文章目錄
- 1 前言
- 2 專案介紹
- 3 效果展示
- 4 專案分析
- 4.1 爬蟲部分
- 4.2 資料分析部分
- 5 最后-畢設幫助
1 前言
Hi,大家好,這里是丹成學長,今天做一個電商銷售預測分析,這只是一個demo,嘗試對電影資料進行分析,并可視化系統
畢設幫助,開題指導,技術解答
🇶746876041
2 專案介紹
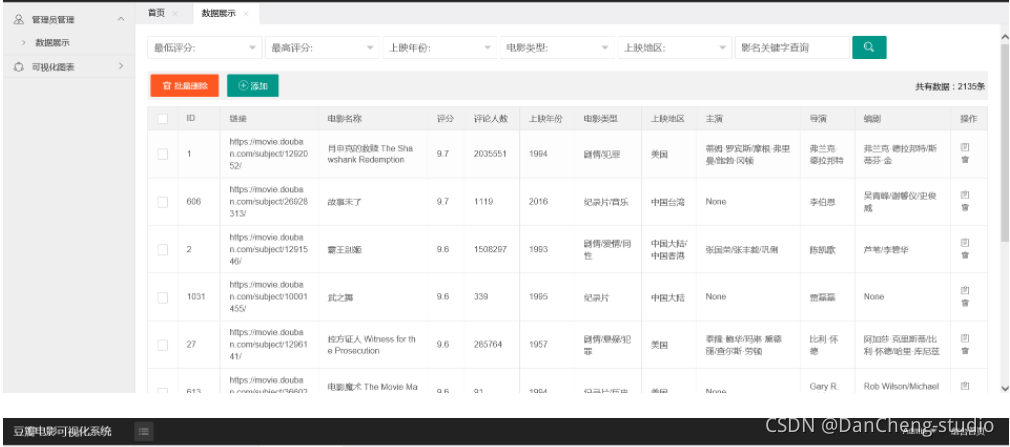
首先通過網頁開發者工具分析豆瓣電影網站,然后使用抓包工具攔截資料,從中找出api介面,接下來使用Python爬蟲進行資料的下載,資料下載完后,使用pandas模塊處理csv電影資料檔案,之后可以選用各種資料分析的方法對資料進行挖掘,包括但不限于關鍵詞提煉、詞頻統計、相關性探索、電影分類,再通過matplotlib繪制資料統計圖如條形圖、餅狀圖,亦或是wordCloud繪制評論詞云,
3 效果展示
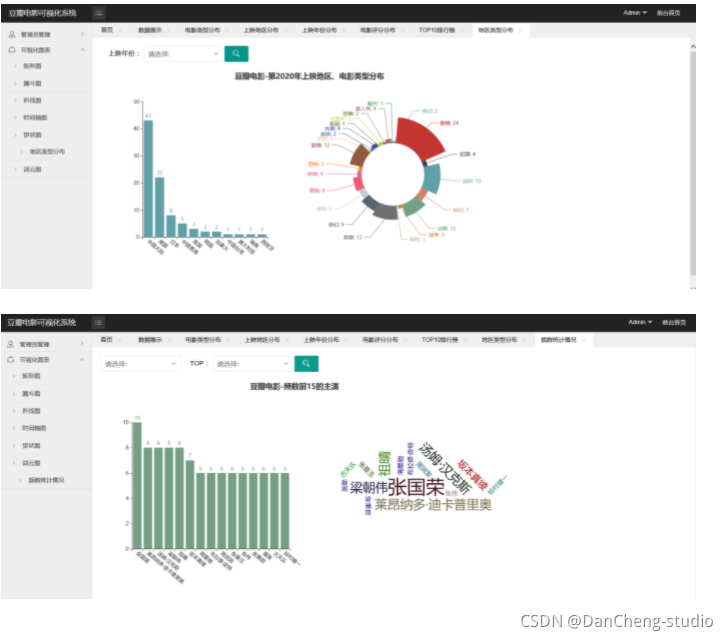
4 專案分析
4.1 爬蟲部分
豆瓣電影官網雖然沒有令人窒息的反爬操作,但是介面較為隱蔽,需要通過Fiddler抓包工具輔助,才能找到電影資料介面,
撰寫爬蟲時使用xpath對網頁資料進行提取,使用正則運算式過濾冗余文本資料并對文本進行清洗,爬蟲運行程序中要控制爬取速度,否則在運行時不會出現爬取問題,但經過一段時間后豆瓣官網檢測到本臺主機IP的不正常請求,就會對IP進行封鎖,阻止下一次大規模爬取,
通過登錄豆瓣賬號獲得Cookie可以級訓這一點,并且可以訪問到更多的資料量,不過并不能保證不會被封號,最后將爬取資料保存為csv檔案,方便后期使用pandas等做資料處理,
## 非完整代碼,畢業設計找丹成學長,q746876041
import csv
import pymysql
import requests
import re
from lxml import html
import time
# 請求頭
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
}
# 讀取電影url
urls = []
with open('./豆瓣電影TOP250鏈接.csv', 'r') as f:
reader = csv.reader(f)
urls = [row[0] for row in reader]
for i in range(0, len(urls)):
url = urls[i]
# 請求頁面
r = requests.get(url=url, headers=headers, timeout=5)
time.sleep(2)
etree = html.etree
selector = etree.HTML(r.text)
# 獲取電影名稱
filmname = []
try:
filmname = selector.xpath('//*[@id="content"]/h1/span[1]/text()')[0] # 電影名
if filmname == "":
filmname = None
except Exception as e:
filmname = None
print("filmname :{}".format(filmname))
# 獲取電影評分
score = []
try:
score_list = selector.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')
score = score_list[0].replace("\t", "").replace("\n", "")
if score == "":
score = None
except Exception as e:
score = None
print("score :{}".format(score))
# 獲取電影上映時間
showtime = []
try:
st = selector.xpath('//*[@id="content"]/h1/span[2]/text()')[0] # 上映日期
showtime = st.replace("(", "").replace(")", "")
if showtime == "":
showtime = None
except Exception as e:
showtime = None
print("time :{}".format(showtime))
# 獲取電影片長
mins = []
try:
mins_list = re.findall('片長:</span>.*?>(.*?)</span>', r.text, re.S) # 片長
mins = mins_list[0].replace(' ', '').replace('分鐘', '')
if mins == "":
mins = None
except Exception as e:
mins = None
print("mins :{}".format(mins))
# 獲取電影型別
genres_list = []
try:
genres_list = re.findall('<span property="v:genre">(.*?)</span>', r.text, re.S)
genres_list = '/'.join(genres_list)
if genres_list == "":
genres_list = None
except Exception as e:
genres_list = None
print("genres_list :{}".format(genres_list))
# 獲取電影制片地區
area_list = []
try:
area_list = re.findall('<span class="pl">制片國家/地區:</span> (.*?)<br/>', r.text, re.S)
area_list = '/'.join(area_list).replace(' ', '')
if area_list == "":
area_list = None
except Exception as e:
area_list = None
print("area_list :{}".format(area_list))
# 獲取電影導演
directors_list = []
try:
d_list = selector.xpath('//div[@id="info"]/span[1]/span[2]/a/text()') # 導演
if len(d_list) > 2:
for i in range(0, 3):
directors_list.append(d_list[i])
else:
for j in range(0, len(d_list)):
directors_list.append(d_list[j])
directors_list = '/'.join(directors_list)
if directors_list == "":
directors_list = None
except Exception as e:
directors_list = None
print("directors_list :{}".format(directors_list))
# 獲取電影編劇
scriptwriters_list = []
try:
w_list = selector.xpath('//*[@id="info"]/span[2]/span[2]/a/text()') # 編劇
if len(w_list) > 2:
for i in range(0, 3):
scriptwriters_list.append(w_list[i])
else:
for j in range(0, len(w_list)):
scriptwriters_list.append(w_list[j])
scriptwriters_list = '/'.join(scriptwriters_list)
if scriptwriters_list == "":
scriptwriters_list = None
except Exception as e:
scriptwriters_list = None
print('scriptwriters_list :{}'.format(scriptwriters_list))
# 獲取電影主演
actors_list = []
try:
actors = selector.xpath('//*[@id="info"]/span[3]/span[2]')[0] # 演員
a_list = actors.xpath('string(.)').replace(' ', '').split('/') # 標簽套標簽,用string(.)同時獲取所有文本
if len(a_list) > 2:
for i in range(0, 3):
actors_list.append(a_list[i])
else:
for j in range(0, a_list):
actors_list.append(a_list[j])
actors_list = '/'.join(actors_list)
if actors_list == "":
actors_list = None
except Exception as e:
actors_list = None
print('actors_list :{}'.format(actors_list))
# 獲取電影評價
comment = []
try:
comment = selector.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/div/div[2]/a/span/text()')[0]
if comment == "":
comment = None
except Exception as e:
comment = None
print("comment :{}".format(comment))
try:
# 打開資料庫連接
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='douban', charset='utf8')
# 使用cursor方法創建一個游標
cursor = conn.cursor()
# # 執行sql陳述句
query = 'insert into tb_film(url, filmname, score, showtime, genres, areas, mins, directors, scriptwriters, actors, comments) values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
values = (
url, filmname, score, showtime, genres_list, area_list, mins, directors_list, scriptwriters_list,
actors_list,
comment)
cursor.execute(query, values)
# 提交之前的操作,如果之前已經執行多次的execute,那么就都進行提交
conn.commit()
except Exception as e:
print(e)
# 回滾
conn.rollback()
# 關閉cursor物件
cursor.close()
# 關閉資料庫連接
conn.close()
## 非完整代碼,畢業設計找丹成學長,q746876041
爬蟲輸出如下:
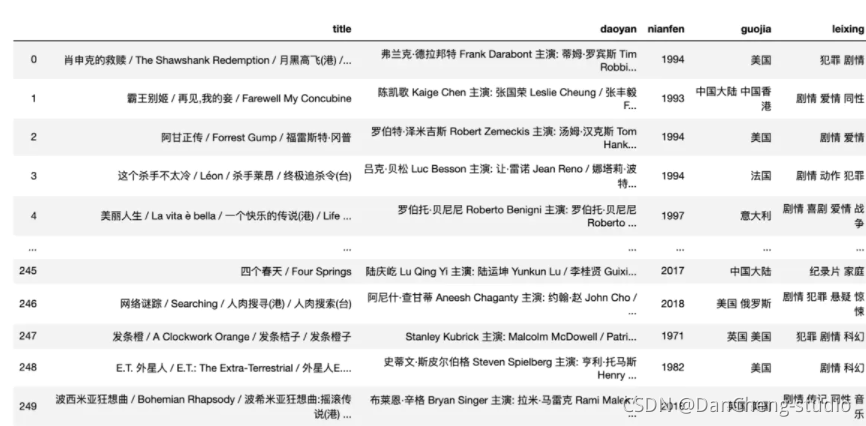
4.2 資料分析部分
針對某部電影的資料分析
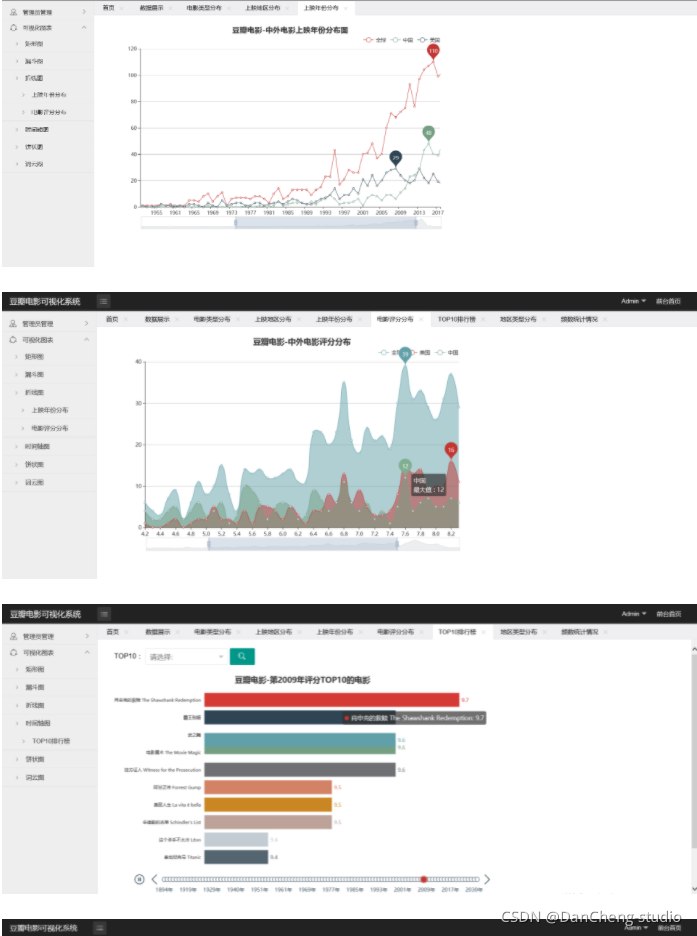
從不同時期影評人數、影評推薦指數、短評內容三個角度入手分析,不同時期的影評人數可以間接反映電影的熱度,因為大多數人都是在電影剛上映觀影完后寫的影評;影評推薦指數可以直接看出觀眾對電影的喜好程度,對最熱門的評論的匯總更能體現這部電影在大眾中的影響力,而不是單靠官方給出的豆瓣評分;短評詞云可以體現電影的許多要素,比如演員、題材、主要情節劇情、觀眾評價,可以讓影迷馬上把握該電影脈搏,從而決定這部電影是否值得一看,
隨機多部電影的綜合資料分析
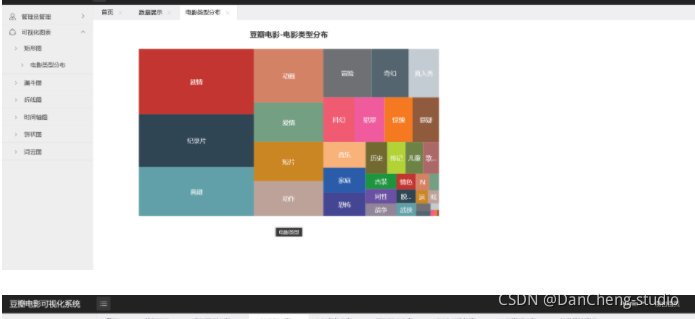
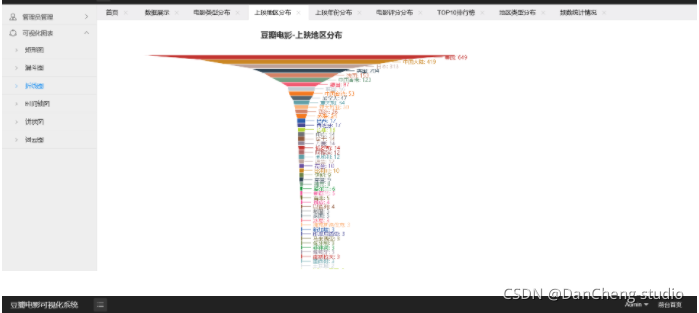
如果說針對某部電影的分析是讓影迷決定是否看該部電影,那么隨機多部電影的綜合分析結果就是指引影迷去觀看哪部電影,使用隨機序號生成器在熱門電影串列中任意選擇電影,然后可視化出電影評分排行榜、電影Top20高分排行榜,電影上映時間線和電影型別分布,多方位直觀俯瞰熱門電影行情,對于大眾來說可以得知哪些電影近期更受歡迎,哪些電影評分高,電影在哪個時間段上映,從而發現自己喜歡的電影和屬于自己的電影偏好,對于電影制作方,可以針對電影型別分布,保持哪些電影型別的產出,加大哪類電影的制作投入以順應大眾口味,甚至可以決策在什么時候上映哪些型別的電影能獲得最大收益,
## 非完整代碼,畢業設計找丹成學長,q746876041
import pymysql
from pyecharts import options as opts
from pyecharts.charts import Timeline, Bar, Grid
# 上映年份
showtime = []
# 查詢中外電影上映年份
def select_showtime():
try:
# 打開資料庫連接
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='douban', charset='utf8')
# 使用cursor方法創建一個游標
cursor = conn.cursor()
# 查詢資料表資料
# 查詢上映年份
sql = "select distinct showtime from tb_film where showtime is not null order by showtime "
cursor.execute(sql)
rows = cursor.fetchall()
showtime.clear()
for row in rows:
showtime.append(row[0])
print(showtime)
except Exception as e:
print(e)
# 回滾
conn.rollback()
finally:
# 關閉cursor物件
cursor.close()
# 關閉資料庫連接
conn.close()
return showtime
# 查詢電影名稱、評分
def select_film(i):
# 電影名稱集合
filmname = []
# 評分集合
score = []
try:
# 打開資料庫連接
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='douban', charset='utf8')
# cursorclass = pymysql.cursors.DictCursor
# 使用cursor方法創建一個游標
cursor = conn.cursor()
# 查詢資料表資料
# 查找評分前十的電影名稱、評分
cursor.execute(
"select filmname,score from tb_film where score is not null and showtime > 0 and showtime <= %s order by score desc limit 10",
i)
# 電影名稱、評分集合
film_list = cursor.fetchall()
for row in film_list:
# 電影名稱集合
filmname.append(row[0])
# 評分集合
score.append(row[1])
filmname.reverse()
score.reverse()
# 最大值
max_score = max(score)
# 最小值
min_score = min(score)
except Exception as e:
print(e)
# 回滾
conn.rollback()
finally:
# 關閉cursor物件
cursor.close()
# 關閉資料庫連接
conn.close()
return filmname, score, max_score, min_score
def select_data(year):
film_list = select_film(year)
colors = [
"#546570", "#c4ccd3", "#bda29a", "#ca8622", "#d48265",
"#6e7074", "#749f83", "#61a0a8", "#2f4554", "#c23531",
"#6e7074", "#749f83", "#61a0a8", "#2f4554", "#c23531"
]
y = []
for n in range(len(film_list[1])):
y.append(
opts.BarItem(
name=film_list[0][n],
value=film_list[1][n],
itemstyle_opts=opts.ItemStyleOpts(color=colors[n]),
)
)
return y
def show_score_top():
# 查找上映年份集合
showtime=select_showtime()
# 生成時間軸的圖
timeline = Timeline(init_opts=opts.InitOpts(page_title="豆瓣電影TOP250-評分TOP10的電影", ))
for year in showtime:
film_tuple=select_film(year)
date_list=select_data(year)
timeline.add_schema(is_auto_play=True, play_interval=1000)
# 柱狀圖初始化
bar = Bar()
# 橫坐標
bar.add_xaxis(film_tuple[0])
# 縱坐標
bar.add_yaxis(
"",
date_list,
# 資料靠右顯示
label_opts=opts.LabelOpts(is_show=True, position='right')
)
# 橫縱坐標翻轉
bar.reversal_axis()
# 全域配置
bar.set_global_opts(
# 標題
title_opts=opts.TitleOpts(title="豆瓣電影TOP250-第{}年評分TOP10的電影".format(year), pos_left='center'),
# 橫坐標隱藏
xaxis_opts=opts.AxisOpts(is_show=False, max_=select_film(year)[2], min_=(float(select_film(year)[3]) - 0.1),
split_number=10),
# 縱坐標
yaxis_opts=opts.AxisOpts(
max_=9,
# 字體大小
axislabel_opts=opts.LabelOpts(font_size=10),
# 隱藏坐標軸
axisline_opts=opts.AxisLineOpts(is_show=False),
# 隱藏刻度
axistick_opts=opts.AxisTickOpts(is_show=False)
)
)
# 組合組件
grid = (
Grid()
.add(bar, grid_opts=opts.GridOpts(pos_top='8%', pos_bottom='12%', pos_left='25%'))
)
timeline.add(grid, "{}年".format(year))
timeline.add_schema(is_auto_play=True, play_interval=1000, is_loop_play=False, width='820px', pos_left='60px')
# 生成HTML
html = "pages/iframes/score_top.html"
timeline.render("./templates/" + html)
return html
## 非完整代碼,畢業設計找丹成學長,q746876041
5 最后-畢設幫助
畢設幫助,開題指導,技術解答
🇶746876041

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/325517.html
標籤:其他
上一篇:分布式一致性協議-Raft