--NeoZng[neozng1@hnu.edu.cn]
5.2.3.目標檢測
利用CNN我們已經可以完成對影像的識別和分類,但是這樣是遠遠不夠的,為了能準確定位影像中的物體,我們需要對影像中所有目標進行定位(找出框住目標的bounding box外接矩形框,即[cx,cy,w,h]四個引數,分別表示目標中心在影像中的坐標和bbox的長寬),此部分會介紹幾個經典的目標檢測網路實作的原理和方法,
有同學可能會想,那我直接讓網路在全連接層后輸出一個向量而不是標量(分類),即多輸出四個坐標也就是8個值,分別代表影像中目標的四個角點不就行了嗎?確實,對于只有一個目標的影像我們可以這么做,可惜倘若影像中有多個目標的話,網路的輸出就變成不確定的了(需要一次性輸出不確定長度,分別表示每個目標框中心、長寬和其對應的分類),我們是無法訓練一個沒有確定輸出的網路的,
?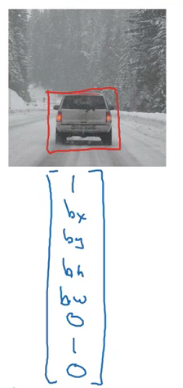
目標定位方法,得到一個WxH到1x9向量的映射
??1代表有目標在影像中,隨后四個數代表中心坐標和目標框的長寬,最后四個數表示目標分類
?
因為影像分類是對整張影像進行的,是一個WxH維到一個確定的標量或向量(如上面說的同時進行分類和回歸)的映射,標準的CNN方法顯然無法完成一張圖片中多個物件的分類和定位操作,不過機智的你應該已經想到,我們可以把圖片拆成很多的部分,然后將這些子圖分別投入CNN從而得到它們對應的分類,不就把里面的物件定位出來了么,
沒錯,這就是密集采樣的定位思想,也是最早的目標檢測方法,使用滑動視窗來檢測目標位置的方法和模板匹配有些類似,還有一種方法是將影像用不同的長度劃分格點,在每個格點中進行影像分類(這其實是一種特殊的滑動視窗方法,即設定滑動步長大小使其與視窗的大小相同),
?
采用不同大小的滑動視窗,裁取影像的一部分投入CNN得到分類(圖中只使用了一種大小)
?
顯然,這種方法的缺點也非常明顯:超高的計算開銷,步長設定的過大可能會發生漏檢,而為了檢測大小不同的目標,我們又需要采用各種大小的視窗來運行CNN,同時還可能需要使用不同長寬比的視窗來應對物體長寬比不同的情況(例如汽車在側面看是細長的矩形,正面又比較接近正方形,如果僅使用一種型別的視窗,則可能會出現定位不精確的問題,得到的定位框包含了大量的背景),
?
使用滑動視窗方法可能出現的問題,沒有一個滑窗能夠和汽車整體匹配
?
仔細觀察,我們就會發現,在目標檢測問題中,我們面臨的最大困難就是候選區域太多且目標大小的尺度不一,問題的搜索空間過于龐大,我們難以用暴力搜索窮舉全部解,于是two-stage方法的代表作R-CNN(region proposal-CNN)橫空出世,不過,再介紹R-CNN之前,先讓我們看看目標檢測中常用的術語和概念吧,
-
常用術語和概念
-
GT(ground truth)
GT可以理解為真實值、有效值、正確的答案、正確的標注資訊,對于目標檢測來說,標記的坐標點和標記分類就被稱作ground truth,
?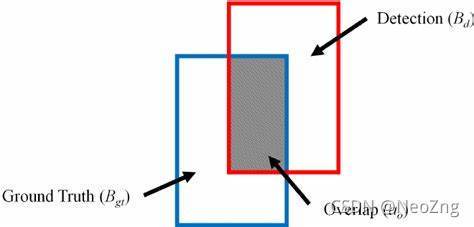
訓練標記的bbox區域(藍色區域)就是ground truth
?在目標檢測網路的推理程序中,如何為預測框分配標簽(訓練的label即GT的屬于的分類)會極大地影響訓練的效率和推理的準確度,這也是當前目標檢測研究的熱點和難點,
-
IOU(intersection of Union)
字面意思,兩個bbox的交集和并集的比例,詳見上方GT的插圖,灰色區域為交集面積,除以兩個bbox的并集就得到交并比,交并比是衡量檢測生成bbox的準確性的一個指標,現在也出現了一些其他用于衡量預測框質量的指標,
-
正/負樣本(positive/negative sample)
在目標檢測中,包含了目標的bbox就是正樣本,而沒有包含目標即bbox內是背景的將被作為負樣本,當然一些網路會對正負樣本進行特殊定義,特別注意,我們是根據訓練標注來生成正負樣本的,并不是說訓練標注中地GT就是正樣本,其他區域都是負樣本,我們會依據某種準則如與GT的IOU或置信度進而由得到正負樣本,
?

我們的檢測目標是杯子,假設網路生成了4個檢測框,認為這里面有杯子,那么根據特定的IOU閾值如0.5,我們將生成的4個檢測框分別作為正負樣本對待;在這里紅色框是GT,紫色和藍色框因為和GT的IOU超過50%被記為正樣本,綠色框則被判定為負樣本(背景)
?在閱讀了下一篇文章的幾個經典網路后再回來看看,你應該會對正負樣本有新的理解,并且目標檢測中有一個很大的、亟待解決的問題就是正負樣本、難易樣本的失衡,(在一張圖片中,沒有目標存在的區域占了全圖的絕大部分,負樣本即背景類占了所有樣本的大多數,大量負樣本在訓練時會淹沒正樣本,導致神經網路失去鑒別能力對負樣本產生過擬合)
正負樣本的劃分策略和不平衡問題同樣是目標檢測的難點,
-
ConvNet和特征圖
ConvNet一般值的是神經網路的backbone(骨干網路),也就是負責提取影像特征的部分,即我們在上面講解CNN的時候由卷積層和池化層堆疊起來的block,特征圖就是經過n個block之后產生的“圖片”,因為原圖的特征被提取到這些小”圖片“上所以我們稱之為特征圖,簡言之經過卷積或池化處理的圖片或特征都可以被稱作特征圖,上面記錄著原圖的某些特征,
-
感受野(receptive field)
從這個術語的名字應該可以略知一二,receptive field是高層feature map上的一個點的資訊是由原圖或之前的feature map中多大的范圍/面積的像素所貢獻的度量,換個簡單句:原圖上的某個像素或低層次的feature map是否和高層中的feature map上的某個點有關聯/間接連接?再或者直接看圖:
?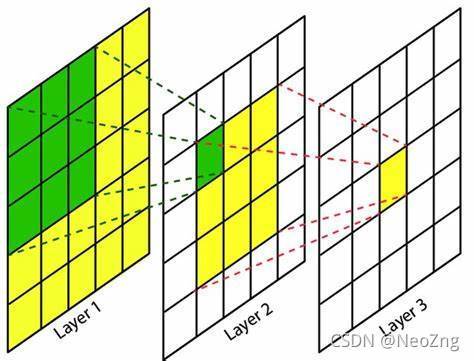
綠色區域是l2中左上角像素的感受野,而黃色區域是l3中間像素的感受野
?有許多擴大感受野的方法如變步長卷積、空洞卷積、膨脹卷積、focus層等我們稍后介紹,其實這個概念應該在CNN部分就進行介紹,但是由于影像分類對此并不敏感所以將介紹移到了此處,
-
NMS(非極大值抑制)
在生成檢測框的時候,可能會出現下圖這種情況,這時候我們要根據框的置信度或定位精度等資訊篩去一些重疊區域很大的目標框,防止出現重復檢測的情況,這里給出了NMS的大致介紹和實作原始碼:NMS 在目標檢測中的應用,

-
性能指標與mAP(mean average precision)
mAP是目標檢測中最常見的測驗檢測器性能的指標,在次之前先讓我們看看混淆矩陣,這是機器學習中所有分類器都要確定的一個引數:
?
混淆矩陣和對應的概念含義
?由混淆矩陣中的資料,我們可以通過各種運算來得到千奇百怪的指標,常見的如正確率、真陽性率、特異度、假陰性率(漏診率)、Youden指數等,我們則選擇mAP來指示一個目標檢測演算法的性能,mAP的計算需要查準率(true positive rate,precision: TP/(TP+FP) )和查全率(又叫召回率recall,計算通過TPR:true positive rate,TP/(TP+FN) )兩個資訊,這兩個指標是一對矛盾指標,當查準率高的時候,說明分類器很少把負類分為正類,只遴選那些最優把握、正類置信度高的樣本,顯然分類為正類的樣本TP+FP將會下降(置信度上升,分類器把更少的樣本分為正類),同時查全率必然跟著下降,很多正樣本將會成為漏網之魚而被分類為負樣本,當降低閾值希望盡可能多地把所有的正類的查出來,那么很多置信度較高的負類同樣容易被分為正類,導致查準度下降,
?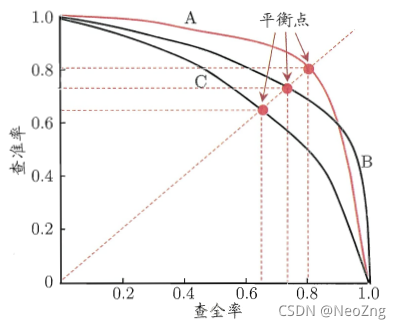
找到曲線上的平衡點,即邊際效用最大的點,當繼續往曲線的右側移動,查全率上升的速度將會低于查準率下降的速度
?目標檢測任務中判斷預測框的正負樣本一般以IOU是否>0.5為準則(這里的分類是說預測框里有沒有物體的置信度,而對預測框中物體的分類準確度測驗則是直接通過分類置信度進行),那么如何繪制處pr曲線?一般的測驗方法是設定一個IOU閾值(如0.5則預測框和GT的IOU大于0.5會被判別為正例),在此閾值下根據不同的查全率水平計算查準率(當然如MSCOCO等更全面的資料集采用的方法是將IOU閾值設定為[0.5,0.95]步長為0.05,對這些閾值水平分別進行測驗再求平均,AP就是PR曲線下方的面積(為什么用曲線下的面積,而不用平衡點處的分類器性能作為指標?),稱作average precision即平均精度,而mAP是把每個類的AP曲線下的面積進行加權平均,即可算出多分類的平均精確度,
但是mAP也有一個問題,就是正負樣本的數量不同的時候會導致PR曲線嚴重失衡(從precision和recall計算方法想想為什么),而ROC和AUC就不會出現這個問題,因此這兩個指標在分類器性能測驗中也很常用,
得到ROC曲線需要查全率和誤診率兩個指標,查全率TPR在上面已經介紹過,這里再介紹false positive rate:它被稱做假陽性率、誤診率和偽正類率,表示所有被分類器判別為負類的樣本有多少實際上是正類(假正類在所有判別為負類的樣本中的占比,FPR=FP/(TN+FP) ),同樣會反映分類的精確程度(同樣你可以思考一下為什么在正負樣本比例失衡的時候ROC曲線不會變形?),
和PR曲線的繪制相同,我們設定不同的分類置信度閾值進而在不同的查全率水平下測驗得到準確率,即可獲得ROC曲線,ROC曲線下方的面積AUC即area under curve同樣也有一些含義,使用AUC值作為評價標準是因為很多時候ROC曲線并不能清晰的說明哪個分類器的效果更好(閾值不同且指標不同),而作為一個數值,對應AUC更大的分類器效果更好,其具體含義為:當隨機挑選一個正樣本和一個負樣本,根據當前的分類器計算得到的score(置信度)將這個正樣本排在負樣本前面的概率,下圖中的(b)可以幫助你更好、更直觀地理解ROC曲線的含義,豎線處theta即設定的分類置信度,
?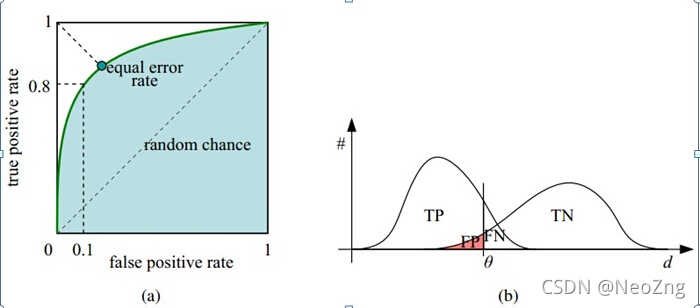
看此圖理解起來沒問題/有新的啟發就說明你大概掌握了這些概念
?如果還是沒懂也沒關系,就把它們當作衡量訓練得到的預測器的好壞的指標即可,這個指標越大越好!
-
公開資料集
列出幾個最常用的目標檢測公開/比賽資料集:
-
VOC(isual object classes chanllenges)2005-2012
經典的計算機視覺競賽,任務包括影像分類、目標檢測、語意分割和動作檢測,20個種類, VOC07和VOC12最為常用,近年來被更大的資料集像ILSVRC和MS-COCO逐漸取代,
-
ImageNet 2010-2017
訓練資料集包含500,000張圖片,屬于200類物體,由于資料集太大,訓練所需計算量很大,因而很少使用,同時,由于類別數也比較多,目標檢測的難度也相當大,一般不會用作檢測網路的性能,二是作為訓練使用,
-
MSCOCO(microsoft common objects in context)2015-now
看名字就知道是巨硬家的,最大的特點是除了bounding box 注釋,還給了segmentation標注,MS-COCO也包含更多的小目標(面積小于影像大小的百分之一)和稠密的目標,這些特征使得MS-COCO更接近于現實生活,MS-COCO已經成了目標檢測家族中的實際標準,
-
-
-
如果覺得筆者總結得還可以,請點一個贊,關注一下筆者吧!還可以把文章轉發給對cv感興趣的同學和其他RMer,
-
下次更新重磅內容,R-CNN!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/333542.html
標籤:其他
上一篇:C/C++程式員是什么讓你有如此優勢?音視頻開發該怎么學?
下一篇:W2-影像增強