文章目錄
- 一、什么是KMP演算法?
- 二、KMP演算法的解決題型
- 三、模式串移動距離的判斷(next陣列)
- 四、KMP演算法的具體實作
- 五、KMP演算法的時間復雜度
- 六、next陣列的改進--nextval陣列及具體代碼
- 七、最后的話
一、什么是KMP演算法?
KMP演算法是一種改進的字串匹配演算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人們稱它為克努特—莫里斯—普拉特操作(簡稱KMP演算法),KMP演算法是在 BF 演算法基礎上改進得到的演算法,學習 BF 演算法我們知道,該演算法的實作程序就是 “傻瓜式” 地用模式串(假定為子串的串)與主串中的字符一一匹配,匹配不成功則回傳到上一次與主串匹配的下一位字符進行匹配,演算法執行效率不高,
二、KMP演算法的解決題型
KMP演算法是在資料結構中兩個字串相互匹配衍生出來的演算法,KMP演算法的作用是在一個已知字串中查找子串的位置,也叫做串的模式匹配,例如,對主串 A(“ABCABCE”)和模式串 B(“ABCE”)進行模式匹配,如果人為去判斷,僅需匹配兩次,雖然在以上字符較少的串中人為匹配很容易,但是讓計算機來匹配就相對慢一些,但是當字串中的字符非常多的時候,就不可能人為去匹配,所以打鐵還需自身硬,我們把這種枯燥的事以一定的演算法交給計算機處理,
圖1:
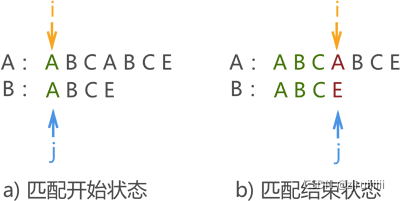
第一次如圖 1 所示,最終匹配失敗,但在本次匹配程序中,我們可以獲得一些資訊,模式串中 “ABC” 都和主串對應的字符相同,但模式串中字符 ‘A’ 與 ‘B’ 和 ‘C’ 不同,
因此進行下次模式匹配時,沒有必要讓串 B 中的 ‘A’ 與主串中第一次匹配的字符 ‘B’ 和 ‘C’ 一一匹配(它們絕不可能相同),而是直接去匹配失敗位置處的字符 ‘A’ ,如圖二所示,
圖2:
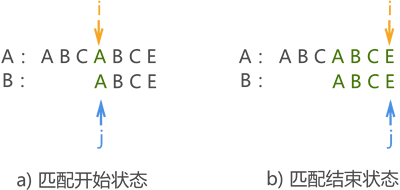
至此,匹配成功,若使用 BF 演算法,則此模式匹配程序需要進行 4 次,
由此可以看出,每次匹配失敗后模式串移動的距離不一定是 1,某些情況下一次可移動多個位置,這個位置是不確定的,因此這個不確定的移動位置就是KMP演算法的難點與重點,這就是 KMP 模式匹配演算法,
三、模式串移動距離的判斷(next陣列)
每次模式匹配失敗后,計算模式串向后移動的距離是 KMP 演算法中的核心部分,
其實,匹配失敗后模式串移動的距離和主串沒有關系,只與模式串本身有關系,
例如,我們將前面的模式串 B 改為 “ABCAE”,則在第一次模式匹配失敗,由于匹配失敗位置模式串中字符 ‘E’ 前面有兩個字符 ‘A’,因此,第二次模式匹配應改為圖三所示的位置:
圖三:
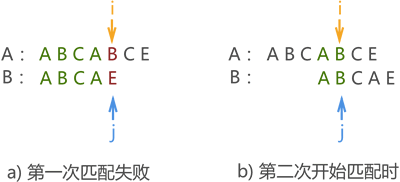
結合圖 1、圖 2 和圖 3 不難看出,模式串移動的距離只和自身有關系,和主串無關,換句話說,不論主串如何變換,只要給定模式串,則匹配失敗后移動的距離就已經確定了,
不僅如此,模式串中任何一個字符都可能導致匹配失敗,因此串中每個字符都應該對應一個數字,用來表示匹配失敗后模式串移動的距離,
因此,我們可以給每個模式串配備一個陣列(例如 next[]),用于存盤模式串中每個字符對應指標 j 重定向的位置(也就是存盤模式串的陣列下標),
模式串中各字符對應 next 值的計算方式是,取該字符前面的字串(不包含自己),其前綴字串和后綴字串相同字符的最大個數就是該字符對應的 next 值,
前綴字串指的是位于模式串起始位置的字串,例如模式串 “ABCD”,則 “A”、“AB”、“ABC” 以及 “ABCD” 都屬于前綴字串;后綴字串指的是位于串結尾處的字串,還拿模式串 “ABCD” 來說,“D”、“CD”、“BCD” 和 “ABCD” 為后綴字串,簡單地來說,next陣列的計算方式就是指不包含將要進行匹配的字符的前一個字符為后綴,而取模式串中第一個字符為首的字串作為前綴,并計算模式串中第一個字符作為前綴、將要比較的字符的上一個字符作為后綴的兩個相同的串長度就是將要進行匹配的字符的next[下標]值,沒有相同的則next值為0,next的值作為匹配不成功后下一次匹配將要回溯的模式串的下標,
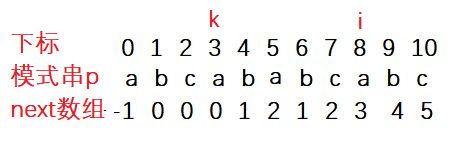
注意,模式串中第一個字符對應的值為 -1,第二個字符對應 0 ,這是固定不變的,因此,圖 3 的模式串 “ABCAE” 中,各字符對應的 next 值如圖4所示:
圖四:
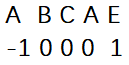
因為從前往后第一個字符’A’與字符’B’的next值已經確定,而字符‘C’的前面只有字符’A’與字符’B’,沒有相同的串則為0;再向后,將要進行匹配的字符’A’的前面有字符’A’、字符’B’、字符’C’,沒有以前綴為A,后綴為C的兩個字串,因此該字符’A’的next值為0;再向后,將要匹配的是’E’字符,而‘E’字符前面有以字符’A’為前綴,以字符’A’為后綴的字串,正是字串’A’,其長度為1(一個字符在此處用一個串來表示),則字符‘E’的的next值為1,
以上所講 next 陣列的實作方式是為了讓大家對此陣列的功能有一個初步的認識,接下來學習如何用編程的思想實作 next 陣列,編程實作 next 陣列要解決的主要問題依然是 “如何計算每個字符前面前綴字串和后綴字串相同的個數”,
以下有三種求得next陣列的情形,
情形一:
圖五:
我們觀察圖五,前提條件有next[i]=k與p[i]=p[k],假設模式串為p,可以觀察到有這樣的規律:式子一:p[0]...p[k-1]=p[x]...p[i-1] (第一個出現的串abc與i下標前面的一個串abc內容相等) ,因此x是模式串p中的某一個下標,有此規律后,可以衍生為k-1-0==i-1-x,最后求得x=i-k ,將x=i-k代回到式子一當中,有式子二:p[0]...p[k-1]=p[i-k]...p[i-1],因為有前提p[i]=p[k],則將p[i-1]改為p[i],p[k-1]改為p[k],因此又能運算得到式子三:p[0]...p[k]=p[i-k]...p[i],因為有式子三與前提條件next[i]=k,則能推出next[i+1]=k+1 (next陣列在任何情況下都要成立此條件),
圖六:

情形二:
圖七:

此時不滿足p[i]=p[k](任何時候都令next[i]=k),那么這種情形下如何求得next陣列的下標呢?如果對情形一理解了,理解情形二就會簡單很多,如果p[i]!=p[k],則以圖七舉例,第一次匹配不成功,模式串p回退到下標為2的位置,但是下標為2的位置的字符開始就不一定是要找的字符,此時就需要繼續回退,回退到了下標0,即第一個字符‘a’,這時我們發現居然再次滿足了next[i+1]=k+1,
當然還有一種特殊情況,只是單純舉例求得next陣列,也就是當我們如果回溯到第一個字符時仍然不相同,此時到達的是下標為-1的字符中,但是我們的陣列中是不存在下標為-1的,因此回溯到下標為0的就無法再回溯了,只能從模式串p的第一個字符開始重新匹配,
注意:
- next陣列的值每次只能加1,不能跳著加,否則一定是錯的,
- 當確定將要確定某個字符對應的next的值并且與它的下標為k的字符不相同時,將要確定某個字符的next值不一定要從0開始,
- 用編程來實作next陣列需要注意的是我們不知道第i的next值為多少,但是我們知道只要有p[i]=p[k],則必定有next[i+1]=k,因此我們要從前往后推,只在next陣列的下標為0的值放入-1,其他的next值都進行“知前往后”推導,
這里給出使用上述思想實作 next 陣列的 C 語言代碼:
#include <stdio.h>
#include <string.h>
#include <assert.h>
#include <stdlib.h>
void GetNext(char* arr2, int* next)//arr2為字串
{
int i = 0;
int k = -1;
int len2 = strlen(arr2);
next[0] = -1;
while (i < len2)
{
if (k == -1 || arr2[i] == arr2[k])//k==-1時有兩種情況:第一種是一開始k就為-1,第二種是k=-1是不能再回溯,
{
k++;//若相等則k一定只加1
i++;//子串往后移一位里放next的值
next[i] = k;//放入next的值
}
else
{
k = next[k];//字符不同則回溯
}
}
}
int KMP(char* arr1, char* arr2) //arr1為主串,arr2為字串
{
assert(arr1 && arr2); //保證傳入的指標不是空指標
int len1 = strlen(arr1);
int len2 = strlen(arr2);
if (len2<0 || len2>len1)
{
return -1;
}
if (len1 == 0 || len2 == 0) //兩種不可能的情況
{
return -1;
}
int* next = (int*)malloc(sizeof(int) * len2);//為next陣列動態開辟空間
GetNext(arr2, next);
int i = 0;
int j = 0;
while (j == -1 || i < len1 && j < len2)
{
if (arr1[i] == arr2[j])//比較相等均后移一位
{
i++;
j++;
}
else
{
j = next[j];//不相等則回溯子串,主串不動
}
}
if (j >= len2)
{
return i - j;//回傳主串與字串開始匹配到成功的開始位置
}
return -1;//子串與主串沒有可匹配的字串
}
int main()
{
char arr1[] = "abababcabc";
char arr2[] = "abcabc";
printf("%d", KMP(arr1, arr2));
return 0;
}
四、KMP演算法的具體實作
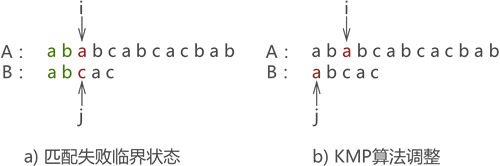
假設主串 A 為 “ababcabcacbab”,模式串 B 為 “abcac”,則 KMP 演算法執行程序為:
- 第一次匹配如圖八所示,匹配結果失敗,指標 j 移動至 next[j] 的位置:
圖八:
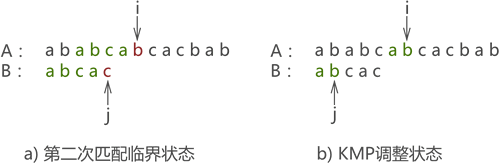
- 第二次匹配如圖九所示,匹配結果失敗,依舊執行 j=next[j] 操作:
圖九:
- 第三次匹配成功,如圖十所示:
圖十:
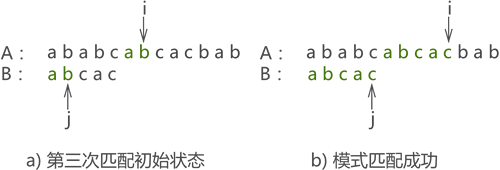
很明顯,使用 KMP 演算法只需匹配 3 次,而同樣的問題使用 BF 演算法則需匹配 6 次才能完成,
五、KMP演算法的時間復雜度
現在我們分析一下KMP演算法的時間復雜度:
KMP演算法中多了一個求陣列的程序,多消耗了一點點空間,我們設主串s長度為n,子串t的長度為m,求next陣列時時間復雜度為O(m),因后面匹配中主串不回溯,比較次數可記為n,所以KMP演算法的總時間復雜度為O(m+n),空間復雜度記為O(m),只為next陣列開辟了m個int位元組大小的空間,相比于樸素的模式匹配時間復雜度O(m*n),KMP演算法提速是非常大的,
六、next陣列的改進–nextval陣列及具體代碼
圖十一:
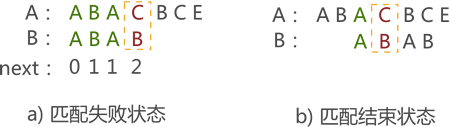
例如,在圖十一中的a),當匹配失敗時,Next 函式會由圖十一的 b) 開始繼續進行模式匹配,但是從圖中可以看到,這樣做是沒有必要的,純屬浪費時間,應該直接從第一個字符‘A’重新開始匹配,那么如何改進next陣列呢?
圖十二:

使用精簡過后的 next 陣列在解決例如模式串為 “aaaaaaab” 這類的問題上,會大大提高效率,如圖十二所示,精簡前為 next1,精簡后為 next2,當然如果人為來求,將需要先求出next的陣列后才能求得nextval陣列,
結論:如果a位字符與它next值指向的b位字符相等,則該a位的nextval就指向b位的nextval值,如果不等,則該a位的nextval值就是它自己a位的next值,
next陣列改進后的代碼:
#include <stdio.h>
#include <string.h>
#include <assert.h>
#include <stdlib.h>
void GetNext(char* arr2, int* next)
{
int i = 0;
int k = -1;
int len2 = strlen(arr2);
next[0] = -1;
while (i < len2)
{
if (k == -1 || arr2[i] == arr2[k])
{
k++;
i++;
if (arr2[i] == arr2[k])//進入第一個if陳述句后向后一位的字符該arr2[i]與arr2[k]仍然相等則直接一次性回溯到位
{
next[i] = next[k];
}
else //arr2[i] != arr2[k]
{
next[i] = k; //不用多次回溯,跟next陣列一樣
}
}
else
{
k = next[k];
}
}
}
int KMP(char* arr1, char* arr2)
{
assert(arr1 && arr2);
int len1 = strlen(arr1);
int len2 = strlen(arr2);
if (len2<0 || len2>len1)
{
return -1;
}
if (len1 == 0 || len2 == 0)
{
return -1;
}
int* next = (int*)malloc(sizeof(int) * len2);
GetNext(arr2, next);
int i = 0;
int j = 0;
while (j == -1 || i < len1 && j < len2)
{
if (arr1[i] == arr2[j])
{
i++;
j++;
}
else
{
j = next[j];
}
}
if (j >= len2)
{
return i - j;
}
return -1;
}
int main()
{
char arr1[] = "abababcabc";
char arr2[] = "abcabc";
printf("%d", KMP(arr1, arr2));
return 0;
}
七、最后的話
實不相瞞,作者對KMP演算法的了解一開始非常懵,只有不斷重復思考、復習與親自敲代碼的練習如今才對KMP演算法非常了解,才有了這篇博客得以展現給大家,當然如果對KMP演算法還有什么誤區與此篇博客需要改進的地方可私聊討論,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/323439.html
標籤:其他