有一定深度學習影像分割基礎,至少閱讀過部分語意分割或者醫學影像分割文獻
文章目錄
- 1 完整原始碼
- 2 資料集
- 3 分割任務的思路
- 4 代碼實作
- 4.1 資料預處理
- 4.2 模型設計
- 4.3 評估指標和損失函式
- 4.4 訓練
- 4.5 模型驗證
前面的一篇 醫學影像分割多目標分割(多分類)實踐文章記錄了筆者在醫學影像分割踩坑入門的實踐,但當時的原始碼不夠完整,通過博客的評論互動和私信發現有很多同學同樣在做這個方向,最近空閑的時間也讓我下定決心重新復現之前代碼并進行一些注釋和講解,希望能對該方向入坑的同學提供一些幫助,
先上原始碼,
1 完整原始碼
【完整原始碼地址】: pytorch-medical-image-segmentation
重新整理了之前的代碼,利用其中一個資料集(前面文章提到的基于磁共振成像的膀胱內外壁分割與腫瘤檢測,)作為案例,但由于沒有官方的資料授權,我僅將該資料集的一小部分資料拿來做演示,
我將代碼托管到了國內的Gitee上(主要覺得比Github速度快點),原始碼 pytorch-medical-image-segmentation可直接下載運行,
【代碼目錄結構】:
pytorch-medical-image-segmentation/
|-- checkpoint # 存放訓練好的模型
|-- dataprepare # 資料預處理的一些方法
|-- datasets # 資料加載的一些方法
|-- log # 日志檔案
|-- media
| |-- Datasets # 存放資料集
|-- networks # 存放模型
|-- test # 測驗相關
|-- train # 訓練相關
|-- utils # 一些工具函式
|-- validate # 驗證相關
|-- README.md
2 資料集
來自ISICDM 2019 臨床資料分析挑戰賽的基于磁共振成像的膀胱內外壁分割與腫瘤檢測資料集,
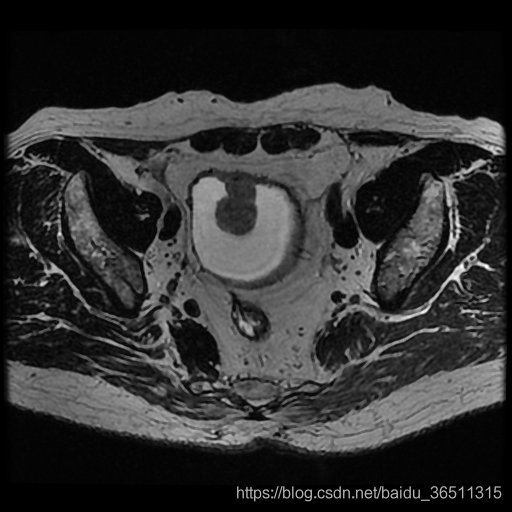

【說明】:筆者沒有權限公開分享該資料集,需要完整資料集可通過官網獲取,若官網資料集也不能獲取,可利用其他資料集代替,本教程主要是提供分割的大體代碼思路,不局限于某一個具體的資料集,
【灰度值】:灰色128為膀胱內外壁,白色255為腫瘤,
【分割任務】:同時分割出膀胱內外壁和腫瘤部分
【分析】:我們需要分割出膀胱內外壁和腫瘤,再加上黑色背景,相當于是一個三分類問題,
3 分割任務的思路
根據筆者做分割的一些經驗,醫學影像分割任務的步驟大體是以下幾個步驟:
- 資料預處理
- 模型設計
- 評估指標和損失函式選擇
- 訓練
- 驗證
- 測驗
接下來我們通過代碼一步步完成分割的程序,
4 代碼實作
4.1 資料預處理
此次的膀胱資料集本身是官方處理好的png影像,不像常規的MRI和CT影像是nii格式的,因此資料處理起來相對容易,
為了簡單起見,筆者主要對原始資料做了資料集劃分、對標簽進行One-hot、裁剪等操作,由于不同的資料集做的資料增廣操作(一般會有旋轉、縮放、彈性形變等)不太一樣,本案例中省略了資料增廣的操作,
首先,我們對原始資料集進行重新資料劃分,這里使用了五折交叉驗證(5-fold validation)的方法對資料進行劃分,不了解交叉驗證的同學可以先去網上搜索了解一下,
這里是將資料集的名字劃分到不同txt檔案中,而不是真正的將原始資料劃分到不同的檔案夾中,后面讀取的時候也是通過名字來讀取,這樣更加方便,
# /dataprepare/kfold.py
import os, shutil
from sklearn.model_selection import KFold
# 按K折交叉驗證劃分資料集
def dataset_kfold(dataset_dir, save_path):
data_list = os.listdir(dataset_dir)
kf = KFold(5, False, 12345) # 使用5折交叉驗證
for i, (tr, val) in enumerate(kf.split(data_list), 1):
print(len(tr), len(val))
if os.path.exists(os.path.join(save_path, 'train{}.txt'.format(i))):
# 若該目錄已存在,則先洗掉,用來清空資料
print('清空原始資料中...')
os.remove(os.path.join(save_path, 'train{}.txt'.format(i)))
os.remove(os.path.join(save_path, 'val{}.txt'.format(i)))
print('原始資料已清空,')
for item in tr:
file_name = data_list[item]
with open(os.path.join(save_path, 'train{}.txt'.format(i)), 'a') as f:
f.write(file_name)
f.write('\n')
for item in val:
file_name = data_list[item]
with open(os.path.join(save_path, 'val{}.txt'.format(i)), 'a') as f:
f.write(file_name)
f.write('\n')
if __name__ == '__main__':
# 膀胱資料集劃分
# 首次劃分資料集或者重新劃分資料集時運行
dataset_kfold(os.path.join('..\media\Datasets\Bladder', 'raw_data\Labels'),
os.path.join('..\media\Datasets\Bladder', 'raw_data'))
運行后會生成以下檔案,相當于是將資料集5份,每一份對應自己的訓練集和驗證集,
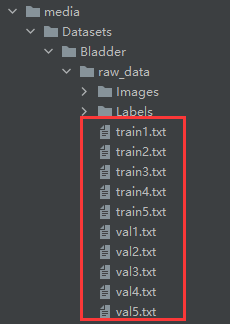
資料集劃分好了,接下來就要寫資料加載的類和方法,以便在訓練的時候加載我們的資料,
# /datasets/bladder.py
import os
import cv2
import numpy as np
from PIL import Image
from torch.utils import data
from utils import helpers
'''
128 = bladder
255 = tumor
0 = background
'''
palette = [[0], [128], [255]] # one-hot的顏色表
num_classes = 3 # 分類數
def make_dataset(root, mode, fold):
assert mode in ['train', 'val', 'test']
items = []
if mode == 'train':
img_path = os.path.join(root, 'Images')
mask_path = os.path.join(root, 'Labels')
if 'Augdata' in root: # 當使用增廣后的訓練集
data_list = os.listdir(os.path.join(root, 'Labels'))
else:
data_list = [l.strip('\n') for l in open(os.path.join(root, 'train{}.txt'.format(fold))).readlines()]
for it in data_list:
item = (os.path.join(img_path, it), os.path.join(mask_path, it))
items.append(item)
elif mode == 'val':
img_path = os.path.join(root, 'Images')
mask_path = os.path.join(root, 'Labels')
data_list = [l.strip('\n') for l in open(os.path.join(
root, 'val{}.txt'.format(fold))).readlines()]
for it in data_list:
item = (os.path.join(img_path, it), os.path.join(mask_path, it))
items.append(item)
else:
img_path = os.path.join(root, 'Images')
data_list = [l.strip('\n') for l in open(os.path.join(
root, 'test.txt')).readlines()]
for it in data_list:
item = (os.path.join(img_path, 'c0', it))
items.append(item)
return items
class Dataset(data.Dataset):
def __init__(self, root, mode, fold, joint_transform=None, center_crop=None, transform=None, target_transform=None):
self.imgs = make_dataset(root, mode, fold)
self.palette = palette
self.mode = mode
if len(self.imgs) == 0:
raise RuntimeError('Found 0 images, please check the data set')
self.mode = mode
self.joint_transform = joint_transform
self.center_crop = center_crop
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
img_path, mask_path = self.imgs[index]
file_name = mask_path.split('\\')[-1]
img = Image.open(img_path)
mask = Image.open(mask_path)
if self.joint_transform is not None:
img, mask = self.joint_transform(img, mask)
if self.center_crop is not None:
img, mask = self.center_crop(img, mask)
img = np.array(img)
mask = np.array(mask)
# Image.open讀取灰度影像時shape=(H, W) 而非(H, W, 1)
# 因此先擴展出通道維度,以便在通道維度上進行one-hot映射
img = np.expand_dims(img, axis=2)
mask = np.expand_dims(mask, axis=2)
mask = helpers.mask_to_onehot(mask, self.palette)
# shape from (H, W, C) to (C, H, W)
img = img.transpose([2, 0, 1])
mask = mask.transpose([2, 0, 1])
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
mask = self.target_transform(mask)
return (img, mask), file_name
def __len__(self):
return len(self.imgs)
if __name__ == '__main__':
np.set_printoptions(threshold=9999999)
from torch.utils.data import DataLoader
import utils.image_transforms as joint_transforms
import utils.transforms as extended_transforms
def demo():
train_path = r'../media/Datasets/Bladder/raw_data'
val_path = r'../media/Datasets/Bladder/raw_data'
test_path = r'../media/Datasets/Bladder/test'
center_crop = joint_transforms.CenterCrop(256)
test_center_crop = joint_transforms.SingleCenterCrop(256)
train_input_transform = extended_transforms.NpyToTensor()
target_transform = extended_transforms.MaskToTensor()
train_set = Dataset(train_path, 'train', 1,
joint_transform=None, center_crop=center_crop,
transform=train_input_transform, target_transform=target_transform)
train_loader = DataLoader(train_set, batch_size=1, shuffle=False)
for (input, mask), file_name in train_loader:
print(input.shape)
print(mask.shape)
img = helpers.array_to_img(np.expand_dims(input.squeeze(), 2))
gt = helpers.onehot_to_mask(np.array(mask.squeeze()).transpose(1, 2, 0), palette)
gt = helpers.array_to_img(gt)
cv2.imshow('img GT', np.uint8(np.hstack([img, gt])))
cv2.waitKey(1000)
demo()
通常我會在資料預處理和加載類已寫好后,運行代碼測驗資料的加載程序,看加載的資料是否有問題,通過可視化的結果可以看到加載的資料是正常的,
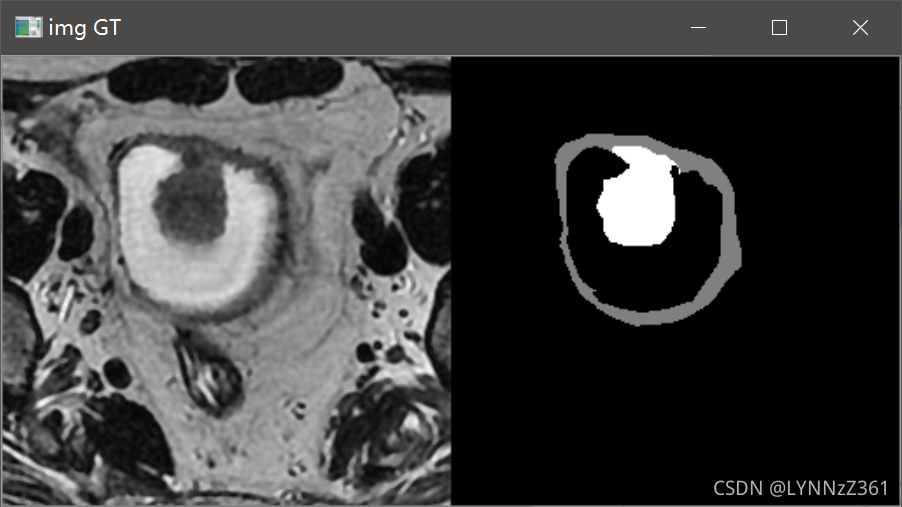
我們在對ground truth反one-hot進行可視化時,改變顏色表palette中的顏色值,就可以將ground truth重新映射成我們想要的顏色,例如:
我們修改上面的部分代碼,將顏色表palette修改成三色值([x, x, x]里邊有三個數字,單色[x]就對應灰色影像)將gt映射成彩色影像,
for (input, mask), file_name in train_loader:
print(input.shape)
print(mask.shape)
img = helpers.array_to_img(np.expand_dims(input.squeeze(), 2))
# 將gt反one-hot回去以便進行可視化
palette = [[0, 0, 0], [246, 16, 16], [16, 136, 246]]
gt = helpers.onehot_to_mask(np.array(mask.squeeze()).transpose(1, 2, 0), palette)
gt = helpers.array_to_img(gt)
# cv2.imshow('img GT', np.uint8(np.hstack([img, gt])))
cv2.imshow('img GT', np.uint8(gt))
cv2.waitKey(1000)
可視化的結果如下

4.2 模型設計
直接用經典的U-Net作為演示模型,注意輸入的影像是1個通道,輸出是3個通道,
# /networks/u_net.py
from networks.custom_modules.basic_modules import *
from utils.misc import initialize_weights
class Baseline(nn.Module):
def __init__(self, img_ch=1, num_classes=3, depth=2):
super(Baseline, self).__init__()
chs = [64, 128, 256, 512, 512]
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.enc1 = EncoderBlock(img_ch, chs[0], depth=depth)
self.enc2 = EncoderBlock(chs[0], chs[1], depth=depth)
self.enc3 = EncoderBlock(chs[1], chs[2], depth=depth)
self.enc4 = EncoderBlock(chs[2], chs[3], depth=depth)
self.enc5 = EncoderBlock(chs[3], chs[4], depth=depth)
self.dec4 = DecoderBlock(chs[4], chs[3])
self.decconv4 = EncoderBlock(chs[3] * 2, chs[3])
self.dec3 = DecoderBlock(chs[3], chs[2])
self.decconv3 = EncoderBlock(chs[2] * 2, chs[2])
self.dec2 = DecoderBlock(chs[2], chs[1])
self.decconv2 = EncoderBlock(chs[1] * 2, chs[1])
self.dec1 = DecoderBlock(chs[1], chs[0])
self.decconv1 = EncoderBlock(chs[0] * 2, chs[0])
self.conv_1x1 = nn.Conv2d(chs[0], num_classes, 1, bias=False)
initialize_weights(self)
def forward(self, x):
# encoding path
x1 = self.enc1(x)
x2 = self.maxpool(x1)
x2 = self.enc2(x2)
x3 = self.maxpool(x2)
x3 = self.enc3(x3)
x4 = self.maxpool(x3)
x4 = self.enc4(x4)
x5 = self.maxpool(x4)
x5 = self.enc5(x5)
# decoding + concat path
d4 = self.dec4(x5)
d4 = torch.cat((x4, d4), dim=1)
d4 = self.decconv4(d4)
d3 = self.dec3(d4)
d3 = torch.cat((x3, d3), dim=1)
d3 = self.decconv3(d3)
d2 = self.dec2(d3)
d2 = torch.cat((x2, d2), dim=1)
d2 = self.decconv2(d2)
d1 = self.dec1(d2)
d1 = torch.cat((x1, d1), dim=1)
d1 = self.decconv1(d1)
d1 = self.conv_1x1(d1)
return d1
if __name__ == '__main__':
# from torchstat import stat
import torch
from torchsummary import summary
x = torch.randn([2, 1, 64, 64]).cuda()
# # 引數計算
model = Baseline(num_classes=3).cuda()
total = sum([param.nelement() for param in model.parameters()])
print("Number of parameter: %.3fM" % (total / 1e6))
# # 引數計算
# # stat(model, (1, 224, 224))
# # 每層輸出大小
print(model(x).shape)
可以直接運行該檔案,測驗模型的輸入和輸出是否符合預期,
4.3 評估指標和損失函式
這里選擇醫學影像分割中最常用的指標Dice和Dice loss,關于實作的討論可參考【Pytorch】 Dice系數與Dice Loss損失函式實作,
Dice系數的實作核心代碼:
# /utils/metrics.py
def diceCoeffv2(pred, gt, eps=1e-5):
r""" computational formula:
dice = (2 * tp) / (2 * tp + fp + fn)
"""
N = gt.size(0)
pred_flat = pred.view(N, -1)
gt_flat = gt.view(N, -1)
tp = torch.sum(gt_flat * pred_flat, dim=1)
fp = torch.sum(pred_flat, dim=1) - tp
fn = torch.sum(gt_flat, dim=1) - tp
score = (2 * tp + eps) / (2 * tp + fp + fn + eps)
return score.sum() / N
多分類Dice loss實作的核心代碼:
# /utils/loss.py
class SoftDiceLoss(_Loss):
def __init__(self, num_classes):
super(SoftDiceLoss, self).__init__()
self.num_classes = num_classes
def forward(self, y_pred, y_true):
class_dice = []
# 從1開始排除背景,前提是顏色表palette中背景放在第一個位置 [[0], ..., ...]
for i in range(1, self.num_classes):
class_dice.append(diceCoeffv2(y_pred[:, i:i + 1, :], y_true[:, i:i + 1, :]))
mean_dice = sum(class_dice) / len(class_dice)
return 1 - mean_dice
如果只是二分類,用下面的損失函式:
class BinarySoftDiceLoss(_Loss):
def __init__(self):
super(BinarySoftDiceLoss, self).__init__()
def forward(self, y_pred, y_true):
mean_dice = diceCoeffv2(y_pred, y_true)
return 1 - mean_dice
4.4 訓練
訓練的整體思路就是,訓練完一個epoch進行驗證(注意驗證的loss不反向傳播,只驗證不影響模型權重),在訓練的程序中使用了早停機制(Early stopping),只要在15個epoch內,驗證集上的評價Dice指標增長不超過0.1%則停止訓練,并保存之前在驗證集上最好的模型,
代碼中Early Stopping提供兩個版本,其中EarlyStopping傳指標進去即可,EarlyStoppingV2傳驗證集的loss值,表示在15個epoch內,loss下降不超過0.001則停止訓練,
# /train/train_bladder.py
import time
import os
import torch
import random
from torch.utils.data import DataLoader
from tensorboardX import SummaryWriter
from torch.optim import lr_scheduler
from tqdm import tqdm
import sys
from datasets import bladder
import utils.image_transforms as joint_transforms
import utils.transforms as extended_transforms
from utils.loss import *
from utils.metrics import diceCoeffv2
from utils import misc
from utils.pytorchtools import EarlyStopping
from utils.LRScheduler import PolyLR
# 超參設定
crop_size = 256 # 輸入裁剪大小
batch_size = 2 # batch size
n_epoch = 300 # 訓練的最大epoch
early_stop__eps = 1e-3 # 早停的指標閾值
early_stop_patience = 15 # 早停的epoch閾值
initial_lr = 1e-4 # 初始學習率
threshold_lr = 1e-6 # 早停的學習率閾值
weight_decay = 1e-5 # 學習率衰減率
optimizer_type = 'adam' # adam, sgd
scheduler_type = 'no' # ReduceLR, StepLR, poly
label_smoothing = 0.01
aux_loss = False
gamma = 0.5
alpha = 0.85
model_number = random.randint(1, 1e6)
model_type = "unet"
if model_type == "unet":
from networks.u_net import Baseline
root_path = '../'
fold = 1 # 訓練集k-fold, 可設定1, 2, 3, 4, 5
depth = 2 # unet編碼器的卷積層數
loss_name = 'dice' # dice, bce, wbce, dual, wdual
reduction = '' # aug
model_name = '{}_depth={}_fold_{}_{}_{}{}'.format(model_type, depth, fold, loss_name, reduction, model_number)
# 訓練日志
writer = SummaryWriter(os.path.join(root_path, 'log/bladder/train', model_name + '_{}fold'.format(fold) + str(int(time.time()))))
val_writer = SummaryWriter(os.path.join(os.path.join(root_path, 'log/bladder/val', model_name) + '_{}fold'.format(fold) + str(int(time.time()))))
# 訓練集路徑
# train_path = os.path.join(root_path, 'media/Datasets/bladder/Augdata_5folds', 'train{}'.format(fold), 'npy')
train_path = os.path.join(root_path, 'media/Datasets/Bladder/raw_data')
val_path = os.path.join(root_path, 'media/Datasets/Bladder/raw_data')
def main():
# 定義網路
net = Baseline(num_classes=bladder.num_classes, depth=depth).cuda()
# 資料預處理
center_crop = joint_transforms.CenterCrop(crop_size)
input_transform = extended_transforms.NpyToTensor()
target_transform = extended_transforms.MaskToTensor()
# 訓練集加載
train_set = bladder.Dataset(train_path, 'train', fold, joint_transform=None, center_crop=center_crop,
transform=input_transform, target_transform=target_transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=6)
# 驗證集加載
val_set = bladder.Dataset(val_path, 'val', fold,
joint_transform=None, transform=input_transform, center_crop=center_crop,
target_transform=target_transform)
val_loader = DataLoader(val_set, batch_size=1, shuffle=False)
# 定義損失函式
if loss_name == 'dice':
criterion = SoftDiceLoss(bladder.num_classes).cuda()
# 定義早停機制
early_stopping = EarlyStopping(early_stop_patience, verbose=True, delta=early_stop__eps,
path=os.path.join(root_path, 'checkpoint', '{}.pth'.format(model_name)))
# 定義優化器
if optimizer_type == 'adam':
optimizer = torch.optim.Adam(net.parameters(), lr=initial_lr, weight_decay=weight_decay)
else:
optimizer = torch.optim.SGD(net.parameters(), lr=0.1, momentum=0.9)
# 定義學習率衰減策略
if scheduler_type == 'StepLR':
scheduler = lr_scheduler.StepLR(optimizer, step_size=4, gamma=0.1)
elif scheduler_type == 'ReduceLR':
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=5)
elif scheduler_type == 'poly':
scheduler = PolyLR(optimizer, max_iter=n_epoch, power=0.9)
else:
scheduler = None
train(train_loader, val_loader, net, criterion, optimizer, scheduler, None, early_stopping, n_epoch, 0)
def train(train_loader, val_loader, net, criterion, optimizer, scheduler, warm_scheduler, early_stopping, num_epoches,
iters):
for epoch in range(1, num_epoches + 1):
st = time.time()
train_class_dices = np.array([0] * (bladder.num_classes - 1), dtype=np.float)
val_class_dices = np.array([0] * (bladder.num_classes - 1), dtype=np.float)
val_dice_arr = []
train_losses = []
val_losses = []
# 訓練模型
net.train()
for batch, ((input, mask), file_name) in enumerate(train_loader, 1):
X = input.cuda()
y = mask.cuda()
optimizer.zero_grad()
output = net(X)
output = torch.sigmoid(output)
loss = criterion(output, y)
loss.backward()
optimizer.step()
iters += 1
train_losses.append(loss.item())
class_dice = []
for i in range(1, bladder.num_classes):
cur_dice = diceCoeffv2(output[:, i:i + 1, :], y[:, i:i + 1, :]).cpu().item()
class_dice.append(cur_dice)
mean_dice = sum(class_dice) / len(class_dice)
train_class_dices += np.array(class_dice)
string_print = 'epoch: {} - iters: {} - loss: {:.4} - mean: {:.4} - bladder: {:.4}- tumor: {:.4} - time: {:.2}' \
.format(epoch, iters, loss.data.cpu(), mean_dice, class_dice[0], class_dice[1], time.time() - st)
misc.log(string_print)
st = time.time()
train_loss = np.average(train_losses)
train_class_dices = train_class_dices / batch
train_mean_dice = train_class_dices.sum() / train_class_dices.size
writer.add_scalar('main_loss', train_loss, epoch)
writer.add_scalar('main_dice', train_mean_dice, epoch)
print('epoch {}/{} - train_loss: {:.4} - train_mean_dice: {:.4} - dice_bladder: {:.4} - dice_tumor: {:.4}'.format(
epoch, num_epoches, train_loss, train_mean_dice, train_class_dices[0], train_class_dices[1]))
# 驗證模型
net.eval()
for val_batch, ((input, mask), file_name) in tqdm(enumerate(val_loader, 1)):
val_X = input.cuda()
val_y = mask.cuda()
pred = net(val_X)
pred = torch.sigmoid(pred)
val_loss = criterion(pred, val_y)
val_losses.append(val_loss.item())
pred = pred.cpu().detach()
val_class_dice = []
for i in range(1, bladder.num_classes):
val_class_dice.append(diceCoeffv2(pred[:, i:i + 1, :], mask[:, i:i + 1, :]))
val_dice_arr.append(val_class_dice)
val_class_dices += np.array(val_class_dice)
val_loss = np.average(val_losses)
val_dice_arr = np.array(val_dice_arr)
val_class_dices = val_class_dices / val_batch
val_mean_dice = val_class_dices.sum() / val_class_dices.size
val_writer.add_scalar('lr', optimizer.param_groups[0]['lr'], epoch)
val_writer.add_scalar('main_loss', val_loss, epoch)
val_writer.add_scalar('main_dice', val_mean_dice, epoch)
print('val_loss: {:.4} - val_mean_dice: {:.4} - bladder: {:.4}- tumor: {:.4}'
.format(val_loss, val_mean_dice, val_class_dices[0], val_class_dices[1]))
print('lr: {}'.format(optimizer.param_groups[0]['lr']))
early_stopping(val_mean_dice, net, epoch)
if early_stopping.early_stop or optimizer.param_groups[0]['lr'] < threshold_lr:
print("Early stopping")
# 結束模型訓練
break
print('----------------------------------------------------------')
print('save epoch {}'.format(early_stopping.save_epoch))
print('stoped epoch {}'.format(epoch))
print('----------------------------------------------------------')
if __name__ == '__main__':
main()
4.5 模型驗證
按照加載訓練集類似的方法,我們加載驗證集或者測驗集進行模型驗證,
# /validate/validate_bladder.py
import os
import cv2
import torch
import shutil
import utils.image_transforms as joint_transforms
from torch.utils.data import DataLoader
import utils.transforms as extended_transforms
from datasets import bladder
from utils.loss import *
from networks.u_net import Baseline
from tqdm import tqdm
crop_size = 256
val_path = r'..\media/Datasets/Bladder/raw_data'
center_crop = joint_transforms.CenterCrop(crop_size)
val_input_transform = extended_transforms.NpyToTensor()
target_transform = extended_transforms.MaskToTensor()
val_set = bladder.Dataset(val_path, 'val', 1,
joint_transform=None, transform=val_input_transform, center_crop=center_crop,
target_transform=target_transform)
val_loader = DataLoader(val_set, batch_size=1, shuffle=False)
palette = bladder.palette
num_classes = bladder.num_classes
net = Baseline(img_ch=1, num_classes=num_classes, depth=2).cuda()
net.load_state_dict(torch.load("../checkpoint/unet_depth=2_fold_1_dice_348055.pth"))
net.eval()
def auto_val(net):
# 效果展示圖片數
dices = 0
class_dices = np.array([0] * (num_classes - 1), dtype=np.float)
save_path = './results'
if os.path.exists(save_path):
# 若該目錄已存在,則先洗掉,用來清空資料
shutil.rmtree(os.path.join(save_path))
img_path = os.path.join(save_path, 'images')
pred_path = os.path.join(save_path, 'pred')
gt_path = os.path.join(save_path, 'gt')
os.makedirs(img_path)
os.makedirs(pred_path)
os.makedirs(gt_path)
val_dice_arr = []
for (input, mask), file_name in tqdm(val_loader):
file_name = file_name[0].split('.')[0]
X = input.cuda()
pred = net(X)
pred = torch.sigmoid(pred)
pred = pred.cpu().detach()
# pred[pred < 0.5] = 0
# pred[np.logical_and(pred > 0.5, pred == 0.5)] = 1
# 原圖
m1 = np.array(input.squeeze())
m1 = helpers.array_to_img(np.expand_dims(m1, 2))
# gt
gt = helpers.onehot_to_mask(np.array(mask.squeeze()).transpose([1, 2, 0]), palette)
gt = helpers.array_to_img(gt)
# pred
save_pred = helpers.onehot_to_mask(np.array(pred.squeeze()).transpose([1, 2, 0]), palette)
save_pred_png = helpers.array_to_img(save_pred)
# png格式
m1.save(os.path.join(img_path, file_name + '.png'))
gt.save(os.path.join(gt_path, file_name + '.png'))
save_pred_png.save(os.path.join(pred_path, file_name + '.png'))
class_dice = []
for i in range(1, num_classes):
class_dice.append(diceCoeffv2(pred[:, i:i + 1, :], mask[:, i:i + 1, :]))
mean_dice = sum(class_dice) / len(class_dice)
val_dice_arr.append(class_dice)
dices += mean_dice
class_dices += np.array(class_dice)
print('mean_dice: {:.4} - dice_bladder: {:.4} - dice_tumor: {:.4}'
.format(mean_dice, class_dice[0], class_dice[1]))
val_mean_dice = dices / (len(val_loader) / 1)
val_class_dice = class_dices / (len(val_loader) / 1)
print('Val mean_dice: {:.4} - dice_bladder: {:.4} - dice_tumor: {:.4}'.format(val_mean_dice, val_class_dice[0], val_class_dice[1]))
if __name__ == '__main__':
np.set_printoptions(threshold=9999999)
auto_val(net)
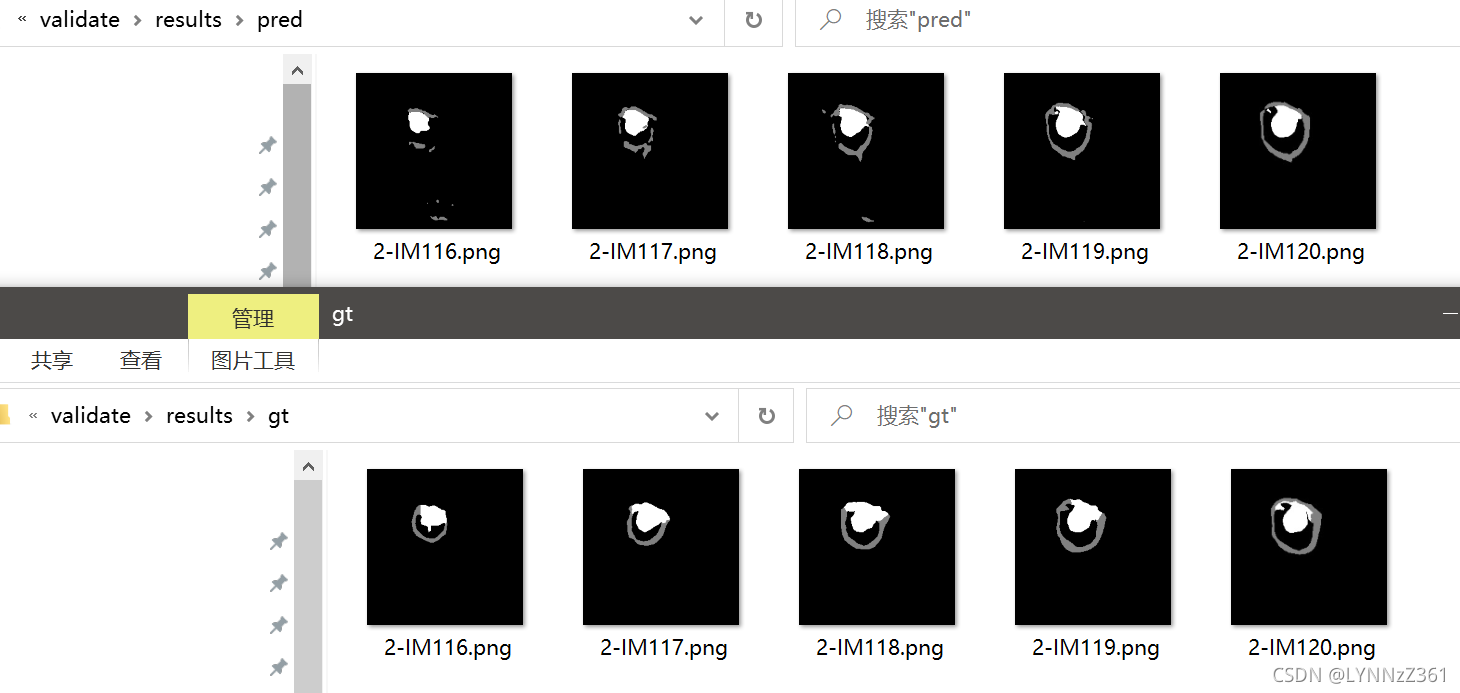
直接運行該檔案可生成我們的預測結果,
雖然我們的U-Net只用了24張圖進行訓練,但從結果可以看到,模型也能大致分割出目標,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/333527.html
標籤:其他
上一篇:Qt+YOLOv4實作目標檢測