我從 URL 讀取了一個 excel 檔案,需要進行一些清理才能保存它。在原始的excel檔案中,前幾行有一些標志和空條目,然后才是真正的資料。Excel 檔案中的列日期(未命名 0:) 顯示為日期,但是當由于某種原因讀入 Pandas 時,它被轉換為數字。使用 astype 和 pd.to_datetime 將列轉換為日期但不正確的日期。有什么建議嗎?
注意:雖然日期列在excel表格中顯示為日期,但其型別是通用的。我可以先在 excel 檔案中手動更改型別,但我不想這樣做,因為我想自動化該程序。
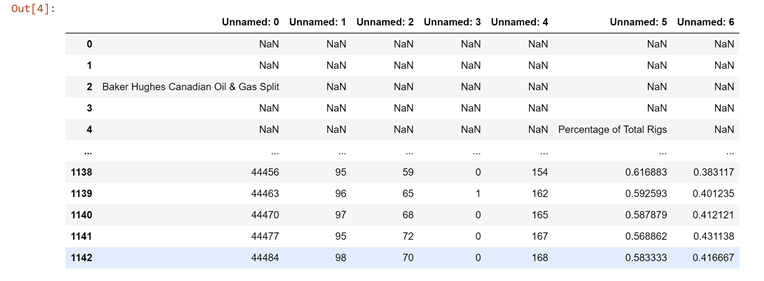
如果你想產生資料,這里是代碼:
from requests import get
import pandas as pd
url = 'http://rigcount.bakerhughes.com/static-files/55ff50da-ac65-410d-924c-fe45b23db298'
# make HTTP request to fetch data
r = get(url)
# check if request is success
r.raise_for_status()
# write out byte content to file
with open('out.xlsb', 'wb') as out_file:
out_file.write(r.content)
Canada_Oil_Gas = pd.read_excel('out.xlsb', sheet_name='Canada Oil & Gas Split', engine='pyxlsb')
uj5u.com熱心網友回復:
問題是由單元格格式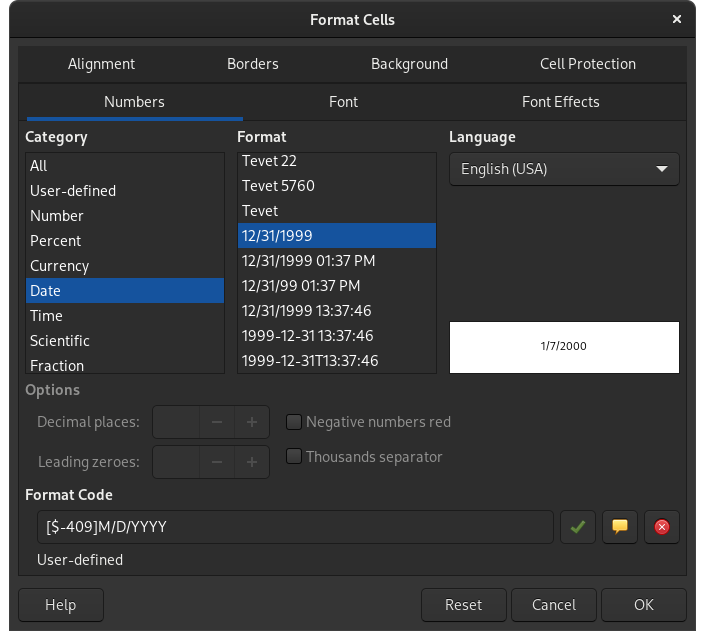
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/326217.html