本期與大家分享的是,小北精心整理的大資料學習筆記,資料采集工具Flume 的詳細介紹,希望對大家能有幫助,喜歡就給點鼓勵吧,記得三連哦!歡迎各位大佬評論區指教討論!
💜🧡💛制作不易,各位大佬們給點鼓勵!
🧡💛💚點贊👍 ? 收藏? ? 關注?
💛💚💙歡迎各位大佬指教,一鍵三連走起!
一、Flume簡介
flume是一個分布式、可靠、和高可用的海量日志采集、聚合和傳輸的系統,支持在日志系統中定制各類資料發送方,用于收集資料;同時,Flume提供對資料進行簡單處理,并寫到各種資料接受方(比如文本、HDFS、Hbase等)的能力 ,flume的資料流由事件(Event)貫穿始終,事件是Flume的基本資料單位,它攜帶日志資料(位元組陣列形式)并且攜帶有頭資訊,這些Event由Agent外部的Source生成,當Source捕獲事件后會進行特定的格式化,然后Source會把事件推入(單個或多個)Channel中,你可以把Channel看作是一個緩沖區,它將保存事件直到Sink處理完該事件,Sink負責持久化日志或者把事件推向另一個Source,
二、Flume架構
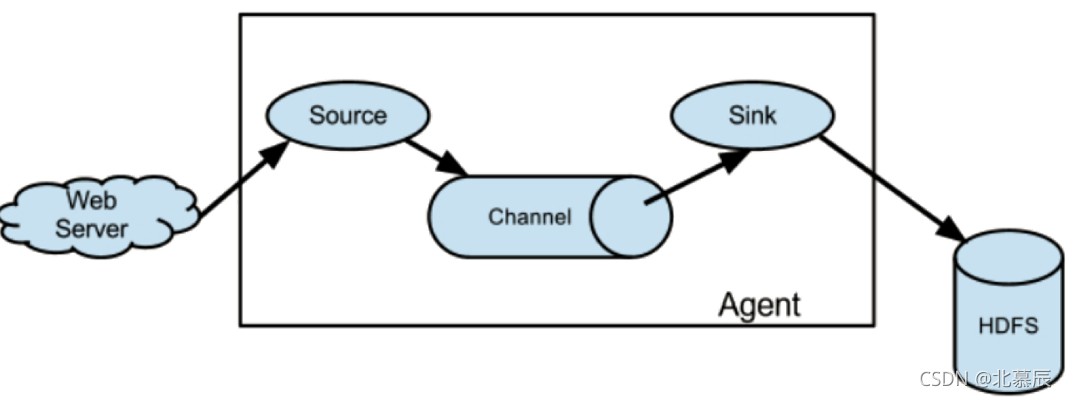
Flume 運行的核心是 Agent,Flume以agent為最小的獨立運行單位,一個agent就是一個JVM,它是一個完整的資料收集工具,含有三個核心組件,分別是
source、 channel、 sink,通過這些組件, Event 可以從一個地方流向另一個地方,如下圖所示,
三、Flume組件
Client:Client生產資料,運行在一個獨立的執行緒,
Event: 一個資料單元,訊息頭和訊息體組成,(Events可以是日志記錄、 avro 物件等,)
Flow: Event從源點到達目的點的遷移的抽象,
Agent: 一個獨立的Flume行程,包含組件Source、 Channel、 Sink,(Agent使用JVM 運行Flume,每臺機器運行一個agent,但是可以在一個agent中包含多個sources和sinks,)
Source: 資料收集組件,(source從Client收集資料,傳遞給Channel)
Channel: 中轉Event的一個臨時存盤,保存由Source組件傳遞過來的Event,(Channel連接 sources 和 sinks ,這個有點像一個佇列,)
Sink: 從Channel中讀取并移除Event, 將Event傳遞到FlowPipeline中的下一個Agent(如果有的話)(Sink從Channel收集資料,運行在一個獨立執行緒,)
Source
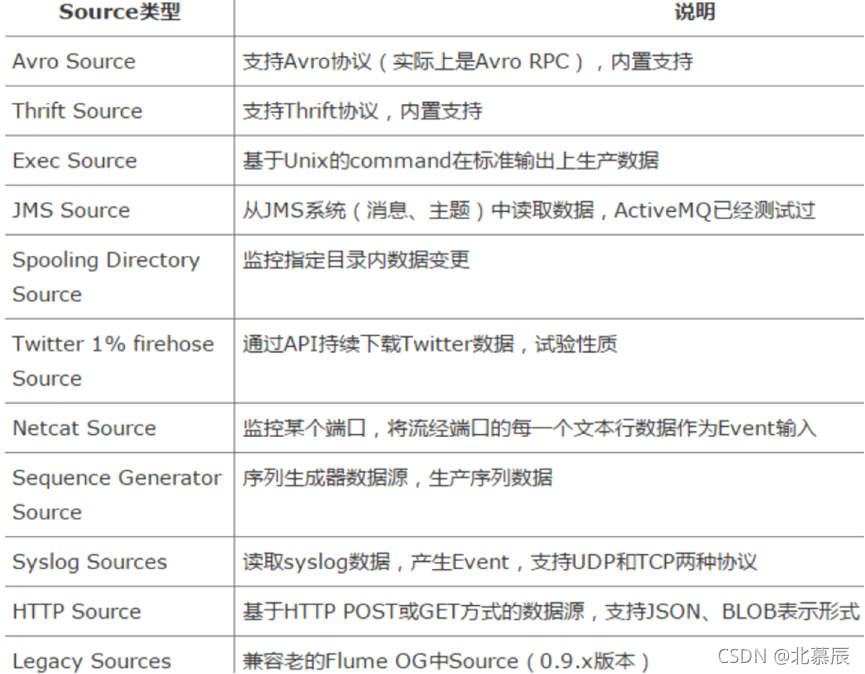
- Source是資料的收集端,負責將資料捕獲后進行特殊的格式化,將資料封裝到事件(event) 里,然后將事件推入Channel中, Flume提供了很多內置的Source, 支持 Avro, log4j, syslog 和 http post(body為json格式),可以讓應用程式同已有的Source直接打交道,如AvroSource
- 如果內置的Source無法滿足需要, Flume還支持自定義Source,
Channel
- Channel是連接Source和Sink的組件,大家可以將它看做一個資料的緩沖區(資料佇列),它可以將事件暫存到記憶體中也可以持久化到本地磁盤上, 直到Sink處理完該事件,介紹兩個較為常用的Channel, MemoryChannel和FileChannel,

Sink
- Sink從Channel中取出事件,然后將資料發到別處,可以向檔案系統、資料庫、 hadoop存資料, 也可以是其他agent的Source,在日志資料較少時,可以將資料存盤在檔案系統中,并且設定一定的時間間隔保存資料,
四、Flume資料流
-
Flume 的核心是把資料從資料源收集過來,再送到目的地,為了保證輸送一定成功,在送到目的地之前,會先快取資料,待資料真正到達目的地后,洗掉自己快取的資料
-
Flume 傳輸的資料的基本單位是 Event,如果是文本檔案,通常是一行記錄,這也是事務的基本單位, Event 從 Source,流向 Channel,再到 Sink,本身為一個 byte 陣列,并可攜帶 headers 資訊, Event 代表著一個資料流的最小完整單元,從外部資料源來,向外部的目的地去,
-
值得注意的是,Flume提供了大量內置的Source、Channel和Sink型別,不同型別的Source,Channel和Sink可以自由組合,組合方式基于用戶設定的組態檔,非常靈活,(比如:Channel可以把事件暫存在記憶體里,也可以持久化到本地硬碟上,Sink可以把日志寫入HDFS, HBase,甚至是另外一個Source等等,Flume支持用戶建立多級流,也就是說,多個agent可以協同作業)
五、Flume可靠性
- Flume 使用事務性的方式保證傳送Event整個程序的可靠性, Sink 必須在Event 已經被傳達到下一站agent里,又或者,已經被存入外部資料目的地之后,才能把 Event 從 Channel 中 remove 掉,這樣資料流里的 event 無論是在一個 agent 里還是多個 agent 之間流轉,都能保證可靠,因為以上的事務保證了 event 會被成功存盤起來,比如 Flume支持在本地保存一份channel檔案作為備份,而memory channel 將event存在記憶體 queue 里,速度快,但丟失的話無法恢復,
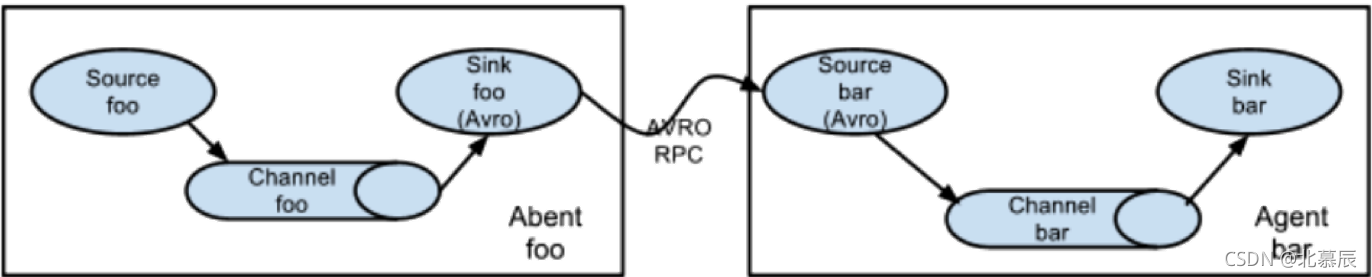
六、多個agent順序連接
-
可以將多個Agent順序連接起來,將最初的資料源經過收集,存盤到最終的存盤系統中,這是最簡單的情況,一般情況下,應該控制這種順序連接的
-
Agent 的數量,因為資料流經的路徑變長了,如果不考慮failover的話,出現故障將影響整個Flow上的Agent收集服務,
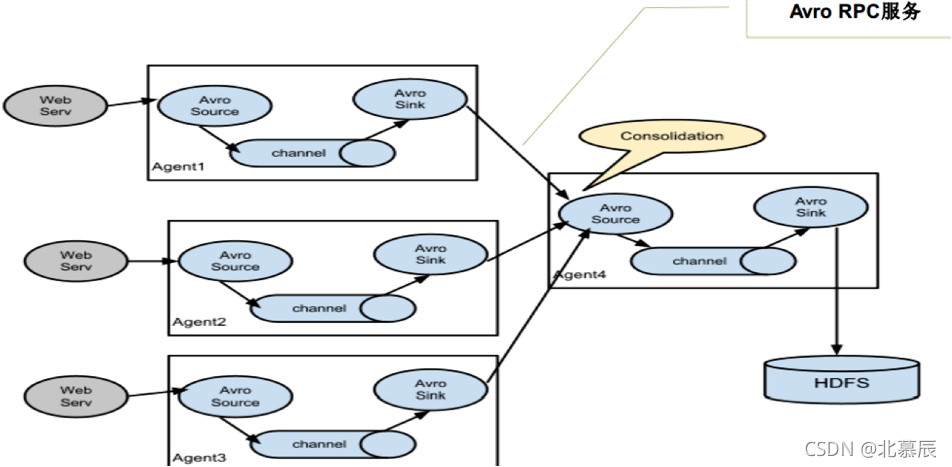
多個Agent的資料匯聚到同一個Agent
- 這種情況應用的場景比較多,比如要收集Web網站的用戶行為日志, Web網站為了可用性使用的負載集群模式,每個節點都產生用戶行為日志,可以為每個節點都配置一個Agent來單獨收集日志資料,然后多個Agent將資料最侄訓聚到一個用來存盤資料存盤系統,如HDFS上,
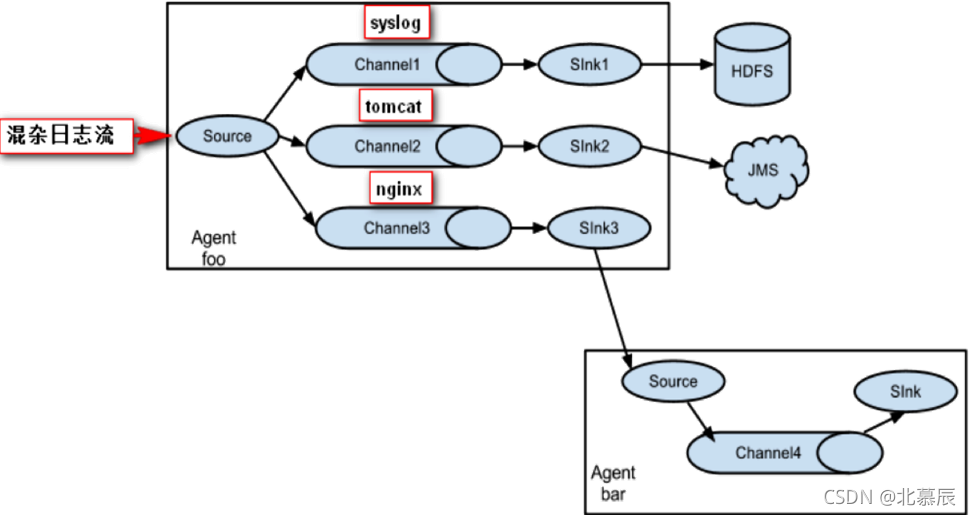
七、Flume多級流
- Flume還支持多級流,什么多級流?結合在云開發中的應用來舉個例子,當syslog, java, nginx、 tomcat等混合在一起的日志流開始流入一個agent后,可以agent中將混雜的日志流分開,然后給每種日志建立一個自己的傳輸通道,
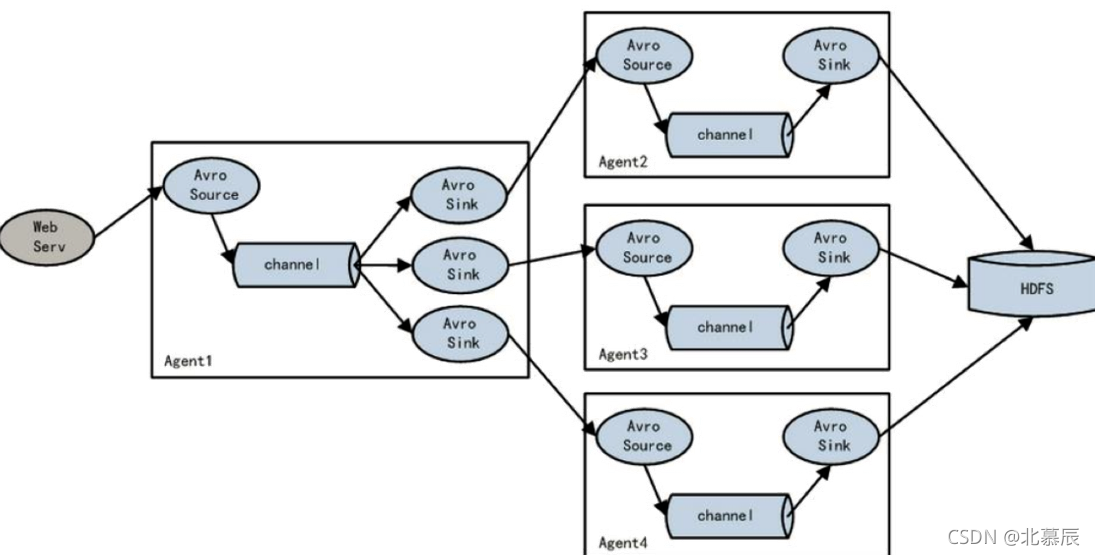
八、負載均衡功能
下圖Agent1是一個路由節點,負責將Channel暫存的Event均衡到對應的多個Sink組件上,而每個Sink組件分別連接到一個獨立的Agent上
九、Flume的安裝
1、上傳至虛擬機,并解壓
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /usr/local/soft/
在環境變數中增加如下命令,可以使用 soft 快速切換到 /usr/local/soft
alias soft=‘cd /usr/local/soft/’
2、重命名目錄,并配置環境變數
#修改目錄名為flume-1.9.0
mv apache-flume-1.9.0-bin/ flume-1.9.0
#配置環境變數
vim /etc/profile
#修改,添加
export FLUME_HOME=/usr/local/soft/flume-1.9.0
export PATH=$PATH:$FLUME_HOME/bin
#source 重繪組態檔
source /etc/profile
3、查看flume版本
flume-ng version

4、測驗flume
監控一個目錄,將資料列印出來
組態檔
# a1表示agent的名字 可以自定義
# 給sources(在一個agent里可以定義多個source)取個名字
a1.sources = r1
# 給channel個名字
a1.channels = c1
# 給channel個名字
a1.sinks = k1
# 對source進行配置
# agent的名字.sources.source的名字.引數 = 引數值
# source的型別 spoolDir(監控一個目錄下的檔案的變化)
a1.sources.r1.type = spooldir
# 監聽哪一個目錄
a1.sources.r1.spoolDir = /root/data
# 是否在event的headers中保存檔案的絕對路徑
a1.sources.r1.fileHeader = true
# 給攔截器取個名字 i1
a1.sources.r1.interceptors = i1
# 使用timestamp攔截器,將處理資料的時間保存到event的headers中
a1.sources.r1.interceptors.i1.type = timestamp
# 配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink為logger
# 直接列印到控制臺
a1.sinks.k1.type = logger
# 將source、channel、sink組裝成agent
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
啟動agent
flume-ng agent -n a1 -f ./spoolingtest.conf -Dflume.root.logger=DEBUG,console
新建/root/data目錄
mkdir /root/data
在/root/data/目錄下新建檔案,輸入內容,觀察flume行程列印的日志
# 隨意在a.txt中加入一些內容
vim /root/data/a.txt
十、Flume的簡單使用
1、 spoolingToHDFS.conf
組態檔
# a表示給agent命名為a
# 給source組件命名為r1
a.sources = r1
# 給sink組件命名為k1
a.sinks = k1
# 給channel組件命名為c1
a.channels = c1
#指定spooldir的屬性
a.sources.r1.type = spooldir
a.sources.r1.spoolDir = /root/data
a.sources.r1.fileHeader = true
a.sources.r1.interceptors = i1
a.sources.r1.interceptors.i1.type = timestamp
#指定sink的型別
a.sinks.k1.type = hdfs
a.sinks.k1.hdfs.path = /flume/data/dir1
# 指定檔案名前綴
a.sinks.k1.hdfs.filePrefix = student
# 指定達到多少資料量寫一次檔案 單位:bytes
a.sinks.k1.hdfs.rollSize = 102400
# 指定多少條寫一次檔案
a.sinks.k1.hdfs.rollCount = 1000
# 指定檔案型別為 流 來什么輸出什么
a.sinks.k1.hdfs.fileType = DataStream
# 指定檔案輸出格式 為text
a.sinks.k1.hdfs.writeFormat = text
# 指定檔案名后綴
a.sinks.k1.hdfs.fileSuffix = .txt
#指定channel
a.channels.c1.type = memory
a.channels.c1.capacity = 1000
# 表示sink每次會從channel里取多少資料
a.channels.c1.transactionCapacity = 100
# 組裝
a.sources.r1.channels = c1
a.sinks.k1.channel = c1
在 /root/data/目錄下準備資料
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
啟動agent
flume-ng agent -n a -f ./spoolingToHDFS.conf -Dflume.root.logger=DEBUG,console
2、 hbaseLogToHDFS
組態檔
# a表示給agent命名為a
# 給source組件命名為r1
a.sources = r1
# 給sink組件命名為k1
a.sinks = k1
# 給channel組件命名為c1
a.channels = c1
#指定exec的屬性
a.sources.r1.type = exec
a.sources.r1.command = tail -f /usr/local/soft/hbase-1.4.6/logs/hbase-root-master-master.log
#指定sink的型別
a.sinks.k1.type = hdfs
a.sinks.k1.hdfs.path = /flume/data/dir2
# 指定檔案名前綴
a.sinks.k1.hdfs.filePrefix = hbaselog
# 指定達到多少資料量寫一次檔案 單位:bytes
a.sinks.k1.hdfs.rollSize = 102400
# 指定多少條寫一次檔案
a.sinks.k1.hdfs.rollCount = 1000
# 指定檔案型別為 流 來什么輸出什么
a.sinks.k1.hdfs.fileType = DataStream
# 指定檔案輸出格式 為text
a.sinks.k1.hdfs.writeFormat = text
# 指定檔案名后綴
a.sinks.k1.hdfs.fileSuffix = .txt
#指定channel
a.channels.c1.type = memory
a.channels.c1.capacity = 1000
# 表示sink每次會從channel里取多少資料
a.channels.c1.transactionCapacity = 100
# 組裝
a.sources.r1.channels = c1
a.sinks.k1.channel = c1
3、hbaselogToHBase
在hbase中創建log表
create 'log','cf1'
組態檔
# a表示給agent命名為a
# 給source組件命名為r1
a.sources = r1
# 給sink組件命名為k1
a.sinks = k1
# 給channel組件命名為c1
a.channels = c1
#指定exec的屬性
a.sources.r1.type = exec
a.sources.r1.command = cat /usr/local/soft/hbase-1.4.6/logs/hbase-root-master-master.log
#指定sink的型別
a.sinks.k1.type = hbase
a.sinks.k1.table = log
a.sinks.k1.columnFamily = cf1
#指定channel
a.channels.c1.type = memory
a.channels.c1.capacity = 100000
# 表示sink每次會從channel里取多少資料
a.channels.c1.transactionCapacity = 100
# 組裝
a.sources.r1.channels = c1
a.sinks.k1.channel = c1
netcatLogger
監聽telnet埠
安裝telnet
yum install telnet
組態檔
# a表示給agent命名為a
# 給source組件命名為r1
a.sources = r1
# 給sink組件命名為k1
a.sinks = k1
# 給channel組件命名為c1
a.channels = c1
#指定netcat的屬性
a.sources.r1.type = netcat
a.sources.r1.bind = 0.0.0.0
a.sources.r1.port = 8888
#指定sink的型別
a.sinks.k1.type = logger
#指定channel
a.channels.c1.type = memory
a.channels.c1.capacity = 1000
# 表示sink每次會從channel里取多少資料
a.channels.c1.transactionCapacity = 100
# 組裝
a.sources.r1.channels = c1
a.sinks.k1.channel = c1
啟動
先啟動agent
flume-ng agent -n a -f ./netcatToLogger.conf -Dflume.root.logger=DEBUG,console
再啟動telnet
telnet master 8888
4、 httpToLogger
組態檔
# a表示給agent命名為a
# 給source組件命名為r1
a.sources = r1
# 給sink組件命名為k1
a.sinks = k1
# 給channel組件命名為c1
a.channels = c1
#指定http的屬性
a.sources.r1.type = http
a.sources.r1.port = 6666
#指定sink的型別
a.sinks.k1.type = logger
#指定channel
a.channels.c1.type = memory
a.channels.c1.capacity = 1000
# 表示sink每次會從channel里取多少資料
a.channels.c1.transactionCapacity = 100
# 組裝
a.sources.r1.channels = c1
a.sinks.k1.channel = c1
啟動
先啟動agent
flume-ng agent -n a -f ./httpToLogger.conf -Dflume.root.logger=DEBUG,console
再使用curl發起一個http請求
curl -X POST -d '[{ "headers" :{"a" : "a1","b" : "b1"},"body" : "hello~http~flume~"}]' http://master:666
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/325521.html
標籤:其他
上一篇:連接HiveServer2的圖形化工具SQuirrel和Dbeaver
下一篇:想要面試大資料作業的50道必看題