做python可視化作業遇到好多問題,蹲個大佬指導我,都是很基礎的代碼!
uj5u.com熱心網友回復:
就是一個條形圖,一個餅圖,動態可視化還有地圖,我真的不會改了,救救孩子
uj5u.com熱心網友回復:
什么問題,說來聽聽uj5u.com熱心網友回復:
就是條形圖縱坐標不知道為什么反了,動態可視化和地圖用老師的代碼報錯不知道怎么改,餅圖資料處理就有問題,uj5u.com熱心網友回復:
要保密嗎 把代碼和 問題發出來 看看uj5u.com熱心網友回復:
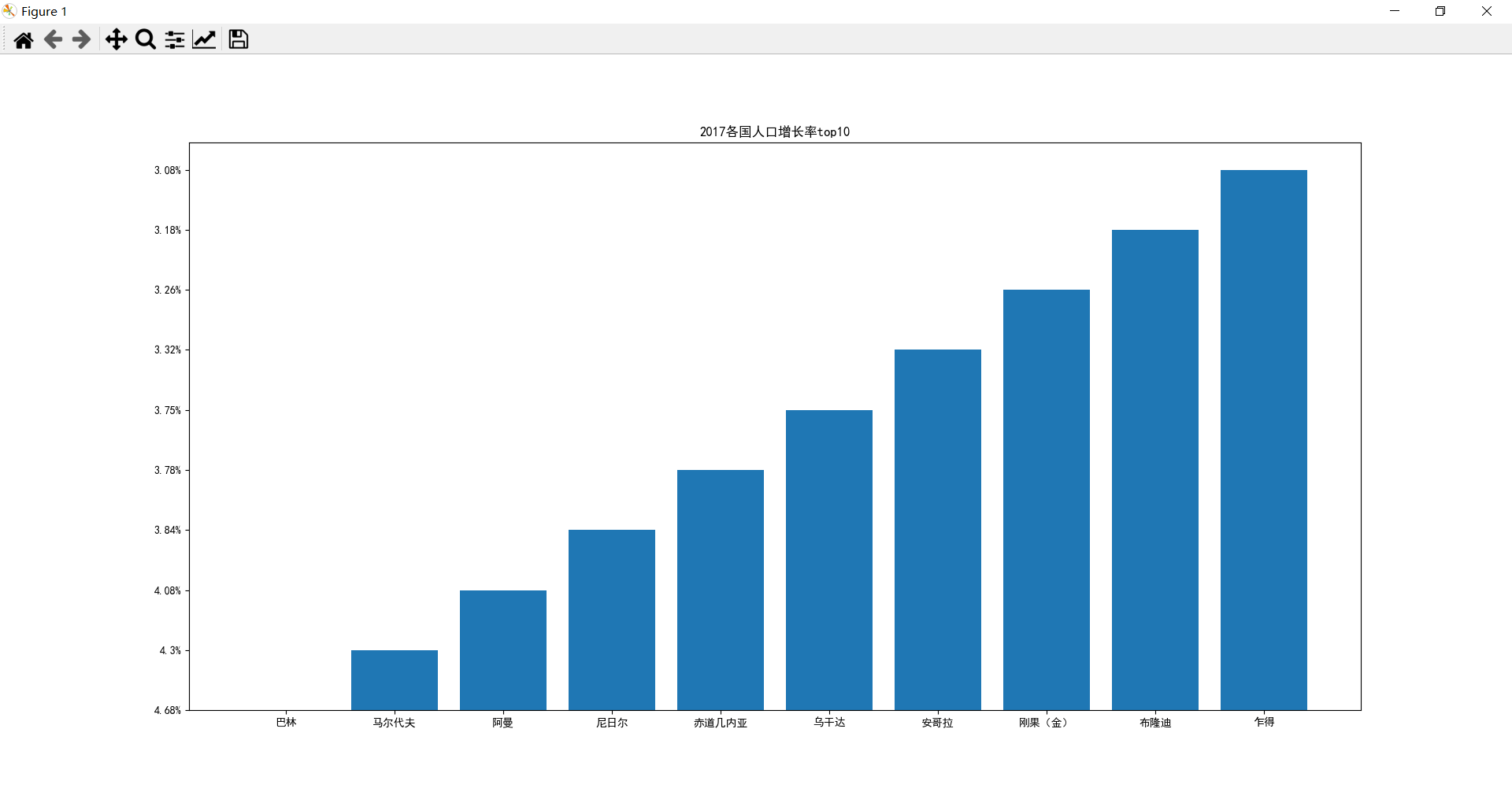
 為什么縱坐標從大到小
為什么縱坐標從大到小
uj5u.com熱心網友回復:
雖然不知道你源資料什么樣的,
但是有個方法可以試試,
在plt.show()之前加上一句 plt.gca().invert_yaxis() 試試
uj5u.com熱心網友回復:
加上整個就倒過來了,源資料是這樣的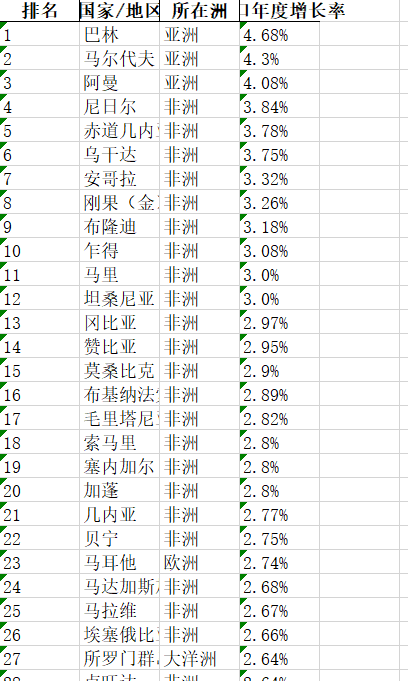
uj5u.com熱心網友回復:
額 我用你的資料都正常呢uj5u.com熱心網友回復:
好吧,謝謝。麻煩你了uj5u.com熱心網友回復:
這個是%分號的問題,去掉%分號正常uj5u.com熱心網友回復:
把你完整代碼和表插進來 我真想看看到底咋回事
uj5u.com熱心網友回復:
但是這個資料就帶著百分號,沒有別的辦法嗎?或者有什么函式可以去掉百分號嗎?uj5u.com熱心網友回復:
我帶著百分號也是正常的
uj5u.com熱心網友回復:
2017年各國人口年度增長率
一、Requetsts爬取頁面
import pandas as pd
import requests
from bs4 import BeautifulSoup #決議html網頁工具
url = 'https://www.kylc.com/stats/global/yearly/g_population_growth_perc/2017.html'
r = requests.get(url,timeout=30)
r.encoding = 'utf-8'
print(r.text)
2.定位人口增長率排名表格節點
# 根據獲取的檔案文本創建BeautifulSoup物件
soup = BeautifulSoup(r.text,'html.parser')
# prettify方法獲取整個html檔案字串
print(type(soup))
stb = soup.table
print(type(stb))
print(stb.prettify())
4.pandas獲取表格默認資料
# 讀取表格到dataframe
tb1 = pd.read_html(r.text)[0]
# 修改表頭
tb1.columns = ['排名', '國家/地區', '所在洲','人口年度增長率']
tb1=tb1.drop([39,80,121])
print(tb1)
tb1.to_excel('output.xlsx',sheet_name='ranklist',index=False)
2018年各國人口年度增長率
一、Requetsts爬取頁面
import pandas as pd
import requests
from bs4 import BeautifulSoup #決議html網頁工具
url = 'https://www.kylc.com/stats/global/yearly/g_population_growth_perc/2018.html'
r = requests.get(url,timeout=30)
r.encoding = 'utf-8'
print(r.text)
2.定位人口增長率排名表格節點?
# 根據獲取的檔案文本創建BeautifulSoup物件
soup = BeautifulSoup(r.text,'html.parser')
# prettify方法獲取整個html檔案字串
print(type(soup))
stb = soup.table
print(type(stb))
print(stb.prettify())
4.pandas獲取表格默認資料
# 讀取表格到dataframe
tb2 = pd.read_html(r.text)[0]
# 修改表頭
tb2.columns = ['排名', '國家/地區', '所在洲','人口年度增長率']
tb2=tb2.drop([39,80,121])
print(tb2)
tb2.to_excel('output2.xlsx',sheet_name='ranklist', index=False)
2017老年人人口比重
一、Requetsts爬取頁面
import pandas as pd
import requests
from bs4 import BeautifulSoup #決議html網頁工具
url = 'https://www.kylc.com/stats/global/yearly/g_population_65above_perc/2017.html'
r = requests.get(url,timeout=30)
r.encoding = 'utf-8'
print(r.text)
2.定位老年人人口比重排名表格節點
# 根據獲取的檔案文本創建BeautifulSoup物件
soup = BeautifulSoup(r.text,'html.parser')
# prettify方法獲取整個html檔案字串
print(type(soup))
stb = soup.table
print(type(stb))
print(stb.prettify())
4.pandas獲取表格默認資料
# 讀取表格到dataframe
tb3 = pd.read_html(r.text)[0]
# 修改表頭
tb3.columns = ['排名', '國家/地區', '所在洲','老年人(65歲及以上)占總人口比重']
tb3=tb3.drop([39,80,121])
print(tb3)
tb3.to_excel('output3.xlsx',sheet_name='ranklist', index=False)
2018老年人人口比重
一、Requetsts爬取頁面
import pandas as pd
import requests
from bs4 import BeautifulSoup #決議html網頁工具
url = 'https://www.kylc.com/stats/global/yearly/g_population_65above_perc/2018.html'
r = requests.get(url,timeout=30)
r.encoding = 'utf-8'
print(r.text)
2.定位老年人人口比重排名表格節點
# 根據獲取的檔案文本創建BeautifulSoup物件
soup = BeautifulSoup(r.text,'html.parser')
# prettify方法獲取整個html檔案字串
print(type(soup))
stb = soup.table
print(type(stb))
print(stb.prettify())
4.pandas獲取表格默認資料
# 讀取表格到dataframe
tb4 = pd.read_html(r.text)[0]
# 修改表頭
tb4.columns = ['排名', '國家/地區', '所在洲','老年人(65歲及以上)占總人口比重']
tb4=tb4.drop([39,80,121])
print(tb4)
tb4.to_excel('output4.xlsx',sheet_name='ranklist', index=False)
將表格保存多個sheet
writer = pd.ExcelWriter('-各國人口增長率及老齡化程度分析.xlsx')
tb1.to_excel(writer,sheet_name = '2017人口增長率排名',index = False)
tb2.to_excel(writer,sheet_name = '2018人口增長率排名',index = False)
tb3.to_excel(writer,sheet_name = '2017老年人人口比重排名',index = False)
tb4.to_excel(writer,sheet_name = '2018老年人人口比重排名',index = False)
writer.save()
表格的合并與處理
將兩年人口增長率sheets合并
import pandas as pd
feature1 = pd.read_excel('-各國人口增長率及老齡化程度分析.xlsx',sheet_name='2017人口增長率排名')
feature1.columns = ["排名","國家/地區","所在洲","人口年度增長率"]
feature1['年份']='2017'
print(feature1)
feature2 = pd.read_excel('-各國人口增長率及老齡化程度分析.xlsx',sheet_name='2018人口增長率排名')
feature2.columns = ["排名","國家/地區","所在洲","人口年度增長率"]
feature2['年份']='2018'
print(feature2)
writer = pd.ExcelWriter('-各國人口增長率及老齡化程度分析.xlsx',mode='a',engine='openpyxl')
result=pd.concat([feature1,feature2])
print(result)
result.to_excel(writer,sheet_name='2017、2018人口增長率',index=False)
writer.save()
合并2018年人口增長率與老年人比重
import pandas as pd
import numpy as np
?
writer = pd.ExcelWriter('-各國人口增長率及老齡化程度分析.xlsx',mode='a',engine='openpyxl')
tb2=pd.read_excel('-各國人口增長率及老齡化程度分析.xlsx',sheet_name='2018人口增長率排名',index_col=0)
tb4=pd.read_excel('-各國人口增長率及老齡化程度分析.xlsx',sheet_name='2018老年人人口比重排名',index_col=0)
df2=pd.merge(tb2, tb4,on='國家/地區',how='left')
df2=df2.drop(['所在洲_y'],axis=1)#洗掉無用列
df2.columns = ['國家/地區', '所在洲', '2018人口增長率','2018老年人人口比重']#修改列名
print(df2)
df2.to_excel(writer,sheet_name='2018人口增長與老年人比重',index=False,na_rep='')
writer.save()
資料分析與可視化
2017、2018年人口增長前10名的條形圖
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
?
writer = pd.ExcelWriter('-各國人口增長率及老齡化程度分析.xlsx',mode='a',engine='openpyxl')
tb1=pd.read_excel('-各國人口增長率及老齡化程度分析.xlsx',sheet_name='2017人口增長率排名')
tb2=pd.read_excel('-各國人口增長率及老齡化程度分析.xlsx',sheet_name='2018人口增長率排名')
dd1=tb1.iloc[0:10]
dd2=tb2.iloc[0:10]
print(dd1)
rf=['國家/地區','人口年度增長率']
rf1=dd1[rf]
rf1.columns=['國家/地區','增長率']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.bar(rf1['國家/地區'],rf1['增長率'])
plt.title('2017各國人口增長率top10')
plt.show()
完整的很長,上邊就是我爬取網頁,合并表格一類
uj5u.com熱心網友回復:
將rf1排一下序,既然默認的是倒序,那就rf1升序排一下uj5u.com熱心網友回復:
指的是rf1的增長率升序uj5u.com熱心網友回復:
怎么讓rf1升序排列?uj5u.com熱心網友回復:
用reverse報錯了uj5u.com熱心網友回復:
rf1.sort_values(by=['增長率'],ascending = True,inplace= True)uj5u.com熱心網友回復:
 這是什么錯誤?
這是什么錯誤?
uj5u.com熱心網友回復:
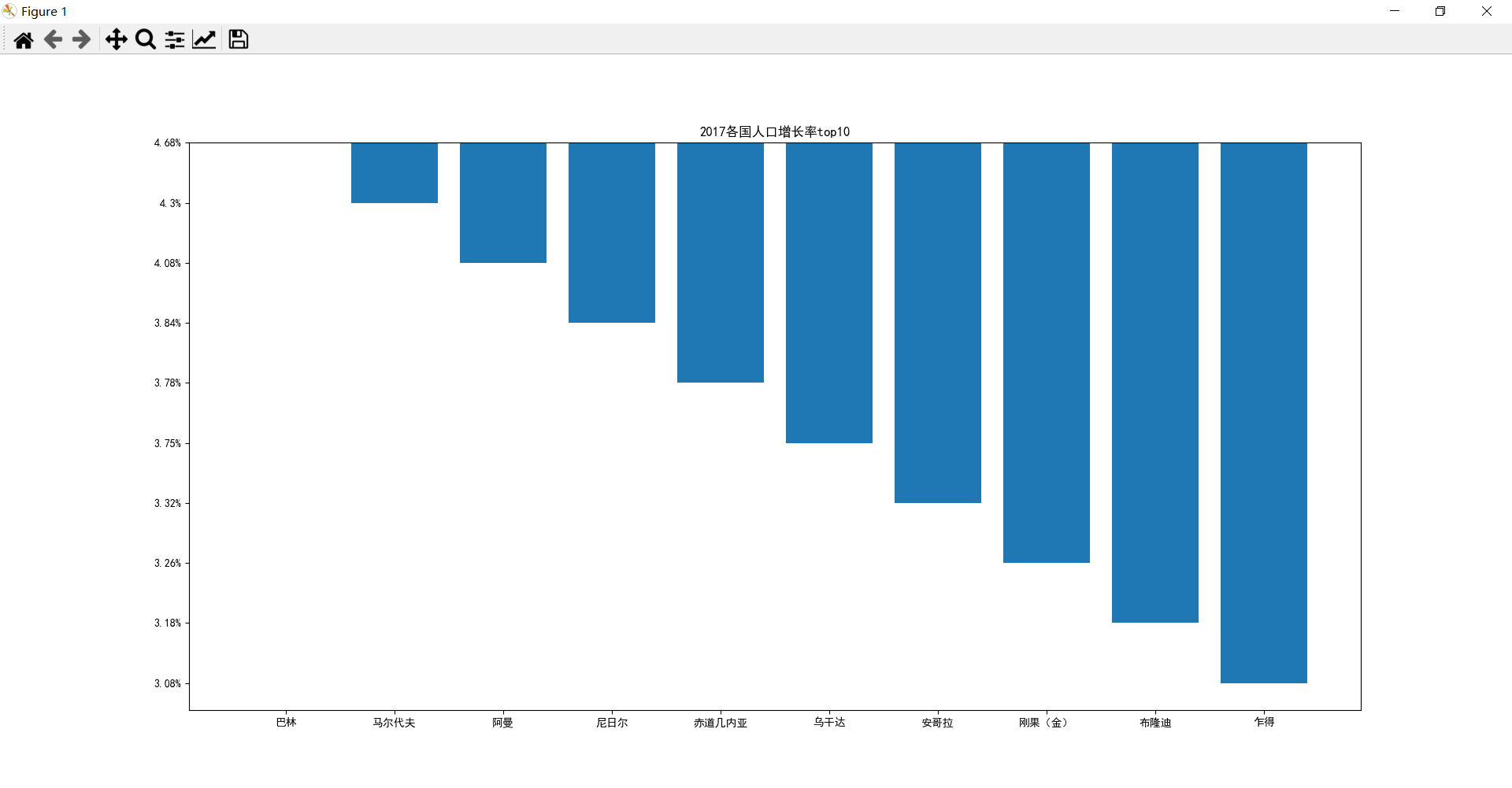
這是修改源資料的原因,做個拷貝再排序展示就可以了
rfx= rf1.copy()
rfx.sort_values(by=['增長率'],ascending = True,inplace= True)
plt.bar(rfx['國家/地區'], rfx['增長率'])
uj5u.com熱心網友回復:
解決了!!!太感謝你了uj5u.com熱心網友回復:
這不影響結果吧,只是個提示uj5u.com熱心網友回復:
這個太難了,技術性問題很復雜啊uj5u.com熱心網友回復:
 來看看你們怎么弄
來看看你們怎么弄
uj5u.com熱心網友回復:
rf1.sort_values(by=['增長率'],ascending = True,inplace= True)uj5u.com熱心網友回復:
借樓進來學習
uj5u.com熱心網友回復:
萌新瑟瑟發抖uj5u.com熱心網友回復:
帖子寫到的不錯,確實受益很多uj5u.com熱心網友回復:
下載需要積分,積分怎么來?uj5u.com熱心網友回復:
唉,發這么長的貼總之只要解決問題就好啊uj5u.com熱心網友回復:
秀啊,沒明白uj5u.com熱心網友回復:
我這兒有一個史上最難C++問題 還沒有得到解決呢uj5u.com熱心網友回復:
條圖,餅圖,散點圖,箱尾圖uj5u.com熱心網友回復:
【文哲講AI的個人主頁】長按復制此條訊息,長按復制打開抖音查看TA的更多作品##Hq2wTDqj798##[抖音口令]或者直接搜索:vince88888
在這里學下或者鞏固下基礎還是不錯的!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/33136.html
上一篇:【JAVA】360-2021校招筆試-技術綜合A卷-0911
下一篇:JAVA和Python有啥區別?