目標檢測 YOLOv5 - 模型壓縮
flyfish
1 什么是剪枝
YOLOv5自帶的模型壓縮是怎樣的呢?就是剪枝,
在一棵樹中,把不重要的枝條剪掉,就是剪枝
園丁的手藝是不同的,不同的園丁剪的效果不同,
做模型的剪枝與園丁干得作業是一模一樣,先看一個回歸實體
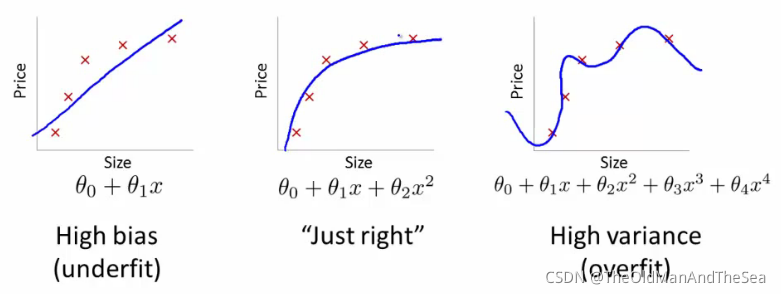
擬合資料的結果有正合適,欠擬合,過擬合
直線就是欠擬合,一個每個資料點都經過的曲線就是過擬合了
再看他們的數學運算式,多項式的最高次數是不同的,剪枝就像去掉上圖中3次方項和4次方項
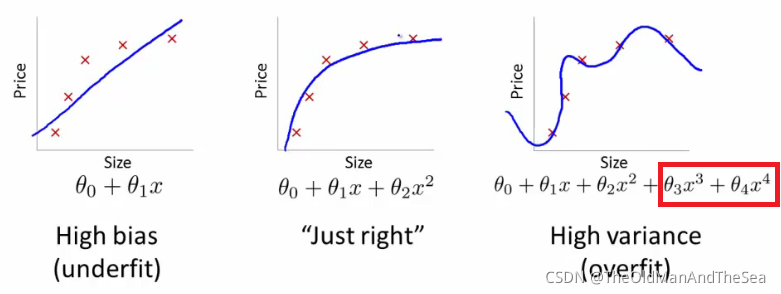
剪枝方法多,因為把不重要的東西去掉,在定義什么東西不重要,各家有各家的方法
如果把項剪的太多了,曲線就變成值線了,這不是我們想要的,
當過擬合的時候,剪太多就把樹枝剪的沒剩幾根,了就變成欠擬合;如果已經擬合的很合適了,再剪也欠擬合了,
期望是精度和召回率都不降低,降低的只有計算量
剪枝的生物學啟示
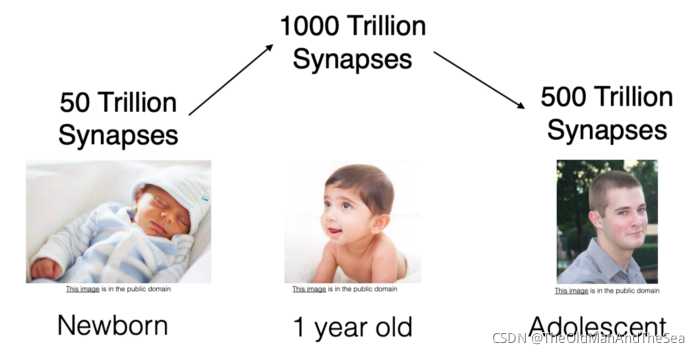
深度學習的剪枝被認為是人腦中突觸剪枝的一個想法,在人腦中之間發生的突觸消除,修剪突觸從出生時開始,一直持續到20多歲左右,
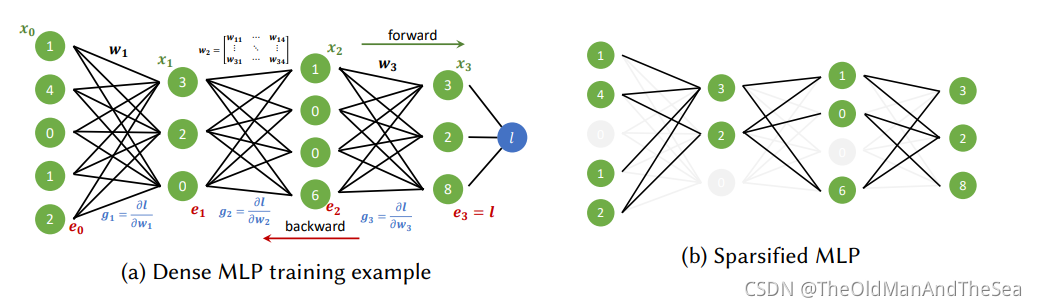
看一個神經網路
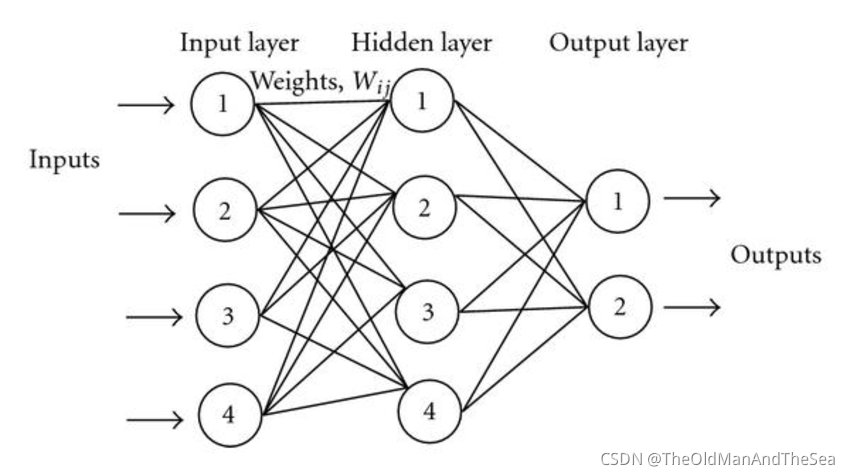
圈與圈之間的連線就是權重,權重也就是一堆堆的數
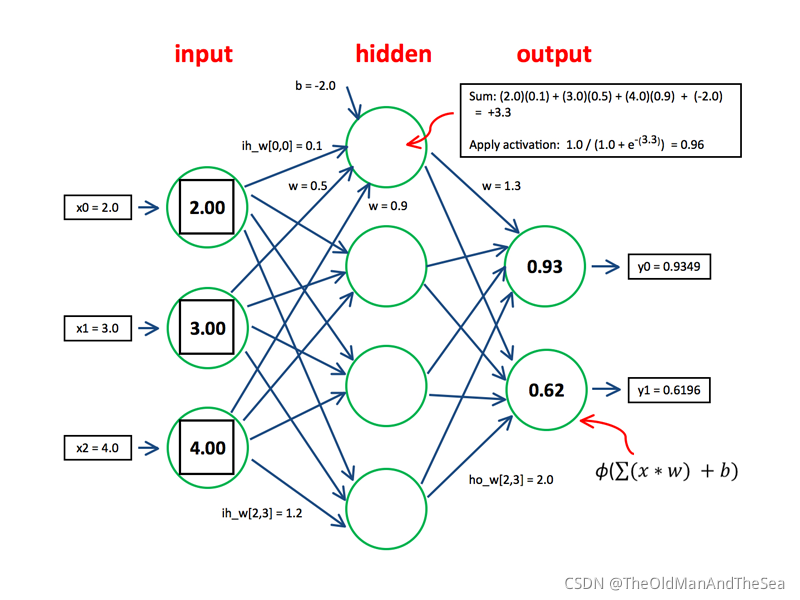
剪節點的可以叫 pruning node 或者 pruning neurons 剪神經元
剪線的可以叫 pruning connections 或者叫 pruning synapses 剪突觸,剪權重
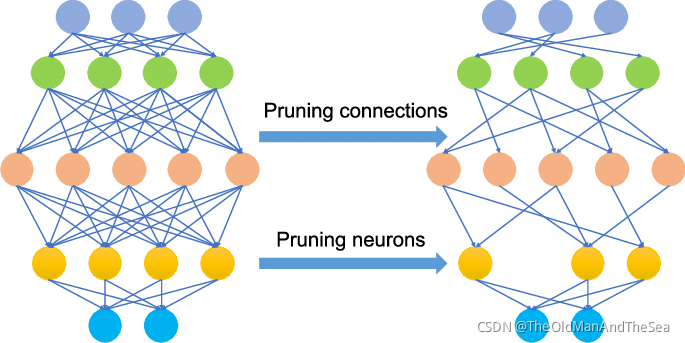
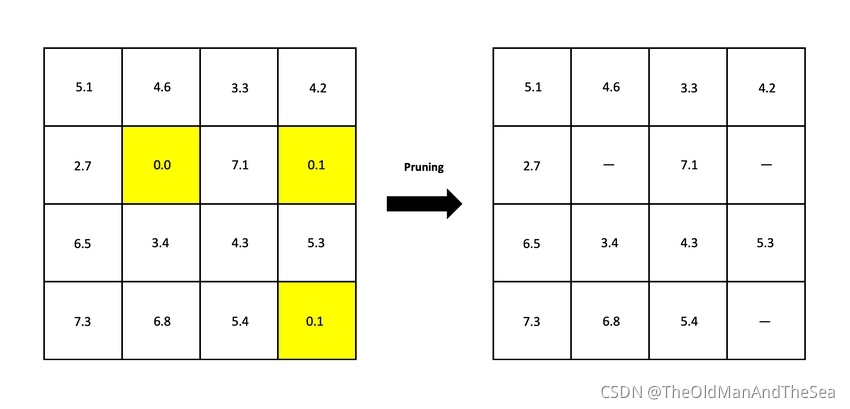
剪的結果
左圖是原始權重矩陣,右圖是閾值為0.1的修剪后的矩陣,高亮顯示的權重將被洗掉或者置零,
weight剪枝的實作
怎么實作呢
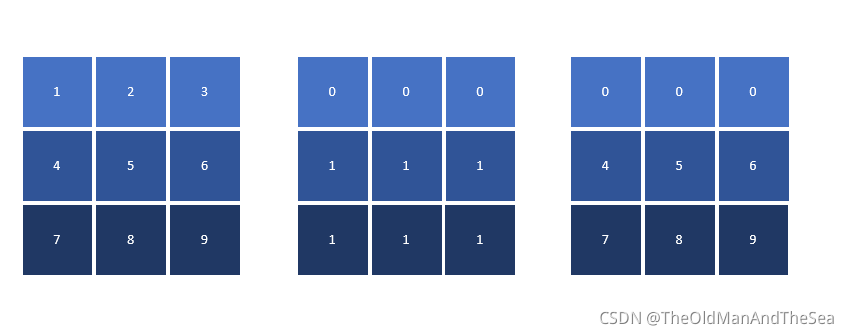
原始的矩陣 * weight_mask = 新的矩陣
這樣知道了代碼里的weight_mask 和 bias_mask是個什么意思
彩票假說:尋找稀疏的、可訓練的神經網路
彩票假說簡單說就是是主要是隨機初始化的密集神經網路包含一個初始化的子網,通過隨機初始化權重的子網路仍可以達到原始網路的精度.
剪枝有unstructured和structured,這兩者有什么區別
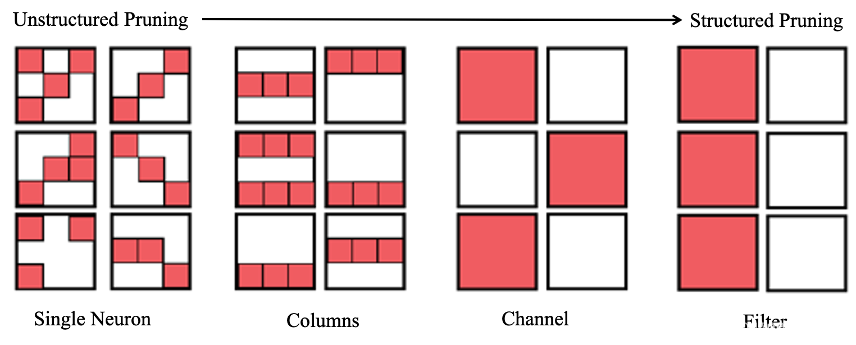
非結構化(左)和結構化(右)剪枝的區別:結構化剪枝去除卷積濾波器和內核行,而不僅僅是剪枝連接,
結構化剪枝和非結構化剪枝的主要區別在于剪枝權重的粒度,
非結構化剪枝主要是對單個權重進行裁剪
結構化剪枝的粒度較大,主要是把整行整列的權重移除掉(即把一個神經元去掉),對channel和Filter維度進行裁剪,
可以反過來說因為對單個權重進行裁剪的結果是unstructured,看上去有點亂,對channel和Filter裁剪的結果是structured的,根據裁剪之后是否保持了structe起了一個名字
YOLOv5的剪枝是怎么操作的
YOLOv5提供的一段剪枝代碼
def sparsity(model):
# Return global model sparsity
a, b = 0., 0.
for p in model.parameters():
a += p.numel()
b += (p == 0).sum()
return b / a
def prune(model, amount=0.3):
# Prune model to requested global sparsity
import torch.nn.utils.prune as prune
print('Pruning model... ', end='')
for name, m in model.named_modules():
if isinstance(m, nn.Conv2d):
prune.l1_unstructured(m, name='weight', amount=amount) # prune
prune.remove(m, 'weight') # make permanent
print(' %.3g global sparsity' % sparsity(model))
寫一段代碼把YOLOv5的剪枝代碼用上去,查看剪枝前和剪枝后的區別
import torch
from torch import nn
import torch.nn.utils.prune as prune
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def sparsity(model):
# Return global model sparsity
a, b = 0., 0.
for p in model.parameters():
a += p.numel()
b += (p == 0).sum()
return b / a
def prune(model, amount=0.3):
# Prune model to requested global sparsity
import torch.nn.utils.prune as prune
print('Pruning model... ', end='')
for name, m in model.named_modules():
if isinstance(m, nn.Conv2d):
prune.l1_unstructured(m, name='weight', amount=amount) # prune
prune.remove(m, 'weight') # make permanent
print(' %.3g global sparsity' % sparsity(model))
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 1 input image channel, 6 output channels, 3x3 square conv kernel
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5x5 image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, int(x.nelement() / x.shape[0]))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model = LeNet().to(device=device)
module = model.conv1
print(list(module.named_parameters()))
prune(module, amount=0.3)
print(list(module.named_parameters()))
剪枝前
[('weight', Parameter containing:
tensor([[[[-0.2032, -0.0269, -0.0981],
[-0.1920, -0.2737, 0.2451],
[ 0.1116, 0.1331, 0.0147]]],
...
[[[ 0.3109, 0.0082, -0.0080],
[-0.3009, -0.0805, -0.0308],
[-0.0347, -0.2851, 0.1614]]]], device='cuda:0', requires_grad=True)), ('bias', Parameter containing:
tensor([-0.0874, 0.2916, 0.2522, 0.2425, -0.2085, 0.2855], device='cuda:0',
requires_grad=True))]
剪枝后
Pruning model... 0.267 global sparsity
[('bias', Parameter containing:
tensor([-0.0874, 0.2916, 0.2522, 0.2425, -0.2085, 0.2855], device='cuda:0',
requires_grad=True)), ('weight', Parameter containing:
tensor([[[[-0.2032, -0.0000, -0.0981],
[-0.1920, -0.2737, 0.2451],
[ 0.1116, 0.1331, 0.0000]]],
...
[[[ 0.3109, 0.0000, -0.0000],
[-0.3009, -0.0805, -0.0000],
[-0.0000, -0.2851, 0.1614]]]], device='cuda:0', requires_grad=True))]
我們看到不重要的權重變成了0
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/332193.html
標籤:其他