文章目錄
- 1 論文閱讀
- 1.1 論文摘要
- 1.2 論文創新點
- 1.3 學習細節
- 1.4 小結
- 2 網路框架
- 2.1 Feature map 維度計算
- 2.2 網路結構分析
- 3 神經元數量和引數數量
- 3.1 計算方法
- 3.2 小結
- 4 網路搭建
- 4.1 基本架構
- 4.2 API架構
- 4.3 Pytroch官方架構
- 5 總結
強烈建議大家在讀論文前先看這個視頻, 如何讀論文【論文精讀】
1 論文閱讀
AlexNet論文翻譯——中英文對照
1.1 論文摘要
我們訓練了一個大型深度卷積神經網路來將120萬高解析度的影像分到1000不同的類別中,這個神經網路有6000萬引數和650000個神經元,包含5個卷積層(某些卷積層后面帶有池化層)和3個全連接層,最后是一個1000維的softmax,為了訓練的更快,我們使用了非飽和神經元并對卷積操作進行了非常有效的GPU實作,為了減少全連接層的過擬合,我們采用了一個最近開發的名為dropout的正則化方法,結果證明是非常有效的,
至此,網路的功能和結構就完全被你了解,下面我們將對細節進行深入的探究,
1.2 論文創新點
① ReLU Nonlinearity ReLU非線性
將神經元輸出f建模為輸入x的函式的標準方式是用f(x) = tanh(x)或f(x) = (1 + e?x)?1,考慮到梯度下降的訓練時間,這些飽和的非線性比非飽和非線性f(x) = max(0,x)更慢,根據Nair和Hinton[20]的說法,我們將這種非線性神經元稱為修正線性單元(ReLU),
特點:加快了訓練的速度,
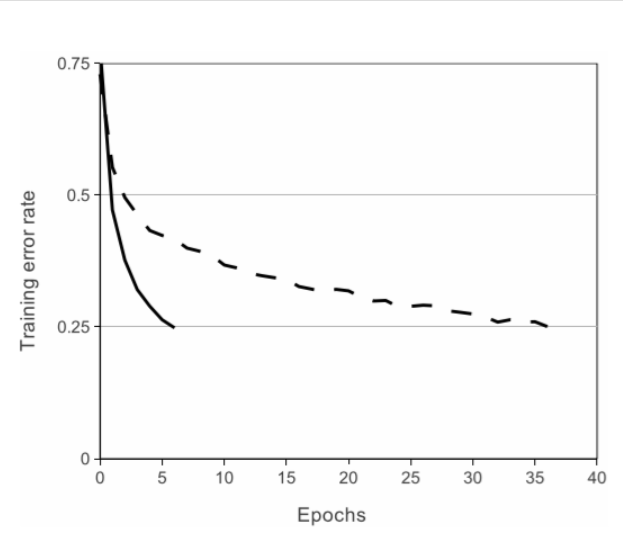 在上圖中,對于一個特定的四層卷積網路,在CIFAR-10資料集上達到25%的訓練誤差所需要的迭代次數可以證實這一點,這幅圖表明,如果我們采用傳統的飽和神經元模型,我們將不能在如此大的神經網路上實驗該作業,(黑線采用Relu作為激活函式)
在上圖中,對于一個特定的四層卷積網路,在CIFAR-10資料集上達到25%的訓練誤差所需要的迭代次數可以證實這一點,這幅圖表明,如果我們采用傳統的飽和神經元模型,我們將不能在如此大的神經網路上實驗該作業,(黑線采用Relu作為激活函式)
② Training on Multiple GPUs 多GPU訓練
事實證明120萬影像用來進行網路訓練是足夠的,但網路太大因此不能在單個GPU上進行訓練,因此我們將網路分布在兩個GPU上,我們采用的并行方案基本上每個GPU放置一半的核(或神經元),還有一個額外的技巧:只在某些特定的層上進行GPU通信,
這意味著,例如,第3層的核會將第2層的所有核映射作為輸入,然而,第4層的核只將位于相同GPU上的第3層的核映射作為輸入,連接模式的選擇是一個交叉驗證問題,但這可以讓我們準確地調整通信數量,直到它的計算量在可接受的范圍內,
③ Local Response Normalization 區域回應歸一化
ReLU具有讓人滿意的特性,它不需要通過輸入歸一化來防止飽和,如果至少一些訓練樣本對ReLU產生了正輸入,那么那個神經元上將發生學習,然而,我們仍然發現接下來的區域回應歸一化有助于泛化,

論文中給的公式時batch normalization的前身,
大概就是說relu雖然有normalization的作用,但他們還是對輸入做了normalization,發現效果更好,
④ Overlapping Pooling 重疊池化
習慣上,相鄰池化單元歸納的區域是不重疊的,在CNN中采用的傳統區域池化,池化區域是不重疊的,例如步長是2,池化視窗是2,每次池化都不會重疊,但當步長是2,池化視窗是3,很容易去想象會有重疊,池化視窗時在訓練程序中通常觀察采用重疊池化的模型,發現它更難過擬合,
⑤ Dropout 失活法
這種最近引入的技術,叫做“dropout”,它會以0.5的概率對每個隱層神經元的輸出設為0,那些“失活的”的神經元不再進行前向傳播并且不參與反向傳播,因此每次輸入時,神經網路會采樣一個不同的架構,但所有架構共享權重,這個技術減少了復雜的神經元互適應,因為一個神經元不能依賴特定的其它神經元的存在,因此,神經元被強迫學習更魯棒的特征,它在與許多不同的其它神經元的隨機子集結合時是有用的,
我們在前兩個全連接層使用失活,如果沒有失活,我們的網路表現出大量的過擬合, 失活大致上使要求收斂的迭代次數翻了一倍,
1.3 學習細節
我們使用隨機梯度下降來訓練我們的模型,樣本的batch size為128,動量為0.9,權重衰減為0.0005,權重衰減不僅僅是一個正則項:它減少了模型的訓練誤差,權重w的更新規則是:

1.4 小結
如果出錯,歡迎批評指正!
| 方法 | 作用 |
|---|---|
| ReLU | 提高速度 |
| GPUS | 提高速度 |
| 區域相應歸一化 | 減小過擬合,泛化能力提高 |
| 重疊池化 | 減小過擬合,泛化能力提高 |
| 丟棄法 | 減小過擬合,泛化能力提高 |
| 權重衰減 | 減小過擬合,泛化能力提高 |
2 網路框架
2.1 Feature map 維度計算
簡單的來說,在cnn的每個卷積層,資料都是以三維形式存在的,可以把它看成許多個二維矩陣疊在一起,其中每一層稱為一個feature map,


2.2 網路結構分析
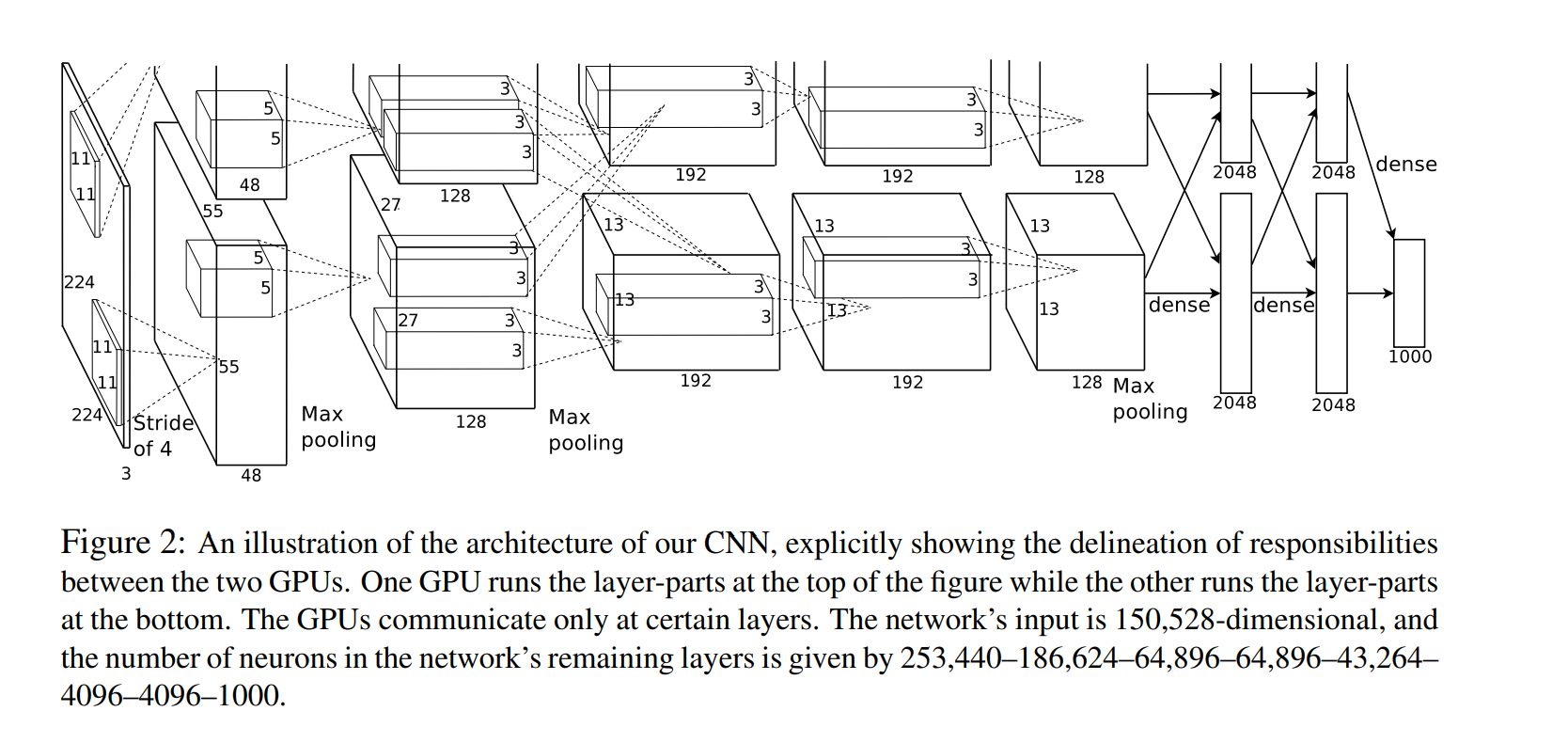
As a fun aside, if you read the actual paper it claims that the input images were 224×224, which is surely incorrect because (224 – 11)/4 + 1 is quite clearly not an integer. This has confused many people in the history of ConvNets and little is known about what happened. My own best guess is that Alex used zero-padding of 3 extra pixels that he does not mention in the paper.
from CS231n blog
根據上面的計算公式,我們來對各層feature map尺寸進行梳理:
值得注意的是:由于本人的電腦只有一塊GPU,所以所有的卷積都是在一塊GPU上實作的,
我看了很多的神經網路的設計,目前我也不太知道誰說的是正確的,所以下面的內容和代碼部分僅供參考,同時,我也會多給幾種網路模型供大家學習參考,
- 卷積層1得到的feature map: (227 - 11 + 2 × 0) ÷ 4 + 1 = 55
- 重疊池化層得到的feature map:(55 - 3) ÷ 2 + 1 = 27
- 卷積層2得到的feature map: (27 - 5 + 2 × 2) ÷ 1 + 1 = 27
- 重疊池化層得到的feature map:(27 - 3) ÷ 2 + 1 = 13
- 卷積層3得到的feature map: (13 - 3 + 2 × 1) ÷ 1 + 1 = 13
- 卷積層4得到的feature map: (13 - 3 + 2 × 1) ÷ 1 + 1 = 13
- 卷積層5得到的feature map: (13 - 3 + 2 × 1) ÷ 1 + 1 = 13
- 重疊池化層得到的feature map:(13 - 3) ÷ 2 + 1 = 6
- Flatten展開:6 × 6 × 128 × 2 = 9216
- 全連接層1:9216 -> 4096
- 丟棄層:p = 0.5
- 全連接層2:4096 -> 4096
- 丟棄層:p = 0.5
- 全連接層3:4096 -> 1000
3 神經元數量和引數數量
3.1 計算方法
神經元的數量 = feature map大小(高寬) * feature map數量(維度)
卷積層的引數 = 卷積核大小 x 卷積核的數量+ 偏置數量(即卷積的核數量)
全連接層的引數數量 = 上一層節點數量(pooling之后的) x 下一層節點數量 + 偏置數量(即下一層的節點數量)
參考閱讀:AlexNet中的引數數量 侵權刪!
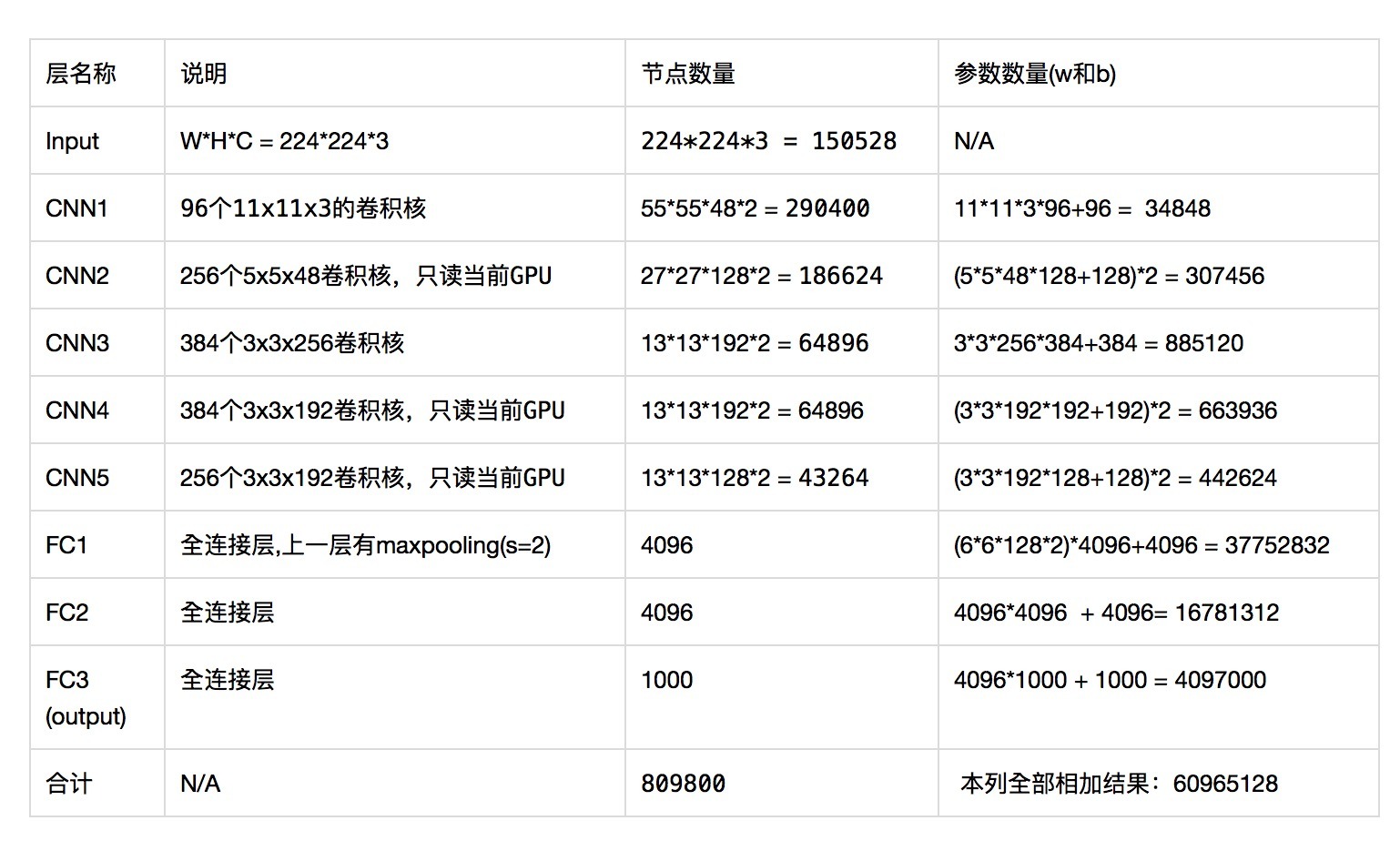
接下來梳理一下各層的引數情況:
- 輸入層:圖片大小:寬高通道(RGB)依次為W * H * C = 224 x 224 x 3, 即150528像素,
- 第1個隱層, 卷積層,使用96個 11 x 11 x 3的卷積核,節點數量為: 55(W) x 55(H) x 48(C ) x 2 = 290400,本層引數數量為: (11 * 11 * 3 * 96) + 96 = 34848
注意,這里是上下兩塊GPU計算,單個GPU是48,兩個在一起計算就是96個卷積核,在某個卷積層中,可以有多個卷積核:下一層需要多少個feature map,本層就需要多少個卷積核,
- 第2個隱層, 卷積層,使用256個 5 x 5 x 48的卷積核,節點數量為: 27(W) x 27(H) x 128(C ) x 2 = 186624,本層引數數量為: (5 * 5 * 48 * 128+128) * 2 = 307456,最后"*2"是因為網路層均勻分布在兩個GPU上,先計算單個GPU上的引數,再乘以GPU數量2,即5 * 5 * 48 * 256 + 256 = 307456,
- 第3個隱層, 卷積層,使用384個 3 x 3 x 192的卷積核,節點數量為: 13(W) x 13(H) x 192(C ) x 2 = 64896,本層引數數量為: 3 * 3* 256 * 384 + 384 = 885120,
- 第4個隱層, 卷積層,使用384個 3 x 3 x 128的卷積核,節點數量為: 13(W) x 13(H) x 192(C ) x 2 = 64896,本層引數數量為: 3 * 3* 192 * 384 + 384 = 663936,
- 第5個隱層, 卷積層,使用256個 3 x 3 x 192的卷積核,節點數量為: 13(W) x 13(H) x 128(C ) x 2 = 43264,本層引數數量為: 3 * 3* 192 * 256 + 256 = 442624,
- 第6個隱層,全連接層,節點數量為: 4096,引數數量為:(6 * 6 * 128 * 2) * 4096 + 4096 = 37752832,
所謂6,就是在經歷最大池化后,矩陣由13 * 13轉化為了6 *6, (13 - 3)/ 2 + 1 = 6
- 第7個隱層,全連接層,節點數量為: 4096,引數數量為: 4096 * 4096 + 4096 = 16781312,
- 第8個隱層,全連接層,也是1000-way的softmax輸出層,節點數量為: 1000,引數數量為: 4096 * 1000 + 1000 = 4097000,
可以看到這個引數數量遠遠大于之前所有卷積層的引數數量之和,也就是說AlexNet的引數大部分位于后面的全連接層,
3.2 小結
總結: 對于隱層節點和引數的計算,可以簡單的理解為:孤立的看待某一隱層,找到對應的輸入和輸出層,節點數等于輸出的feature map的尺寸(包括高寬和通道數),引數數量為 輸入層的卷積核大小×卷積核數量+卷積核數量或上一層節點數量(pooling之后的) x 下一層節點數量 + 偏置數量(即下一層的節點數量),
如果對這部分不理解的可以私信我,或QQ1257663033,
最后,為了方便查看,匯總為表格如下,其中最后一行給出了AlexNet的引數總量,
4 網路搭建
4.1 基本架構
基本結構的搭建可參見該博客
使用pytorch搭建AlexNet并訓練花分類資料集
這些博客和視頻的博主開源了自己的代碼,下面是修改的網路層,因為我設定的輸入是227 * 227,所以對池化和填充的大小做了改變,并且在后面也給出了兩種解釋最終的效果圖,發現差別并不大,
net:
import torch
from torch import nn
import torch.nn.functional as F
class MyAlexNet(nn.Module):
def __init__(self):
super(MyAlexNet, self).__init__()
self.c1 = nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=0)
self.ReLU = nn.ReLU()
self.s1 = nn.MaxPool2d(kernel_size=3, stride=2)
self.c2 = nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2)
self.s2 = nn.MaxPool2d(kernel_size=3, stride=2)
self.c3 = nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1)
self.c4 = nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1)
self.c5 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1)
self.s5 = nn.MaxPool2d(kernel_size=3, stride=2)
self.flatten = nn.Flatten()
self.f6 = nn.Linear(9216, 4096) # 256 * 6 * 6 = 9216
self.f7 = nn.Linear(4096, 4096)
self.f8 = nn.Linear(4096, 1000)
self.f9 = nn.Linear(1000, 10)
def forward(self, x):
x = self.ReLU(self.c1(x))
x = self.s1(x)
x = self.ReLU(self.c2(x))
x = self.s2(x)
x = self.ReLU(self.c3(x))
x = self.ReLU(self.c4(x))
x = self.ReLU(self.c5(x))
x = self.s5(x)
x = self.flatten(x)
x = self.f6(x)
x = F.dropout(x, p=0.5)
x = self.f7(x)
x = F.dropout(x, p=0.5)
x = self.f8(x)
x = F.dropout(x, p=0.5)
x = self.f9(x)
x = F.dropout(x, p=0.5)
return x
if __name__ == "__main__":
x = torch.rand([1, 3, 227, 227])
model = MyAlexNet()
print(model)
y = model(x)
4.2 API架構
測驗的是fashion_mnist資料集,
net:
import torch
from torch import nn
MyAlexNet = nn.Sequential(
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
nn.Linear(9216, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 1000),
nn.Dropout(p=0.5),
nn.Linear(1000, 10))
X = torch.randn(1, 1, 227, 227)
for layer in MyAlexNet:
X = layer(X)
print(layer.__class__.__name__, 'Output shape:\t', X.shape)
train_d2l:
import torch
from d2l import torch as d2l
from NetAPI import MyAlexNet
import matplotlib.pyplot as plt
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=227)
lr, num_epochs = 0.01, 10
d2l.train_ch6(MyAlexNet, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
測驗結果:
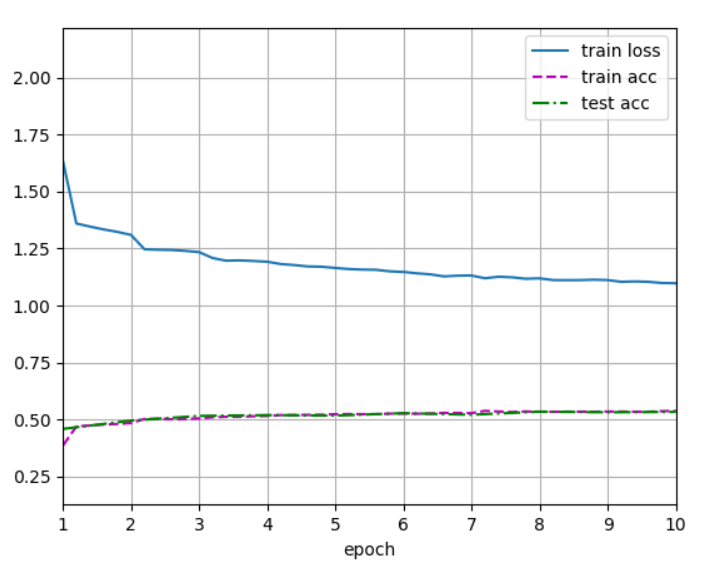
本人還測驗了輸入影像為224 * 224的網路:
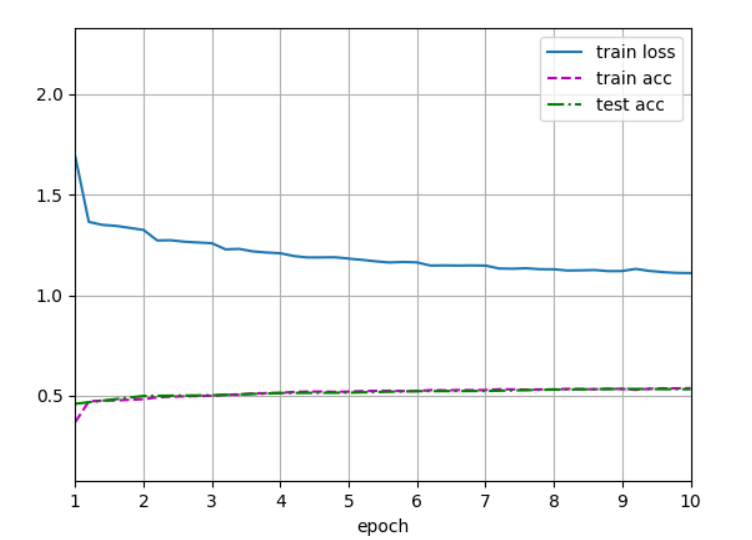
可以看到兩者的訓練出來的網路,精度相差不大,所以也沒有必要去糾結輸入影像到底是224 * 224還是227 * 227咯,
4.3 Pytroch官方架構
from torchvision.models.alexnet import alexnet
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 1000) -> None:
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
5 總結
未解決問題:如何改變資料集的圖片尺寸以適應網路默認輸入尺寸?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/330450.html
標籤:其他
上一篇:超解析度重建測驗(ESRGAN)