目錄
- import
- 傳統關系型資料到匯入到HDFS
- 注意事項
- 傳統關系型資料到匯入到HIVE
- 提升關系型資料庫匯入到HIVE的執行效率
- 傳統關系型資料到匯入到HBASE
- export
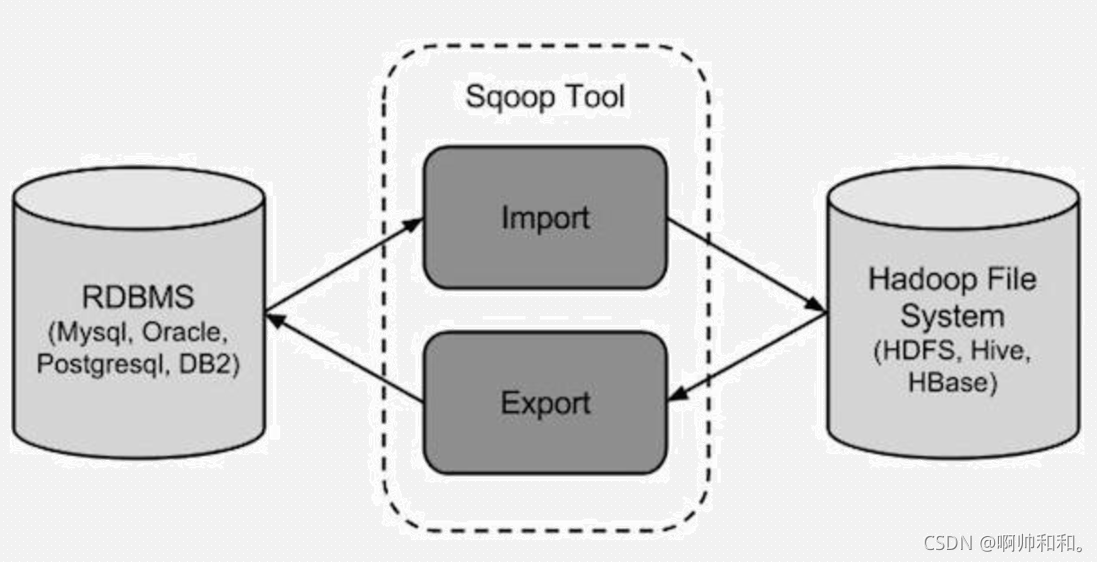
sqoop是一種資料集成工具,主要負責異構資料源的互相匯入,也就是
可以將關系型資料庫的資料(比如MySQL的資料)匯入HDFS中,或者從HDFS中匯入到關系型資料庫中
但是不能自己匯入自己,也就是說,不能自己從MySQL匯入到MySQL,不能從HDFS匯入到HDFS
import
從傳統關系型資料庫匯入到HDFS、HIVE、HBASE…
傳統關系型資料到匯入到HDFS
撰寫腳本:
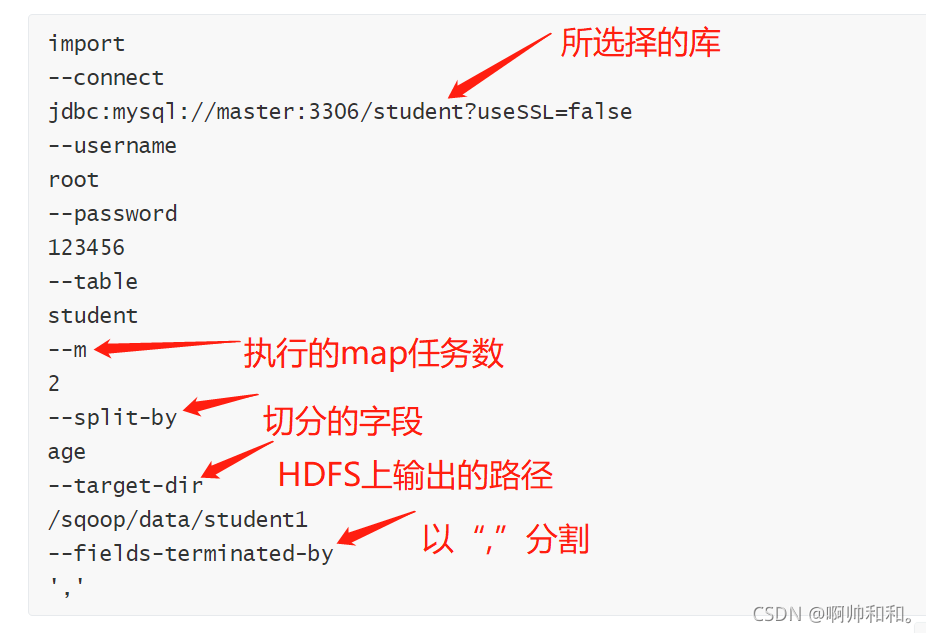
執行腳本:
sqoop --options-file /opt/datas/sql/MYSQLtoHDFS.conf
執行成功
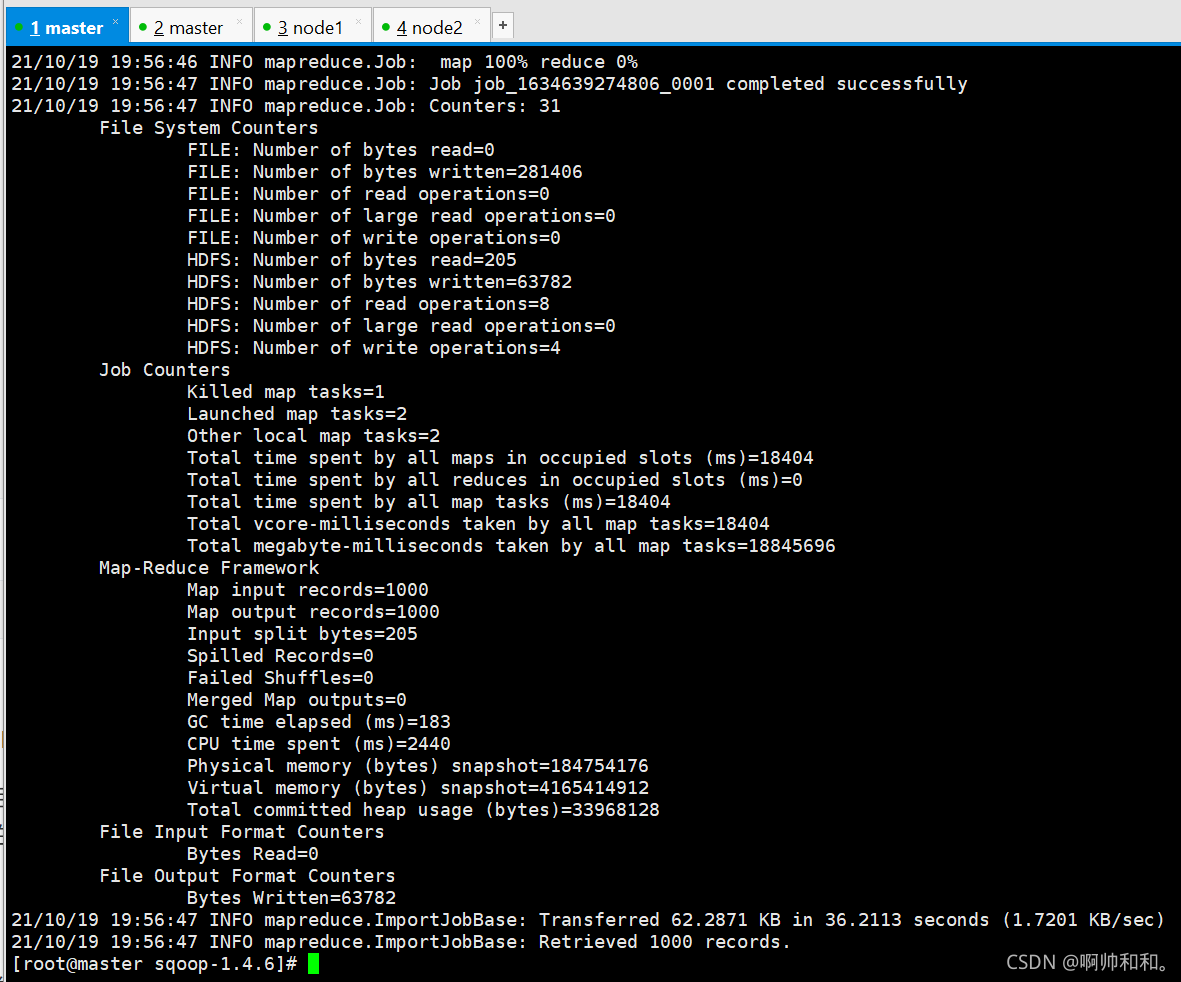
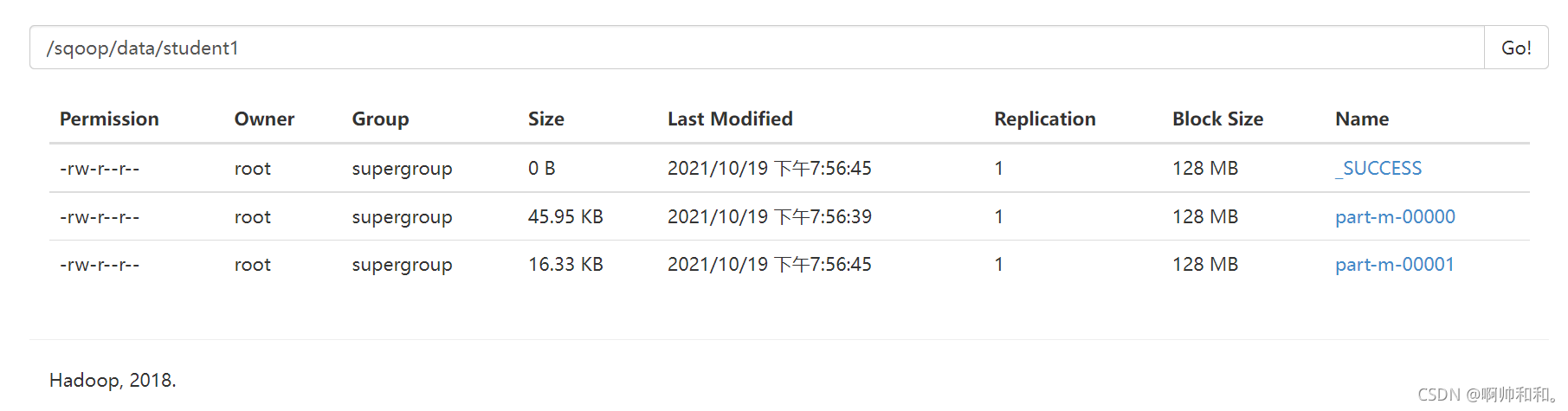
以age作為分割,并且設定了map的任務數為2之后,得到了兩個檔案(這里可以看到名字為part-m-00000和part-m-00001,其中的m指的是map)
注意事項
注意事項:
1、–m 表示指定生成多少個Map任務,不是越多越好,因為MySQL Server的承載能力有限
2、當指定的Map任務數>1,那么需要結合--split-by引數,指定分割鍵,以確定每個map任務到底讀取哪一部分資料,最好指定數值型的列,最好指定主鍵(或者分布均勻的列=>避免每個map任務處理的資料量差別過大)
3、如果指定的分割鍵資料分布不均,可能導致資料傾斜問題
4、分割的鍵最好指定數值型的,而且欄位的型別為int、bigint這樣的數值型
5、撰寫腳本的時候,注意:例如:--username引數,引數值不能和引數名同一行
–username root // 錯誤的
// 應該分成兩行
–username
root
6、實際上sqoop在讀取mysql資料的時候,用的是JDBC的方式,所以當資料量大的時候,效率不是很高
7、sqoop底層通過MapReduce完成資料匯入匯出,只需要Map任務,不需要Reduce任務
8、每個Map任務會生成一個檔案
傳統關系型資料到匯入到HIVE
撰寫腳本
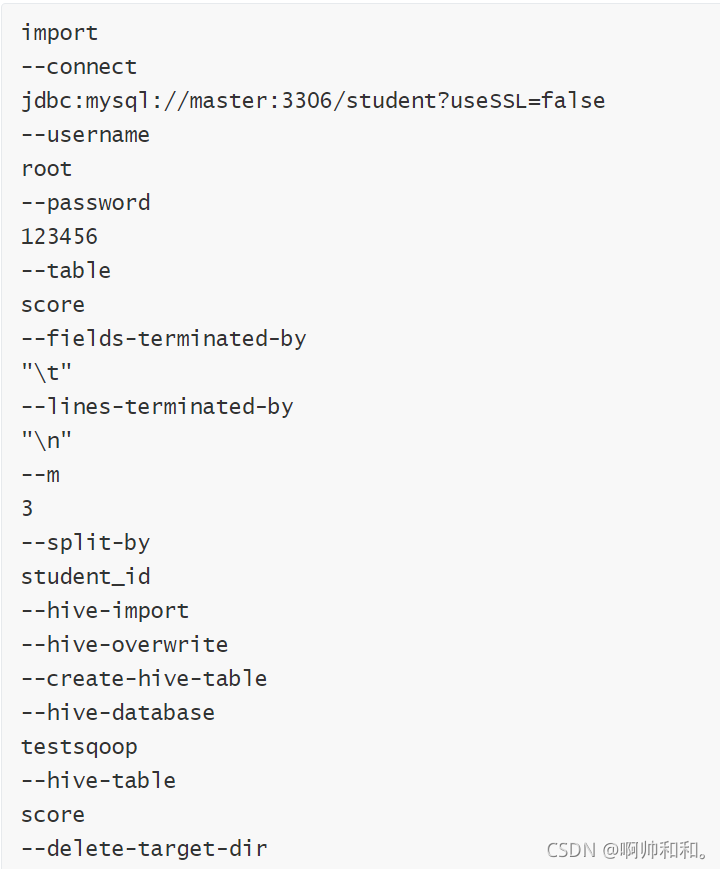
在hive中創建testsqoop庫

將HADOOP_CLASSPATH加入到環境變數(/etc/profile)中
export HADOOP_CLASSPATH=$HADOOP_HOME/lib:$HIVE_HOME/lib/*
將hive-site.xml放入SQOOP_HOME/conf/
cp /opt/modules/hive-1.2.1/conf/hive-site.xml /opt/modules/sqoop-1.4.6/conf/
在創建腳本的執行路徑下執行腳本
sqoop --options-file MySQLToHIVE.conf
執行成功
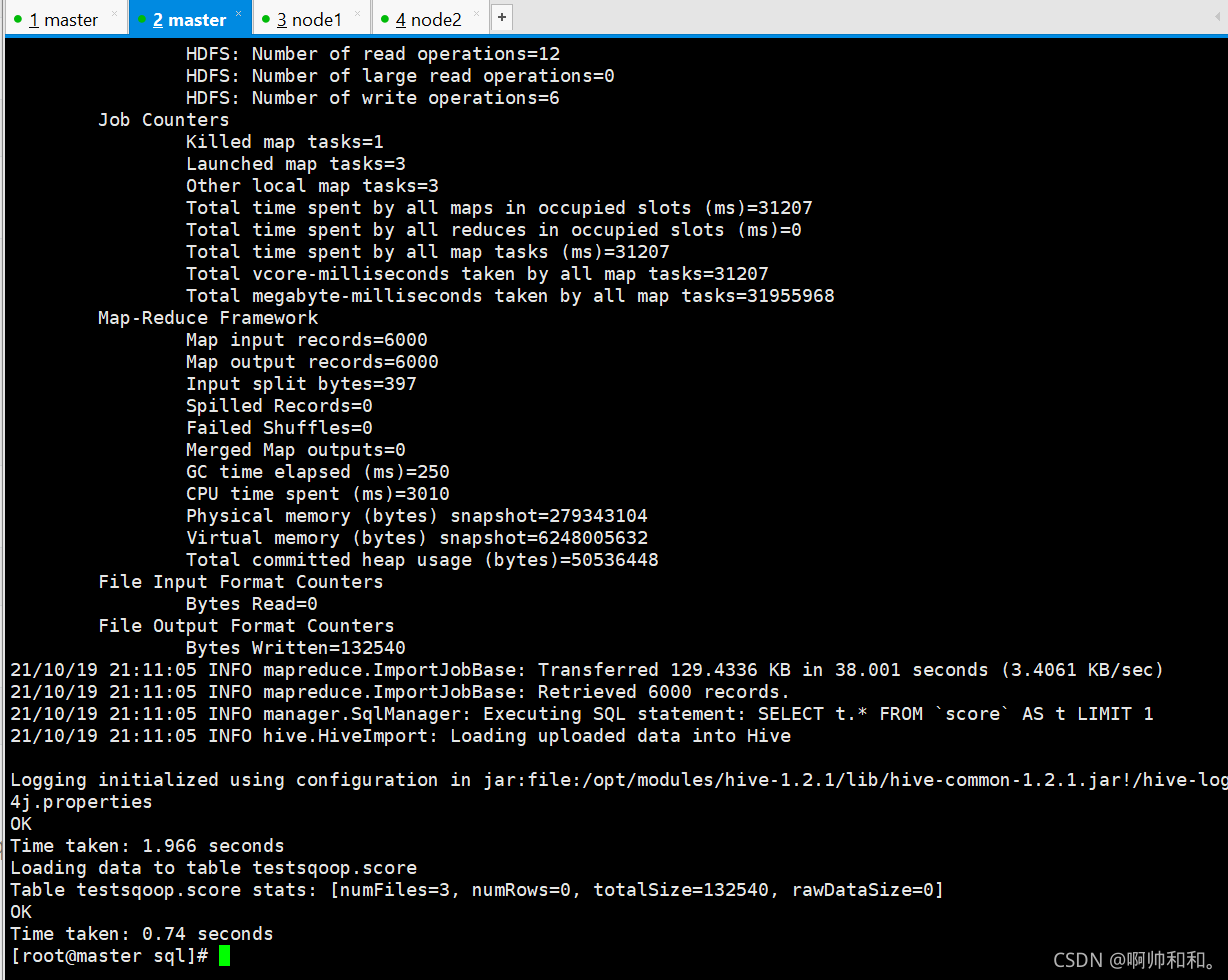
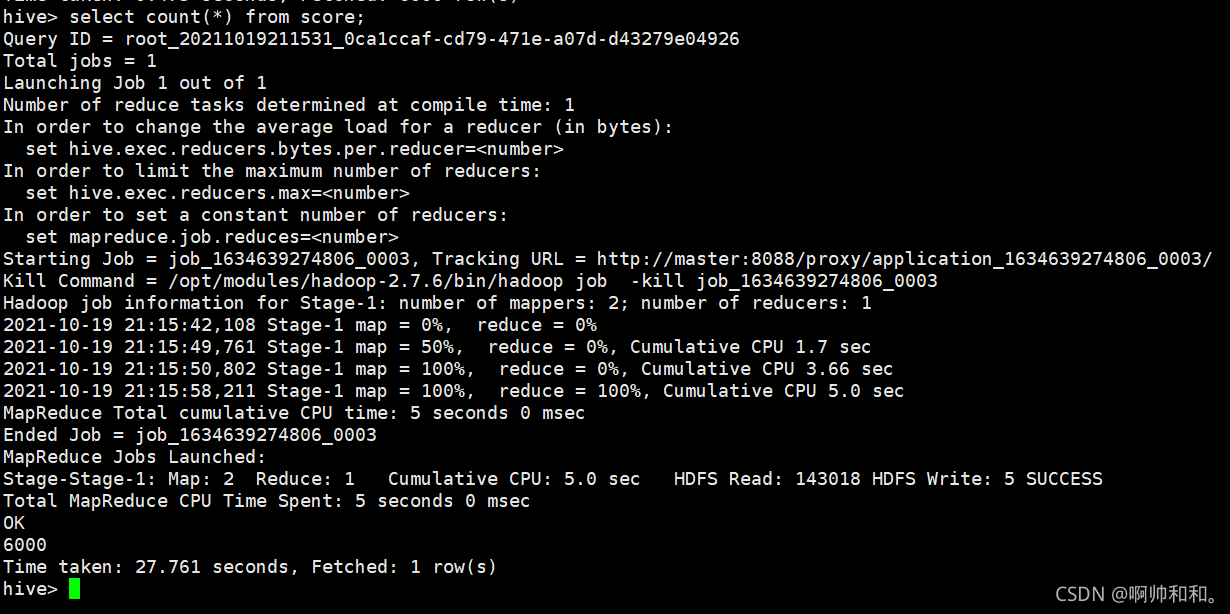
提升關系型資料庫匯入到HIVE的執行效率
-direct
加上這個引數,可以在匯出MySQL資料的時候,使用MySQL提供的匯出工具mysqldump,加快匯出速度,提高效率
需要將master上的/usr/bin/mysqldump分發至 node1、node2的/usr/bin目錄下
scp /usr/bin/mysqldump node1:/usr/bin/
scp /usr/bin/mysqldump node2:/usr/bin/
-e引數的使用
傳統關系型資料到匯入到HBASE
撰寫腳本

hbase中創建student表
create ‘student’,‘cf1’
執行腳本
sqoop --options-file MYSQLtoHBase.conf
執行成功
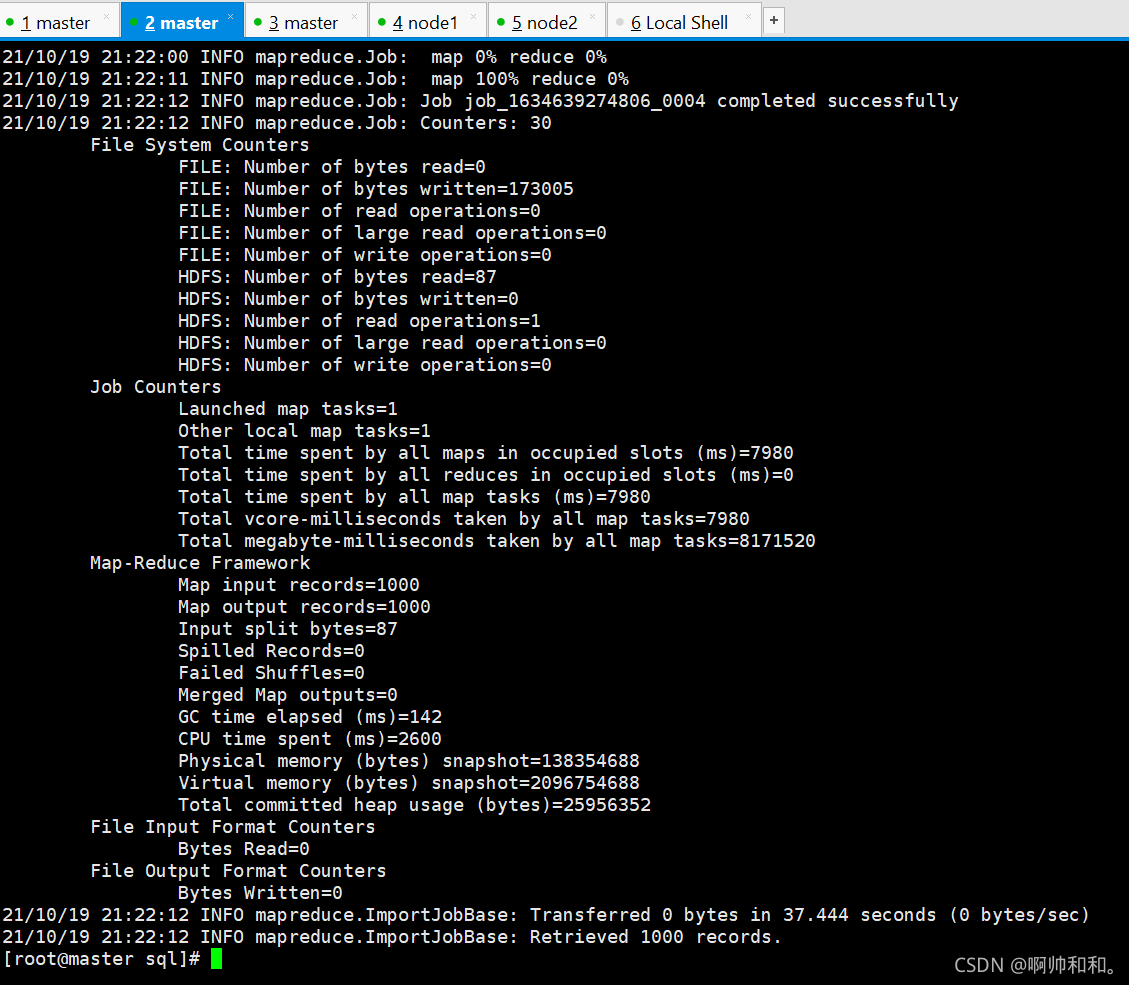
hbase中資料匯入成功
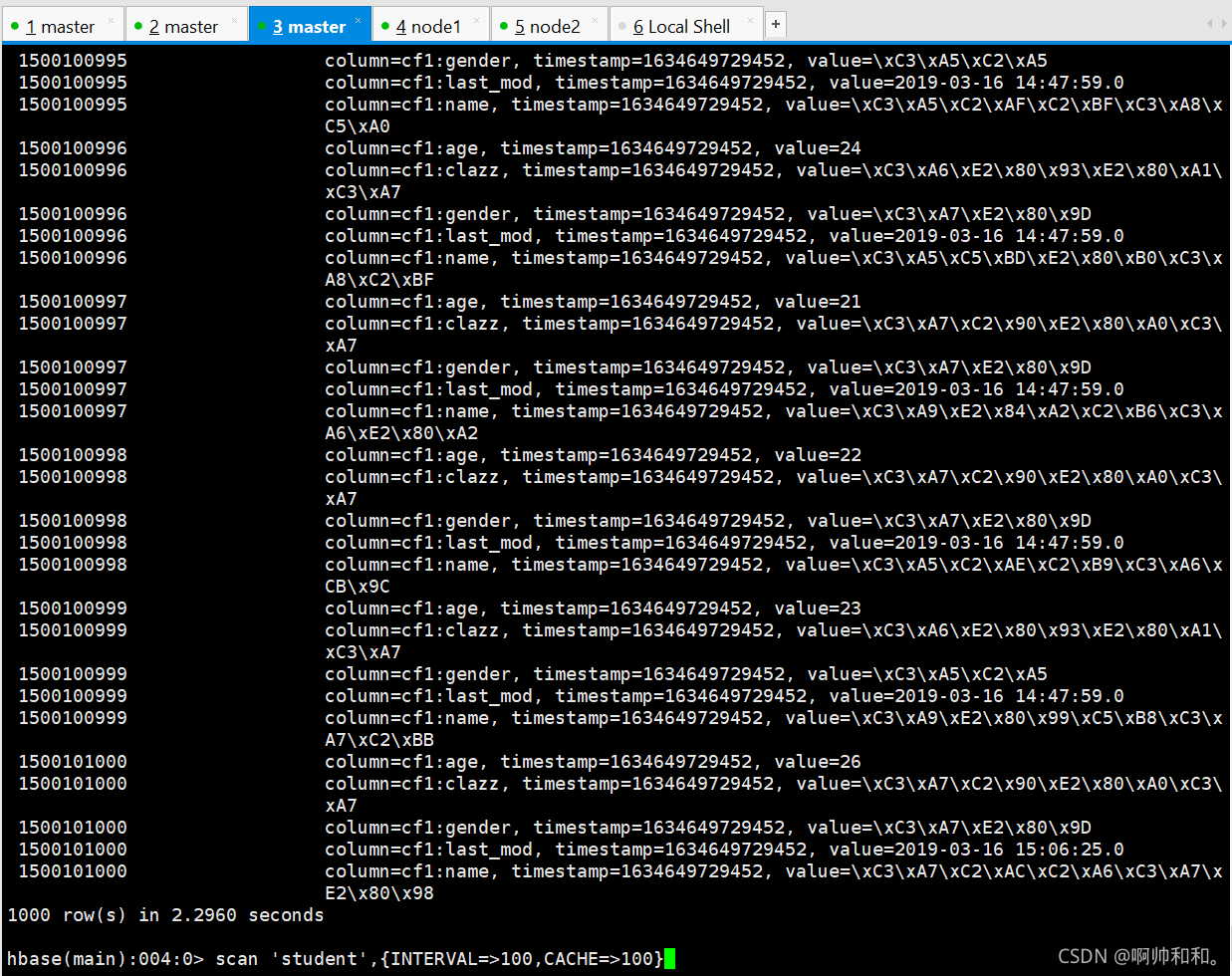
export
將HDFS中的資料匯入到MYSQL
撰寫腳本
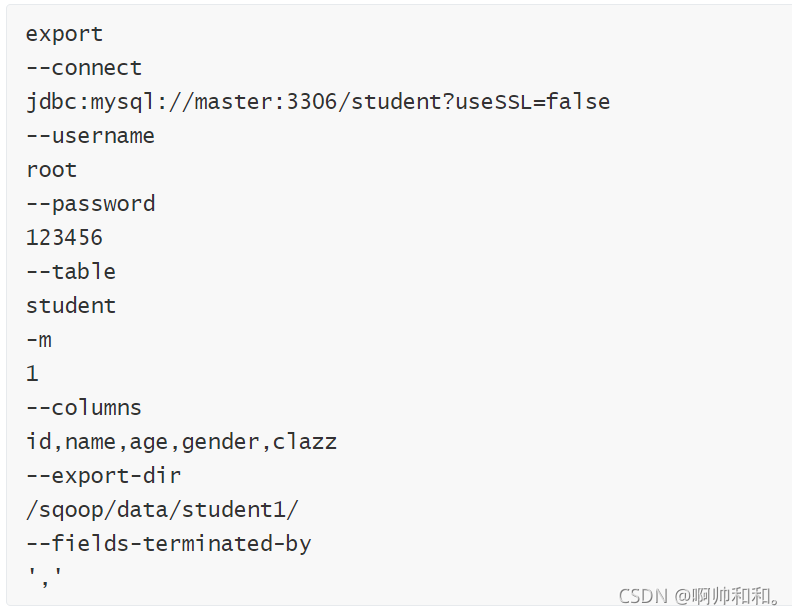
清空MySQL中student表中的資料
執行腳本
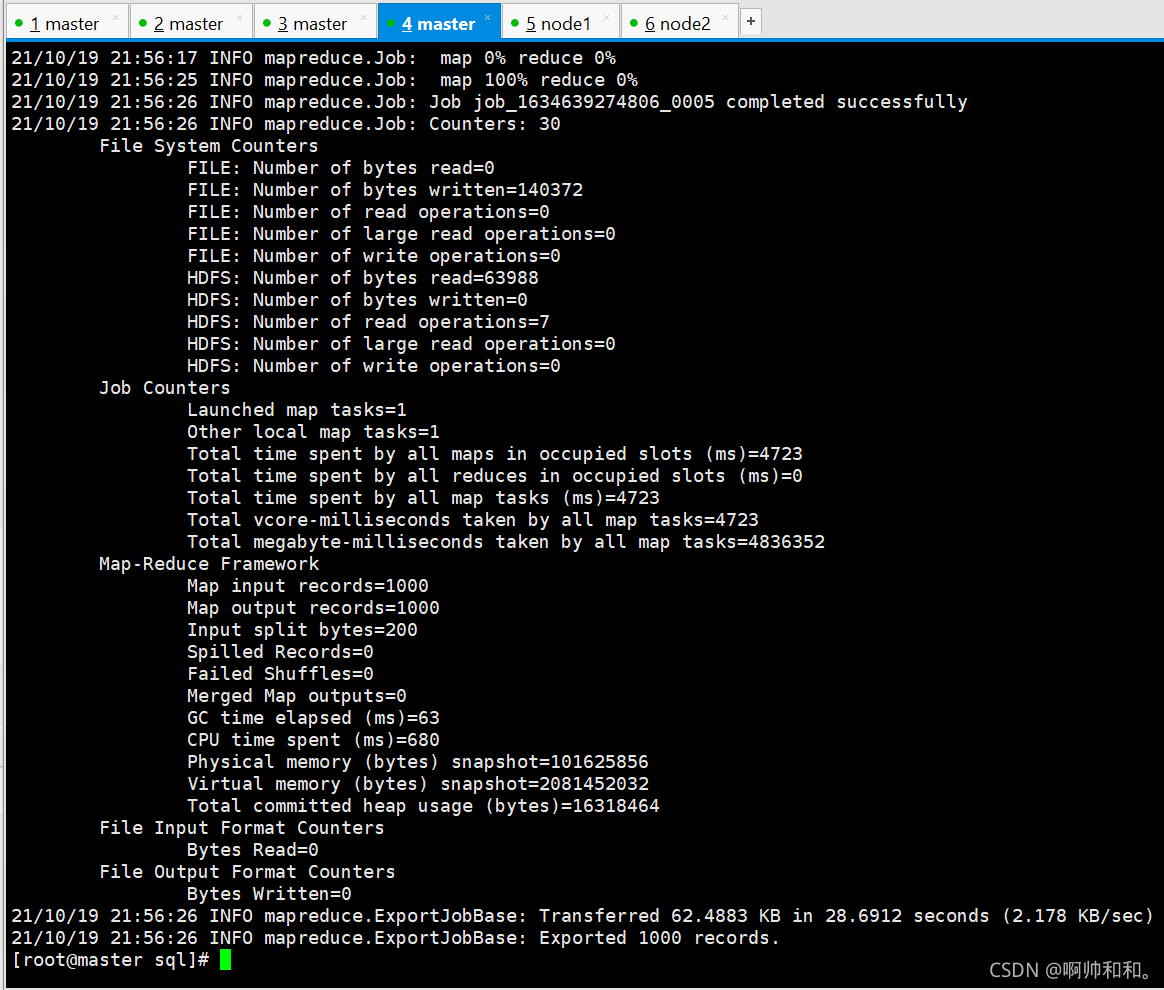
sqoop --options-file HDFSToMySQL.conf
執行成功
感謝閱讀,我是啊帥和和,一位大資料專業大四學生,祝你快樂,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/327921.html
標籤:其他