
經過長達一個月的復現,終于成功利用MindSpore復現了SwinTransformer在imagenet上的分類精度,中間踩過很多的坑,這個帖子就作為復現SwinTransformer的記錄貼,希望能對大家復現2021年這種充滿訓練Trick的論文有所幫助,
復現著復現著突然Swin就拿了最佳論文了,當時感覺也非常有意思,突然就在復現ICCV2021的最佳論文了,模型的效果的確很炸裂,
博客所有的相關代碼已經上傳到我的碼云
修改完成后代碼將會合入MindSpore的model的models主倉,有需要的同學可以自取,
資料篇——資料增強
由于SwinTransformer原始碼是基于PyTorch和timm完成的,其中的AutoAugment雖然是基本基于PIL庫實作的,但是由于MindSpore本身影像庫介面和timm和PyTorch存在一定的區別,非常不易自己實作,
因此筆者選擇將timm的相關資料增強代碼復制到MindSpore中并且基于numpy對其中PyTorch的一部分完整修改,同時也可以認為相當于是MindSpore的dataset擴充了一個可以即插即用的AutoAugment,相關的介面和PyTorch完全統一(反正也是cv來的),可以作為未來復現此類論文的一個基本模板,代碼見我的倉庫swin_transformer/data/data_utils檔案夾
模型篇——混合精度
混合精度訓練方法是通過混合使用單精度和半精度資料格式來加速深度神經網路訓練的程序,同時保持了單精度訓練所能達到的網路精度,混合精度訓練能夠加速計算程序,同時減少記憶體使用和存取,并使得在特定的硬體上可以訓練更大的模型或batchsize,
這里我們主要針對MindSpore的混合精度和PyTorch(Apex)混合精度的區別做一些說明,
這里應該倒過來看,在筆者從模型訓練、資料、性能角度都匹配了原基于PyTorch的SwinTransformer后,模型在10輪的時候會比同期PyTorch低1-2個點,這讓人非常疑惑,因此最后聯想到了混合精度,(不確定最后能不能靠O2跑到,一次三天實在等不起,就選擇還是盡量同步原始碼了)
下面的理解是我基于MindSpore原始碼得到的,如果有錯誤希望指正,
首先是關于運算模式的一些定義:
- O0:純FP32訓練,可以作為accuracy的baseline;
- O1:混合精度訓練(推薦使用),根據黑白名單自動決定使用FP16(GEMM, 卷積)還是FP32(Softmax)進行計算,
- O2:“幾乎FP16”混合精度訓練,不存在黑白名單,除了BatchNorm,幾乎都是用FP16計算,
- O3:純FP16訓練,很不穩定,但是可以作為speed的baseline;
MindSpore擁有了O0、O2和O3,但是O1是預設的,對于O2和O3,唯一的區別就是BN層是fp32還是fp16,那就是說如果不使用BN層的大多數ViT,O2和O3是一樣的,
知道了這個區別之后,我們了解到Apex庫中有對于fp16和fp32在O1模式下的名單,見
list
可以看到,實際在O1模式下,softmax、layernorm這類對精度影響較大的模塊都會被保留在fp32,因此我們也選擇將這些模塊保存在fp32,進一步同步PyTorch,
關于轉fp32和fp16的操作,選擇直接去抄mindspore的amp.py檔案:
print(f"=> using amp_level {args.amp_level}")
# 轉換fp16
net.to_float(mstype.float16)
print(f"=> change {args.arch} to fp16")
# 轉換fp32,反正swin就用了幾個nn.Conv2d,主要還是nn.Dense,我就索性轉fp32了
cell_types = (nn.GELU, nn.Softmax, nn.Conv2d, nn.Conv1d, nn.BatchNorm2d, nn.LayerNorm)
_do_keep_fp32(net, cell_types)
print(f"=> cast {cell_types} to fp32 back")
class OutputTo16(nn.Cell):
"Wrap cell for amp. Cast network output back to float16"
def __init__(self, op):
super(OutputTo16, self).__init__(auto_prefix=False)
self._op = op
def construct(self, x):
return F.cast(self._op(x), mstype.float16)
def _do_keep_fp32(network, cell_types):
cells = network.name_cells()
change = False
for name in cells:
subcell = cells[name]
if subcell == network:
continue
elif isinstance(subcell, cell_types):
network._cells[name] = OutputTo16(subcell.to_float(mstype.float32))
change = True
else:
# 這里是遞回呼叫
_do_keep_fp32(subcell, cell_types)
if isinstance(network, nn.SequentialCell) and change:
network.cell_list = list(network.cells()
經過手動的MindSpore的O1模式轉換后,十輪同期的精度正常了,然后可以放心往下跑了,
模型篇——性能調優
相對于V100 GPU來說,MindSpore基于CANN,擁有更加優秀的矩陣計算演算法,這點非常贊,同時MindSpore的on-device執行 - MindSpore master documentation可以極大的提高資料加載和模型運行的效率,
相應的,目前讓人感覺最深刻的就是MindSpore目前對于索引的優化可以說是相當不靠譜了,一旦模型中出現大量的索引算子,整個模型是性能會急劇下滑,甚至單步訓練時長可能是同等條件下V100GPU的四五倍,
這里舉幾個例子,希望可以作為目前Ascend910性能瓶頸經典的幾個坑:
例1 qkv范式的不同寫法
"""qkv注意力寫法1"""
self.qkv = nn.Dense(in_channels=dim, out_channels=dim * 3, has_bias=qkv_bias)
qkv = ops.Reshape()(self.qkv(x), (B_, N, 3, self.num_heads, C // self.num_heads))
qkv = ops.Transpose()(qkv, (2, 0, 3, 1, 4))
q, k, v = qkv[0]*self.scale, qkv[1], qkv[2]
"""qkv注意力寫法2"""
self.q = nn.Dense(in_channels=dim, out_channels=dim, has_bias=qkv_bias)
self.k = nn.Dense(in_channels=dim, out_channels=dim, has_bias=qkv_bias)
self.v = nn.Dense(in_channels=dim, out_channels=dim, has_bias=qkv_bias)
q = ops.Reshape()(self.q(x), (B_, N, self.num_heads, C // self.num_heads))
k = ops.Reshape()(self.k(x), (B_, N, self.num_heads, C // self.num_heads))
k = ops.Transpose()(k, (0, 1, 3, 2))
v = ops.Reshape()(self.v(x), (B_, N, self.num_heads, C // self.num_heads))
這兩種方法是目前最主流的self attention范式,在Ascend910上,強烈要求使用寫法2,雖然這兩者得到的最后解決是相同的,但是由于寫法1用到了索引操作(哪怕的qkv[0]這么一點),在SwinTransformer上swin_tiny模型的單步訓練時長會白白增加100ms最后(大約從600ms左右到700ms+),性能差距非常大,
例2 用reshape和Transpose代替一部分典型索引
"""寫法1"""
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
"""寫法2"""
x = P.Reshape()(x, (B, self.H_2, 2, self.W_2, 2, self.dim))
x = P.Transpose()(x, (0, 1, 3, 4, 2, 5))
x = P.Reshape()(x, (B, self.H2W2, self.dim_mul_4))
很容易可以理解,兩者都是做了一個類似于反上采樣和PixelShuffle的操作,將像素重排,這個形式的非常規則的,而且輸入輸出數量也是相同的,
在這種情況下,切記要使用同等的reshape操作,這個操作在這個模型使用較多的情況下,可以為模型再一次節約大量的時間,swin_tiny節約了大概150ms/step
容易知道,當kernel_size=strides的unfold的時候,也推薦之后這種方式,此處略過,
例3 用矩陣乘法代替索引
"""寫法1"""
a = [1, 2, 3]
index = 2
a[index] => 3
"""寫法2"""
a = [1, 2, 3]
index = 2
one_hot_index = [0, 0, 1] # predefine
a dot one_hot_index.T => 3
這里由于篇幅問題,不拿SwinTransformer的代碼做說明(參見relative_position_index的使用處),簡單說就是在索引固定的情況下,使用onehot和矩陣乘法來代替索引,只要索引夠多,這種方法能為模型性能做很大貢獻,
關于如何使用MindSpore的Profiler的性能除錯工具,可以參見我的師兄的帖子
【昇騰眾智】RetinaFace_ResNet50模型的910訓練+310推理
模型篇——模型訓練
關于如何使用MindSpore進行自定義訓練,可以參考我的博客如何實作MindSpore自定義訓練
這里主要對之前的博客留下來的問題進行一些解決(感覺昱峰哥提的建議,深受啟發):
異構并行訓練
異構并行訓練方法是通過分析圖上算子記憶體占用和計算密集度,將記憶體消耗巨大或適合CPU邏輯處理的算子切分到CPU子圖,將記憶體消耗較小計算密集型算子切分到硬體加速器子圖,框架協同不同子圖進行網路訓練,使得處于不同硬體且無依賴關系的子圖能夠并行進行執行的程序,
首先是關于異構并行計算方面的優化:
驅動源自MindSpore的這句話:在盤古或GPT3大模型訓練程序中,優化器狀態占用了大量記憶體,進而限制了可訓練的模型規模,使用優化器異構,將優化器指定到CPU上執行,可以極大擴展可訓練模型規模,
結合這兩句話,我們很容易意識到,模型的權重保存和更新正好非常符合這種記憶體大且運算少的特性,之前那種將grad_sum和zero_op放在顯存中運算是不合理的,我們要將這種運算都放在CPU里面去,為模型節約寶貴的顯存,因此在這里我們對之前的操作進行一些優化:
- 不再自己重寫TrainOneStepCell,而是從nn.TrainOneStepWithLossScaleCell繼承(這個Cell包含了自動過濾overflow的梯度),減少實際的代碼量,特別是關于分布式運算的管理,
- 將_sum_op和_clear_op全部丟到CPU里面去,根據異構計算中的模板即可
assignadd = P.AssignAdd()
assignadd.add_prim_attr("primitive_target", "CPU")
進一步的,考慮到在保存最后的權重的會包括grad_sum和zeros權重,這樣子加上原來的optimizer包含的權重,相當于存了四個模型的大小權重,有什么方法可以優化呢?
我們可以去除zeros權重:
_sum_op = C.MultitypeFuncGraph("grad_sum_op")
assignadd = P.AssignAdd()
assignadd.add_prim_attr("primitive_target", "CPU")
# 相當于執行a -= a,a減去自己就可以得到0
self.hyper_map(F.partial(_sum_op), self._grad_sum, -self._grad_sum)
配合上clip_grad_norm,我們成功的從資料和模型都對原來基于PyTorch的SwinTransformer進行了全方位的復現,然后就該去ModelArts進行訓練了~ 沖沖沖
ModelArts使用篇
ModelArts 是面向開發者的一站式 AI 開發平臺,為機器學習與深度學習提供海量資料預處理及互動式智能標注、大規模分布式訓練、自動化模型生成,及端-邊-云模型按需部署能力,幫助用戶快速創建和部署模型,管理全周期 AI 作業流,
上面的介紹摘自華為云的官方,也就當個大概的介紹,大家可以將這個理解成一個高效的深度學習平臺吧,
首先簡單介紹一個華為云ModelArts使用的感受:
- 快:不知道是由于Ascend910ProA和Ascend910B的不同,相同的代碼在ModelArts跑起來就是比線下的910B服務器要快100ms/step左右,猜想有可能是因為云服務器環境穩定,或者就是傳說中的ModelArts對分布式運算做了特定優化,
- 開銷大:V100八卡需要195一小時,Ascend910八卡155一小時,SwinTransformer一跑就是3天,1w代金券直接走了 T T
- 難入門,入門后很方便:要不是本地的910NPU資源不夠,內心一直是很抗拒使用云服務器的,因為當時缺少合適的檔案,官網的教程還誤導了我,導致學習成本極高,后來在自己的摸索下,終于解決了其中的坑點,直到后來群里才發了使用檔案才發現坑白踩了,這里推薦一份很詳細的檔案,來自東北大學的一位老兄,寫的非常詳細:【ModelArts】鵬城云腦實驗平臺(華為云ModelArts)使用教程
解決完之后就可以安心訓練,并且可以保存訓練引數,啟動訓練只需要動動滑鼠,再也不用敲命令列寫腳本了!
結果篇
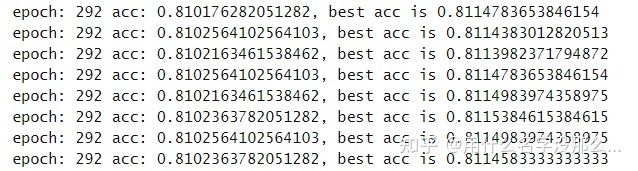
論文當時拿他的權重跑出來是81.15%,復現了一個月,終于到了,果然這種論文還是得各種同步作者的操作~,
這一個月踩了各種MindSpore的坑,感覺自己更懂MindSpore了,
感謝鵬城實驗室提供的計算資源、華為作業人員的配合與問題的解答、除錯群同學的幫助,希望大家都能調出自己的模型指標,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/332191.html
標籤:其他
上一篇:CV方向電子書推薦(持續更新)