目錄
spark安裝
前言
資料鏈接
安裝scala
創建scala作業目錄
配置環境變數(三臺機器)
查看是否安裝成功
分發到節點
驗證
安裝spark
創建spark作業目錄
編輯spark-env.sh
配置spark從節點
配置環境變數(三臺機器)
分發到節點
測驗運行環境(只在master節點執行)
訪問spark web界面
開啟spark-shell
輸入pyspark測驗python環境spark互動模式
spark安裝
Apache Spark 是專為大規模資料處理而設計的快速通用的計算引擎,Spark是UC Berkeley AMP lab (加州大學伯克利分校的AMP實驗室)所開源的類Hadoop MapReduce的通用并行框架,Spark,擁有Hadoop MapReduce所具有的優點;但不同于MapReduce的是——Job中間輸出結果可以保存在記憶體中,從而不再需要讀寫HDFS,因此Spark能更好地適用于資料挖掘與機器學習等需要迭代的MapReduce的演算法,
前言
在部署完hadoop集群后,再安裝scala與spark
Spark 是在 Scala 語言中實作的,它將 Scala 用作其應用程式框架,與 Hadoop 不同,Spark 和 Scala 能夠緊密集成,其中的 Scala 可以像操作本地集合物件一樣輕松地操作分布式資料集,
資料鏈接
鏈接:https://pan.baidu.com/s/1ytGL3cLGQxGltl5bHrSBQQ
提取碼:yikm
安裝scala
創建scala作業目錄
mkdir -p /usr/scala/
tar -xvf /usr/package/scala-2.11.12.tgz -C /usr/scala/
配置環境變數(三臺機器)
vim /etc/profile添加以下內容:
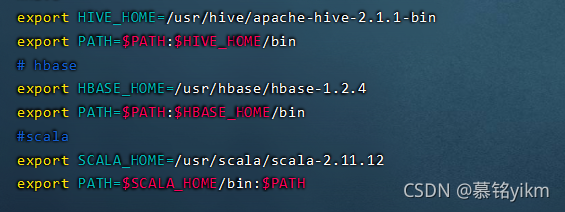
#scala
export SCALA_HOME=/usr/scala/scala-2.11.12
export PATH=$SCALA_HOME/bin:$PATH
生效環境變數
source /etc/profile

查看是否安裝成功
scala -version
分發到節點
scp -r /usr/scala/ root@slave1:/usr/
scp -r /usr/scala/ root@slave2:/usr/
驗證
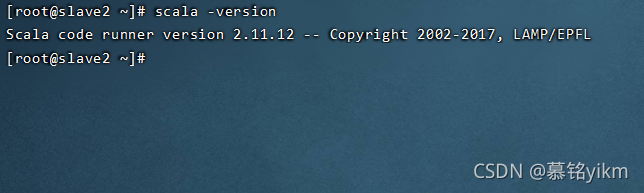
scala -version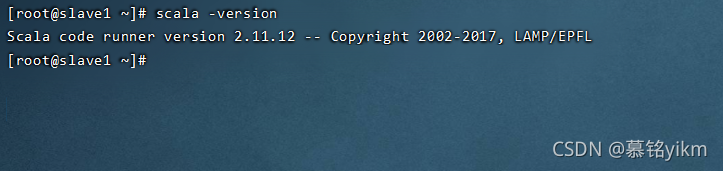
安裝spark
創建spark作業目錄
mkdir -p /usr/spark
tar -zxvf /usr/package/spark-2.4.0-bin-hadoop2.7.tgz -C /usr/spark/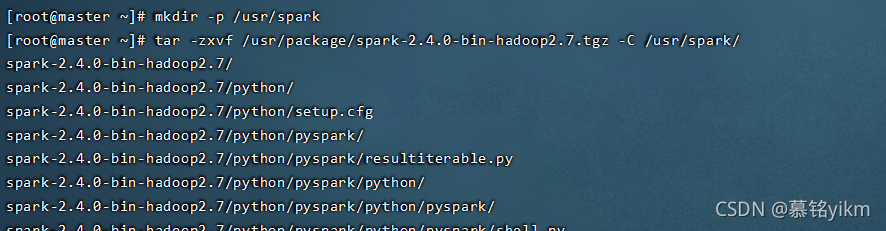
編輯spark-env.sh
cd /usr/spark/spark-2.4.0-bin-hadoop2.7/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh

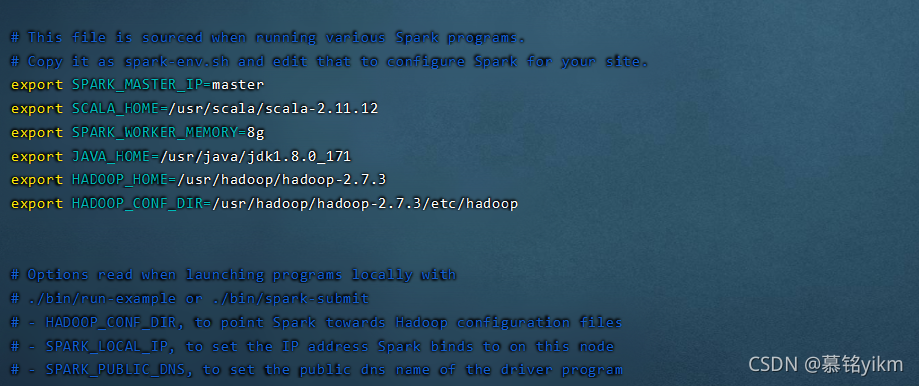
添加以下內容:
export SPARK_MASTER_IP=master
export SCALA_HOME=/usr/scala/scala-2.11.12
export SPARK_WORKER_MEMORY=8g
export JAVA_HOME=/usr/java/jdk1.8.0_171
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.7.3/etc/hadoop
配置spark從節點
mv slaves.template slaves
vim slaves

修改localhost:
slave1
slave2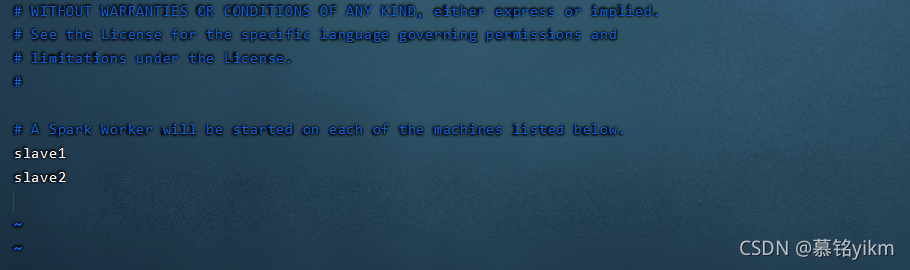
配置環境變數(三臺機器)
vim /etc/profile
添加以下內容:
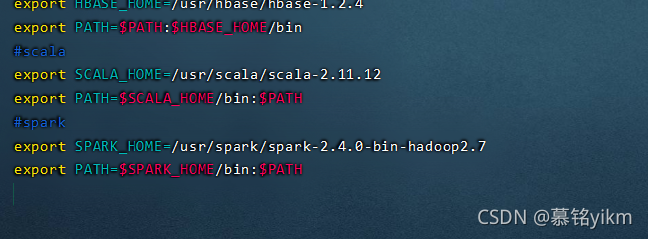
#spark
export SPARK_HOME=/usr/spark/spark-2.4.0-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
生效環境變數
source /etc/profile
分發到節點
scp -r /usr/spark/ root@slave1:/usr/
scp -r /usr/spark/ root@slave2:/usr/
測驗運行環境(只在master節點執行)
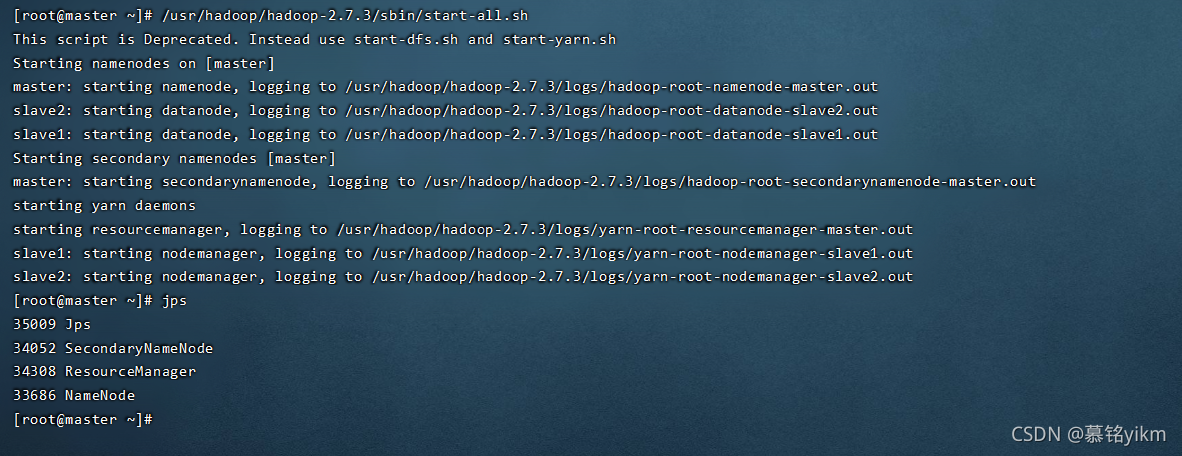
啟動hadoop
/usr/hadoop/hadoop-2.7.3/sbin/start-all.sh
啟動spark集群
/usr/spark/spark-2.4.0-bin-hadoop2.7/sbin/start-all.sh

jps查看行程



訪問spark web界面
192.168.111.3:8080 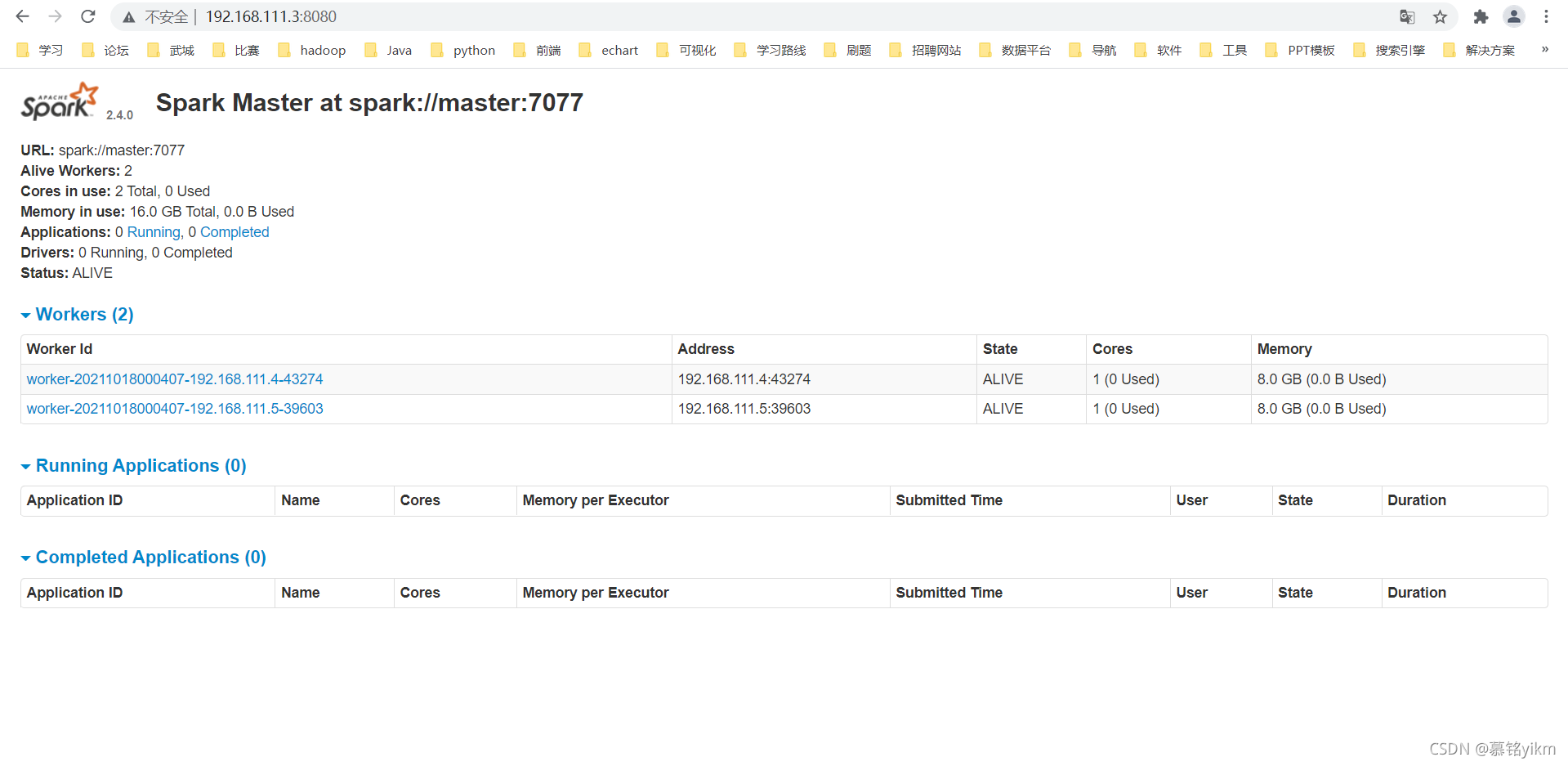
開啟spark-shell
spark-shell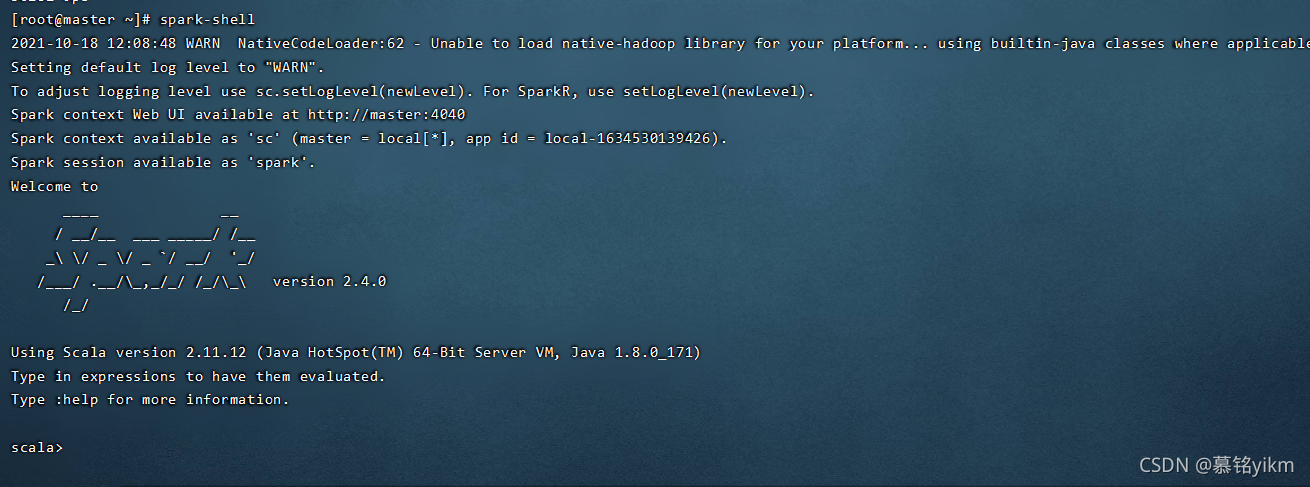
輸入以下命令測驗:
println("Hello world")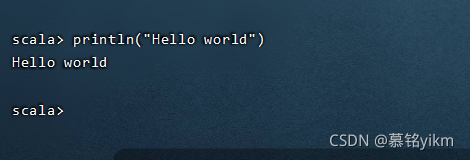
輸入pyspark測驗python環境spark互動模式
pyspark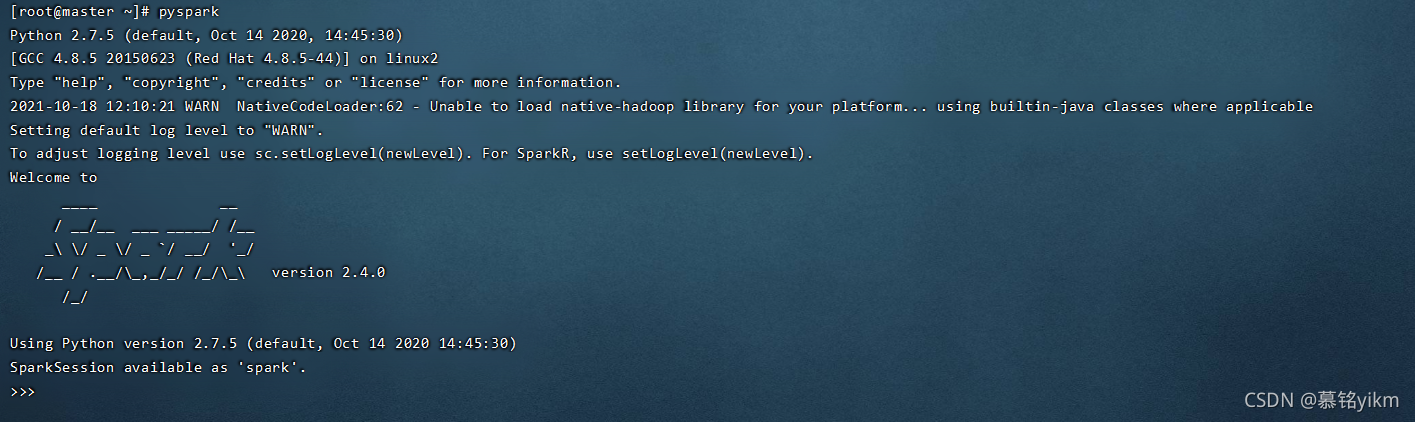
輸入命令測驗:
print("Hello world")
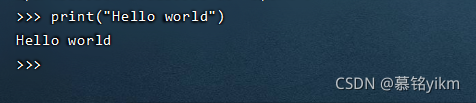
輸入quit()可退出

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/323377.html
標籤:其他