本文為論文閱讀筆記,僅用作學習記錄,Paper原文鏈接
注:本文提到的可轉移性也可以說是可移植性
背景介紹
??這篇文章是清華大學與英特爾中國實驗室在2018年聯合發布的一篇CVPR,主要提出了使用動量來增強對抗樣本的攻擊性,也就是在生成對抗樣本的迭代程序中加入動量從而使得對抗樣本具有較強的攻擊性,除此之外這篇文章提出的方法獲得了2017年NIPS比賽中無目標攻擊組與有目標攻擊組中的第一名,
對抗樣本目前存在的問題
??在文中,作者指出對于對抗樣本攻擊,目前大部分存在的對抗樣本攻擊的方法對于黑盒模型而言,成功率較低,而對于白盒攻擊而言,在知道模型的結構以及模型的引數,許多對抗樣本生成的方法都能利用生成的樣本以較高的成功率去攻擊模型,其中包括基于優化的方法Box Constrained L-BFGS、基于一步梯度的方法如FGSM(Fast Gradient Sign Method)又或者多步迭代的FGSM,但總而言之,對抗樣本一個更為嚴重的問題就是它需要良好的可轉移性,也就是說所生成的對抗樣本對于其它模型而言同樣是具有對抗性的,換句話說就是利用對抗樣本生成演算法生成的對抗樣本不僅對于一個模型攻擊可行,對于其它模型而言,同樣攻擊可行,這便是對抗樣本的可轉移性,對抗樣本的可轉移性基于這樣的一個事實,也就是不同的機器學習模型在一個資料點周圍學習到相似的(針對同一種機器學習或者深度學習任務,比如說影像分類)決策邊界,這就使得我們針對某個模型設計出來的對抗樣本對于其它模型同樣有效,所以總結起來如下:
- 對于白盒攻擊而言,目前的對抗樣本攻擊演算法已經比較完備了,效果呈現比較好
- 對于黑盒攻擊而言,那些在白盒攻擊上表現得很好演算法,在黑盒攻擊上往往以一個較低的成功率告終
- 對抗樣本良好的可轉移性是我們需要研究的目標,如何使我們生成的對抗樣本具有良好的可轉移性,這是一個問題
- 平衡好模型的攻擊能力與模型的可轉移性這是我們需要解決的
作者的Contributions
- 提出了一種叫做基于梯度的動量迭代演算法(MI-FGSM),能夠在損失函式的每一次迭代中積累梯度使得我們的優化得以穩定并且逃離區域最大值
- 研究了幾種集中同時攻擊多個模型的集成方法,保有較高的攻擊成功率,證明了演算法的轉移性
- 首個證明了即使通過集成對抗訓練得到的模型也容易被黑盒攻擊擊破
??作者在介紹完自己的contributions之后就對背景進行了介紹,其中介紹了什么是對抗樣本,對抗樣本是如何生成的,然后介紹了對抗攻擊的一些知識,這里介紹了三種型別的對抗樣本生成演算法,分別是一步梯度的方法、迭代的方法、基于優化的方法,一步梯度的方法簡單快速,但是準確率低,對于黑盒模型完全不行,可轉移性差,迭代方法比一步梯度的方法更好,但是耗時更長并且已經證明了迭代方法在白盒攻擊上比一步梯度的方法要好,但是代價卻是較差的可轉移性,而基于優化的方式與迭代的方法一樣在黑盒攻擊上缺乏攻擊力,
??然后作介紹了防御的方法,對對抗樣本的防御無非是在訓練的程序中加入對抗樣本來輔助訓練,通過在訓練的程序中加入對抗樣本,模型容易學會抵御那些在損失函式的梯度方向上生成的擾動,但是卻不能夠賦予對黑盒攻擊的魯棒性,因為對抗樣本的生成與正在訓練的模型的引數耦合了,所以集成對抗訓練的資料不僅要使用對抗樣本來增強訓練資料,還要使用其它hold-out模型的資料(例如有A、B、C、D四個模型,我們集成A、B、C三個模型進行集成對抗訓練,所以對抗樣本不僅來自于A、B、C,還來自于D),因此這個集成訓練的模型才會對一步攻擊魯棒,同時也對黑盒攻擊魯棒,
主要作業
基于梯度的動量迭代演算法
??演算法偽代碼如下圖所示,其實這個演算法與迭代模型下的FGSM差不多,唯一的區別就是在計算梯度的時候使用了動量的方式來計算梯度,想必我們對基于動量的梯度下降演算法并不陌生吧,這里先來說一下基于動量的梯度下降演算法,我們一般的梯度下降演算法在每次引數的更新中之和當前的梯度有關,并不涉及之前的梯度,而在動量梯度下降演算法中,在計算梯度的時候考慮到之前的梯度,所以梯度計算公式是這樣的 梯度 = 比例因子×上一次計算的梯度+當前梯度,我們可以思考下這樣做的目的,其實動量這里借用了物理學的概念,動量在物理學中是物體的質量與速度的乘積,我們可以考慮把梯度下降看成一個人在運動,每次求梯度就是得到一個命令,這個命令讓這個人怎么走,人在最開始接到命令后跑了起來,假設之后我們求得的梯度是之前運動的相反的方向,那么人需要忘相反的方向運動,由于人之前運動了具有速度,所以速度的方向并不會馬上減為0再反向,需要一個緩沖的時間,那么我們的梯度下降同樣如此,在回圈迭代的程序中也會出現這樣的情況,那么這種計算梯度的方式相當于考慮到之前的梯度作用了,這樣模擬了這個緩沖(如果沒有考慮先前的梯度,那么收到命令后馬上反向直接減小,但是考慮到先前的梯度,那么相當于減小的沒有那么嚴重,相當于模擬了緩沖也就是速度減小再增大的程序),動量梯度下降的好處一個是加速下降,另外一方面使得迭代跳出區域極小值點,從而找到全域極小值點,

??對于這個基于梯度的動量迭代演算法而言,輸入分類器 f 以及損失函式 j還有真實的輸入x以及我們的ground truth y,還有擾動的大小
?
\epsilon
?,以及回圈迭代的次數T和衰減引數
μ
\mu
μ,詳細步驟如下:
- 求出每次回圈擾動的大小 α = ? / T \alpha = \epsilon/T α=?/T
- 進行回圈,每次回圈中當前需要求的梯度總是等于上一次的梯度乘以衰減因子 μ \mu μ加上當前的梯度
- 更新當前擾動為上一次的擾動加上擾動步長 α \alpha α乘以梯度的方向
- 回圈直到結束
- 求得最后一次回圈求得的擾動即是我們最終的擾動,也就是我們生成的對抗樣本
??這個方法的思路其實挺簡單,直接借鑒了動量梯度下降的思想,因為我們求對抗樣本也是求梯度,不過是對損失函式求輸入的梯度,那么在多步迭代求梯度的程序中也會遇到像梯度下降程序中的容易陷入區域極小值點以及縱向震蕩嚴重的問題,所以帶有動量的對抗樣本攻擊方法,加速梯度求解的程序同時避免進入區域極小值或者區域極大值,
攻擊模型的集成
?? 作者在這里采用了三種集成策略,集成策略如下:
l
(
x
)
=
∑
k
=
1
K
ω
k
l
k
(
x
)
p
(
x
)
=
∑
k
=
1
K
ω
k
p
k
(
x
)
J
(
x
,
y
)
=
∑
k
=
1
K
w
k
J
k
(
x
,
y
)
\begin{aligned} & l(x) = \sum_{k=1}^{K}{\omega}_k{l_k(x)}\\ & \textbf{p}(x) = \sum_{k=1}^{K}\omega_k\textbf{p}_k{(x)}\\ & J(x,y) = \sum_{k=1}^{K}w_kJ_k(x,y)\\ \end{aligned}
?l(x)=k=1∑K?ωk?lk?(x)p(x)=k=1∑K?ωk?pk?(x)J(x,y)=k=1∑K?wk?Jk?(x,y)?
??這三種策略什么意思呢?這里解釋下,第一個策略這里的
l
k
(
x
)
l_k(x)
lk?(x)表示第k個模型,輸入為x,輸出的邏輯值,這里的logit value指的就是我們在分類任務的時候輸入到softmax的輸入值,這里的
w
k
w_k
wk?就表示每個模型的所占的權重,我們所有的權重加起來等于1(
∑
k
=
1
K
w
k
=
1
\sum_{k=1}^{K}w_k = 1
∑k=1K?wk?=1),相當于第一種策略集成了模型的logit,對于第二種策略,
p
(
x
)
p(x)
p(x)代表分類任務輸出的概率值,也就是經過softmax之后的輸出,而第三種集成策略則是集成損失函數,將損失函式根據權重占比相加,實驗表明第一種集成策略最優,在集成策略當中,我們的損失函式如下:
J
(
x
,
y
)
=
?
1
y
?
log
?
(
s
o
f
t
m
a
x
(
l
k
(
x
)
)
)
\begin{aligned} J(x,y) = -\textbf{1}_y·\log(softmax(\textbf{l}_k(x))) \\ \end{aligned}
J(x,y)=?1y??log(softmax(lk?(x)))?
??這里解釋下為什么要這樣集成,我們知道一般的對抗樣本攻擊方法都是對損失函式求輸入的梯度,所以損失函式對我們而言很重要,而上面幾種方式的集成,說到底就是對我們的損失函式做了一定的改變,第三種集成策略直接是損失函式按照權重相乘再相加,而第一、第二種都是在預測的輸出上做文章,這樣集成相當于考慮到了多種模型,所以才是集成,集成的詳細演算法流程如下:

實驗
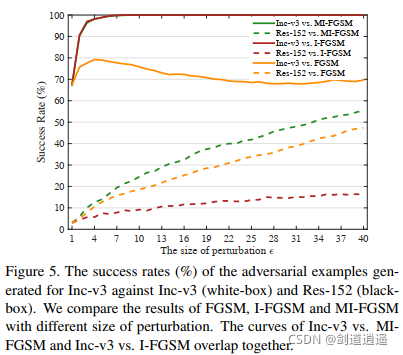
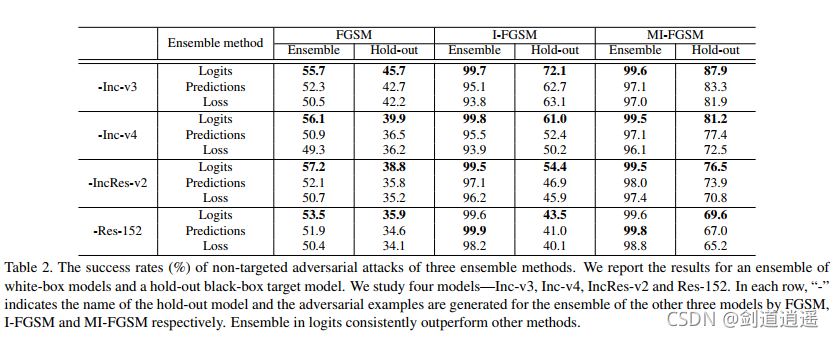
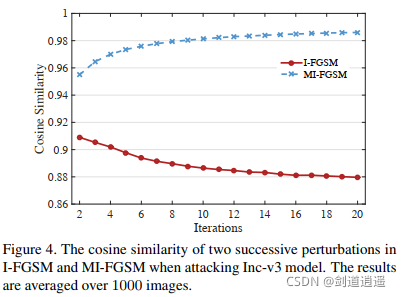
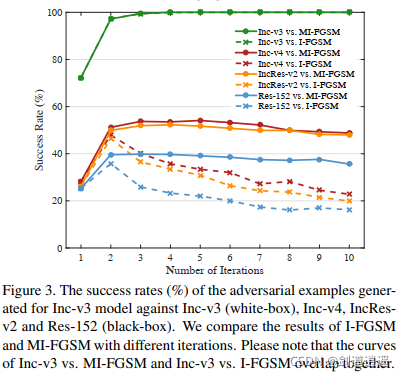
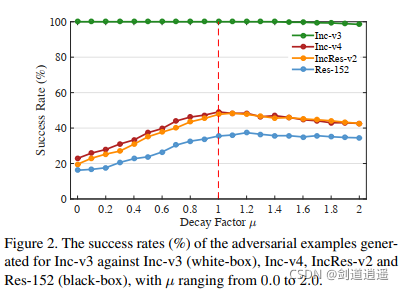
??作者做了幾個實驗,第一個實驗表明衰減因子 μ = 1 \mu = 1 μ=1的時候攻擊成功率最高,第二個實驗表明迭代的方法產生的對抗樣本容易過擬合白盒模型,不可能跨模型傳遞,但是基于動量的迭代方法有助于保持白盒攻擊和可轉移性之間的平衡,從而對白盒和黑盒模型同時顯現出很強的攻擊能力,第三個實驗證明了基于動量迭代的對抗樣本攻擊演算法的可轉移性,
參考文獻
[1] 大鯊魚沖鴨,2019.論文閱讀筆記. Boosting Adversarial Attacks with Momentum[DB/OL].[2021.10.22].https://blog.csdn.net/invokar/article/details/96697633
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/332186.html
標籤:其他
下一篇:python錯誤日志——神秘錯誤