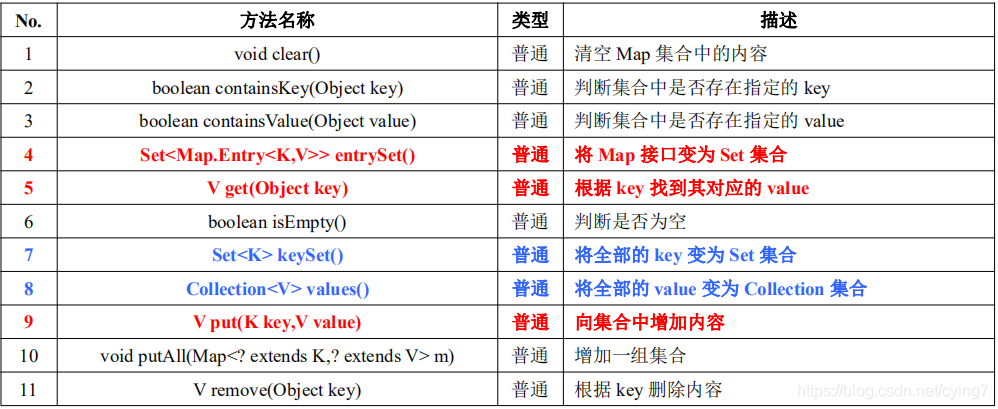
學習主題:
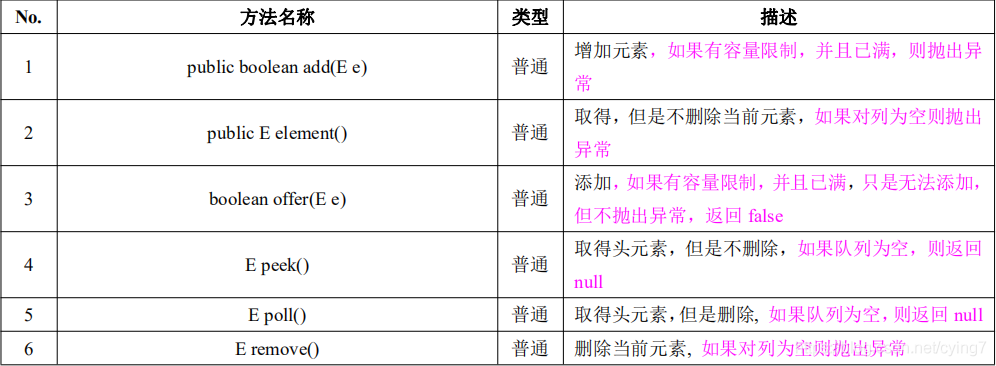
Java 中的集合體系
集合是Java常用類別庫最重要的一部分,
集合是資料的容器,相比于陣列陣列的長度是固定的,陣列無法改變自己的大小,即使使用動態擴容,也是創造新的陣列,而且陣列不是很適合資料的插入,所以陣列滿足不了我們的需要,所以Java官方內置了各種資料結構,經過發展到了jdk1.2之后集合到了一起,類集是Java對資料結構一種成熟的體現,
下面我將總結一下我對于集合的相關學習,
學習內容:
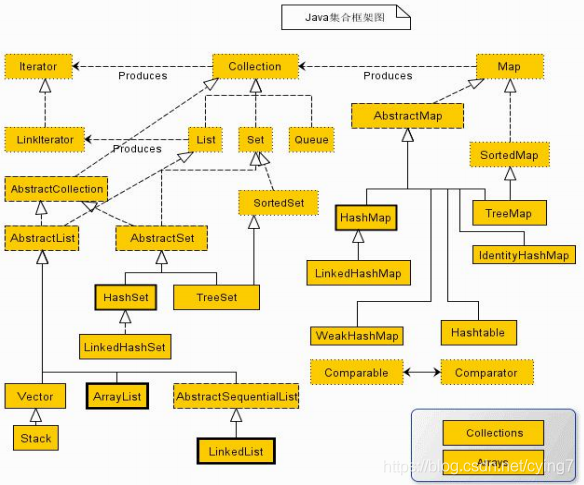
Collection介面:
Collection 介面是在整個 Java 類集中保存單值的最大操作父介面,里面每次操作的時候都只能保存一個物件的資料, 此介面定義在 java.util 包中,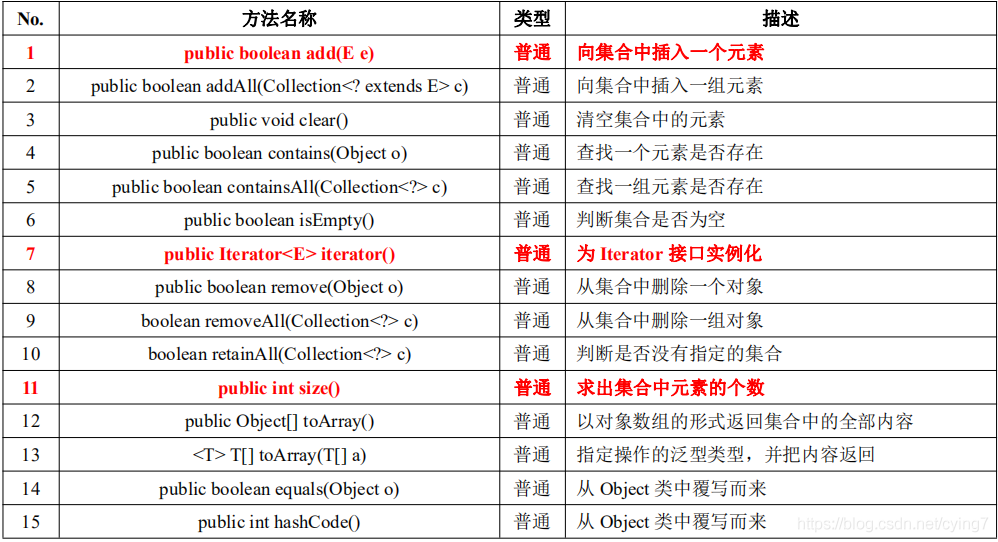
Collection或者其他的子類都擁有相同的方法對資料進行操作,
public boolean add(E e) 插入資料
public E get(int index) 獲取資料(List中)
public boolean contains(Object o) 判斷集合中是否包含
public E remove(int index) 洗掉資料
List介面:
在整個集合中 List 是 Collection 的子介面,里面的所有內容都是允許重復的,
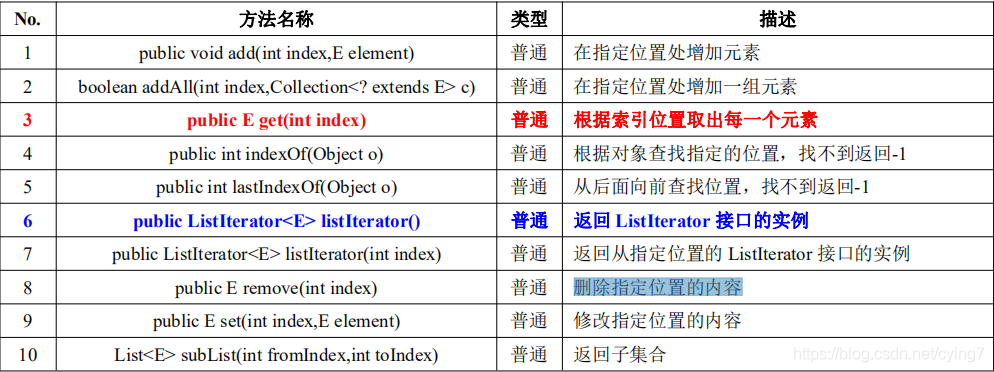
注:List相比于Collection大部分方法是可以使用的,其中有一些方法有多載和擴展,
其中remove方法進行了多載,具體如下:
public E remove(int index)洗掉指定位置的內容,使用下標進行操作,并且取出來,如果你操作List,想獲取和洗掉共同進行,即可以使用remove方法,
public E set(int index,E element)方法是對某個指定下標進行修改,覆寫的操作,
public void add(int index,E element)方法是對其進行添加,通俗的說就是往后 擠,
List subList(int fromIndex,int toIndex)方法就是給定一段下標進行截取,
List 介面類有如下幾個: ArrayList(95%)(執行緒不安全),Vector(4%)(執行緒安全),LinkedList(1%)
ArrayList介面:
ArrayList為陣列結構,特點:增刪慢,查找快
// ArrayList的宣告
ArrayList<Integer> data= new ArrayList<>();
根據API查看構造方法:

構造方法內輸入數字為陣列大小,每次擴容為原來的1.5倍,建議使用一參構造方法根據陣列大小輸入合適的數,
Q:為什么初始容量為10?
A:根據原始碼

其中elementData是可以存盤任何資料型別的陣列,賦值DEFAULTCAPACITY_EMPTY_ELEMENTDATA,的值為
transient Object[] elementData;
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
長度為0
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
正是因為長度為0,在發現無法存入的時候,就會發生擴容,我們再來查看一下擴容的原始碼,不同版本的jdk貌似演算法有所不同,我以自己電腦上的版本為準,先初始化ArrayList,再進行添加,初始長度為0,則進行擴容,
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
回傳為true,再查看ensureCapacityInternal()與calculateCapacity()兩個方法;
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
可以看出如果陣列elementData與DEFAULTCAPACITY_EMPTY_ELEMENTDATA相同,也就是都為空時,就回傳DEFAULT_CAPACITY與minCapacity最大值,而minCapacity為1,DEFAULT_CAPACITY默認為10,
private static final int DEFAULT_CAPACITY = 10;
所以擴容長度默認為10.
接下來我們用實體來測驗其他的方法,源代碼和結果如下:
import java.util.ArrayList;
import java.util.Collection;
public class Test1 {
public static void main(String[] args) {
//陣列結構
//特點:增刪慢,查找快
ArrayList<Integer> data= new ArrayList<>();
data.add(1);//順序添加
data.add(2);
data.add(3);
data.add(4);
data.add(5);
data.add(0,6);//第一個引數是下標插入
System.out.println(data); // 列印all物件呼叫toString()方法
}
}
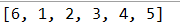
import java.util.ArrayList;
import java.util.Collection;
public class Test1 {
public static void main(String[] args) {
//陣列結構
//特點:增刪慢,查找快
ArrayList<Integer> data= new ArrayList<>();
ArrayList<String> data1= new ArrayList<>();
data.add(1);//順序添加
data.add(2);
data.add(3);
data.add(4);
data.add(5);
data.add(0,6);//第一個引數是下標插入
data.remove(4);//洗掉下標為4的數
data1.add("hello");//插入陣列型別的
data1.add("world");
data1.remove("hello");//洗掉內容為hello的陣列
System.out.println(data); // 列印all物件呼叫toString()方法
}
}

Vector介面:
Vector 本身也屬于 List 介面的子類,基本和ArrayList一樣,
import java.util.Vector;
public class Test1 {
public static void main(String[] args) {
Vector<String> all = new Vector<String>(); // 實體化List物件,并指定泛型型別
all.add("hello "); // 增加內容,此方法從Collection介面繼承而來
all.add(0, "LAMP ");// 增加內容,此方法是List介面單獨定義的
all.add("world"); // 增加內容,此方法從Collection介面繼承而來
all.remove(1); // 根據索引洗掉內容,此方法是List介面單獨定義的
all.remove("world");// 洗掉指定的物件
System.out.print(all);
}
}

區別:


相比于ArrayList可以自定義擴容的大小,
LinkedList:
此類的使用幾率是非常低,此類繼承了 AbstractList,所以是 List 的子類,但是此類也是 Queue 介面的子類,主要是鏈表,增刪快,查找滿,可以當作堆疊或者佇列使用,
新加操作:
public void addFirst(E e) :將指定元素插入此串列的開頭,
public void addLast(E e) :將指定元素添加到此串列的結尾,
public E getFirst() :回傳此串列的第一個元素,
public E getLast() :回傳此串列的最后一個元素,
public E removeFirst() :移除并回傳此串列的第一個元素,
public E removeLast() :移除并回傳此串列的最后一個元素,
public E pop() :從此串列所表示的堆疊處彈出一個元素,
public void push(E e) :將元素推入此串列所表示的堆疊,
public boolean isEmpty() :如果串列不包含元素,則回傳true,
LinkedList<Integer> all = new LinkedList<Integer>(); // 實體化List物件,并指定泛型型別
LinkedList<Integer> all1 = new LinkedList<Integer>();
//壓堆疊
all.push(1);
all.push(2);
all.push(3);
//彈堆疊
Integer i = all.pop();
//佇列
all1.addFirst(4);
all1.addFirst(5);
all1.removeLast();
System.out.println(all);
System.out.println(i);
System.out.println(all1);
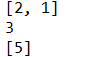
Iterator迭代器:
Iterator主要是針對輸出集合,Ilterator主要是針對Collection,而ListIlterator是針對List,
常用方法:
public E next() :回傳迭代的下一個元素,
public boolean hasNext() :如果仍有元素可以迭代,則回傳 true,
主要原理是在陣列第一個地址之前有一個指標,通過next()方法,不斷地向下移動,再用hasNext()判斷回圈調節,即可進行遍歷,換句話說,hasNext()說如果下一個地址有元素,next()就可以將指標往后移動并且回傳下一個元素,具體實作如下
ArrayList<Integer> all = new ArrayList<Integer>(); // 實體化List物件,并指定泛型型別
all.add(1); // 增加內容,此方法從Collection介面繼承而來
all.add(2);
all.add(3);
all.add(4);
all.add(5);
all.add(6);
Iterator<Integer> iterator = all.iterator();
while(iterator.hasNext()) {
Integer i = iterator.next();
System.out.println(i);
}

其中remove()方法一定要獲取后再進行洗掉,具體實作也就是先next()移動指標再進行remove();但是此時指標已經移動,如果想回復指標初始狀態,則必須配合previous進行使用,
增強for:
增強for回圈(也稱for each回圈)是JDK1.5以后出來的一個高級for回圈,專門用來遍歷陣列和集合的,它的內部原理其實是個Iterator迭代器,所以在遍歷的程序中,不能對集合中的元素進行增刪操作,
ArrayList<Integer> all = new ArrayList<Integer>(); // 實體化List物件,并指定泛型型別
all.add(1); // 增加內容,此方法從Collection介面繼承而來
all.add(2);
all.add(3);
all.add(4);
all.add(5);
all.add(6);
for(int i:all) {
System.out.println(i);
}
String型別也是一樣:
ArrayList<String> all = new ArrayList<String>(); // 實體化List物件,并指定泛型型別
all.add("楊花落盡子規啼,"); // 增加內容,此方法從Collection介面繼承而來
all.add("聞道龍標過無錫,");
all.add("我寄愁心與明月,");
all.add("隨風直到夜郎西,");
for(String i:all) {
System.out.println(i);
}

Set介面:
Set 介面也是 Collection 的子介面,與 List 介面最大的不同在于,Set 介面里面的內容是不允許重復的, Set 介面并沒有對 Collection 介面進行擴充,基本上還是與 Collection 介面保持一致,因為此介面沒有 List 介面中定義 的 get(int index)方法,所以無法使用回圈進行輸出, 那么在此介面中有兩個常用的子類:HashSet、TreeSet,
總結的來說Set是一個不包含重復元素的單值集合,
HashSet:
方法和Collection一樣(因為是子類嘛)但是沒有get的方法,可以用interator進行迭代,他的特性是散列存盤,也被稱之為散串列,
根據原始碼,HashSet使用add方法,是將元素放入一個HashMap里面,后續會講解HashMap,總之特性解釋亂序,
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
private transient HashMap<E,Object> map;
HashSet<String> all = new HashSet<String>(); // 實體化List物件,并指定泛型型別
all.add("楊花落盡子規啼,"); // 增加內容,此方法從Collection介面繼承而來
all.add("聞道龍標過無錫,");
all.add("我寄愁心與明月,");
all.add("隨風直到夜郎西,");
for(String i:all) {
System.out.println(i);
}

HashSet<String> all = new HashSet<String>(); // 實體化List物件,并指定泛型型別
all.add("楊花落盡子規啼,"); // 增加內容,此方法從Collection介面繼承而來
all.add("聞道龍標過無錫,");
all.add("我寄愁心與明月,");
boolean flag1 = all.add("隨風直到夜郎西,");
boolean flag2 = all.add("隨風直到夜郎西,");
System.out.println(flag1);
System.out.println(flag2);
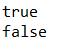
這里可以顯示無法存入相同元素,
TreeSet:
和HashSet不同,TreeSet采用二叉樹進行操作,方法都是一樣的,但是資料結構不同,順序不是無序,而是自然順序,具體展示如下:
TreeSet<String> all = new TreeSet<String>(); // 實體化List物件,并指定泛型型別
all.add("楊花落盡子規啼,"); // 增加內容,此方法從Collection介面繼承而來
all.add("聞道龍標過無錫,");
all.add("我寄愁心與明月,");
all.add("隨風直到夜郎西,");
for(String i:all) {
System.out.println(i);
}

TreeSet<String> all = new TreeSet<String>(); // 實體化List物件,并指定泛型型別
all.add("z"); // 增加內容,此方法從Collection介面繼承而來
all.add("b");
all.add("a");
all.add("e");
for(String i:all) {
System.out.println(i);
}
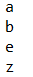
由此可見,字串,都是由Unicode碼進行排序,但是如果你不使用系統自帶的型別,而是自定義的型別,比如class Person類,這個時候使用TreeSet就會發生錯誤,所以再使用自定義類的時候一定要給出判斷大小的定義,
TreeSet<Person> all = new TreeSet<Person>(); // 實體化List物件,并指定泛型型別
Person p1 = new Person("小李",18);
Person p2 = new Person("小盧",19);
all.add(p1);
all.add(p2);
for(Person i:all) {
System.out.println(i);
}
}
static class Person{
private String name;
private int age;
public Person(String name,int age) {
this.name = name;
this.age = age;
}
}

由此引出一個Comparable類,并使用其一個抽象方法compareTo:
public int compareTo(Person per) {
if (this.age > per.age) {
return 1;
}
else if (this.age < per.age) {
return -1;
}
else {
return 0;
}
}
由此,Person類的判斷規則是年齡來進行比較,回傳值為正數,負數和0,
完善后的代碼如下:
public static void main(String[] args) {
TreeSet<Person> all = new TreeSet<Person>(); // 實體化List物件,并指定泛型型別
Person p1 = new Person("小李",18);
Person p2 = new Person("小盧",19);
all.add(p1);
all.add(p2);
for(Person i:all) {
System.out.println(i);
}
}
static class Person implements Comparable<Person>{
private String name;
private int age;
public Person(String name,int age) {
this.name = name;
this.age = age;
}
public String toString() {
return "姓名:" + this.name + ",年齡:" + this.age;
}
public int compareTo(Person per) {
if (this.age > per.age) {
return 1;
}
else if (this.age < per.age) {
return -1;
}
else {
return 0;
}
}
}

Map 介面:
Map不再是單值存盤,Map和Collection同一級別,存盤的是一對資料,為鍵值對,key,value,
相當于鑰匙和鎖,資料接相當于鎖,需要對應的key去打開,
形象的說身份證號和人,身份證號不可重復,而Map中key也是不可重復的,
Map和陣列類似,都是通過鍵來尋找資料,陣列是系統提供的0,1,2,3…,而Map是自定義的,
Map的遍歷十分麻煩,先用keyset()把鍵全部拿出來,再進行迭代進行尋找,
其中添加操作V put(K key,V value),原理是用新值覆寫舊值,如果不存在舊值就回傳null,如果存在舊值就回傳舊值,
而洗掉remove(),可以通過鍵來洗掉,也可以通過一對鍵值對來洗掉,通過鍵來洗掉的時候,回傳被洗掉的資料(成功),失敗的話就是 null,
boolean containsValue(Object value)判斷是否存在值,
boolean containsKey(Object key)判斷是否存在鍵,
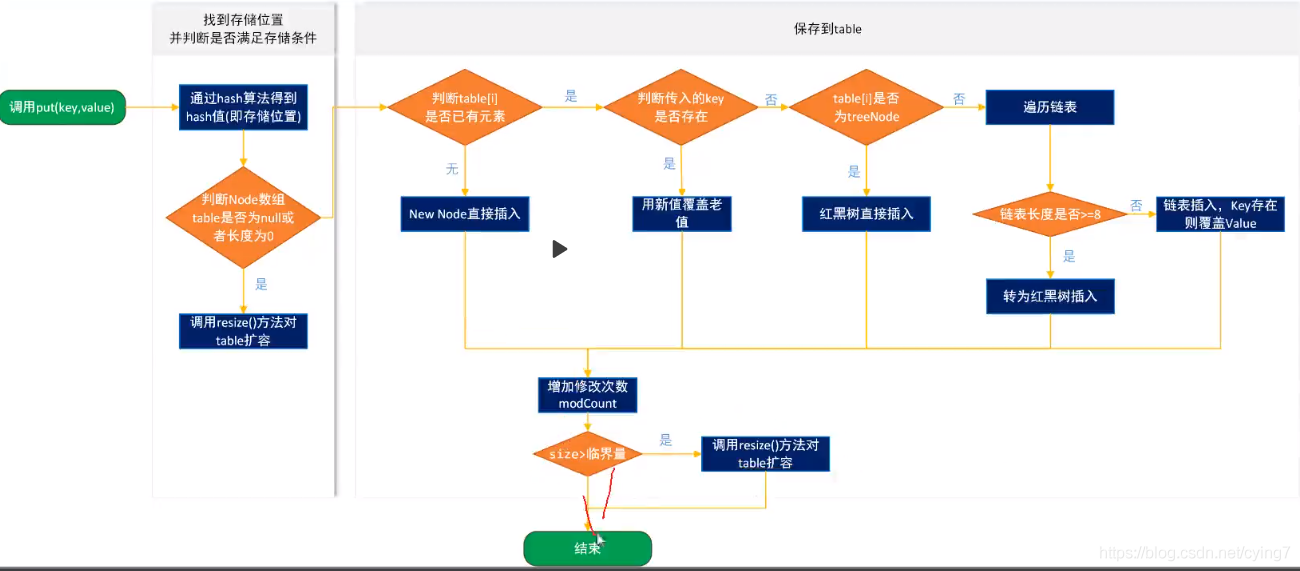
HashMap:
哈希表的結構是物件陣列+鏈表,
hashcode的int值與陣列長度進行取模的運算,如果取模結果重復了,那將存盤在同一個陣列中(哈希桶),陣列中存在一個鏈表可以不斷地向下存盤,
當一個陣列中鏈表的長度大于8是會將鏈表轉化為紅黑樹,哈希桶中的資料量減小為6時,會從紅黑樹變為鏈表,
還存在特殊的特性,Java中初始桶的數量為16,散列因子為0.75.
static final float DEFAULT_LOAD_FACTOR = 0.75f;
通俗的來說,當75%的桶子裝了時將會對桶進行擴容,

Map<Integer, String> map = new HashMap<Integer, String>();
map.put(1, "張三A");
map.put(1, "張三B"); // 新的內容替換掉舊的內容
map.put(2, "李四");
map.put(3, "王五");
String val = map.get(1);
System.out.println(val);
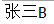
Map<Integer, String> map = new HashMap<Integer, String>();
map.put(1, "張三A");
map.put(2, "李四");
map.put(3, "王五");
Set<Integer> set = map.keySet(); // 得到全部的key
Collection<String> value = map.values(); // 得到全部的value
Iterator<Integer> iter1 = set.iterator();
Iterator<String> iter2 = value.iterator();
System.out.print("全部的key:");
while (iter1.hasNext()) {
System.out.print(iter1.next() + "、");
}
System.out.print("\n全部的value:");
while (iter2.hasNext()) {
System.out.print(iter2.next() + "、");
}
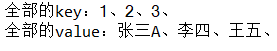
Map<String, String> map = new HashMap<String, String>();
map.put("ZS", "張三");
map.put("LS", "李四");
map.put("WW", "王五");
map.put("ZL", "趙六");
map.put("SQ", "孫七");
Set<String> set = map.keySet(); // 得到全部的key
Iterator<String> iter = set.iterator();
while (iter.hasNext()) {
String i = iter.next(); // 得到key
System.out.println(i + " --:> " + map.get(i));
}

注:HashMap鍵的資料物件,一定不能亂改,特別是自定義物件,因為key->value是根據哈希值進行查找,一旦改變將會丟失,
HashMap 與 Hashtable 的區別:

HasshMap,Hashtable,ConcurrentHashMap,三者最大的區別在于多執行緒,執行緒的安全,
HasshMap 執行緒不安全,效率高;Hashtable 執行緒安全,效率低,
ConcurrentHashMap采用分段鎖機制,保證執行緒安全,和效率高,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/33127.html
標籤:其他