文章目錄
- 節點配置
- 允許root遠程登錄
- hostname修改
- IP地址修改
- host修改
- SSH免密登錄
- JDK 安裝
- Hadoop集群安裝
- 安裝目錄規劃
- 集群角色規劃
- 集群安裝
- 集群配置
節點配置
允許root遠程登錄
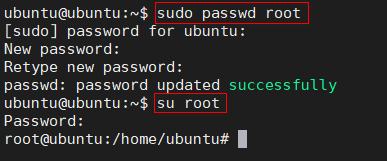
Step 1:登錄 node1 節點,修改 root 密碼
sudo passwd root
su root
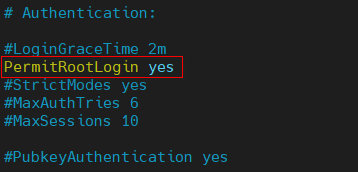
Step 2:修改 ssh 組態檔,允許 root 遠程登錄
vim /etc/ssh/sshd_config
#取消PermitRootLogin注釋,并將其改為
PermitRootLogin yes
# 重啟SSH服務
systemctl restart sshd
Step 3:使用 root 賬戶遠程登錄進行驗證
Step 4:按照同樣的方式修改 node2 和 node3
hostname修改
Step 1:使用 root 遠程登錄 node1,修改 hostname 為 node1
vim /etc/hostname

Step 2:重啟系統
reboot
Step 3:以同樣的方式修改 node2 和 node3
IP地址修改
各節點IP地址規劃如下
node1 192.168.10.10
node2 192.168.10.20
node3 192.168.10.30
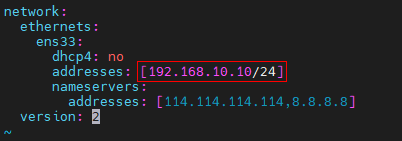
Step 1:使用 root 賬戶遠程登錄到 node1 節點,將其 IP 地址改為 192.168.10.10
vim /etc/netplan/00-installer-config.yaml
network:
ethernets:
ens33:
dhcp4: no
addresses: [192.168.10.10/24] # node2和node3只用修改這里的IP
nameservers:
addresses: [114.114.114.114,8.8.8.8]
version: 2
# 使得配置生效
netplan apply
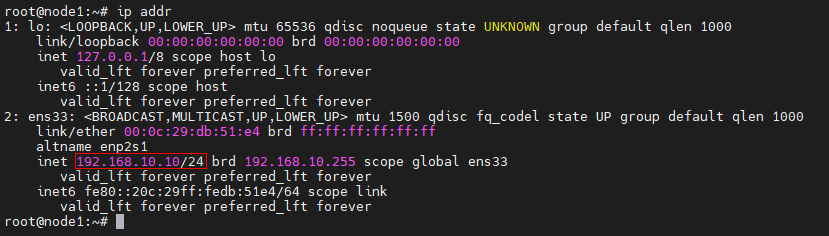
Step 2:使用 root 賬戶,并使用修改后的 IP 地址登錄,進行驗證
ip addr
Step 3:以同樣的方式修改 node2 和 node3 的 IP 地址
host修改
Step 1:使用 root 賬戶登錄 node1節點,修改 hosts檔案
vim /etc/hosts
192.168.10.10 node1
192.168.10.20 node2
192.168.10.30 node3
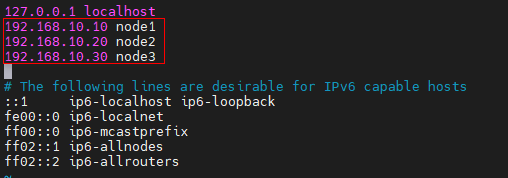
Step 2:以同樣的方式修改 node2 和 node3
SSH免密登錄
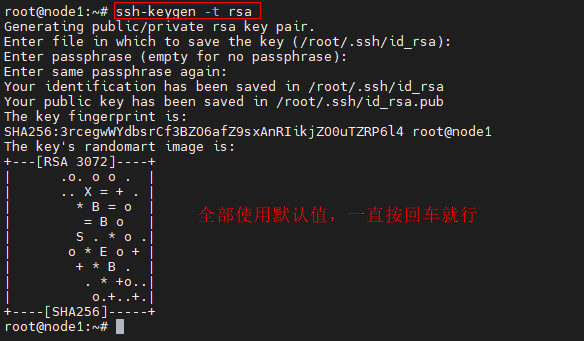
Step 1:使用 root 賬戶登錄 node1 節點,生成 RSA 密鑰對
ssh-keygen -t rsa
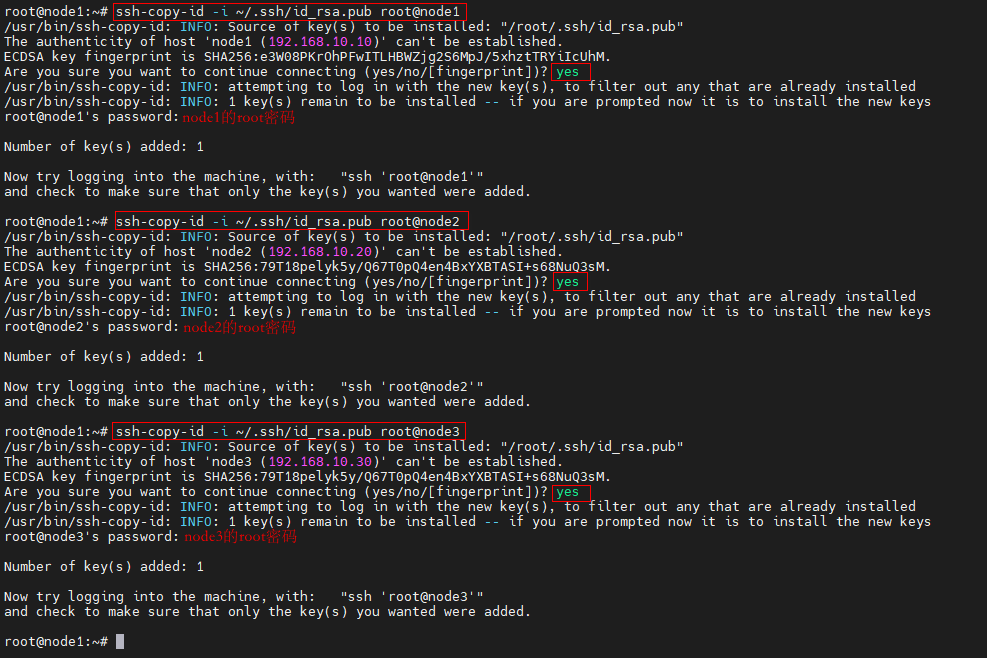
Step 2:使用 ssh-copy-id 將公鑰拷貝到各個節點
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node1
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node2
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node3
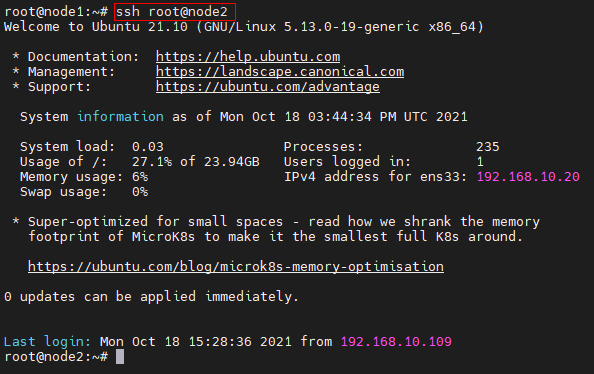
Step 3:免密登錄驗證
Step 4:以同樣的方式在 node2 和 node3 上進行配置
JDK 安裝
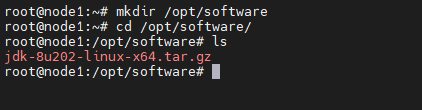
Step 1:遠程登錄 node1 節點,創建 JDK 安裝目錄,并把安裝包上傳到該目錄
mkdir /opt/software
cd /opt/software
ls
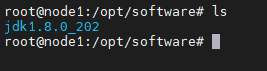
Step 2:解壓安裝包到當前目錄
tar -xzvf jdk-8u202-linux-x64.tar.gz
# 解壓之后可以洗掉安裝包
rm jdk-8u202-linux-x64.tar.gz
ls
Step 3:環境變數配置
vim /etc/profile.d/env.sh
export JAVA_HOME=/opt/software/jdk1.8.0_202
export PATH=$PATH:$JAVA_HOME/bin

# 讓環境變數生效
source /etc/profile
Step 4:安裝驗證
java -version

Step 5:遠程將 JDK 檔案和 環境變數檔案拷貝到 node2 和 node3
scp -r /opt/software/ root@node2:/opt/software/
scp -r /opt/software/ root@node3:/opt/software/
scp /etc/profile.d/env.sh root@node2:/etc/profile.d/env.sh
scp /etc/profile.d/env.sh root@node3:/etc/profile.d/env.sh
# 分別登錄 node2 和 node3 讓環境變數生效
source /etc/profile
Hadoop集群安裝
本例使用 Hadoop 3.1.4 版本進行安裝
安裝目錄規劃
# 資料存盤目錄
/opt/bigdata/data
# 安裝目錄
/opt/bigdata/server
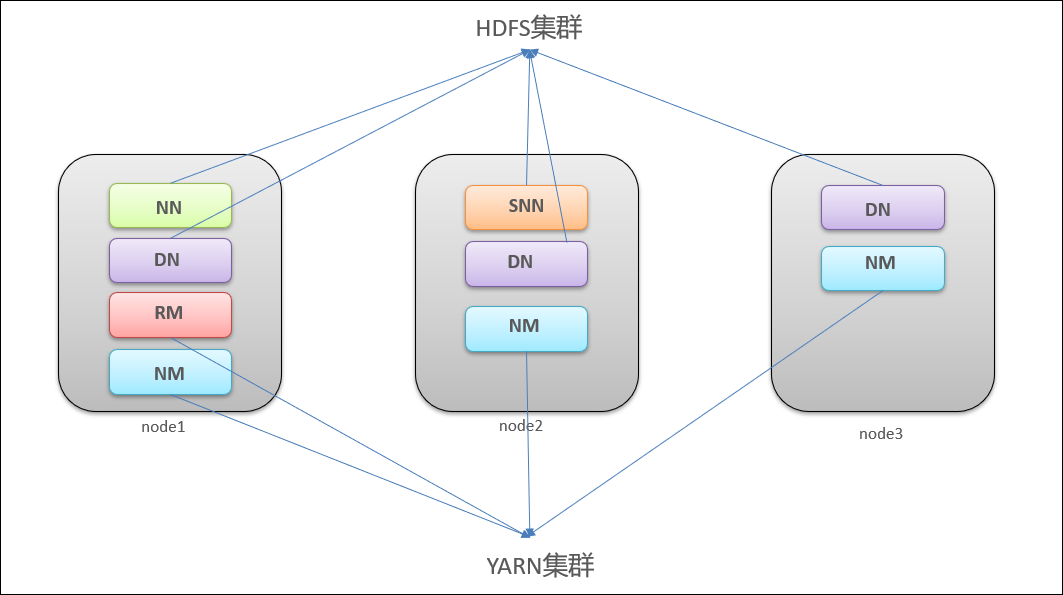
集群角色規劃
NN: NameNode
SNN: SecondaryNameNode
DN: DataNode
RM: ResourceManager
NM: NodeManager
集群安裝
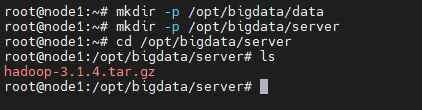
Step 1:遠程登錄 node1 節點,創建相關目錄,并把 Hadoop 安裝包上傳到 server目錄
mkdir -p /opt/bigdata/data
mkdir -p /opt/bigdata/server
cd /opt/bigdata/server
ls
Step 2:解壓安裝包到當前目錄
tar -xzvf hadoop-3.1.4.tar.gz
# 解壓之后可以洗掉安裝包
rm hadoop-3.1.4.tar.gz
ls
Step 3:環境變數配置
vim /etc/profile.d/env.sh
export JAVA_HOME=/opt/software/jdk1.8.0_202
export HADOOP_HOME=/opt/bigdata/server/hadoop-3.1.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

# 讓環境變數生效
source /etc/profile
Step 4:安裝驗證
hadoop version

集群配置
Step 1:hadoop-env.sh 配置
cd /opt/bigdata/server/hadoop-3.1.4/etc/hadoop
vim hadoop-env.sh
#配置JAVA_HOME
export JAVA_HOME=/opt/software/jdk1.8.0_202
#設定用戶以執行對應角色shell命令(hadoop3.0版本開始,如果需要用root賬戶執行,則需要添加如下環境變數)
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root

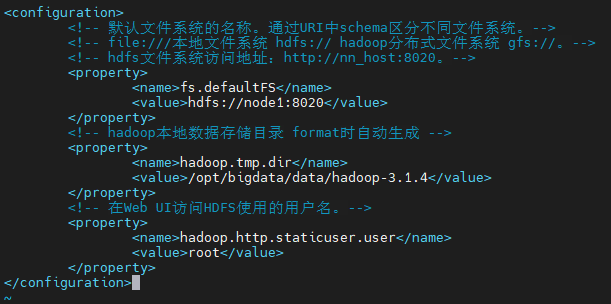
Step 2:core-site.xml 配置
cd /opt/bigdata/server/hadoop-3.1.4/etc/hadoop
vim core-site.xml
<!-- 默認檔案系統的名稱,通過URI中schema區分不同檔案系統,-->
<!-- file:///本地檔案系統 hdfs:// hadoop分布式檔案系統 gfs://,-->
<!-- hdfs檔案系統訪問地址:http://nn_host:8020,-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- hadoop本地資料存盤目錄 format時自動生成 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/data/hadoop-3.1.4</value>
</property>
<!-- 在Web UI訪問HDFS使用的用戶名,-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
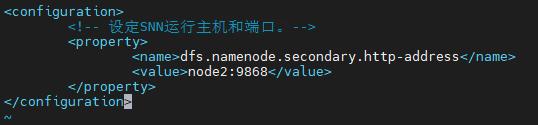
Step 3:hdfs-site.xml 配置
cd /opt/bigdata/server/hadoop-3.1.4/etc/hadoop
vim hdfs-site.xml
<!-- 設定SNN運行主機和埠,-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
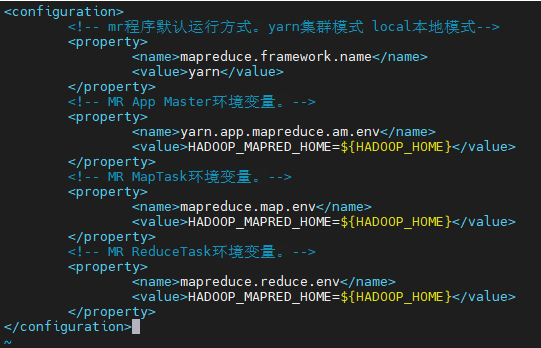
Step 4:mapred-site.xml 配置
cd /opt/bigdata/server/hadoop-3.1.4/etc/hadoop
vim mapred-site.xml
<!-- mr程式默認運行方式,yarn集群模式 local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR App Master環境變數,-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask環境變數,-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask環境變數,-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
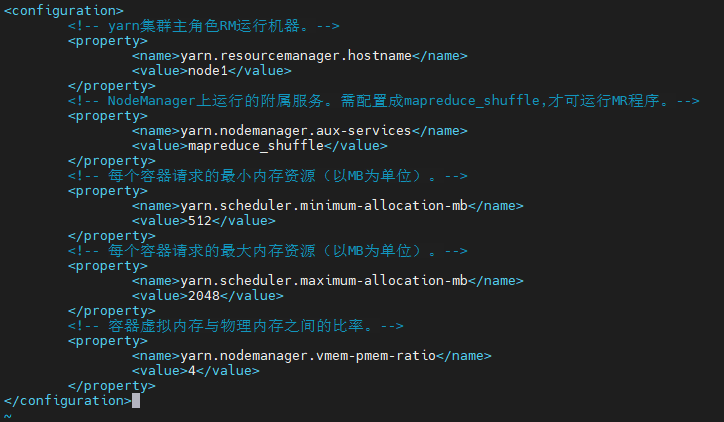
Step 5:yarn-site.xml 配置
cd /opt/bigdata/server/hadoop-3.1.4/etc/hadoop
vim yarn-site.xml
<!-- yarn集群主角色RM運行機器,-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- NodeManager上運行的附屬服務,需配置成mapreduce_shuffle,才可運行MR程式,-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 每個容器請求的最小記憶體資源(以MB為單位),-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<!-- 每個容器請求的最大記憶體資源(以MB為單位),-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器虛擬記憶體與物理記憶體之間的比率,-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
Step 6:將修改后的 Hadoop 安裝包和資料目錄拷貝到 node2 和 node3
scp -r /opt/bigdata/ root@node2:/opt/bigdata/
scp -r /opt/bigdata/ root@node3:/opt/bigdata/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/325525.html
標籤:其他