一、概述
Hadoop的HA應該分為HDFS 的 HA 和 YARN 的 HA,主要是解決NameNode和ResourceManager的單點故障問題,所以HA就是通過配置 Active/Standby 兩個 實體來解決單點故障
二、HDFS-HA 作業機制
2.1HDFS-HA 作業要點
(1)元資料管理方式改變
兩個NameNode記憶體中各自保存一份元資料,Edits 日志只有 Active 狀態的 NameNode 節點可以做寫操作, 兩個 NameNode 都可以讀取 Edits,共享的 Edits 放在一個共享存盤中JounalNode
(2) 增加一個狀態管理功能模塊
Zkfailover(hadoop的模塊),常駐在每一個 namenode 所在的節點,每一個 zkfailover 負責監控自己所在 NameNode 節點,和ZooKeeper通信利用 zk 進行狀態標識,當需要進行狀態切換時,由 zkfailover 來負責切換,切換時需要防止 brain split 現象的發生,
(3) 必須保證兩個 NameNode 之間能夠 ssh 無密碼登錄(為了防止腦裂,遠程登錄進行kill)
(4)隔離(Fence),即同一時刻僅僅有一個 NameNode 對外提供服務
2.2、 HDFS-HA 自動故障轉移作業機制
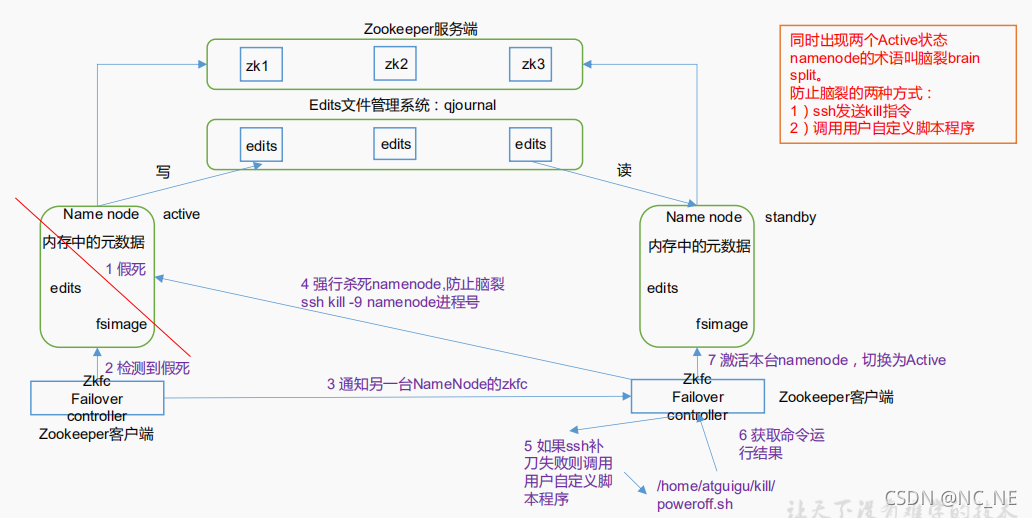
1)故障檢測:集群中的每個NameNode在ZooKeeper 中維護了一個持久會話,如果機器崩潰,ZooKeeper 中的會話將終止,ZooKeeper 通知另一個 NameNode 需要觸發故障轉移,
2)現役 NameNode 選擇:ZooKeeper 提供了一個簡單的機制用于唯一的選擇一個節點為 active 狀態,如果目前現役 NameNode 崩潰,另一個節點可能從 ZooKeeper 獲得特殊的排外鎖以表明它應該成為現役 NameNode,
3)ZKFC作業原理:
(1)健康監測:ZKFC 使用一個健康檢查命令定期地 ping 與之在相同主機的 NameNode,只要該 NameNode 及時地回復健康狀態,ZKFC 認為該節點是健康的,如果該節點崩潰,凍結或進入不健康狀態,健康監測器標識該節點為非健康的,
(2)ZooKeeper 會話管理:當本地 NameNode 是健康的,ZKFC 保持一個在 ZooKeeper中打開的會話,如果本地 NameNode 處于 active 狀態,ZKFC 也保持一個特殊的 znode 鎖,該鎖使用了 ZooKeeper 對短暫節點的支持,如果會話終止,鎖節點將自動洗掉,
(3)基于 ZooKeeper 的選擇:如果本地 NameNode 是健康的,且 ZKFC 發現沒有其它的節點當前持有 znode 鎖,它將為自己獲取該鎖,如果成功,則它已經贏得了選擇,并負責運行故障轉移行程以使它的本地 NameNode 為 Active,
三、YARN-HA 作業機制
yarn的高可只依賴于zookeeper即可,所以只需要配置一下高可用引數和zookeeper引數即可
可以參考官網
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/330149.html
標籤:其他