一、安裝三臺CentOS 7,
二、虛擬機網路設定,
1.關閉防火墻,輸入命令:systemctl stop firewalld
2.設定靜態ip
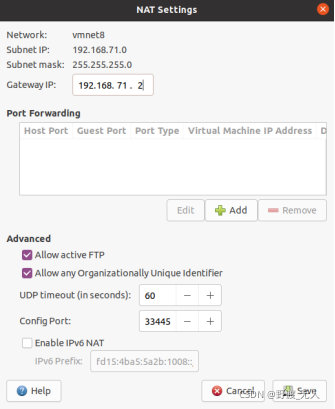
(1)確定網關Gateway IP
-
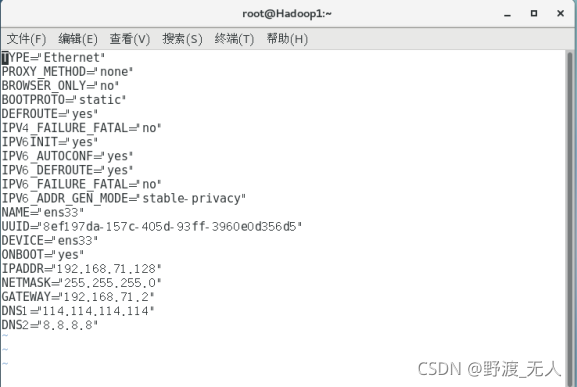
(2)分別為修改三臺虛擬機/etc/sysconfig/network-scripts路徑下,相應的 ifcfg-ens33檔案
-
在終端輸入:vi /etc/sysconfig/network-scripts
-
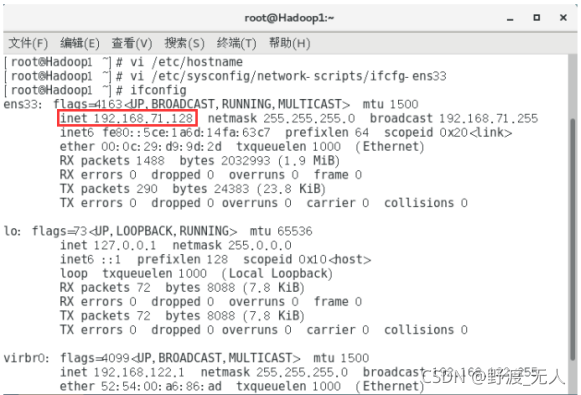
(3)輸入命令 systemctl restart network.service 重啟網路服務;輸入ifconfig即可查看剛剛配置的ip,
(4)修改三臺主機名稱
vi /etc/hostname
Hadoop1
vi /etc/hostname
Hadoop2
vi /etc/hostname
Hadoop3
-
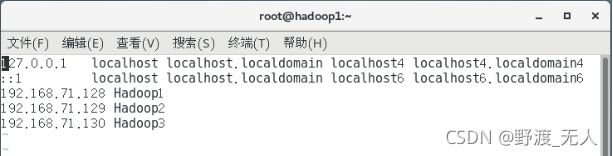
3.配置三臺主機的/etc/hosts檔案,在終端輸入 vi /etc/hosts,添加如圖所示
-
內容
-
三、hadoop和jdk的安裝
-
1.將hadoop-2.7.2.tar移到/opt/module目錄下解壓
-
tar –xvf hadoop-3.2.1.tar
- 2.將jdk-8u144-linux-x64.tar.gz移到/opt/module目錄下解壓
- tar -zxvf jdk-8u144-linux-x64.tar.gz
- 3.配置環境變數,vi /etc/profile,加入如圖所示環境變數
-

-
-
將BOOTPROTO=dhcp改為BOOTPROTO=static
并在最下面加入以下內容
IPADDR=192.168.71.128(Hadoop1)/192.168.71.129(Hadoop2)/192.168.71.130(Hadoop3) //IP
NETMASK=255.255.255.0
GATEWAY=192.168.71.2 //網關
DNS1=8.8.8.8
DNS2=114.114.114.114
4.然后運行source /etc/profile 使檔案生效
-
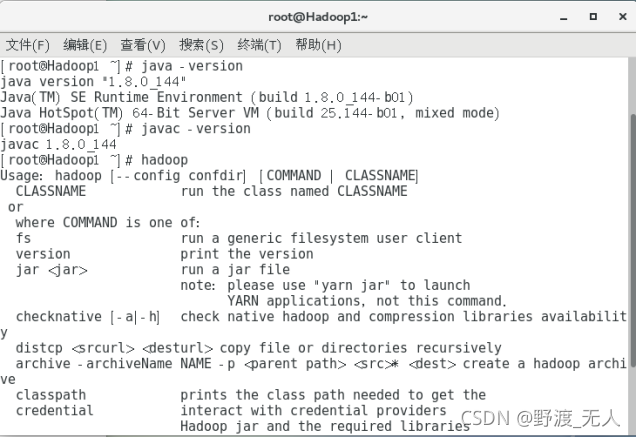
輸入 java -version
javac -version
hadoop
-
進行測驗,結果如下圖
-
四、配置ssh免密登錄
-
1.安裝openssh-server;
yum install -y openssl openssh-server
2.修改組態檔/etc/ssh/sshd_config
vi /etc/ssh/sshd_config
-

- 3.啟動ssh的服務
-
systemctl start sshd.service
- 4.設定開機自動啟動ssh服務
-
systemctl enable sshd.service
- 5.設定檔案夾~/.ssh的訪問權限
-
cd ~
chmod 700 .ssh
- 6.設定免密登錄
-
cd ~/.ssh/
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys
chmod 600 ./authorized_keys
- 7.把三臺的公鑰放在一起即可完成免密驗證
-
ssh-copy-id root@Hadoop2
ssh-copy-id root@Hadoop3
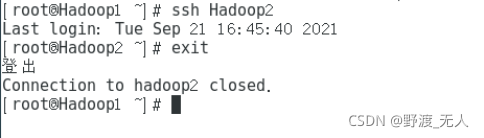
- 8.實驗驗證
-
ssh Hadoop2
-
- 五、配置時間服務器
-
對Hadoop執行1-5步操作
- 1.安裝ntp
-
yum –y install ntp
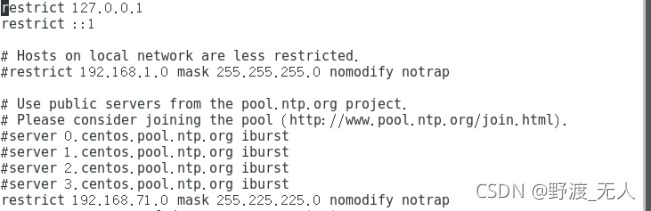
- 2.修改組態檔 vi /etc/ntp.conf
-
添加:
restrict 192.168.71.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
注釋掉:
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
- 3.修改/etc/sysconfig/ntpd檔案,讓硬體時間與系統時間一起同步,添加內容
-
SYNC_HWCLOCK=yes
echo "SYNC_HWCLOCK=yes" >> /etc/sysconfig/ntpd
- 4.重啟ntpd服務
-
systemctl restart ntpd
- 5.設定ntpd為開機啟動
-
systemctl enable ntpd
-
對Hadoop2、Hadoop3執行6
- 6.創建例行性命令,10分鐘與時間服務?同步一次
-
創建/etc/cron.d/ntpupdate.cron檔案,并寫入:
*/10 * * * * root /usr/sbin/ntpdate Hadoop1
echo'*/10* * * * root/usr/sbin/ntpdate Hadoop1'>/etc/cron.d/ ntpupdate.cron
- 六、修改Hadoop組態檔,并下發至集群中的節點
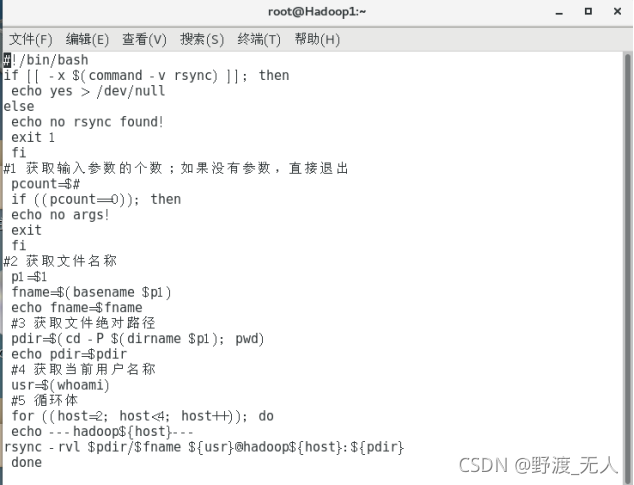
- 1.安裝rsync
- 2.在/usr/local/bin目錄下創建xsync腳本
-
-
-
3..配置core-site.xml檔案并下發至集群中的節點 xsync core-site.xml
-

4.配置hdfs-site.xml檔案并下發至集群中的節點 xsync hdfs-site.x
-

5.配置yarn-site.xml檔案并下發至集群中的節點 xsync yarn-site.xml

6.配置mapred-site.xml檔案并下發至集群中的節點 xsync mapred-site.xml

7.配置hadoop-env.sh檔案、yarn-env.sh檔案、mapred-env.sh檔案的
JAVA_HOME:
JAVA_HOME=/opt/module/jdk1.8.0_144
xsync hadoop-env.sh
xsync yarn-env.sh
xsync mapred-env.sh
七、集群啟動并測驗集群
1.格式化NameNode(注:第一次啟動時格式化,以后無需再進行)
bin/hdfs namenode -format
重新格式化步驟:
(1)停止所有節點上的NameNode和DataNode行程
(2)洗掉所有節點的data和logs檔案夾(hadoop.tmp.dir)
(3)格式化NameNode
2.配置salves
vi salves
加入資料節點
Hadoop1
Hadoop2
Hadoop3
復制到集群的全部節點 xsync salves
3.啟動集群
(1)啟動HDFS
Hadoop1執行 sbin/start-dfs.sh
每個節點都啟動NameNode
sbin/hadoop-daemon.sh start namenode
每個節點都啟動DataNode
sbin/hadoop-daemon.sh start datanode
(2)啟動YARN
Hadoop2(指定的ResourceManager)執行 sbin/start-yarn.sh
每個節點都啟動ResourceManager
sbin/yarn-daemon.sh start resourcemanager
每個節點都啟動NodeManager
sbin/yarn-daemon.sh start nodemanager
4.啟動歷史服務器(Hadoop1)
sbin/mr-jobhistory-daemon.sh start historyserver
5.測驗
(1)jps
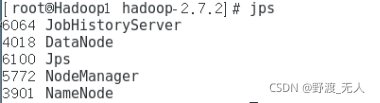
Hadoop1

Hadoop2

Hadoop3
(2)Web UI
使用ip+埠可以在瀏覽器訪問 hadoop頁面

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/333556.html
標籤:其他
上一篇:詳細模板引擎