v8; // [esp+20h] [ebp-8h] BYREF
v4 = *v120;
v5 = _1000000000;
v3 = -1;
v8 = 0;
v7 = _1000000000 * v4;
while ( _1000000000 ) //這里積累第一個經驗:雖然這里回圈1000000000次,但是程式回傳的是v120,這里有很多和v120沒有關系的其它變數,是用來混淆的,找與v120有關的才是關鍵,
{
v6 = v7 * v4;
sub_401000(&v8, *v120); //由下面代碼知道這是一個相加函式,初始值v8=0,回圈1000000000次就是1000000000個v120相加,就是v120 * 1000000000 ,就是傳入引數a1*a2結果賦值給第一個引數a1,
++v7;
--_1000000000; //其它的與v120無關的不用看它
v5 = v6 - 1;
}
while ( v3 ) //這里v3=-1,負數回圈,這里本來要回圈FFFFFFFF,就是100000000 - 1次的,但是后面有*v120=v8的賦值操作,所以這部分也是冗余混淆代碼,
{
++v7;
++*v120;
--v3;
--v5;
}
++*v120;
*v120 = v8; //這里最后是賦值v8給v120,所以while(v3)回圈根本不用管,前面說過這些和v120沒有關系的變數是用來混淆的,不用管,
return v120;
}
分析第二個函式 sub_401000,這也是上面的嵌套函式:(簡單的傳入引數相加)
_DWORD *__cdecl sub_401000(_DWORD *a1, int a2) //回傳a1,故只看對a1的操作
{
int v3; // [esp+Ch] [ebp-18h]
int v4; // [esp+10h] [ebp-14h]
int v5; // [esp+18h] [ebp-Ch]
int v6; // [esp+1Ch] [ebp-8h]
v4 = -1;
v3 = -1 - a2 + 1; //v3=-a2
v6 = 1231;
v5 = a2 + 1231;
while ( v3 ) //這里積累第二個經驗:負數做回圈條件的知識,v3=-a2,然后在回圈體里又--v3,一開始我也以為是死回圈,因為0才是false,但是查了資料后說在32位里 -1 就是 FFFFFFFF,就是100000000 - 1,所以這一下子就轉正了!所以如果while(-1)就回圈100000000 - 1次,這里while(-a2),所以就回圈100000000 - a2次,
{
++v6;
--*a1; //同樣的回傳a1我們只關注a1即可,這個回圈100000000 - a2次,每次a1-1,所以a1變成a1=a1-(100000000 - a2)
--v3;
--v5;
}
while ( v4 ) //這里while(-1)回圈100000000 - 1次
{
--v5;
++*a1; //這里加上上面的回圈變成a1=a1-(100000000 - a2) + (100000000 - 1) = a1+a2-1
--v4;
}
++*a1; //這里+1,最后結果就變成a1=a1+a2-1+1=a1+a2
return a1; //所以這個函式的作用就是a1=a1+a2,就是把傳入的兩個引數相加,結果賦值給第一個引數
}
分析最后一個函式sub_401220函式:(簡單的傳入引數相加)
_DWORD *__cdecl sub_401220(_DWORD *a1, int a2) //回傳a1,故只看對a1的操作
{
int v3; // [esp+8h] [ebp-10h]
int v4; // [esp+Ch] [ebp-Ch]
int v5; // [esp+14h] [ebp-4h]
int v6; // [esp+14h] [ebp-4h]
v4 = -1;
v3 = -1 - a2 + 1;
v5 = -1;
while ( v3 ) //前面說過這里負數回圈100000000 - a2次
{
++*a1; //所以這里a1=a1+100000000 - a2
--v3;
--v5;
}
v6 = v5 * v5;
while ( v4 ) //這里負數回圈100000000 - 1次
{
v6 *= 123;
++*a1; //這里a1=a1+100000000 - a2+100000000 - 1
--v4;
}
++*a1; //這里a1=a1+100000000 - a2+100000000 - 1+1,這里積累第三個經驗,在32位系統中100000000就是0了,所以上面要寫成a1=a1-a2,所以在運算題型中,程式的系統位數也是關鍵內容
return a1; //所以這個函式就是簡單的引數相減操作a1-a2,結果賦值給第一個引數
}
那么到這里已經理清程式了,三個函式都可以提取成簡單的相乘、相減、相加操作,然后就修改程式了:
第一種手動計算寫python腳本:
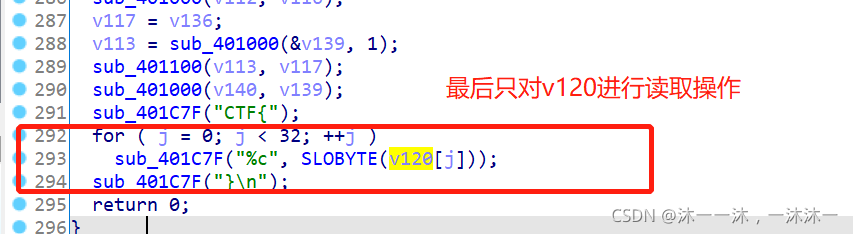
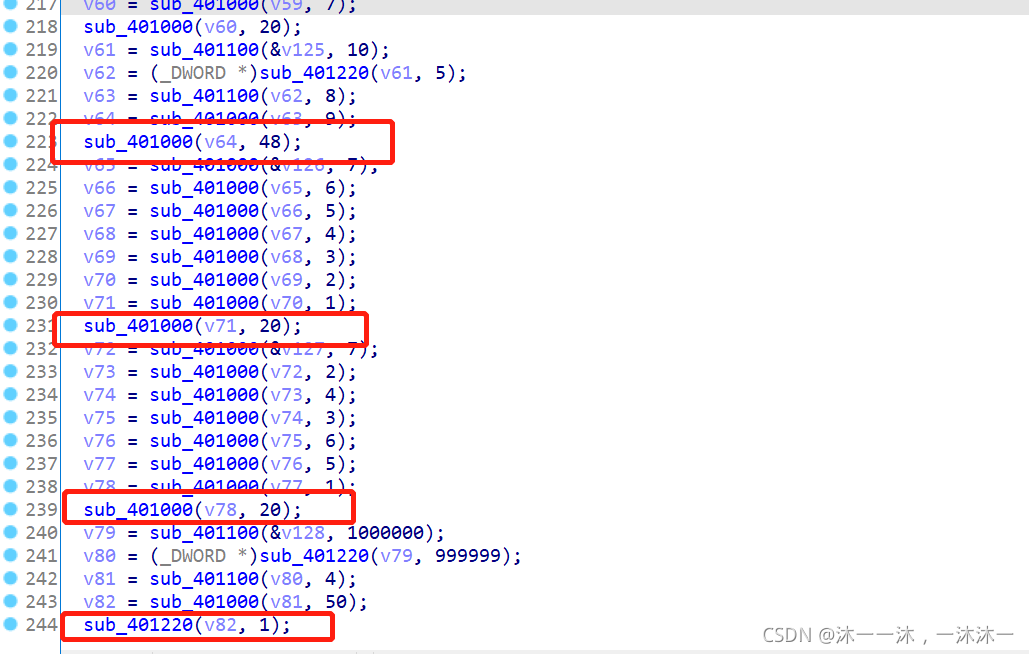
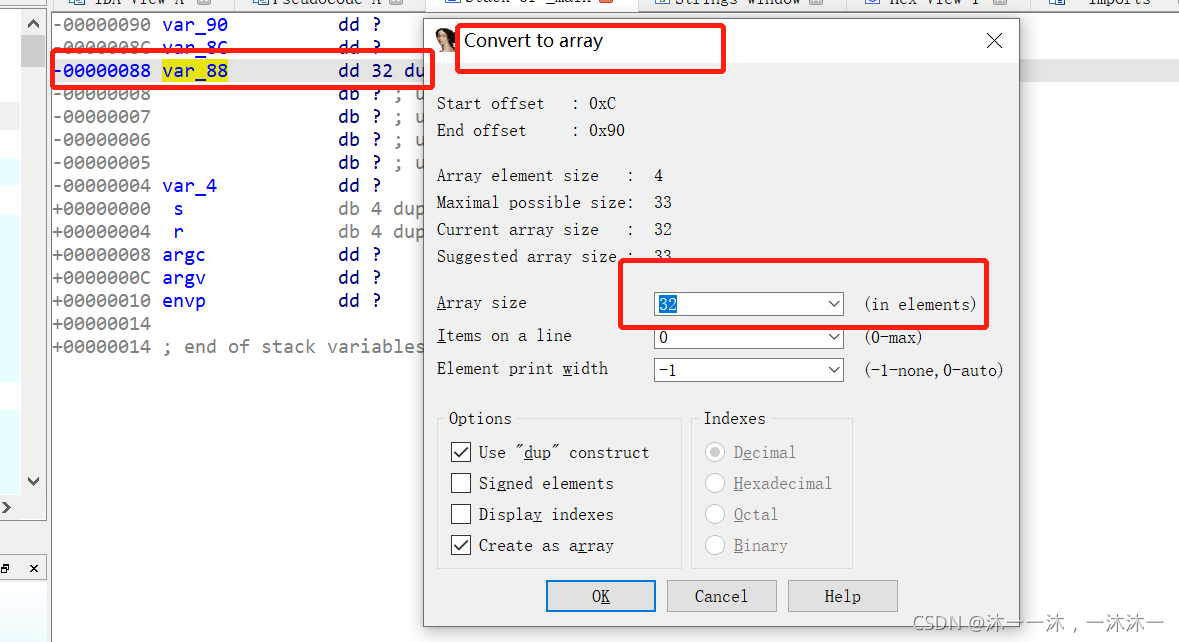
這里積累第4個經驗,IDA反匯編代碼中可能把一個連續的陣列拆成好多個變數,這些變數在函式堆疊中是連續的,但是后面整理陣列時你很難發現和很難梳理他們是不是同一個陣列的內容,此時應該在IDA函式堆疊中修改變數陣列大小為它真正的陣列大小,
舉個例子,下面明明是列印v120[32]陣列的:
可是IDA變數卻只給了V120[12]陣列和一堆其它變數,就是它把陣列拆分了:

導致的后果就是后面的代碼因為用的是連續變數代替陣列下標,所以很難理解哪個變數對應哪個下標:(變數的間隔還不同!)
所以我們要在IDA堆疊中修改v120[12]為v120[32]:
這樣修改之后就好看多了,不過手動計算好像還是很麻煩,算了,不手動計算了,(笑~)
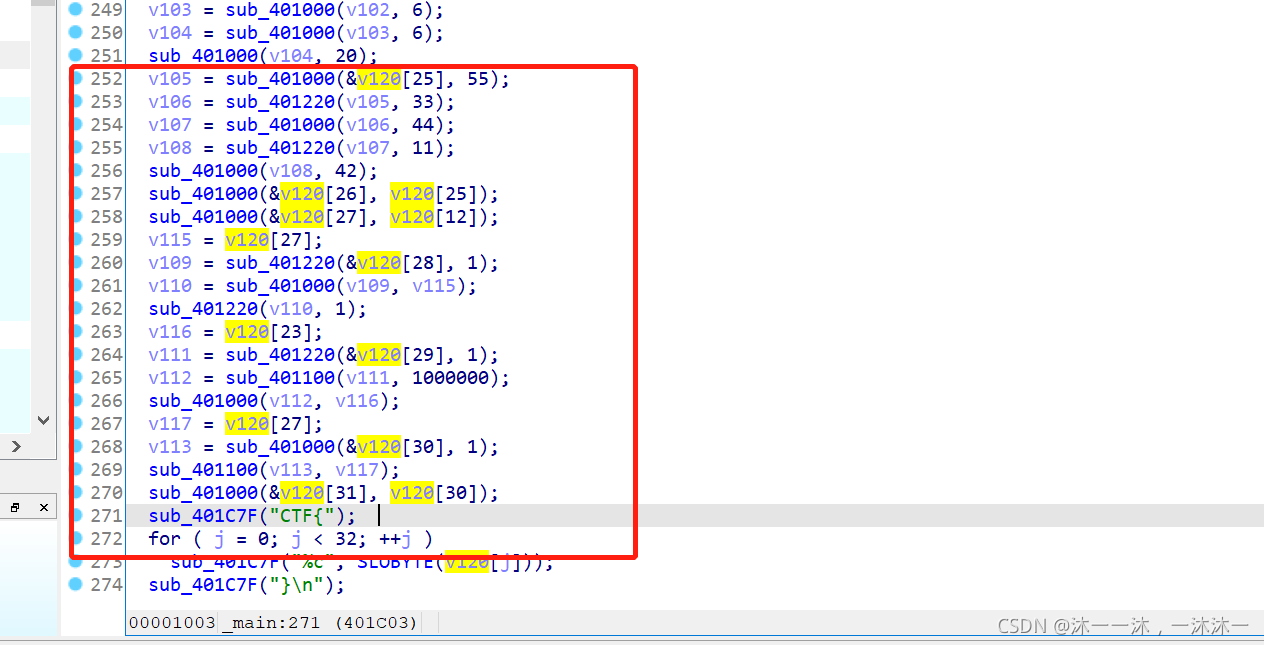
第二種方法:直接復制到C語言中修改代碼
直接復制到C語言中修改代碼吧,很簡單的,首先修改_Dword為int,然后把三個函式都改個函式名,列印函式換成Printf就好啦!
(注意!這里如果沒有像前面那樣修改堆疊v120[32]數字的話,多個拆分變數在dev中就會造成變數之間的空間不連續,不連續就沒法作為一個連續陣列輸出了,就會輸出個四不像出來,):
#include<iostream>
using namespace std;
int *first(int *a1,int a2) //函式題要在Main函式外宣告,回傳型別是指標,所以int *做回傳型別,
{
*a1=*a1*a2;
return a1;
}
int *second(int *a1,int a2)
{
*a1=*a1-a2;
return a1;
}
int *third(int *a1,int a2)
{
*a1=*a1+a2;
return a1;
}
int main(int argc, const char **argv, const char **envp)
{
int *v3; // eax
int *v4; // eax
int *v5; // eax
int *v6; // eax
int *v7; // eax
int *v8; // eax
int *v9; // eax
int *v10; // eax
int *v11; // eax
int *v12; // eax
int *v13; // eax
int *v14; // eax
int *v15; // eax
int *v16; // eax
int *v17; // eax
int *v18; // eax
int *v19; // eax
int *v20; // eax
int *v21; // eax
int *v22; // eax
int *v23; // eax
int *v24; // eax
int *v25; // eax
int *v26; // eax
int *v27; // eax
int *v28; // eax
int *v29; // eax
int *v30; // eax
int *v31; // eax
int *v32; // eax
int *v33; // eax
int *v34; // eax
int *v35; // eax
int *v36; // eax
int *v37; // eax
int *v38; // eax
int *v39; // eax
int *v40; // eax
int *v41; // eax
int *v42; // eax
int *v43; // eax
int *v44; // eax
int *v45; // eax
int *v46; // eax
int *v47; // eax
int *v48; // eax
int *v49; // eax
int *v50; // eax
int *v51; // eax
int *v52; // eax
int *v53; // eax
int *v54; // eax
int *v55; // eax
int *v56; // eax
int *v57; // eax
int *v58; // eax
int *v59; // eax
int *v60; // eax
int *v61; // eax
int *v62; // eax
int *v63; // eax
int *v64; // eax
int *v65; // eax
int *v66; // eax
int *v67; // eax
int *v68; // eax
int *v69; // eax
int *v70; // eax
int *v71; // eax
int *v72; // eax
int *v73; // eax
int *v74; // eax
int *v75; // eax
int *v76; // eax
int *v77; // eax
int *v78; // eax
int *v79; // eax
int *v80; // eax
int *v81; // eax
int *v82; // eax
int *v83; // eax
int *v84; // eax
int *v85; // eax
int *v86; // eax
int *v87; // eax
int *v88; // eax
int *v89; // eax
int *v90; // eax
int *v91; // eax
int *v92; // eax
int *v93; // eax
int *v94; // eax
int *v95; // eax
int *v96; // eax
int *v97; // eax
int *v98; // eax
int *v99; // eax
int *v100; // eax
int *v101; // eax
int *v102; // eax
int *v103; // eax
int *v104; // eax
int *v105; // eax
int *v106; // eax
int *v107; // eax
int *v108; // eax
int *v109; // eax
int *v110; // eax
int *v111; // eax
int *v112; // eax
int *v113; // eax
int v115; // [esp-8h] [ebp-9Ch]
int v116; // [esp-4h] [ebp-98h]
int v117; // [esp-4h] [ebp-98h]
int i; // [esp+4h] [ebp-90h]
int j; // [esp+8h] [ebp-8Ch]
int v120[33]; // [esp+Ch] [ebp-88h] BYREF
for ( i = 0; i < 32; ++i )
v120[i] = 1; // 最后操作的是v120,直接跟蹤v120即可,這里賦值v120[32]都為1
v120[32] = 0;
puts("Your flag is:");
v3 = first(v120, 1000000000);
v4 = second(v3, 999999950);
first(v4, 2); // v120=100
v5 = third(&v120[1], 5000000);
v6 = second(v5, 6666666);
v7 = third(v6, 1666666);
v8 = third(v7, 45);
v9 = first(v8, 2);
third(v9, 5); // 97
v10 = first(&v120[2], 1000000000);
v11 = second(v10, 999999950);
v12 = first(v11, 2);
third(v12, 2); // 104
v13 = third(&v120[3], 55);
v14 = second(v13, 3);
v15 = third(v14, 4);
second(v15, 1); // 56
v16 = first(&v120[4], 100000000);
v17 = second(v16, 99999950);
v18 = first(v17, 2);
third(v18, 2); // 102
v19 = second(&v120[5], 1);
v20 = first(v19, 1000000000);
v21 = third(v20, 55);
second(v21, 3); // 58
v22 = first(&v120[6], 1000000);
v23 = second(v22, 999975);
first(v23, 4); // 100
v24 = third(&v120[7], 55);
v25 = second(v24, 33);
v26 = third(v25, 44);
second(v26, 11); // 56
v27 = first(&v120[8], 10);
v28 = second(v27, 5);
v29 = first(v28, 8);
third(v29, 9); // 49
v30 = third(&v120[9], 0);
v31 = second(v30, 0);
v32 = third(v31, 11);
v33 = second(v32, 11);
third(v33, 53); // 54
v34 = third(&v120[10], 49);
v35 = second(v34, 2);
v36 = third(v35, 4);
second(v36, 2); // 50
v37 = first(&v120[11], 1000000);
v38 = second(v37, 999999);
v39 = first(v38, 4);
third(v39, 50); // 54
v40 = third(&v120[12], 1);
v41 = third(v40, 1);
v42 = third(v41, 1);
v43 = third(v42, 1);
v44 = third(v43, 1);
v45 = third(v44, 1);
v46 = third(v45, 10);
third(v46, 32); // 49
v47 = first(&v120[13], 10);
v48 = second(v47, 5);
v49 = first(v48, 8);
v50 = third(v49, 9);
third(v50, 48); // 97
v51 = second(&v120[14], 1);
v52 = first(v51, -294967296);
v53 = third(v52, 55);
second(v53, 3); // 52
v54 = third(&v120[15], 1);
v55 = third(v54, 2);
v56 = third(v55, 3);
v57 = third(v56, 4);
v58 = third(v57, 5);
v59 = third(v58, 6);
v60 = third(v59, 7);
third(v60, 20); // 48
v61 = first(&v120[16], 10);
v62 = second(v61, 5);
v63 = first(v62, 8);
v64 = third(v63, 9);
third(v64, 48); // 97
v65 = third(&v120[17], 7);
v66 = third(v65, 6);
v67 = third(v66, 5);
v68 = third(v67, 4);
v69 = third(v68, 3);
v70 = third(v69, 2);
v71 = third(v70, 1);
third(v71, 20); // 49
v72 = third(&v120[18], 7);
v73 = third(v72, 2);
v74 = third(v73, 4);
v75 = third(v74, 3);
v76 = third(v75, 6);
v77 = third(v76, 5);
v78 = third(v77, 1);
third(v78, 20); // 49
v79 = first(&v120[19], 1000000);
v80 = second(v79, 999999);
v81 = first(v80, 4);
v82 = third(v81, 50);
second(v82, 1); // 53
v83 = second(&v120[20], 1);
v84 = first(v83, -294967296);
v85 = third(v84, 49);
second(v85, 1);
v86 = second(&v120[21], 1); // 48
v87 = first(v86, 1000000000);
v88 = third(v87, 54);
v89 = second(v88, 1);
v90 = third(v89, 1000000000);
second(v90, 1000000000); // 53
v91 = third(&v120[22], 49);
v92 = second(v91, 1);
v93 = third(v92, 2);
second(v93, 1); // 50
v94 = first(&v120[23], 10);
v95 = second(v94, 5);
v96 = first(v95, 8);
v97 = third(v96, 9);
third(v97, 48); // 97
v98 = third(&v120[24], 1);
v99 = third(v98, 3);
v100 = third(v99, 3);
v101 = third(v100, 3);
v102 = third(v101, 6);
v103 = third(v102, 6);
v104 = third(v103, 6);
third(v104, 20); // 49
v105 = third(&v120[25], 55);
v106 = second(v105, 33);
v107 = third(v106, 44);
v108 = second(v107, 11);
third(v108, 42); // 97
third(&v120[26], v120[25]); // 56
third(&v120[27], v120[12]);
v115 = v120[27];
v109 = second(&v120[28], 1);
v110 = third(v109, v115);
second(v110, 1);
v116 = v120[23];
v111 = second(&v120[29], 1);
v112 = first(v111, 1000000);
third(v112, v116);
v117 = v120[27];
v113 = third(&v120[30], 1);
first(v113, v117);
third(&v120[31], v120[30]);
printf("CTF{");
for ( j = 0; j < 32; ++j )
printf("%c", (v120[j]));
printf("}");
return 0;
}
結果:
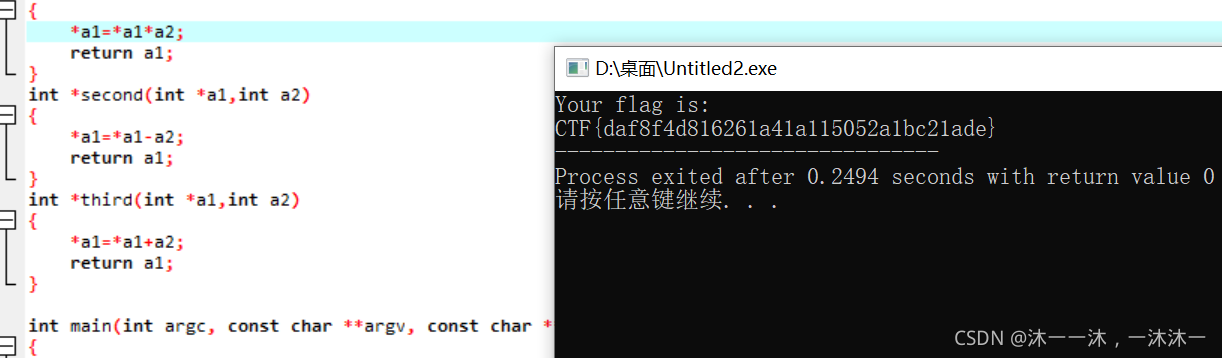
函式邏輯封裝型別:
攻防世界的no-strings-attached:(函式名稱暗示,GDB動態除錯,小端)
32位ELF的linux檔案,照例扔如IDA32位中查看代碼資訊,跟進Main函式:
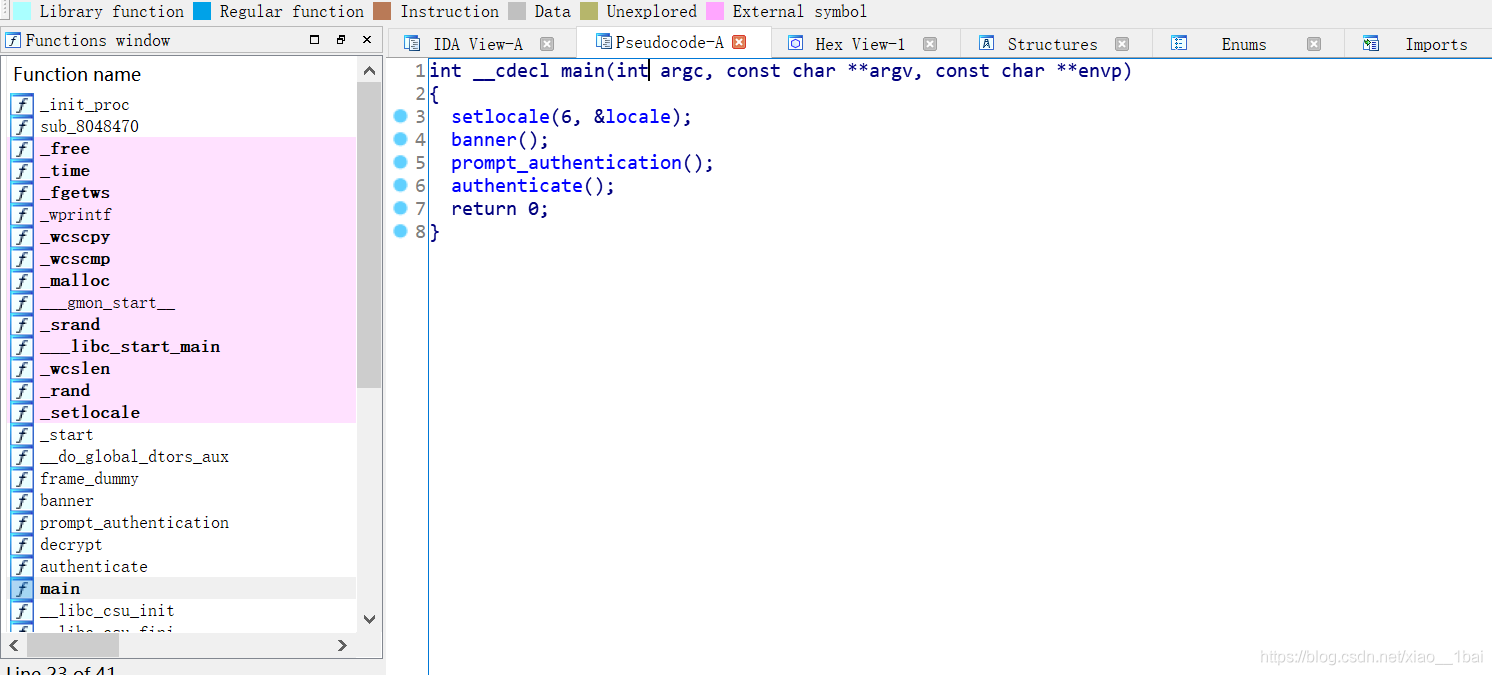
看到四個函式,由于才疏學淺,以為flag不在這里,還去查看了一下strings視窗,也沒有flag字眼,有點懵(還是沒覺得main的四個函式有問題,還是太菜了啊),查了查資料,說flag操作就在這四個函式里,于是有回頭去看這四個函式,
先看匯入表,看那些是自帶的函式:
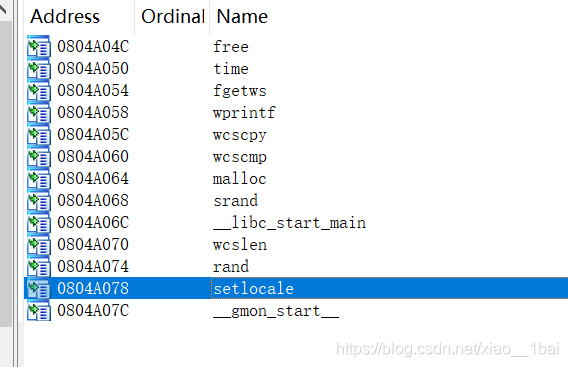
可以看見第一個setlocale是自帶的函式,第二第三個雙擊跟蹤進去是列印函式,banner(橫幅),猜測應該是列印開頭資訊的,那么就剩下第四個函式了,雙擊查看內容:
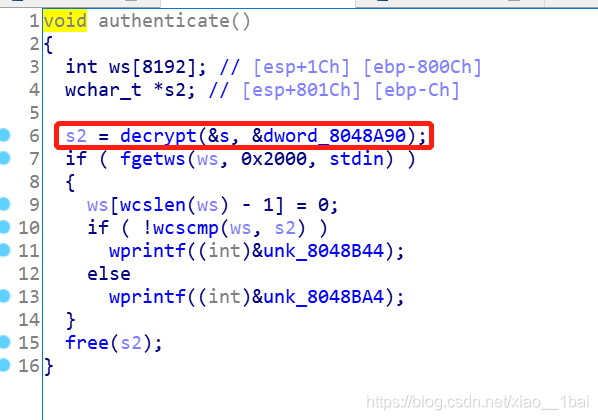
這里有個decrypt函式,中文名是加密,不在匯入表中說明不是系統函式,后面的if判斷條件是輸入,還有個比較的wcscmp函式,后面兩個wprintf分別是success 和access這些成功和拒絕的字串地址,
fgetws函式是從輸入流stdin中獲取0x2000個字符給ws,也就是說s2是關鍵了,s2由decrypt函式得出,decrypt是用戶自定義函式,在這里學到了非系統函式的英文名會是題目給的暗示,所以這里是加密操作后與輸入的比較,只要輸入后與加密后的s2一樣就會列印success或access這些字串,那flag自然也在加密函式中了,
由于這種題是和用戶輸入的比較的,也就是說flag就在s2里面,我們可以在記憶體除錯中提取s2的值,然后解密即可得到flag,(通常s2就是flag,因為如果s2還是加密的flag的話就不用玩了)
我還嘗試print s2指令輸出變數s2的值,因為我以為和IDA顯示的一樣,flag賦值給了s2,后來才想起IDA是根據自己的規則給無法決議變數名賦值的,也就是說在IDA里變數是s2這個名字,但是實際上程式里并沒有s2這個變數名,所以只能查看暫存器了,畢竟函式是先回傳到eax暫存器中再移動到變數中的,
還有就是admin的wp中給的是n指令然后查看eax暫存器的值,可是n指令執行的是一行高級語言命令,而ni和si才是單步執行一潭訓編指令,所以不要調著調著跳過對應指令都不知道,
還有就是這里雖然是decrypt產出flag后賦值給了s2,但是雙擊s2跟蹤顯示的是s2初始的地址和值,而s2初始并沒有什么東西,decrypt函式是用初始有值的&s進行加密操作后才產出flag賦值給s2的,所以不能用雙擊跟蹤s2初始值的方式得到flag,
&s雙擊后跟進的字串值:

GDB動態除錯:
gdb ./no_strings_attached 將檔案加載到GDB中:
之前通過IDA,我們知道關鍵函式是decrypt,所以我們把斷點設定在decrypt處,b在GDB中就是下斷點的意思,即在decrypt處下斷點:
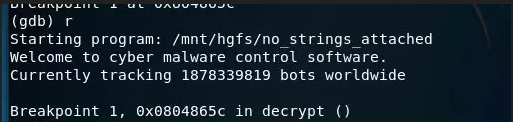
我們要的是經過decrypt函式,生成的字串,所以我們這里就需要運行一步,GDB中用n來表示運行一步高級語言代碼:
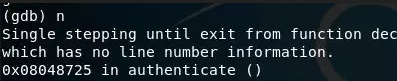
然后我們就需要去查看記憶體了,去查找最后生成的字串:
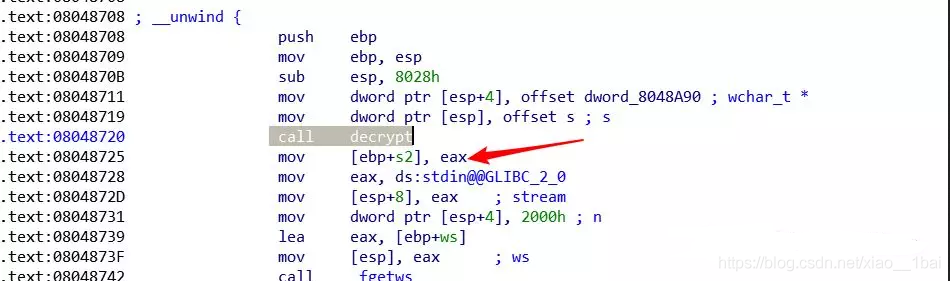
通過IDA生成的匯編指令,我們可以看出進過decrypt函式后,生成的字串保存在EAX暫存器中,所以,我們在GDB就去查看eax暫存器的值:
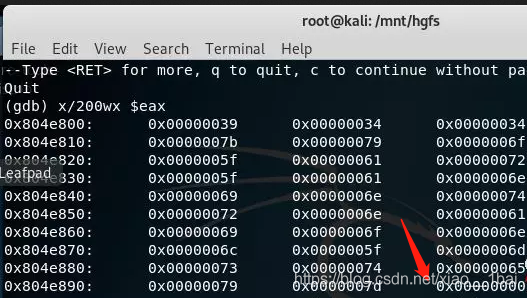
x:就是用來查看記憶體中數值的,后面的200代表查看多少個
x 代表是以word位元組查看看
$ eax代表的eax暫存器中
在這里我們看到0x00000000,這就證明這個字串結束了,因為,在C中,代表字串結束的就是"\0",那么前面的就是經過decrypt函式生成的flag,
這里要特別注意一下:操作是面對反匯編低級語言來操作的,所以是對照著記憶體來操作的!
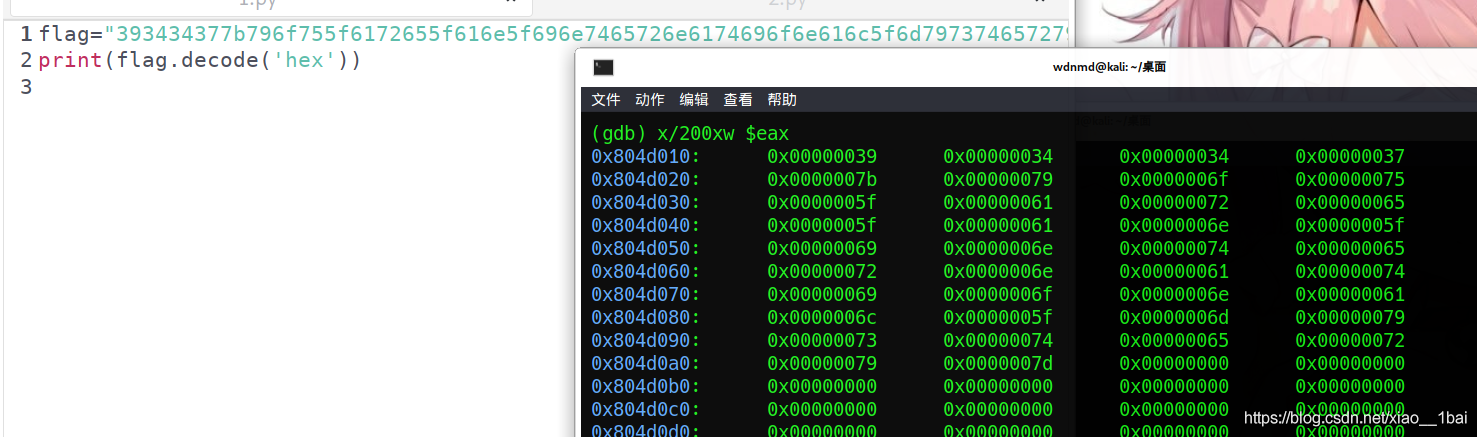
這里是記憶體數,所以不用像小端一樣反過來(可能只有我才會傻到反過來吧~),十六進制數解密后就是flag了:(注意,這里請用python2執行,具體原因看我的Python筆記)
flag="393434377b796f755f6172655f616e5f696e7465726e6174696f6e616c5f6d7973746572797d";
print(flag.decode('hex'))
靜態仿寫加密流程:
首先回顧前面的話:
由于這種題是和用戶輸入的比較的,也就是說flag就在s2里面,我們可以在記憶體除錯中提取s2的值,然后解密即可得到flag,
flag在s2內,不用gdb查看記憶體的話s2就無法得知,但是s2是由decrypt這個加密函式得出的,而這里decrypt傳入的加密引數&s和&dword_8048A90都可以雙擊跟蹤記憶體查看初始值,而且decrypt的內部構造也有,那么我們直接提取出&s和&dword_8048A90這兩個引數的值,然后仿照decrypt寫個一樣加密流程的腳本得出的不也是flag嗎?
![]()
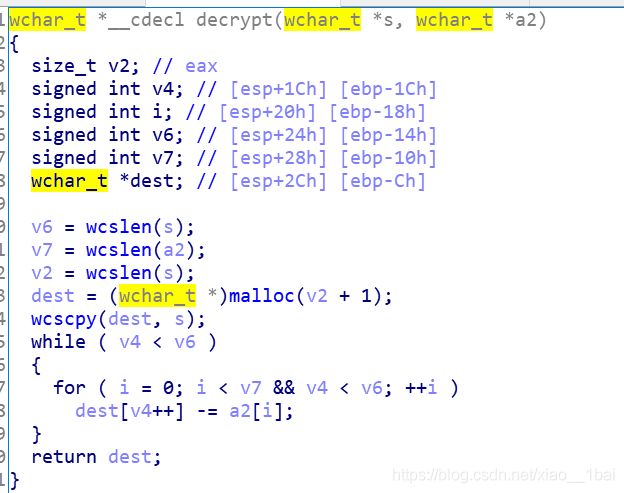
所以我們去提取&s和&dword_8048A90的內容:
addr=0x08048AA8 #陣列的地址
arr = []
for i in range(39): #陣列的個數
arr.append(Dword(addr+4* i))
print(arr)

提取&dword_8048A90:
addr=0x08048A90 #陣列的地址
arr = []
for i in range(6): #陣列的個數
arr.append(Dword(addr+4* i))
print(arr)

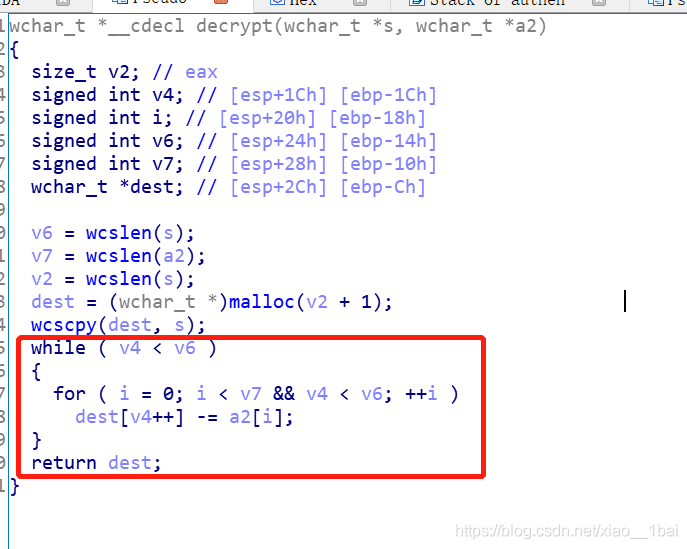
然后就是用python仿照decrypt加密流程寫腳本了:(注意:前面c++中v4++是先賦值后再加,所以到了python中v4+=1就放在賦值后面了)
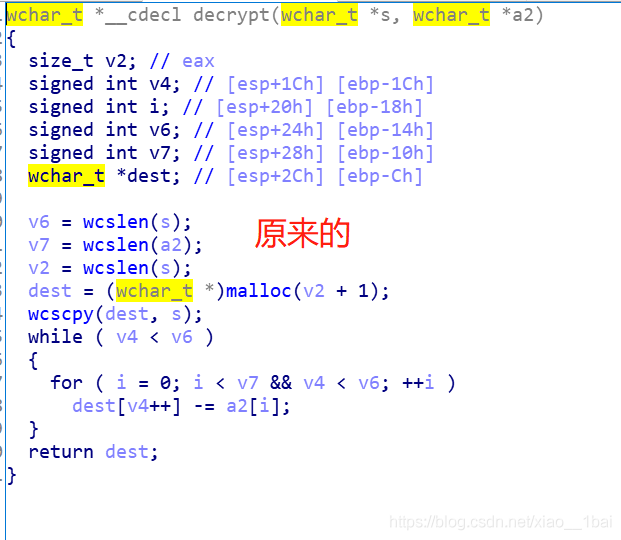
s = [5178, 5174, 5175, 5179, 5248, 5242, 5233, 5240, 5219, 5222, 5235, 5223, 5218, 5221, 5235, 5216, 5227, 5233, 5240, 5226, 5235, 5232, 5220, 5240, 5230, 5232, 5232, 5220, 5232, 5220, 5230, 5243, 5238, 5240, 5226, 5235, 5243, 5248]
a = [5121, 5122, 5123, 5124, 5125]
v6 = len(s)
v7 = len(a )
v2 = len(s)
v4=0
while v4<v6:
for i in range(0,5):
if(i<v7 and v4<v6):
s[v4]-=a[i]
v4 += 1
else:
break
for i in range (38):
print(chr(s[i]),end="")
攻防世界answer_to_everything:(函式名稱暗示、函式邏輯封裝、出人意料的flag、題目描述暗示)
這里看題目犯下第一個錯誤:
題目中的人名原來可以包含重要資訊的,比如這里的sha1就是sha1加密意思,原諒我年長無知,
IDA靜態分析:
跟蹤主函式,看到not_the_flag函式,進去看一下:
這里犯下第二個錯誤,我看到字串以為真的是not_the_flag,然后看了其它函式也沒發現有用資訊,查了資料才發現這里就是flag,因為我沒有把他翻譯成中文,所以錯過了重要提示!!!!

這里已經提示得很透徹了,提交時不要帶標簽,就是直接提交kdudpeh即可,結合錯誤1中的sha1人名,flag就是kdudpeh的sha1加密:
攻防世界secret-galaxy-300:(函式名稱暗示、題目描述暗示、字串拆分演算法積累)
下載附件壓縮包,解壓,得到三個檔案:
一開始我很震驚,以為是那種多檔案關聯的逆向題,結果不是,查看資料后發現這只是三個同一型別檔案的三個不同版本而已,一個windows32位exe,另外兩個分別是32位和64位的ELF的linux可執行檔案,就分析32位的ELF檔案吧,
扔入IDA32中查看偽代碼,有main函式看main函式:
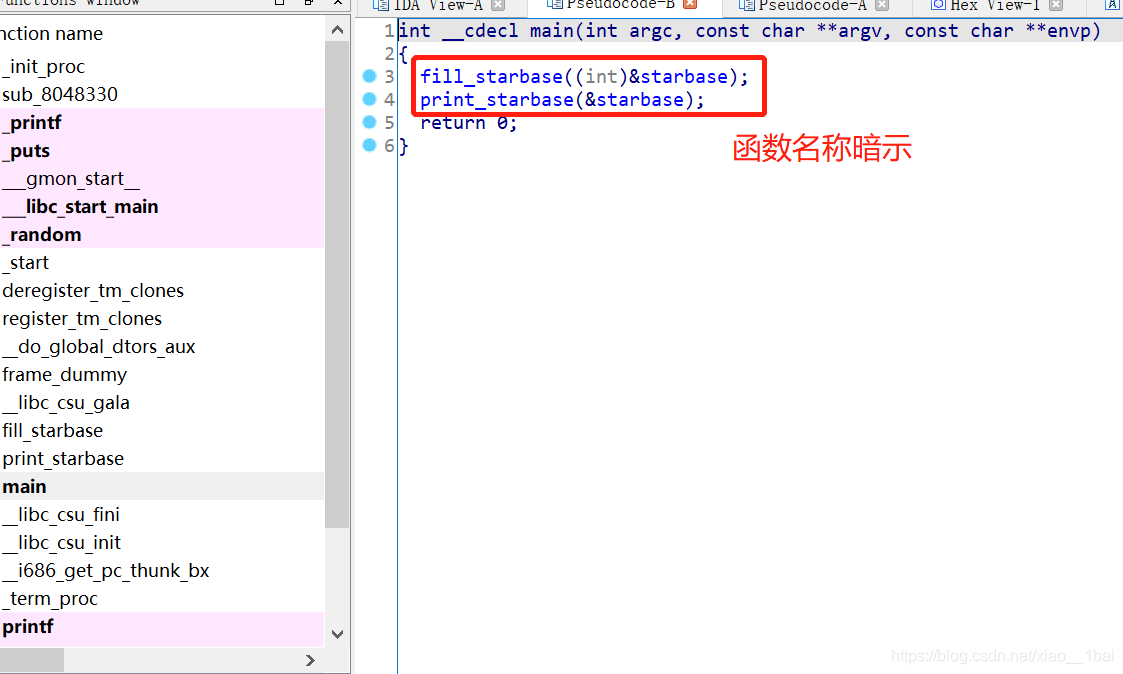
兩個函式,一個填充fill_starbase,一個列印print_starbase,列印的函式跟蹤進去沒啥,列印一些橫幅和其它資訊,其中v2跟蹤不了,看了一下是作為引數傳入的:

這里a1跟蹤不了,因為是在外部的&starbase傳入的,所以前面fill_starbase猜想是填充該陣列的,雙擊跟蹤:
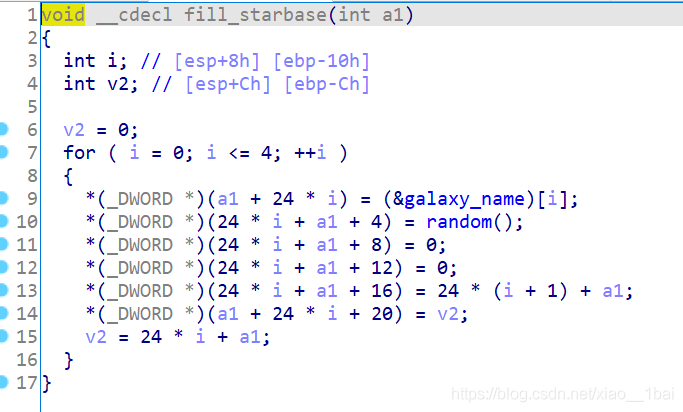
看到一個陣列&galaxy_name,還是取地址,后面是對它的一些運算,雙擊跟蹤陣列:
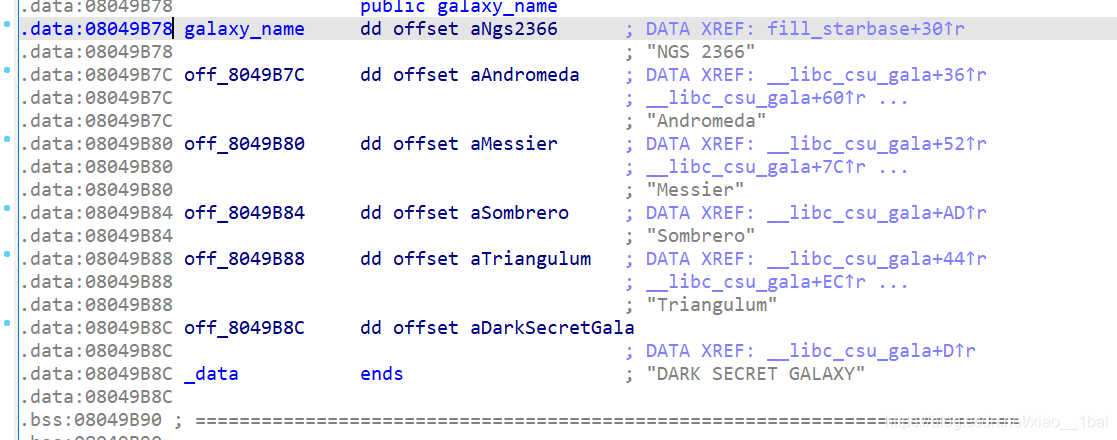
看到這里有點不明覺厲,因為至始至終沒有flag字眼,想起我還沒運行程序式,就去運行一下:
(PS:這里犯下第一個錯誤:從一開始就運行程式可以幫助我門了解主要顯示資訊和判斷隱藏資訊,這里我現在才運行是太后了)
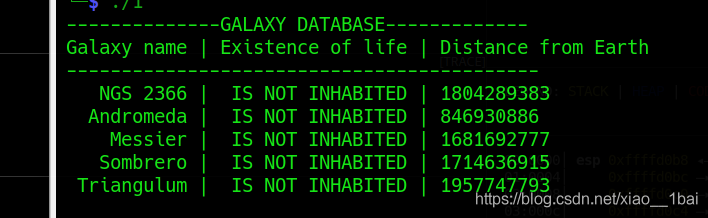
列印的資訊在前面分析中都可以看到,這里犯下第二個錯誤:沒有結合題目的暗示,題目是secret-galaxy-300,中文引導型暗示——隱藏的星系,運行結果顯示了5個星系,而我前面跟蹤的陣列有6個星系,少了DARK SECRET GALAXY,那么這個就是關鍵點!
跟蹤DARK SECRET GALAXY的呼叫,發現一個函式,代碼分析如下:(這里是把一個星系字串拆分成大量的單個字符逐個賦值,可以說是一種演算法積累辨識了)
int _libc_csu_gala() //呼叫DARK SECRET GALAXY的函式
{
int result; // eax
sc[0] = off_8049B8C; // DARK SECRET GALAXY的地址
sc[3] = aAliensAreAroun; //一開始雙擊跟蹤啥也沒有,后面是對它的賦值操作
sc[1] = 31337;
sc[2] = 1;
aAliensAreAroun[0] = off_8049B7C[8]; //off_8049B7C處是Andromeda字串的地址,是第一個星系
aAliensAreAroun[1] = off_8049B88[7]; //off_8049B88處是Triangulum字串的地址,是第二個星系
aAliensAreAroun[2] = off_8049B80[4]; //off_8049B80是Messier字串的地址,是第三個星系
aAliensAreAroun[3] = off_8049B7C[6];
aAliensAreAroun[4] = off_8049B7C[1];
aAliensAreAroun[5] = off_8049B80[2];
aAliensAreAroun[6] = 95; //_
aAliensAreAroun[7] = off_8049B7C[8];
aAliensAreAroun[8] = off_8049B7C[3];
aAliensAreAroun[9] = off_8049B84[5]; //off_8049B84是Sombrero的地址,是第四個星系
aAliensAreAroun[10] = 95; //_
aAliensAreAroun[11] = off_8049B7C[8];
aAliensAreAroun[12] = off_8049B7C[3];
aAliensAreAroun[13] = off_8049B7C[4];
aAliensAreAroun[14] = off_8049B88[6];
aAliensAreAroun[15] = off_8049B88[4];
aAliensAreAroun[16] = off_8049B7C[2];
aAliensAreAroun[17] = 95; //_
aAliensAreAroun[18] = off_8049B88[6];
result = (unsigned __int8)off_8049B80[3];
aAliensAreAroun[19] = off_8049B80[3];
aAliensAreAroun[20] = 0;
return result; //這里犯下第三個錯誤,回傳result,可是result是off_8049B80[3],就是Messier的第三個字符s,我醉了,難怪不顯示,因為前面一直在用 aAliensAreAroun,結果這里回傳別的東西去了,
}
分析完后可以知道 aAliensAreAroun陣列大概就是我們要找的flag了:
(PS:可能是我已經運行且除錯過IDA了,所以這里的陣列名字和我一開始看到的不一樣,IDA應該是自己又修改過了)
第一種方法:
手動除錯,就這樣不同的字串一個個截取對應的位拼接即可,
第二種方法:
IDA遠程動態除錯,下斷點在return處,運行:

雙擊跟蹤 aAliensAreAroun,按a鍵生成陣列:(a鍵是IDA生成陣列的熱鍵)
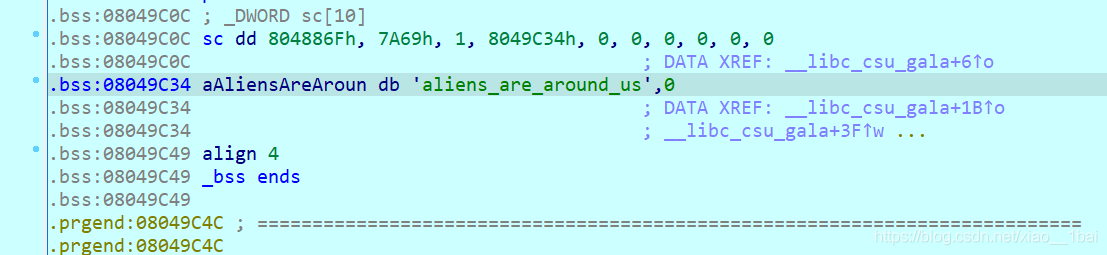
結果就是aliens_are_around_us
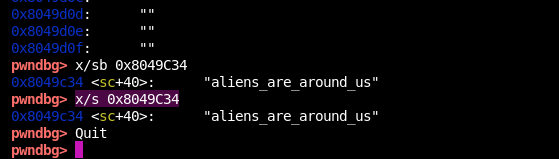
GDB動態除錯:
b *0x80485bc //下斷點(32位的ELF檔案才是這個記憶體地址啊!其他的不是)
run //運行
x/s 0x8049C34 //查看aAliensAreAroun陣列記憶體
攻防世界simple-check-100:(IDA動態除錯、GDB動態除錯)
下載附件,又是三個同一型別不同版本的附件,還以為終于遇到了那種關聯檔案的逆向題:用win32檔案,照例扔入IDA32中查看偽代碼,有main函式看main函式:

關鍵代碼如上,輸入和檢查判斷是v8,而v8=&v6,也就是說我們是在v6地址上操作,
這里犯下第一個錯誤:
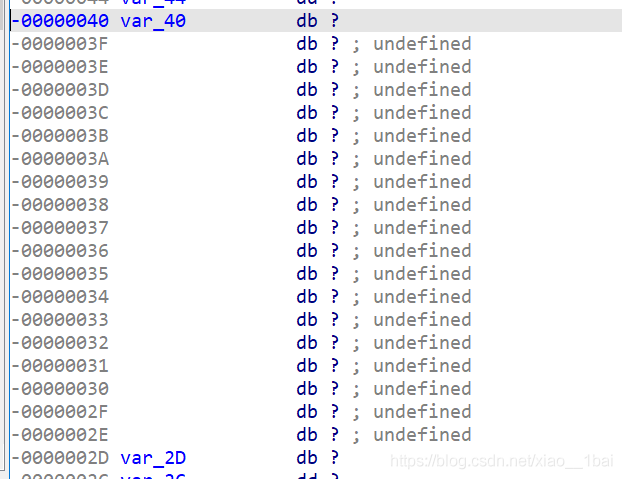
我看v6堆疊地址的時候發現編譯器給v6留了好多空間,但我竟然以為這題沒有這么簡單,我以為我么輸入的v8會覆寫v7~v35這些地址,如果會覆寫的話題型就變成與用戶輸入有關的生成型flag了,就不能靠簡單修改跳轉點來做了,畢竟我們的輸入會修改資料,可結果就是v6空間大到我們輸入的資料不會覆寫其它變數的資料,真是多想了!
(下圖是v6空間,從40~2D,夠大了!)
所以我們簡單修改跳轉條件輸出呼叫后面生成flag的函式即可:

直接用剛學到的IDA本地除錯:(修改jz 為 jnz)
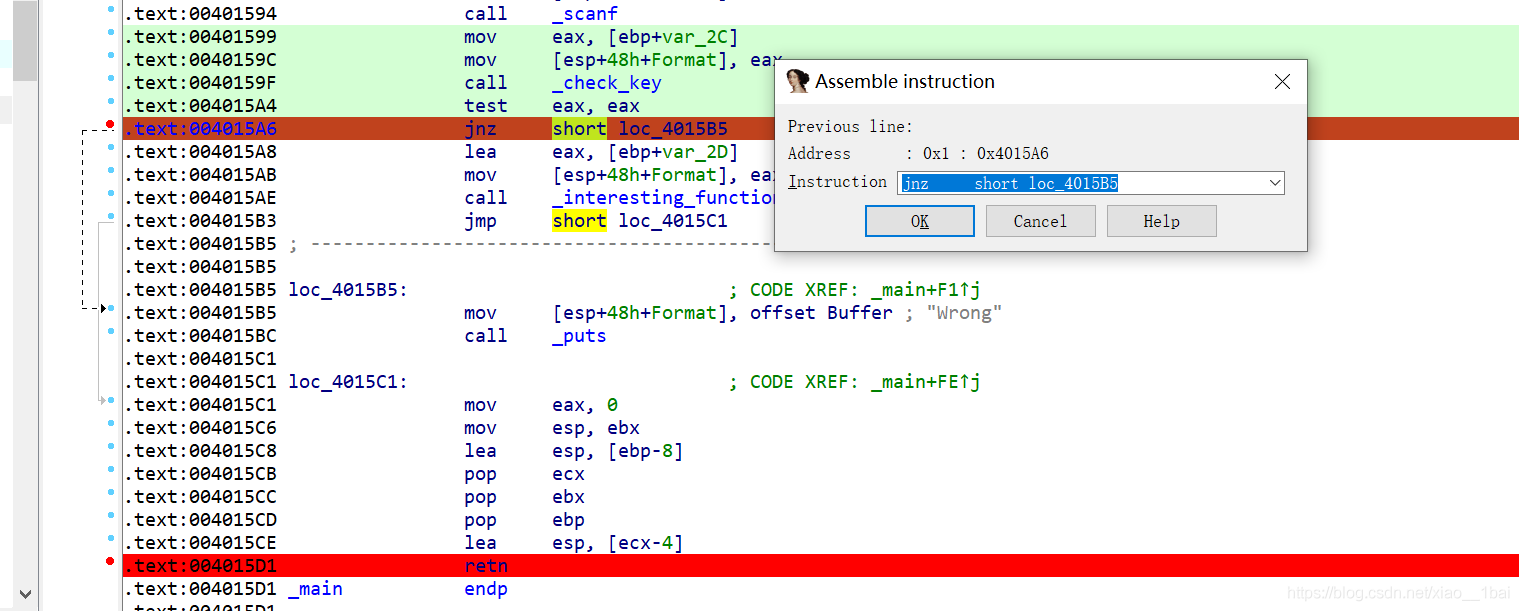
額,亂碼了:
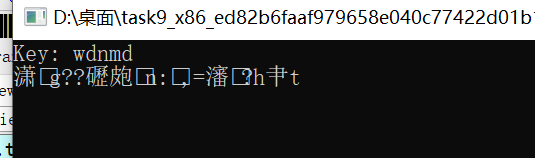
換linux32位來試,繼續扔ELF32位入IDA中查看對應代碼在虛擬記憶體中的位置,好下斷點:(在8048719處):

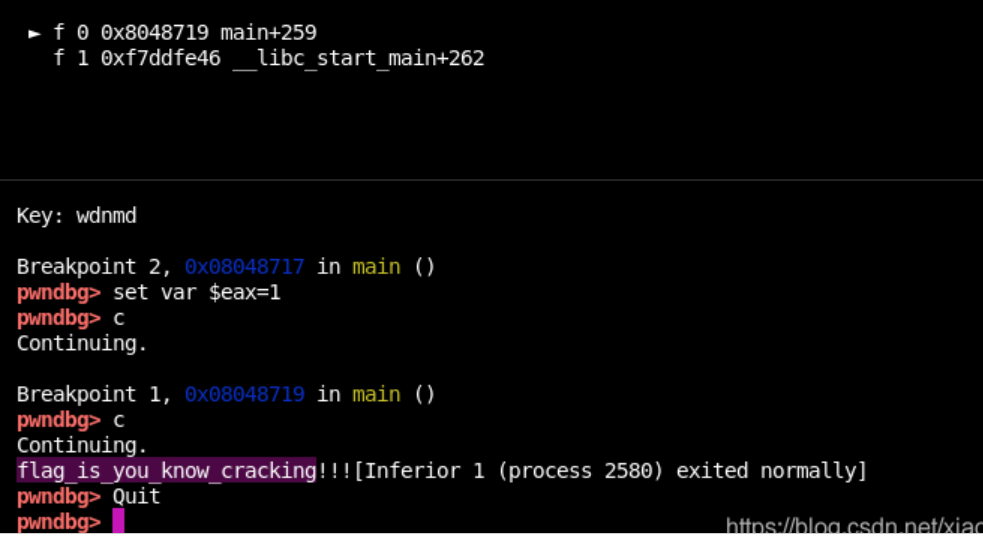
LInux GDB除錯,代碼如下:
b *0x8048717 //判斷位置test eax eax處下斷點
r
set var $eax=1 //這里犯下第二個錯誤:因為前面位運算陳述句是test eax eax,我們沒法直接修改狀態標志位ZF=0或修改jz為jnz , 所以我們直接修改eax讓test eax eax使ZF=0
c
結果:
攻防世界re1-100:(函式邏輯封裝、出人意料的flag、非預期行為)
64位ELF檔案,照例扔入IDA64中查看偽代碼資訊,有main函式看main函式:
這里犯下第一個錯誤,前面是一堆系統函式,我知道系統函式通常不是關鍵,但是它系統函式中又混雜了字串,加上我之前寫的HOOK題,還以為藏了什么重要資訊在里面,后來才發現關鍵邏輯代碼在后面,
所以以后遇到這種系統函式多的題目先瀏覽一下全域,看看系統函式外有沒有關鍵邏輯代碼:

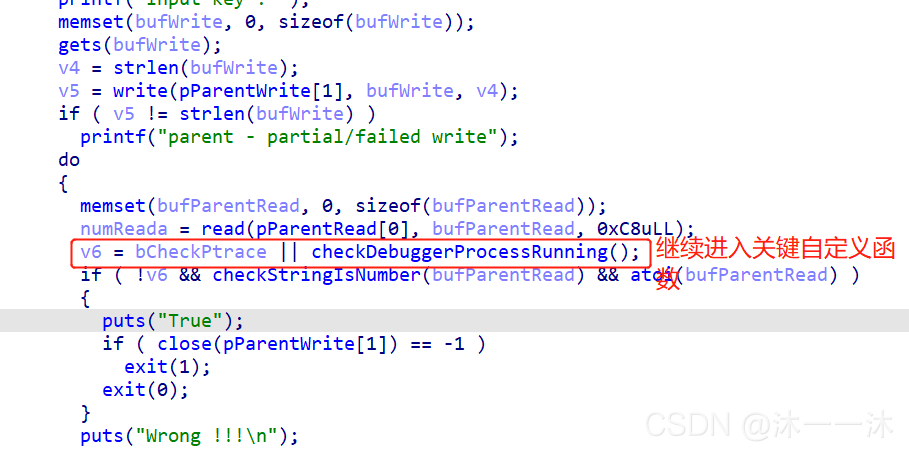
前面是對&bufParentRead[1]的開頭十個賦值,后面&bufParentRead[31]是對倒數十個賦值,但是后面順序又亂掉了:strncmp(bufParentRead, “{daf29f59034938ae4efd53fc275d81053ed5be8c}”, 42uLL)
所以中間一定有改變,跟蹤一下中間的confuseKey(bufParentRead, 42)函式:

前面比較多東西,但是這次我忽然看到后面的關鍵了,如截圖所示,把字串分成四份,按3、4、1、2、的順序重新打亂,而且按照主函式最后混亂代碼那里{daf29f59034938ae4efd53fc275d81053ed5be8c}也的確是符合4和1的新順序,
所以之前的函式順序就是簡單的1、2、3、4、:
{53fc275d81053ed5be8cdaf29f59034938ae4efd}
好像很簡單,但是提交的時候顯示錯誤:
這里就犯下第二個錯誤了,既然題目沒有flag模板,我加flag變成flag{53fc275d81053ed5be8cdaf29f59034938ae4efd}還是提交錯誤,那這里就應該去掉花括號啊,結果就是53fc275d81053ed5be8cdaf29f59034938ae4efd
攻防世界elrond32:(argv[]外部呼叫輸入引數符合條件、函式邏輯封裝、遞回呼叫演算法)
32位ELF檔案,無殼,扔入32位IDA中查看偽代碼資訊,有Main函式看main函式:
額,看上去好像比較簡單,int __cdecl main(int a1, char **a2)中a1是命令列傳入引數的個數,起始值為1,a2是命令列傳入引數的陣列,a2[0]存的是程式名稱,所以才有a1的起始1,我們傳入的引數從a2[1]開始,
跟蹤sub_8048414函式:(遞回呼叫演算法)
int __cdecl sub_8048414(_BYTE *input_flag, int a2)
{
int result; // eax
switch ( a2 ) // a2=0,從0開始,然后后面遞回重新呼叫此函式時會對a2重新賦值,每次+1,按順序對應case的不同情況,以此按順序鎖定flag每個字符,
{
case 0:
if ( *input_flag == 'i' )
goto LABEL_19;
result = 0;
break;
case 1:
if ( *input_flag == 'e' )
goto LABEL_19;
result = 0;
break;
case 3:
if ( *input_flag == 'n' )
goto LABEL_19;
result = 0;
break;
case 4:
if ( *input_flag == 'd' )
goto LABEL_19;
result = 0;
break;
case 5:
if ( *input_flag == 'a' )
goto LABEL_19;
result = 0;
break;
case 6:
if ( *input_flag == 'g' )
goto LABEL_19;
result = 0;
break;
case 7:
if ( *input_flag == 's' )
goto LABEL_19;
result = 0;
break;
case 9:
if ( *input_flag == 'r' )
LABEL_19:
result = sub_8048414(input_flag + 1, 7 * (a2 + 1) % 11); // 修改input_flag的地址,a2重新賦值,遞回呼叫,
else
result = 0;
break;
default:
result = 1;
break;
}
return result;
}
這里我們先寫腳本正向逆向(仿寫)這個邏輯先,只要保證每個回傳的都是1即可,遞回呼叫我們用大量回圈來寫,反正不符合結果就會跳出:
a2=0
flag=""
for i in range(32):
a=a2
if a==0:
flag+='i'
elif a==1:
flag+='e'
elif a==3:
flag+='n'
elif a==4:
flag+='d'
elif a==5:
flag+='a'
elif a==6:
flag+='g'
elif a==7:
flag+='s'
elif a==9: #python寫c語言的
flag+='r'
else:
break
a2=7 * (a2 + 1) % 11
print(flag)
print(len(flag))
結果,生成一個8位的字串就退出了:
跟蹤下一個函式,sub_8048538((int)a2[1]),發現flag要對前面生成的8位字符進一步操作才行,
int __cdecl sub_8048538(int input_flag)
{
int v2[33]; // [esp+18h] [ebp-A0h] BYREF
int i; // [esp+9Ch] [ebp-1Ch]
qmemcpy(v2, &dword_8048760, sizeof(v2));
for ( i = 0; i <= 32; ++i )
putchar(v2[i] ^ *(char *)(input_flag + i % 8)); //一個簡單的異或操作然后輸出,%8對得上前面輸出的8位字串
return putchar(10);
}
寫IDA腳本列印dword_8048760陣列內容:
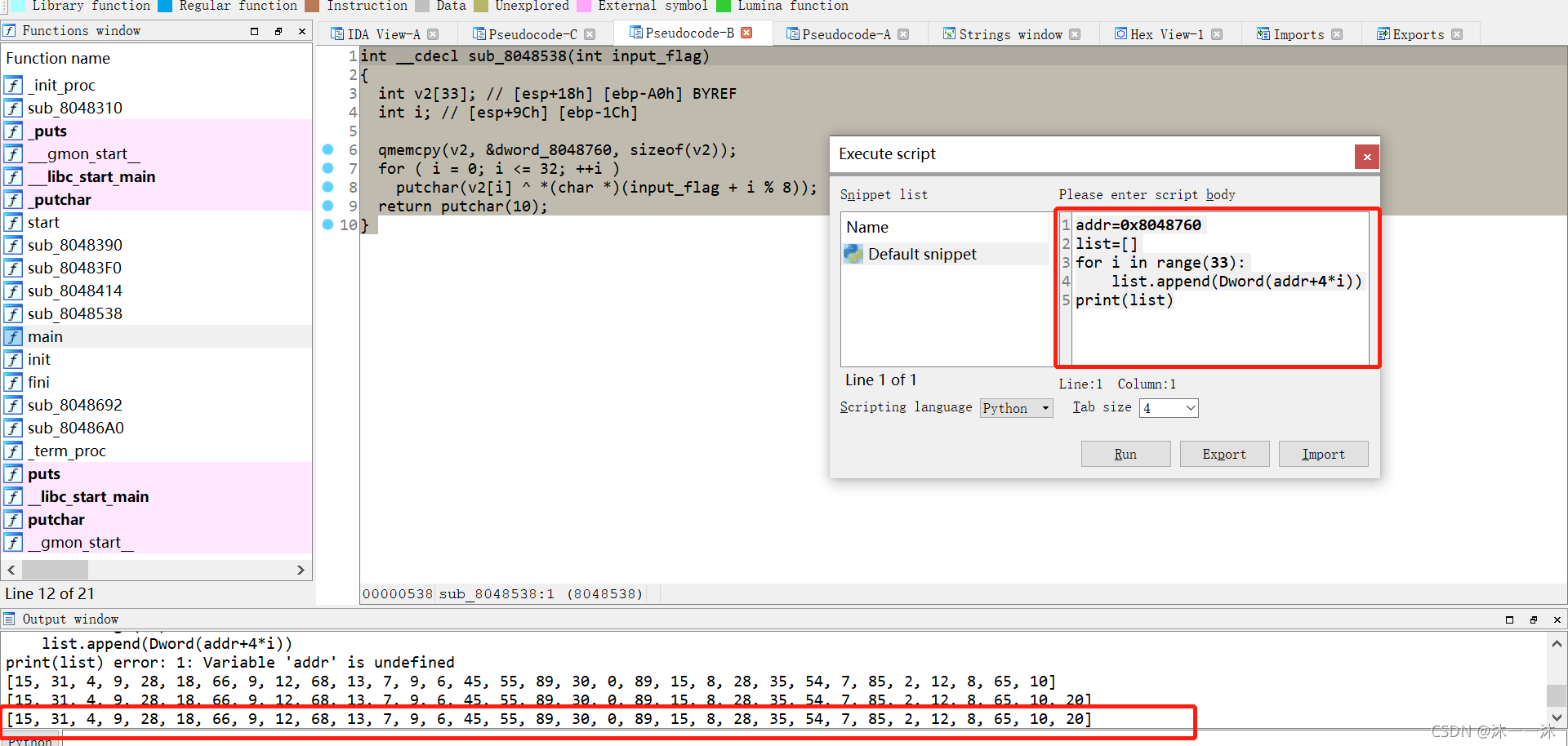
復制粘貼陣列,重新修改腳本內容:
a2=0
flag=""
v2=[15, 31, 4, 9, 28, 18, 66, 9, 12, 68, 13, 7, 9, 6, 45, 55, 89, 30, 0, 89, 15, 8, 28, 35, 54, 7, 85, 2, 12, 8, 65, 10,20]
flag2=""
for i in range(32):
a=a2
if a==0:
flag+='i'
elif a==1:
flag+='e'
elif a==3:
flag+='n'
elif a==4:
flag+='d'
elif a==5:
flag+='a'
elif a==6:
flag+='g'
elif a==7:
flag+='s'
elif a==9: #python寫c語言的
flag+='r'
else:
break
a2=7 * (a2 + 1) % 11
print(flag)
print(len(flag))
for i in range(33):
flag2+=chr(v2[i]^ord(flag[i%8]))
print(flag2)
結果:

main函式中有與本地檔案相關的操作型別:
攻防世界getit:(IDA、GDB動態除錯)
64位ELF檔案,無殼,然后扔入IDA查看偽代碼資訊:
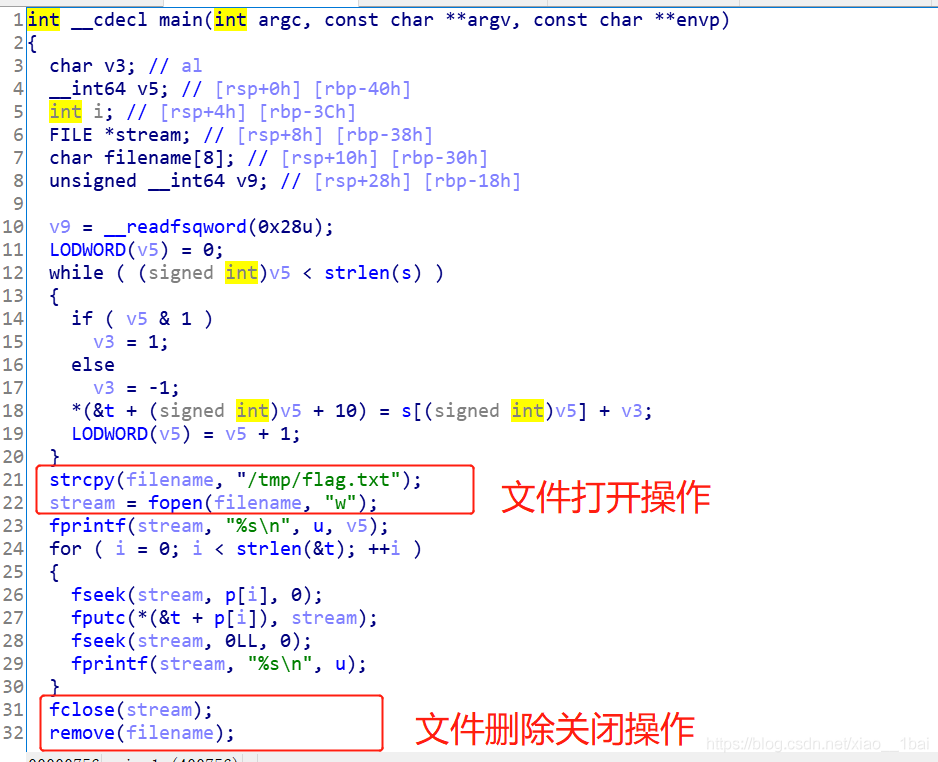
這里說寫入了/tmp/flag.txt,也因為是tmp檔案,所以不是管理員也可以寫入,后面顯眼的fclose(stream);remove(filename);也說明了一運行完程式就洗掉檔案,所以我們沒法在運行完程式后找到該檔案
現在分析中間的回圈寫入陳述句:
for ( i = 0; i < strlen(&t); ++i ) //我是認為&t是flag的長度
{
fseek(stream, p[i], 0); //定位到開頭偏移p[i]位置處,
fputc(*(&t + p[i]), stream); //在上一句的定位處寫入&t起始字串的p[i]偏移的單個位元組
fseek(stream, 0LL, 0); //重新定位到0且沒有偏移
fprintf(stream, "%s\n", u); //寫入完整字符u來覆寫前面寫入的一個字符,雙擊跟蹤u發現是*******************************************,就是一個覆寫干擾
}
這里的p[i]雙擊跟蹤長這個樣子:(p[i]滑鼠長時間停留顯示int[43]型別):
可以看到p[i]陣列存放的是無序的整數,但是這些整數都是唯一的flag的位數,也就是說每次在/tmp/flag.txt檔案中寫入的flag是不按順序寫的,且每次只出現一個字符,需要自己排序,
開頭的回圈判斷中的&t在前面出現過,長這個樣子:
![]()
后來發現前面的回圈才是生成的flag代碼,后面的p[i]只是將flag分成單個單個字符寫進去而已:
v9 = __readfsqword(40u); //這里我也不清楚,是windows的API函式,從偏移量的指定位置讀取記憶體相對 FS 段開頭
LODWORD(v5) = 0; //這里把__in64的v5(longlong型)轉地址型別為32為DWORD,即取低32位為0
while ( (signed int)v5 < strlen(s) ) //這里signed int是有符號整形,s雙擊跟蹤是c61b68366edeb7bdce3c6820314b7498這樣的無序字串
{
if ( v5 & 1 ) //這里是v5的1位和1進行與操作,因為后面有LODWORD(v5) = v5 + 1,所以v3在這里會1、-1這樣反復橫條strlen(s)次
v3 = 1;
else
v3 = -1;
*(&t + (signed int)v5 + 10) = s[(signed int)v5] + v3; //這里是賦值,因為v5一開始是0,所以從&t+10開始賦值,&t雙擊跟蹤是SharifCTF{????????????????????????????????},第10位剛好是第一個?,賦值是從s[0]開始+1,s[1]-1,s[2]+1這樣賦值,分別對應不斷遞增的v5和反復橫跳的v3,所以這里也可以手動計算第一個?是b,第二個?是7這樣,
LODWORD(v5) = v5 + 1; //v5底32位加1,其實就是v5加1
}
有好幾種做題方法,
第一個靜態計算,就像我上面分析flag生成代碼手動計算一樣,
手動計算即可,
第二種動態截停,截止flag生成后的位置,查看暫存器即可,
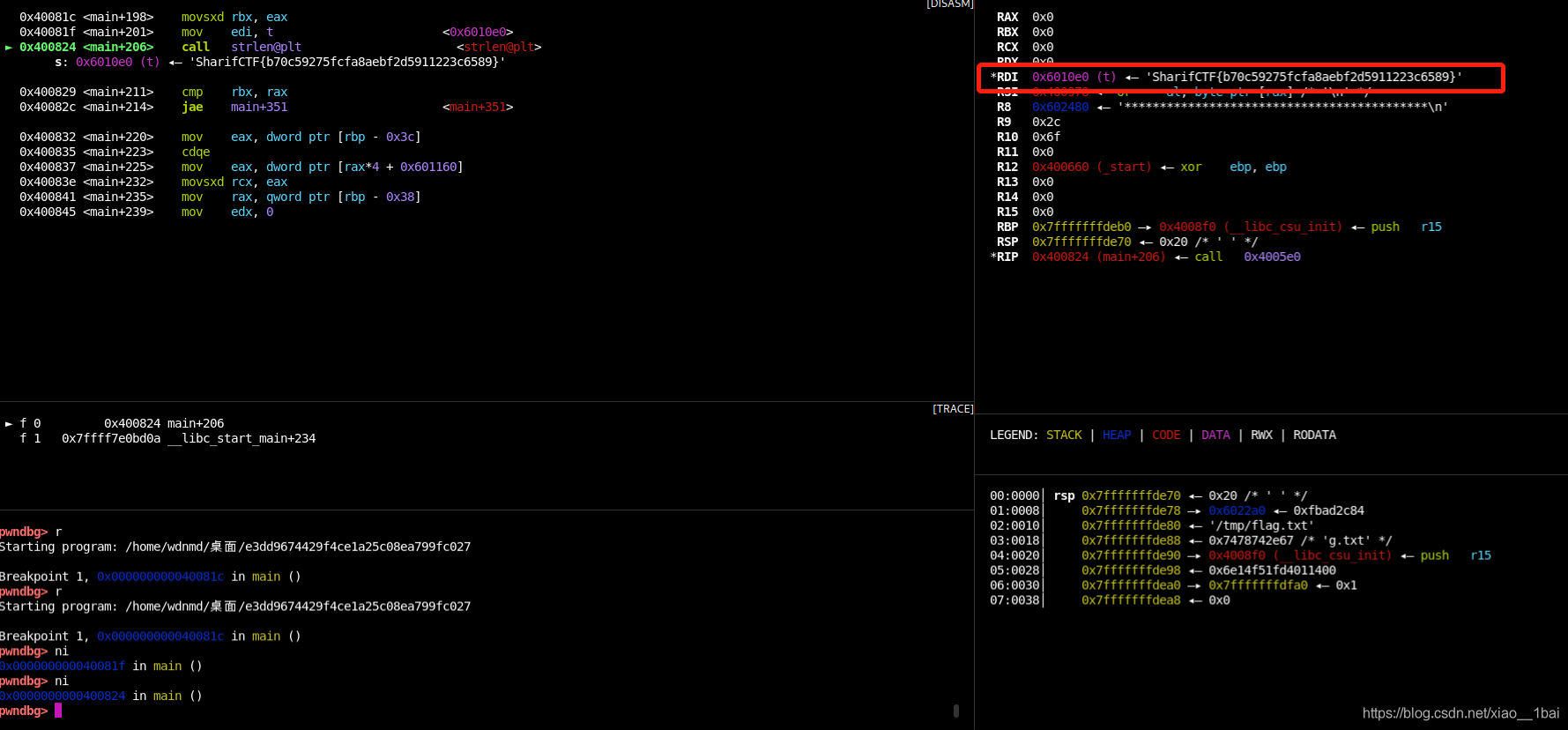
GDB動態除錯,首先我們知道了下面strlen(&t)的t是flag程式運行后生成的flag,那我們把滑鼠放在那一行上看一下下面的反匯編行數,如下所示是400824,那么我們在反匯編視窗跟上,

可以看到反匯編中400824行的確是_strlen函式,而它上面就是把&t移入了edi,所以在GDB中我們斷點400824,然后查看edi暫存器即可,
GDB所需命令:(可以看到flag就在RDI暫存器里)
b *0x400824
r
第三種靜態計算,仿寫c語言腳本或python腳本安裝一樣的演算法生成flag,
key1="c61b68366edeb7bdce3c6820314b7498"
v5=0
flag=""
while v5 < len(key1):
if v5 & 1:
v3=1
else:
v3=-1
flag+=chr(ord(key1[v5])+v3)
v5+=1
print(flag)
第四種動態截停,在IDA遠程除錯中截停在remove(filename);最后這里,或者return 0;也行,然后在IDA中寫python腳本命令輸出&t地址的字串即可,

直接雙擊t看到?已經被替換成flag了,這里是斷點在return,
第五個動態截停,在linux中用GDB或IDA遠程除錯斷點斷在fprintf(stream, “%s\n”, u); 這里,然后每次記錄寫入的一個flag字符,
嗯~第五種就不演示了,大致像這個樣子吧,不過他這個是整理過的,真實的是不按順序出現的,

main函式主邏輯分析(C++)
main函式中嵌入大量冗余代碼,拆分代碼混淆:
攻防世界dmd-50:(函式積累、地址小端存放與正向、涉及加密、出人意料的flag)
64位ELF檔案,無殼,照例扔入IDA64位中查看偽代碼,有main函式看main函式:
看到一堆變數,一堆系統函式,我知道系統函式通常不是考點,可這系統函式多到我都差點找不到主要代碼:
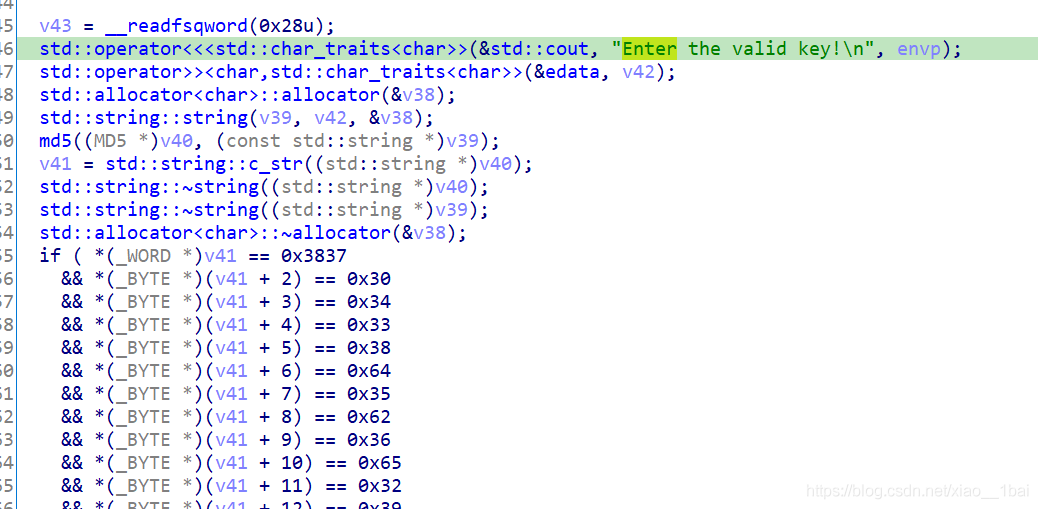
突然看見字串Enter the valid key!\n 猜測題型是與用戶輸入相關的判斷型flag,代碼分析:
v43 = __readfsqword(0x28u); //一個記憶體段偏移,無用
std::operator<<<std::char_traits<char>>(&std::cout, "Enter the valid key!\n", envp);
std::operator>><char,std::char_traits<char>>(&edata, v42); //這里應該是輸入
std::allocator<char>::allocator(&v38); //記憶體空間分配,空間分配就是用于輸入或復制的
std::string::string(v39, v42, &v38); // v42 輸入復制給 v39,這里借鑒了別人的博客,這里犯下第一個錯誤,因為系統函式太多了,我也就只注意到了下面的md5,沒去查這個函式用法,結果這個函式是賦值函式,也是關鍵
md5((MD5 *)v40, (const std::string *)v39); //一個md5加密函式, 把 v39 進行 MD5 后保存在 v40,我記得C語言沒有md5函式的,這里可能是呼叫了外部的庫函式
v41 = std::string::c_str((std::string *)v40);
std::string::~string((std::string *)v40);
std::string::~string((std::string *)v39);
std::allocator<char>::~allocator(&v38);
繼續分析判斷陳述句:
if ( *(_WORD *)v41 == 0x3837 //這里犯下第二個錯誤,這里本來是14390的整數的,這里型別是16位WORD,后面都是8位的BYTE,也就是這里應該分出一個*(_BYTE *)v41和*(_BYTE *)(v41 + 1)的,可是我不會分,想起數在記憶體中是小端的十六進制數,就改為了十六進制,那么前面(_BYTE *)v41就是0x37,后面*(_BYTE *)(v41 + 1)就是0x38了,
&& *(_BYTE *)(v41 + 2) == 0x30
&& *(_BYTE *)(v41 + 3) == 0x34
&& *(_BYTE *)(v41 + 4) == 0x33
&& *(_BYTE *)(v41 + 5) == 0x38
&& *(_BYTE *)(v41 + 6) == 0x64
&& *(_BYTE *)(v41 + 7) == 0x35
&& *(_BYTE *)(v41 + 8) == 0x62
&& *(_BYTE *)(v41 + 9) == 0x36
&& *(_BYTE *)(v41 + 10) == 0x65
&& *(_BYTE *)(v41 + 11) == 0x32
&& *(_BYTE *)(v41 + 12) == 0x39
&& *(_BYTE *)(v41 + 13) == 0x64
&& *(_BYTE *)(v41 + 14) == 0x62
&& *(_BYTE *)(v41 + 15) == 0x30
&& *(_BYTE *)(v41 + 16) == 0x38
&& *(_BYTE *)(v41 + 17) == 0x39
&& *(_BYTE *)(v41 + 18) == 0x38
&& *(_BYTE *)(v41 + 19) == 0x62
&& *(_BYTE *)(v41 + 20) == 0x63
&& *(_BYTE *)(v41 + 21) == 0x34
&& *(_BYTE *)(v41 + 22) == 0x66
&& *(_BYTE *)(v41 + 23) == 0x30
&& *(_BYTE *)(v41 + 24) == 0x32
&& *(_BYTE *)(v41 + 25) == 0x32
&& *(_BYTE *)(v41 + 26) == 0x35
&& *(_BYTE *)(v41 + 27) == 0x39
&& *(_BYTE *)(v41 + 28) == 0x33
&& *(_BYTE *)(v41 + 29) == 0x35
&& *(_BYTE *)(v41 + 30) == 0x63
&& *(_BYTE *)(v41 + 31) == 0x30 )
再后面判斷后的結果按照以前經驗轉成ASCII字符,發現都是成功失敗類的字串,那這里的系統函式作用應該只是簡單的賦值和輸出吧,就不用深究了:
所以思路清晰了,對用戶輸入進行md5加密后一位一位比較,那么我們用md5后的值在在線工具中反向解密即可:
key1=[0x37,0x38,0x30,0x34,0x33,0x38,0x64,0x35,0x62,0x36,0x65,0x32,0x39,0x64,0x62,0x30,0x38,0x39,0x38,0x62,0x63,0x34,0x66,0x30,0x32,0x32,0x35,0x39,0x33,0x35,0x63,0x30]
md=""
for i in key1:
md+=chr(i)
print(len(md))
print(md)
md5結果:
在線解密網址:
https://www.cmd5.com/
額,我們不需要兩次解密,一次就可以了,所以對grape再加密一次:
攻防世界crazy:(函式名稱暗示、地址賦值演算法積累、非預期行為、出人意料的flag)
64位ELF檔案,扔入對應IDA中查看資訊,有main函式看main函式:
可以看到,一堆眼花繚亂的系統函式,有些則是用類名呼叫的普通C++函式,
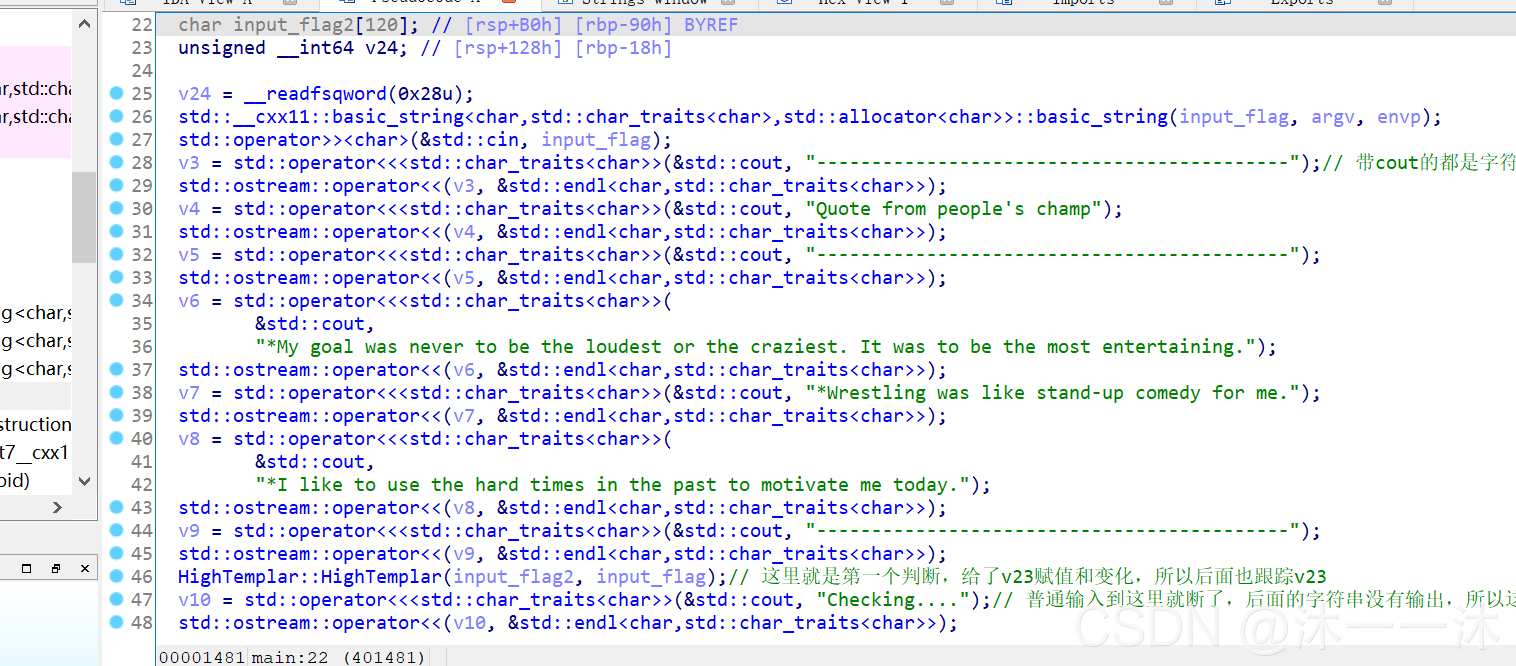
這里積累第一個經驗:(別人博客的一句話)
代碼看著很亂,有很多很長的命令,解決辦法:依據英文意思去猜測,
找關鍵變數的方法:從后往前找,看flag和輸入關系,復雜代碼本質應該是簡潔的,這樣才叫出題,
但是從后往前找與flag的有關變數還是很麻煩,所以我們用運行程式方法不斷查看顯示資訊,鎖定關鍵位置,(除錯的話不知道斷點下在那里可能要遍歷很長時間)
第一次亂輸入:
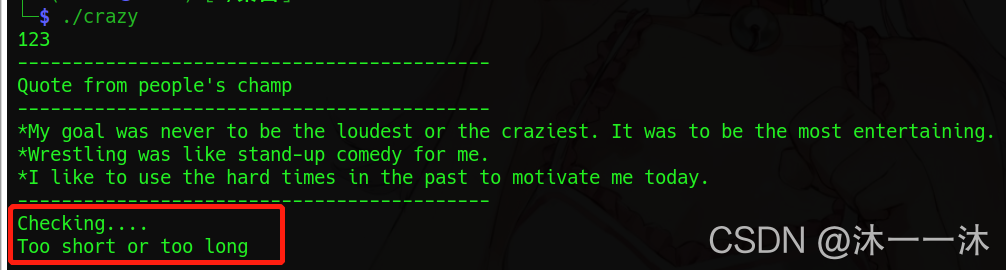
可以看到運行到checking…后顯示too short or too long處,還有就是用戶輸入在字串輸出之前,回傳IDA查看代碼:
這里有個cin,也是主函式中在其它字串之前的,cin是c++的輸入函式,

從這里積累第二個經驗:該程式的長字符傳命令中從后往前找到的熟悉的C++函式就是我們要關注的命令,比如這里的cin函式,像下面截圖中字串前面也有cout函式:
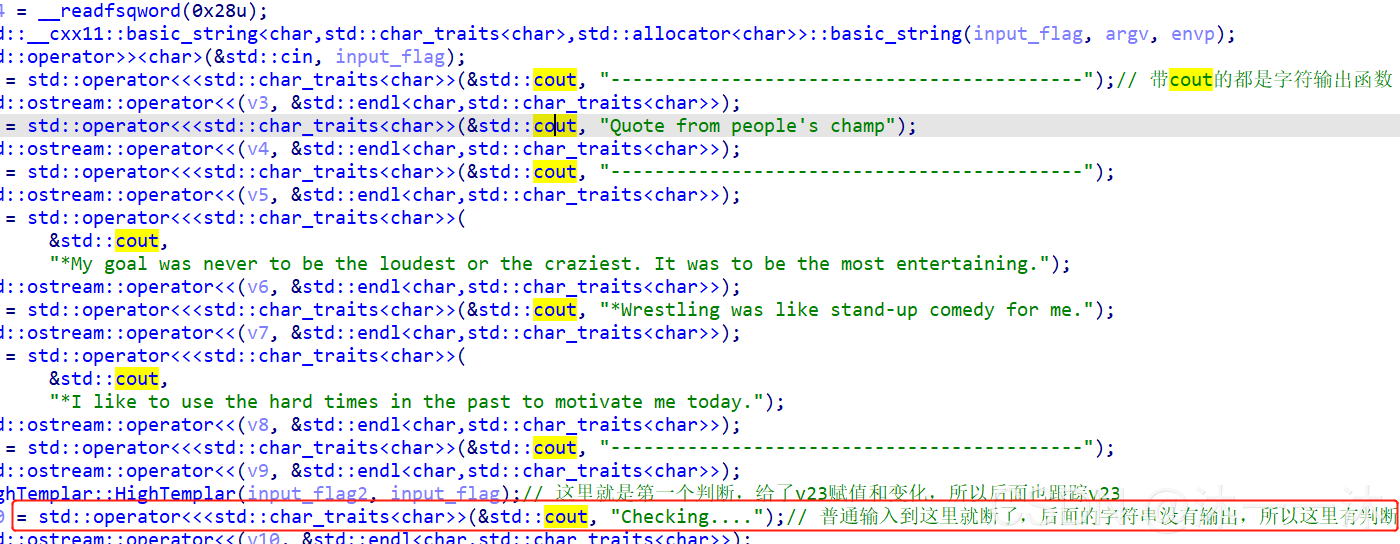
看上圖中最后的check…字串之后的函式:
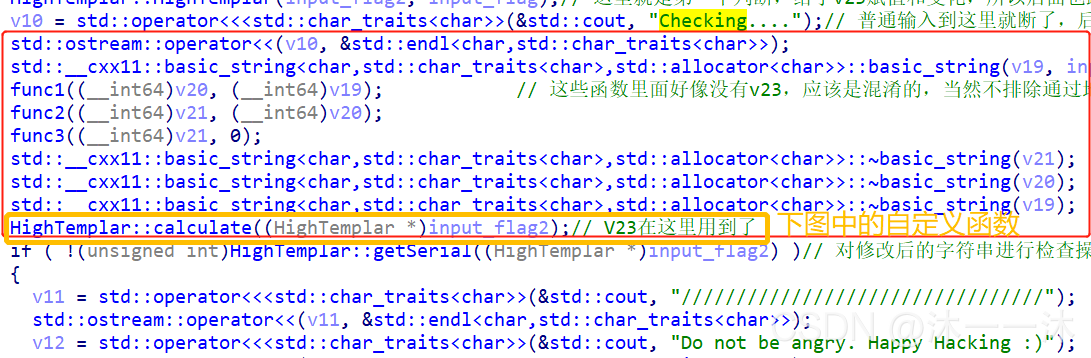
可以看到 checking 到 if 判斷陳述句之間還是有很多函式的,可以用前面的依據英文意思猜測的方法去看函式,也可以在strings視窗查找too short or too long處的函式位置:(我選擇后者)
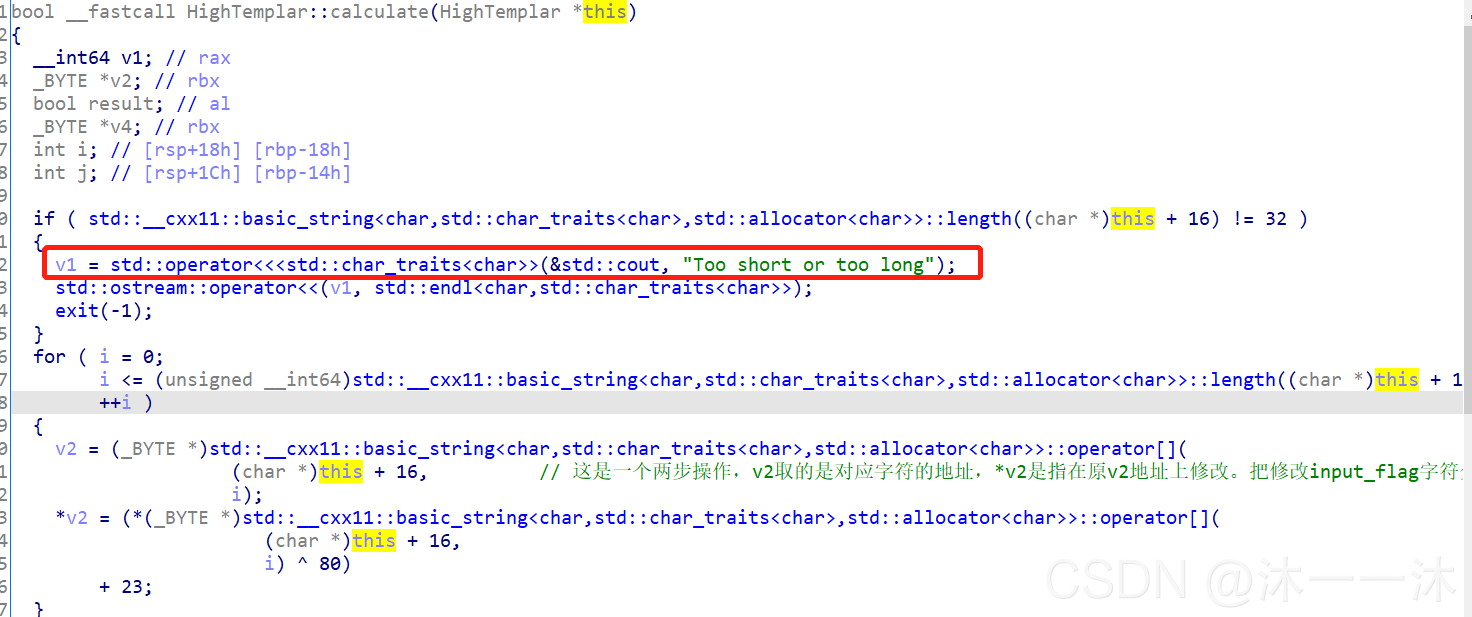
這里跟蹤到HighTemplar::calculate函式,根據英文名是計算函式,但是我看不懂這里的this+16,憑借意思我推測是我們輸入flag的地址,把我們輸入的flag經過兩個簡單的回圈異或加密后輸出:
bool __fastcall HighTemplar::calculate(HighTemplar *this) //接受用戶輸入作為引數
{
__int64 v1; // rax
_BYTE *v2; // rbx
bool result; // al
_BYTE *v4; // rbx
int i; // [rsp+18h] [rbp-18h]
int j; // [rsp+1Ch] [rbp-14h]
if ( std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::length((char *)this + 16) != 32 ) //判斷長度
{
v1 = std::operator<<<std::char_traits<char>>(&std::cout, "Too short or too long"); //輸出判斷結果陳述句
std::ostream::operator<<(v1, std::endl<char,std::char_traits<char>>);
exit(-1);
}
for ( i = 0;
i <= (unsigned __int64)std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::length((char *)this + 16);
++i ) //在長度范圍內的for回圈操作
{
v2 = (_BYTE *)std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::operator[](
(char *)this + 16, // 這里積累第三個經驗:這是一個兩步操作,v2取的是對應字符的地址,*v2是指在原v2地址上對值進行修改,也就是對Input_flag進行修改,把修改input_flag字符分成了兩步做,讓不熟悉的我載了跟頭,(這里算是地址賦值演算法積累)
i);
*v2 = (*(_BYTE *)std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::operator[](
(char *)this + 16,
i) ^ 80) //對input_flag每個字符異或80
+ 23;
}
for ( j = 0; ; ++j )
{
result = j <= (unsigned __int64)std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::length((char *)this + 16); //又是在input_flag的長度范圍內的for陳述句
if ( !result )
break;
v4 = (_BYTE *)std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::operator[](
(char *)this + 16,
j); //簡單分配空間,取地址
*v4 = (*(_BYTE *)std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::operator[](
(char *)this + 16,
j) ^ 19) 對input_flag每個字符異或19
+ 11;
}
return result;
}
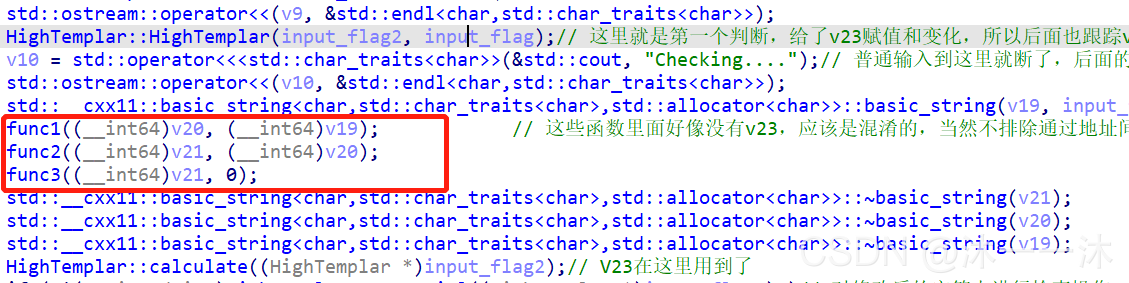
然后由于HighTemplar::calculate函式的下一個就是if判斷函式,所以我們只能跟蹤if判斷函式內的HighTemplar::getSerial了:
前面this+16我推測是我們輸入flag的地方,但是這個this+80存了什么東西我是真不知道了,雙擊跟蹤堆疊也是未賦值的狀態,
這里積累第四個經驗,逆向中不符合預期的運算結果基本都是中間做了其它操作,如之前遇到的HOOK,這里很多函式我還沒跟蹤,那說明的確會有未發現的操作,
回到一開始cin函式的地方,表黃輸入變數,看哪里還參考過該變數:
可以看到在checking前面還參考了一下,而該函式我們并沒有分析,雙擊跟蹤分析:
這里我們可以看到把輸入的flag分別給了this+16和this+48地址處,在this+80地址處給了327a6c4304ad5938ea
f0efb6cc3e53dc這個字串,那么前面對this+80的疑惑就解釋得通了,
unsigned __int64 __fastcall HighTemplar::HighTemplar(DarkTemplar *a1, __int64 input_flag)
{
char v3; // [rsp+17h] [rbp-19h] BYREF
unsigned __int64 v4; // [rsp+18h] [rbp-18h]
v4 = __readfsqword(0x28u);
DarkTemplar::DarkTemplar(a1);
*(_QWORD *)a1 = &off_401EA0;
*((_DWORD *)a1 + 3) = 0;
std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::basic_string(
(char *)a1 + 16, // C++函式,basic_string(字串類模板),不是復制就是比較,這里是復制輸入字串給a1+16開始的地址的陣列中
input_flag);
std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::basic_string(
(char *)a1 + 48, // C++函式,basic_string(字串類模板),不是復制就是比較,復制輸入字串給a1+48開始的地址的陣列中,與前面隔了32個字符
input_flag);
std::allocator<char>::allocator(&v3);
std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::basic_string(
(char *)a1 + 80,
"327a6c4304ad5938eaf0efb6cc3e53dc", // C++函式,basic_string(字串類模板),不是復制就是比較,復制輸入字串給a1+80開始的地址的陣列中,與前面還是隔了32個字符,這個v3不清楚
&v3);
std::allocator<char>::~allocator(&v3);
return __readfsqword(0x28u) ^ v4; //記憶體操作,暫時不用管
}
現在直接寫腳本逆向邏輯即可:
key1="327a6c4304ad5938eaf0efb6cc3e53dc"
flag1=""
flag=""
print(len(key1))
for i in range(len(key1)):
flag1+=chr((ord(key1[i])-11)^19)
for i in range(len(flag1)):
flag+=chr((ord(flag1[i])-23)^80)
print(flag)
結果:(這里積累第5個經驗:現在的flag真的是越來越古靈精怪了,還有花括號,我一開始都以為我寫錯腳本了,現在看來,什么型別的flag都可以!一次不行就修改再交幾次)

最后,下面這三個函式有什么用呢,我判斷它是沒什么用的,因為引數沒有傳入我輸入的flag,跟蹤里面也沒有我輸入的flag地址,除非是偏移地址間接參考我輸入的flag,不過那樣的話題就很難了!
無main函式分析(C語言)
主邏輯平鋪一函式內:
攻防世界Mysterious:(地址小端存放與正向,出人意料的flag)
W32可執行檔案,無殼,扔入IDA32中看偽代碼判斷題目型別:
沒有主函式,看來是非正常檔案,雙擊程式看看有什么資訊可以提取:
一個輸入密碼型彈框,Crack按鈕按不下去,資訊夠了,查看IDAstring視窗:
沒有發現input the password字眼,應該是隱藏了,想起彈框是用了Messagebox的windowsAPI函式,于是雙擊跟蹤該函式:(要在import視窗才能跟蹤,string視窗不行,因為import是匯入API外部函式的視窗,string視窗那里可能只是剛好有同名字串而已)
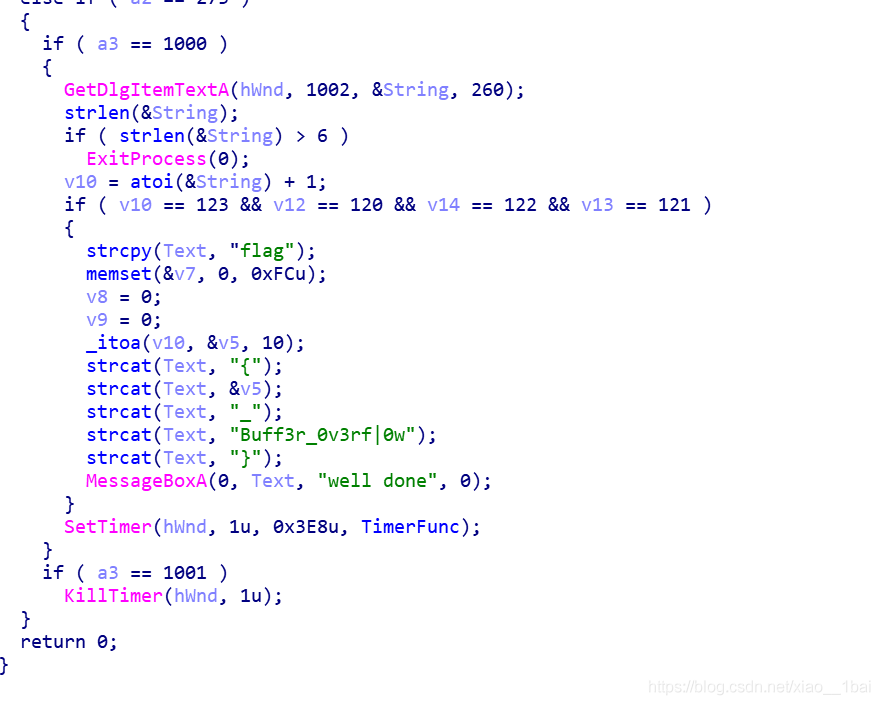
邏輯很簡單,真的簡單,但我就是錯了:
錯誤1:習慣性的字串反轉,這里不是記憶體操作,就是列印Text這個字串,所以不用反轉:
MessageBoxA(0, Text, "well done", 0);
錯誤2:我把v10的123轉成ASCII字符了,對應的字符是{,于是我就得到一個神奇的flag:
flag{{_Buff3r_0v3rf|0w}
這個當然是錯的,關鍵是我還直接以為這是假的flag代碼而去尋找其它函式去了,
后面就引發了一系列問題,比如設想Crack按鈕按不下是不是要動態調整調整跳轉等等:
結果是失敗的,我都不知道它是從那個函式跳出來的!!!
后來查了資料(WP)才發現,flag的確在這里,關鍵是{寫成123即可,不用轉ASCII字符,想想也對flag就是數字字符的結合啊!!!
所以最后flag:
flag{123_Buff3r_0v3rf|0w}
至于那個crack按鈕為什么按不下,可能考點不在那吧~
攻防世界流浪者:(多層交叉參考查看、函式邏輯封裝、范圍演算法積累、函式積累)
32位PE檔案無殼,照例扔入ida32中查看偽代碼:
是沒有主函式的題型,那就運行程式提取有用資訊:
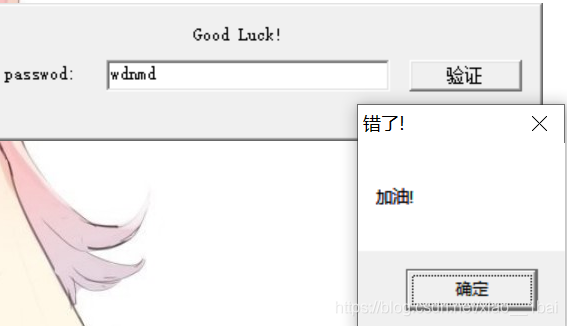
資訊提取完了,一個彈框,一個判斷,根據字串我們可以找到彈框所在函式,彈框是messagebox函式,而import中只有一個messagebox,雙擊跟蹤即可:
發現主要邏輯不在該函式處,查看該函式被誰呼叫,用IDA權威指南學到的新技巧,function call視窗:
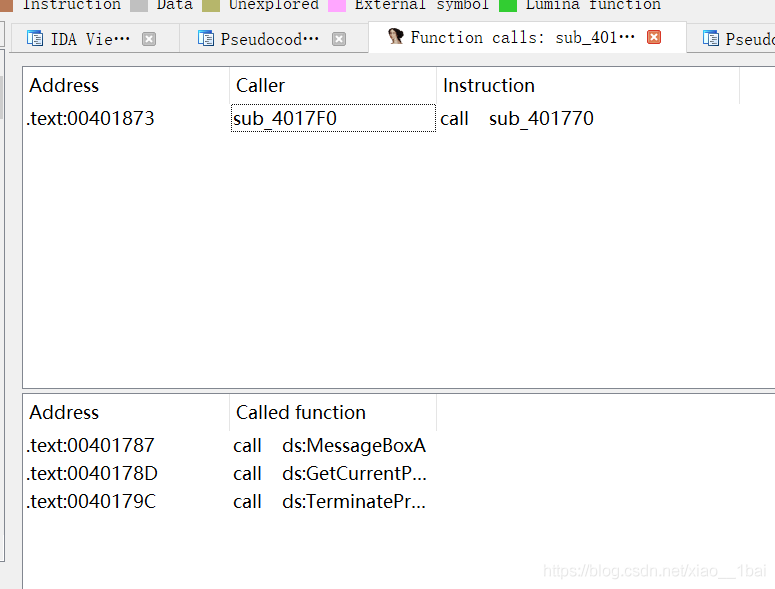
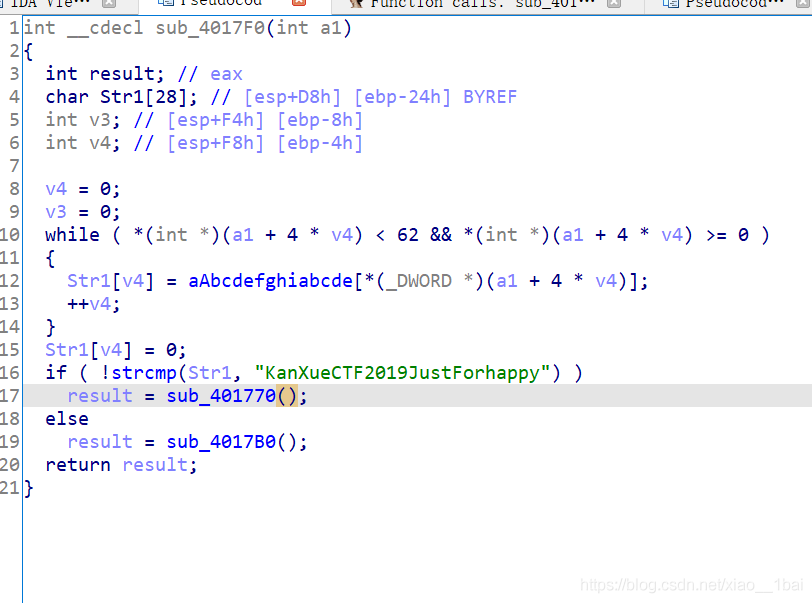
找到比較函式,但是沒有找到輸入函式,繼續查看被誰呼叫,繼續function call視窗:
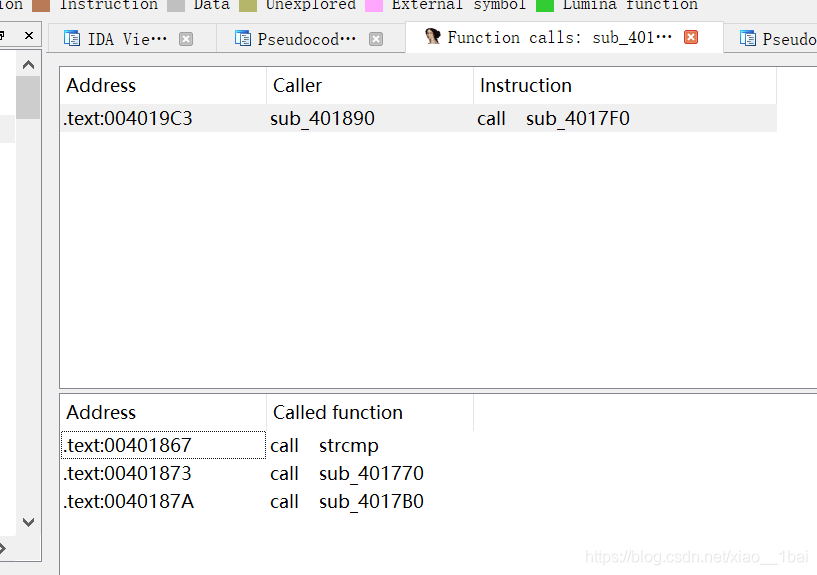
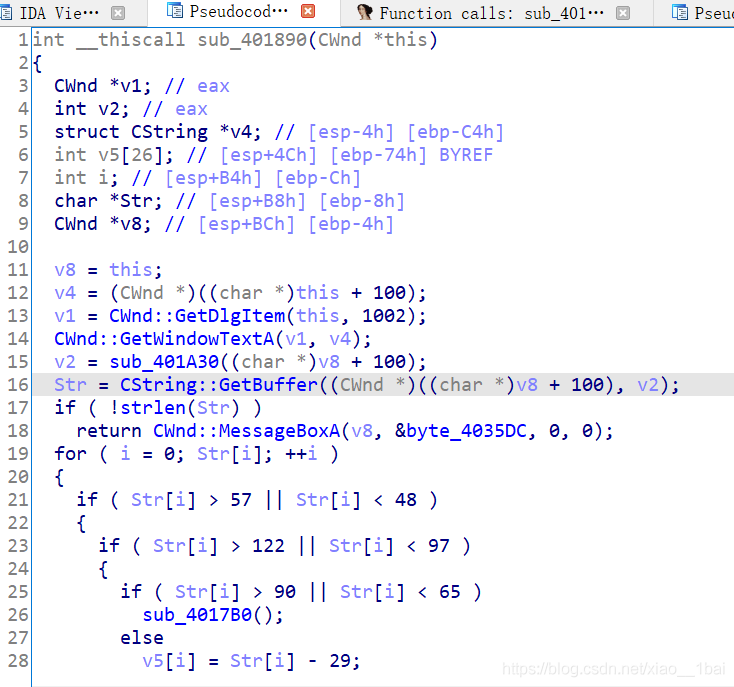
找到函式了,按照流程走,我們要判斷是和輸入有關的生成型flag還是簡單的存盤型flag,答案是前者,而且是明文密文對照型別,那就開始代碼分析:
v4 = (CWnd *)((char *)this + 100);
v1 = CWnd::GetDlgItem(this, 1002); //這些系統函式一開始嚇到我了,雖然系統函式一直不是什么考點,但還是認為這里會有和輸入相關的東西,后來下載了API的chm檔案查了一下作用,的確,后面的GetBuffer應該就是獲取用戶輸入了,但只是獲取而已,相當于scanf,知道即可,還是沒什么考點
CWnd::GetWindowTextA(v1, v4);
v2 = sub_401A30((char *)v8 + 100);
Str = CString::GetBuffer((CWnd *)((char *)v8 + 100), v2);
if ( !strlen(Str) )
return CWnd::MessageBoxA(v8, &byte_4035DC, 0, 0); //彈框函式,這里犯下第一個錯誤,IDA雙擊進去的資料都是db型別的,而我們一開始看到的彈框顯示的是中文,所以我們要改型別為dd型別才可以,不然就顯示不了中文,所以&byte_4035DC跟蹤進去后要用熱鍵D改為dd型別再轉字符,
for ( i = 0; Str[i]; ++i ) //把輸入的字串逐個判斷條件并根據不同條件修改,
{
if ( Str[i] > 57 || Str[i] < 48 )
{
if ( Str[i] > 122 || Str[i] < 97 )
{
if ( Str[i] > 90 || Str[i] < 65 )
sub_4017B0(); //有一個不是彈框范圍內就回傳失敗
else
v5[i] = Str[i] - 29; //范圍在65~90中,輸出結果在36~61中
}
else
{
v5[i] = Str[i] - 87; //范圍在97~122中,輸出結果在10~35中
}
}
else
{
v5[i] = Str[i] - 48; //范圍在48~57中,輸出結果在0~9中
}
}
return sub_4017F0((int)v5); //把修改后的陣列結果作為引數賦給后面密文對照函式,
密文對照函式:
int __cdecl sub_4017F0(int a1)
{
int result; // eax
char Str1[28]; // [esp+D8h] [ebp-24h] BYREF
int v3; // [esp+F4h] [ebp-8h]
int v4; // [esp+F8h] [ebp-4h]
v4 = 0;
v3 = 0;
while ( *(int *)(a1 + 4 * v4) < 62 && *(int *)(a1 + 4 * v4) >= 0 )
{
Str1[v4] = aAbcdefghiabcde[*(_DWORD *)(a1 + 4 * v4)]; //aAbcdefghiabcde雙擊跟蹤是abcdefghiABCDEFGHIJKLMNjklmn0123456789opqrstuvwxyzOPQRSTUVWXYZ'的62位長度字串,也就不難解釋while判斷條件的<62了,這里還犯下第二,第三個錯誤,第二個錯誤是一開始沒看出來這是個陣列,*(_DWORD *)(a1 + 4 * v4)是取索引而已,a1是陣列頭地址,現在要知道帶方括號的[]基本都是陣列取字符! 第三個錯誤是這里*(_DWORD *)(a1 + 4 * v4)型我是真的搞不懂,明明a1是int型,還是陣列頭地址,它前面的(_DWORD *)把它又變成了uint32型地址,先不說這多此一舉,關鍵是int型地址+1就是加4個位元組啊!這里直接+4*v4,那不是一下就跳過4個a1陣列元素了嗎!關鍵是我除錯IDA既然沒有問題!!!好吧,只能認為是IDA分析出錯了,
++v4;
}
Str1[v4] = 0;
if ( !strcmp(Str1, "KanXueCTF2019JustForhappy") ) //從字典中獲取的字符與明文對比,符合就是flag
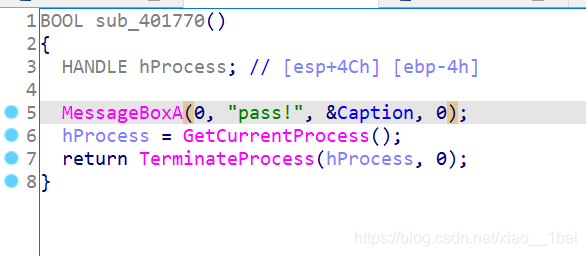
result = sub_401770();
else
result = sub_4017B0();
return result;
}
所以現在就是字典和明文的加密關系逆向題了,這里犯下第四個錯誤,這類明文字典密文題目逆向要從密文出發,找到對應的字典下標,再用下標陣列反邏輯逆向出明文:
第一步從密文出發,找到對應的字典下標:
key1="abcdefghiABCDEFGHIJKLMNjklmn0123456789opqrstuvwxyzOPQRSTUVWXYZ"
key2="KanXueCTF2019JustForhappy"
suoyin=[]
suoyin2=[]
v4=0
for i in range(len(key2)):
for a in range(len(key1)):
if key2[i] == key1[a]:
suoyin.append(a)
print(suoyin)
#print(len(suoyin))
這是我的做法,逐個對比,找出下標,當然后面還學到更好的.index(str)方法,后面會講,輸出:
[19, 0, 27, 59, 44, 4, 11, 55, 14, 30, 28, 29, 37, 18, 44, 42, 43, 14, 38, 41, 7, 0, 39, 39, 48]
這就是字典索引了,然后后面逆向出明文時就犯錯了,逆向,是從底部出發向上走,也是是我們一開始掌握的是結果,要從條件中有關結果的判斷往上走,而不是從0~1000這樣從上往下加密然后提取出對應條件的下標,雖然結果一樣,但是流程就差太多了:
suoyin2=[19, 0, 27, 59, 44, 4, 11, 55, 14, 30, 28, 29, 37, 18, 44, 42, 43, 14, 38, 41, 7, 0, 39, 39, 48]
v5=0
flag=""
for i in suoyin2: //這里的判斷條件是從從條件中有關結果的判斷往上走,因為前面寫出了結果的范圍,所以我們應該用結果的范圍向上走,
if i >= 0 and i <= 9:
v5=i+48
elif i >= 10 and i <= 35:
v5=i+87
elif i >= 36:
v5=i+29
flag+=chr(v5)
print(flag)
輸出:
j0rXI4bTeustBiIGHeCF70DDM
別人更好的利用.index獲取索引下標的腳本:
table = "abcdefghiABCDEFGHIJKLMNjklmn0123456789opqrstuvwxyzOPQRSTUVWXYZ"
s = "KanXueCTF2019JustForhappy"
ff = []
for i in s:
ff.append(table.index(i)) //這里我不得不說真的妙,我是一時想不到,用字串內置函式.index(str)完美輸出索引,比我快多了,
flag = ""
for i in ff:
if 0 <= i <= 9:
flag += chr(i + 48)
elif 9 < i <= 35:
flag += chr(i + 87)
elif i > 36:
flag += chr(i + 29)
print (flag)
攻防世界srm-50:
windows的32位程式,無殼,運行一下判斷主要展示資訊,看樣子以為是逆向工程核心原理的例題,就是繞過注冊條件的,結果后面發現不是:
知道了一些特定字串,和判斷陳述句,資訊夠了,照例扔入IDA32中查看偽代碼,有main函式看main函式,這里是Winmain函式:

跟蹤,無果,照例下一步查看string視窗,鎖定一開始展示字串的位置:
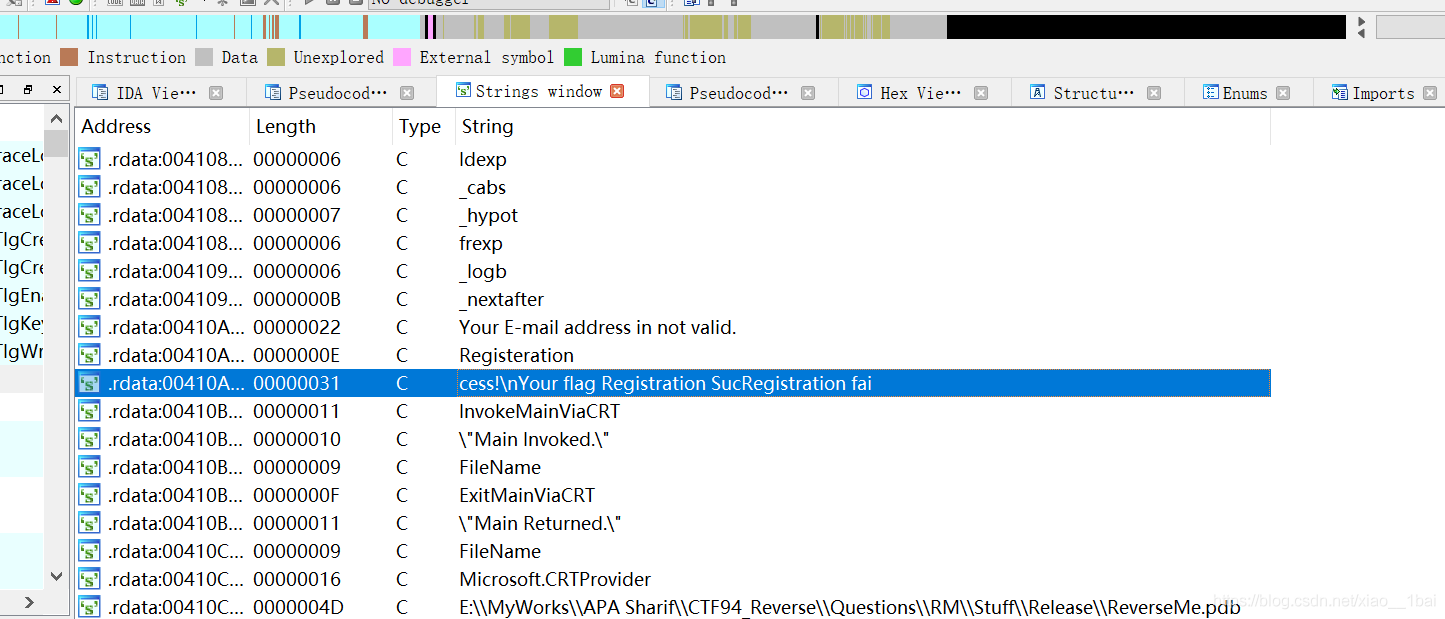
找到了,雙擊跟蹤,然后跟蹤到參考它的函式:
答案很明顯了,flag就是Registration Success!\nYour flag is:陳述句的下面一串字符,轉字符后按序號排好即可:
攻防世界hackme:(可變引數混淆、隨機抽取比較、取特定位數演算法)
64位ELF檔案無殼,照例扔入IDA64中查看偽代碼資訊,有main函式看main函式,結果沒有main函式:
沒有main函式就運行程式收集顯示資訊:

找到兩個字串,直接在strings視窗雙擊跟蹤,找到主要邏輯函式:
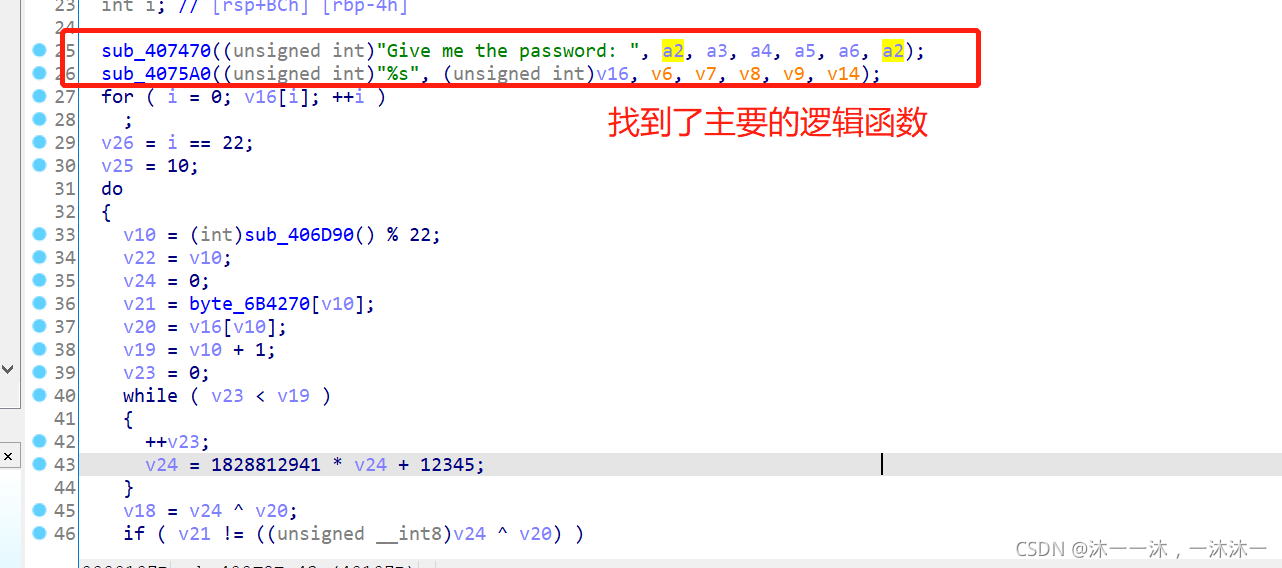
這里積累第一個經驗:如上圖紅框所示
sub_407470((unsigned int)“Give me the password: “, a2, a3, a4, a5, a6, a2);
sub_4075A0((unsigned int)”%s”, (unsigned int)v16, v6, v7, v8, v9, v14);
人傻了,這么多個引數,雙擊跟蹤進去不是嵌套就是復雜代碼,查看反匯編,好像又沒有呼叫這么多引數,以為是什么復雜的高端函式,開始怕了,結果才發現,這就是根據C語言函式可變引數的特性反匯編出來的,其實就是普通的輸出和輸入函式而已,果然還是自己經驗太少,太菜了~,
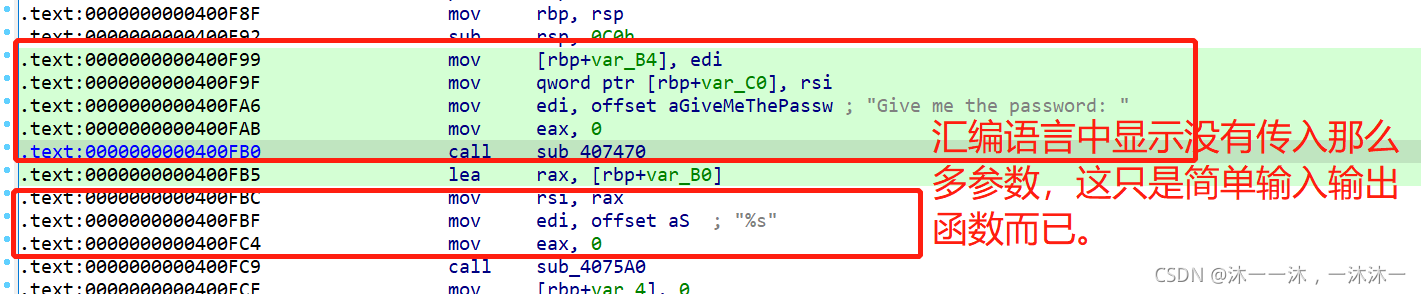
跨過這個坎繼續往下走,第一個紅框v10范圍是0~21,第二個紅框陣列又以v10作為下標,猜測是一個22的遍歷陣列操作,第三個紅框是判斷,所以逆向邏輯很簡單,關鍵是最外面的v25的10次回圈后面查了資料說是v10是一個亂數,范圍也的確是0 ~ 21,但是不是順序來取值的,結合外面v25的10回圈就是隨機從陣列中抽取10個下標來比較,那我們直接順序取整個下標操作也是一樣的,
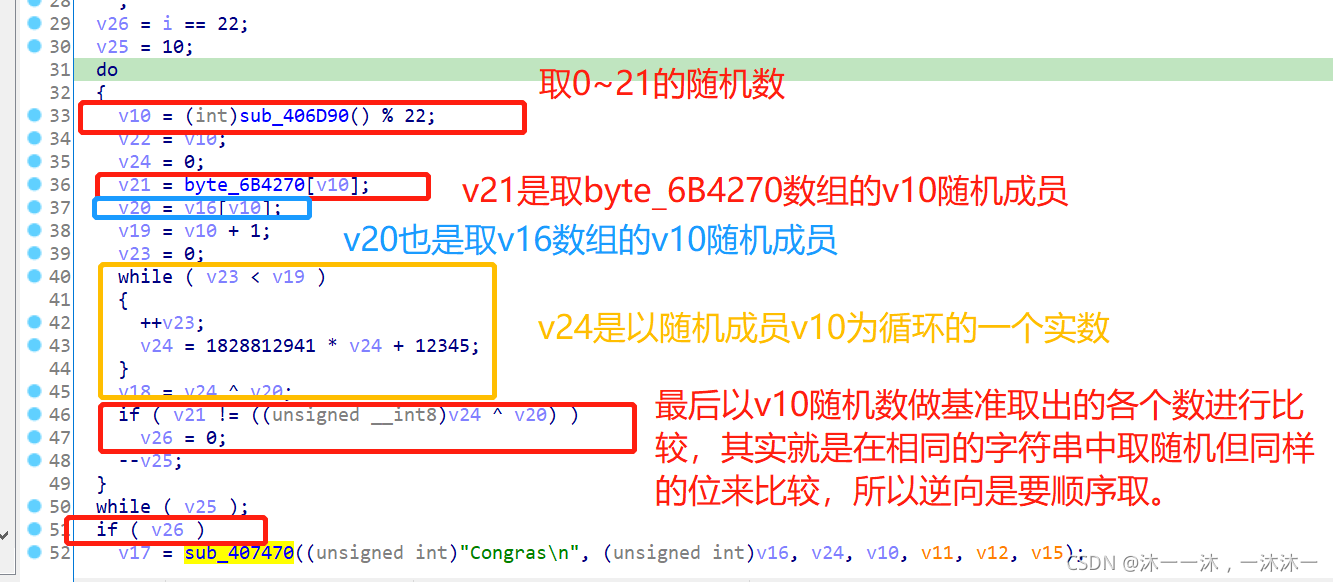
根據前面回顧的逆向解題流程:
第一步確定Flag字符數量,
第二步找到已確定的字串作為基點來反推falg字符,
第三步找出邏輯中與flag直接相關的部分,該部分可以正向爆破或者從尾到頭的反向邏輯,
然后找到與flag沒有直接關聯的部分,該部分無需逆向邏輯,直接正向流程復現即可,
按照流程來即可寫出逆向邏輯腳本:
key1=[95, 242, 94, 139, 78, 14, 163, 170, 199, 147, 129, 61, 95, 116, 163, 9, 145, 43, 73, 40, 147, 103]
flag=""
for i in range(10):
for a in range(22):
v15=0
v12=key1[a]
v10=a+1
v14=0
for i in range(v10):
v14+=1
v15=1828812941*v15+12345
flag+=chr((v12^v15)&0xff)
print(flag)
最后這里積累第二個經驗:
一開始我flag+=chr((v12^v15)&0xff)沒加 &0xff,然后報錯,我以為源程式中會有溢位導致的數重置,但是想起程式是64位的,不應該超范圍啊,然后我看到源代碼有__int8這個限制,這是取前8位啊,可是python中怎么取前8位呢?查了資料才發現有&0xff這種方法,因為&在Python中是邏輯與運算,所以與的時候就保留了v12 ^ v15的前8位,就達到取前8位的目的了,取前16,32位都可以套用這個方法,

結果:(這里我一開始沒理解是隨機抽取10次,所以我照搬,結果回圈了10次)

帶殼題目型別
脫殼后邏輯平鋪:
攻防世界simple-unpack脫殼:(工具脫殼)
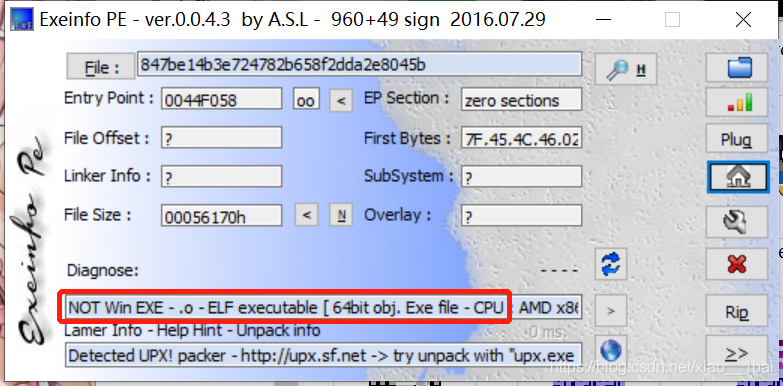
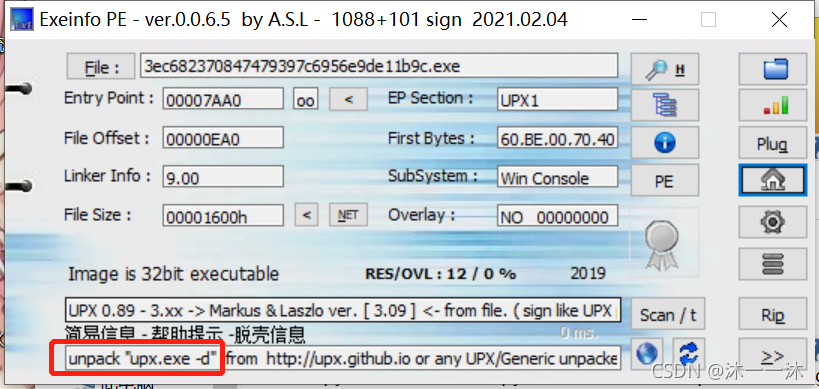
顯示說探測到UPX殼,由于第一次做帶殼的題目,所以查到了以下資料:
UPX (the Ultimate Packer for eXecutables)是一款先進的可執行程式檔案壓縮器,壓縮過的可執行檔案體積縮小50%-70% ,這樣減少了磁盤占用空間、網路上傳下載的時間和其它分布以及存盤費用, 通過 UPX 壓縮過的程式和程式庫完全沒有功能損失和壓縮之前一樣可正常地運行,對于支持的大多數格式沒有運行時間或記憶體的不利后果, UPX 支持許多不同的可執行檔案格式 包含 Windows 95/98/ME/NT/2000/XP/CE 程式和元件、DOS 程式、 Linux 可執行檔案和核心,
UPX是一個壓縮工具,好在今天準備看《逆向核心工程原理》這本書的壓縮部分,原來這就是壓縮,之前也學了一點PE檔案格式,知道了一些檔案資源的存放位置,那么下一步就是脫殼了,
查到了kali中關于UPX的脫殼命令:
upx -d filename
脫完殼就可以直接IDA查看了,FLAG直接就顯示出來了:
IDA等二進制分析器應該都需要完整的檔案格式才能分析,壓縮后(加殼)的檔案由于并沒有破壞可執行檔案的格式規則,所以還是可以運行的,用IDA分析加殼后的檔案就分析不出來了,如圖:
攻防世界Windows_Reverse1:(工具脫殼、不能直接運行、暫存器傳參、地址差值+陣列組合遍歷字串、字符ASCII碼做索引、ASCII碼表相關)
下載附件,照例扔入exeinfope中查看資訊:
UPX殼,32位windows中,扔入我的kali中先用命令upx -d 檔案名 脫殼先:
雙擊運行不了,查看不了起始資訊,看了資料說:
UPX的殼,手動脫殼或者脫殼機脫殼,但發現脫完殼的程式在win7下打不開,即使是顯示沒殼(這里后來查到win7包括以上版本開啟了ASLR(地址隨機化),winxp就沒有,如果程式采用絕對地址,在win7和win10上就運行不了),直接IDA啟動,IDA里不爆紅就沒事,
不管了,IDA分析偽代碼:
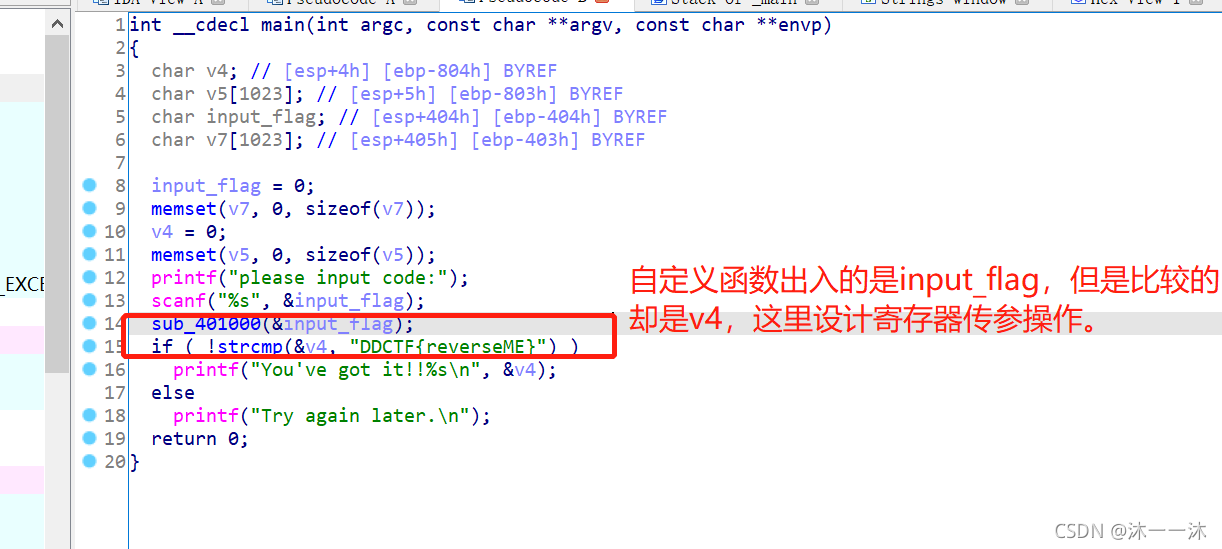
代碼一目了然,神奇的是紅框框起來的地方,這里積累第一個經驗:出入的是input_flag(v6改名而來),結果比較的是v4,一開始我以為是IDA出了錯誤,后來才發現題目考的就是我以前一直說得地址偏移間接操作,v4存入了暫存器中,暫存器再作為引數傳入關鍵自定義函式中,IDA沒有反匯編出暫存器引數,用的是暫存器操作,
input_flag點進去-00000404 var_404 db ?
v4點進去-00000804 var_804 db ?
這里積累第二個經驗:
查看反匯編代碼,前面有sub esp, 804h,所以esp+804h處可以說是基址EBP的地方,這里的[esp+82Ch+input_flag]和[esp+830h+v4]只是在esp+804h的EBP基礎上加上中間代碼的指令位元組長度而已,本質就是取input_flag和v4引數,

這里Input_flag和v4分別給了eax和ecx,我們查看sub_401000函式的反匯編代碼和函式圖都可以發現ECX(v4)被使用了:
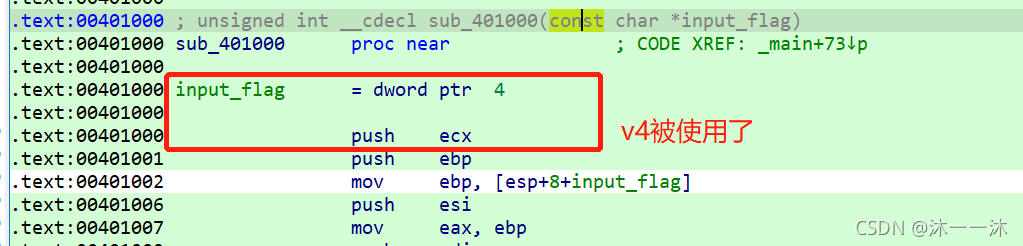
所以我們分析邏輯代碼:(地址差值+陣列組合遍歷字串,單個字符ASCII碼作為索引)
unsigned int __cdecl sub_401000(const char *input_flag)
{
_BYTE *v1; // ecx即外部v4,這里用v1來接受暫存器ecx的值,且值為0
unsigned int v2; // edi
unsigned int result; // eax
int v4; // ebx
v2 = 0;
result = strlen(input_flag);
if ( result )
{
v4 = input_flag - v1; //這里積累第三個經驗:地址減地址取差值,這里v4是Input_flag和v1(主函式v4)的地址的差值,差值剛好在32,后面梳理完后發現byte_402FF8是ASCII碼表,32后是可列印字符
do
{
*v1 = byte_402FF8[(char)v1[v4]]; //這里積累第四個經驗:這里V1作為地址和v4作為陣列v1[v4]執行的是v1+v4的操作,就是v4+v1=input_flag啊,因為陣列a[b]本質就是在陣列頭地址a加上偏移量b來遍歷陣列的,所以這里是一種遍歷input_flag的新操作,至于最外面的byte_402FF8[]陣列框,應該這樣理解,v1[v4]逐個取input_flag的單個字符,這個字符的ascii碼作為偏移繼續在byte_402FF8[]陣列中尋址,(PS:這不是Python中list.index()函式可以用字符查找對應索引!),最后ECX暫存器的v1接受了新的flag,
++v2;
++v1;
result = strlen(input_flag);
}
while ( v2 < result );
}
return result;
}
也附上別人博客的解釋:(本是字符本身作為索引)
1:a1是通過壓堆疊的方式傳遞的引數; v1是通過暫存器保存地址的方式傳遞的引數,
2:最令人迷惑的便是v1[v4]這個地方. v1是一個地址, v4是a1和v1兩個地址間的差值. 地址的差值是怎么成為一個陣列的索引的呢 ?
3:這里卡了我好長時間, 之后我突然意識到, v1[v4]和v1+v4是等價的, 而在回圈剛開始的時候v1+v4等于a1, 隨著v1的遞增,v1[v4]也會遍歷a1陣列中的各個元素的地址,
4:而地址又怎么能作為陣列的索引呢? 這里就是 IDA 背鍋了, 換言之, 做題還是不能太依賴于反編譯后的偽代碼. 查看了反匯編代碼后, 發現其實是將a1字串中的字符本身作為byte_402FF8的索引, 取值后放入v1陣列中,
雙擊跟蹤byte_402FF8[]陣列:
可以看到前面亂碼的?,后面倒是有字串,陣列地址偏移從0x00402FF8~0x00403078,
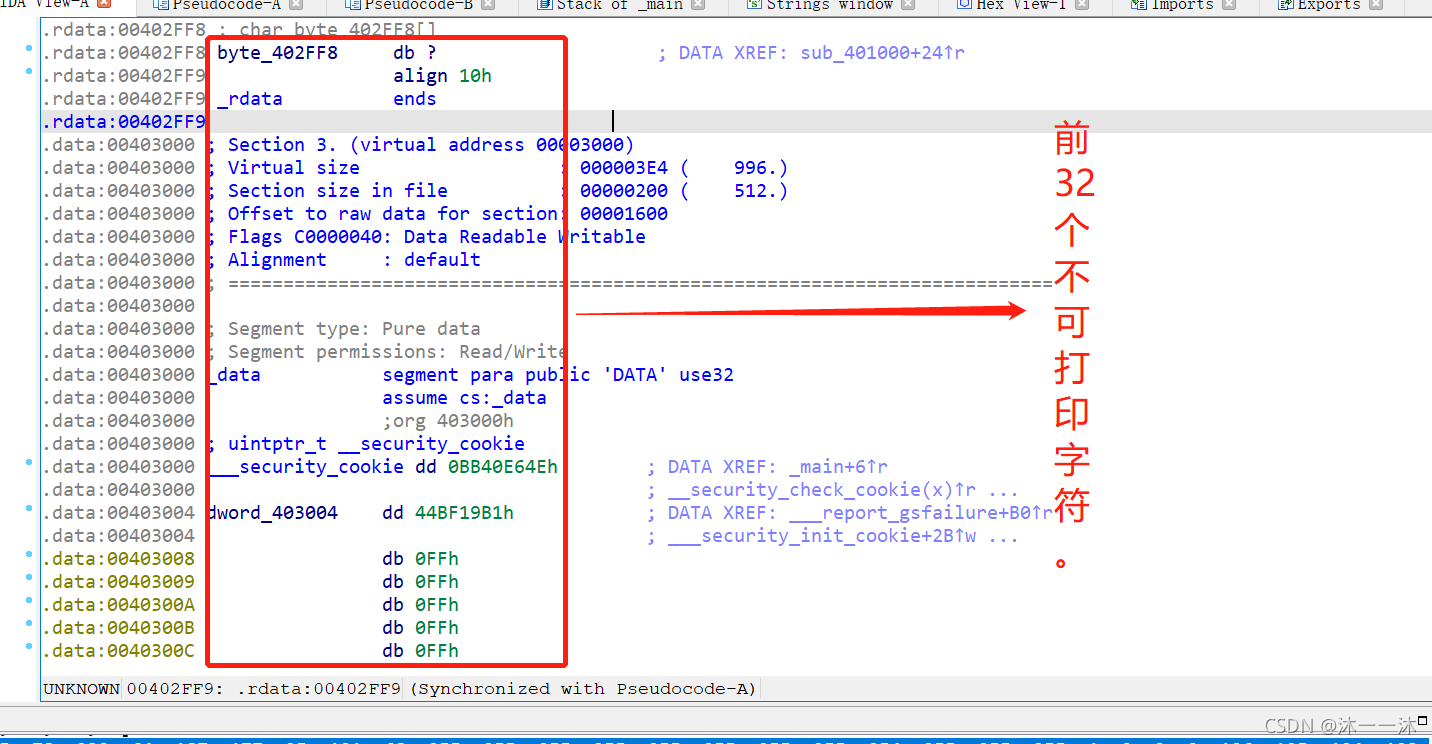
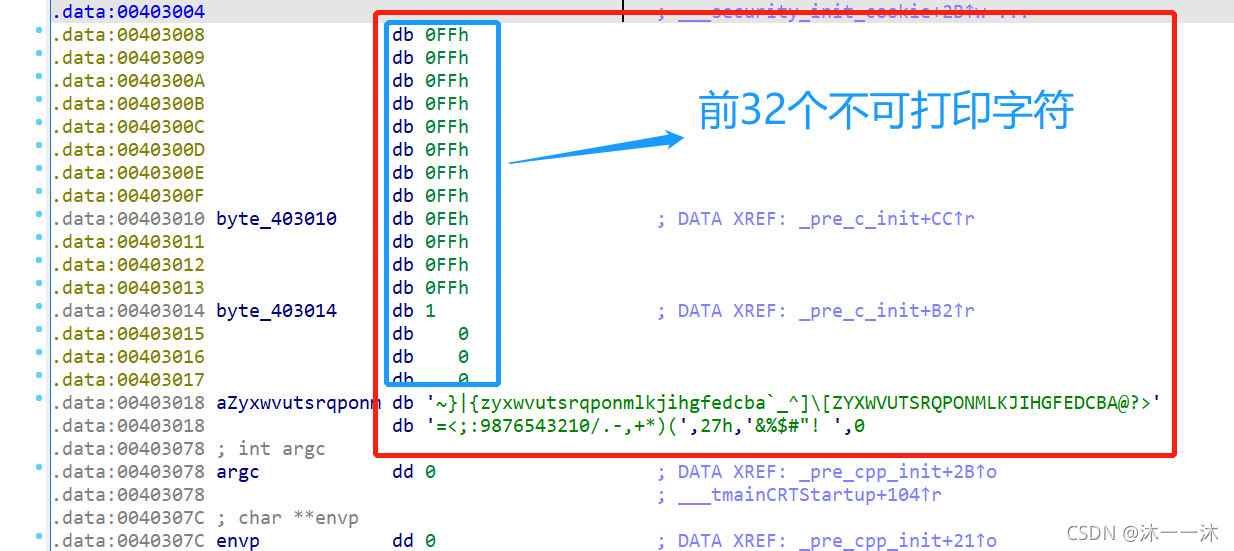
這里積累第5個經驗:(ASCII碼表可視字符范圍)
ASCII編碼表里的可視字符就得是32往后了, 所以, byte_402FF8里凡是位于32以前的數統統都是迷惑項. 不會被索引到的,而這里0x00402FF8~0x00403017剛好是32個字符,那么后面有字串就可以解釋通了,它們是連在一起的,
陣列有了,邏輯有了,逆向邏輯很簡單,先用IDA腳本列印0x00402FF8~0x00403078陣列處的地址內容先:
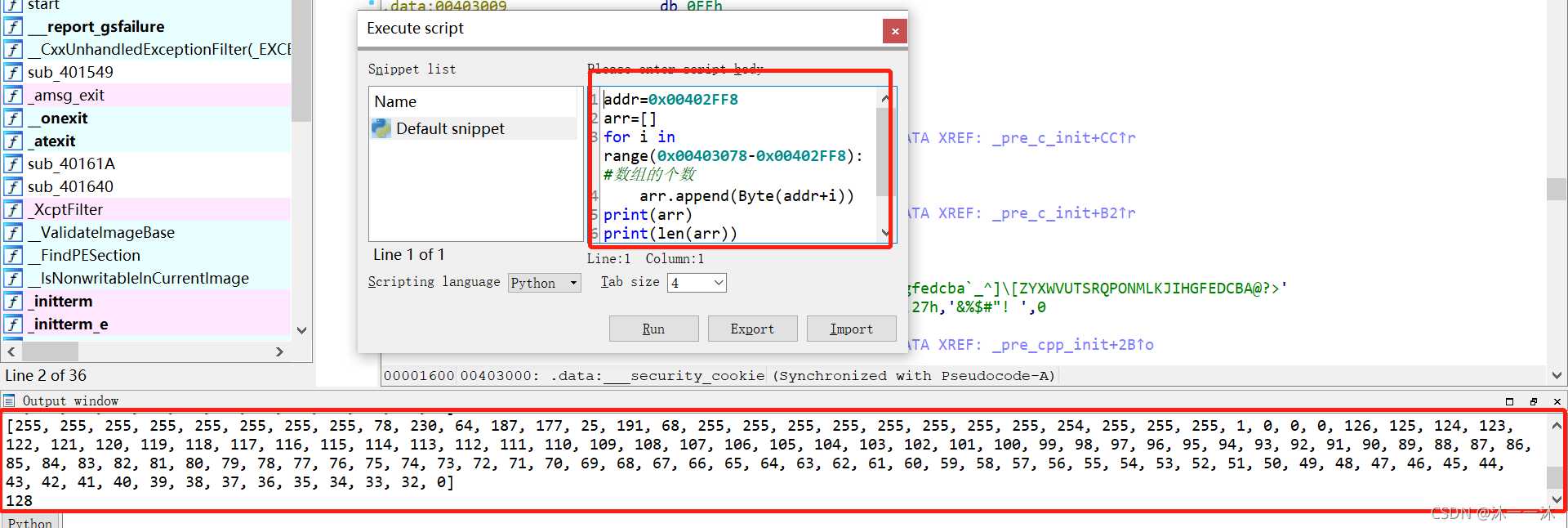
復制陣列內容寫逆向腳本:
key1=[255, 255, 255, 255, 255, 255, 255, 255, 78, 230, 64, 187, 177, 25, 191, 68, 255, 255, 255, 255, 255, 255, 255, 255, 254, 255, 255, 255, 1, 0, 0, 0, 126, 125, 124, 123, 122, 121, 120, 119, 118, 117, 116, 115, 114, 113, 112, 111, 110, 109, 108, 107, 106, 105, 104, 103, 102, 101, 100, 99, 98, 97, 96, 95, 94, 93, 92, 91, 90, 89, 88, 87, 86, 85, 84, 83, 82, 81, 80, 79, 78, 77, 76, 75, 74, 73, 72, 71, 70, 69, 68, 67, 66, 65, 64, 63, 62, 61, 60, 59, 58, 57, 56, 55, 54, 53, 52, 51, 50, 49, 48, 47, 46, 45, 44, 43, 42, 41, 40, 39, 38, 37, 36, 35, 34, 33, 32, 0]
key2="DDCTF{reverseME}"
flag=""
for i in key2:
flag+=chr(key1[ord(i)]) //字符的ASCII碼作為索引
print("flag{"+flag+"}")
結果:

攻防世界Replace:(工具脫殼、解題逆向模板、>> 和 % 運算子演算法積累、正向爆破)
有殼,用Kali的upx -d脫殼,然后照例扔入IDA32中查看偽代碼,有main函式看main函式:(脫殼后不能運行,因為偽代碼資訊足夠,所以就不用修復了)
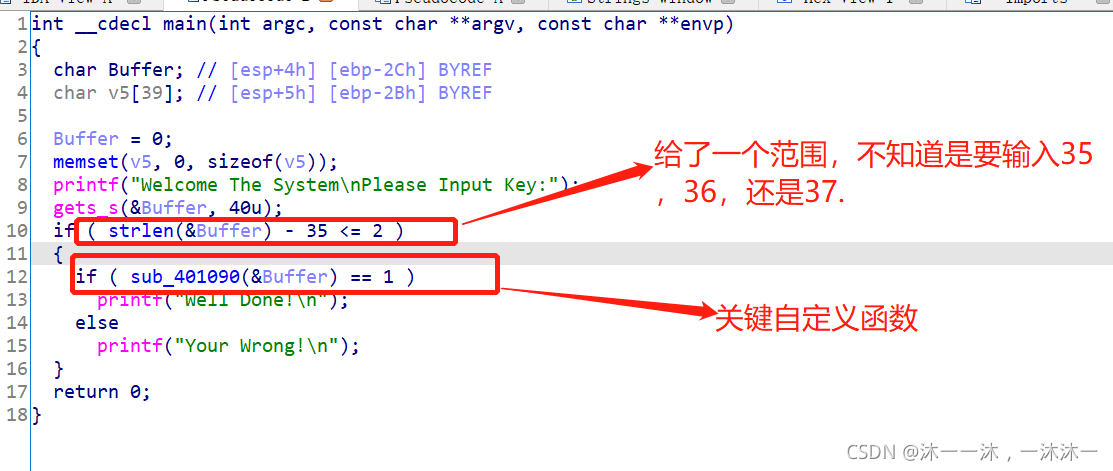
直接跟蹤第二個紅框自定義函式:
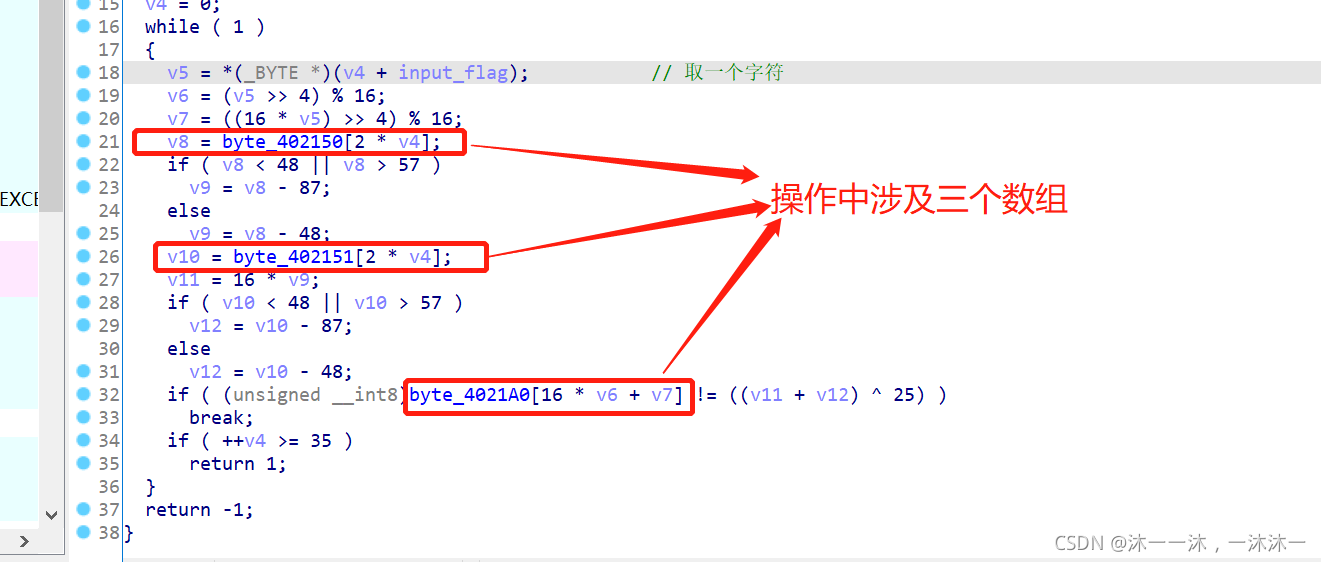
主要邏輯在上面了,涉及三個陣列,用IDA內嵌腳本dump下來,這里積累第一個經驗:陣列dump下載的時候dump到0字符結尾處,不要怕dump多,就怕dump少,
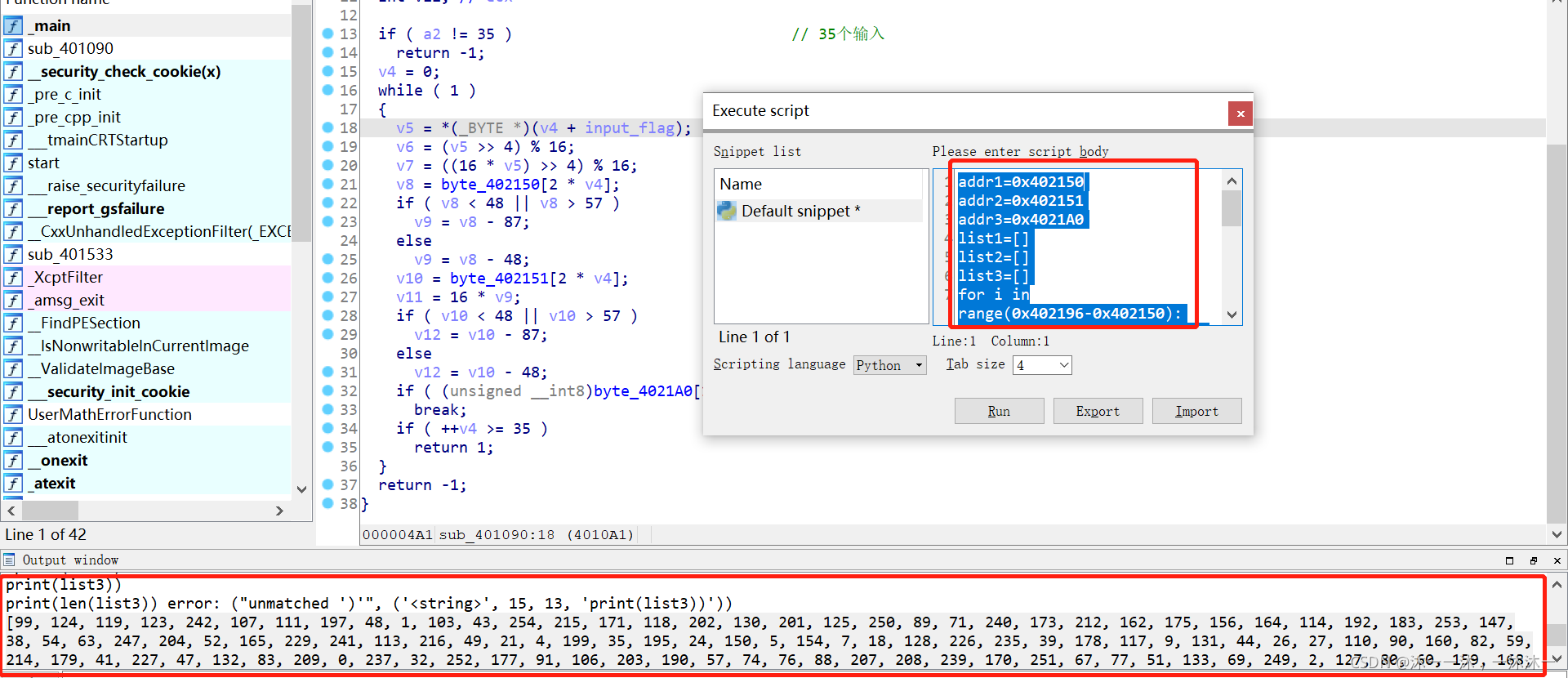
開始撰寫逆向邏輯腳本,這里積累第二個經驗:主要回顧一下每一步的思路,給日后自己增添一些解題模板,
第一步確定Flag字符數量,第一個紅框處得到flag數量是35,
第二步找到已確定的比較字串作為基點來反推flag字符,如第二個紅框處,
第三步找出邏輯中與flag直接相關的部分,該部分可以正向爆破或者從尾到頭的反向邏輯,如第一個紅框所示,然后找到與flag沒有直接關聯的部分,該部分無需逆向邏輯,直接正向流程復現即可,如第二個紅框所示,
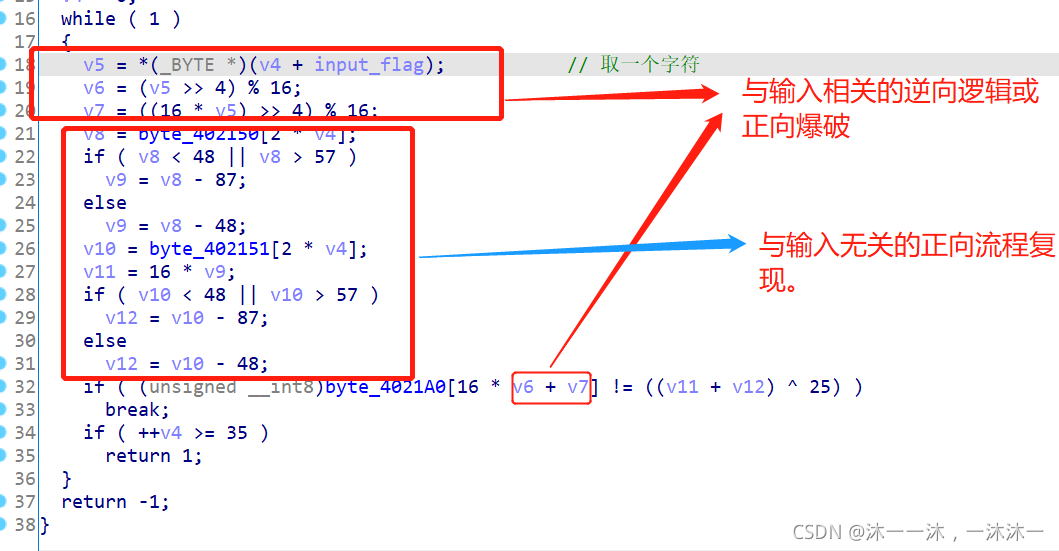
梳理完這些之后就可以寫腳本了:
腳本1,爆破,這里積累第三個經驗:由于用了取余 % 運算,所以采用列舉正向爆破的方法,讓flag中的每一個字符遍歷常用的字符(ascii碼表中32-126),帶入加密演算法,如果成功,就把這個flag存入,
list1=[50, 97, 52, 57, 102, 54, 57, 99, 51, 56, 51, 57, 53, 99, 100, 101, 57, 54, 100, 54, 100, 101, 57, 54, 100, 54, 102, 52, 101, 48, 50, 53, 52, 56, 52, 57, 53, 52, 100, 54, 49, 57, 53, 52, 52, 56, 100, 101, 102, 54, 101, 50, 100, 97, 100, 54, 55, 55, 56, 54, 101, 50, 49, 100, 53, 97, 100, 97, 101, 54]
list2=[97, 52, 57, 102, 54, 57, 99, 51, 56, 51, 57, 53, 99, 100, 101, 57, 54, 100, 54, 100, 101, 57, 54, 100, 54, 102, 52, 101, 48, 50, 53, 52, 56, 52, 57, 53, 52, 100, 54, 49, 57, 53, 52, 52, 56, 100, 101, 102, 54, 101, 50, 100, 97, 100, 54, 55, 55, 56, 54, 101, 50, 49, 100, 53, 97, 100, 97, 101, 54]
list3=[99, 124, 119, 123, 242, 107, 111, 197, 48, 1, 103, 43, 254, 215, 171, 118, 202, 130, 201, 125, 250, 89, 71, 240, 173, 212, 162, 175, 156, 164, 114, 192, 183, 253, 147, 38, 54, 63, 247, 204, 52, 165, 229, 241, 113, 216, 49, 21, 4, 199, 35, 195, 24, 150, 5, 154, 7, 18, 128, 226, 235, 39, 178, 117, 9, 131, 44, 26, 27, 110, 90, 160, 82, 59, 214, 179, 41, 227, 47, 132, 83, 209, 0, 237, 32, 252, 177, 91, 106, 203, 190, 57, 74, 76, 88, 207, 208, 239, 170, 251, 67, 77, 51, 133, 69, 249, 2, 127, 80, 60, 159, 168, 81, 163, 64, 143, 146, 157, 56, 245, 188, 182, 218, 33, 16, 255, 243, 210, 205, 12, 19, 236, 95, 151, 68, 23, 196, 167, 126, 61, 100, 93, 25, 115, 96, 129, 79, 220, 34, 42, 144, 136, 70, 238, 184, 20, 222, 94, 11, 219, 224, 50, 58, 10, 73, 6, 36, 92, 194, 211, 172, 98, 145, 149, 228, 121, 231, 200, 55, 109, 141, 213, 78, 169, 108, 86, 244, 234, 101, 122, 174, 8, 186, 120, 37, 46, 28, 166, 180, 198, 232, 221, 116, 31, 75, 189, 139, 138, 112, 62, 181, 102, 72, 3, 246, 14, 97, 53, 87, 185, 134, 193, 29, 158, 225, 248, 152, 17, 105, 217, 142, 148, 155, 30, 135, 233, 206, 85, 40, 223, 140, 161, 137, 13, 191, 230, 66, 104, 65, 153, 45, 15, 176, 84, 187, 22, 72, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
v4=0
flag=""
for i in range(35):
v8=list1[2*i]
if v8 < 48 or v8 > 57:
v9=v8 - 87
else:
v9=v8 - 48
v10=list2[2*i]
v11=16*v9
if v10 <48 or v10 > 57:
v12=v10-87
else:
v12=v10-48
v4=((v11+v12)^25) #這里前面都是與flag沒有直接關聯的正向流程復現
for a in range(32,127): #取余型別正向爆破,如果符合比較,就獲取對應字符,
v5=a
v6=(v5>>4)%16 #邏輯都是一樣的,因為是正向爆破
v7=((16*v5)>>4)%16
if list3[16*v6+v7] == v4:
flag+=chr(a)
print(flag)
腳本2:這里積累第四個經驗:>> 運算子其實是不帶余數的除法 / 演算法,單取整數部分,% 運算子其實是不帶整數的求余運算,單取余數部分,
所以這里 v6 = (v5 >> 4) % 16 是除以16后的整數部分, v7 = ((16 * v5) >> 4) % 16 是乘16后除16再取16內的余數,也就是直接取16內的余數,一個取整數,一個取余數,所以他們的逆向演算法就是16 * v6 + v7,就是最后陣列byte_4021A0[16 * v6 + v7]的下標,
(既然v5 >> 4相當于v5除以16取整數部分,是不帶余數的除法 / 演算法,順帶說一下,v5 & 0xf 相當于v5除以16取余數部分,是完全的求余%演算法,這里0xf是4位所以為16,)
所以flag就是由這些下標組成 !
因此如果有些偽代碼中前面的運算邏輯如果和后面的運算邏輯如果有相似之處,要試著判斷他們是反向邏輯,因為出題者的意圖往往如此,
list1=[50, 97, 52, 57, 102, 54, 57, 99, 51, 56, 51, 57, 53, 99, 100, 101, 57, 54, 100, 54, 100, 101, 57, 54, 100, 54, 102, 52, 101, 48, 50, 53, 52, 56, 52, 57, 53, 52, 100, 54, 49, 57, 53, 52, 52, 56, 100, 101, 102, 54, 101, 50, 100, 97, 100, 54, 55, 55, 56, 54, 101, 50, 49, 100, 53, 97, 100, 97, 101, 54]
list2=[97, 52, 57, 102, 54, 57, 99, 51, 56, 51, 57, 53, 99, 100, 101, 57, 54, 100, 54, 100, 101, 57, 54, 100, 54, 102, 52, 101, 48, 50, 53, 52, 56, 52, 57, 53, 52, 100, 54, 49, 57, 53, 52, 52, 56, 100, 101, 102, 54, 101, 50, 100, 97, 100, 54, 55, 55, 56, 54, 101, 50, 49, 100, 53, 97, 100, 97, 101, 54]
list3=[99, 124, 119, 123, 242, 107, 111, 197, 48, 1, 103, 43, 254, 215, 171, 118, 202, 130, 201, 125, 250, 89, 71, 240, 173, 212, 162, 175, 156, 164, 114, 192, 183, 253, 147, 38, 54, 63, 247, 204, 52, 165, 229, 241, 113, 216, 49, 21, 4, 199, 35, 195, 24, 150, 5, 154, 7, 18, 128, 226, 235, 39, 178, 117, 9, 131, 44, 26, 27, 110, 90, 160, 82, 59, 214, 179, 41, 227, 47, 132, 83, 209, 0, 237, 32, 252, 177, 91, 106, 203, 190, 57, 74, 76, 88, 207, 208, 239, 170, 251, 67, 77, 51, 133, 69, 249, 2, 127, 80, 60, 159, 168, 81, 163, 64, 143, 146, 157, 56, 245, 188, 182, 218, 33, 16, 255, 243, 210, 205, 12, 19, 236, 95, 151, 68, 23, 196, 167, 126, 61, 100, 93, 25, 115, 96, 129, 79, 220, 34, 42, 144, 136, 70, 238, 184, 20, 222, 94, 11, 219, 224, 50, 58, 10, 73, 6, 36, 92, 194, 211, 172, 98, 145, 149, 228, 121, 231, 200, 55, 109, 141, 213, 78, 169, 108, 86, 244, 234, 101, 122, 174, 8, 186, 120, 37, 46, 28, 166, 180, 198, 232, 221, 116, 31, 75, 189, 139, 138, 112, 62, 181, 102, 72, 3, 246, 14, 97, 53, 87, 185, 134, 193, 29, 158, 225, 248, 152, 17, 105, 217, 142, 148, 155, 30, 135, 233, 206, 85, 40, 223, 140, 161, 137, 13, 191, 230, 66, 104, 65, 153, 45, 15, 176, 84, 187, 22, 72, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
v4=0
flag=""
for i in range(35):
v8=list1[2*i]
if v8 < 48 or v8 > 57:
v9=v8 - 87
else:
v9=v8 - 48
v10=list2[2*i]
v11=16*v9
if v10 <48 or v10 > 57:
v12=v10-87
else:
v12=v10-48
v4=((v11+v12)^25) #這里前面都是與flag沒有直接關聯的正向流程復現
flag+=chr(list3.index(v4)) #這里知道逆向演算法發現對應下標后,直接Index對要比較的字符v4取索引即可,flag就是索引中下標的內容,
print(flag)
結果:
![]()
花指令題目型別
自定義函式自修改:
攻防世界BABYRE:(函式名稱暗示、IDA熱鍵重新反匯編、IDA動態除錯、堆疊地址連續小陣列)
這題應該是我第一次接觸的花指令題,怪興奮的!目前我的理解是代碼和資料混淆,讓IDA誤認為是資料而反匯編出錯,
64位ELF檔案,無殼,扔入IDA64位中查看偽代碼:
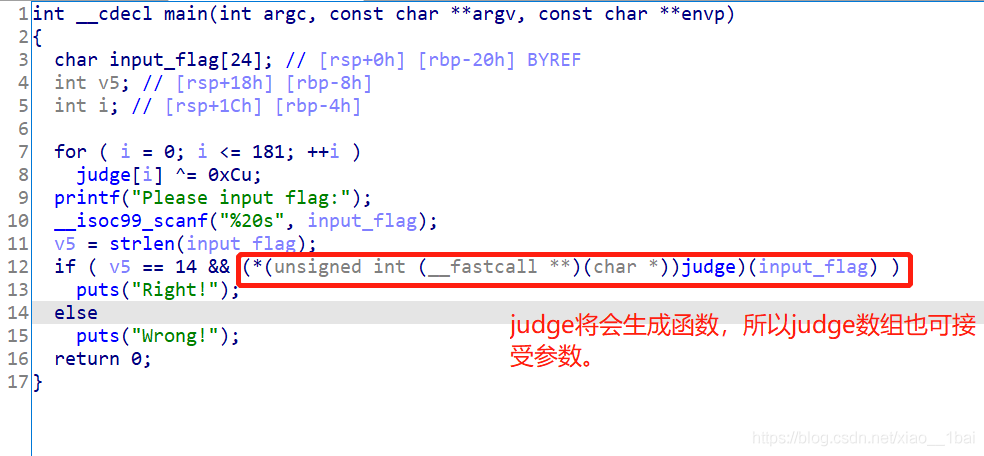
這里犯下第一個錯誤:
由于是第一次接觸花指令,對 (*(unsigned int (__fastcall **)(char *))judge)(input_flag) ) 這一行代碼我看了好久愣是沒看懂,input_flag是我們輸入的字串,judge中文暗示是判斷,根據以前做題這種中文類名字的確是暗示,可前面顯示的judge[i] 這擺明是個陣列啊,judge(input_flag) 不就變成了陣列首地址加Input_flag了嗎?還有這種玩法???
然后我就去看wp了(笑~):
他們大概意思了judge是一個函式名,這個judge函式名的函式呢是通過前面邏輯用資料生成出來的,
想起C語言好像有通過字串拼接生成新命令的技巧,突然就恍然大悟了,
所以這里 (*(unsigned int (__fastcall **)(char *))judge)(input_flag) ) 應該這樣分析,unsigned int 是judge函式的回傳型別,(__fastcall **)是函式的呼叫約定,(char *)這個只是提取judge的陣列頭的一連串字串做函式名而已,
然后看他們WP中顯示judge是雙擊跟蹤跟蹤不了的,會報錯,我的倒是跟蹤得了,長這樣:
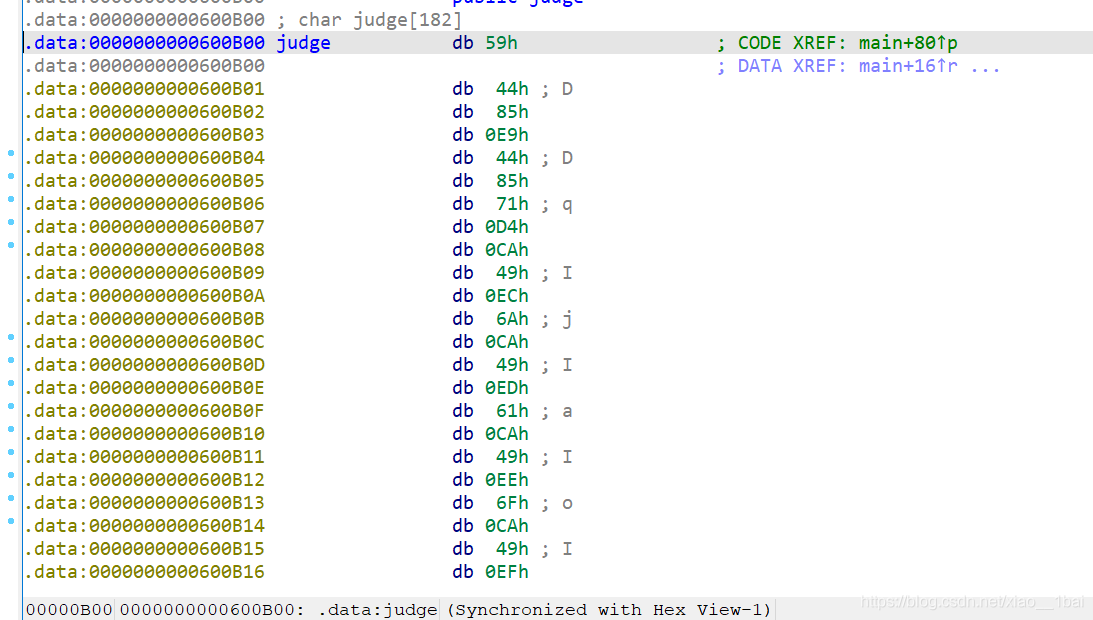
這里犯下第二個錯誤:
一開始這里也卡了我好一會,后來發現是我用了新版的IDA7.5,這里本來有個指標分析錯誤,IDA7.5直接把它當成資料去了,如果我用C(匯編),P(創建函式),在judge開頭處按一下照樣顯示指標分析錯誤:(ps:不按C的話有時IDA會報錯函式在指定地址具有未定義的指令/資料,您的請求已放入自動分析佇列,按一下C可能是提醒它可以轉成資料吧)
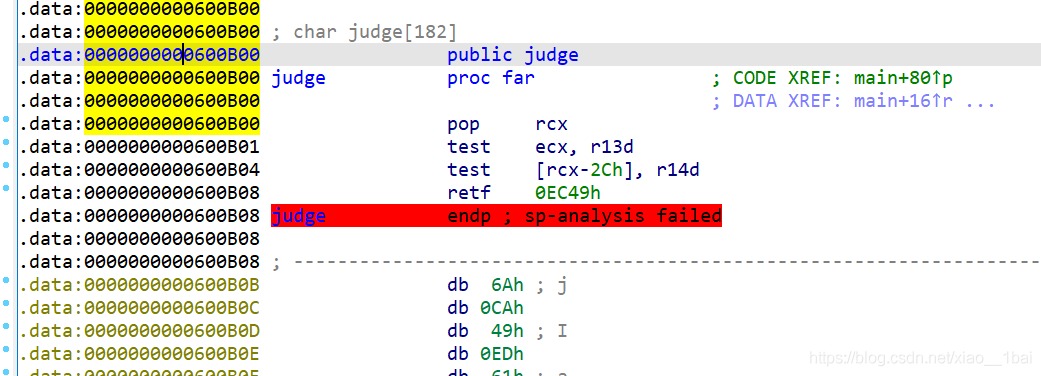
知道原理后我們可以開始做題了,第一種方法:直接嵌入腳本在讓他把加密流程跑一遍得出真正judge代碼邏輯,根據邏輯解密:
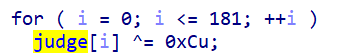
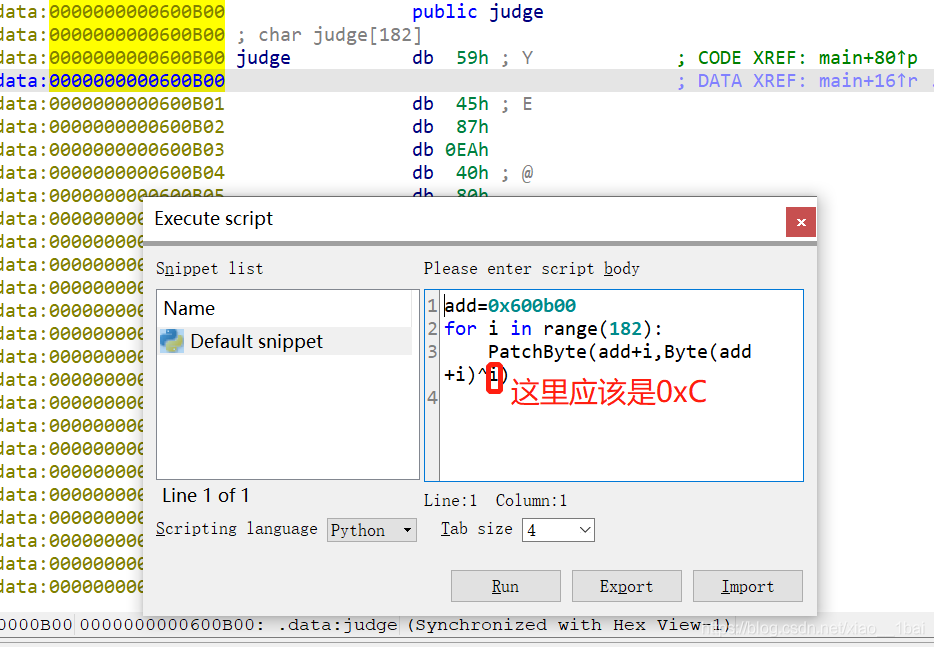
然后C,P鍵掃描生成函式,如果有紅色的行就用U設為未定義再C,P鍵即可:(C鍵是為了先轉成資料,P鍵是在轉成資料后創建函式)
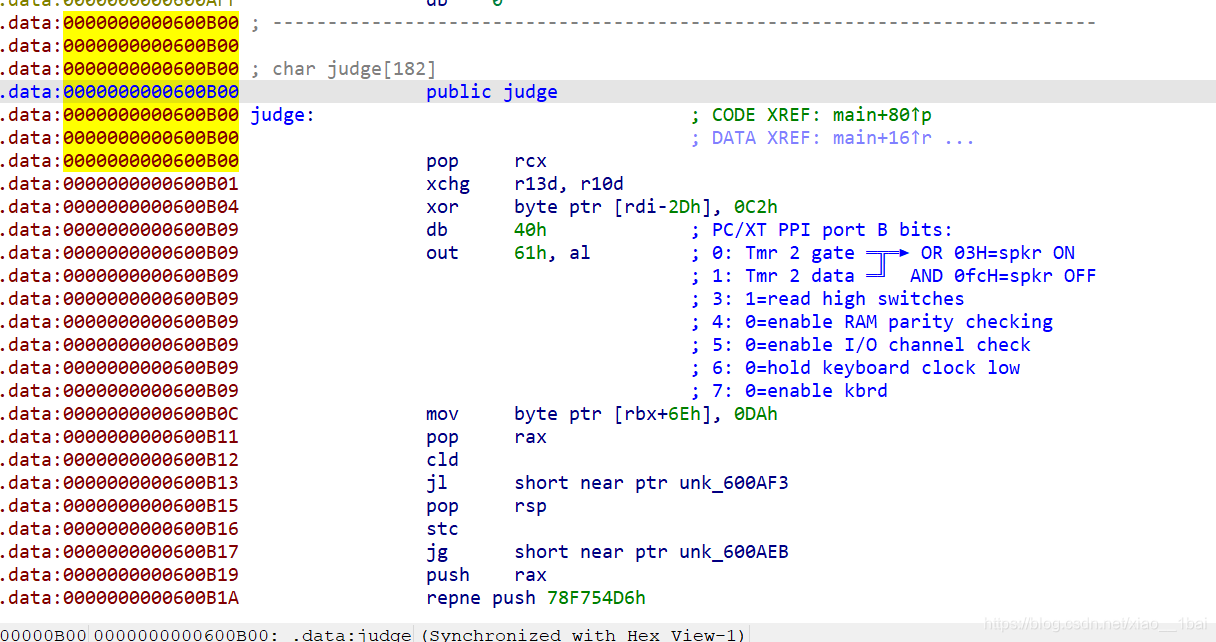
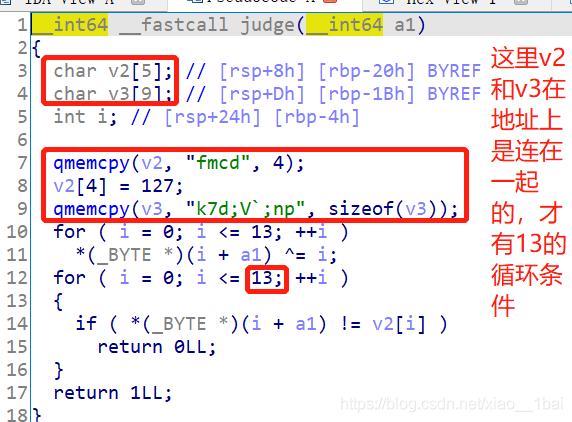
函式邏輯很簡單,flag是用戶輸入有關的生成型flag,對輸入的簡單的異或然后比較每個字符與預先給的字串是否相等,等就回傳1(true),所以我們直接用預先給的字串逆邏輯異或即可:
#key1="fmcd"
#key2=chr(0x7f)
#key3="k7d;V`;np"
#key4=key1+key2+key3
key="fmcd\x7Fk7d;V`;np"
flag=""
for i in range(14):
flag+=chr(ord(key[i])^i)
print(flag)
代碼如上,犯下的第 3 個錯誤就是我一開始以為python會把\x7F判斷成4個字符,結果是我多慮了,直接就是python自己會決議\x型別,太妙了,結果如圖:
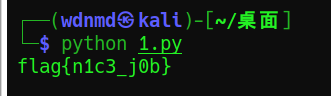
第二種方法:IDA動態除錯
直接遠程除錯,在第12行 if ( v5 == 14 && (unsigned int)judge((__int64)s) )處斷下代碼,斷在這里的話IDA已經把judge解密完了,直接雙擊跟蹤生成函式即可:
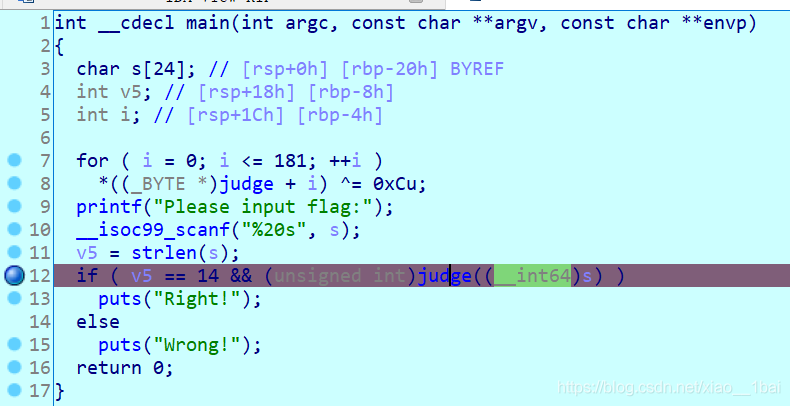
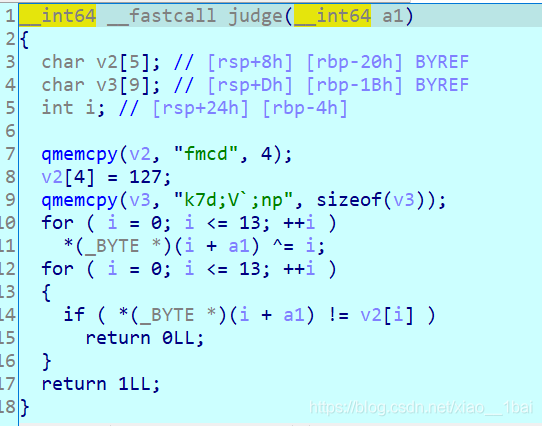
2021年10月廣東強網杯,REVERSE的simplere:(迷宮結合、涉及加密、)
64位ELF檔案,無殼,照例先運行一下程式,查看主要回顯資訊:
照例扔入IDA中查看偽代碼資訊,有main函式看main函式:
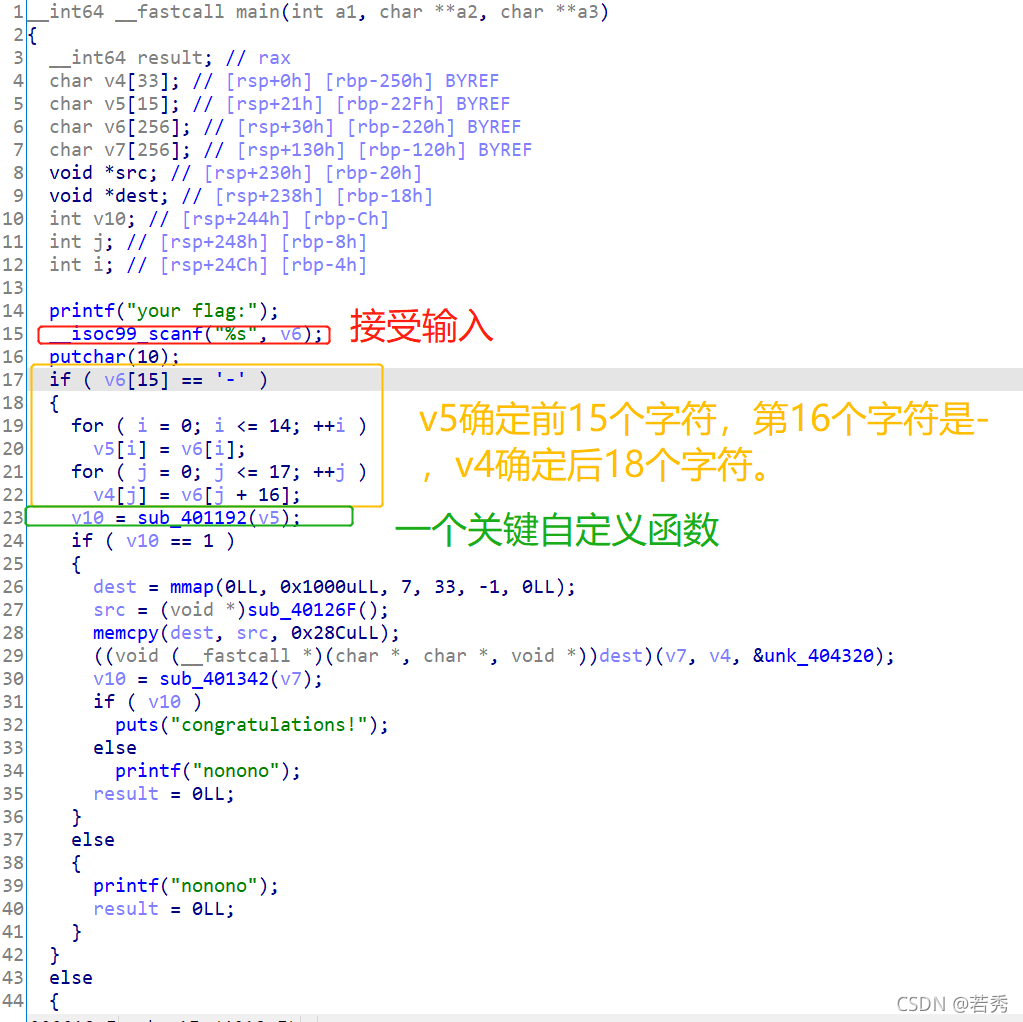
(這里積累第一個經驗)
上圖分析了前半部分,現在跟蹤那個關鍵自定義函式v10 = sub_401192(v5);這是對前15個字符組成的迷宮進行操作,
點進去查看邏輯,是一個走迷宮,輸入15步的wasd,要從A開始走,必須走到.上,最后必須走到B上,
根據11可以判斷是二維陣列,這也是我第一次學到迷宮的維數判斷,因為一個走11步,另一個一步一步走,所以一維字串最后得出二維迷宮,長11寬5的5*11型,s和w字符一下走11步就是上下移動,a和d一下走1步就是左右移動,也就是說走得多的就是行移動,走得少的就是列移動,
A********
.*…
…*.
*******…
******B
手扒得到ssddddwddddssas
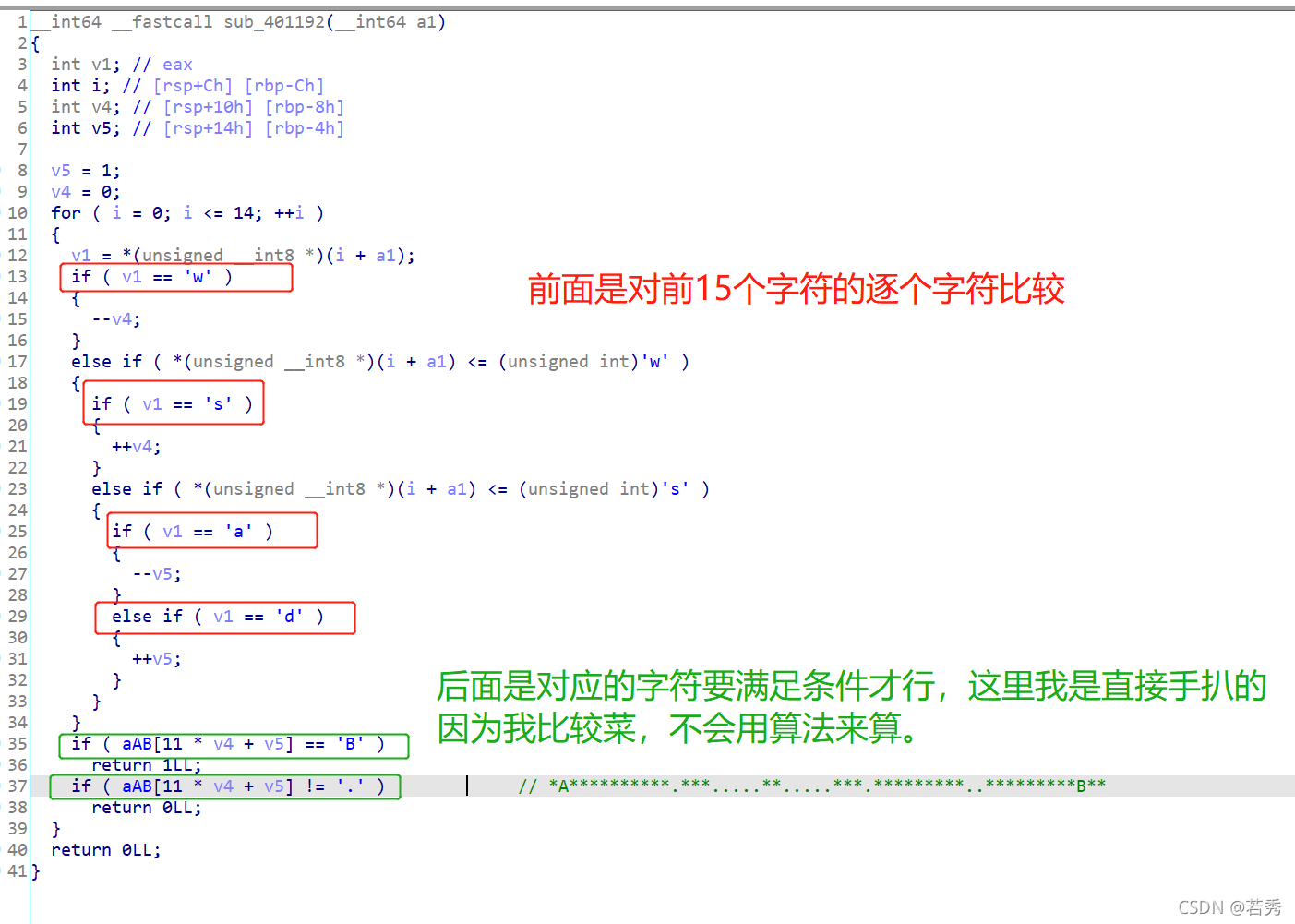
然后上半部分條件就過了,開始分析后半部分:

先跟蹤分析src = (void *)sub_40126F();函式:
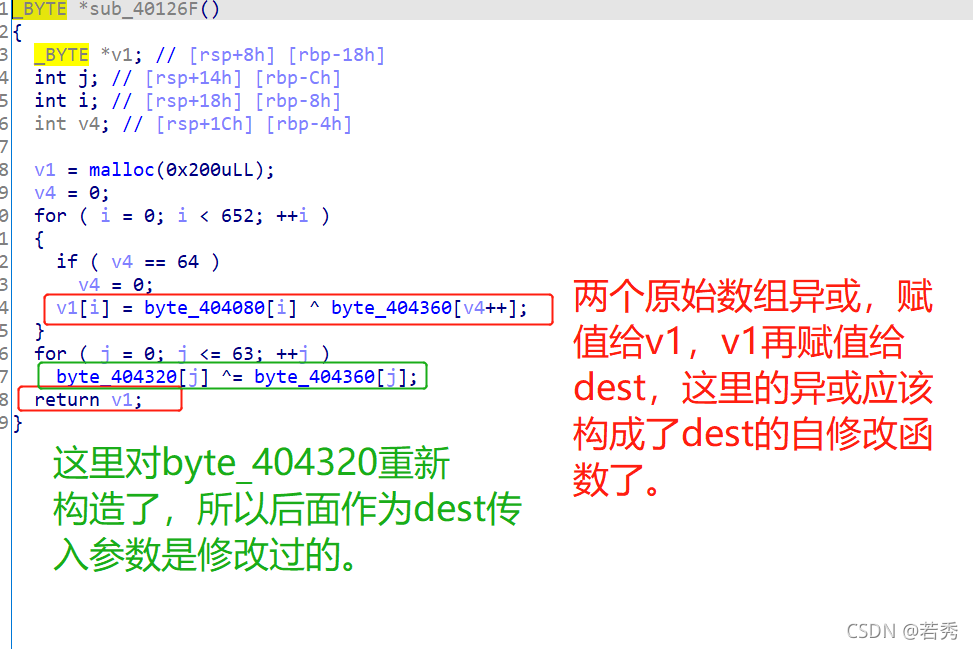
(這里積累第二個經驗)
這里的dest是在記憶體中的,這里靜態修補我不太會,因為dest和src都是在堆疊中的所以直接用動態除錯,用前面得出的前半部分搭配其它字符來運行ssddddwddddssas-666666666666666666:
所以這題就是base64變碼加密了,繼續跟蹤最后的自定義函式v10 = sub_401342(v7);
密文也有了,可以寫邏輯了,首先求出base64變形碼表,從src = (void *)sub_40126F();處匯出陣列:
key2=[ 0x4D, 0x20, 0x07, 0x05, 0x43, 0x15, 0x7A, 0x73, 0x39, 0x01,
0x7F, 0x53, 0x66, 0x4E, 0x0D, 0x18, 0x60, 0x76, 0x75, 0x00,
0x58, 0x15, 0x00, 0x32, 0x68, 0x3F, 0x78, 0x7F, 0x7B, 0x64,
0x4E, 0x49, 0x0F, 0x2E, 0x3F, 0x0D, 0x0D, 0x0D, 0x64, 0x66,
0x61, 0x53, 0x06, 0x44, 0x34, 0x6E, 0x69, 0x2F, 0x20, 0x14,
0x37, 0x6A, 0x49, 0x55, 0x36, 0x37, 0x23, 0x23, 0x2A, 0x6B,
0x73, 0x06, 0x78, 0x0B]
key3=[ 0x3E, 0x7A, 0x40, 0x64, 0x27, 0x25, 0x48, 0x04, 0x4F, 0x63,
0x19, 0x60, 0x0B, 0x3A, 0x75, 0x5D, 0x11, 0x4E, 0x07, 0x44,
0x30, 0x4C, 0x4B, 0x06, 0x5F, 0x73, 0x0D, 0x1A, 0x38, 0x08,
0x34, 0x78, 0x45, 0x47, 0x58, 0x3B, 0x74, 0x7D, 0x2C, 0x2B,
0x4A, 0x3C, 0x29, 0x13, 0x01, 0x3F, 0x03, 0x61, 0x70, 0x52,
0x65, 0x09, 0x22, 0x00, 0x7F, 0x59, 0x6C, 0x77, 0x72, 0x3D,
0x32, 0x55, 0x41, 0x49]
for i in range(len(key3)):
key2[i]^=key3[i]
print(key2)
print(''.join(map(chr,key2))) #base64變表碼
結果:

然后把變形碼表替換傳統base64加密碼表,這里用的是我以前寫過的base64python編碼實作:(https://blog.csdn.net/xiao__1bai/article/details/120338971)
base64="sZGad02wvbf3mtxEq8rDhYK47LueClz1Jig6ypHM+o/W5QjNPFRckUInOTXVAS9B" #準備好base64的基表
def encryption(inputstring): #定義加密函式
ascii=['{:0>8}'.format(str(bin(ord(i))).replace('0b','')) for i in inputstring] #把每個輸入字符保證8位一個,才能3*8變4*6,
#{:0>8}是右對齊8位然后左邊補0,因為python是自己判斷資料大小型別的,所以必須強制滿足8位,bin轉化二進制會帶0b前綴,所以要用replace('0b','')去掉,
encrystr='' #while外的變數,回傳base64加密后的字串
equalnumber=0 #while外的變數,記錄拆分后不足4的倍數時需要補齊的等號個數
while ascii:
subascii=ascii[:3] #用一個子串列subascii每次取輸入的三位進行操作,前面操作后每位都是8位
while len(subascii)<3: #這里其實是最后一段截取中才會用上的,不滿足3位時要單獨取出,記錄equalnumber數量用于后期補'='號,然后補齊8位的0免得干擾后面3*8拆分成4*6
equalnumber+=1 #計算要補‘=’的個數
subascii+=['0'*8] #補8個0來填充夠3的倍數,這然后面就不會出錯,
substring=''.join(subascii)#用substring合并subascii的3個8位,準備進行拆分操作
encrystringlist=[substring[x:x+6] for x in [0,6,12,18]] #開始進行3*8變4*6的拆分,每次拆分一組24位,
encrystringlist=[int(x,2) for x in encrystringlist] #把前面拆分的6位一組轉成10進制,就不用進行位數補齊操作了,這是用來后面對應base64基表的下標,
if equalnumber:
encrystringlist=encrystringlist[0:4-equalnumber] #如果前面不足3字符補了0,比如2個8位字符16位,拆分后就要用3個6位共18位,所以有效位是4-equalnumber
encrystr+=''.join(base64[x] for x in encrystringlist) #這里encrystringlist已經在前面拆分成4*6且轉換成10進制了,所以對應基表的下標,
ascii=ascii[3:] #每次向后取3個串列元素,對應while回圈條件
encrystr+='='*equalnumber #因為前面encrystringlist[0:4-equalnumber]去掉了補0位,所以這里最后補齊'='號
return encrystr
def decryption(inputstring):
ascii=['{0:0>6}'.format(str(bin(base64.index(i))).replace('0b',''))for i in inputstring if i!='=']#從加密字符中取除補位'='之外加密字符,即6位生成的base64基表下標的數,按6位一組排列,準備拆分
decrystr=''#準備while外的解密后的字符
equalnumber=inputstring.count('=')#這里計數補位的'='號的個數,后面不夠8位時會根據'='號補加位數,
while ascii:
subascii=ascii[:4]#取加密字符的4個6位一組共24位準備拆分合并成3*8
substring=''.join(subascii)#先連成一串24位
if len(substring)%8!=0:
substring=substring[0:-1*equalnumber*2]
#截取到倒數第equalnumber*2個元素,對不足8位的組補位,因為加密時1個8位要來2個6位,兩個'='號,截取到8位就是倒數第4位1*2*2,2個8位要3個6位,要一個'='號,截取到16位就是倒數第2位1*1*2,
decrystringlist=[substring[x:x+8] for x in [0,8,16]]#開始進行4*6變3*8的拆分,每次拆分4個6位一組24位,
decrystringlist=[int(x,2) for x in decrystringlist if x]#把前面拆分的8位一組轉成10進制,用來對應十進制ASCII碼,if x功能不清楚,但不可缺少,應該是要排除空格吧,
decrystr+=''.join([chr(x) for x in decrystringlist])#這里decrystringlist已經在前面拆分成3*8且轉換成10進制了,現在轉換成ASCII碼,
ascii=ascii[4:]#每次向后取4個串列元素,對應while回圈條件
return decrystr
if __name__=="__main__":
#print(encryption('abcd'))
print(decryption('r60ihyZ/m4lseHt+m4t+mIkc'))
結果:
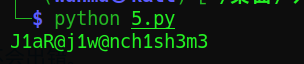
所以最終flag:
flag{ssddddwddddssas-J1aR@j1w@nch1sh3m3}
系統函式函式自修改:(HOOK,通常兩次修改系統函式,一次改成自定義機器碼,一次改回正常)
Hook 技術又叫做鉤子函式,在系統沒有呼叫該函式之前,鉤子程式就先捕獲該訊息,鉤子函式先得到控制權,這時鉤子函式既可以加工處理(改變)該函式的執行行為,還可以強制結束訊息的傳遞,簡單來說,就是把系統的程式拉出來變成我們自己執行代碼片段,
攻防世界EASYHOOK:(非預期行為、函式積累、手動機器碼)
這是我第一次遇到HOOK型別的題目,我很是興奮,我也花了相當長的時間才把該HOOK流程全部弄懂,希望能給日后更多經驗,
直接入重點,打開IDA查看main函式,具體分析我寫在代碼里:
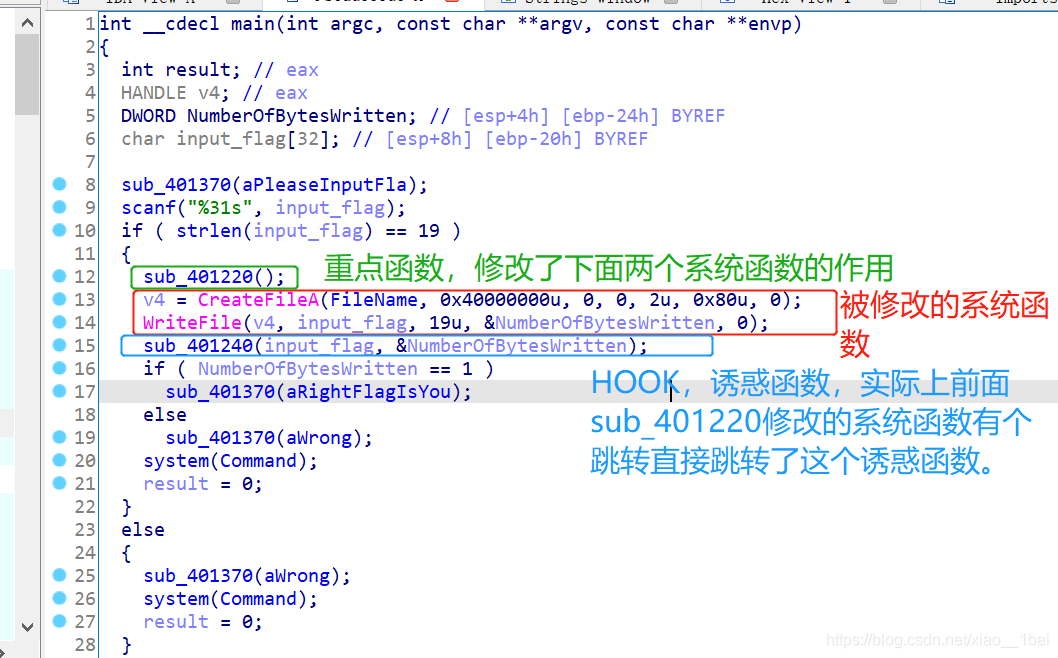
sub_401370(aPleaseInputFla);
scanf("%31s", input_flag);
if ( strlen(input_flag) == 19 )
{
sub_401220(); //未知名函式,一開始當然不會注意
v4 = CreateFileA(FileName, 0x40000000u, 0, 0, 2u, 0x80u, 0); //創建檔案函式
WriteFile(v4, input_flag, 19u, &NumberOfBytesWritten, 0); //寫入函式,這些系統函式通常不是重點,如果影響理解代碼的話直接查API即可, WriteFile(句柄, 寫入字串, 寫入位元組, 指向寫入直接的指標, 0)
sub_401240(input_flag, &NumberOfBytesWritten);
if ( NumberOfBytesWritten == 1 ) //判斷函式
sub_401370(aRightFlagIsYou);
else
sub_401370(aWrong);
system(Command);
result = 0;
}
else
{
sub_401370(aWrong);
system(Command);
result = 0;
}
return result;
}
好了,疑惑開始,首先當然直接跟蹤sub_401240函式:然后就犯下第一個錯誤:(被HOOK了):
查看該函式代碼讓我疑惑的事情發生了,v4[a1 - v4 + result] == v4[result] 這條神仙代碼無解啊,a1是我輸入的字串地址,作為下標運算就算了,result還是從0開始的,完全走不通啊!(PS:這題還算好了,給了我一個走不通的HOOK,要是這個HOOK還是走得通的話就更花時間了!)
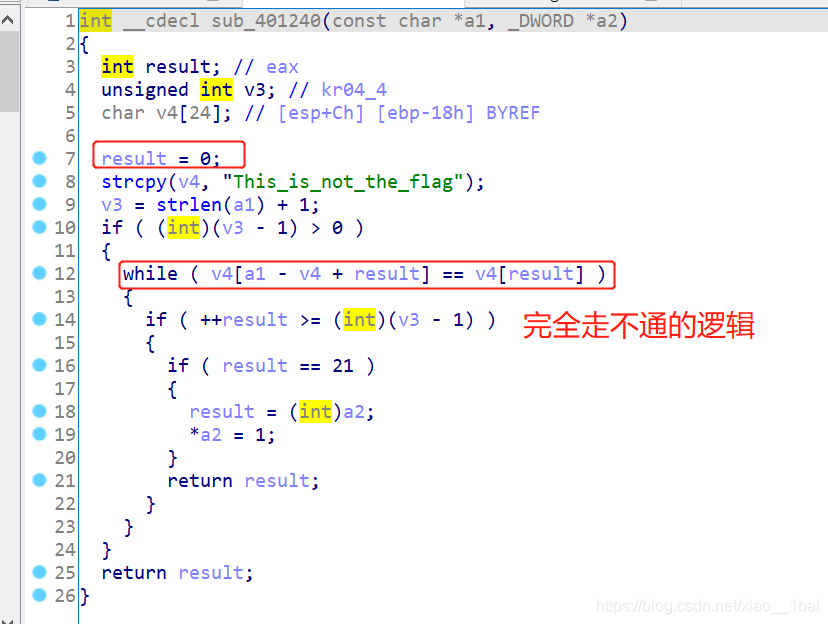
然后我又看了一下生成的Your_input檔案,???生成的不是我寫入的:

然后就去查資料了,期間學到了很多東西,我們先用靜態除錯細致分析:首先這一系列非預期行為基本說明了存在其他操作,那前面非系統函式就只剩下sub_401220()了,跟蹤加代碼分析:
int sub_401220()
{
HMODULE v0; // eax
DWORD v2; // eax
v2 = GetCurrentProcessId(); //系統函式,獲取行程ID,就是當前程式的ID
hProcess = OpenProcess(0x1F0FFFu, 0, v2); //系統函式,回傳現有行程物件的句柄,
v0 = LoadLibraryA(LibFileName); //系統函式,將指定的可執行模塊映射到呼叫行程的地址空間,這里LibFileName雙擊跟蹤存入的是kernel32.dll模塊,就是匯入了它
*(_DWORD *)WriteFile_0 = GetProcAddress(v0, ProcName); //系統函式,回傳指定的匯出元件(DLL)函式的地址, ProcName存放的是WriteFile函式名,也就是匯入WriteFile函式,
lpAddress = *(LPVOID *)WriteFile_0; //獲取WriteFile函式地址
if ( !*(_DWORD *)WriteFile_0 ) //無用函式,因為kernel32.dll模塊的WriteFile函式一定存在
return sub_401370(&unk_40A044); //sub_401370函式型別puts函式,是通過主函式分析得到的,&unk_40A044處的字串是獲取原API入口地址出錯,不用管他,
unk_40C9B4 = *(_DWORD *)lpAddress; //這里獲取WriteFile函式的地址
*((_BYTE *)&unk_40C9B4 + 4) = *((_BYTE *)lpAddress + 4); //這里地址后四位也保持一樣,不知道有什么用
byte_40C9BC = 0351; //這里連同第二句是我犯下的第二個錯誤:這里轉十六進制不是E9,是JMP的機器碼指令,而不一開始并沒有機器碼的相關知識,
dword_40C9BD = (char *)sub_401080 - (char *)lpAddress - 5; //這里是一個偏移地址,而且還是滿足HOOK的連續地址,之所以這樣寫是因為匯編語言JMP address被編譯后會變成機器指令碼,E9 偏移地址,偏移地址=目標地址-當前地址-5(jmp和其后四位地址共占5個位元組),所以前面直接用E9,這里直接用偏移地址就省去編譯生成機器碼那一步,這也是HOOK的原型,
return sub_4010D0(); //回傳一個函式,繼續跟蹤,因為前面并沒有什么修改程式的行為,只是創造了一個JMP指令而已,
}
跟蹤sub_4010D0()函式:(這里替換了WriteFile函式的5位元組為JMP跳轉指令)
BOOL sub_4010D0()
{
DWORD v1; // [esp+4h] [ebp-8h] BYREF
DWORD flOldProtect; // [esp+8h] [ebp-4h] BYREF
v1 = 0;
VirtualProtectEx(hProcess, lpAddress, 5u, 4u, &flOldProtect); //這里犯下第三個錯誤就是我一開始看不懂這三行代碼
函式理解:
VirtualProtectEx(行程,修改地址,修改區域大小,[修改其中權限,1,2,4對應執行,寫,讀],一個保存修改前權限的變數 ),
所以這三行作用是對lpAddress所存盤的地址處進行了5位元組的權限修改操作,先將關鍵地址區改成可讀寫再往此處寫入前面E9 偏移量地址處的5個位元組(即上面的跳轉指令),最后恢復權限,完成修改,
WriteProcessMemory(hProcess, lpAddress, &byte_40C9BC, 5u, 0); //在原WriteFile函式地址處覆寫寫入5位元組的JMP手動機器碼
return VirtualProtectEx(hProcess, lpAddress, 5u, flOldProtect, &v1); //恢復權限
所以這里執行到WriteFile函式的時候就會變成一個跳轉陳述句,跳轉到目標地址sub_401080處,雙擊跟蹤該函式:
int __stdcall sub_401080(HANDLE hFile, LPCVOID input_flag, DWORD nNumberOfBytesToWrite, LPDWORD lpNumberOfBytesWritten, LPOVERLAPPED lpOverlapped)
{
int v5; // ebx
v5 = sub_401000((int)input_flag, nNumberOfBytesToWrite); //真正加密函式,后面分析
sub_401140(); //重寫WriteFile函式地址處的記憶體,和前面4010D0處函式的三句類似,只是代碼 WriteProcessMemory(hProcess, lpAddress, &unk_40C9B4, 5u, 0);寫入的地址為&unk_40C9B4,這的確是WriteFile函式地址,就是為了下面那個WriteFile函式不受影響,真正是寫入檔案函式
WriteFile(hFile, input_flag, nNumberOfBytesToWrite, lpNumberOfBytesWritten, lpOverlapped); //真正的寫入函式
if ( v5 )
*lpNumberOfBytesWritten = 1; //這里*lpNumberOfBytesWritten已經賦值為1了,也是全域變數,你會猛的發現主函式的sub_401240(input_flag, &NumberOfBytesWritten);這個幌子函式就算對不上陣列字符也不會設定*lpNumberOfBytesWritten = 0;所以只要這里真正加密的對了,后面錯誤退出*lpNumberOfBytesWritten還是等于1.
return 0;
}
分析真正加密函式 sub_401140():
int __cdecl sub_401000(int input_flag, int _19)
{
char i; // al
char v3; // bl
char v4; // cl
int v5; // eax
for ( i = 0; i < _19; ++i )
{
if ( i == 18 )
{
*(_BYTE *)(input_flag + 18) ^= 19u; // 這里犯下第五個錯誤,寫腳本時這種單獨的if陳述句應該直接在外面單獨成行,不然就要多寫幾個elif陳述句了,界面就會很亂!
}
else
{
if ( i % 2 )
v3 = *(_BYTE *)(i + input_flag) - i;
else
v3 = *(_BYTE *)(i + input_flag + 2);
*(_BYTE *)(i + input_flag) = i ^ v3;
}
}
v4 = 0;
if ( _19 <= 0 ) // 不會小于等于,所以不會在這里回傳
return 1;
v5 = 0;
while ( aAjygkfm[v5] == *(_BYTE *)(v5 + input_flag) ) //這里犯下第四個錯誤,前面的加密邏輯中我們沒有可以參照的字串,因為flag是推出來的,而真正的字串在后面,所以逆向邏輯時首先要找到非輸入的字串才行!這里雙擊跟蹤 aAjygkfm等于ajygkFm.\x7f_~-SV{8mLn
{
v5 = ++v4;
if ( v4 >= _19 )
return 1;
}
return 0;
}
所以最后腳本:
flag=list("-------------------") #這是學別人的,因為我們要的是19個元素的陣列,所以List函式很不錯喔
print(len(flag))
key1="ajygkFm.\x7f_~-SV{8mLn"
flag[18]=chr(ord(key1[18])^19)
for i in range(18):
v3=ord(key1[i])^i
if i%2==1: #把18的判斷條件抽出去后里面就只有一層條件了,簡便很多,
flag[i]=chr(v3+i)
else:
flag[i+2]=chr(v3)
print(''.join(flag))
結果,改第一個字符為f即可:

參考別人博客的一句話:
現在程式流程就很明朗了
粗略來看程式流程是CreateFileA->(lpAddress里存的指令)WriteFile->sub_401240
但是在經過sub_401220()的處理以后,變成了CreateFileA->(lpAddress里存的指令)sub_401080->sub_401240,
那么最后的sub_401240又干了什么事呢,分析一下代碼:(這里我重命名了一些變數名):
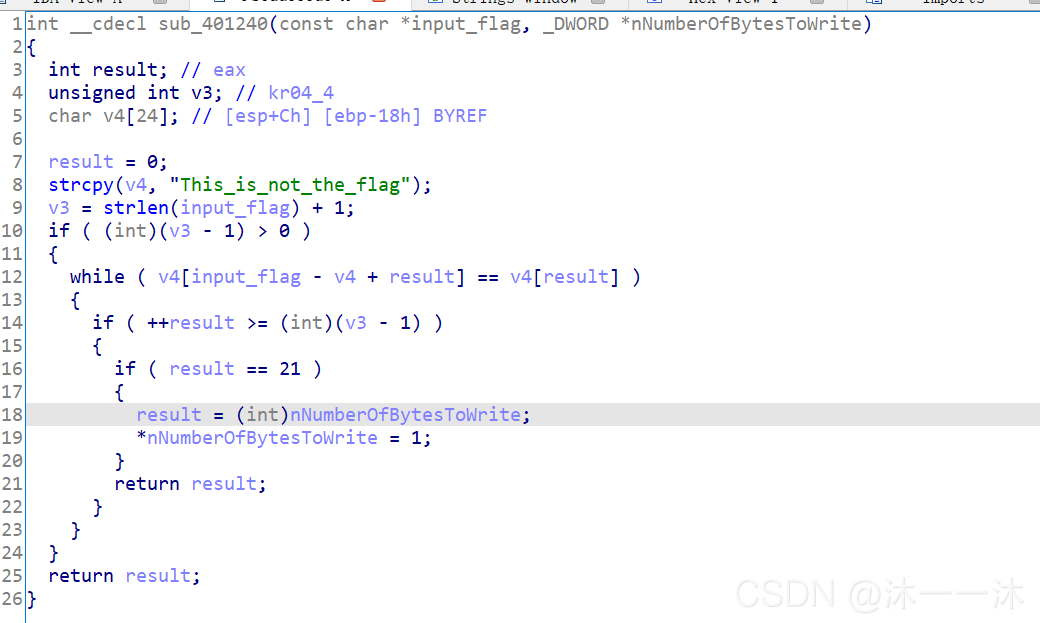
這里最有意思的是這個函式完全符合就會執行nNumberOfBytesToWrite = 1;,但是不符合也沒有nNumberOfBytesToWrite = 0;的操作啊,我們前面真加密函式的時候就賦值*nNumberOfBytesToWrite = 1;了,也就是說不管這里對還是錯都會輸出you flag is right啊!而且動態除錯的時候你會發現,這里回圈執行一次就退出來了,因為while ( v4[input_flag - v4 + result] == v4[result] )這個代碼根本不合邏輯,
最后動態除錯就不想搞了:
我記得IDA動態運行到主函式WriteFile處的時候用F7單步執行會看到一個jmp的指令,繼續動態到sub_401240函式的時候也是正如我說的回圈運行第一次就退出來了,但是照樣輸出you flag is right,
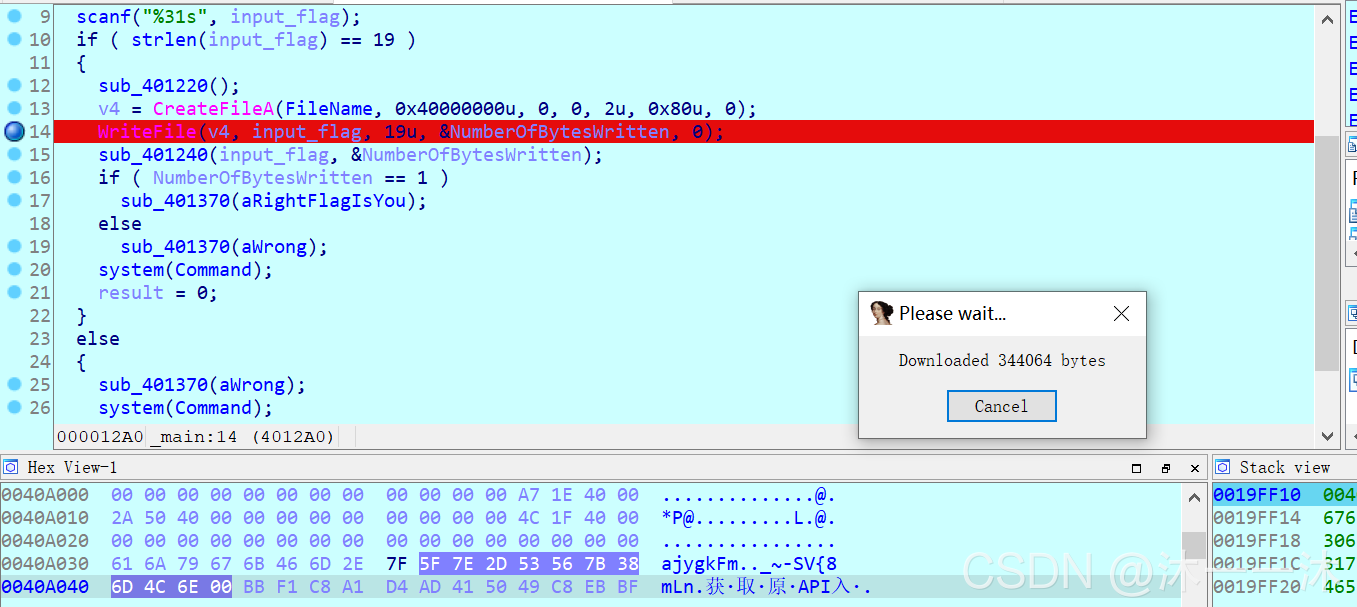
安卓java類逆向分析
java邏輯平鋪:
攻防世界Guess-the-Number:(代碼截斷重寫)
下載了一個jar檔案,根據題目描述猜個數字然后找到flag.,估計題目型別是flag存盤型,滿足條件就有flag:
用我之前做安卓逆向下載的jar.gui打開,查看代碼邏輯:
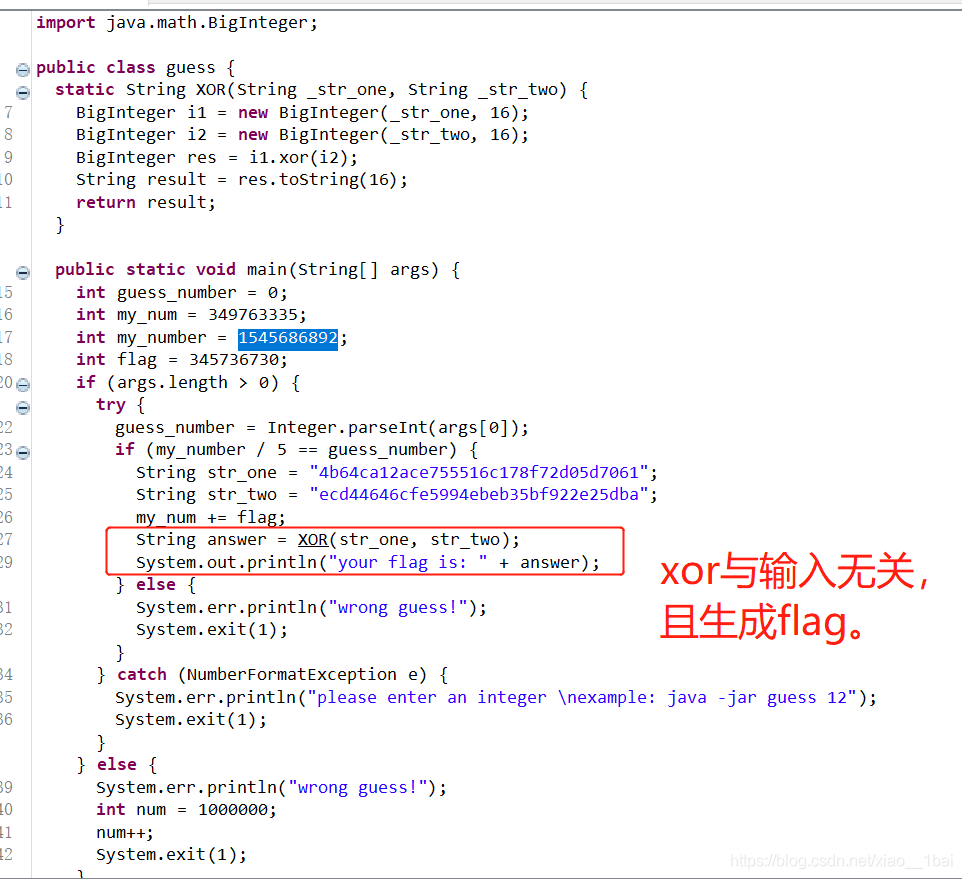
邏輯不難,果然是滿足條件就有的存盤型flag,這里我直接修改截斷代碼即可,xor是生成存盤型flag的代碼,要保留:
import java.math.BigInteger;
public class guess {
static String XOR(String _str_one, String _str_two) {
BigInteger i1 = new BigInteger(_str_one, 16);
BigInteger i2 = new BigInteger(_str_two, 16);
BigInteger res = i1.xor(i2);
String result = res.toString(16);
return result;
}
public static void main(String[] args) {
int guess_number = 0;
int my_num = 349763335;
int my_number = 1545686892;
int flag = 345736730;
String str_one = "4b64ca12ace755516c178f72d05d7061";
String str_two = "ecd44646cfe5994ebeb35bf922e25dba";
my_num += flag;
String answer = XOR(str_one, str_two);
System.out.println("your flag is: " + answer);
}
}
這里截斷代碼的時候遇到第一個錯誤,我竟然忘記編譯命令是什么了,還傻傻的用java -c,真的是馬冬梅啊馬冬梅,后來查看了百度才想起編譯命令是javac,運行即得flag:
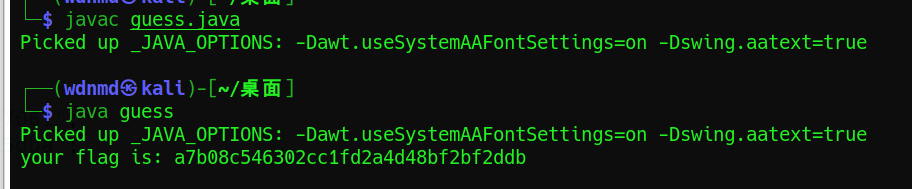
當然還有第二種方法,看輸入后處理的判斷邏輯,輸入正確的數即可:
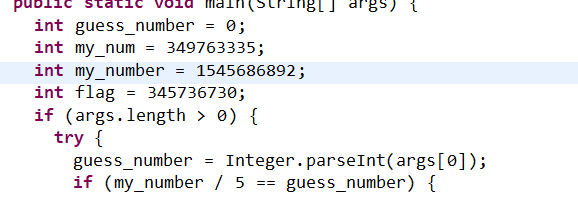
這里判斷邏輯是my_number / 5 == guess_number,一開始不記得前面的guess_number = Integer.parseInt(args[0])是什么意思,所以就沒往這里想,后來才發現是簡單的獲取整數引數而已,所以計算機運算1545686892 / 5再取整數就是我們要輸入的數:(PS:引數寫在右邊)

RC4解密腳本:
#include<stdio.h>
void rc4_init(unsigned char* s, unsigned char* key, unsigned long Len_k) //初始化函式
{
int i = 0, j = 0;
char k[256] = { 0 };
unsigned char tmp = 0;
for (i = 0; i < 256; i++) {
s[i] = i;
k[i] = key[i % Len_k];
}
for (i = 0; i < 256; i++) {
j = (j + s[i] + k[i]) % 256;
tmp = s[i];
s[i] = s[j];
s[j] = tmp;
}
}
void rc4_crypt(unsigned char* Data, unsigned long Len_D, unsigned char* key, unsigned long Len_k) //加解密
{
unsigned char s[256];
rc4_init(s, key, Len_k);
int i = 0, j = 0, t = 0;
unsigned long k = 0;
unsigned char tmp;
for (k = 0; k < Len_D; k++) {
i = (i + 1) % 256;
j = (j + s[i]) % 256;
tmp = s[i];
s[i] = s[j];
s[j] = tmp;
t = (s[i] + s[j]) % 256;
Data[k] = Data[k] ^ s[t];
}
}
void main()
{
unsigned char key[] = "[Warnning]Access_Unauthorized"; //密鑰
unsigned long key_len = sizeof(key) - 1;
unsigned char data[] = { 0xC3,0x82,0xA3,0x25,0xF6,0x4C,
0x36,0x3B,0x59,0xCC,0xC4,0xE9,0xF1,0xB5,0x32,0x18,0xB1,
0x96,0xAe,0xBF,0x08,0x35};//把加密腳本放在kali中打開,根據kali推薦的編碼再復制到burp中用hex編碼寫出來放在這里, kali ISO-8859-1編碼顯示類似于 ??£%?L6;Yì?é?μ2±???5
int i;
rc4_crypt(data, sizeof(data), key, key_len);
for ( i = 0; i < sizeof(data); i++)
{
printf("%c", data[i]);
}
printf("\n");
return;
}
//flag{RC4&->ENc0d3F1le}
INT3斷點:
INT3斷點,簡單地說就是將你要斷下的指令地址處的第一個位元組設定為0xCC,軟體執行到0xCC(對應匯編指令INT3)時,會觸發例外代碼為EXCEPTION_BREAKPOINT的例外,這樣我們的除錯程式就能夠接收到這個例外,然后進行相應的處理,如果沒有處理就會強制退出程式,就無法除錯了,
INT3斷點的資訊結構體如下:
struct stuPointInfo
{
PointType ptType; //斷點型別
int nPtNum; //斷點序號
LPVOID lpPointAddr; //斷點地址
BOOL isOnlyOne; //是否一次性斷點(針對INT3斷點)
char chOldByte; //原先的位元組(針對INT3斷點)
};
而每一個INT3斷點資訊結構體指標又保存到一個鏈表中,
INT3斷點的設定:
設定INT3斷點比較簡單,只需要根據用戶輸入的斷點地址和斷點型別(是否一次性斷點),將被除錯行程中對應地址處的位元組替換為0xCC,同時將原來的位元組保存到INT3斷點資訊結構體中,并將該結構體的指標加入到斷點鏈表中,
如果在被除錯的某地址處已經存在一個同樣的斷點了,那么用戶 還要往這個地址上設定相同的斷點,則必然會因為重復設定斷點導致錯誤,例如這里的INT3斷點,如果不對用戶輸入的地址進行是否重復的檢查,而讓用戶在同 一個地址先后下了兩次INT3斷點,則后一次INT3斷點會誤以為這里本來的位元組就是0xCC而一直斷點在這里,
所以在設定INT3斷點之前應該先看該地址是否已經下過 INT3斷點,如果該地址已經存在一個INT3斷點,且是非一次性的,則不能再在此地址下INT3斷點,如果該地址有一個INT3一次性斷點,而用戶要繼續下一個INT3非一次性斷點,則將原來存在的INT3斷點的屬性從一次性改為非一次性斷點,
INT3斷點被斷下的處理:
INT3斷點被斷下后,首先從斷點鏈表中找到對應的斷點資訊結構體,如果沒有找到,則說明該INT3斷點不是用戶下的斷點,除錯器不做處理,交給系統程式去處理(其他型別的斷點觸發例外也需要做同樣的處理,而系統通常是強制退出結束程式),這也是攻防世界的csaw2013reversing2的考點,
如果找到對應的斷點,根據斷點資訊將斷下地址處的位元組還原為原來的位元組,并將被除錯行程的 EIP減一,因為INT3例外被斷下后,被除錯行程的EIP已經指向了INT3指令后的下一條指令,所以為了讓被除錯行程執行本來需要執行的指令,應該讓 其EIP減1,
如以下代碼:
地址 機器碼 匯編代碼
01001959 55 push ebp
0100195A 33ED xor ebp,ebp
0100195C 3BCD cmp ecx,ebp
0100195E 896C24 04 mov dword ptr ss:[esp+4],ebp
當用戶在0100195A地址處設定INT3斷點后,0100195A處的位元組將改變為0xCC(原先是0x33),
此時對應的代碼如下:
地址 機器碼 匯編代碼
01001959 55 push ebp
0100195A CC int3
0100195B ED in eax,dx
0100195C 3BCD cmp ecx,ebp
0100195E 896C24 04 mov dword ptr ss:[esp+4],ebp
當被除錯程式執行到0100195A地址處,觸發例外,進入例外處理程式后,獲取被除錯執行緒的環境(GetThreadContext),可看 出此時EIP指向了0100195B,也就是INT3指令之后,所以我們除了要恢復0xCC為原來的位元組之外,還要將被除錯執行緒的EIP減一,讓EIP指 向0100195A,否則CPU就會執行0100195B處的指令(0100195B ED in eax,dx),顯然這是錯誤的,
如果查找到的斷點資訊顯示該INT3斷點是一個非一次性斷點,那么需要設定單步,然后在進入單步后將這一個斷點重新設定上(硬體執行斷點和記憶體 斷點如果是非一次性的也需要做相同的處理),因為INT3斷點同時只會斷下一個,所以可以用一個臨時變數保存要重新設定的INT3斷點的地址,然后用一個 BOOL變數表示當前是否有需要重新設定的INT3斷點,
關于INT3斷點的一些細節:
1. 創建除錯行程后,為了能夠讓被除錯程式斷在OEP(程式入口點),我們可以在被除錯程式的OEP處下一個一次性INT3斷點,
2. 在創建除錯行程的程序中(程式還沒有執行到OEP處),會觸發一個ntdll.dll中的INT3,遇到這個斷點直接跳出不處理,這個斷點在使用微 軟自己的除錯工具WinDbg時會被斷下,可以猜測,微軟設定這個斷點是為了能夠在程式到達OEP之前就被斷下,方便用戶做一些處理(如設定各種斷點),
3. 因為INT3斷點修改了被除錯程式的代碼內容,所以在進行反匯編和顯示被除錯行程記憶體資料的時候,需要檢查碰到的0xCC位元組是否是用戶所下的 INT3斷點,如果是需要替換為原來的位元組,再做相應的反匯編和顯示資料作業,這一點olldbg做的很不錯,而有一些國產的除錯器好像沒有注意到這些小 的細節,
IDA獲取地址內容命令嵌入:
提取&s處的陣列內容:
addr=0x08048AA8 #陣列的地址
arr = []
for i in range(39): #陣列的個數
arr.append(Dword(addr+4* i))
print(arr)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/323343.html
標籤:其他
上一篇:Web AWD流程與技巧