- 🎉粉絲福利送書:《 Java多執行緒與大資料處理實戰》
- 🎉點贊 👍 收藏 ?留言 📝 即可參與抽獎送書
- 🎉下周二(10月26日)晚上20:00將會在【點贊區和評論區】抽一位粉絲送這本北京大學出版社的書~🙉
- 🎉詳情請看第六點的介紹嗷~?
目錄
- 1.詞頻統計任務要求
- 1.1 MapReduce程式撰寫方法
- 1.1.1 撰寫Map處理邏輯
- 1.1.2 撰寫Reduce處理邏輯
- 1.1.3 撰寫main方法
- 2 完整的詞頻統計程式
- 3. 編譯打包程式
- 3.1 使用命令列編譯打包詞頻統計程式
- 3.2 使用IDEA編譯打包詞頻統計程式
- 4. 運行程式
- 5. 編程題
- 5.1 根據附件的資料檔案flow_data.dat , 編程完成下面需求:
- 5.2 附加題(選做)
- 6. 福利送書
- 最后
1.詞頻統計任務要求
本地編輯txt檔案

填入文字
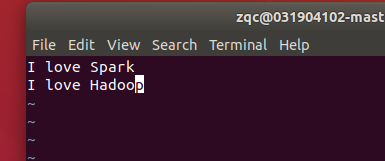
撰寫檔案入其中
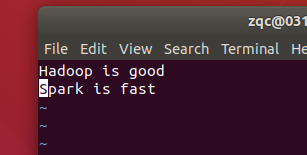
1.1 MapReduce程式撰寫方法
匯入包
- mapreduce下所有jar
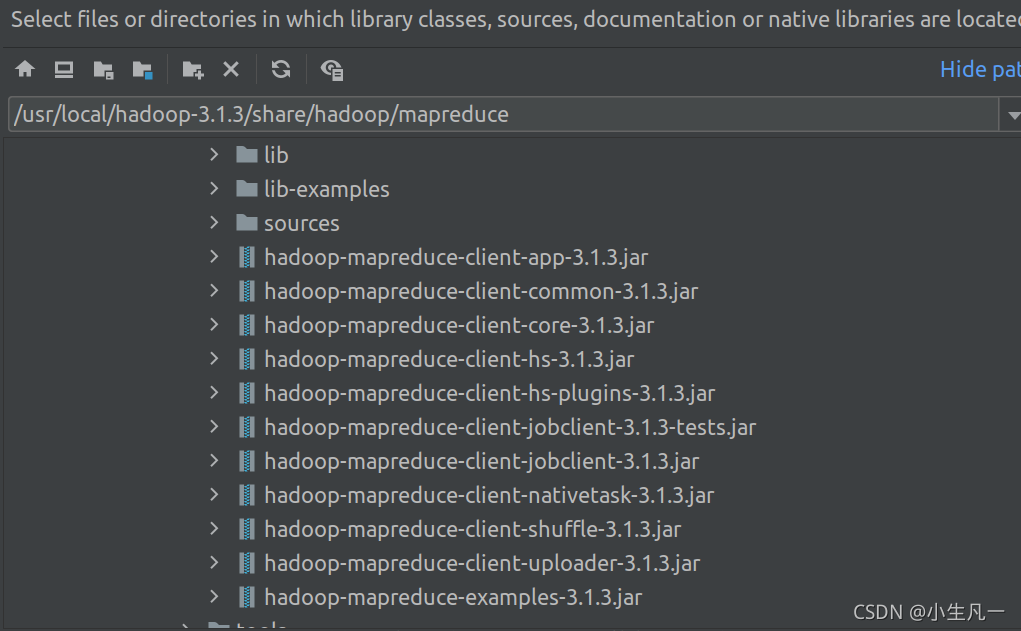
-
common下所有jar
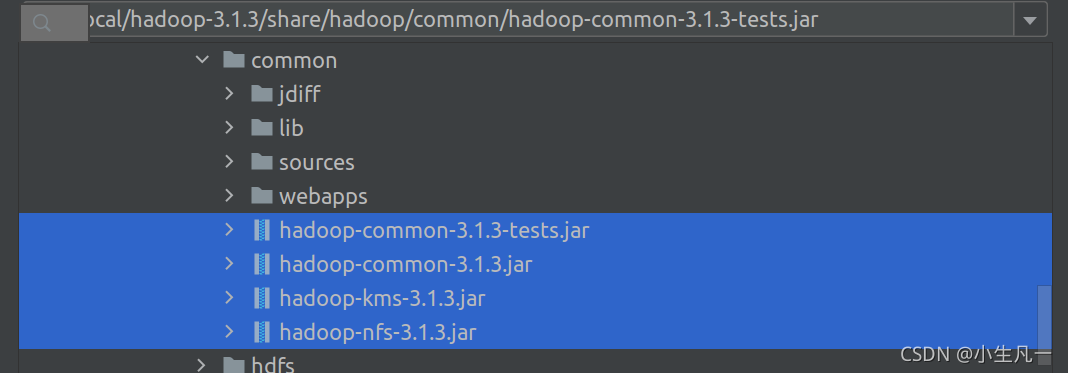
-
common/lib下所有jar
-
yarn下所有包
- hdfs下所有包
在hdfs上創建input,output檔案夾,

查看是否創建

上傳剛剛新建立的wordfile1.txt和wordfile2.txt到hdfs檔案中!

查看是否上傳成功!

1.1.1 撰寫Map處理邏輯
在Map階段,檔案wordfile1.txt和檔案wordfile2.txt中的文本資料被讀入,以<key , value>的形式提交給Map函式進行處理,其中key是當前讀取到的行的地址偏移量,value是當前讀取到的行的內容,<key , value>提交給Map函式以后,就可以運行自定義的Map處理邏輯,對value進行處理,然后以特定的鍵值對的形式進行輸出,這個輸出將作為中間結果,繼續提供給Reduce階段作為輸入資料,
public static class TokenizerMapper extends Mapper<Object, Text, Text,
IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text,
IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
1.1.2 撰寫Reduce處理邏輯
Map階段得到的中間結果,經過Shuffle階段(磁區、排序、合并)以后,分發給對應的Reduce任務去處理,對于該階段而言,輸入是<key , value-list>形式,例如,<’Hadoop’, <1,1>>,Reduce函式就是對輸入中的value-list進行求和,得到詞頻統計結果,
public static class IntSumReducer extends Reducer<Text, IntWritable,
Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws
IOException, InterruptedException {
int sum = 0;
IntWritable val;
for (Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable) i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
1.1.3 撰寫main方法
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();// 加載hadoop配置
conf.set("fs.defaultFS", "hdfs://localhost:9000");
String[] otherArgs = new String[]{"/input/wordfile1.txt","/input/wordfile2.txt","/output/output"};
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
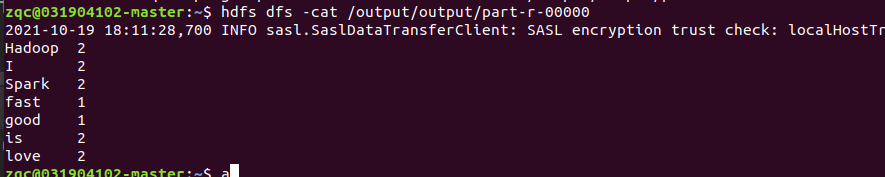
2 完整的詞頻統計程式
3. 編譯打包程式
3.1 使用命令列編譯打包詞頻統計程式
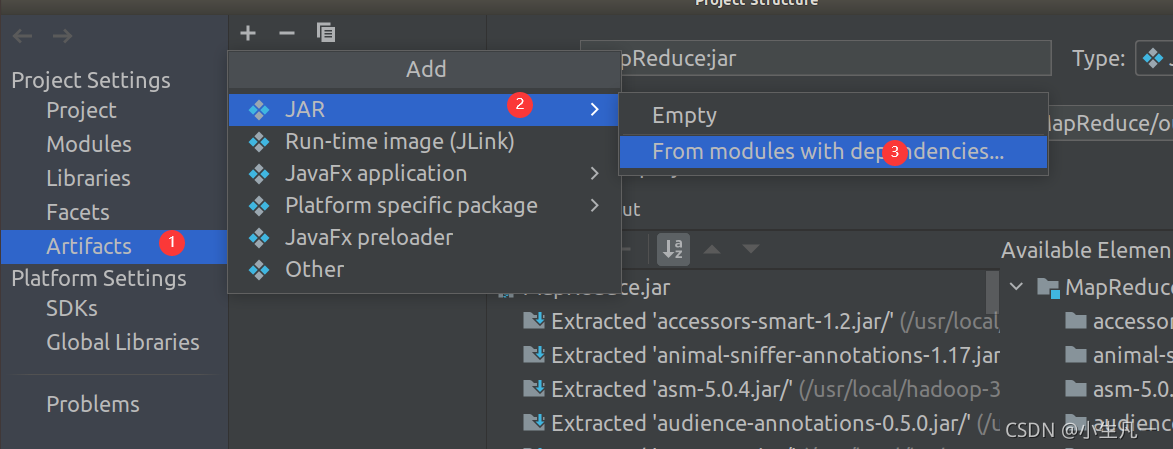
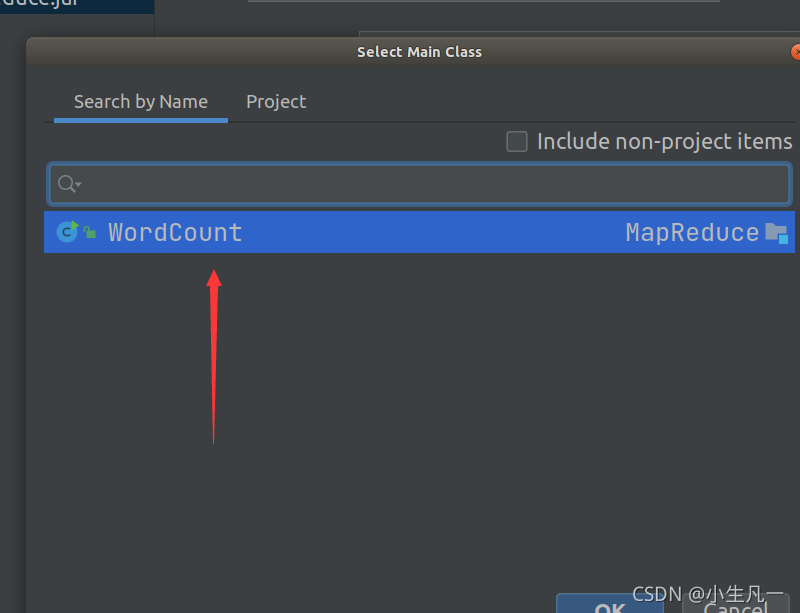
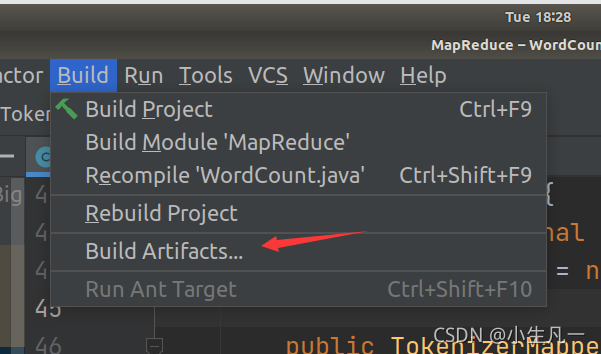
3.2 使用IDEA編譯打包詞頻統計程式
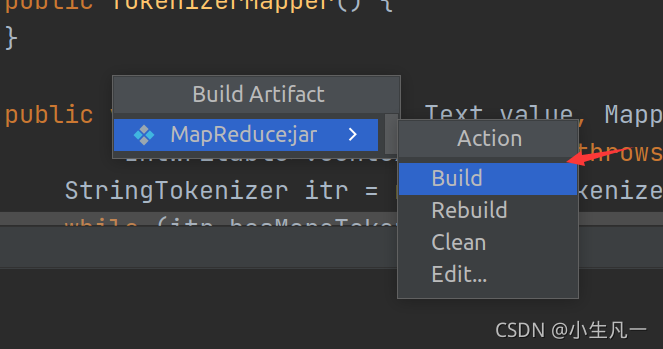
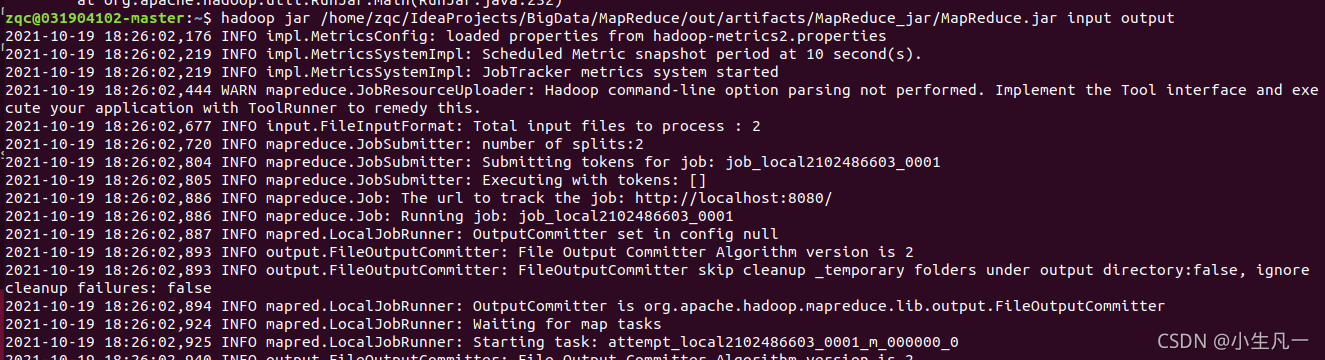
4. 運行程式
如果要再次運行WordCount.jar,需要先洗掉HDFS中的output目錄,否則會報錯,
5. 編程題
5.1 根據附件的資料檔案flow_data.dat , 編程完成下面需求:
統計每個手機號的上行流量總和,下行流量總和,上行總流量之和,下行總流量之和
( Hint:以手機號碼作為key值,上行流量,下行流量,上行總流量,下行總流量四個欄位作為value值,然后以這個key,和value作為map階段的輸出,reduce階段的輸入,)
- 定義一個結構
public static class FlowBean implements Writable {
private long upflow;
private long downflow;
private long sumflow;
public FlowBean() {
}
public long getUpflow() {
return upflow;
}
public void setUpflow(long upflow) {
this.upflow = upflow;
}
public long getDownflow() {
return downflow;
}
public void setDownflow(long downflow) {
this.downflow = downflow;
}
public long getSumflow() {
return sumflow;
}
public void setSumflow(long sumflow) {
this.sumflow = sumflow;
}
public FlowBean(long upflow, long downflow) {
this.upflow = upflow;
this.downflow = downflow;
this.sumflow = upflow + downflow;
}
public void write(DataOutput output) throws IOException {
output.writeLong(this.upflow);
output.writeLong(this.downflow);
output.writeLong(this.sumflow);
}
public void readFields(DataInput Input) throws IOException {
this.upflow = Input.readLong();
this.downflow = Input.readLong();
this.sumflow = Input.readLong();
}
@Override
public String toString() {
return this.upflow + "\t" + this.downflow + "\t" + this.sumflow;
}
}
- 主函式
import java.io.IOException;
import java.util.Objects;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
public class PhoneCount {
public PhoneCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();// 加載hadoop配置
conf.set("fs.defaultFS", "hdfs://localhost:9000");
String[] otherArgs = new String[]{"/phone/input/flow_data.dat","/phone/output4"};
Job job = Job.getInstance(conf);
job.setJarByClass(PhoneCount.class);
job.setMapperClass(MapWritable.class);
job.setReducerClass(ReduceWritable.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
job.waitForCompletion(true);
}
- map操作
public static class MapWritable extends Mapper<LongWritable, Text,Text,FlowBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
System.out.println("line");
System.out.println(line);
String[] fields = line.split("\t");
if (Objects.equals(fields[fields.length - 3], "上行總和")){
} else {
long upflow = Long.parseLong(fields[fields.length - 3]);
long downflow = Long.parseLong(fields[fields.length - 2]);
context.write(new Text(fields[1]), new FlowBean(upflow, downflow));
}
}
}
- reduce 操作
public static class ReduceWritable extends Reducer<Text,FlowBean,Text,FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
//定義兩個計數器,計算每個用戶的上傳流量、下載流量
long sumupflow = 0;
long sumdownflow = 0;
//累加的號的流量和
for (FlowBean f: values) {
sumupflow+=f.getUpflow();
sumdownflow+=f.getDownflow();
}
//輸出
context.write(key,new FlowBean(sumupflow,sumdownflow));
}
}
5.2 附加題(選做)
MapReduce 實作最短路徑演算法,最優路徑演算法是路徑圖中滿足通路上所有頂點(除起點、終點外)各異,所有邊也各異的通路,
應用在公路運輸中,可以提供起點和終點之間的最短路徑,節省運輸成本,可以大大提高交通運輸效率,
給定下述路徑圖 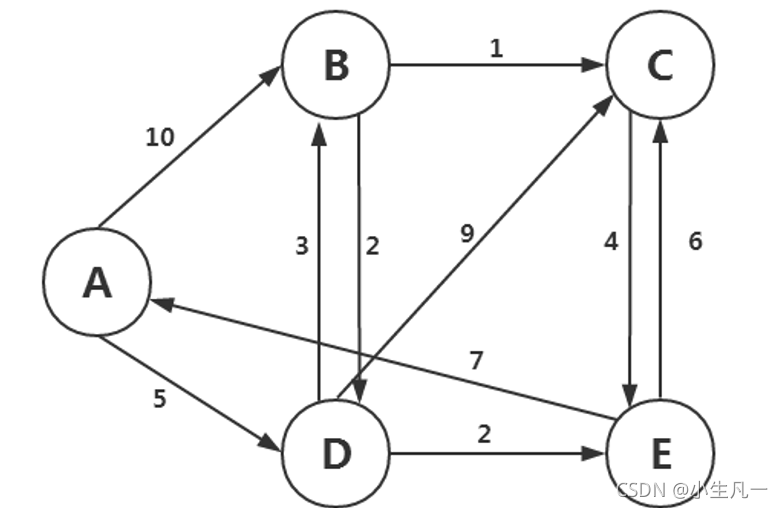
:
請編程計算出A到C之間的最短路徑大小
6. 福利送書

【內容簡介】
《億級流量Java高并發與網路編程實戰》 系統全面的介紹了開發人員必學的知識,如
JVM、網路編程、NIO等知識,讓開發人員系統地掌握JAVA高并發與網路編程知識,
《億級流量Java高并發與網路編程實戰》分為10章,內容如下,
- 第1章,主要講高并發相關JVM原理決議
- 第2章,主要講 Java 網路編程
- 第3章,主要講 Java NIO
- 第4章,主要講并發框架Disruptor
- 第5章,主要講微服務構建框架Spring Boot
- 第6章,主要講微服務治理框架Spring Cloud/Dubbo
- 第7章,主要講 Java高并發網路編程框架Netty - 實戰應用
- 第8章,主要講 Java高并發網路編程框架Netty - 深度解讀
- 第9章,主要講海量資料的高并發處理
- 第10章,主要講基于高并發與網路編程的大型互聯網專案實戰,
本書主要面向面向零基礎及入門級讀者,Java從業人員,
【評論區】和 【點贊區】 會抽一位粉絲送出這本書籍嗷~
當然如果沒有中獎的話,可以到釘釘,京東北京大學出版社的自營店進行購買,
也可以關注我!每周都會送一本出去噠~
最后
小生凡一,期待你的關注,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/330222.html
標籤:其他