文章目錄
- 鏈表的概念及結構
- 初始化鏈表
- 列印單鏈表
- 創建新節點
- 計算鏈表節點數
- 單鏈表頭插
- 單鏈表尾插
- 特定位置插入
- 特定位置之前插入
- 特定位置后插入
- 單鏈表頭刪
- 單鏈表尾刪
- 特定位置洗掉
- 洗掉特定位置的節點
- 洗掉特定位置的后一節點
- 單鏈表查找
- 修改鏈表
- 銷毀單鏈表
鏈表的概念及結構
概念:鏈表是一種物理存盤結構上非連續、非順序的存盤結構,資料元素的邏輯順序是通過鏈表中的指標鏈接次序實作的 ,鏈表由一系列結點(鏈表中每一個元素稱為結點)組成,結點可以在運行時動態生成,每個結點包括兩個部分:一部分是存盤資料元素的資料域,另一部分是存盤其他結點地址的指標域,
結構:
就拿單鏈表的結構舉例,其邏輯結構如下:

可以看出該鏈表有一個頭結點pList,用來儲存單鏈表第一個節點的地址,第一個節點的指標域儲存第二個節點的地址,依次到最后一個節點,最后一個節點的指標域就為NULL,這就是一個簡單的單鏈表的邏輯結構,
這里有幾點需要提示:
1.從上圖可以看出,鏈式結構在邏輯上是連續的,但在物理上不一定連續
2.現實中的節點一般都是從堆上申請出來的
3.從堆上申請的空間,是按照一定的策略來分配的,兩次申請的空間可能連續,也可能不連續
在實際中,鏈表的結構多種多樣,具體有如下:
1)帶頭/不帶頭
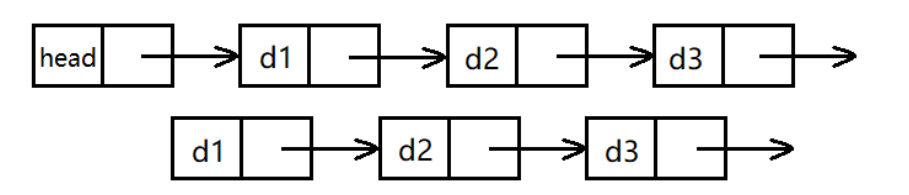
2)單向/雙向

3)回圈/非回圈
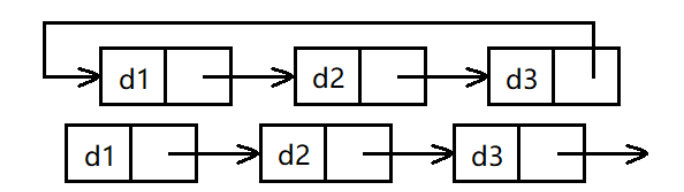
雖然有這么多的鏈表的結構,但是我們實際中最常用還是兩種結構:
1.無頭單向非回圈鏈表:

無頭單向非回圈鏈表結構簡單,一般不會單獨用來存資料,實際中更多是作為其他資料結構的子結構,如哈希桶、圖的鄰接表等等,
2.帶頭雙向回圈鏈表

帶頭雙向回圈鏈表:結構最復雜,一般用在單獨存盤資料,實際中使用的鏈表資料結構,都是帶頭雙向回圈鏈表,另外這個結構雖然結構復雜,但是使用代碼實作以后會發現結構會帶來很多優勢,實作反而相對簡單,
本篇博客主要就是對無頭單向非回圈鏈表的詳解,
初始化鏈表
初始化鏈表就是首先定義一個結構體,該結構體包含兩個成員,一個為資料域,用來存盤資料;另一個為指標域,用來保存下一節點的地址,具體如下:
typedef int SLTDataType; //對型別進行重定義,方便后期改變
typedef struct SListNode //對結構體進行重定義,方便使用
{
SLTDataType data; //資料域,用于存盤該節點的資料
struct SListNode* next; //指標域,用來存放下一節點的地址
}SLTNode;
列印單鏈表
即將單鏈表中的每個節點的資料域中的內容列印出來,方便查看其中的內容并除錯,
void SLTPrint(SLTNode* phead)
{
SLTNode* cur = phead; //定義一個標記指標指向頭節點
while (cur!= NULL) //對鏈表遍歷
{
printf("%d->", cur->data);
cur = cur->next; //若節點的指標域不為NULL(即不為尾節點),就將標記指標向前移動一步
}
printf("NULL");
printf("\n");
}
創建新節點
在對鏈表進行操作時(增刪查改),有時會需要一個新節點來完成這些操作,
SLTNode* BuySListNode(SLTDataType x)
{
SLTNode* node = (SLTNode*)malloc(sizeof(SLTNode)); //定義新節點并用malloc開辟空間
if (node == NULL)
{
printf("malloc fail!\n");
exit(-1);
}
node->data = x; //新節點資料域為傳入該函式的引數x
node->next = NULL; //指標域為NULL
}
計算鏈表節點數
對鏈表進行遍歷,定義一變數用來計數,回傳的該變數的值就為節點數,很容易實作:
int SListSize(SLTNode* phead)
{
int size = 0;
SLTNode* cur = phead;
while (cur)
{
size++;
cur = cur->next;
}
return size;
}
單鏈表頭插
即在表頭插入一個新節點,新節點就為表頭
void SListPushFront(SLTNode** pphead, SLTDataType x) //pphead為一個二級指標,該二級指標指向頭節點的地址,所以*pphead就為頭節點的地址
{
assert(pphead);//斷言,若pphead為NULL,則程式會報錯
SLTNode* newnode = BuySListNode(x);//申請一個新節點
newnode->next = *pphead;//使新節點的指標域指向第一個節點(1)
*pphead = newnode;//此時*pphead就為新插入的頭節點的地址(2)
}
注:上述程式中的第(1)步與第(2)步的順序不能顛倒,若顛倒,則原本頭節點的地址就會被覆寫(丟失),而無法使新節點與原頭節點建立起聯系,
單鏈表尾插
即在表尾插入一個節點,新節點就為表尾,若鏈表為空鏈表,則需重新創建一個節點,具體如下:
void SListPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);//斷言
if (*pphead == NULL)//鏈表為空鏈表,則新創建一個節點
{
SLTNode*newnode= BuySListNode(x);
*pphead = newnode;
}
else
{
SLTNode* tail = *pphead;//定義一個標記指標指向頭節點
while (tail->next != NULL)//尋找尾結點
{
tail = tail->next;
}
SLTNode* newnode = BuySListNode(x);//新建一個要插入的節點
tail->next = newnode;//使原表尾的指標域指向新節點
}
}
特定位置插入
特定位置之前插入
給定一個特定的位置(地址),在這個位置前插入給定的值x,圖解如下:
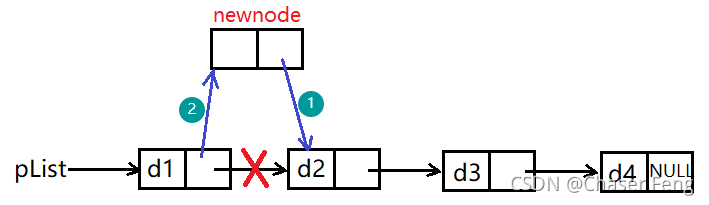
如上圖,若要在d2前插入一個新節點,首先需將新節點的指標域存盤d2的地址,再將d1的指標域指向新節點,具體實作方法如下:
void SListInsert(SLTNode** pphead, SLTNode*pos, SLTDataType x)
{
assert(pphead);
//頭插
if (*pphead == pos) //當表只有一個節點時,可直接復用頭插的方法
{
SListPushFront(pphead,x);
}
else //中間插入
{
SLTNode* prev = *pphead;
while (prev->next != pos) //找到pos的前一個節點
{
prev = prev->next;
}
SLTNode*newnode = BuySListNode(x);
newnode->next = pos;
prev->next = newnode;
}
}
特定位置后插入
同在特定位置前插入的方法一樣,因為給定了位置,又在該位置之后插入,所以實作起來相對簡單,
void SListInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos); //斷言,傳入的位置指標不能為空
SLTNode* newnode = BuySListNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
單鏈表頭刪
即洗掉原先的頭節點,新的頭節點就為原本的第二個節點,
void SListPopFront(SLTNode** pphead)
{
assert(pphead);
if (*pphead == NULL) //若鏈表為空,則直接結束
{
return;
}
SLTNode* Next = (*pphead)->next; //定義一個指標指向第二個節點
free(*pphead); //將原本指向頭節點的指標釋放掉
(*pphead) = Next; //新頭節點指向第二個節點
}
單鏈表尾刪
即洗掉尾節點,當鏈表只有一個節點時,尾刪后就為空鏈表;當鏈表有多個節點時,刪掉尾節點后原鏈表的倒數第二個就變為尾刪后的尾節點,
void SListPopBack(SLTNode** pphead)
{
assert(pphead);
if (*pphead == NULL) //當鏈表為空時,直接結束
{
return;
}
//一個節點
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
//多個節點
else
{
SLTNode* tail = *pphead;
while (tail->next->next != NULL) //通過回圈找到尾節點的前一個節點
{
tail = tail->next;
}
free(tail->next); //釋放掉尾節點
tail->next = NULL; //將新的尾節點的指標域置空
}
}
特定位置洗掉
洗掉特定位置的節點
即使該位置的前一個節點指向該位置的后一個節點,再將該位置的節點釋放即可,例如如下圖洗掉d2節點:

void SListErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);
assert(pos);
if (*pphead == pos) //當鏈表只有一個節點時,直接復用頭刪的方法
{
SListPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos) //定義的prev指標用來找到該位置的前一個節點
{
prev = prev->next;
}
prev->next = pos->next; //pos的前一個節點指向pos的后一個節點
free(pos); //釋放掉pos
pos = NULL;
}
}
洗掉特定位置的后一節點
因為是洗掉該節點的后一個位置,所以不用再找到被洗掉節點的前一個位置,實作起來相對容易:
void SListEraseAfter(SLTNode* pos)
{
assert(pos);
SLTNode* Next = pos->next; //保存給定位置的后一個節點的地址
pos->next = Next->next; //使pos處的節點的指標域指向被洗掉節點的后一個節點的位置
free(Next); //釋放掉被洗掉的節點,防止記憶體泄露
Next = NULL; //置空
}
單鏈表查找
通過遍歷查找到目標節點 x ,并回傳該節點的位置,若未找到則回傳NULL ,實作起來比較容易,
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
else
{
cur = cur->next;
}
}
return NULL;
}
修改鏈表
有手就行的修改操作,將指定位置的節點修改為 x 即可,(因為太簡單,但為了將增、刪、查、改的功能寫完整,索性還是寫一下)
void SListModify(SListNode* pos, SLTDataType x)
{
pos->data = x;//將結點的資料改為目標資料
}
銷毀單鏈表
當使用完單鏈表后,防止記憶體泄露,需要銷毀鏈表,
void SListDestory(SLTNode** pphead)
{
assert(pphead);
SLTNode* cur = *pphead; //定義一個標記指標,用于節點的移動
while (cur)
{
SLTNode* Next = cur->next; //保存被釋放節點的后一個節點的地址,防止節點被釋放后找不到后一節點的地址
free(cur);
cur = Next;
}
*pphead = NULL; //節點釋放完后將指向頭節點的指標置空
}
資料結構單鏈表的內容到此結束,如有講解不當的地方歡迎各位博友指出!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/325588.html
標籤:其他
上一篇:中年大叔蟬聯周榜亞軍!今天告訴你一個小秘技:怎樣用python來獲取各種DOS命令顯示的內容?注意不是回傳值哦!
下一篇:視頻解說:簡易版二分查找