The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation
在本文中擴充了DenseNets,以解決語意分割的問題,在城市場景基準資料集(CamVid和Gatech)上獲得了最優異的結果,沒有使用進一步的后處理模塊(如CRF)和預訓練模型,此外,由于模型的優異結構,這個方根比當前發布在這些資料集上取得了最佳的網路引數要少得多,
DenseNets背后的思想是讓每一層以一種前饋的方式與所有層相連接,能夠讓網路更容易訓練,更加準確,
主要貢獻在:
- 針對語意分割任務,將DenseNets的結構擴展到了全卷積網路中;
- 提出密集網路中進行上采樣路徑的方式,這要比其他的上采樣路徑性能更好,
- 證明了網路能夠在標準的基準測驗資料集上產生較好的效果,
https://arxiv.org/abs/1611.09326
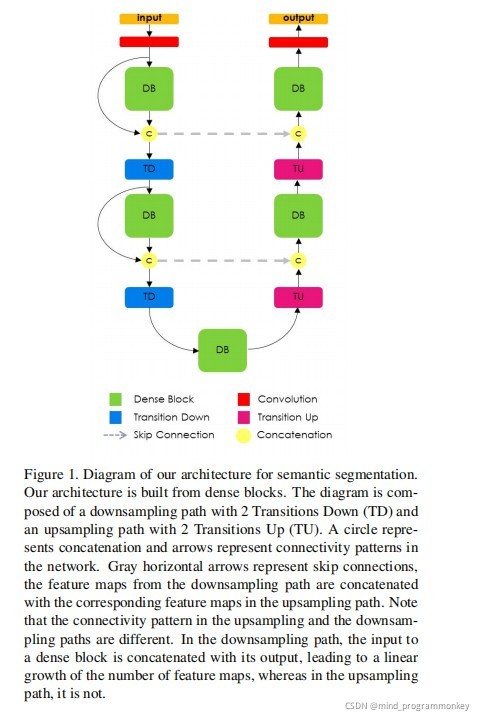
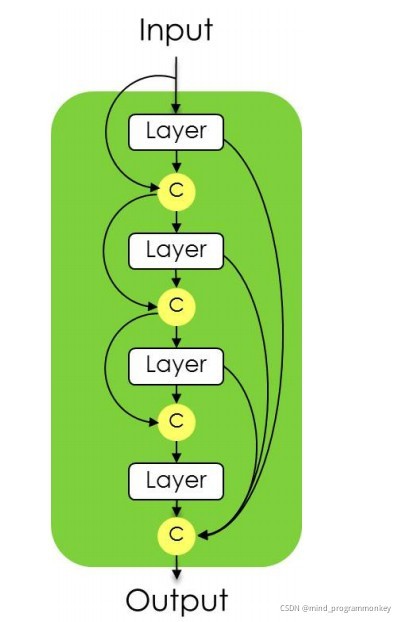
-
DenseBlock: BatchNormalization + Activation [ Relu ] + Convolution2D + Dropout
-
TransitionDown: BatchNormalization + Activation [ Relu ] + Convolution2D + Dropout + MaxPooling2D
-
TransitionUp: Deconvolution2D (Convolutions Transposed)

論文架構:
-
Abstract
一個典型的影像分割模型的結構是:一個下采樣的模塊用來提取粗糙的語意資訊;之后一個經過訓練的上采樣模型來恢復影像的尺寸;最后一個后處理單元來精修模型預測,發現了一個新的網路架構DenseNet
將DenseNets擴展到語意分割上
-
Introduction
FCN為了補償池化層造成的損失,FCN引進了skip connections跳躍連接結構,在下采樣和上采樣之間的路徑中,這種結構有利于增加準確率以及幫助快速訓練優化,
DenseNet:parameter efficiency;implicit deep supervision;feature reuse;以便skip connections 和 multi-scale supervision
論文主要貢獻:將DenseNet網路架構引入到了FCN當中,并緩解了特征圖探索,也就是只使用前幾層;提出基于dense blocks的上采樣路徑;在幾個資料集達到最先進,
-
Related Work
主要改進的措施:改進上采樣的路徑(從簡單的雙線性插值 - > unpooling or transposed connvolutions -> skip connections);
引進廣泛的語意理解;擴張卷積;RNNS;無監督的全域影像描述符;提出一個基于擴張卷積的語意模塊來擴大網路呃感受野
賦予FCN結構化的能力:增加一個CRF模塊(Conditional Random Fields)
-
Fully Convolutional DenseNets
a down sampling path;an upsampling path;skip connections;
跳過連接通過重用特征映射幫助上采樣路徑從下采樣路徑恢復空間詳細資訊,
我們模型的目標是通過擴展更復雜的DenseNet體系結構來進一步利用特征重用,同時避免網路上采樣路徑上的特征爆炸,DenseNetss回顧;DenseNets到FCNS中;語意分割;
-
Experiments
兩個基準資料集;IOU;訓練細節:HeUniform和RMSprop;
兩個資料集;
-
Conclusion
公式

代碼
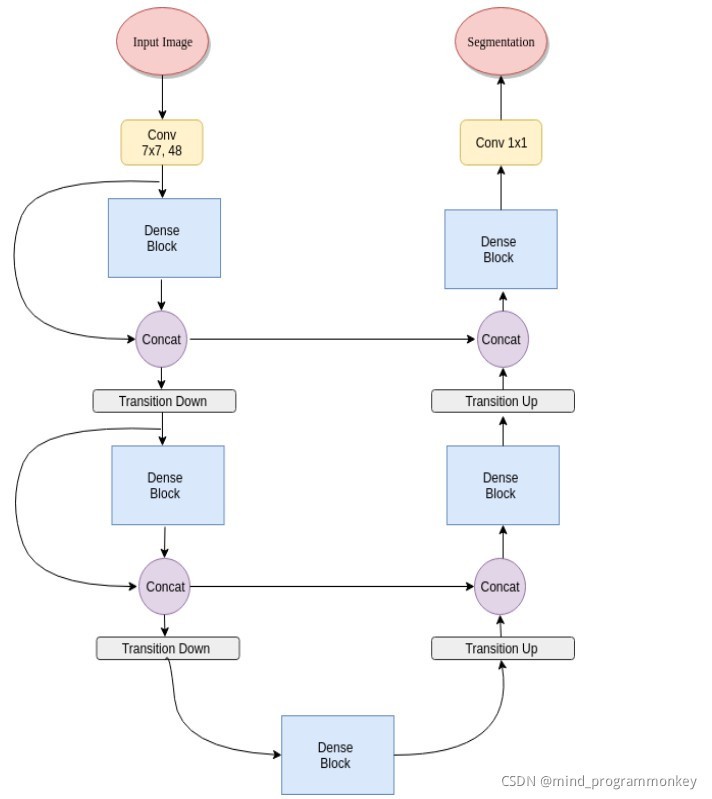
模塊化
from keras.layers import Activation,Conv2D,MaxPooling2D,UpSampling2D,Dense,BatchNormalization,Input,Reshape,multiply,add,Dropout,AveragePooling2D,GlobalAveragePooling2D,concatenate
from keras.layers.convolutional import Conv2DTranspose
from keras.models import Model
import keras.backend as K
from keras.regularizers import l2
from keras.engine import Layer,InputSpec
from keras.utils import conv_utils
def BN_ReLU_Conv(inputs, n_filters, filter_size=3, dropout_p=0.2):
'''Apply successivly BatchNormalization, ReLu nonlinearity, Convolution and Dropout (if dropout_p > 0)'''
l = BatchNormalization()(inputs)
l = Activation('relu')(l)
l = Conv2D(n_filters, filter_size, padding='same', kernel_initializer='he_uniform')(l)
if dropout_p != 0.0:
l = Dropout(dropout_p)(l)
return l
def TransitionDown(inputs, n_filters, dropout_p=0.2):
""" Apply first a BN_ReLu_conv layer with filter size = 1, and a max pooling with a factor 2 """
l = BN_ReLU_Conv(inputs, n_filters, filter_size=1, dropout_p=dropout_p)
l = MaxPooling2D((2,2))(l)
return l
def TransitionUp(skip_connection, block_to_upsample, n_filters_keep):
'''Performs upsampling on block_to_upsample by a factor 2 and concatenates it with the skip_connection'''
#Upsample and concatenate with skip connection
l = Conv2DTranspose(n_filters_keep, kernel_size=3, strides=2, padding='same', kernel_initializer='he_uniform')(block_to_upsample)
l = concatenate([l, skip_connection], axis=-1)
return l
def SoftmaxLayer(inputs, n_classes):
"""
Performs 1x1 convolution followed by softmax nonlinearity
The output will have the shape (batch_size * n_rows * n_cols, n_classes)
"""
l = Conv2D(n_classes, kernel_size=1, padding='same', kernel_initializer='he_uniform')(inputs)
l = Reshape((-1, n_classes))(l)
l = Activation('softmax')(l)#or softmax for multi-class
return l
Using TensorFlow backend.
FC_DenseNet
def FC_DenseNet(
input_shape=(None, None, 3),
n_classes=1,
n_filters_first_conv=48,
n_pool=5,
growth_rate=16,
n_layers_per_block=[4, 5, 7, 10, 12, 15, 12, 10, 7, 5, 4],
dropout_p=0.2
):
if type(n_layers_per_block) == list:
print(len(n_layers_per_block))
elif type(n_layers_per_block) == int:
n_layers_per_block = [n_layers_per_block] * (2 * n_pool + 1)
else:
raise ValueError
#####################
# First Convolution #
#####################
inputs = Input(shape=input_shape)
stack = Conv2D(filters=n_filters_first_conv, kernel_size=3, padding='same', kernel_initializer='he_uniform')(inputs)
n_filters = n_filters_first_conv
#####################
# Downsampling path #
#####################
skip_connection_list = []
for i in range(n_pool):
for j in range(n_layers_per_block[i]):
l = BN_ReLU_Conv(stack, growth_rate, dropout_p=dropout_p)
stack = concatenate([stack, l])
n_filters += growth_rate
skip_connection_list.append(stack)
stack = TransitionDown(stack, n_filters, dropout_p)
skip_connection_list = skip_connection_list[::-1]
#####################
# Bottleneck #
#####################
block_to_upsample = []
for j in range(n_layers_per_block[n_pool]):
l = BN_ReLU_Conv(stack, growth_rate, dropout_p=dropout_p)
block_to_upsample.append(l)
stack = concatenate([stack, l])
block_to_upsample = concatenate(block_to_upsample)
#####################
# Upsampling path #
#####################
for i in range(n_pool):
n_filters_keep = growth_rate * n_layers_per_block[n_pool + i]
stack = TransitionUp(skip_connection_list[i], block_to_upsample, n_filters_keep)
block_to_upsample = []
for j in range(n_layers_per_block[n_pool + i + 1]):
l = BN_ReLU_Conv(stack, growth_rate, dropout_p=dropout_p)
block_to_upsample.append(l)
stack = concatenate([stack, l])
block_to_upsample = concatenate(block_to_upsample)
#####################
# Softmax #
#####################
output = SoftmaxLayer(stack, n_classes)
model = Model(inputs=inputs, outputs=output)
return model
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/328224.html
標籤:其他