文章目錄
- 一、基于CNN的樣式遷移
- 1. 直觀理解樣式遷移
- 2. 基于CNN的樣式遷移方法
- 二、樣式遷移實作
- 1. 閱讀內容和樣式影像
- 2. 預處理和后處理
- 3. 抽取影像特征
- 4. 定義損失函式
- 4.1 內容損失
- 4.2 樣式損失
- 4.3 總變差損失
- 4.4 總損失加權
- 5. 初始化合成影像
- 6. 模型訓練
- 三、總結
一、基于CNN的樣式遷移
1. 直觀理解樣式遷移
??如果你是一位攝影愛好者,你也許接觸過濾鏡,它能改變照片的顏色樣式,從而使風景照更加銳利或者令人像更加美白,但一個濾鏡通常只能改變照片的某個方面,如果要照片達到理想中的樣式,你可能需要嘗試大量不同的組合,這個程序的復雜程度不亞于模型調參,
在本節中,我們將介紹如何使用卷積神經網路,自動將一個影像中的樣式應用在另一影像之上,即樣式遷移(style transfer),這里我們需要兩張輸入影像:一張是內容影像,另一張是樣式影像(注意:內容圖和樣式圖都是我們的輸入,和之前的一張輸入影像是明顯不相同的),我們將使用神經網路修改內容影像,使其在樣式上接近樣式影像,
例如,下圖中影像為李沐沐神在西雅圖郊區的雷尼爾山國家公園拍攝的風景照,而樣式影像則是一幅主題為秋天橡樹的油畫,最終輸出的合成影像應用了樣式影像的油畫筆觸讓整體顏色更加鮮艷,同時保留了內容影像中物體主體的形狀,


2. 基于CNN的樣式遷移方法
下面的圖中用簡單的例子闡述了基于卷積神經網路的樣式遷移方法,
- 首先,我們初始化合成影像,例如將其初始化為內容影像(初始化成什么都沒關系,可以嘗試不同的初始化),該合成影像是樣式遷移程序中唯一需要更新的變數,即樣式遷移所需迭代的模型引數,
- 然后,我們選擇一個預訓練的卷積神經網路來抽取影像的特征,其中的模型引數在訓練中無須更新,這個深度卷積神經網路憑借多個層逐級抽取影像的特征,我們可以選擇其中某些層的輸出作為內容特征或樣式特征,(越是接近底層,抽取的特征越是全域化)
以下圖為例,這里選取的預訓練的神經網路含有3個卷積層,其中第二層輸出內容特征,第一層和第三層輸出樣式特征,
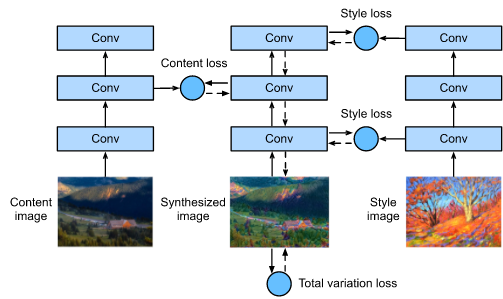
接下來,我們通過正向傳播(實線箭頭方向)計算樣式遷移的損失函式,并通過反向傳播(虛線箭頭方向)迭代模型引數,即不斷更新合成影像,
樣式遷移常用的損失函式由3部分組成:
- (i) 內容損失使合成影像與內容影像在內容特征上接近;
- (ii) 樣式損失使合成影像與樣式影像在樣式特征上接近;
- (iii) 總變差損失則有助于減少合成影像中的噪點,
最后,當模型訓練結束時,我們輸出樣式遷移的模型引數,即得到最終的合成影像,
在下面,我們將通過代碼來進一步了解樣式遷移的技術細節,
二、樣式遷移實作
1. 閱讀內容和樣式影像
首先,我們讀取內容和樣式影像,
從列印出的影像坐標軸可以看出,它們的尺寸并不一樣,
%matplotlib inline
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
import os
import matplotlib.pyplot as plt
d2l.set_figsize()
content_img = d2l.Image.open('./course_file/pytorch/img/rainier.jpg')
d2l.plt.imshow(content_img)

style_img = d2l.Image.open('./course_file/pytorch/img/autumn-oak.jpg')
d2l.plt.imshow(style_img);

2. 預處理和后處理
"""
下面,定義影像的預處理函式和后處理函式,
預處理函式`preprocess`對輸入影像在RGB三個通道分別做標準化,并將結果變換成卷積神經網路接受的輸入格式,
后處理函式`postprocess`則將輸出影像中的像素值還原回標準化之前的值,
由于影像列印函式要求每個像素的浮點數值在0到1之間,我們對小于0和大于1的值分別取0和1,
"""
rgb_mean = torch.tensor([0.485, 0.456, 0.406])
rgb_std = torch.tensor([0.229, 0.224, 0.225])
def preprocess(img, image_shape):
"""圖片變為tensor"""
transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize(image_shape),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=rgb_mean, std=rgb_std)])
return transforms(img).unsqueeze(0)
def postprocess(img):
"""tensor變為圖片"""
img = img[0].to(rgb_std.device)
img = torch.clamp(img.permute(1, 2, 0) * rgb_std + rgb_mean, 0, 1)
return torchvision.transforms.ToPILImage()(img.permute(2, 0, 1))
3. 抽取影像特征
# 我們使用基于ImageNet資料集預訓練的VGG-19模型來抽取影像特征,
pretrained_net = torchvision.models.vgg19(pretrained=True)
pretrained_net
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(17): ReLU(inplace=True)
(18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(24): ReLU(inplace=True)
(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(26): ReLU(inplace=True)
(27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): ReLU(inplace=True)
(32): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(33): ReLU(inplace=True)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): ReLU(inplace=True)
(36): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
為了抽取影像的內容特征和樣式特征,我們可以選擇VGG網路中某些層的輸出,
一般來說:
- 越靠近輸入層,越容易抽取影像的細節資訊;
- 反之,則越容易抽取影像的全域資訊,
??為了避免合成影像過多保留內容影像的細節,我們選擇VGG較靠近輸出的層,即內容層,來輸出影像的內容特征,我們還從VGG中選擇不同層的輸出來匹配區域和全域的樣式,這些圖層也稱為樣式層,正如vgg網路中所介紹的,VGG網路使用了5個卷積塊,實驗中,我們選擇第四卷積塊的最后一個卷積層作為內容層,選擇每個卷積塊的第一個卷積層作為樣式層,這些層的索引可以通過打pretrained_net實體獲取,
style_layers, content_layers = [0, 5, 10, 19, 28], [25] # 越小越靠近輸入(區域樣式),越大越靠近輸出(全域樣式)
??使用VGG層抽取特征時,我們只需要用到從輸入層到最靠近輸出層的內容層或樣式層之間的所有層,下面構建一個新的網路net,它只保留需要用到的VGG的所有層,
# 丟棄最大層之后的層
net = nn.Sequential(*[
pretrained_net.features[i]
for i in range(max(content_layers + style_layers) + 1)])
??給定輸入X,如果我們簡單地呼叫前向計算net(X),只能獲得最后一層的輸出,由于我們還需要中間層的輸出,因此這里我們逐層計算,并保留內容層和樣式層的輸出,
def extract_features(X, content_layers, style_layers):
"""輸入X,獲取內容層和樣式層的輸出"""
contents = []
styles = []
for i in range(len(net)):
X = net[i](X)
if i in style_layers:
styles.append(X)
if i in content_layers:
contents.append(X)
return contents, styles
# 因為訓練的時候無需改變預訓練的VGG的引數,所以我們可以在訓練開始之前抽取內容特征和樣式特征
# 由于合成影像是樣式遷移時所需要迭代的模型引數,我們只能在訓練程序中呼叫extract_features函式來抽取合成影像的內容特征和樣式特征
def get_contents(image_shape, device):
"""對內容影像抽取內容特征"""
content_X = preprocess(content_img, image_shape).to(device)
contents_Y, _ = extract_features(content_X, content_layers, style_layers)
return content_X, contents_Y
def get_styles(image_shape, device):
"""對樣式影像抽取樣式特征"""
style_X = preprocess(style_img, image_shape).to(device)
_, styles_Y = extract_features(style_X, content_layers, style_layers)
return style_X, styles_Y
4. 定義損失函式
下面我們來描述樣式遷移的損失函式,它由內容損失、樣式損失和總變差損失3部分組成,
4.1 內容損失
??與線性回歸中的損失函式類似,內容損失通過平方誤差函式衡量合成影像與內容影像在內容特征上的差異,平方誤差函式的兩個輸入均為extract_features函式計算所得到的內容層的輸出,
def content_loss(Y_hat, Y):
"""合成影像與內容影像在內容特征上的差異"""
# 我們從動態計算梯度的樹中分離目標:
# 這是一個規定的值,而不是一個變數,
return torch.square(Y_hat - Y.detach()).mean()
4.2 樣式損失
??對于樣式,我們將其看作是像素點在每個通道統計分布,例如要匹配兩張圖片的顏色,我們的一個做法就是匹配這兩張圖片在RGB三個通道上的直方圖,
??樣式損失與內容損失類似,也通過平方誤差函式衡量合成影像與樣式影像在樣式上的差異,為了表達樣式層輸出的樣式,我們先通過extract_features函式計算樣式層的輸出,假設該輸出的樣本數為1,通道數為
c
c
c,高和寬分別為
h
h
h和
w
w
w,我們可以將此輸出轉換為矩陣
X
\mathbf{X}
X,其有
c
c
c行和
h
w
hw
hw列,這個矩陣可以被看作是由
c
c
c個長度為
h
w
hw
hw的向量
x
1
,
…
,
x
c
\mathbf{x}_1, \ldots, \mathbf{x}_c
x1?,…,xc?組合而成的,其中向量
x
i
\mathbf{x}_i
xi?代表了通道
i
i
i 上的樣式特征,
??在這些向量的格拉姆矩陣
X
X
?
∈
R
c
×
c
\mathbf{X}\mathbf{X}^\top \in \mathbb{R}^{c \times c}
XX?∈Rc×c 中,
i
i
i 行
j
j
j 列的元素
x
i
j
x_{ij}
xij? 即向量
x
i
\mathbf{x}_i
xi? 和
x
j
\mathbf{x}_j
xj? 的內積,它表達了通道
i
i
i 和通道
j
j
j 上樣式特征的相關性,我們用這樣的格拉姆矩陣來表達樣式層輸出的樣式,需要注意的是,當
h
w
hw
hw的值較大時,格拉姆矩陣中的元素容易出現較大的值,此外,格拉姆矩陣的高和寬皆為通道數
c
c
c,為了讓樣式損失不受這些值的大小影響,下面定義的gram函式將格拉姆矩陣除以了矩陣中元素的個數,即
c
h
w
chw
chw
def gram(X):
num_channels, n = X.shape[1], X.numel() // X.shape[1] # channel為通道數,n為高寬乘積
X = X.reshape((num_channels, n))
return torch.matmul(X, X.T) / (num_channels * n)
??自然地,樣式損失的平方誤差函式的兩個格拉姆矩陣輸入分別基于合成影像與樣式影像的樣式層輸出,這里假設基于樣式影像的格拉姆矩陣gram_Y已經預先計算好了,
def style_loss(Y_hat, gram_Y):
return torch.square(gram(Y_hat) - gram_Y.detach()).mean()
4.3 總變差損失
??有時候,我們學到的合成影像里面有大量高頻噪點,即有特別亮或者特別暗的顆粒像素,一種常見的降噪方法是總變差降噪:假設 x i , j x_{i, j} xi,j? 表示坐標 ( i , j ) (i, j) (i,j) 處的像素值,降低總變差損失
∑ i , j ∣ x i , j ? x i + 1 , j ∣ + ∣ x i , j ? x i , j + 1 ∣ \sum_{i, j} \left|x_{i, j} - x_{i+1, j}\right| + \left|x_{i, j} - x_{i, j+1}\right| i,j∑?∣xi,j??xi+1,j?∣+∣xi,j??xi,j+1?∣
能夠盡可能使鄰近的像素值相似,
def tv_loss(Y_hat):
"""TV降噪,使得鄰近像素值類似"""
return 0.5 * (torch.abs(Y_hat[:, :, 1:, :] - Y_hat[:, :, :-1, :]).mean() +
torch.abs(Y_hat[:, :, :, 1:] - Y_hat[:, :, :, :-1]).mean())
4.4 總損失加權
風格轉移的損失函式是內容損失、風格損失和總變化損失的加權和
通過調節這些權值超引數,我們可以權衡合成影像在保留內容、遷移樣式以及降噪三方面的相對重要性,
content_weight, style_weight, tv_weight = 1, 1e3, 10
def compute_loss(X, contents_Y_hat, styles_Y_hat, contents_Y, styles_Y_gram):
# 分別計算內容損失、樣式損失和總變差損失
contents_l = [
content_loss(Y_hat, Y) * content_weight
for Y_hat, Y in zip(contents_Y_hat, contents_Y)]
styles_l = [
style_loss(Y_hat, Y) * style_weight
for Y_hat, Y in zip(styles_Y_hat, styles_Y_gram)]
tv_l = tv_loss(X) * tv_weight
# 對所有損失求和
l = sum(10 * styles_l + contents_l + [tv_l])
return contents_l, styles_l, tv_l, l
5. 初始化合成影像
??在樣式遷移中,合成的影像是訓練期間唯一需要更新的變數,因此,我們可以定義一個簡單的模型SynthesizedImage,并將合成的影像視為模型引數,模型的前向計算只需回傳模型引數即可,
class SynthesizedImage(nn.Module):
def __init__(self, img_shape, **kwargs):
super(SynthesizedImage, self).__init__(**kwargs)
self.weight = nn.Parameter(torch.rand(*img_shape))
def forward(self):
return self.weight
def get_inits(X, device, lr, styles_Y):
"""
該函式創建了合成影像的模型實體,并將其初始化為影像 `X` ,
樣式影像在各個樣式層的格拉姆矩陣 `styles_Y_gram` 將在訓練前預先計算好,
"""
gen_img = SynthesizedImage(X.shape).to(device)
gen_img.weight.data.copy_(X.data)
trainer = torch.optim.Adam(gen_img.parameters(), lr=lr)
styles_Y_gram = [gram(Y) for Y in styles_Y]
return gen_img(), styles_Y_gram, trainer
6. 模型訓練
??在訓練模型進行樣式遷移時,我們不斷抽取合成影像的內容特征和樣式特征,然后計算損失函式,下面定義了訓練回圈,訓練程序與傳統的神經網路訓練不同在于:
- 損失函式更加復雜
- 我們只對輸入進行更新(意味著需要對輸入X預先分配梯度)
- 我們可能會替換匹配內容和樣式的層,調整他們之間的權重,以得到不同風格的輸出,
- 仍然使用簡單的隨機梯度下降,但是每隔n次迭代減小一次學習率
def train(X, contents_Y, styles_Y, device, lr, num_epochs, lr_decay_epoch):
X, styles_Y_gram, trainer = get_inits(X, device, lr, styles_Y)
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_decay_epoch, 0.8) # 依次降低學習率
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs],
legend=['content', 'style',
'TV'], ncols=2, figsize=(7, 2.5))
for epoch in range(num_epochs):
trainer.zero_grad()
contents_Y_hat, styles_Y_hat = extract_features(
X, content_layers, style_layers)
contents_l, styles_l, tv_l, l = compute_loss(X, contents_Y_hat,
styles_Y_hat, contents_Y,
styles_Y_gram)
l.backward()
trainer.step()
scheduler.step()
if (epoch + 1) % 10 == 0:
animator.axes[1].imshow(postprocess(X))
animator.add(
epoch + 1,
[float(sum(contents_l)),
float(sum(styles_l)),
float(tv_l)])
return X
# 現在我們[**訓練模型**]:首先將內容影像和樣式影像的高和寬分別調整為300和450像素,用內容影像來初始化合成影像,
device, image_shape = d2l.try_gpu(), (300, 450)
net = net.to(device)
content_X, contents_Y = get_contents(image_shape, device)
_, styles_Y = get_styles(image_shape, device)
output = train(content_X, contents_Y, styles_Y, device, 0.1, 500, 200)
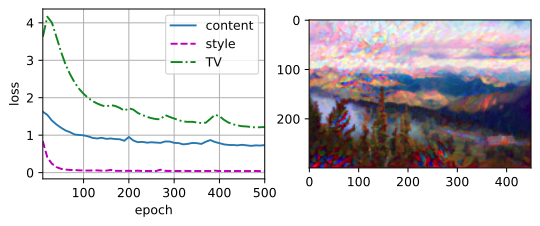
plt.imshow(postprocess(output))
plt.savefig("test.png")

三、總結
- 樣式遷移的損失包含三個部分
- 內容損失:使得合成影像與內容影像在內容特征上接近
- 樣式損失:使得合成影像與樣式影像在樣式特征上接近
- 總變差損失:減少合成影像中的噪聲點
- 可以通過預訓練模型的卷積神經網路抽取影像的特征,并通過最小化損失函式來不斷更新合成影像作為模型引數
- 使用拉格姆矩陣表達樣式層的樣式
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/332196.html
標籤:其他
上一篇:OpenCV-Python自適應直方圖均衡類CLAHE及方法詳解
下一篇:Jenkins安裝與持續部署