1、 ELK簡介
1.1、 ELK
Elasticsearch + Logstash + Kibana(ELK)是一套開源的日志管理方案,分析網站的訪問情況時我們一般會借助Google/百度等方式嵌入JS做資料統計,但是當網站訪問例外或者被攻擊時我們需要在后臺分析如Nginx的具體日志,而Nginx日志分割/GoAccess/Awstats都是相對簡單的單節點解決方案,針對分布式集群或者資料量級較大時會顯得心有余而力不足,而ELK的出現可以使我們從容面對新的挑戰,
日志主要包括系統日志、應用程式日志和安全日志,系統運維和開發人員可以通過日志了解服務器軟硬體資訊、檢查配置程序中的錯誤及錯誤發生的原因,經常分析日志可以了解服務器的負荷,性能安全性,從而及時采取措施糾正錯誤,
通常,日志被分散的儲存不同的設備上,如果你管理數十上百臺服務器,你還在使用依次登錄每臺機器的傳統方法查閱日志,這樣是不是感覺很繁瑣和效率低下,當務之急我們使用集中化的日志管理,例如:開源的syslog,將所有服務器上的日志收集匯總,
集中化管理日志后,日志的統計和檢索又成為一件比較麻煩的事情,一般我們使用grep、awk和wc等Linux命令能實作檢索和統計,但是對于要求更高的查詢、排序和統計等要求和龐大的機器數量再去使用這些方法就比較的麻煩了,
開源實時日志分析ELK平臺能夠完美的解決我們上述的問題,ELK由ElasticSearch、Logstash和Kiabana三個開源工具組成
1.2、 ELK 優點
ELK Stack 在最近兩年迅速崛起,成為機器資料分析,或者說實時日志處理領域,開源界的第一選擇,和傳統的日志處理方案相比,ELK Stack 具有如下幾個優點:
處理方式靈活,Elasticsearch 是實時全文索引,不需要像 storm 那樣預先編程才能使用;
配置簡易上手,Elasticsearch 全部采用 JSON 介面,Logstash 是 Ruby DSL 設計,都是目前業界最通用的配置語法設計;
檢索性能高效,雖然每次查詢都是實時計算,但是優秀的設計和實作基本可以達到全天資料查詢的秒級回應;
集群線性擴展,不管是 Elasticsearch 集群還是 Logstash 集群都是可以線性擴展的;
前端操作炫麗,Kibana 界面上,只需要點擊滑鼠,就可以完成搜索、聚合功能,生成炫麗的儀表板,
1.3、 Elasticsearch
1.3.1、 Elasticsearch簡介
Elasticsearch是個開源分布式搜索引擎,它的特點有:分布式,零配置,自動發現,索引自動分片,索引副本機制,restful風格介面,多資料源,自動搜索負載等,
Elasticsearch 是一個建立在全文搜索引擎 Apache Lucene? 基礎上的分布式的,高可用的,基于json格式的資料構建索引,準實時查詢的搜索引擎,Lucene 是當今最先進最高效的全功能開源搜索引擎框架,但是Lucene使用非常復雜,
Elasticsearch使用 Lucene 作為內部引擎,但是在你使用它做全文搜索時,只需要使用統一開發好的API即可,而并不需要了解其背后復雜的 Lucene 的運行原理,
Elasticsearch為去中心化的分布式架構,由若干節點組成集群,節點中沒有固定的主控角色,可以靈活伸縮規模,集群中每臺服務器通常只需部署一個Elasticsearch節點,每個節點可以將本機的所有資料盤用于存盤索引資料,
1.3.2、 API、XML、JSON
 有了API就可以更好的呼叫和使用,XML為什么會被丟棄,因為XML檔案格式比較龐大,而且不容易決議,不同瀏覽器之間決議XML又不一樣,而且現在微博,等web端的應用,XML越來越跟不上時代的發展,所以現在開始用輕量級的JSON
有了API就可以更好的呼叫和使用,XML為什么會被丟棄,因為XML檔案格式比較龐大,而且不容易決議,不同瀏覽器之間決議XML又不一樣,而且現在微博,等web端的應用,XML越來越跟不上時代的發展,所以現在開始用輕量級的JSON
1.3.3、 RESTFUL的解釋
Elasticsearch是可伸縮的,一個采用RESTFUL api 標準的高擴展性和高可用性的實時資料分析的全文搜索工具,
REST全稱是Representational State Transfer,中文意思是表現層狀態轉化,它首次出現在2000年Roy Fielding的博士論文中,Roy Fielding是HTTP規范的主要撰寫者之一,
1.表現層:代表資源,比如說一段文本,一部電影,每個資源都有一個ID來表示,這個ID成為我們的URL,每個資源僅代表一個資訊,一個資訊又可以用很多種形式來表示,比如文字,有txt ,word格式
2.狀態轉化:客戶端想要訪問服務器,必須要通過某些手段與服務器進行互動,互動的程序又是基于表現層的,這里的某些手段指的是,GET用來獲取資源,post 用來新建資源,PUT 用來更新資源,delete洗掉資源,
高擴展性體現在拓展非常簡單,Elasticsearch新的節點,基本無需做復雜配置,自動發現節點,
高可用性,因為這個服務是分布式的,而且是一個實時搜索平臺,支持PB級的大資料搜索能力,從一個檔案到這個檔案被搜索到,只有略微的延遲,所以說他的實時性非常高,
RESTful是一種軟體架構風格、設計風格,而不是標準,只是提供了一組設計原則和約束條件,它主要用于客戶端和服務器互動類的軟體,基于這個風格設計的軟體可以更簡潔,更有層次,更易于實作快取等機制,
1.3.4、 Elasticsearch的一些基本概念
節點(Node) - 一個Elasticsearch運行的實體,
集群(Cluster) - 具有同一集群名稱的節點組成的分布式集群,
索引(Index) - 一個日志記錄的集合,類似資料庫,須要注意的是索引的名稱不能有大寫字母,
切片(Shard) - 每個索引的資料可以劃分成若干切片,不同切片會被存盤到不同的節點上以實作客戶端讀寫條帶化,
副本(replica) - 切片的資料冗余,和切片主體的內容相同,保證資料安全和高可用,
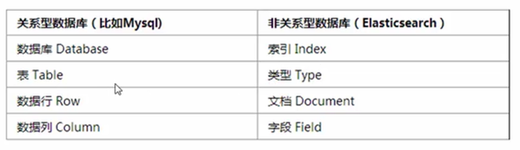
你可以把elasticearch當做一個資料庫,來對比下與其他資料庫的不同,elasticseach是非關系型資料庫,
1.3.5、 Elasticseach架構
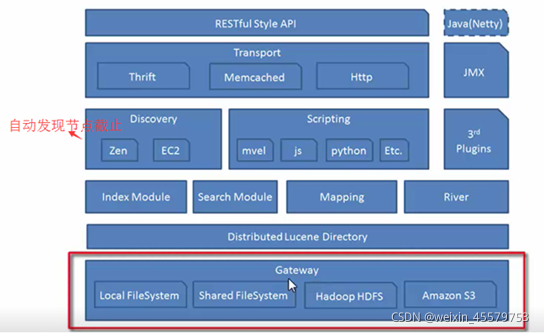
gateway:elasticsearch支持的索引資料的存盤格式,當這個elasticsearch關閉再啟動的時候,他就會從gateway里面讀取索引資料,本地的,分布式,亞馬遜的S3
第二行是lucene的框架
第三行:對資料的加工處理方式,創建index模塊,search Module(搜索模塊),
Mapping(映射)是定義檔案及其包含的欄位是如何存盤和索引的程序
例如,我們用映射來定義:
哪些字串欄位應該被當做全文欄位
哪些欄位包含數字、日期或地理位置
是否應該將檔案中所有欄位的值索引到catch-all欄位中
river代表es的一個資料源,也是其它存盤方式(如:資料庫)同步資料到es的一個方法,它是以插件方式存在的一個es服務,通過讀取river中的資料并把它索引到es中,
第四行:
左邊第一塊是elasticsearch自動發現節點的機制,
zen 用來實作節點自動發現的,加入master發生故障,其他的節點就會自動選舉,來確定一個master,
中間,方便對查詢出來的資料進行資料處理,
最右邊:插件識別,中文分詞插件,斷點監控插件
倒數第二層,是互動方式,默認是用httpd協議來傳輸的,
最頂層右邊是說可以使用java語言,本身就是用java開發的
1.4、 Logstash
logstash是一個應用程式日志、事件的傳輸、處理、管理和搜索的平臺,你可以用它來統一對應用程式日志進行收集管理,提供 Web 介面用于查詢和統計,其實logstash是可以被別的替換,比如常見的fluented.
Logstash是一個完全開源的工具,他可以對你的日志進行收集、分析,并將其存盤到elasticsearch供以后使用(如,搜索),
1.5、 Kibana
Kibana是一個為 Logstash 和 ElasticSearch 提供的日志分析的 Web 介面,也是一個開源和免費的工具,可以為 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以幫助您匯總、分析和搜索重要資料日志,
1.6、 ELK架構
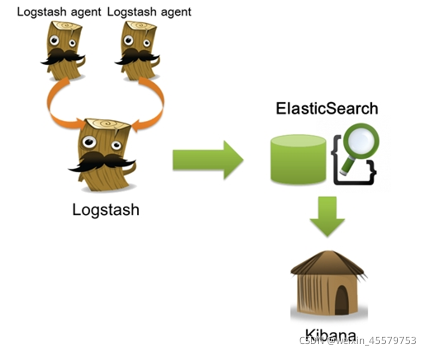
在需要收集日志的所有服務上部署logstash,作為logstash agent(logstash shipper托運人)用于監控并過濾收集日志,將過濾后的內容發送到logstash indexer(索引器),logstash indexer將日志收集在一起交給全文搜索服務ElasticSearch,可以用ElasticSearch進行自定義搜索通過Kibana 來結合自定義搜索進行頁面展示
1.7、 ELK有兩種安裝方式
(1)集成環境:Logstash有一個集成包,里面包括了其全套的三個組件;也就是安裝一個集成包,
(2)獨立環境:三個組件分別單獨安裝、運行、各司其職,(比較常用)
1.8、 ELK常見的幾種架構
1.8.6、 Elasticsearch + Logstash + Kibana
這是一種最簡單的架構,這種架構,通過logstash收集日志,Elasticsearch分析日志,然后在Kibana(web界面)中展示,這種架構雖然是官網介紹里的方式,但是往往在生產中很少使用,
1.8.7、 Elasticsearch + Logstash + filebeat + Kibana
與上一種架構相比,這種架構增加了一個filebeat模塊,filebeat是一個輕量的日志收集代理,用來部署在客戶端,優勢是消耗非常少的資源(較logstash), 所以生產中,往往會采取這種架構方式,但是這種架構有一個缺點,當logstash出現故障, 會造成日志的丟失,
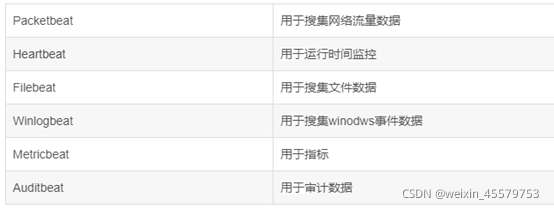
輕量級日志采集框架Beats,其中包含以下6種:
 1.8.8、 Elasticsearch + Logstash + filebeat + redis(kafka)
1.8.8、 Elasticsearch + Logstash + filebeat + redis(kafka)
這種架構是上面那個架構的完善版,通過增加中間件,來避免資料的丟失,當Logstash出現故障,日志還是存在中間件中,當Logstash再次啟動,則會讀取中間件中積壓的日志,傳統web專案中,經常使用log4j以及logback(性能更高)等成熟日志插件進行日志的記錄,日志采集新增Logback直接發送日志到Logstash的形式,如果采用此方式,web服務可減少部分生成log檔案配置,提高實時性和日志推送效率,架構圖:
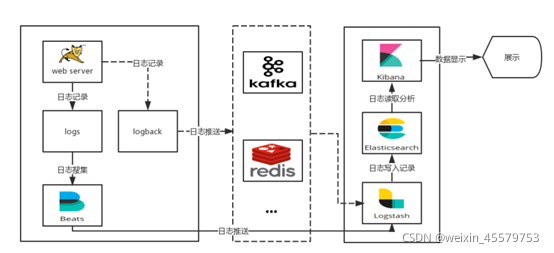
說明: logstash節點和elasticsearch節點可以根據日志量伸縮節點數量, filebeat部署在每臺需要收集日志的服務器上,
1.9、 官網地址

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/332482.html
標籤:其他