任務一
安裝centOS 7
配置網路
任務二
Ssh免密操作
安裝JDK和hadoop
廢話不多說直接開始了
需準備軟體如下:
VMware 14.X以上的版本,官網下也可以,也可以用百度網盤鏈接
下載鏈接:https://pan.baidu.com/s/1BWA55zt7TvLU9AjxNqKhrg,提取碼:123l
centOS 7鏡像,可在官網免費下載,官網https://www.centos.org
Xshell和xftp,都可以在官網下載
Eclipse直接在官網下Linux系統版本
任務一
安裝好VMware后開始centOS 7的安裝,進入如圖所示的界面后點擊“創建新的虛擬機”然后點“典型推薦”,完成后點下一步
好好看截圖
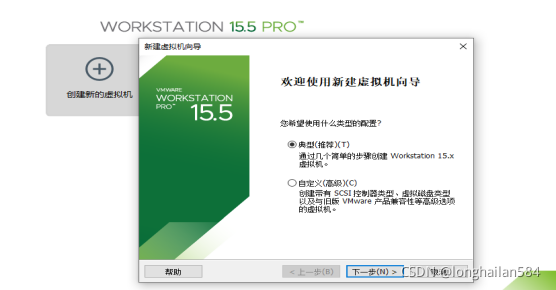
小提示:
在進行這一步之前請務必記住centOS 7所在的檔案夾,并且檔案夾不可有中文,
點擊瀏覽將centOS檔案放進去,
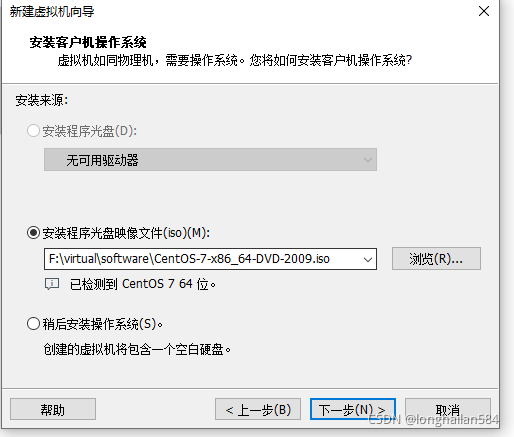
點下一步,然后先在某個盤下(最好是跟vmware一個盤)新建一個檔案并在該目錄下創建一個裝新建虛擬機的檔案夾,如圖所示:

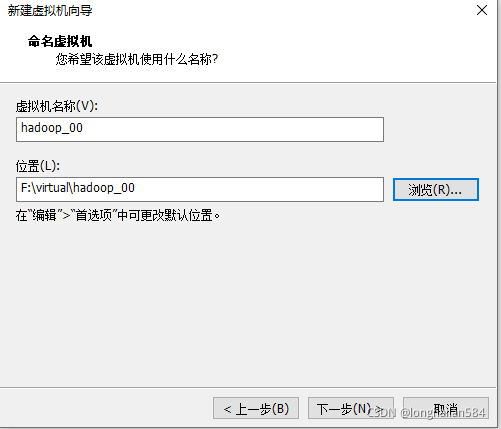
然后看圖可知,我們要給虛擬機取名字,隨便取一個就行,然后點“瀏覽”找到上一步新建的裝虛擬機的檔案夾,把虛擬機放到這里面去,如圖所示的路徑,
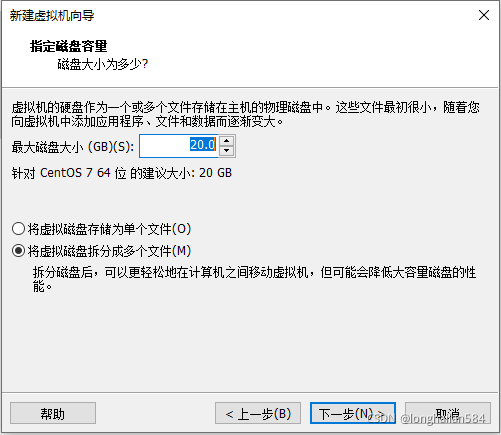
繼續下一步,磁盤大小20G足夠了,注意要點“將虛擬機磁盤拆分成多個檔案”選項,
點“自定義硬體”
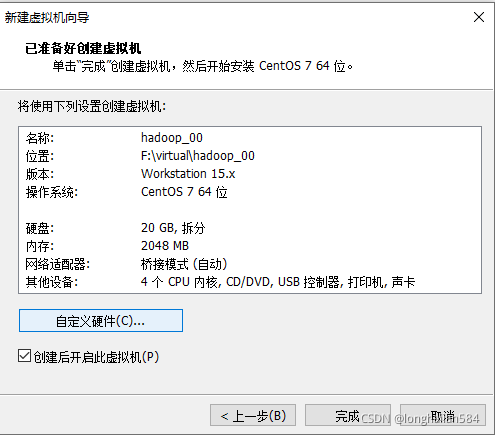
記憶體可以設定大一點方便后面虛擬機的運行,當然也可以默認,

處理器看自己電腦來,也可以默認,
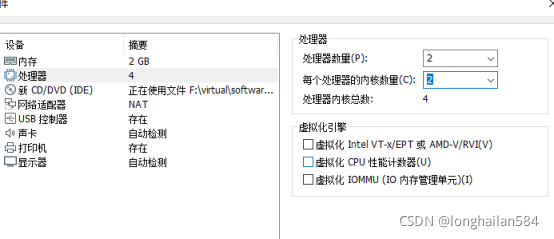
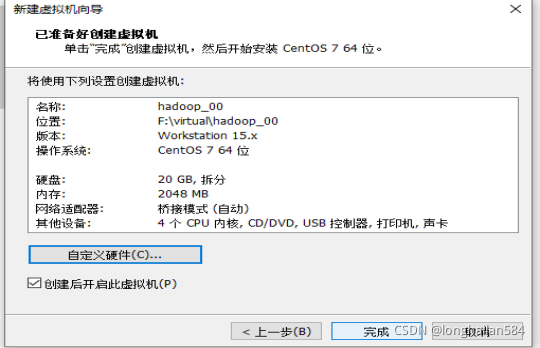
弄完點關閉后再直接點完成即可,
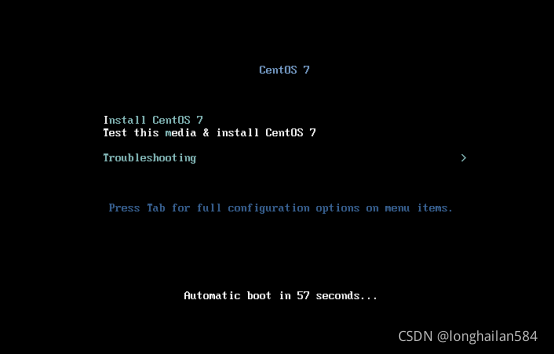
點了“完成”以后虛擬機自動啟動了,出現了如圖所示界面,點“Install CentOS 7”
選擇中文,然后繼續
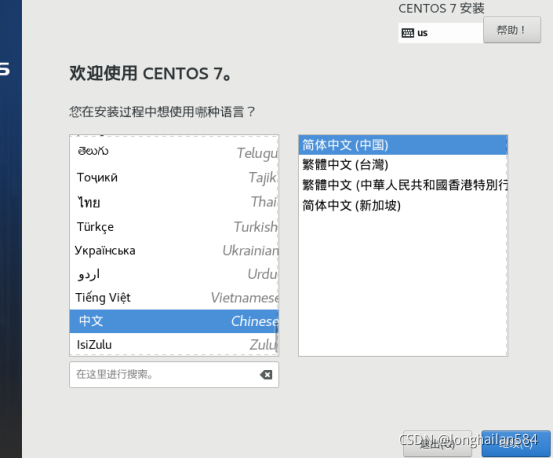
時間選如圖所示時間,軟體選擇安裝建議裝有桌面的,不然后面用指令安裝圖形界面很麻煩,

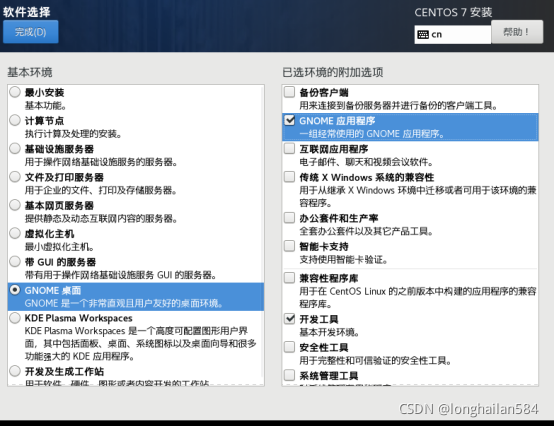
點軟體選擇進入如圖所示界面,選如圖所示的“GNOME桌面”,附加項可以不選,
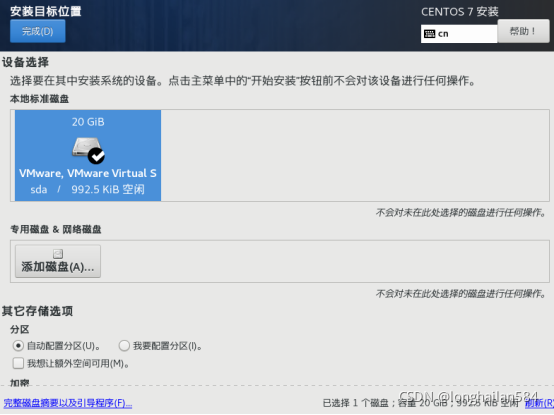
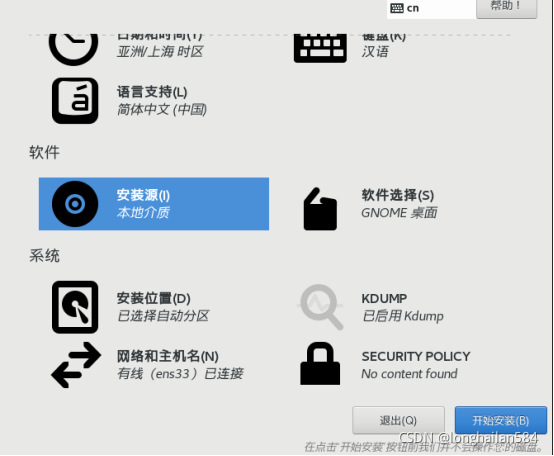
安裝位置選“自動磁區”如圖所示:
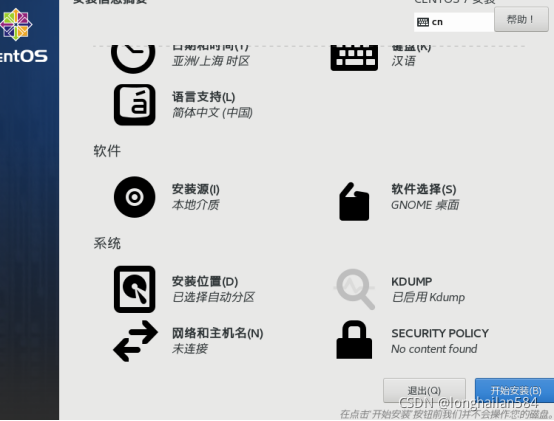
點“網路和主機名稱”
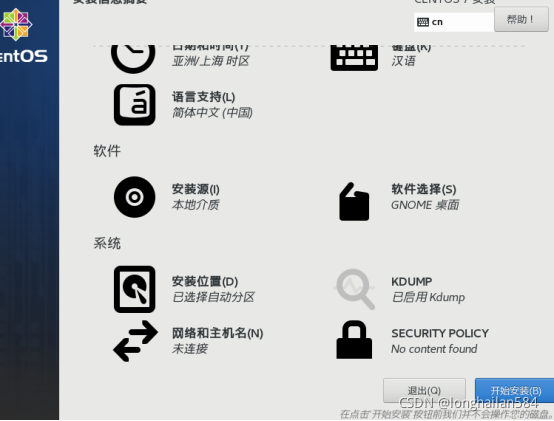
打開以太網,設定主機名然后點擊“應用”(一定要點,還要記住自己主機名字),然后點“完成”
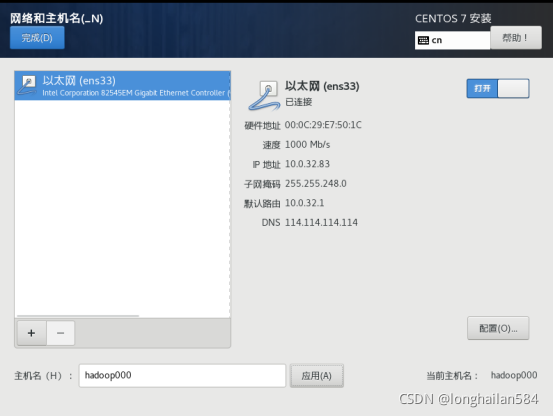
弄好這些然后點“開始安裝”,安裝需要一會時間,慢慢等,
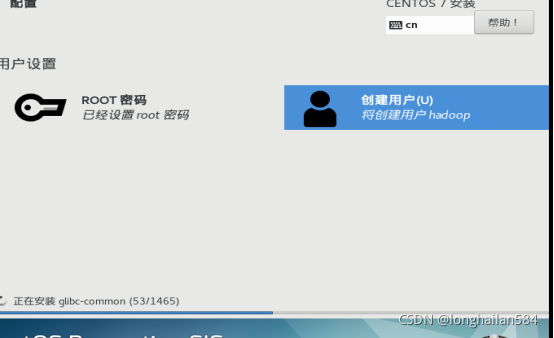
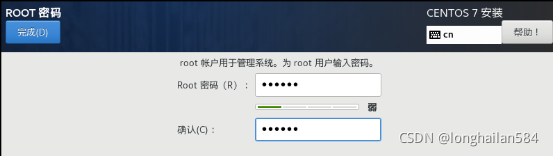
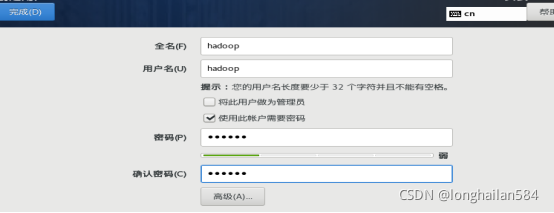
在centOS安裝的時候把root密碼和用戶建立一下,切記一定要記住密碼和用戶名,后面有用,密碼簡單點,用戶名名和root免密最好一致以免后面記混淆,密碼太簡單點兩次完成就可以退出當前界面,
遇到這個三角形加感嘆號提示的直接點進去

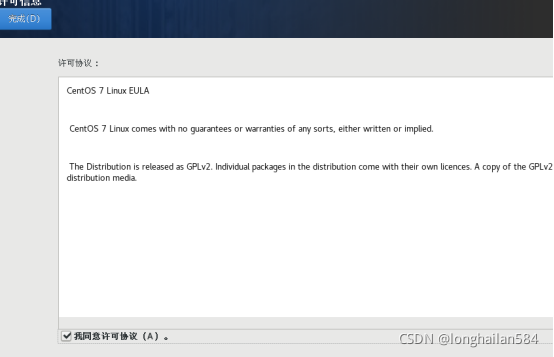
然后點“我同意許可協議”再點完成
出來了點“完成配置”就可以繼續安裝了,
點“重啟”重新啟動虛擬機
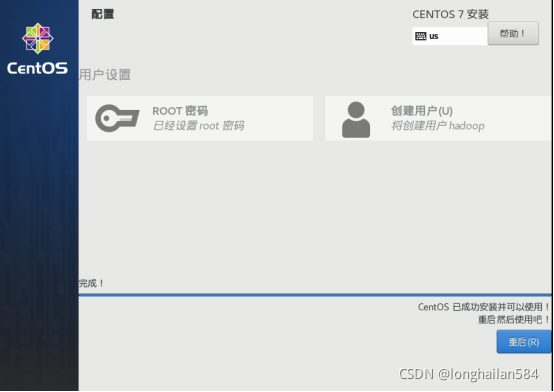
出現這個代表著centOS 7安裝完成了,點這個用戶輸入密碼進入圖形界面,

確認所選沒問題,就一路點前進
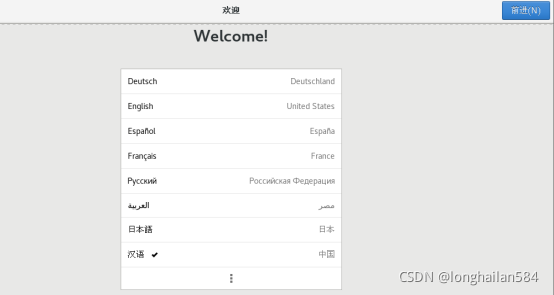
這就是圖形桌面

下面來配置網路
點擊右鍵選中“打開終端”選項,進入終端后輸入如圖所示指令,
我們的權限并不高,所有我們來弄一個提高權限操作
輸入指令:vi /etc/sudoers,找的root所在的那一行,然后在下邊添加(添加內容要按i)一行內容為:hadoop ALL=(root) NOPASSWD:ALL,注意:hadoop為主機名,如圖所示:

然后按Esc鍵+:+wq!為保存退出操作
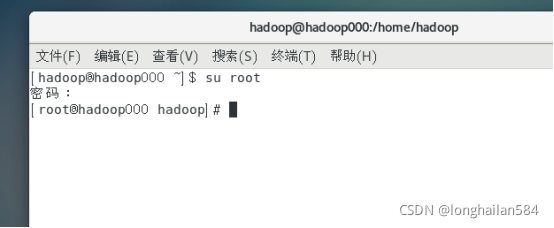
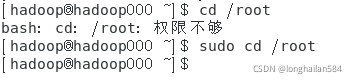
切換到hadoop用戶,指令:su hadoop

來驗證一下權限,發現cd /root權限很低,但是sudo cd /root卻可以,
開始配置網路了,注意啦!
首先點擊VMware的編輯點開“虛擬網路編輯器”
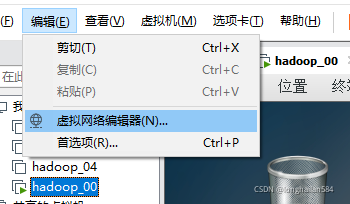
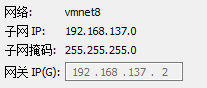
然后點“VMnet8”再點“NAT”設定查看IP地址等相關資訊
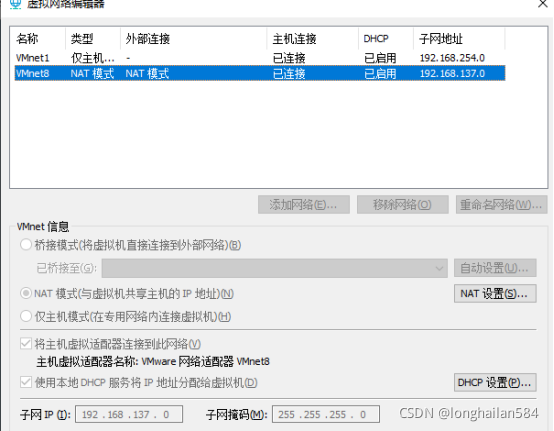
然后記住如圖所示資訊,截個圖就行,
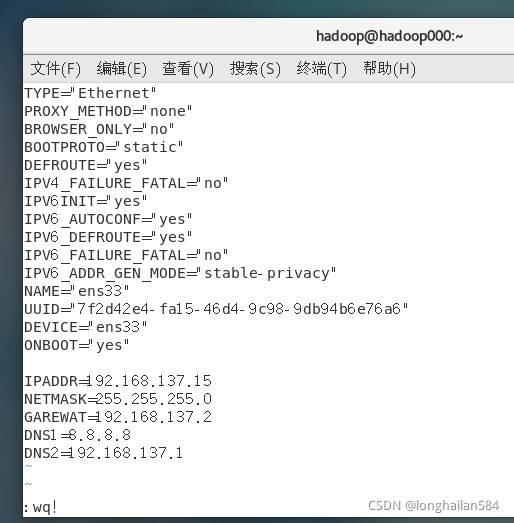
在終端輸入指令:sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改如圖所示內容,將BOOTPROTO后面的內容改成"static"
添加內容有:
IPADDR=
NETMASK=
GATEWAY
DNS1=
DNS2=
在等號后面填入你的ip地址與你的子網ip不同,子網掩碼和網關要和剛剛查看NAT設定截圖的一致,一定要保存,命令是:Esc+:+wq!
用指令:ping www.baidu.com看能不能ping通,ping通了說明連到網路了,因為我的是校園網所有ping不到外網,但是不影響后面操作,

重啟一下網路,指令:sudo service netwoek restart,再ping一次

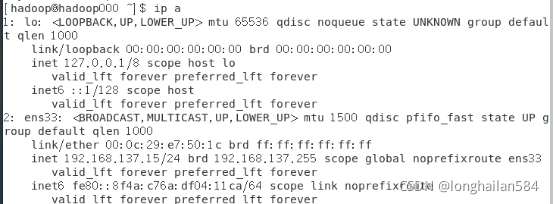
然后使用指令:ip a查看一下新ip,我這個新ip是:192.168.137.15
下載一個vim包,遇到(y/n)輸入y就行,指令如圖所示:
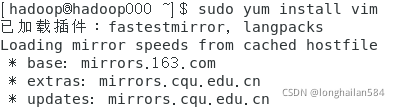
下面做一個虛擬機與主機的映射操作
指令:sudo vim /etc/hosts,將檔案里的前兩行注釋掉,注釋符號為“#”,在添加圈出內容,即ip地址+主機名
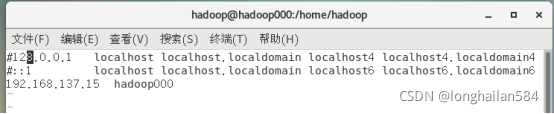
任務二
ssh免密登入操作
輸入命令:ssh-keygen -t rsa,然后按三次回車
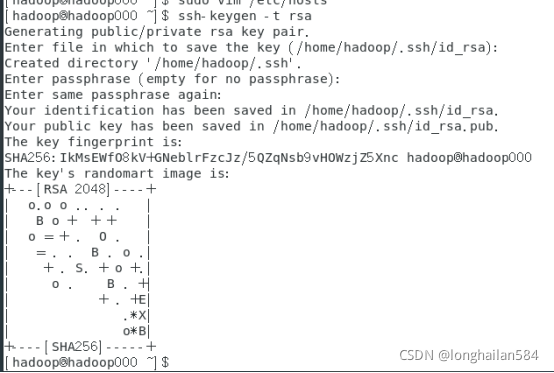
查看ssh生成檔案

Pub表示公開,我們要把公開資訊寫入一個檔案里authorized_keys
命令:cat id_rsa.pub >> authorized_keys,其中兩個大于號的意思表示追加,使內容不重復,
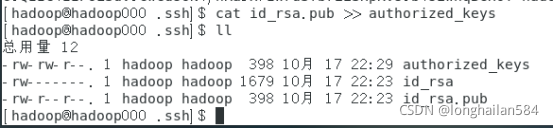
再輸入命令:sudo chmod 600 ~/.ssh/authorized_keys

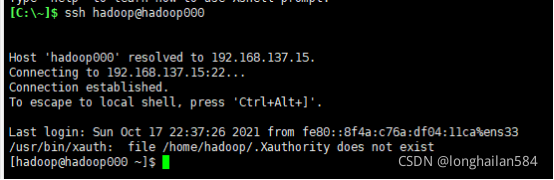
測驗一下SSH免密登入操作是否成功,命令:ssh hadoop@hadoop000,從圖片可看出我們的免密操作時成功了的,

因為虛擬機視窗不可以往上滑動,下面我們切換到xshell,在這里還要弄個東西,windows系統與虛擬機的映射,打開如圖所示的檔案目錄下的hosts檔案,注:C盤下的Windows檔案---->System32---->drivers---->etc---->hosts,用你電腦上可以編輯代碼的軟體打開,
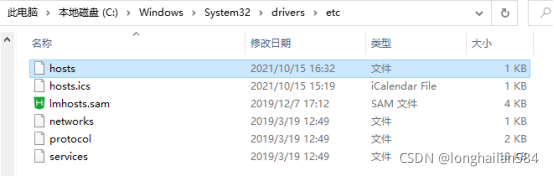
添加圖中點中所示的內容,即ip+虛擬機主機名,然后保存該檔案
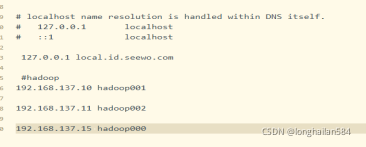
按win+r輸入cmd,在doc系統里輸入:ping hadoop000,表明映射成功,
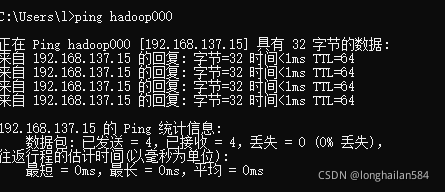
在xshell中輸入命令:ssh hadoop@hadoop000,彈出如圖所示內容,點擊“接受并保存”然后輸入密碼即可,
如圖所示為連接成功
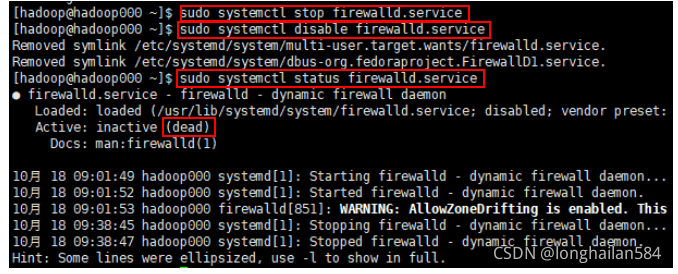
注意這里要進行關閉防火墻操作,命令如圈出內容所示
Sudo sysremctl stop firewalld.service 表示關閉防火墻
Sudo systemctl disable firewalld.service 不讓防火墻運行
Sudo systemctl disable firewalld.service 查看防火墻狀態,看到如圖圈出的dead單詞說明關閉成功
安裝JDK和hadoop
需要的安裝包有:JDK安裝和hadoop安裝包
JDK鏈接:百度網盤 請輸入提取碼![]() https://pan.baidu.com/s/1IGXbauo5YSgcjxddohDTdA
https://pan.baidu.com/s/1IGXbauo5YSgcjxddohDTdA
提取碼:1234
Hadoop鏈接:百度網盤 請輸入提取碼![]() https://pan.baidu.com/s/1hZ7Asw97ICdwjUHnU6JiXg
https://pan.baidu.com/s/1hZ7Asw97ICdwjUHnU6JiXg
提取碼:1234
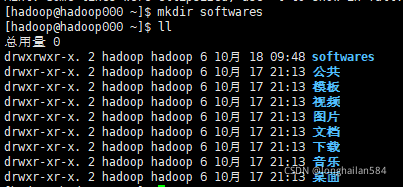
現在虛擬機里建立一個檔案夾
命令:mkdir softwares
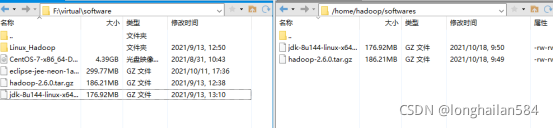
通過Xftp與虛擬機連接后進入到安裝包所在檔案目錄,將安裝包傳送到softwares檔案,如圖所示直接將安裝包拖過去就行,
輸入如圖所示命令(先cd softwares再ll),查看softwares檔案目錄的東西

在新建一個檔案夾(我的叫app),用來存放解壓后安裝的軟體
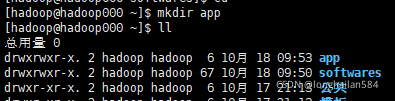
進入到softwares檔案目錄下,然后開始解壓JDK和hadoop,可以一個接一個的解壓,
命令:tar -zxvf jdk-8u144-linux-x64.tar.gz -C ~/app
tar -zxvf hadoop-2.6.0.tar.gz -C ~/app
在xshell里可以直接在softwares目錄下復制檔案名,
![]()
進入app檔案夾查看解壓情況,從圖中可以看到兩個安裝包都解壓成功,
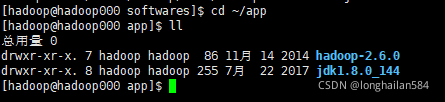
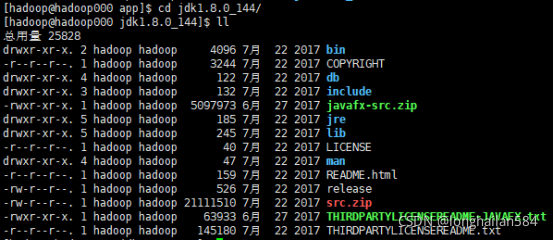
查看jdk
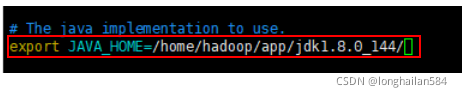
輸入命令:vim ~/.bash_profile,配置JDK和hadoop路徑,
![]()
添加內容如圖內容所示,注意這一步內容千萬不要錯,檔案路徑可以在Xftp里面看到,

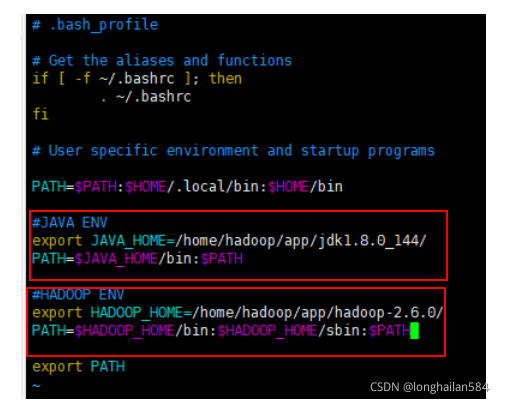
輸入指令:source ~/.bash_profile和java查看java資訊
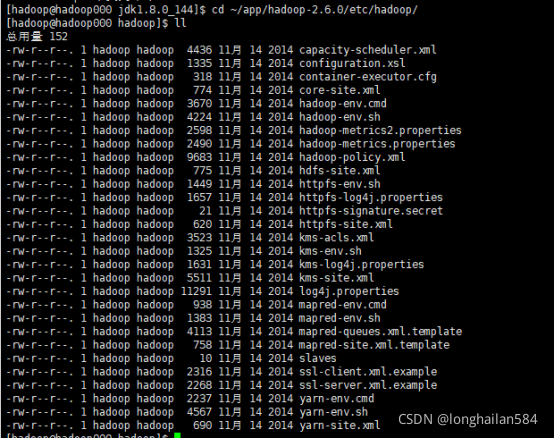
使用命令:cd ~/app/hadoop-2.6.0/etc/hadoop/和ll查看hadoop檔案
開始修改檔案啦,注意不要打錯內容,
第一個檔案,輸入命令:vim hadoop-env.sh,添加內容如圈出內容所示,將JDK路徑寫死,然后按Esc+:+wq!保存退出,
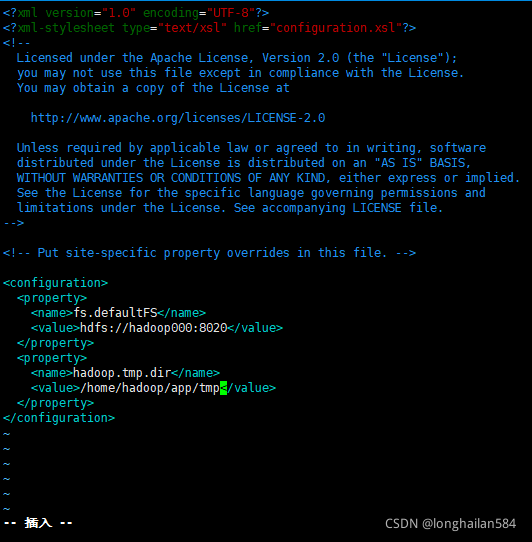
第二個檔案,命令:vim core-site.xml,添加如下內容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop000:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/tmp</value>
</property>
</configuration>
保存退出就行了,
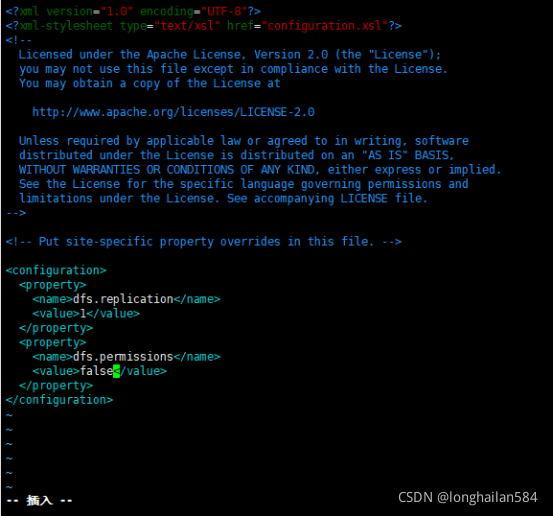
第三個檔案,命令:vim hdfs-site.xml
添加內容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
如圖所示
第四個檔案,一開始MapReduce檔案是沒有的,但是官方提供了模板,我們直接copy過去,
命令:cp mapred-site.xml.template mapred-site.xml,copy完成后輸入命令:vim mapred-site.xml打開這個檔案并在里面添加如下內容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
圖示內容如下:
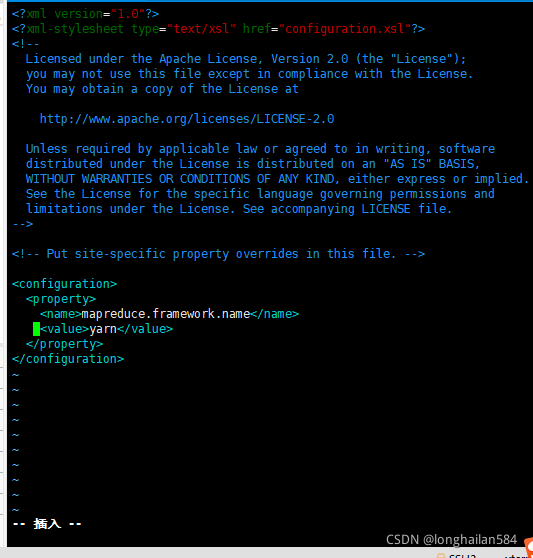
第五個檔案,命令:vim yarn-site.xml
添加內容為:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop000</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
圖片所示:
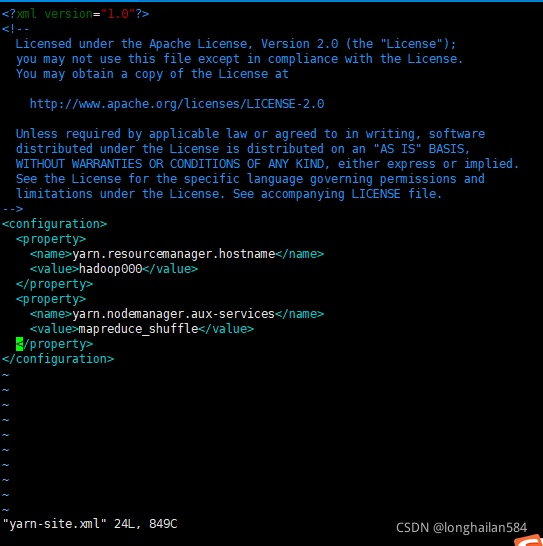
檔案修改為就來進行格式化,注意格式化只能進行一次,出錯需刪掉tmp檔案重新來,
命令:hdfs namenode -format
看到這一句話說明格式化成功
![]()
進行下面一系列操作,做這些都是為了啟動HDFS,啟動和關閉都需要一些時間慢慢等:
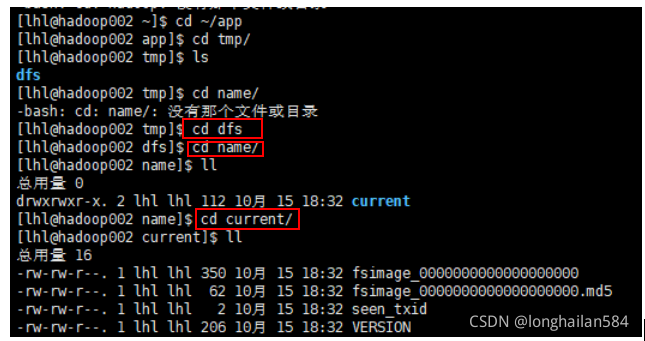
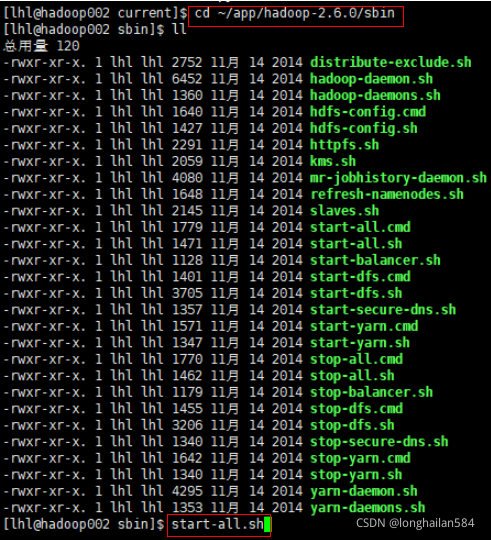
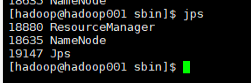
輸入命令:jps檢測啟動是否成功,成功如圖所示:
關閉命令:stop-all.sh

測驗
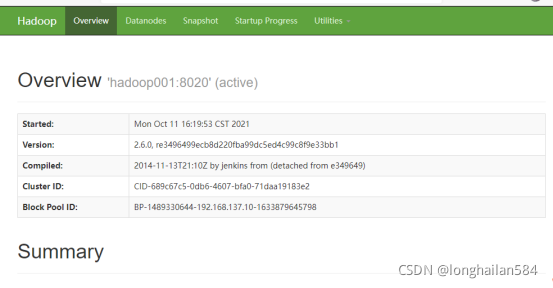
關閉電腦防火墻,打開瀏覽器,輸入:http://hadoop000:50070,得到如圖所示界面(因為我有現成截圖就沒有再截新的了,反正換湯不換藥,效果一樣,大家不要忘記自己的主機名就行)
查看share檔案:
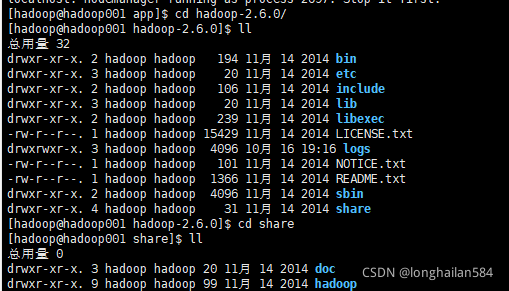
然后打開里面的hadoop檔案再打開mapreduce檔案,看到hadoop-mapreduce-examples-2.6.0.jar
回到根目錄下創建一個叫data的檔案,命令:mkdir data
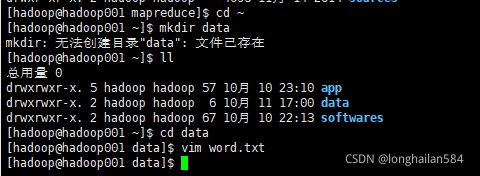
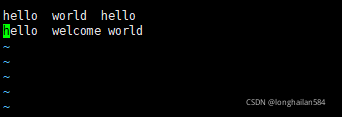
最后進入一個word.txt的檔案來測驗,命令:vim word.txt
內容隨便輸入,
把word.txt上傳到input檔案里,進行下面的指令操作檔案
hadoop fs -mkdir /input #創建input檔案
hadoop fs -put word.txt /input/word.txt #把word.txt上傳到HDFS檔案系統上
hadoop fs -text word.txt /input/word.txt #查看該檔案,把-text改成-cat效果一樣
![]()
![]()
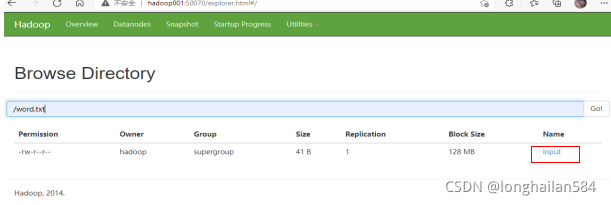
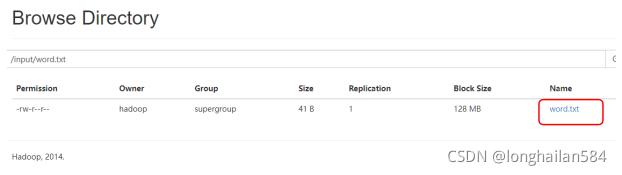
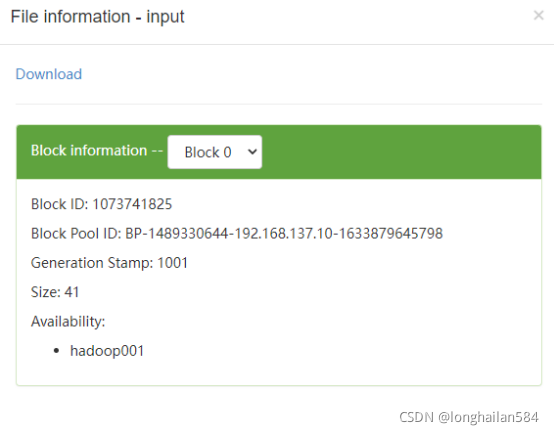
在網頁中可以看到input檔案,看到可以看到word.txt檔案,點擊他可以查看相關資訊
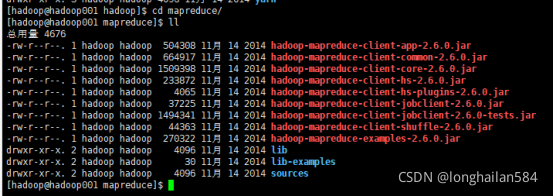
最后再打開mapreduce檔案,輸入:cd ~/app/hadoop-2.6.0/share/hadoop/---->ll---->cd mapreduce/---->ll---->hadoop jar hadoop-mapreduce-examples-2.6.0.jar
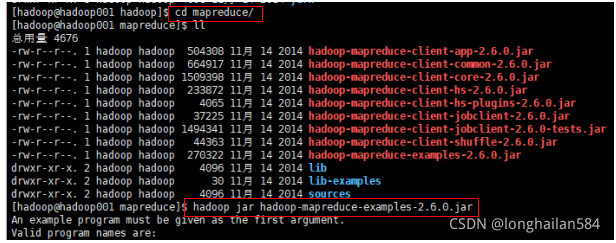
用wordcount統計字符,命令如圖圈出所示

然后輸入命令:hadoop fs -ls /output,可以看到一個SUCCESS單詞,說明統計成功,
輸入命令:hadoop fs -text /output/part-r-0000,可以清楚的知道word.txt的單詞數量,
好了到這hadoop的安裝就算是完成了,祝大家安裝順利,
我的學習資料視頻鏈接:CENTOS7下的HADOOP偽分布式安裝教程![]() https://www.bilibili.com/video/BV1sE41197mi?spm_id_from=333.999.0.0
https://www.bilibili.com/video/BV1sE41197mi?spm_id_from=333.999.0.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/325514.html
標籤:其他
下一篇:分布式一致性協議-Raft