前言
前言就是嘮嘮嗑,想看干貨的可以直接看下一節,
今年ICCV的最佳論文還是給到了刷榜各大CV競賽榜的模型Swin Transformer,研究團隊來自MSRA(你大爺還是你大爺啊),
自從ViT、DETR等嘗試把language模型中的王炸transformer使用到視覺領域并得到還不錯的驗證效果后,研究者們一直在致力于“如何更好地將語言模型建模到視覺”這個問題,ViT直接把圖片劃分patch,用對待word的方式來對待每個patch,輕松將圖片建模成sentence;而DETR則需要CNN輔助提取特征,而transformer只是當一個neck,后者更像是一個過渡模式,咱們本文不做過多討論,
重點說下ViT的問題,首先ViT不適合作為通用模型的backbone,不擅長處理dense輸出型(如目標檢測、分割等)的視覺任務,ViT通過將影像劃分成不相交的patch,通過編碼每個patch然后計算兩兩patch之間的attention,來實作聚合資訊,這樣,應對更高清的圖片時,劃分的patch數會受計算資源掣肘,你可以這么想,4x4=16個patch,兩兩計算注意力,和100x100=10000個patch,兩兩計算注意力,計算復雜度完全不一樣(指數級的差別),假如用降采樣的方法依舊保持少量的patch數,那就沒使用到高解析度帶來的好處;假如把用更大的編碼器來保持較少的patch數,那么transformer會慢慢往MLP的方向退化,于是,研究者們開始設想一種新的transformer結構,使之能更好地適應視覺任務,
Swin Transformer就是一種通用視覺任務的Backbone而存在的模型,以替代CNN,它做到了,而且outperform現有的CNN模型,這也是其獲得Best Paper的主要原因,
將ST復現到我自己的資料集(四分類),效果如下:
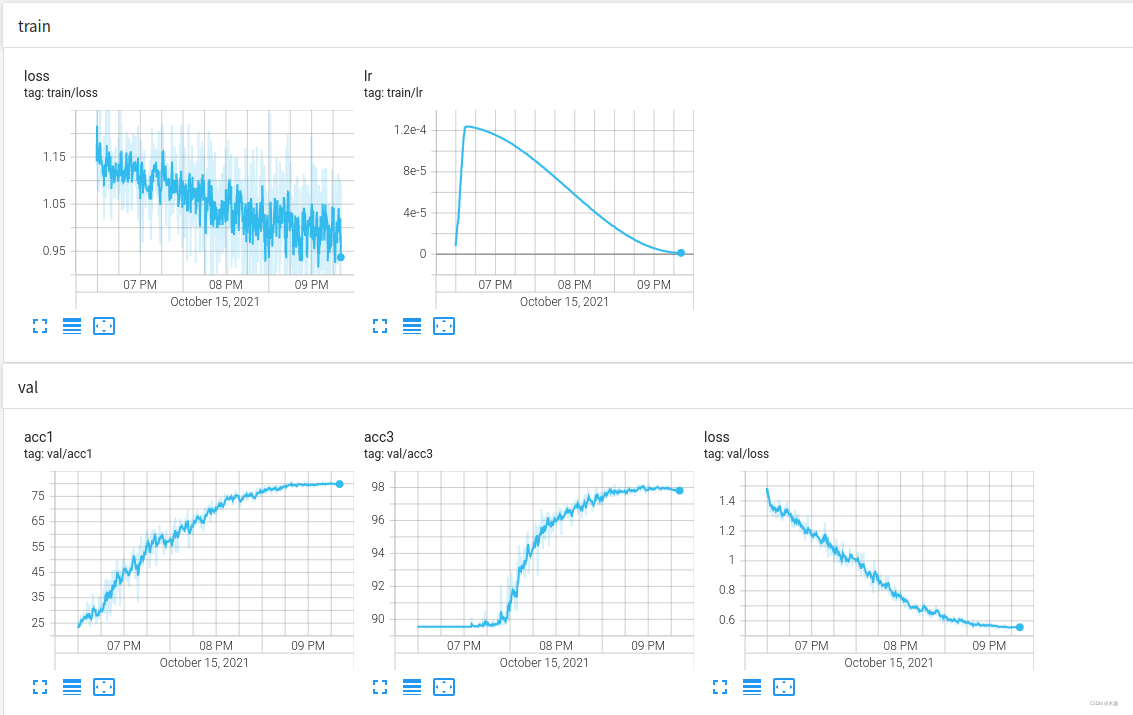
穩步收斂,最終準確率達到81%左右,
論文鏈接:https://arxiv.org/abs/2103.14030
論文標題:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
官方代碼實作(pytorch):https://github.com/microsoft/Swin-Transformer/(本文主要參考代碼)
本文行文主要參考是官方代碼,次要參考才是論文,所以讀者最好結合代碼一起看本文,
總概
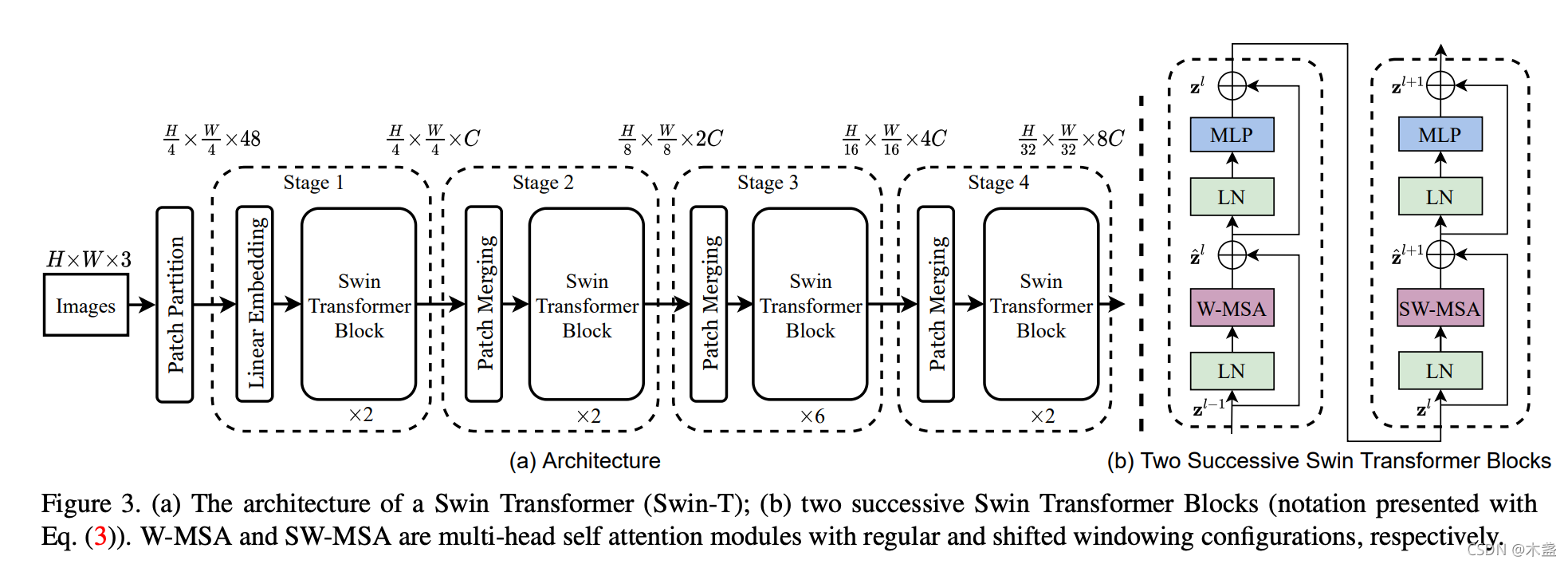
主體結構
Swin的主體結構主要由4個Basic Layer組成,每個Basic Layer都有Depths、NUM_HEADS兩個主要引數,以此來區分各種量級的swin transformer(如swin tiny,swin base等),
Depths代表這個Basic Layer由幾個swin transformer block(以下簡稱“STB”)串聯而成,如圖1中虛線框中的數字’x2’,‘x2’,‘x6’等待,
NUM_HEADS代表這個Basic Layer中的STB的head數量(每個head就是一組獨立的注意力計算機制,類似于CNN中的channel,不了解可戳《transformer詳解》),head數量越多,代表特征channel越多,
第一步,名詞解答:Window、Patch、Token
這三個名詞,我們可以用一個栗子來解答,假設輸入圖片的尺寸為224X224,先劃分成多個大小為4x4像素的小片,每個小片之間沒有交集,224/4=56,那么一共可以劃分56x56個小片,每一個小片就叫一個patch,每一個patch將會被對待成一個token,所以patch=token,而一張圖被劃分為7x7個window,每個window之間也沒有交集,那么每個window就會包含8x8個patch,這段計算整明白了,你就會了解window、patch和pixel的關系,
Patch Embedding
一張224x224的圖片,被劃分成56x56個patch,然后對每個patch(尺寸為4x4)進行編碼得到96-d的embedding向量,
那么這一步的張量尺寸變換為:Bx224x224x3 -> Bx3196x96
這里的B表示batch size,而3196=56x56,
用白話描述:咱們每個圖片被劃分為3196個patch,每個patch又被編碼成96維的向量,
這一步在代碼上實作十分簡單,就是一個Conv2D,把步長和kernel size都設定為patch的長度即可,可看:
nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
這步以后再flatten一下,就可以把56x56x96變為3196x96,
輸入到STB(swin transformer block)之前,對輸入張量進行dropout,這里的dropout主要是為了進行資料增強,因為這一步會隨機性讓一些patch embedding的數值為0,詳情可戳《pytorch中nn.Dropout的使用技巧》,
Patch Merging
先把STB當做一個黑盒模型,Patch Embedding就是處理STB輸入,而Patch Merging就是處理STB的輸出,Patch merging模塊是整個Swin Transformer模型中唯一的降采樣操作,張量通過STB模塊的時候尺寸是不發生改變的,

Patch Merging就好比CNN中的Pooling操作,但是比Pooling操作復雜一些,我們看圖1,56x56x96對應(H/4)x(W/4)xC,經過Patch Merging以后,變為(H/8)x(W/8)x2C,即28x28x192,
解析度下降到了1/4,而token的維度擴充到了2倍,
這一步經過了以下操作:
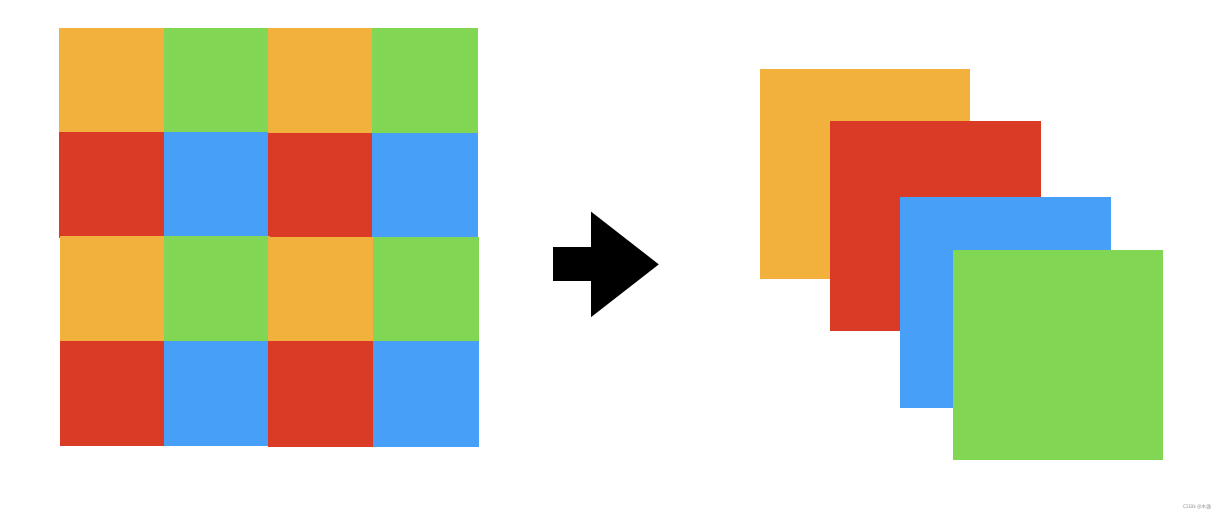
上面操作有沒有些熟悉,就是pixel shuffle(鏈接可戳)的反程序嘛,
這一操作,直接可以把56x56x96變成28x28x(4x96),再通過一個線性層變為28x28x(2x96),線性層如下:
nn.Linear(4*dim, 2*dim, bias=False)
有疑問可留言交流~
Swin Transformer Block
重頭戲來了,Swin transformer是在標準transformer上的一個改進,主要是用Shifted window來改進標準多頭自注意力模塊,
ST中使用的激活函式是《GELU》,使用的正則化方法是Layer Normalization(可戳《Layer Normalization》《常見的Normalization》進一步了解)
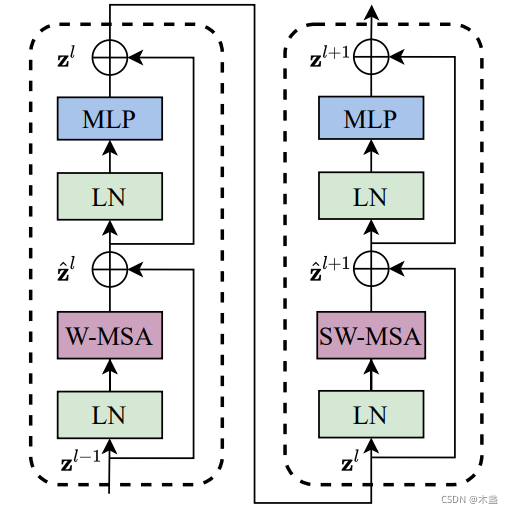
與標準transformer不同的就是紫色部分的兩個框,分別是W-MSA和SW-MSA,
W-MSA表示,在window內部的Multi-Head Self-Attention,就是把window當做獨立的全域來計算window中每個token兩兩注意力,
SW-MSA與W-MSA的一丟丟不一樣,就是將window的覆寫范圍偏移一下,原文設定為window的邊長的一半,
W-MSA
全稱為Window based Multi-head Self Attention,一張圖平分為7x7個window,這些window互相都沒有overlap,然后,每個window包含一定數量的token,直接對這些token計算window內部的自注意力, 以分而治之的方法,遠遠降低了標準transformer的計算復雜度,以第1層為例,7x7個window,每個window包含16x16個patch,相當于把標準transformer應用在window上,而不是全圖上,不太了解標準transformer做法的可戳《令人心動的transformer》,文中介紹了QKV、Multi-Head self attention等原理,
那么,不同window之間的資訊怎么聚合呢?這就要用到SW-MSA了,
SW-MSA
這里的shifted window相對于初始的劃分有一個平移,這個平移距離剛好是單個window邊長的一半,
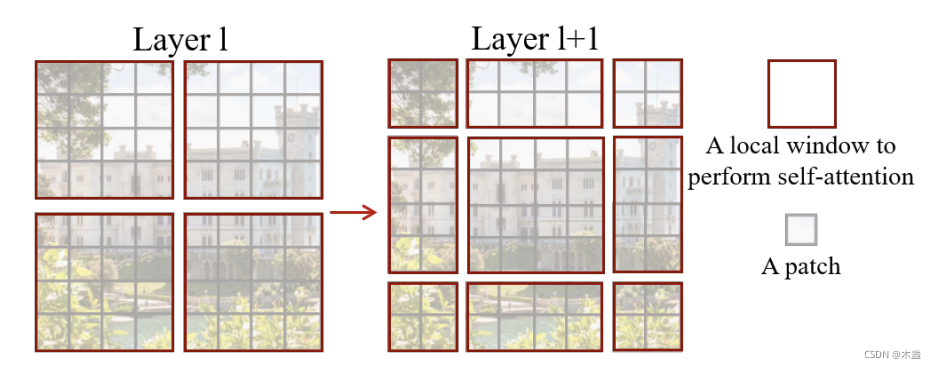
圖3
上圖是一個2x2個window的例子,window通過對角線方向滑動后,中間那個window就獲取到了上一層所有window的資訊了,用這種Shifted Window技巧來聚合各個不相交window之間的資訊被證明是在各種視覺任務中非常有效的,
SW-MSA在邏輯上很make sense,但在計算上需要頗費心機,我們看圖3,當視窗滑動后,視窗數從2x2變到3x3,而且邊緣的視窗也比正常視窗小,為了應對計算上的問題,作者提出了基于cyclic shift的batch computation,
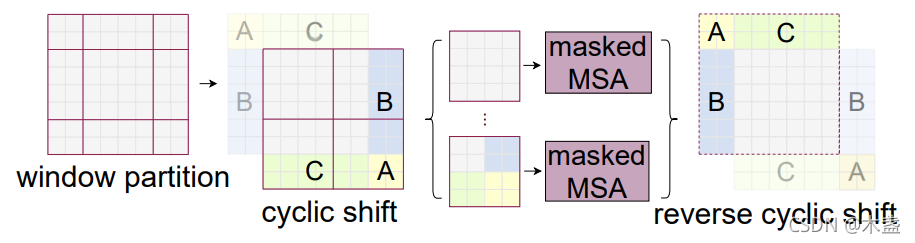
這種做法可以保證window數量不變,也可以保證每個window中的token數量也一樣多,然后,通過MSA中的mask來分開window中的子視窗,如那個黃色部分A小塊,這樣,就可以實作非常高效且省資源的計算,
代碼中通過2個torch.roll來實作,一個負責滑動過去,一個負責滑動回來,
torch.roll的圖片示例為:
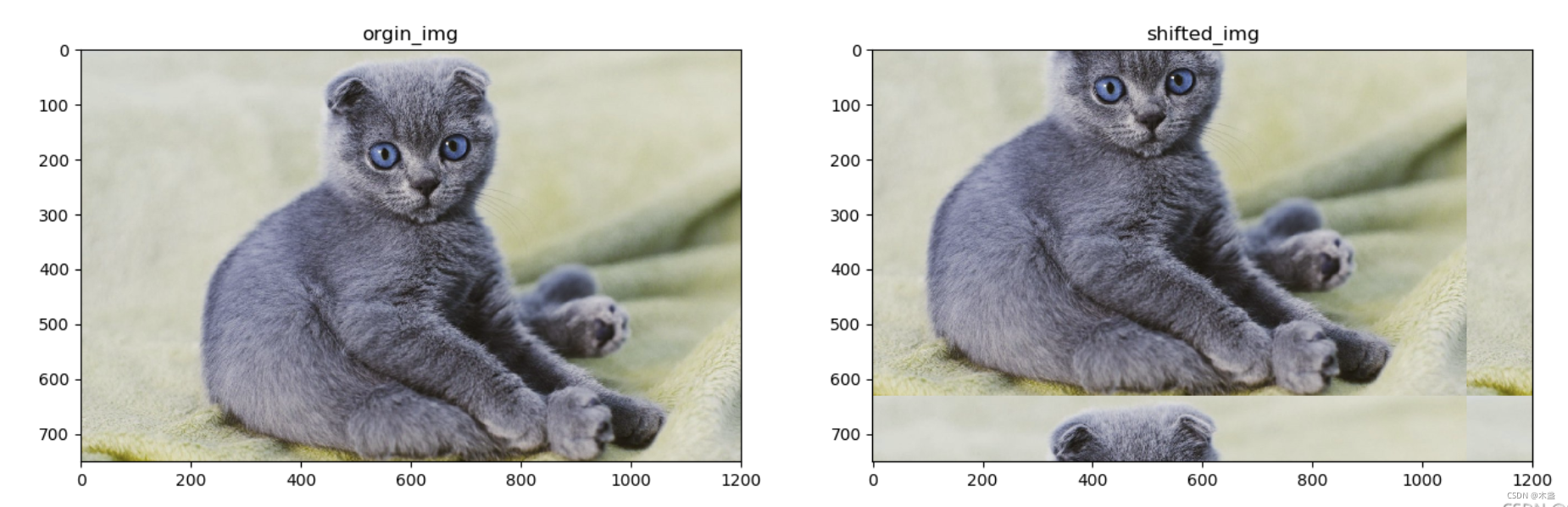
詳情可戳《torch.roll圖片實驗》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/325439.html
標籤:AI