目錄
1. 概念
2. 概率分布
2.1 概率質量函式
2.2 概率分布函式
2.3 生存函式,風險函式
2.4 百分點函式
3. 常用統計特征
3.1 均值,Mean
3.2 中位數,Median
3.3 眾數,Mode
3.4 方差,Variance
3.5 偏度,Skewness
3.6 峰度,Kurtosis
4. 代碼示例
1. 概念
設試驗E只有兩種可能的結果,這種試驗稱為伯努利試驗,伯努利試驗的結果為一個隨機變數,它遵循伯努利分布,
伯努利分布也稱為(0-1)分布,遵循伯努利分布的隨機變數只有兩種取值,分別用0和1表示(分別對應試驗的兩種結果),典型的例子是扔硬幣實驗結果,將扔硬幣的實驗結果(正面向上或向下)看作是一個隨機變數X,則X遵循伯努利分布,這是一種離散分布,記為:
其中通常p表示X取值為1的概率,
2. 概率分布
2.1 概率質量函式
PMF: Probability Mass Function
有些書也寫作分布律(如浙大版<<概率論與數理統計>>),與連續隨機變數的PDF(Probability Density Function: 概率密度函式)相對應),
伯努利分布的概率質量函式為:
當然,為了和條件概率區分開來,也有將 寫成 的寫法,一般情況下根據背景關系也可以做出區分,
也可以進一步簡記(未必簡單,但是對于要做數學推導處理等就比較方便)為:
![]()
其中I(x)是所謂的Indicator函式,因此,以上式表示僅在x=0或x=1時成立,其它情況下則為0.
2.2 概率分布函式
伯努利分布的概率分布函式(CDF: Cumulative Distribution Function,累積分布函式,不管對于離散隨機變數還是連續隨機變數,CDF總是一個連續函式,只不過對于離散隨機變數而言,CDF是一個分段函式:piecewise function)如下所示:
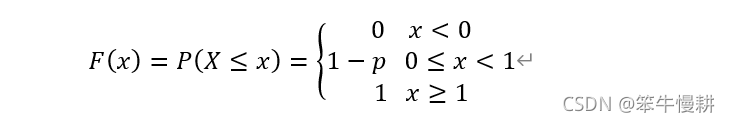
2.3 生存函式,風險函式
生存函式是概率分布函式的互補函式,定義為: ,伯努利分布的生存函式為:
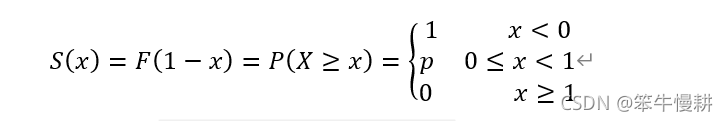
與生存函式相關聯風險函式定義為:![]()
注意,風險函式僅在S(x)的非零區間(In other words, only valid on S support)有定義,伯努利分布的風險函式為:
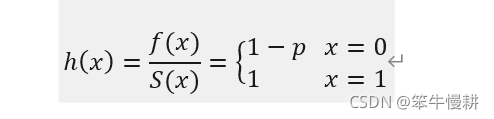
伯努利分布的累計風險函式為:
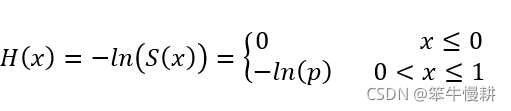
(???待確認)
2.4 百分點函式
PPF: Percent Point Function. 也稱百分位數(percentile)?
百分點函式PPF是CDF的反函式,它回答了“為了得到一定的累積分布概率,CDF相應的輸入值是什么”的問題,伯努利分布的百分點函式為:
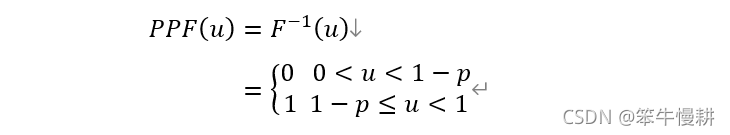
3. 常用統計特征
3.1 均值,Mean
3.2 中位數,Median
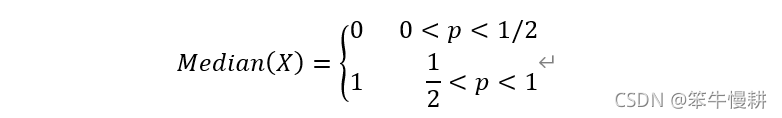
3.3 眾數,Mode
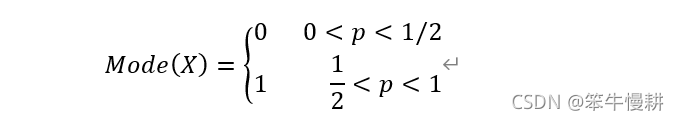
3.4 方差,Variance
3.5 偏度,Skewness
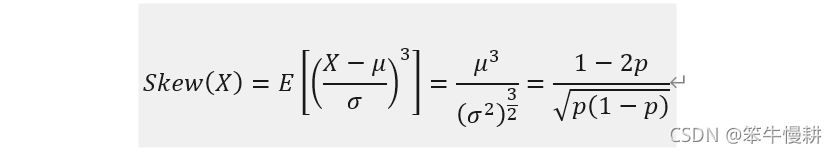
3.6 峰度,Kurtosis
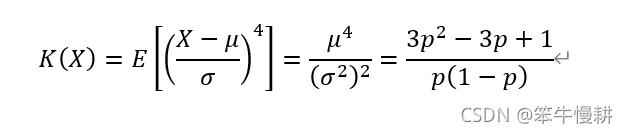
4. 代碼示例
首先,匯入必要的庫,
import random
import numpy as np
from scipy.stats import bernoulli
%matplotlib inline
from matplotlib import pyplot as plt看看p=0.4條件下的PMF函式 :
fig, ax = plt.subplots(1, 1)
p = 0.4
x = np.arange(-1,3)
ax.plot(x, bernoulli.pmf(x, p), 'bo', ms=8, label='bernoulli pmf')
ax.vlines(x, 0, bernoulli.pmf(x, p), colors='b', lw=5, alpha=0.5)
#rv = bernoulli(p)
#ax.vlines(x, 0, rv.pmf(x), colors='k', linestyles='-', lw=1, label='frozen pmf')
ax.legend(loc='best', frameon=False)
ax.grid()
plt.show()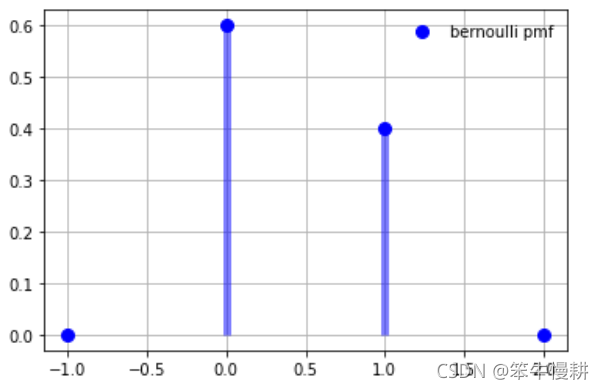
x=0時概率等于0.6, x=1時等于0.4,符合預期,
看看CDF與PPF的關系(它們是互逆的關系):
cdf_prob = bernoulli.cdf(x, p)
print('cdf_prob[{0}] = {1}'.format(x,cdf_prob))
print('ppf[{0}] = {1}'.format(cdf_prob,bernoulli.ppf(cdf_prob, p)))Output:
cdf_prob[[-1 0 1 2]] = [0. 0.6 1. 1. ]
ppf[[0. 0.6 1. 1. ]] = [-1. 0. 1. 1.]
注意存在在不滿足可逆條件的區間,cdf(2) = 1, 而ppf(1) = 1,這是可以理解的,因為對于在x>=1的區間,cdf的定義域到值域不是一一映射,因此不可逆,所以ppf(cdf(x))不一定等于x,
4種常用的統計特征:
p=0.5
mean, var, skew, kurt = bernoulli.stats(p, moments='mvsk')
print('Bernoulli distribution with p ={}'.format(p))
print('mean = {0}, var = {1}, skew = {2}, kurt = {3}'.format(mean, var, skew, kurt))
p=0.4
mean, var, skew, kurt = bernoulli.stats(p, moments='mvsk')
print('Bernoulli distribution with p ={}'.format(p))
print('mean = {0}, var = {1}, skew = {2}, kurt = {3}'.format(mean, var, skew, kurt))
當p=0.5時,說明0和1是等概率的,因此是一個對稱的分布,因此3階中心矩(對應Skewness)變為0,p!=0.5時,分布變為非對稱的了,skewness變為非0就顯示了分布非對稱性,
來看看實際采樣實驗,即基于scipy.stats提供的函式進行亂數采樣,然后看看它的統計特征是否符合預期,
r = bernoulli.rvs(p, size=10000)
_ = plt.hist(r, bins='auto', density=True) # arguments are passed to np.histogram
plt.title("Histogram with 'auto' bins")
plt.grid()
plt.show()
print('sample means of r = {0}'.format(np.mean(r)))
print('sample variance of r = {0}'.format(np.var(r)))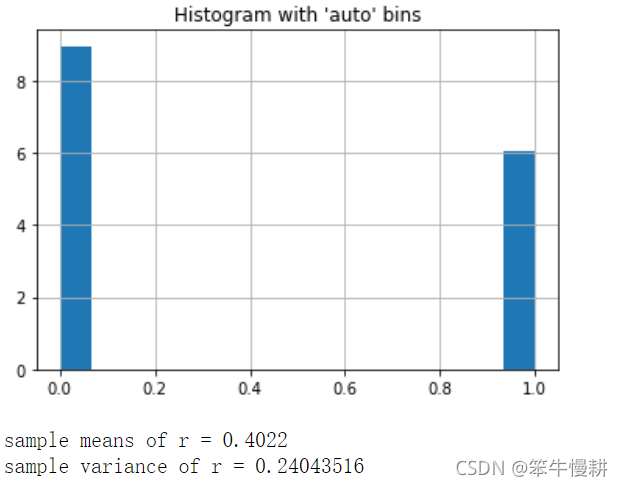
mean和variance是符合預期的,
但是直方圖上(雖然已經選擇了是density=True),所顯示的兩個離散點的值的和并不為1,這個是numpy的histogram()函式(plt.hist()是呼叫numpy的histogram())的行為所致,查閱numpy.histogram()的手冊有如下說明:
histogram() parameter: densitybool, optional If False, the result will contain the number of samples in each bin. If True, the result is the value of the probability density function at the bin, normalized such that the integral over the range is 1. Note that the sum of the histogram values will not be equal to 1 unless bins of unity width are chosen; it is not a probability mass function.
但是這個畢竟不甚方便,需要琢磨一下如何讓直方圖能夠進行歸一化計算和顯示,
上一篇:面向機器學習的概率統計:均勻分布(Uniform Distribution)https://blog.csdn.net/chenxy_bwave/article/details/120725136![]() https://blog.csdn.net/chenxy_bwave/article/details/120725136
https://blog.csdn.net/chenxy_bwave/article/details/120725136
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/325418.html
標籤:AI