Logistic 回歸
- 創作背景
- 回歸與分類的區別
- 回歸向分類的轉變
- 飽和函式
- sigmoid 函式(logistic 函式)
- 極大似然估計
- 梯度下降更新公式
- 代碼實作
- 自己實作
- 利用 sklearn 實作
- 參考資料
- 結尾
創作背景
本菜雞最近想學學 機器學習,這不,剛開始,
如果覺得我這篇文章寫的好的話,能不能給我 點個贊 ,評論 一波,如果要點個 關注 的話也不是不可以🤗
回歸與分類的區別
- 回歸 要預測的結果是 具體的數值,根據訓練資料預測某一輸入對應的輸出資料,輸出的結果是 實數,
- 分類 要判斷的結果是 類別,根據訓練資料預測 分類正確的概率 (屬于
[0, 1]),進而輸出 判斷的類別 ,
回歸向分類的轉變
既然都是 預測,使用相同的 x ,只是輸出從原來的 實數 變成了 類別,那我們就用一個函式將結果從 實數集 映射到 [0, 1] 中,然后再轉成對應分類不就行了唄,
- 舉個栗子:
- 有兩個類別的實體,
o代表正例,x代表負例 - 可以找到一個超平面
w
T
x
+
b
=
0
{w}^{T}x+b=0
wTx+b=0 將兩類實體分隔開,即
正確分類 - 其中,
w
∈
R
n
w \in {\mathbb{R}}^{n}
w∈Rn 為超平面的
法向量, b ∈ R b \in \mathbb{R} b∈R 為偏置 - 超平面上方的點都滿足 w T x + b > 0 {w}^{T}x+b>0 wTx+b>0
- 超平面下方的點都滿足 w T x + b < 0 {w}^{T}x+b<0 wTx+b<0
- 可以根據以下
x的線性函式值(與 0 的比較結果)判斷實體類別: z = g ( x ) = w T x + b z=g(x)={w}^{T}x+b z=g(x)=wTx+b - 分類函式以
z為輸入,輸出預測的類別: c = H ( z ) = H ( g ( x ) ) c=H(z)=H(g(x)) c=H(z)=H(g(x))
- 有兩個類別的實體,
- 以上是 線性分類器 的基本模型,
有個方法可以實作 線性分類器 ,那就是 Logistic 回歸,
Logistic回歸是一種 廣義線性 模型,使用 線性判別式函式 對實體進行分類,
而一般實作這種分類方法的函式是 sigmoid 函式,(因為其中最為出名的是 logistic 函式,所以也被稱為 logistic 函式),
飽和函式
先看一下 飽和函式,至于為什么要看這個函式,因為 Sigmoid 函式都需要滿足這個函式,具體見下述 sigmoid (也即 logistic) 函式,
x < 0時,導數值↑,x ≥ 0時,導數值↓,即,將導函式為 正態分布 的分布函式稱為 飽和函式 ,- 看一下影像,
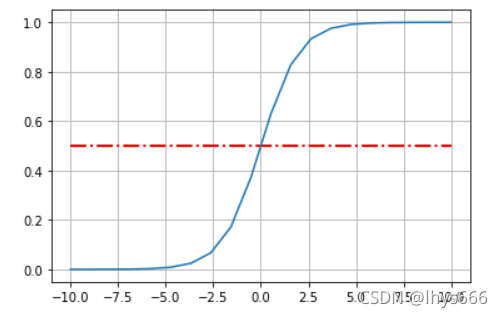
一些飽和函式
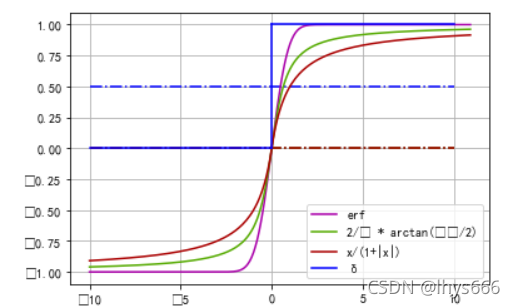
- 單位階躍函式
δ - e r f ( π 2 x ) erf(\frac{\sqrt {\pi}}{2}x) erf(2π ??x)
- 2 π arctan ? ( π 2 x ) \frac{2}{\pi} \arctan {(\frac{\pi}{2}x)} π2?arctan(2π?x)
- 2 π g d ( π 2 x ) \frac{2}{\pi} gd(\frac{\pi}{2}x) π2?gd(2π?x)
- x 1 + ∣ x ∣ \frac{x}{1+|x|} 1+∣x∣x?
影像如下
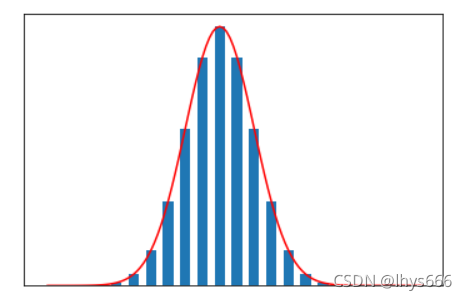
它們的導函式是服從 正態分布 的,影像如下
所以,最理想的分類函式為 單位階躍函式 ,直上直下的,是 飽和函式 的一種,如下圖

也就是
H
(
z
)
=
{
0
,
x
<
0
0.5
,
x
=
0
1
,
x
>
0
H(z)= \begin{cases} 0, x<0 \\ 0.5, x=0 \\ 1, x>0 \end{cases}
H(z)=??????0,x<00.5,x=01,x>0?
- 但單位階躍函式作為分類函式有一個嚴重缺點,不連續,所以 不是處處可微,使得一些演算法不可用(如 梯度下降),
- 找一個 輸入輸出特性與單位階躍函式類似,并且 單調可微的函式 來代替階躍函式,
sigmoid函式是一種常用替代函式,
sigmoid 函式(logistic 函式)
sigmoid 函式是一類函式,滿足以下函式特征即可:
- 有極限
- 單調 增 函式
- 滿足 飽和函式 (知道我為什么要提到 飽和函式 了吧(●’?’●))
函式定義
σ
(
x
)
=
1
1
+
e
?
z
\sigma(x)=\frac{1}{1+{e}^{-z}}
σ(x)=1+e?z1?
- 一般
σ
\sigma
σ 函式就指
logistic函式
logistic 函式的值域在 (0,1) 之間連續,函式的輸出可視為 x 條件下實體為正例的條件概率 ,即
P
(
y
=
1
∣
x
)
=
σ
(
g
(
x
)
)
=
1
1
+
e
?
(
w
T
x
+
b
)
P(y=1|x)=\sigma (g(x))=\frac{1}{1+{e}^{-({w}^{T}x+b)}}
P(y=1∣x)=σ(g(x))=1+e?(wTx+b)1?
x 條件下實體為負例的條件概率為
P
(
y
=
0
∣
x
)
=
1
?
σ
(
g
(
x
)
)
=
1
1
+
e
(
w
T
x
+
b
)
P(y=0|x)=1-\sigma (g(x))=\frac{1}{1+{e}^{({w}^{T}x+b)}}
P(y=0∣x)=1?σ(g(x))=1+e(wTx+b)1?
logistic 函式是 對數概率函式 的 反函式,一個事件的概率指該事件發生的概率 p 與該事件不發生的概率 1-p 的比值,
- 對數概率為
log ? p 1 ? p \log{\frac{p}{1-p}} log1?pp? - 對數概率大于 0 表明 正例 的概率大,反之,則 負例 的概率大,
Logistic 回歸模型假設一個實體為正例的對數概率是輸入 x 的 線性函式,即:
log
?
p
1
?
p
=
w
T
x
+
b
\log {\frac{p}{1-p}}={w}^{T}x+b
log1?pp?=wTx+b
反求 p ,即:
p
=
σ
(
g
(
x
)
)
=
1
1
+
e
?
(
w
T
x
+
b
)
p = \sigma(g(x))=\frac{1}{1+{e}^{-({w}^{T}x+b)}}
p=σ(g(x))=1+e?(wTx+b)1?
logistic 函式有個很好的數學特性,
σ
(
z
)
\sigma(z)
σ(z) 一階導數形式簡單,并且關于其本身的函式:
d
σ
(
z
)
d
z
=
σ
(
z
)
(
1
?
σ
(
z
)
)
\frac{d \sigma(z)}{dz} = \sigma(z) (1-\sigma(z))
dzdσ(z)?=σ(z)(1?σ(z))
Logistic 回歸模型假設函式為
h
w
,
b
(
x
)
=
σ
(
g
(
x
)
)
=
1
1
+
e
?
(
w
T
x
+
b
)
{h}_{w,b}(x) = \sigma (g(x)) = \frac{1}{1+{e}^{-({w}^{T}x+b)}}
hw,b?(x)=σ(g(x))=1+e?(wTx+b)1?
將 b 納入權向量 w ,假設函式更改為
h
w
(
x
)
=
1
1
+
e
?
(
w
T
x
)
{h}_{w}(x) = \frac{1}{1+{e}^{-({w}^{T}x)}}
hw?(x)=1+e?(wTx)1?
極大似然估計
- 根據 h w ( x ) {h}_{w}(x) hw?(x) 的概率意義,有
P ( y = 1 ∣ x ) = h w ( x ) P ( y = 0 ∣ x ) = 1 ? h w ( x ) P(y=1|x)={h}_{w}(x) \\ P(y=0|x)=1-{h}_{w}(x) P(y=1∣x)=hw?(x)P(y=0∣x)=1?hw?(x)
- 由此可得,訓練集
D中的某樣本 ( x i , y i ) ({x}_{i}, {y}_{i}) (xi?,yi?) ,模型將輸入實體 x i {x}_{i} xi? 預測為類別 y i {y}_{i} yi? 的概率為
P ( y = y i ∣ x i ; w ) = h w ( x i ) y i ( 1 ? h w ( x i ) ) 1 ? y i P(y={y}_{i}|{x}_{i};w)={h}_{w}({x}_{i})^{{y}_{i}}(1-{h}_{w}({x}_{i}))^{1-{y}_{i}} P(y=yi?∣xi?;w)=hw?(xi?)yi?(1?hw?(xi?))1?yi?
- 訓練集
D各樣本獨立同分布,定義似然函式L(w)描述訓練集中m個樣本同時出現的概率,公式如下:
L ( w ) = Π i = 1 m P ( y = y i ∣ x i ; w ) = ∏ i = 1 m h w ( x i ) y i ( 1 ? h w ( x i ) ) 1 ? y i L(w)=\Pi^{m}_{i=1}{P(y={y}_{i}|{x}_{i};w)} \\ =\prod \limits_{i=1}^{m}{h}_{w}({x}_{i})^{{y}_{i}}(1-{h}_{w}({x}_{i}))^{1-{y}_{i}} L(w)=Πi=1m?P(y=yi?∣xi?;w)=i=1∏m?hw?(xi?)yi?(1?hw?(xi?))1?yi?
用 極大似然法 估計引數 w 的核心思想是
- 選擇引數
w,使得當前已經觀測到的資料(訓練集中的m個樣本)最有可能出現(概率最大),即:
w ^ = a r g w m a x ? L ( w ) \hat{w}={arg}_{w}max \, L(w) w^=argw?maxL(w)
- 為了 方便求極值點 ,可將找
L(w)的極值點轉化為找其對數似然函式ln(L(w))的最大值點,即:
w ^ = a r g w m a x ? l n ( L ( w ) ) \hat{w} = {arg}_{w}max \, ln(L(w)) w^=argw?maxln(L(w))
- 根據定義,對數似然函式為
l ( w ) = l n ( L ( w ) ) = ∑ i = 1 m y i l n ( h w ( x i ) ) + ( 1 ? y i ) l n ( 1 ? h w ( x i ) ) l(w)=ln(L(w))=\displaystyle \sum ^{m}_{i=1}{{y}_{i}ln({h}_{w}({x}_{i}))}+(1-{y}_{i})ln(1-{h}_{w}({x}_{i})) l(w)=ln(L(w))=i=1∑m?yi?ln(hw?(xi?))+(1?yi?)ln(1?hw?(xi?))
梯度下降更新公式
對于 Logistic 回歸模型,可以定義其損失為:
J ( w ) = ? 1 m l ( w ) = ? 1 m ∑ i = 1 m y i l n ( h w ( x i ) ) + ( 1 ? y i ) l n ( 1 ? h w ( x i ) ) J(w)=-\frac{1}{m} \ l(w)=-\frac{1}{m} \displaystyle \sum ^{m}_{i=1}{{y}_{i} \ ln({h}_{w}({x}_{i}))+(1-{y}_{i}) \ ln(1-{h}_{w}({x}_{i}))} J(w)=?m1? l(w)=?m1?i=1∑m?yi? ln(hw?(xi?))+(1?yi?) ln(1?hw?(xi?))
- 此時,求出損失函式 最小值 與求出對數似然函式 最大值
等價,求損失函式最小值依然可以使用 梯度下降演算法 ,最終估計出模型引數 w ^ \hat{w} w^
計算 J(w) 對分量
w
j
{w}_{j}
wj? 的偏導數(就對上邊的公式 求導)
?
?
w
j
J
(
w
)
=
?
1
m
∑
i
=
1
m
y
i
l
n
h
w
(
x
i
)
+
(
1
?
y
i
)
l
n
(
1
?
h
w
(
x
i
)
)
\frac{\partial}{\partial {w}_{j}}J(w)=-\frac{1}{m}\displaystyle \sum^{m}_{i=1}{{y}_{i}ln{h}_{w}({x}_{i})+(1-{y}_{i})ln(1-{h}_{w}({x}_{i}))}
?wj???J(w)=?m1?i=1∑m?yi?lnhw?(xi?)+(1?yi?)ln(1?hw?(xi?))
=
?
1
m
∑
i
=
1
m
y
i
?
?
w
j
l
n
h
w
(
x
i
)
+
(
1
?
y
i
)
?
?
w
j
l
n
(
1
?
h
w
(
x
i
)
)
=-\frac{1}{m}\displaystyle \sum^{m}_{i=1}{{y}_{i}\frac{\partial }{\partial {w}_{j}}ln{h}_{w}({x}_{i})+(1-{y}_{i})\frac{\partial}{\partial {w}_{j}}ln(1-{h}_{w}({x}_{i}))}
=?m1?i=1∑m?yi??wj???lnhw?(xi?)+(1?yi?)?wj???ln(1?hw?(xi?))
=
?
1
m
∑
i
=
1
m
y
i
1
h
w
(
x
i
)
?
h
w
(
x
i
)
?
z
i
?
z
i
w
j
+
(
1
?
y
i
)
1
1
?
h
w
(
x
i
)
(
?
?
h
w
(
x
i
)
?
z
i
)
?
z
i
w
j
=- \frac{1}{m} \displaystyle \sum^{m}_{i=1}{{y}_{i} \ \frac{1}{{h}_{w}({x}_{i})} \frac{\partial {h}_{w}({x}_{i})}{\partial {z}_{i}} \frac{\partial {z}_{i}}{{w}_{j}} + (1-{y}_{i}) \frac{1}{1-{h}_{w}({x}_{i})} (-\frac{\partial {h}_{w}({x}_{i})}{\partial {z}_{i}}) \frac{\partial {z}_{i}}{{w}_{j}}}
=?m1?i=1∑m?yi? hw?(xi?)1??zi??hw?(xi?)?wj??zi??+(1?yi?)1?hw?(xi?)1?(??zi??hw?(xi?)?)wj??zi??
=
?
1
m
∑
i
=
1
m
(
y
i
h
w
(
x
i
)
?
(
1
?
h
w
(
x
i
)
h
w
(
x
i
)
?
(
1
?
y
i
)
h
w
(
x
i
)
?
(
1
?
h
w
(
x
i
)
)
(
1
?
h
w
(
x
i
)
)
)
?
z
i
w
j
=-\frac{1}{m} \displaystyle \sum^{m}_{i=1}({y}_{i} \frac{{h}_{w}({x}_{i}) \cdot (1-{h}_{w}({x}_{i})}{{h}_{w}({x}_{i})} -(1-{y}_{i}) \frac{{h}_{w}({x}_{i}) \cdot (1-{h}_{w}({x}_{i}))}{(1-{h}_{w}({x}_{i}))}) \frac{\partial {z}_{i}}{{w}_{j}}
=?m1?i=1∑m?(yi?hw?(xi?)hw?(xi?)?(1?hw?(xi?)??(1?yi?)(1?hw?(xi?))hw?(xi?)?(1?hw?(xi?))?)wj??zi??
=
?
1
m
∑
i
=
1
m
(
y
i
?
h
w
(
x
i
)
)
?
z
i
w
j
=- \frac{1}{m} \displaystyle \sum^{m}_{i=1}({y}_{i}-{h}_{w}({x}_{i})) \frac{\partial {z}_{i}}{{w}_{j}}
=?m1?i=1∑m?(yi??hw?(xi?))wj??zi??
=
1
m
∑
i
=
1
m
(
h
w
(
x
i
)
?
y
i
)
x
i
j
=\frac{1}{m} \displaystyle \sum^{m}_{i=1}({h}_{w}({x}_{i})-{y}_{i}){x}_{ij}
=m1?i=1∑m?(hw?(xi?)?yi?)xij?
- 其中, h w ( x i ) ? y i {h}_{w}({x}_{i})-{y}_{i} hw?(xi?)?yi? 可解釋為模型預測 x i {x}_{i} xi? 為正例的概率與其實際類別之間的 誤差 ,
由此可推出梯度
?
J
(
w
)
\nabla J(w)
?J(w) 計算公式為
?
J
(
w
)
=
1
m
∑
i
=
1
m
(
h
w
(
x
i
)
?
y
i
)
x
i
\nabla J(w)=\frac{1}{m} \displaystyle \sum^{m}_{i=1}({h}_{w}({x}_{i})-{y}_{i}){x}_{i}
?J(w)=m1?i=1∑m?(hw?(xi?)?yi?)xi?
對于隨機梯度下降,即 m = 1 時,相應梯度計算公式為
?
J
(
w
)
=
(
h
w
(
x
i
)
?
y
i
)
x
i
\nabla J(w)=({h}_{w}({x}_{i})-{y}_{i}){x}_{i}
?J(w)=(hw?(xi?)?yi?)xi?
設學習率為
η
\eta
η ,模型引數 w 的更新公式為
w
=
w
?
η
?
J
(
w
)
w = w - \eta \ \nabla J(w)
w=w?η ?J(w)
代碼實作
自己實作
既然我們已經了解了 Logistic 模型的數學原理,那現在我們就使用 Python 實作吧!
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
class LogisticRegression:
def __init__(self, w_init=0.0, steps=10000, eta=0.01):
# 訓練迭代次數
self.steps = steps
# 學習率
self.eta = eta
# 初始化模型引數
self.w_init = w_init
self.w = None
def __z(self, X):
'''
計算 x 與 w 的內積
'''
# 矩陣點積:[1*n] ? [n*m] = [1*m]
return np.dot(self.w, X.T)
def __sigmoid(self, z):
'''
Sigmoid 函式
'''
return 1. / (1. + np.exp(-z))
def __predict_proba(self, X):
'''
預測為正例的概率
'''
# 求 z
z = self.__z(X)
# 利用 Sigmoid 函式求預測為 '分類1' 的概率,>=0.5 的為 '分類1' ,否則為 '分類0'
return self.__sigmoid(z)
def __loss(self, y, y_pred):
'''
求損失
'''
# 數學公式見上述
return -np.sum(y * np.log(y_pred) + (1-y)* np.log(1-y_pred)) / y.size
def __preprocess(self, X):
'''
預處理 x,x0 = 1
'''
m, n = X.shape
# 初始化新矩陣
X_ = np.zeros((m, n+1))
# x0 = 1
X_[:, 0] = 1
X_[:, 1:] = X
return X_
def __gradient(self, X, y, y_pred):
'''
求梯度
'''
# 矩陣乘法:[1*m] * [m*n] = [1*n]
return np.matmul(y_pred-y, X) / y.size
def train(self, X, y):
# 預處理 X
X = self.__preprocess(X)
# 生成 w 矩陣
m, n = X.shape
self.w = np.full((1, n), self.w_init)
# 創建 step-loss DataFrame,用于繪圖
plot_loss = pd.DataFrame(columns=['step', 'loss'])
for step in range(1, self.steps+1):
# 求 y_hat
y_pred = self.__predict_proba(X)
# 求損失,存入 DataFrame 中,并輸出
loss = self.__loss(y, y_pred)
plot_loss.loc[plot_loss.shape[0]+1] = [step, loss]
print('\rEpoch: {} {:>.2f}%: [{}{}] loss={:>.2f}'.format(
step, step / self.steps * 100,
'■' * int(step / self.steps * 20),
'□' * (20 - int(step/self.steps*20)),
loss
), end='')
# 求梯度
grad = self.__gradient(X, y, y_pred)
# 更新權重 w
self.w -= self.eta * grad
# 繪制 step-loss 折線圖
plt.plot(plot_loss['step'], plot_loss['loss'])
plt.xlabel('step')
plt.ylabel('loss')
plt.show()
def predict(self, X):
# 預處理 X
X = self.__preprocess(X)
# 求 y_hat
y_pred = self.__predict_proba(X)
# 轉標簽
return np.where(y_pred >= 0.5, 1, 0)
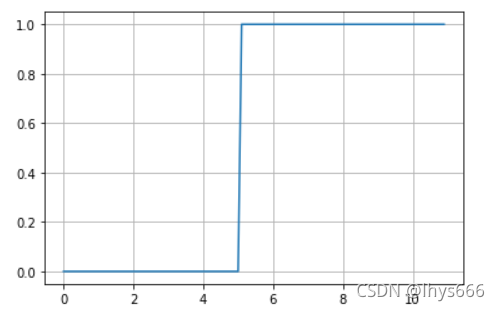
測驗一下,訓練集就取
x
∈
[
0
,
10
]
x \in [0, 10]
x∈[0,10],0.1 為步長的 等引數列,
y
∈
0
,
1
y \in {0, 1}
y∈0,1 的二分類陣列,將
x
≥
5
x \geq 5
x≥5 的資料對應的標簽設定為 1 ,其余為 0,弄好以后畫個圖瞅瞅,代碼如下:
train_x = np.arange(0, 11, 0.1).reshape(-1, 1)
train_y = np.where(train_x > 5, 1, 0).reshape(1, -1)
# x = [m*n] = [110*1],即有 110 個 x,每個 x 的維度為 1
# y = [1*m] = [1*110],即有 110 個 y
# 顯示網格線
plt.grid()
plt.plot(train_x, train_y[0])
plt.show()
折線圖如下
下邊就用我們的模型試一試效果
model = LogisticRegression()
model.train(train_x, train_y)
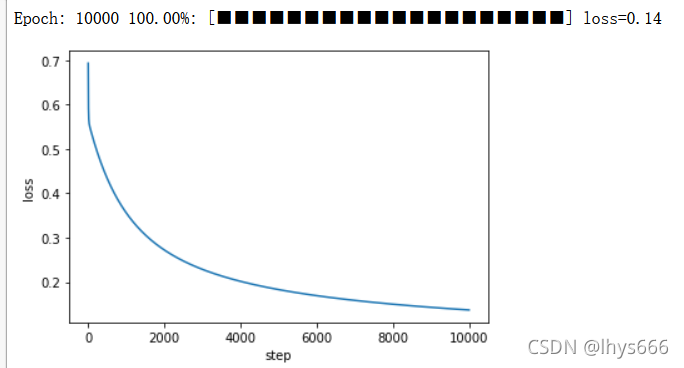
可以看到,損失是逐漸 下降 的,
讓我們來預測一波試試,
In[]: model.predict(np.array([[2], [3], [4], [5], [6]]))
-------------------------------------------------------------
Out[]: array([[0, 0, 0, 1, 1]])
看起來結果還是不錯的,
利用 sklearn 實作
不得不佩服強大的 Python 生態,有好多大佬們寫好的庫,我們直接呼叫其中的 API 即可,sklearn 就是 Python 機器學習 一個常用的庫,用它實作 Logistic 回歸,代碼如下(資料還是上邊的資料):
In[]: from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_x, train_y.reshape(-1, 1))
lr.predict(np.array([[2], [3], [4], [5], [6]]))
---------------------------------------------------------------
Out[]: array([0, 0, 0, 1, 1])

成功咯!!!
參考資料
這可不能忘
[1]劉碩.Python機器學習演算法原理、實作與案例[M].北京:清華大學出版社,2019
結尾
有想要一起學習 python 的小伙伴可以掃碼進群哦,

以上就是我要分享的內容,因為學識尚淺,會有不足,還請各位大佬指正,
有什么問題也可在評論區留言,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/325425.html
標籤:AI
上一篇:2021年華為杯數模賽D題總結