SynFace: Face Recognition with Synthetic Data
該文主要目的是將合成的人臉資料用于人臉識別模型的訓練,指出了用生成影像來訓練無法達到真實圖片效果的原因,并給出了解決方法,文中同時還討論了資料集的深度和廣度對模型性能的影響,并研究了資料中一些屬性如光照、表情、姿勢等對訓練結果的影響,
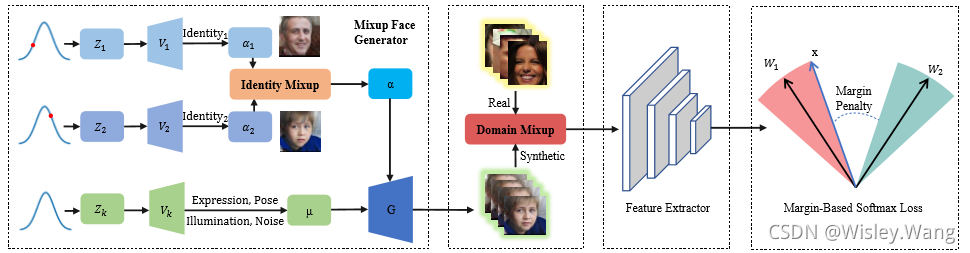
背景
近年來,人臉識別在一系列具有挑戰性的問題上取得了非凡的進展,比如不同年齡匹配、多模態模態,遮擋人臉等問題,在這些發展中,不單單是對網路模型的改進或是對損失的改進,資料集的規模和質量的提升,對人臉識別模型性能提升也同樣有很大的幫助,然而隨著互聯網的發展,資料集的規模不斷擴張的同時,由于噪聲標簽和人臉隱私等問題,使得人臉識別模型的性能很難進一步提升,同時,許多人臉訓練資料集也存在長尾問題,即頭類樣本數多,尾類樣本數少等問題,因此,為了解決人臉資料質量低和涉及隱私等問題,使用合成的人臉資料是一個不錯的選擇和探索,
在本文中,作者的主要作業有如下三個部分:
- 通過一個可控的人臉合成模型(DiscoFaceGAN,并非該文 作業),生成了非真實存在的大規模人臉資料,解決了隱私問題的風險;
- 探討不同人臉資料集屬性的影響,如深度(每個身份的樣本數量)和寬度(身份數量);
- 分析不同面部屬性(如表情、姿勢、光照)的對模型性能的影響
探索分析
作者將DiscoFaceGAN作為基本的生成模型,先與真實資料訓練得到的模型進行對比分析,下圖是分別在真實人臉資料與混合人臉資料上的結果對比,可以看到混合人臉資料訓練的模型無法很好地適應真實的人臉資料集,

進一步作者使用MDS可視化了真實樣本和合成樣本的特征分布結果,明顯合成人臉的類內間距比真實人臉的要小,圖中淺藍色三角、藍色三角、紅色圓圈分別表示了不同精度下的合成人臉特征的類內分布情況,可以看出隨著類內間隔的增大,模型訓練的精度也得到了提升,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-a9peKRmk-1634565647569)(./images/img2.png)]](https://img.uj5u.com/2021/10/20/275949200934063.png)
身份混合
為增大類內間距,受到mixup的啟發,作者提出通過插值兩個不同的身份作為一個新的中間身份,并相應地改變標簽,來擴大階層內的變化,具體來說,生成人臉模型的身份系數空間引入mixup,即Identity Mixup (IM),得到Mixup Face Generator,數學表達如下公式(1):
α
=
φ
?
α
1
+
(
1
?
φ
)
?
α
2
η
=
φ
?
η
1
+
(
1
?
φ
)
?
η
2
(
1
)
\begin{aligned} &\alpha=\varphi \cdot \alpha_{1}+(1-\varphi) \cdot \alpha_{2} \\ &\eta=\varphi \cdot \eta_{1}+(1-\varphi) \cdot \eta_{2} \end{aligned} \qquad(1)
?α=φ?α1?+(1?φ)?α2?η=φ?η1?+(1?φ)?η2??(1)
其中α1、α2為λ空間的兩個隨機恒等系數(詳細需要去了解下 DiscoFaceGAN的輸入),η1、η2為對應的類標,注意,加權比?是從線性空間隨機采樣的,線性空間從0.0到1.0,間隔為0.05(即,np.linspace(0.0, 1.0, 21)),
下圖是權重系數? 從 0 到 1 影像生成變化的程序,可以看到,即便是中間的混合人臉,生成的影像也是蠻逼真的,

領域混合
進一步,為了縮小模型早生成資料與真實資料表現上的差異,作者提出了Domain Mixup(DM)領域混合,具體來說,作者利用一小部分帶有標注的真實資料加上大規模的生成資料,通過DM的方式來訓練模型,DM具體數學表達如公式2,X_s與X_R分別代表生成和真實的人臉圖片,相應的其標簽也隨之線性改變,
X
=
ψ
?
X
S
+
(
1
?
ψ
)
?
X
R
Y
=
ψ
?
Y
S
+
(
1
?
ψ
)
?
Y
R
(
2
)
\begin{aligned} &X=\psi \cdot X_{S}+(1-\psi) \cdot X_{R} \\ &Y=\psi \cdot Y_{S}+(1-\psi) \cdot Y_{R} \end{aligned} \qquad (2)
?X=ψ?XS?+(1?ψ)?XR?Y=ψ?YS?+(1?ψ)?YR??(2)
同時為探索資料集的深度(每個身份的樣本數量)和寬度(身份數量,作者也對比了不同身份數量與每個身份下圖片數量的資料集訓練效果,其中,“Mix N S”表示N個真實身份的混合,每個身份S個樣本,Syn合成資料為10K個身份,每個身份50張人臉圖片,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-QB21OzVv-1634565647575)(./images/img6.png)]](https://img.uj5u.com/2021/10/20/275949200934065.png)
深度與廣度探索
進一步為了探索生成資料集的寬度(即類別數量)和深度(即類內樣本數量) 對識別準確率的影響,作者在LFW資料集上做了一些消融實驗,如下圖所示, 可以看到隨著深度和寬度的增加,準確率都是逐步上升的,但是深度在達到20之后,準確率就開始逐漸飽和,通過觀察(a)(e)可以看到,它們具有相同數量的總樣本(50K),但是(a)極大地超過了(e),差距為4.37,說明了寬度相比深度承擔了更重要的角色,另外通過引入Identity Mixup (IM),所有結果都得到了很大地提升,再次說明了IM的有效性,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-efF86gDM-1634565647576)(./images/img8.png)]](https://img.uj5u.com/2021/10/20/275949200934066.png)
屬性分析
作者后續還研究了不同人臉屬性變化對訓練的影響,通過保持其他特性不變,只改變當前探索的特性來研究單一屬性變化的作用,
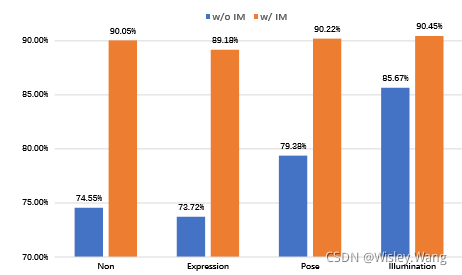
可以看到不變(Non)和只變表情取得了最差的結果,這是因為這里生成的表情種類十分有限,基本上是微笑,故而可以等價成什么都不變,改變姿態和光照取得了巨大提升,這可能是因為測驗資料集中的姿態和光照變化非常大的緣故,同樣地,引入IM帶來了穩定的提升,并且都達到了相似的準確率,潛在的原因是IM可以被視作為一種很強的資料增強,減少了各個特性對最終準確率的影響,
總結
- 研究分析造成合成人臉資料訓練表現不佳的具體原因,
- 提出了Identity Mixup (IM)與Domain Mixup(DM)來增大類內間隔和縮小領域間隔,通過實驗證明了其有效性,
- 探索了不同深度和廣度的資料集對結果的影響,當深度達到一定程度后,逐漸達到飽和,而提升資料寬度可以使得模型表現進一步提升,
- 研究了不同屬性的影響,其中光照和姿態有較大的影響,通過IM方法同能消除這些影響,
利用合成人臉資料可以解決人臉隱私和噪聲的問題,通過作者提出的方法混合方法,讓合成人臉資料達到甚至超越了原始真實人臉訓練的效果,最后還揭示了訓練資料集的深度與寬度對于最終識別率的影響,并對比了幾種屬性的影響,
思考
1、實驗精度是否非常依賴于生成模型,作者的作業更像是DiscoFaceGAN的應用,算是錦上添花的作業,
2、GAN網路一搬都比較難訓練,使用的資料集是否對最后用來訓練的模型影響比較大?
3、跨領域的融合是在像素級別上進行的(總感覺非常怪),是否要考慮人臉對齊的問題,定點融合是否需要?
后續筆者研究下DiscoFaceGAN的相關作業和實驗效果,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/325861.html
標籤:其他
上一篇:【PyTorch基礎教程12】影像多分類問題(學不會來打我啊)
下一篇:怎么快速上手python機器學習,OpenCV、OpenGL、Pandas、Matplotlib、scikit—learn五大工具庫的參考手冊