目錄
pandas讀取資料
查看資料例外
提取指定列
將dataframe資料以numpy形式提取
資料劃分
隨機森林回歸
GBDT回歸
特征重要性可視化
輸出:
? 繪制3D散點圖
匯入自定義包且.py檔案修改時jupyter notebook自動同步
dataframe洗掉某列中重復欄位并洗掉對應行
LASSO回歸
繪制回歸誤差圖
輸出:
? Adaboost回歸
LightGBM回歸
XGBoost
繪制學習曲線
輸出:
繪制dataframe資料分布圖
輸出:
SVM分類
使用貝葉斯優化SVM
輸出:
后續:
繪制ROC曲線
輸出:
PCA降維
PCA降維可視化
輸出:
求解極值
輸出解釋:
pandas讀取資料
import numpy as np
import pandas as pd
import random
Molecular_Descriptor = pd.read_excel('Molecular_Descriptor.xlsx',header=0)
Molecular_Descriptor.head()查看資料例外
#判斷資料NAN,INF
print(Molecular_Descriptor.isnull().any())
print(np.isnan(Molecular_Descriptor).any())
print(np.isfinite(Molecular_Descriptor).all())
print(np.isinf(Molecular_Descriptor).all())提取指定列
Molecular_Descriptor.iloc[:,1:]將dataframe資料以numpy形式提取
# .values能夠將dataframe中的資料以numpy的形式讀取
X = Molecular_Descriptor.iloc[:,1:].values
Y = ERα_activity.iloc[:,2].values資料劃分
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
Y,
test_size=0.2,
random_state=0)
#列印出原始樣本集、訓練集和測驗集的數目
print("The length of original data X is:", X.shape[0])
print("The length of train Data is:", X_train.shape[0])
print("The length of test Data is:", X_test.shape[0])隨機森林回歸
#匯入隨機森林庫
from sklearn.ensemble import RandomForestRegressor
#匯入sklearn度量庫
from sklearn import metrics
#定義分類器
RFRegressor = RandomForestRegressor(n_estimators=200, random_state=0)
#模型訓練
RFregressor.fit(X_train, y_train)
#模型預測
y_pred = RFregressor.predict(X_test)
#輸出回歸模型評價指標
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error:',
np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
#獲得特征重要性
print(RFregressor.feature_importances_)GBDT回歸
from sklearn.ensemble import GradientBoostingRegressor
gbdt = GradientBoostingRegressor(random_state=0)
gbdt.fit(X_train, y_train)
y_pred = gbdt.predict(X_test)
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error:',
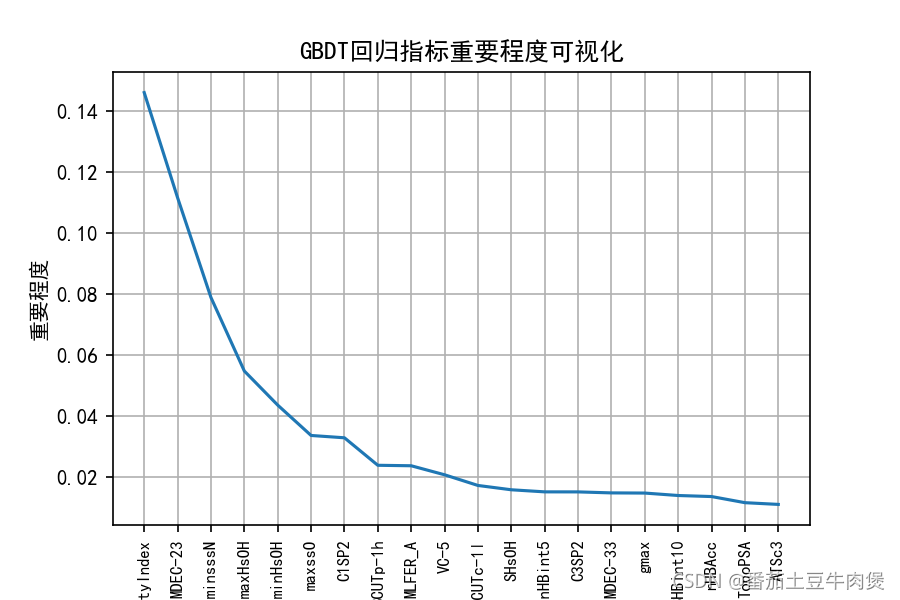
np.sqrt(metrics.mean_squared_error(y_test, y_pred)))特征重要性可視化
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"] = ["SimHei"] # 用來正常顯示中文標簽
plt.rcParams["axes.unicode_minus"] = False # 解決負號"-"顯示為方塊的問題
plt.rcParams['savefig.dpi'] = 150 #圖片像素
plt.rcParams['figure.dpi'] = 150 #解析度
def plot_feature_importance(dataset, model_bst):\
'''
dataset : 資料集 dataframe
model_bst : 訓練好的模型
'''
list_feature_name = list(dataset.columns[1:])
list_feature_importance = list(model_bst.feature_importances_)
dataframe_feature_importance = pd.DataFrame(
{'feature_name': list_feature_name, 'importance': list_feature_importance})
dataframe_feature_importance20 = dataframe_feature_importance.sort_values(by='importance', ascending=False)[:20]
print(dataframe_feature_importance20)
x = range(len(dataframe_feature_importance20['feature_name']))
plt.xticks(x, dataframe_feature_importance20['feature_name'], rotation=90, fontsize=8)
plt.plot(x, dataframe_feature_importance20['importance'])
plt.xlabel("分子描述符")
plt.ylabel("重要程度")
plt.title('重要程度可視化')
plt.grid()
#保存影像
#plt.savefig('重要程度可視化.png')
plt.show()
return dataframe_feature_importance20['feature_name']
if __name__ == '__main__':
# 傳入資料集dataframe , 模型對特征重要性進行評估
gbdt_name = plot_feature_importance(Molecular_Descriptor,gbdt)輸出:
 繪制3D散點圖
繪制3D散點圖
z = list(range(0,729))
plt.rcParams['savefig.dpi'] = 150 #圖片像素
plt.rcParams['figure.dpi'] = 150 #解析度
plt.rcParams["font.sans-serif"] = ["SimHei"] # 用來正常顯示中文標簽
plt.rcParams["axes.unicode_minus"] = False # 解決負號"-"顯示為方塊的問題
from mpl_toolkits.mplot3d import Axes3D
x = regressor.feature_importances_
y = gbdt.feature_importances_
fig = plt.figure()
plt.subplots_adjust(right=0.8)
ax = fig.add_subplot(111, projection='3d') # 創建一個三維的繪圖工程
ax.scatter(x,y,z,c='b',s=5,alpha=1)
#設定x、y軸坐標刻標以及對應的標簽
plt.xticks(fontsize=7)
plt.yticks(fontsize=7)
#統一設定x、y、z軸標簽字體
plt.tick_params(labelsize=7)
#設定x、y、z標簽
plt.xlabel("x軸",fontsize=8)
plt.ylabel("y軸",fontsize=8)
ax.set_zlabel('z軸',fontsize=8)
plt.savefig('這是三維圖.png')匯入自定義包且.py檔案修改時jupyter notebook自動同步
%load_ext autoreload
%autoreload 2dataframe洗掉某列中重復欄位并洗掉對應行
dataframe_feature_importance = dataframe_feature_importance.drop_duplicates(subset=['feature_name'], keep='first', inplace=False)LASSO回歸
from sklearn import linear_model
model = linear_model.LassoCV()
model.fit(X_train, y_train)
y_predict = model.predict(X_test)
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_predict))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_predict))
print('Root Mean Squared Error:',
np.sqrt(metrics.mean_squared_error(y_test, y_predict)))繪制回歸誤差圖
x_t = np.linspace(0, len(np.array(y_test)), len(np.array(y_test)))
plt.plot(x_t, y_test, marker='.', label="origin data")
# plt.xticks([])
plt.plot(x_t, y_predict, 'r-', marker='.', label="predict", lw=1)
plt.xlabel('樣本編號')
plt.ylabel('預測結果')
# plt.figure(figsize=(10,100))
plt.legend(labels=['test','predict'],loc='best')
# plt.xticks([])
score = model.score(X_test,y_test)
print(score)
plt.text(140, 3, 'score=%.4f' % score, fontdict={'size': 15, 'color': 'red'})
plt.savefig('Lasso.png')輸出:
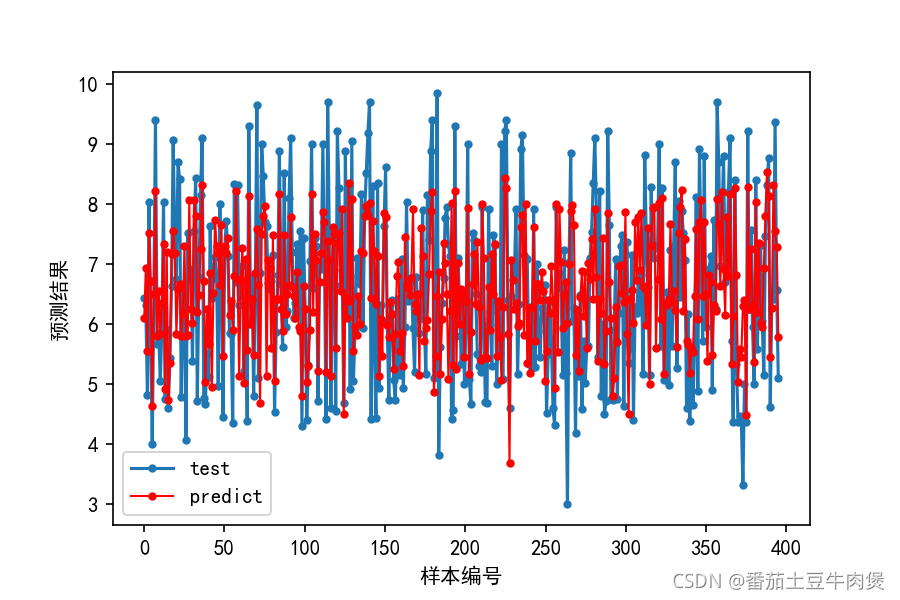 Adaboost回歸
Adaboost回歸
from sklearn.ensemble import AdaBoostClassifier
clf = AdaBoostRegressor(DecisionTreeRegressor(max_depth=3),
n_estimators=5000, random_state=123)
clf.fit(X_train,y_train)
y_predict = clf.predict(X_test)
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_predict))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_predict))
print('Root Mean Squared Error:',
np.sqrt(metrics.mean_squared_error(y_test, y_predict)))LightGBM回歸
import lightgbm as lgb
clf = lgb.LGBMRegressor(
boosting_type='gbdt',
random_state=2019,
objective='regression')
# 訓練模型
clf.fit(X=X_train, y=y_train, eval_metric='MSE', verbose=50)
y_predict = clf.predict(X_test)
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_predict))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_predict))
print('Root Mean Squared Error:',
np.sqrt(metrics.mean_squared_error(y_test, y_predict)))XGBoost
import xgboost as xgb
clf = xgb.XGBRegressor(max_depth=5, learning_rate=0.1, n_estimators=5000, silent=False, objective='reg:gamma')
# 訓練模型
clf.fit(X=X_train, y=y_train)
y_predict = clf.predict(X_test)
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_predict))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_predict))
print('Root Mean Squared Error:',
np.sqrt(metrics.mean_squared_error(y_test, y_predict)))繪制學習曲線
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
if __name__ == '__main__':
title = "Learning Curves"
# Cross validation with 100 iterations to get smoother mean test and train
# score curves, each time with 20% data randomly selected as a validation set.
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
estimator =lgb.LGBMRegressor(learning_rate=0.001,
max_depth=-1,
n_estimators=10000,
boosting_type='gbdt',
random_state=2019,
objective='regression',)
#模型 影像標題 資料 標簽 K折
p = plot_learning_curve(estimator, title, XX, YY, cv=cv, n_jobs=4)
p.savefig('LearnCurves.png')輸出:
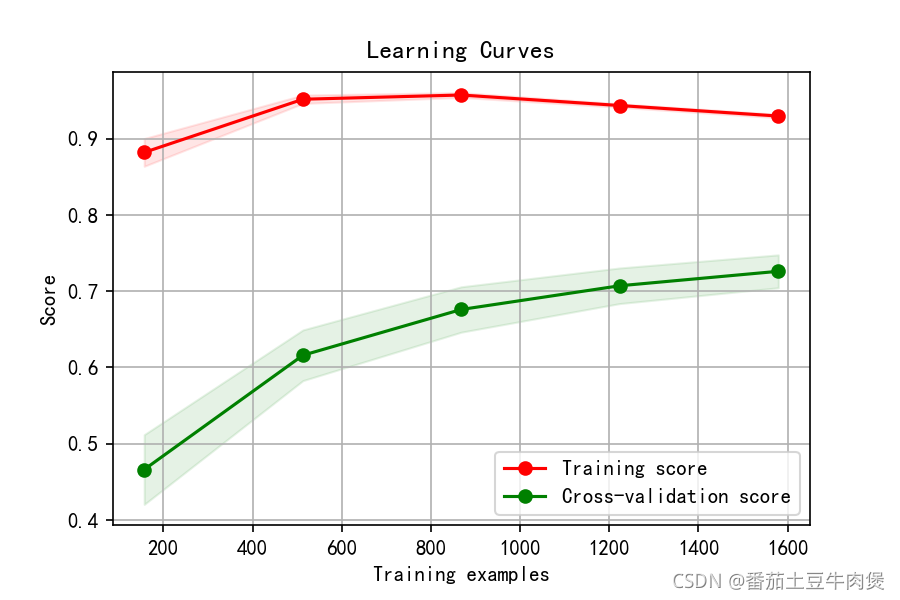
繪制dataframe資料分布圖
#
name = ['gmin', 'MDEC-22', 'minaaN', 'maxHBint10', 'minHBint10', 'maxdO',
'C2SP1', 'BCUTw-1h', 'BCUTp-1l', 'MDEN-33', 'VC-4', 'nAtomLAC',
'SHBint10', 'minHBint4', 'C2SP2', 'MDEC-24', 'hmax', 'SHBint9',
'fragC', 'LipinskiFailures']
# 提取資料指定列
t = Molecular_Descriptor[name]
#資料歸一化
t = (t-t.min())/(t.max()-t.min())
t.plot(alpha=0.8)
#橫向拉長x軸
N=100
plt.legend(loc=2, bbox_to_anchor=(1.05,1.0),borderaxespad= 0)
# change x internal size
plt.gca().margins(x=0)
plt.gcf().canvas.draw()
tl = plt.gca().get_xticklabels()
# maxsize = max([t.get_window_extent().width for t in tl])
maxsize = 30
m = 0.2 # inch margin
s = maxsize / plt.gcf().dpi * N + 2 * m
margin = m / plt.gcf().get_size_inches()[0]
plt.gcf().subplots_adjust(left=margin, right=1. - margin)
plt.gcf().set_size_inches(s, plt.gcf().get_size_inches()[1])
#合理布局
plt.tight_layout()
plt.savefig("資料分布.png")輸出:

SVM分類
from sklearn.svm import SVC
from sklearn import metrics
#定義SVM分類器
clf = SVC()
#模型訓練
clf.fit(X_train,y_train)
#模型預測
y_pred = clf.predict(X_test)
#模型評估
print('準確率=%.4f'%metrics.accuracy_score(y_test,y_pred))
print('召回率=%.4f'%metrics.recall_score(y_test, y_pred, pos_label=1))
print('精準率=%.4f'%metrics.precision_score(y_test, y_pred, pos_label=1) )
print('F1=%.4f'%metrics.f1_score(y_test, y_pred, average='weighted',pos_label=1) )使用貝葉斯優化SVM
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.svm import SVC
from bayes_opt import BayesianOptimization
from bayes_opt.util import Colours
def svc_cv(C, gamma, X_train, y_train):
"""SVC cross validation.
This function will instantiate a SVC classifier with parameters C and
gamma. Combined with data and targets this will in turn be used to perform
cross validation. The result of cross validation is returned.
Our goal is to find combinations of C and gamma that maximizes the roc_auc
metric.
"""
#設定分類器
estimator = SVC(C=C, gamma=gamma, random_state=2)
#交叉驗證
cval = cross_val_score(estimator, X_train, y_train, scoring='roc_auc', cv=4)
return cval.mean()
def optimize_svc(X_train, y_train):
"""Apply Bayesian Optimization to SVC parameters."""
def svc_crossval(expC, expGamma):
"""Wrapper of SVC cross validation.
Notice how we transform between regular and log scale. While this
is not technically necessary, it greatly improves the performance
of the optimizer.
"""
C = 10 ** expC
gamma = 10 ** expGamma
return svc_cv(C=C, gamma=gamma, data=X_train, targets=y_train)
optimizer = BayesianOptimization(
f=svc_crossval,
#設定超參范圍
pbounds={"expC": (-3, 2), "expGamma": (-4, -1)},
random_state=1234,
verbose=2
)
optimizer.maximize(n_iter=10)
print("Final result:", optimizer.max)
if __name__ == '__main__':
#開始搜索超參
optimize_svc(X_train, y_train)
輸出:
| iter | target | expC | expGamma |
-------------------------------------------------
| 1 | 0.8239 | -2.042 | -2.134 |
| 2 | 0.8973 | -0.8114 | -1.644 |
| 3 | 0.8791 | 0.8999 | -3.182 |
| 4 | 0.8635 | -1.618 | -1.594 |
| 5 | 0.9104 | 1.791 | -1.372 |
| 6 | 0.9213 | 1.099 | -1.502 |
| 7 | 0.9165 | 0.2084 | -1.0 |
| 8 | 0.8727 | 2.0 | -4.0 |
| 9 | 0.9117 | 1.131 | -1.0 |
| 10 | 0.9241 | 0.3228 | -1.88 |
| 11 | 0.9346 | 2.0 | -2.322 |
| 12 | 0.9335 | 1.429 | -2.239 |
| 13 | 0.7927 | -3.0 | -4.0 |
| 14 | 0.927 | 2.0 | -2.715 |
| 15 | 0.9354 | 1.742 | -2.249 |
=================================================
Final result: {'target': 0.9353828944247531, 'params': {'expC': 1.7417094883510253, 'expGamma': -2.248984327197053}}iter為迭代次數,target為模型所獲得的分數(越高越好),expC、expGamma為需要貝葉斯優化的引數
后續:
如何使用?根據搜索到的超引數'params': {'expC': 1.7417094883510253, 'expGamma': -2.248984327197053}重新訓練分類器即可
clf = SVC(C=10**1.74,gamma=10**(-2.248))
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)繪制ROC曲線
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
plt.rcParams['savefig.dpi'] = 150 #圖片像素
plt.rcParams['figure.dpi'] = 150 #解析度
#傳入真實值和預測值
fpr, tpr, thersholds = roc_curve(y_test, y_pred, pos_label=1)
for i, value in enumerate(thersholds):
print("%f %f %f" % (fpr[i], tpr[i], value))
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, 'k--', label='ROC (area = {0:.2f})'.format(roc_auc), lw=2,c='r')
plt.xlim([-0.05, 1.05]) # 設定x、y軸的上下限,以免和邊緣重合,更好的觀察影像的整體
plt.ylim([-0.05, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate') # 可以使用中文,但需要匯入一些庫即字體
plt.title('ROC Curve')
plt.legend(loc="lower right")
plt.savefig('Caco-2分類ROC曲線.png')
plt.show()
print(roc_auc)輸出:
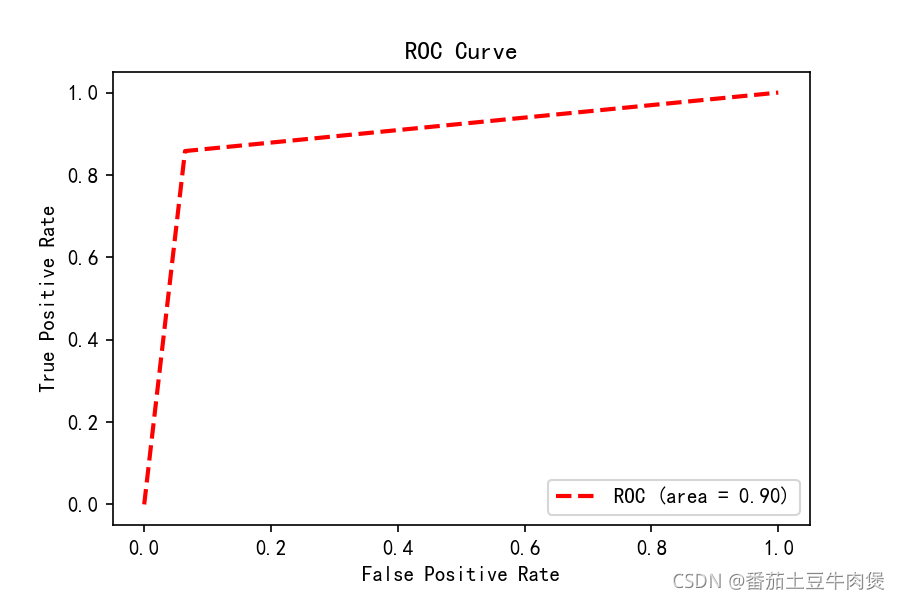
PCA降維
from sklearn.decomposition import PCA
#定義PCA分類器,n_components為需要降到的維數
pca = PCA(n_components=50)
# X.shape = (1974,729)
#資料轉換 (1974,729) -> (1974,50)
new_X = pca.fit_transform(X)
#new_X.shape = (1974,50)PCA降維可視化
# plt.rcParams['savefig.dpi'] = 150 #圖片像素
# plt.rcParams['figure.dpi'] = 150 #解析度
plt.rcParams["font.sans-serif"] = ["SimHei"] # 用來正常顯示中文標簽
plt.rcParams["axes.unicode_minus"] = False # 解決負號"-"顯示為方塊的問題
from mpl_toolkits.mplot3d import Axes3D
# 降到3維
pca = PCA(n_components=3)
pca_test = pca.fit_transform(X_test)
pca_test.shape
fig = plt.figure()
plt.subplots_adjust(right=0.8)
ax = fig.add_subplot(111, projection='3d') # 創建一個三維的繪圖工程
y_pred==0
#分離0 1
label0 = pca_test[y_pred==0]
label1 = pca_test[y_pred==1]
# label0
ax.scatter(label0[:,0],label0[:,1],label0[:,2],label=0,alpha=0.8)
ax.scatter(label1[:,0],label1[:,1],label1[:,2],label=1,alpha=0.8)
plt.legend()
plt.savefig('Caco2分類三維影像.png')輸出:
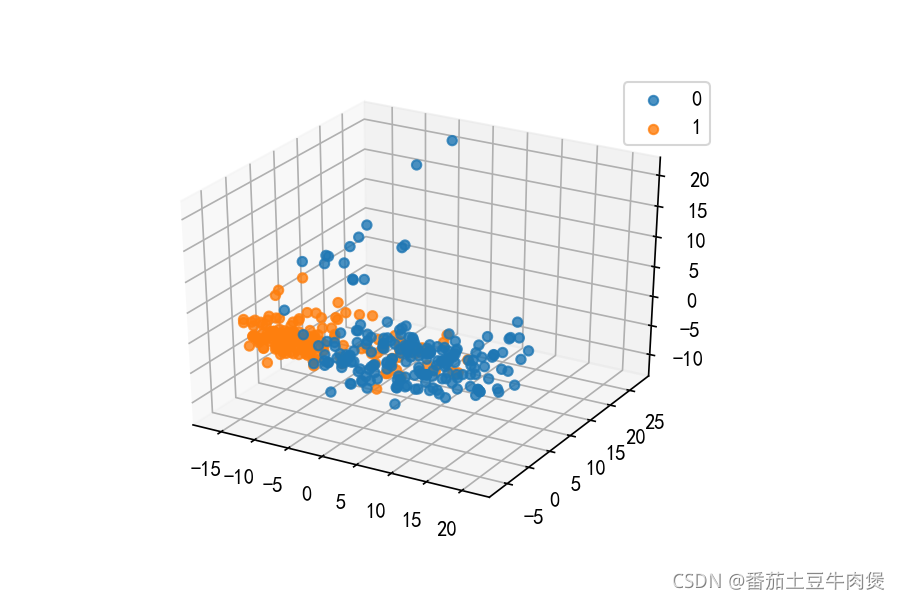
求解極值
# coding=utf-8
from scipy.optimize import minimize
import numpy as np
#設定引數范圍/約束條件
l_x_min = [0,1,2,3]
l_x_max = [4,5,6,7]
def fun():
#minimize只能求極小值,如果需要極大值,則在函式前添加負號,本案例為求極大值
v=lambda x: -1*(coef[0]*x[0]+coef[1]*x[1]+coef[2]*x[2]+coef[3]*x[3]+intercept)
return v
def con():
# 約束條件 分為eq 和ineq
#eq表示 函式結果等于0 ; ineq 表示 運算式大于等于0
#{'type': 'ineq', 'fun': lambda x: x[0] - l_x_min[0]}表示 x[0] - l_x_min[0]>=0
cons = ({'type': 'ineq', 'fun': lambda x: x[0] - l_x_min[0]},\
{'type': 'ineq', 'fun': lambda x: -x[0] + l_x_max[0]},\
{'type': 'ineq', 'fun': lambda x: x[1] - l_x_min[1]},\
{'type': 'ineq', 'fun': lambda x: -x[1] + l_x_max[1]},\
{'type': 'ineq', 'fun': lambda x: x[2] - l_x_min[2]},\
{'type': 'ineq', 'fun': lambda x: -x[2] + l_x_max[2]},\
{'type': 'ineq', 'fun': lambda x: x[3] - l_x_min[3]},\
{'type': 'ineq', 'fun': lambda x: -x[3] + l_x_max[3]})
return cons
if __name__ == "__main__":
#定義常量值
cons = con()
#設定初始猜測值
x0 = np.random.rand(4)
res = minimize(fun(), x0, method='SLSQP',constraints=cons)
print(res.fun)
print(res.success)
print(res.x)輸出解釋:
#舉例:
[output]:
-1114.4862509294192 # 由于在開始時給函式添加符號,最后還需要*-1,因此極大值為1114.4862509294192
True #成功找到極值
[-1.90754988e-10 6.36254335e+00 -1.25920646e-10 1.90480000e-01] #該極值對應x解轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/325428.html
標籤:AI