思路:通過開窗函式進行分組,然后實作topN的排序
- OVER函式
- 按需求查詢資料:
- (1)查詢在 2017 年 4 月份購買過的顧客及總人數
- (2) 查詢顧客的購買明細及月購買總額
- (3)將每個顧客的 cost 按照日期進行累加
- (4)查看顧客上次的購買時間
- (5) 查詢前 20%時間的訂單資訊
- RANK函式
- 使用rank()函式進行排序:
- 使用DESENS_RANK():
- 使用ROW_NUMBER():
OVER函式
OVER():指定分析函式作業的資料視窗大小,這個資料視窗大小可能會隨著行的變而變化,
CURRENT ROW:當前行
n PRECEDING:往前 n 行資料
n FOLLOWING:往后 n 行資料
UNBOUNDED:起點,
CURRENT ROW:當前行
n PRECEDING:往前 n 行資料
n FOLLOWING:往后 n 行資料
UNBOUNDED:起點,
UNBOUNDED PRECEDING 表示從前面的起點,
UNBOUNDED FOLLOWING 表示到后面的終點
LAG(col,n,default_val):往前第 n 行資料
LEAD(col,n, default_val):往后第 n 行資料
資料準備:
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
按需求查詢資料:
(1)查詢在 2017 年 4 月份購買過的顧客及總人數
思考:在做這個需求的時候,需要用到substring函式,因此,查看substring方法的具體用法,
hive (default)> desc function substring;
OK
tab_name
substring(str, pos[, len]) - returns the substring of str that starts at pos and is of length len orsubstring(bin, pos[, len]) - returns the slice of byte array that starts at pos and is of length len
Time taken: 0.093 seconds, Fetched: 1 row(s)
截取字串,start定義為pos,截取長度為len,
hive (default)> select substring(orderdate,0,7) from business;
OK
_c0
2017-01
2017-01
2017-02
2017-01
2017-01
2017-04
2017-01
2017-01
2017-04
2017-04
2017-05
2017-04
2017-06
2017-04
Time taken: 0.218 seconds, Fetched: 14 row(s)
如果是用以下的sql的話
select
name,
count(*)
from business
where substring(orderdate,0,7)='2017-04'
group by name;
他所得出的結果是根據name的個數來進行計算的,結果如下:
OK
name _c1
jack 1
mart 4
這個結果和我們題目中的需求不相符,我們需要的是,前面是name,后面是加總人數,在這里只要稍作修改,就能扭轉結果,如下:
select
name,
count(*) over()
from business
where substring(orderdate,0,7)='2017-04'
group by name;
結果:
name count_window_0
jack 2
mart 2
這里通過添加over()就將結果改變了,深入理解over的用法,over他的這個用法的話,相當于再name的后面進行開窗,開窗函式,每個name都開窗,本來name有14行,count(*)只有一行,現在count也有14行.
(2) 查詢顧客的購買明細及月購買總額
第一步,計算出顧客的購買明細以及購買總額:
select
name,
orderdate,
cost,
sum(cost) over(partition by name)
from business;
第二部計算出顧客的購買明細以及月購買總額:
select
name,
orderdate,
cost,
sum(cost) over(partition by name,month(orderdate))
from business;
結果如下:
OK
name orderdate cost sum_window_0
jack 2017-01-01 10 111.0
jack 2017-01-05 46 111.0
jack 2017-01-08 55 111.0
jack 2017-02-03 23 23.0
jack 2017-04-06 42 42.0
mart 2017-04-13 94 299.0
mart 2017-04-08 62 299.0
mart 2017-04-09 68 299.0
mart 2017-04-11 75 299.0
neil 2017-05-10 12 12.0
neil 2017-06-12 80 80.0
tony 2017-01-04 29 94.0
tony 2017-01-07 50 94.0
tony 2017-01-02 15 94.0
(3)將每個顧客的 cost 按照日期進行累加
select
name,
orderdate,
cost,
sum(cost) over(partition by name order by orderdate)
from business;
結果如下:
OK
name orderdate cost sum_window_0
jack 2017-01-01 10 10.0
jack 2017-01-05 46 56.0
jack 2017-01-08 55 111.0
jack 2017-02-03 23 134.0
jack 2017-04-06 42 176.0
mart 2017-04-08 62 62.0
mart 2017-04-09 68 130.0
mart 2017-04-11 75 205.0
mart 2017-04-13 94 299.0
neil 2017-05-10 12 12.0
neil 2017-06-12 80 92.0
tony 2017-01-02 15 15.0
tony 2017-01-04 29 44.0
tony 2017-01-07 50 94.0
根據name 進行磁區,然后每一行的開窗,都是從第一行開到當前行,進行一個累加,除了上面那種寫法還有另外一種寫法,因為上面在order by 之后沒有指定視窗,默認值的話就是第一行開窗到當前行, 相當于對上面那種寫法的補全:
select
name,
orderdate,
cost,
sum(cost) over(partition by name order by orderdate rows
between unbounded preceding and current row)
from business;
結果如下:
OK
name orderdate cost sum_window_0
jack 2017-01-01 10 10.0
jack 2017-01-05 46 56.0
jack 2017-01-08 55 111.0
jack 2017-02-03 23 134.0
jack 2017-04-06 42 176.0
mart 2017-04-08 62 62.0
mart 2017-04-09 68 130.0
mart 2017-04-11 75 205.0
mart 2017-04-13 94 299.0
neil 2017-05-10 12 12.0
neil 2017-06-12 80 92.0
tony 2017-01-02 15 15.0
tony 2017-01-04 29 44.0
tony 2017-01-07 50 94.0
Time taken: 103.08 seconds, Fetched: 14 row(s)
注意:如果over()后面接的是空的話,可以理解成對每一行都元素都開窗了,用下面這個例子來理解:
//建表導資料
create table num(id string);
load data local inpath '/opt/module/datas/num.txt' into table num;
hive (default)> select * from num;
OK
num.id
1
2
3
3
4
5
hive (default)> select id,sum(id) over() from num;
//查詢結果:
id sum_window_0
1 18.0
2 18.0
3 18.0
3 18.0
4 18.0
5 18.0
hive (default)> select id,sum(id) over(order by id) from num;
OK
id sum_window_0
1 1.0
2 3.0
3 9.0
3 9.0
4 13.0
5 18.0
//注意:這里出現兩個id為3的情況,進行開窗的時候,設定相同大小
如果排序中遇到兩個id都是一樣的,在開窗的時候,值為一樣的會被統一默認是一樣
(4)查看顧客上次的購買時間
通過使用lag函式,lag函式有三個引數,欄位,往前多少行,默認值,下面這個例子加深理解:
select
name,
orderdate,
cost,
lag(orderdate,1) over(partition by name order by orderdate)
from business;
結果如下:
OK
name orderdate cost lag_window_0
jack 2017-01-01 10 NULL
jack 2017-01-05 46 2017-01-01
jack 2017-01-08 55 2017-01-05
jack 2017-02-03 23 2017-01-08
jack 2017-04-06 42 2017-02-03
mart 2017-04-08 62 NULL
mart 2017-04-09 68 2017-04-08
mart 2017-04-11 75 2017-04-09
mart 2017-04-13 94 2017-04-11
neil 2017-05-10 12 NULL
neil 2017-06-12 80 2017-05-10
tony 2017-01-02 15 NULL
tony 2017-01-04 29 2017-01-02
tony 2017-01-07 50 2017-01-04
Time taken: 99.989 seconds, Fetched: 14 row(s)
我如果lag函式沒有傳入默認值的話,如果遇到NULL,則輸出NULL.
想把NULL做修改,如果遇到的值為NULL,則修改為默認值,可以用下面這個hive sql:
select
name,
orderdate,
cost,
lag(orderdate,1,'1990-01-01') over(partition by name order by orderdate)
from business;
結果如下,如果遇到的是null,則輸出默認值:
name orderdate cost lag_window_0
jack 2017-01-01 10 1990-01-01
jack 2017-01-05 46 2017-01-01
jack 2017-01-08 55 2017-01-05
jack 2017-02-03 23 2017-01-08
jack 2017-04-06 42 2017-02-03
mart 2017-04-08 62 1990-01-01
mart 2017-04-09 68 2017-04-08
mart 2017-04-11 75 2017-04-09
mart 2017-04-13 94 2017-04-11
neil 2017-05-10 12 1990-01-01
neil 2017-06-12 80 2017-05-10
tony 2017-01-02 15 1990-01-01
tony 2017-01-04 29 2017-01-02
tony 2017-01-07 50 2017-01-04
如果將默認值,寫成欄位本身,那么遇到NULL,則輸出自己:
select
name,
orderdate,
cost,
lag(orderdate,1,orderdate) over(partition by name order by orderdate)
from business;
輸出結果:
OK
name orderdate cost lag_window_0
jack 2017-01-01 10 2017-01-01
jack 2017-01-05 46 2017-01-01
jack 2017-01-08 55 2017-01-05
jack 2017-02-03 23 2017-01-08
jack 2017-04-06 42 2017-02-03
mart 2017-04-08 62 2017-04-08
mart 2017-04-09 68 2017-04-08
mart 2017-04-11 75 2017-04-09
mart 2017-04-13 94 2017-04-11
neil 2017-05-10 12 2017-05-10
neil 2017-06-12 80 2017-05-10
tony 2017-01-02 15 2017-01-02
tony 2017-01-04 29 2017-01-02
tony 2017-01-07 50 2017-01-04
Time taken: 39.097 seconds, Fetched: 14 row(s)
那么lead函式,就是往后n行:
select
name,
orderdate,
cost,
lead(orderdate,1,orderdate) over(partition by name order by orderdate)
from business;
最后一行的結果為null,輸出自己,結果如下:
OK
name orderdate cost lead_window_0
jack 2017-01-01 10 2017-01-05
jack 2017-01-05 46 2017-01-08
jack 2017-01-08 55 2017-02-03
jack 2017-02-03 23 2017-04-06
jack 2017-04-06 42 2017-04-06
mart 2017-04-08 62 2017-04-09
mart 2017-04-09 68 2017-04-11
mart 2017-04-11 75 2017-04-13
mart 2017-04-13 94 2017-04-13
neil 2017-05-10 12 2017-06-12
neil 2017-06-12 80 2017-06-12
tony 2017-01-02 15 2017-01-04
tony 2017-01-04 29 2017-01-07
tony 2017-01-07 50 2017-01-07
Time taken: 13.057 seconds, Fetched: 14 row(s)
(5) 查詢前 20%時間的訂單資訊
通過ntile函式對資料進行分組,要取前20%,分成5組,每一組就是20%
ntile(5)表示將資料資料分成5組:
select
name,
orderdate,
cost,
ntile(5) over( order by orderdate) groupId
from business;
結果如下:
name orderdate cost groupid
jack 2017-01-01 10 1
tony 2017-01-02 15 1
tony 2017-01-04 29 1
jack 2017-01-05 46 2
tony 2017-01-07 50 2
jack 2017-01-08 55 2
jack 2017-02-03 23 3
jack 2017-04-06 42 3
mart 2017-04-08 62 3
mart 2017-04-09 68 4
mart 2017-04-11 75 4
mart 2017-04-13 94 4
neil 2017-05-10 12 5
neil 2017-06-12 80 5
以上是分組的結果,再選取出前20%:
select
name,
orderdate,
cost
from
(select
name,
orderdate,
cost,
ntile(5) over( order by orderdate) groupId
from business)t1
where groupId=1;
前20%,輸出結果如下:
OK
name orderdate cost
jack 2017-01-01 10
tony 2017-01-02 15
tony 2017-01-04 29
如果要取中間的20%也行,
RANK函式
RANK() 排序相同時會重復,總數不會變
DENSE_RANK() 排序相同時會重復,總數會減少
ROW_NUMBER() 會根據順序計算.
RANK函式后面必須要跟著OVER.
資料準備 vim scoretxt:
孫悟空 語文 87
孫悟空 數學 95
孫悟空 英語 68
大海 語文 94
大海 數學 56
大海 英語 84
宋宋 語文 64
宋宋 數學 86
宋宋 英語 84
婷婷 語文 65
婷婷 數學 85
婷婷 英語 78
創建表匯入資料:
create table score (
name string,
subject string,
score int
)
row format delimited fields terminated by '\t';
load data local inpath '/opt/module/datas/score.txt'
into table score;
使用rank()函式進行排序:
hive (default)> select *,rank() over(order by score) from score;
查詢結果:
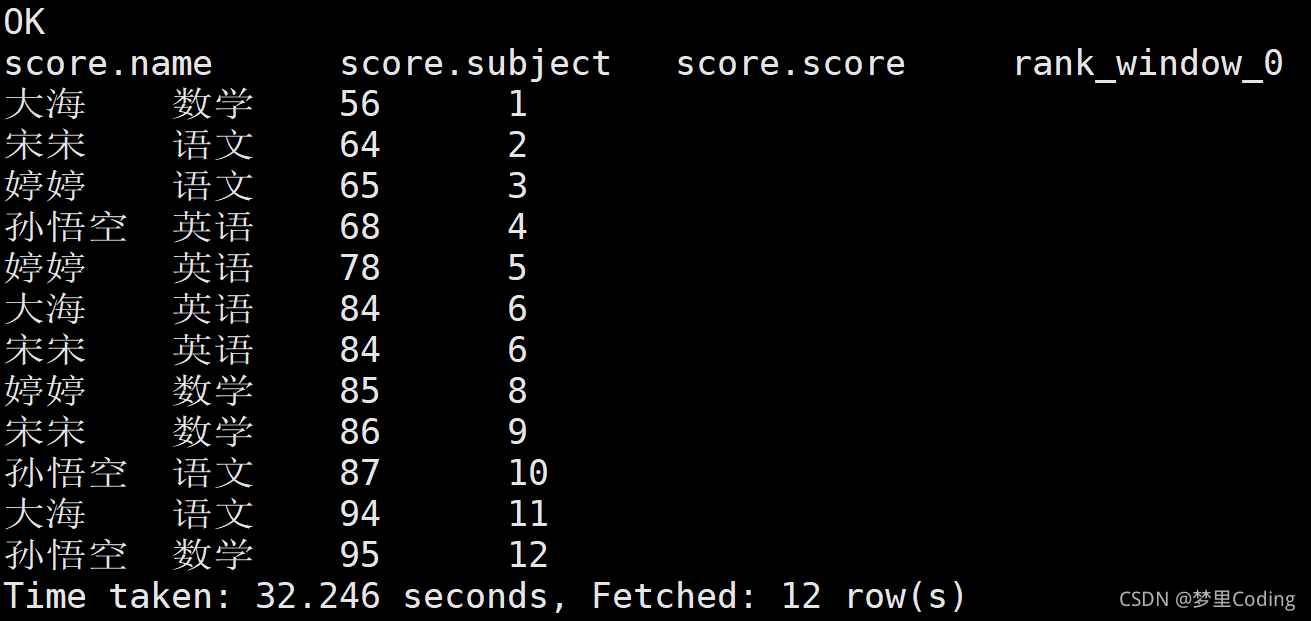
上面的查詢結果,認真觀察就會注意到遇到相同的,排名第6就會并排,沒有排名第7.
使用DESENS_RANK():
hive (default)> SELECT *,DENSE_rank() over(order by score) FROM score;
查詢結果如下:
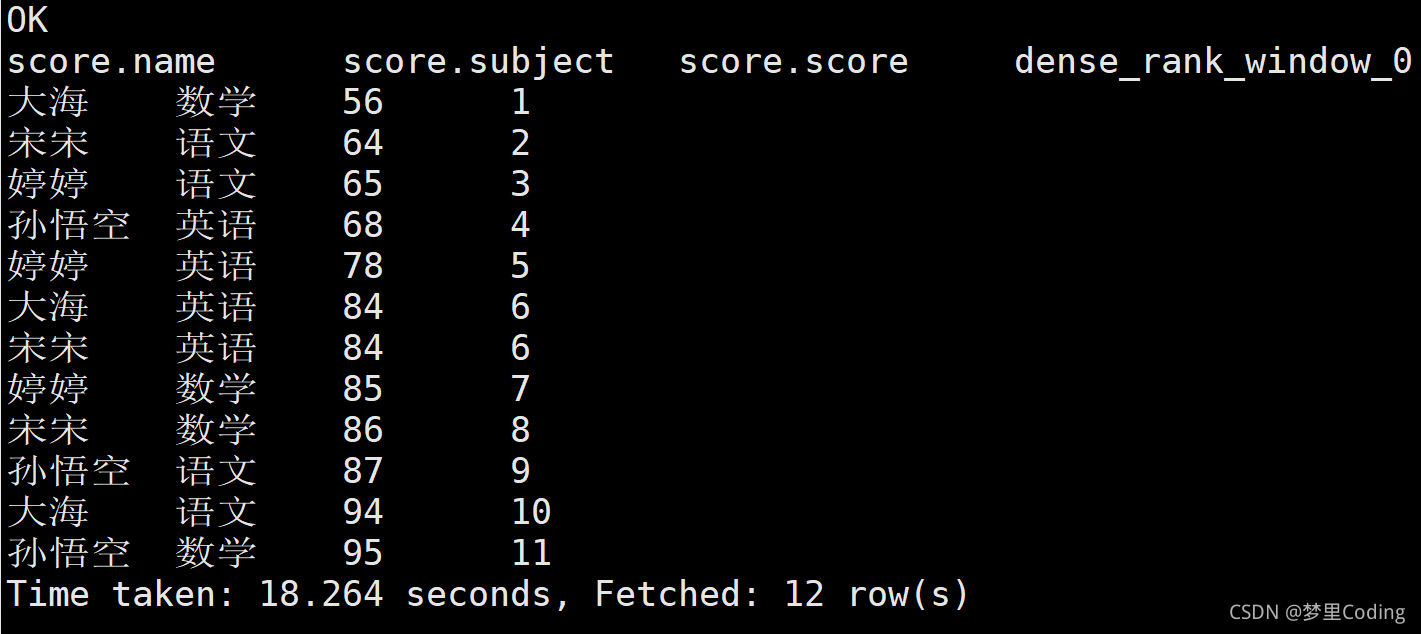
注意到了,總共是抓取12行,但是其排名也就11行
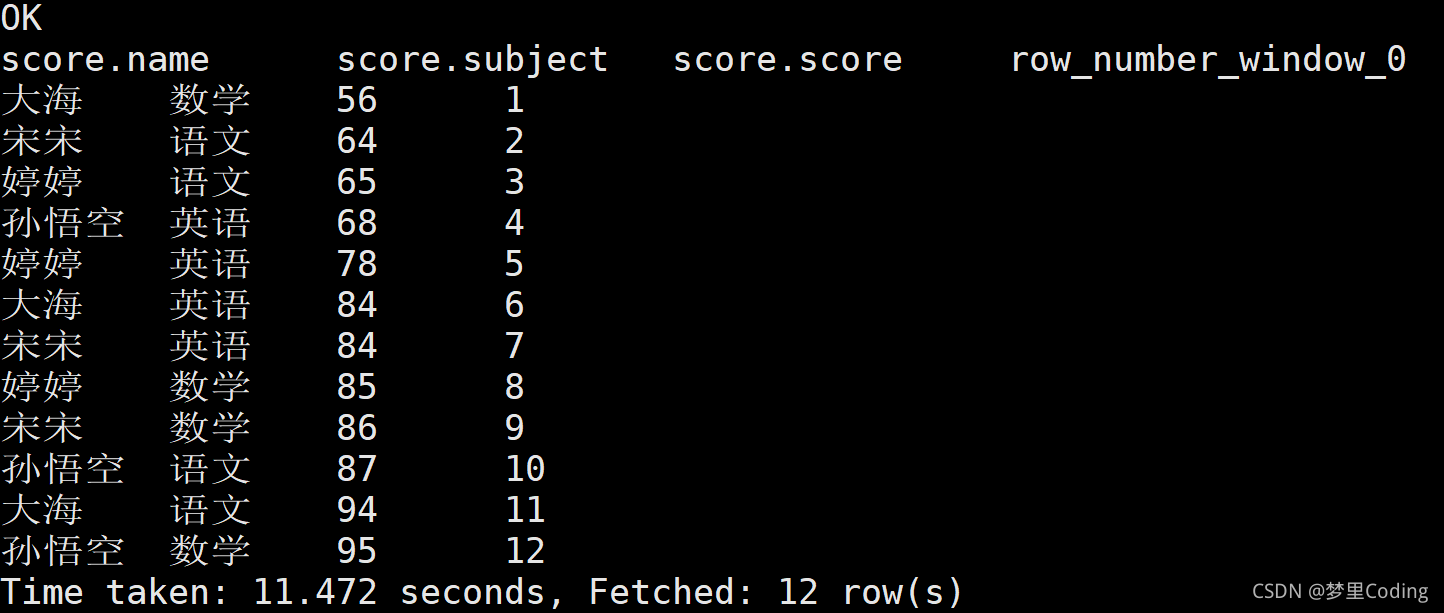
使用ROW_NUMBER():
SELECT *,ROW_NUMBER() over(order by score) FROM score;
查詢結果:
根據各個學科的成績來進行排序:
SELECT *,ROW_NUMBER() over(partition by subject order by score) FROM score;
查詢結果: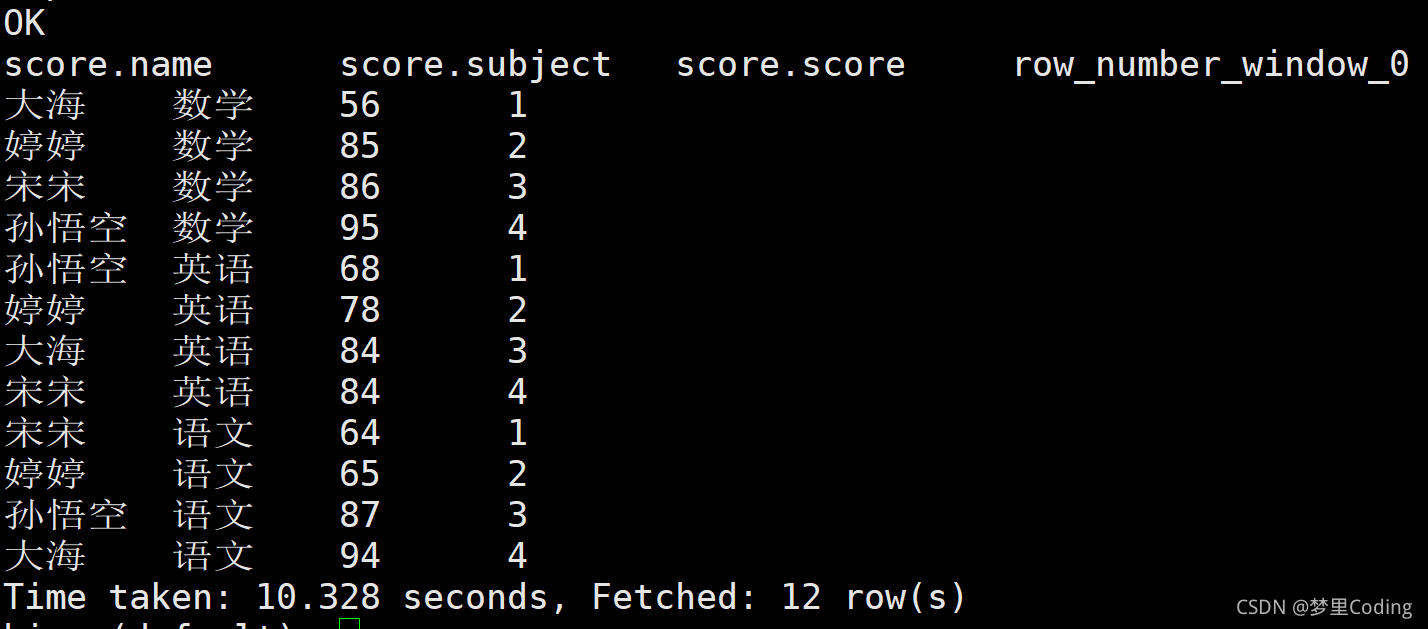
需求:取每個學科的前三名:
第一步,對每個學科進行排名:
SELECT *,
ROW_NUMBER() over(partition by subject order by score desc ) rk
FROM score;
再根據rk欄位取排名前三的:
select
name,
subject,
score
from
(SELECT *,
ROW_NUMBER() over(partition by subject order by score desc ) rk
FROM score)t1
where rk<=3;
查詢結果:
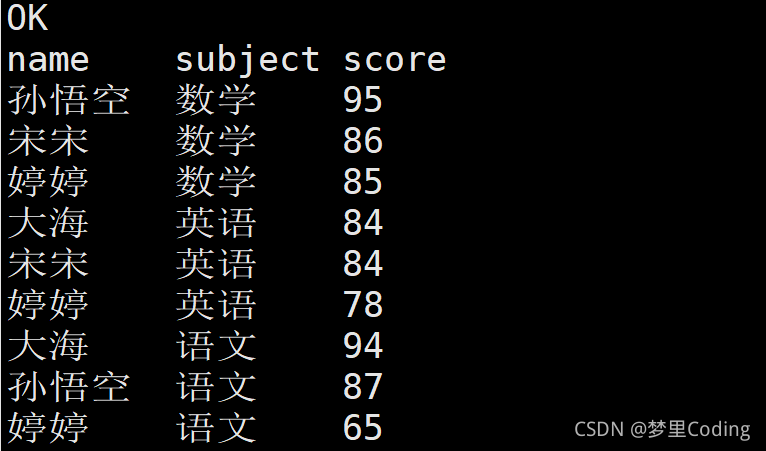
這樣每個學科取得了前三名,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/323380.html
標籤:其他