Unsupervised domain adaptation (UDA) for person re-ID.
UDA methods have attracted much attention because their capability of saving the cost of manual annotations. There are three main categories of methods.
UDA方法由于節省了手工標注的花費而吸引了許多關注,這里主要有三種方法:
The first category of clustering-based methods maintains state-of-the-art performance to date
第一類集群時至今日也保持著最優的性能
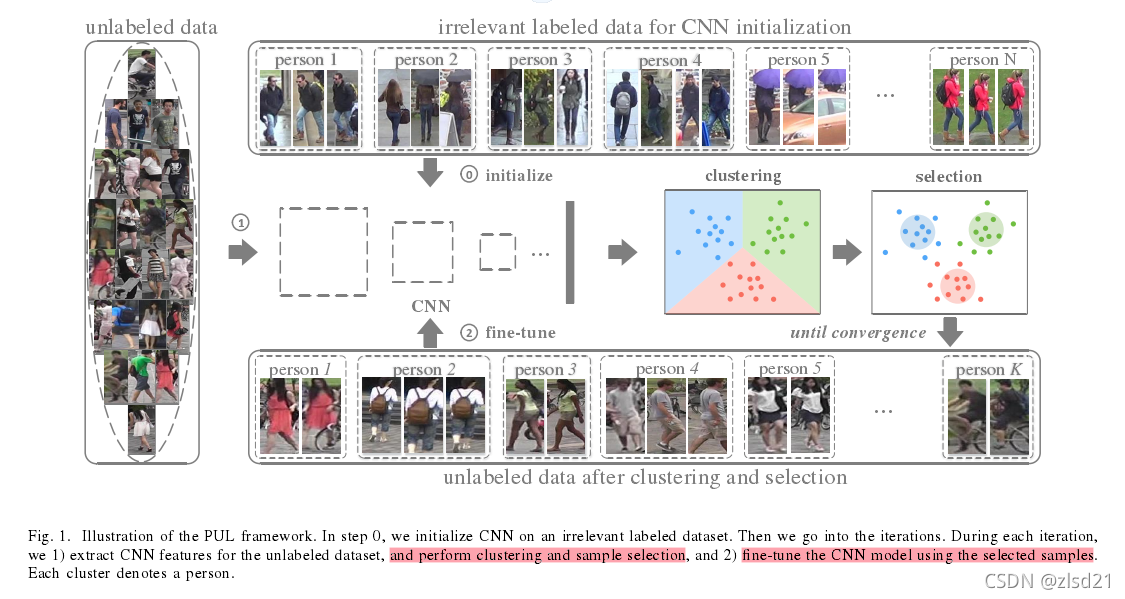
- (Fan et al., 2018) proposed to alternatively assign labels for unlabeled training samples and optimize the network with the generated targets.
原文鏈接:https://arxiv.org/pdf/1705.10444.pdf
提出為未標記的訓練樣本交替分配標簽(fine-tune與clustering交替的程序),并且用生成的目標優化網路,
1.解決的問題:
(1)用無標簽資料(或 其他域有標簽資料及無標簽資料)訓練模型,
(2)把K-means和CNN結合,減輕了cluster太過noisy的問題,
(3)用自步學習更加流暢地完成模型訓練,
2.訓練步驟:
step1: ImageNet上預訓練的ResNet
step2: 用不相關的有標簽資料對網路進行初始化
step3: 將無標簽的資料喂給網路,進行聚類,(聚類到底是怎樣的,如何初始化聚類中心)(覺得這個初始點的選擇應該很重要吧)
step4: 選擇離中心最近的幾個點,加入“可靠訓練集”,訓練集的標簽即為k-means的k,
step5: 將“可靠訓練集”的資料喂給網路再次訓練,因為模型會越來越好,所以接近聚類中心的樣本會隨著epoch增加,即本文的賣點之一,(為避免陷入區域最優,先從“可靠度”最高的樣本訓練起)
step6: 以上3,4,5環節周而復始,直到每次選擇的個數穩定,
本文提出了一個關于self-paced learning(自步學習)方法,我查了一下,覺得這篇博客較為清晰,供大家參考 https://blog.csdn.net/weixin_37805505/article/details/79144854
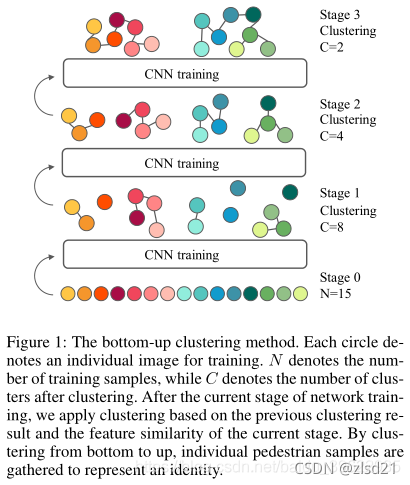
- (Lin et al., 2019) proposed a bottom up clustering framework with a repelled loss.
提出了一種具有排斥損失的自頂向下的聚類框架
文章思想:作者的方法考慮到了行人再識別任務的兩個基本的事實:不同人間的diversity和同一個人間的similarity,作者的演算法最開始把每個人作為單獨的一類,來最大化每類的diversity,然后逐漸的把相似的類合并為同一類,來提升每類的similarity,作者在自底向上的聚類程序中利用了一個多樣性正則項來平和每個cluster的資料量,最終,作者的模型在diversity和similarity之間達到了很好的平衡,
3. (Yang et al., 2019) introduced to assign hard pseudo labels for both global and local features. However, the training of the neural network was substantially hindered by the noise of the hard pseudo labels generated by clustering algorithms, which was mostly ignored by existing methods.
提出用于為全域和區域特征分配的硬偽標簽,然而,現有的聚類演算法大多忽略硬偽標簽的噪聲,嚴重阻礙了神經網路的訓練,
文章思想:兩個資料庫之間,影像風格迥異,如果將影像進行分割,那么每一塊之間的風格差異或許會小一點,這樣,也就學到了魯棒性更強的特征,
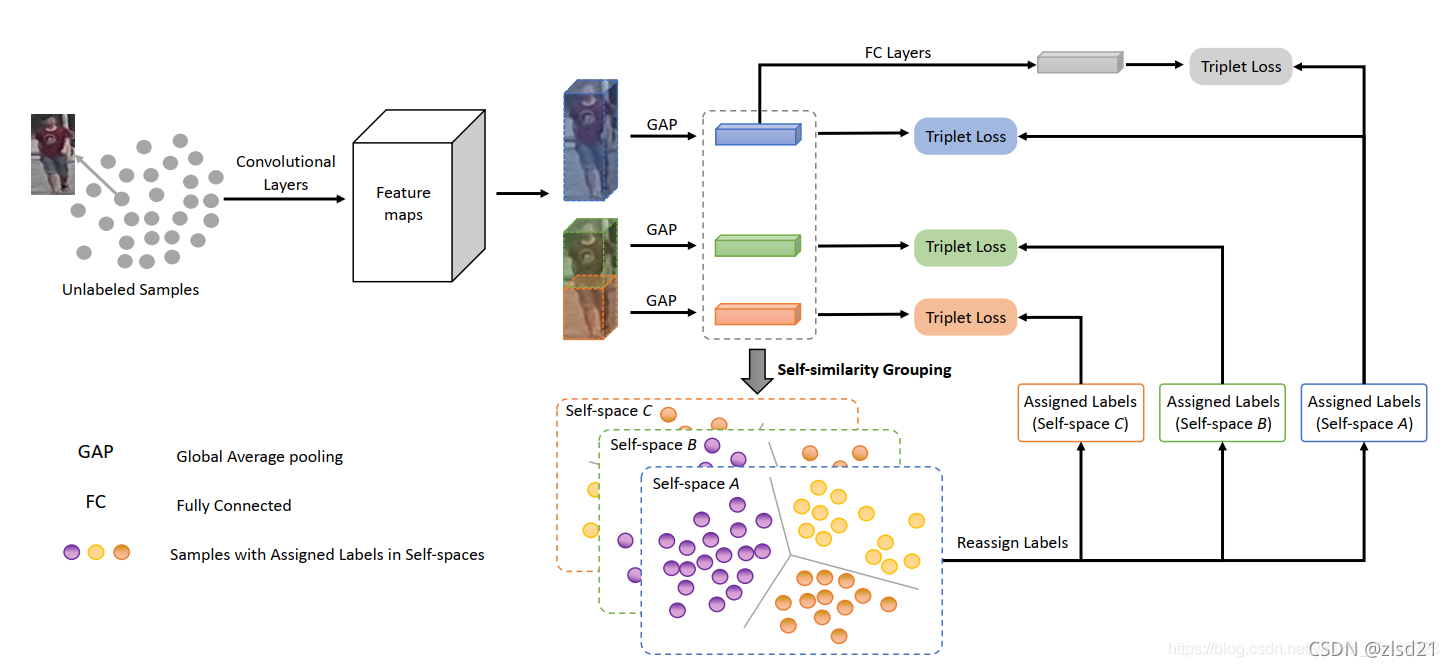
藍色、綠色、紅色分別代表了整個影像,上半影像和下半影像,分別提取出各自的特征向量,灰色的是將三者連接在一起,
對藍色、綠色、紅色三類特征向量分別進行聚類,每一個特征向量就獲得了對應的標簽,灰色的標簽直接和藍色的保持一致,所以,一個人的上半身、下半身、全身對應的標簽可能是不一樣的,這就與開頭的思想相對應,學習的程序中不會拘泥于整個影像的標簽,更具有靈活性,
有了標簽之后,對每一類特征向量分別使用最難三元組損失對模型進行訓練,
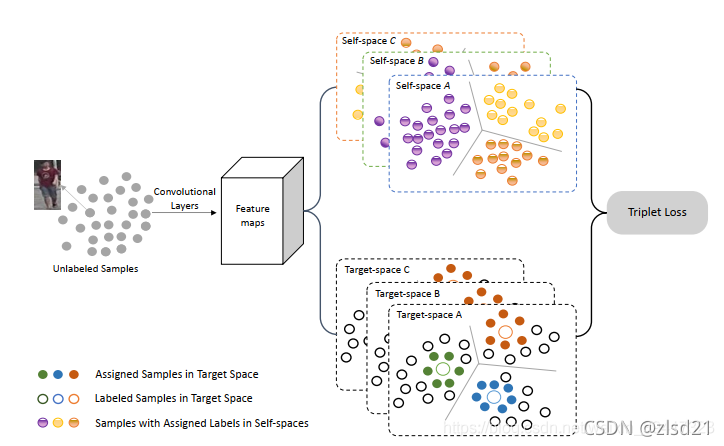
對整張影像的特征向量聚類結束后,總共分為了N類,從每一類中隨機挑選一張影像,共N張,分別提取該影像的全域、上半部分、下半部分的特征向量,作為字典,在采樣的程序中,對被采到的影像提取三類特征向量,每一類分別和上述提到的N張影像對應類別的特征向量比較,距離最小的,就和其保持相同的標簽,在此基礎上,再進行最難三元組損失,
原文鏈接:https://blog.csdn.net/weixin_39417323/article/details/103474275
The second category of methods learns domain-invariant features from style-transferred source-domain images.
第二部分是從style-transferred的源影像學習域不變特征
5. SPGAN (Deng et al., 2018) and PTGAN (Wei et al., 2018) transformed source-domain images to match the image styles of the target domain while maintaining the original person identities. The style-transferred images and their identity labels were then used to fine-tune the model.
轉換源域影像以匹配目標域的影像樣式,同時保持原始的人的身份,然后使用樣式轉換的影像及其身份標簽對模型進行微調,
文章思想:
1.解決domain gap 問題
該文方法是提出一個“learning via translation”framework,使用GAN把source domain的圖片轉換到target domain中,并使用這些translated images訓練ReID model,流程如下圖Figure2,
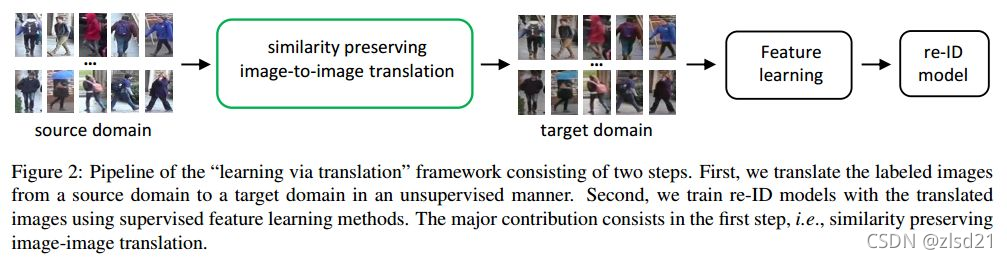
2.解決unsupervised image-image translation程序中,source-domain labels 資訊會丟失
(1)對于每張圖片,ID資訊對于識別有重要意義,需要保留 --> self-similarity,可見下圖Figure1,轉換前后的圖片要盡量相似,
(2)source 和 target domain中包含的人員是沒有overlap的,因此,轉換得到的圖片應該要和target domain的任何一張圖片都不相似–> domain-dissimilarity,
因此,作者提出Similarity Preserving GAN (SPGAN)來實作他的兩個motivation,

6. HHL (Zhong et al., 2018) learned camera-invariant features with
camera style transferred images. However, the retrieval performances of these methods deeply relied on the image generation quality, and they did not explore the complex relations between different samples in the target domain.
HHL (Zhong et al., 2018)學習了相機不變特征相機風格轉移的影像,然而,這些方法的檢索性能很大程度上依賴于影像生成質量,沒有探索目標域中不同樣本之間的復雜關系,
引入了一種Hetero(異質)-Homogeneous(同質) Learning (HHL) 學習方法,考慮兩個屬性:相機不變性,即一張影像遷移到其他相機后ID不變;源域和目標域ID不重疊,因此源域和目標域各選一張影像組成pair必定是負對,前者在目標域操作,為同質;而后者在源域和目標域操作,為異質,
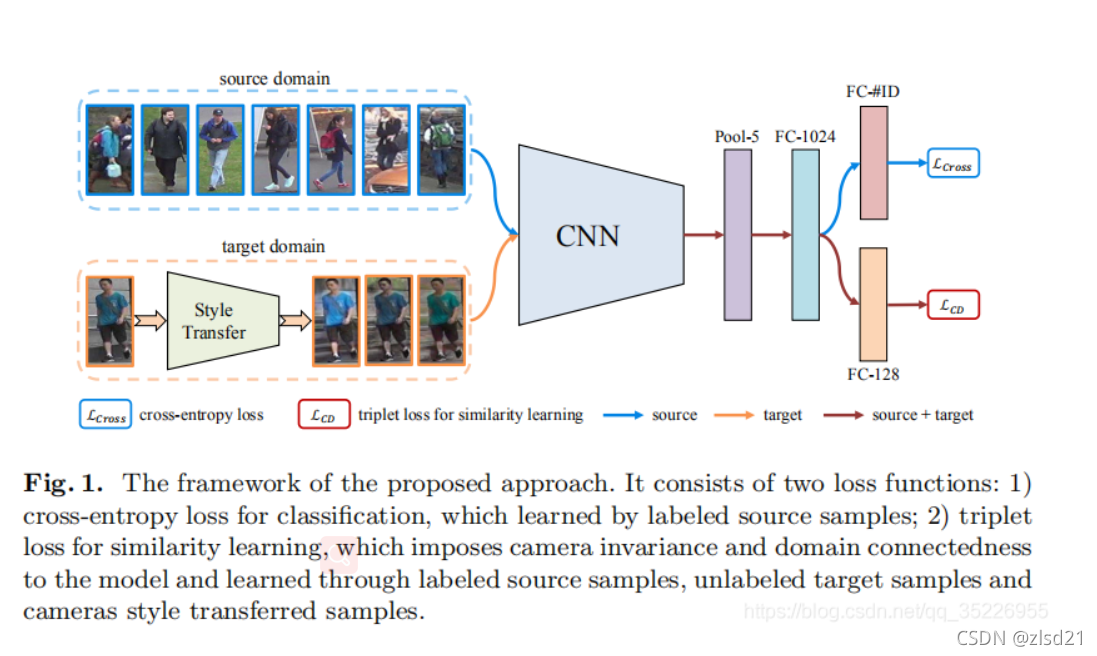
基本思路:利用source domain和target domain進行混合訓練,以domain adaption
a) Target domain利用camStyle進行各個攝像頭的資料增強
b) Source和target經過ResNet50的baseline
c) 輸出有兩個branches:
一個是cross-entropy loss for classification
一個是triplet loss for similarity learning:source的anchor image,利用source label構建正樣本對,然后再選擇target image形成負樣本對,
文章的Hetero-Homogeneous Learning
在訓練階段,每個batch包含了labeled source images,unlabeled real target images以及對應的camStyle生成的fake target images,這樣,前二者是學習兩個domain之間的關系,后兩者學習到了target domain中的camera invariances,
The third category of methods attempts on optimizing the neural networks with soft labels for target-domain samples by computing the similarities with reference images or features.
第三類方法嘗試通過計算與參考影像或特征的相似性來優化目標域樣本的軟標簽神經網路**
(開始提出soft labels的思想)
7. ENC (Zhong et al., 2019) assigned soft labels by saving averaged features with an exemplar memory module.
以存盤器的方式保存平均特征從而獲得軟標簽(這篇文章我會單獨寫一篇總結)
文章名字:Exemplar Memory for Domain Adaptive Person Re-identification
論文連接https://arxiv.org/abs/1904.01990
代碼:https://github.com/zhunzhong07/ECN
8. MAR (Yu et al., 2019) conducted multiple soft-label learning by
comparing with a set of reference persons. However, the reference images and features might not be representative enough to generate accurate labels for achieving advanced performances.
進行多次軟標簽學習與一組參照人比較,然而,參考影像和特征可能沒有足夠的代表性來生成精確的標簽來實作高級性能,(這篇文章我會單獨寫一篇總結)
文章名字:Unsupervised Person Re-identification by Soft Multilabel Learning
原文鏈接:https://arxiv.org/abs/1903.06325
Generic domain adaptation methods for close-set recognition.
Generic domain adaptation methods learn features that can minimize the differences between data distributions of source and target
domains.
- Adversarial learning based methods (Zhang et al., 2018a; Tzeng et al., 2017; Ghifary et al., 2016; Bousmalis et al., 2016; Tzeng et al., 2015) adopted a domain classifier to dispel the discriminative domain information from the learned features in order to reduce the domain gap.
- There also exist methods (Tzeng et al., 2014; Long et al., 2015; Yan et al., 2017; Saito et al., 2018; Ghifary et al., 2016) that minimize the Maximum Mean Discrepancy (MMD) loss between source- and target-domain distributions. However, these methods assume that the classes on different domains are shared, which is not suitable for unsupervised domain adaptation on person re-ID.
Teacher-student models
Teacher-student models have been widely studied in semi-supervised learning methods and knowledge/model distillation methods. The key idea of teacher-student models is to create consistent training supervisions for labeled/unlabeled data via different models’ predictions.
- Temporal ensembling (Laine & Aila, 2016) maintained an exponential moving average prediction for each sample as the supervisions of the unlabeled samples, while the mean-teacher model (Tarvainen & Valpola,2017) averaged model weights at different training iterations to create the supervisions for unlabeled samples.
- Deep mutual learning (Zhang et al., 2018b) adopted a pool of student models instead of the teacher models by training them with supervisions from each other. However, existing methods with teacher-student mechanisms are mostly designed for close-set recognition problems, where both labeled and unlabeled data share the same set of class labels and could not be directly utilized on unsupervised domain adaptation tasks of person re-ID.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/325858.html
標籤:其他