學習總結
(1)RNN的激活函式一般用tanh(范圍在-1到1之間),之前多分類問題的最后一層用的torch.nn.CrossEntropyLoss(注意已經包括softmax了),而前面的層使用relu,GoogleNet和ResNet我們也是用了relu作為激活函式,
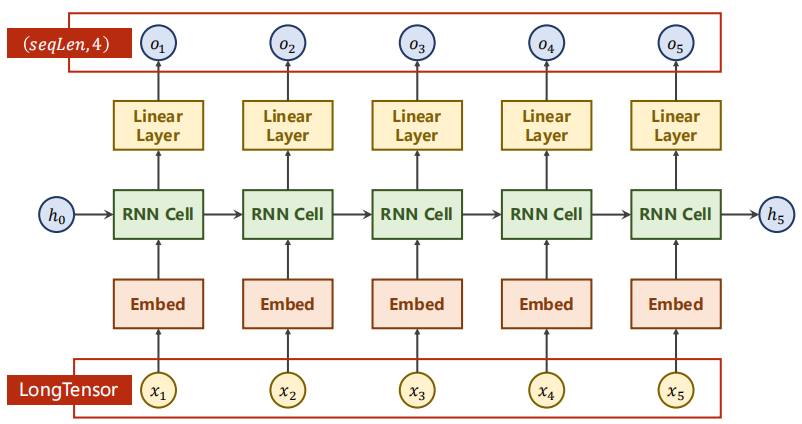
(2)RNN實作我們分別用了三種方法:利用RNN Cell后面重寫回圈呼叫等程序;直接呼叫RNN網路;加上embedding部分的RNN網路(更快收斂),要注意計算好輸入輸出的維度和引數準確,
(3)不止RNN能實作seq2seq任務(如NLP、天氣資料、股市金融資料等序列資料等),還有LSTM、GRU、還有之前學的transformer等都是可以實作的,
PS:用pytorch的Embedding層的輸入必須是要LongTensor型別
文章目錄
- 學習總結
- 一、簡單回顧
- 二、RNN演算法
- 2.1 RNN Cell
- 2.2 文本轉為向量
- 2.3 注意維度
- 2.4 輸出是預測值
- 三、nn.RNN小栗子
- 3.1 如何使用RNNCell
- 3.2 如何使用RNN
- 四、RNNCell訓練
- 五、用RNN模塊訓練
- 六、優化:Embedding
- 6.1 通過embedding降維
- 6.2 embedding改進的代碼
- 七、LSTM網路
- 八、介于RNN和LSTM:GRU
- Reference
一、簡單回顧
全連接被稱為Dense或者Deep層,輸入資料樣本的不同特征,
CNN用了權重共享的概念,而全連接層的引數量是巨大的,所以使用RNN解決如下圖(天氣預報預測)這種帶有序列模式的資料(如NLP、天氣、股市金融資料等),并且使用權重共享的概念來減少引數量,
下圖栗子簡述:已知前三天的天氣,并且每個樣本有3個特征(天數、 溫度、氣壓),label是是否下雨,
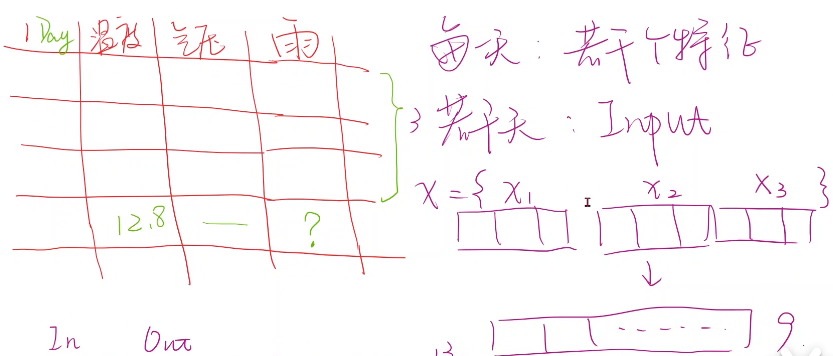
如果需要用影像生成文本,可以用CNN+FC層后的結果輸入RNN,如果沒有先驗前置資訊h0,就設定和h1一樣的全0向量即可(維度要匹配),
二、RNN演算法
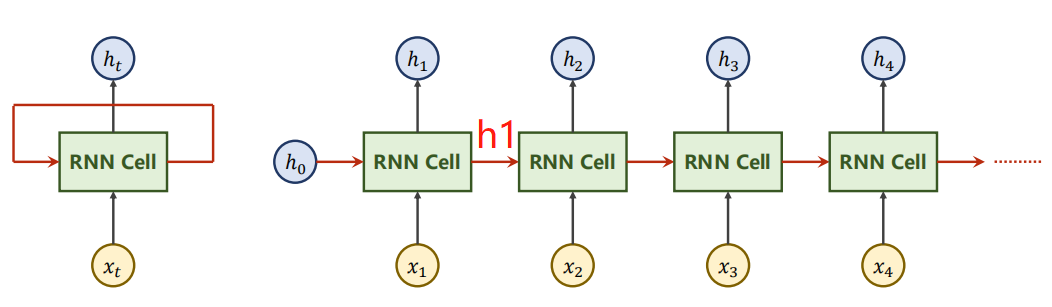
2.1 RNN Cell
RNN Cell本質上為一個線性層(共享權重的線性層,如上圖),在t時刻的N維向量,經過RNN Cell后變為一個M維的向量 h t h_t ht?,
W i h \mathrm{W}_{\mathrm{ih}} Wih?:和輸入向量 x t x_t xt?相乘的權重矩陣,維度大小為 h i d d e n _ s i z e × i n p u t _ s i z e hidden\_size \times input\_size hidden_size×input_size,
W
h
h
\mathrm{W}_{\mathrm{hh}}
Whh?:和隱層向量
h
t
?
1
h_{t-1}
ht?1?相乘的權重矩陣,維度大小為
h
i
d
d
e
n
_
s
i
z
e
×
h
i
d
d
e
n
_
s
i
z
e
hidden\_size \times hidden\_size
hidden_size×hidden_size,
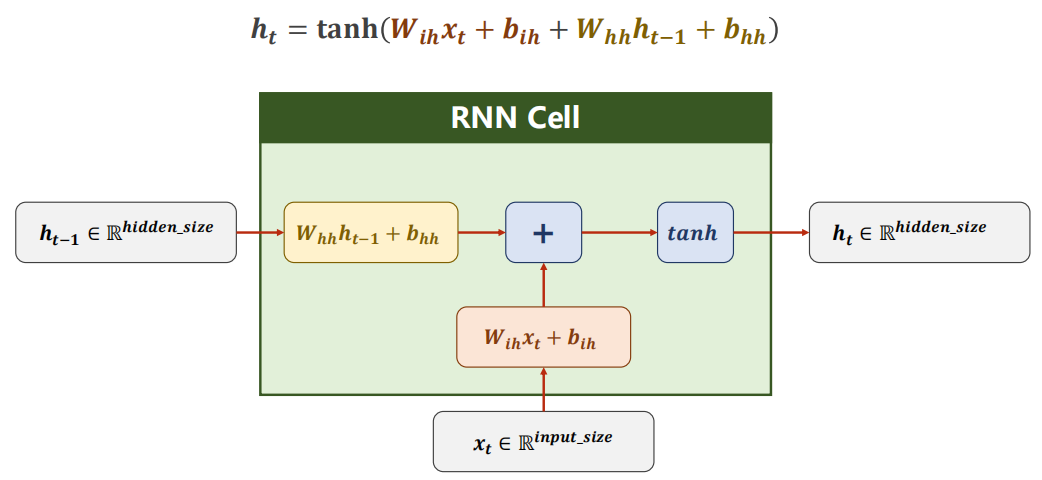
幾點注意:
(1)通過RNN Cell的維度和上一個hidden_size的維度相同,
(2)也可以將兩個線性層的運算合并:

嚴謹寫的矩陣運算形式是:
W
h
h
h
t
?
1
+
W
i
h
x
t
=
[
W
h
h
W
i
h
]
[
h
x
]
\mathrm{W}_{\mathrm{hh}} \mathrm{h}_{\mathrm{t}-1}+\mathrm{W}_{\mathrm{ih}} \mathrm{x}_{\mathrm{t}}=\left[\begin{array}{ll} \mathrm{W}_{\mathrm{hh}} & \mathrm{W}_{\mathrm{ih}} \end{array}\right]\left[\begin{array}{l} \mathrm{h} \\ \mathrm{x} \end{array}\right]
Whh?ht?1?+Wih?xt?=[Whh??Wih??][hx?]
(3)維度的要求:
seqLen = 3指序列長度為3,每個樣本里有x1,x2,x3,
(4)一個batch中,各個元素之間是并行計算;輸入資料是按批次來的,每一批3個,
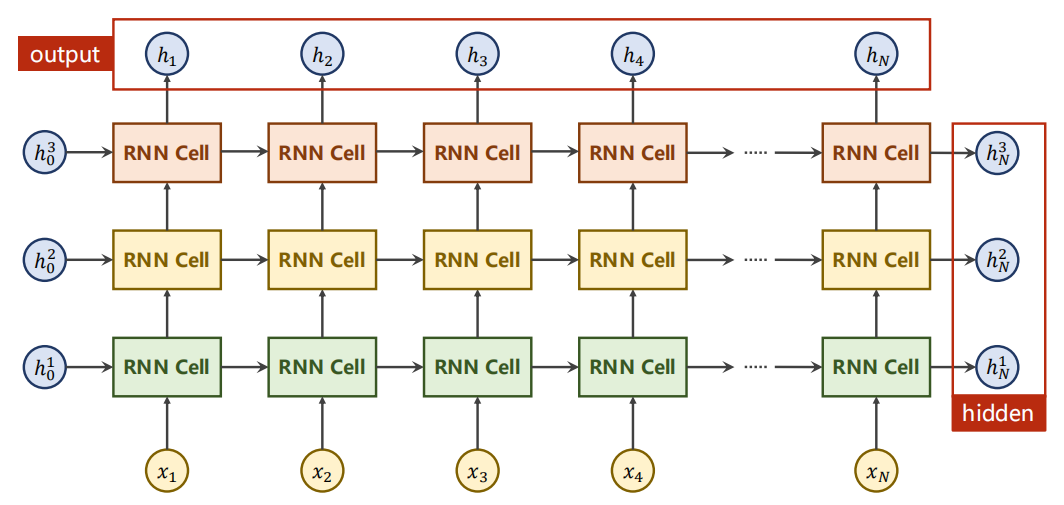
(5)注意輸入的hidden有引數numLayers(如上圖,每種顏色是一個線性層),指RNN的層數,可以發現輸入和輸出的2個引數之間,不同的只有input_size變為hidden_size,

2.2 文本轉為向量
(1)將單詞轉成one-hot編碼,注意下面的input_size為4,

2.3 注意維度
注意訓練部分的內層for回圈的input和inputs的維度:

另外label和labels的維度:

# 訓練模型
for epoch in range(15):
loss = 0
optimizer.zero_grad()
# 初始化h0
hidden = net.init_hidden()
print('Predicted string:', end = '')
# input是(seq × batch × inputsize) 依次拿x1,x2..x5
for input, label in zip(inputs, labels):
# zip函式是沿著第一個維度拼接
hidden = net(input, hidden)
# 沒用item,因為整個序列的loss之和才是損失(要構建計算圖)
loss += criterion(input, hidden)
_, idx = hidden.max(dim = 1)
print(idx2char[idx.item()], end = '')
loss.backward()
optimizer.step()
print(', Epoch [%d/15] loss = %.4f' % (epoch + 1, loss.item()))
2.4 輸出是預測值
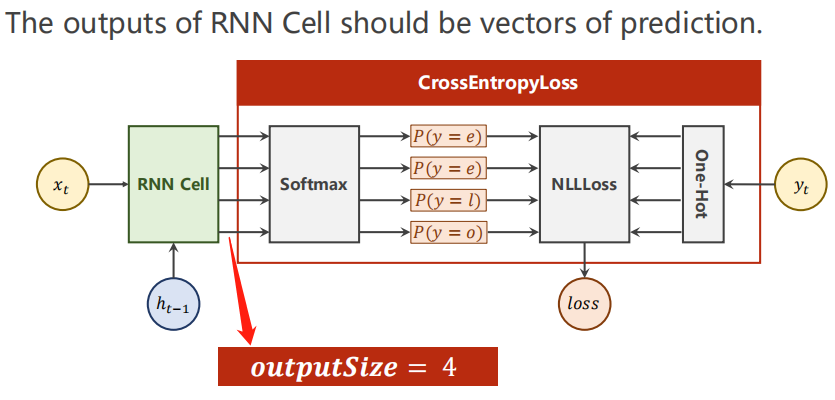
三、nn.RNN小栗子
3.1 如何使用RNNCell
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 23 09:07:58 2021
@author: 86493
"""
import torch
import torch.nn as nn
batch_size = 1
seq_len = 3 # x1, x2, x3
input_size = 4
hidden_size = 2
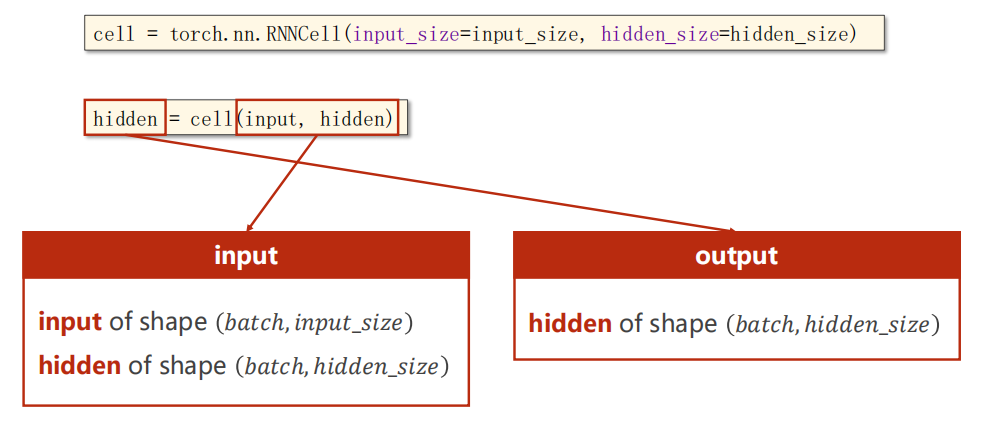
cell = torch.nn.RNNCell(input_size = input_size,
hidden_size = hidden_size)
# (seq, batch, features)
dataset = torch.randn(seq_len,
batch_size,
input_size)
hidden = torch.zeros(batch_size,
hidden_size)
# 分別讀x1, x2, x3
for idx, input in enumerate(dataset):
print('=' * 20, idx, '=' * 20)
# Input size: torch.Size([1, 4])
print('Input size:', input.shape)
hidden = cell(input, hidden)
# outputs size: torch.Size([1, 2])
print('outputs size:', hidden.shape)
print(hidden)
3.2 如何使用RNN
如果直接使用nn.RNN,就不用像3.1一樣自己寫回圈了,
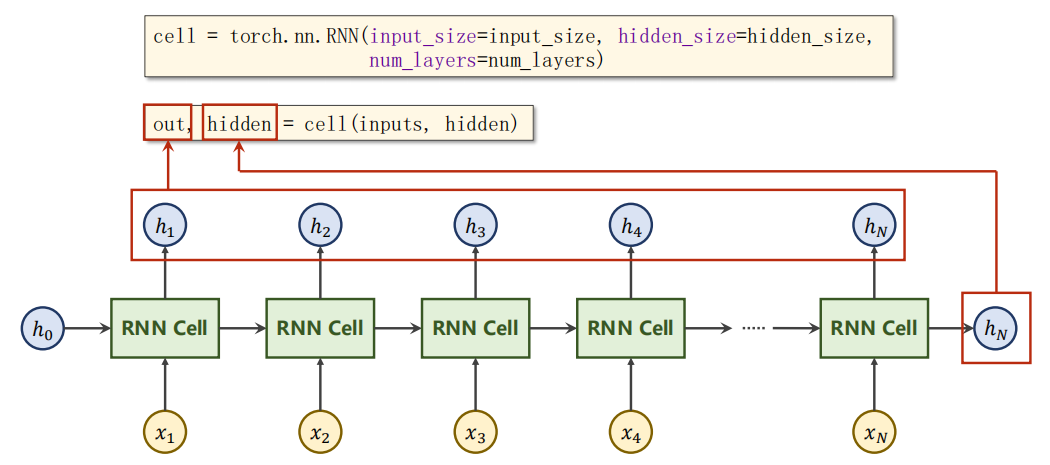
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 23 09:07:58 2021
@author: 86493
"""
import torch
import torch.nn as nn
batch_size = 1
input_size = 4
hidden_size = 2
num_layers = 1
cell = torch.nn.RNN(input_size = input_size,
hidden_size = hidden_size,
num_layers = num_layers)
# (seqLen, batchSize, inputSize)
inputs = torch.randn(seq_len,
batch_size,
input_size)
hidden = torch.zeros(num_layers,
batch_size,
hidden_size)
out, hidden = cell(inputs, hidden)
print('Output size:', out.shape)
print('Output:', out)
print('Hidden size:', hidden.shape)
print('Hidden:', hidden)
結果為:
Output size: torch.Size([3, 1, 2])
Output: tensor([[[-0.2704, -0.7284]],
[[-0.4312, 0.0836]],
[[ 0.6894, -0.9946]]], grad_fn=<StackBackward>)
Hidden size: torch.Size([1, 1, 2])
Hidden: tensor([[[ 0.6894, -0.9946]]], grad_fn=<StackBackward>)
四、RNNCell訓練
在(四)中我們是先實作RNN Cell,再手動寫回圈呼叫訓練等邏輯;在(五)中我們可以直接呼叫RNN網路(代碼會少很多),
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 23 09:17:10 2021
@author: 86493
"""
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
input_size = 4
hidden_size = 4
batch_size = 1
losslst = []
# 準備資料
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(-1,
batch_size,
input_size)
labels = torch.LongTensor(y_data).view(-1, 1)
# 模型設計
class Model(nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size = self.input_size,
hidden_size = self.hidden_size)
def forward(self, input, hidden):
hidden = self.rnncell(input, hidden)
return hidden
# 生成默認的初始隱層h0,batch_size也僅為了構造h0
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size,
hidden_size,
batch_size)
# loss函式和優化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),
lr = 0.1)
# 訓練模型
for epoch in range(15):
loss = 0
optimizer.zero_grad()
# 初始化h0
hidden = net.init_hidden()
print('Predicted string:', end = '')
# input是(seq × batch × inputsize) 依次拿x1,x2..x5
for input, label in zip(inputs, labels):
# zip函式是沿著第一個維度拼接
hidden = net(input, hidden)
# 沒用item,因為整個序列的loss之和才是損失(要構建計算圖)
loss += criterion(hidden, label)
# hidden是四維的(e h l o),找出概率值最大的數的下標
_, idx = hidden.max(dim = 1)
# 每一輪訓練能輸出的預測字串
print(idx2char[idx.item()], end = '')
loss.backward()
optimizer.step()
losslst.append(loss.item())
print(', Epoch [%d/15] loss = %.4f' % (epoch + 1, loss.item()))
plt.plot(range(15), losslst)
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.show()
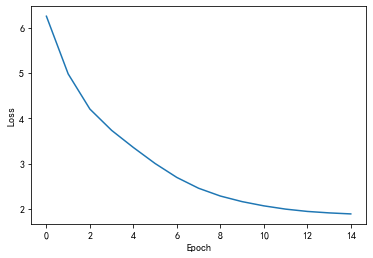
同時從預測的字串結果看,當趨于收斂時,字串是ohlol:
Predicted string:hhhhh, Epoch [1/15] loss = 6.2508
Predicted string:ohlol, Epoch [2/15] loss = 4.9792
Predicted string:ohlol, Epoch [3/15] loss = 4.2028
Predicted string:ohlol, Epoch [4/15] loss = 3.7331
Predicted string:ohlol, Epoch [5/15] loss = 3.3555
Predicted string:ohlol, Epoch [6/15] loss = 3.0020
Predicted string:ohlol, Epoch [7/15] loss = 2.6944
Predicted string:ohlol, Epoch [8/15] loss = 2.4562
Predicted string:ohlol, Epoch [9/15] loss = 2.2846
Predicted string:ohlol, Epoch [10/15] loss = 2.1613
Predicted string:ohlol, Epoch [11/15] loss = 2.0679
Predicted string:ohlol, Epoch [12/15] loss = 1.9959
Predicted string:ohlol, Epoch [13/15] loss = 1.9450
Predicted string:ohlol, Epoch [14/15] loss = 1.9128
Predicted string:ohlol, Epoch [15/15] loss = 1.8900
五、用RNN模塊訓練
用RNN模塊訓練就簡化很多:
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 23 09:17:10 2021
@author: 86493
"""
import torch
import torch.nn as nn
input_size = 4
hidden_size = 4
num_layers = 1
batch_size = 1
seq_len = 5
# 準備資料
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(seq_len,
batch_size,
input_size)
labels = torch.LongTensor(y_data)
# 模型設計
class Model(nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.num_layers = num_layers
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnn = torch.nn.RNN(input_size = self.input_size,
hidden_size = self.hidden_size,
num_layers = num_layers)
def forward(self, input):
hidden = torch.zeros(self.num_layers,
self.batch_size,
self.hidden_size)
out, _ = self.rnn(input, hidden)
# 輸出要變成兩維的,用交叉熵的時候變成一個矩陣
return out.view(-1, self.hidden_size)
net = Model(input_size,
hidden_size,
batch_size)
# loss函式和優化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),
lr = 0.05)
for epoch in range(15):
optimizer.zero_grad()
# 向前傳播
outputs = net(inputs)
# labels的shape是 seq×B×1
# outputs的shape是 seq×B×H
loss = criterion(outputs, labels)
# 反向傳播
loss.backward()
# 更新引數
optimizer.step()
_, idx = outputs.max(dim = 1)
idx = idx.data.numpy()
print('Predicted:', ''.join([idx2char[x] for x in idx]), end = '')
print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))
結果為:
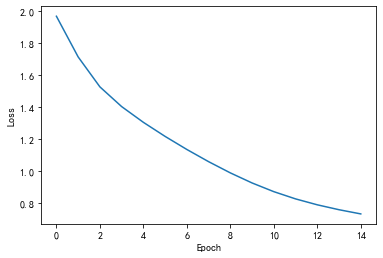
Predicted: lhhhh, Epoch [1/15] loss = 1.481
Predicted: lhlhh, Epoch [2/15] loss = 1.360
Predicted: lhlll, Epoch [3/15] loss = 1.244
Predicted: lhlll, Epoch [4/15] loss = 1.132
Predicted: lhlll, Epoch [5/15] loss = 1.026
Predicted: ohlll, Epoch [6/15] loss = 0.931
Predicted: ohlll, Epoch [7/15] loss = 0.852
Predicted: ohlol, Epoch [8/15] loss = 0.791
Predicted: ohlol, Epoch [9/15] loss = 0.744
Predicted: ohlol, Epoch [10/15] loss = 0.706
Predicted: ohlol, Epoch [11/15] loss = 0.675
Predicted: ohlol, Epoch [12/15] loss = 0.649
Predicted: ohlol, Epoch [13/15] loss = 0.626
Predicted: ohlol, Epoch [14/15] loss = 0.605
Predicted: ohlol, Epoch [15/15] loss = 0.588
六、優化:Embedding
6.1 通過embedding降維
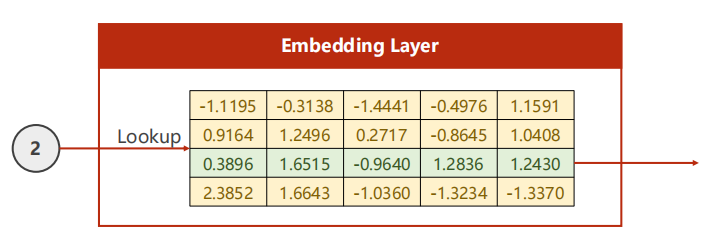
獨熱編碼向量:維度會太高、向量系數、硬編碼,
通過embedding將向量編碼為低維、稠密的向量(從data中學習),
nn.Embedding的shape:

6.2 embedding改進的代碼
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 23 19:12:40 2021
@author: 86493
"""
import torch
import torch.nn as nn
num_class = 4
input_size = 4
hidden_size = 8
embedding_size = 10
num_layers = 2
batch_size = 1
seq_len = 5
# 準備資料
idx2char = ['e', 'h', 'l', 'o']
# (batch, seq_len)
x_data = [[1, 0, 2, 2, 3]]
# (batch * seq_len)
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
# 模型設計
class Model(nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.emb = torch.nn.Embedding(input_size, embedding_size)
self.rnn = torch.nn.RNN(input_size = embedding_size,
hidden_size = hidden_size,
num_layers = num_layers,
batch_first = True)
self.fc = nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
# (batch, seqLen, embeddingSize)
x = self.emb(x)
x, _ = self.rnn(x, hidden)
x = self.fc(x)
return x.view(-1, num_class)
net = Model(input_size,
hidden_size,
batch_size)
# loss函式和優化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),
lr = 0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
# labels的shape是 seq×B×1
# outputs的shape是 seq×B×H
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim = 1)
idx = idx.data.numpy()
print('Predicted:', ''.join([idx2char[x] for x in idx]), end = '')
print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))
這次可以看到第6個epoch就收斂到ohlol了,上次是第8個epoch才收斂到這個單詞,
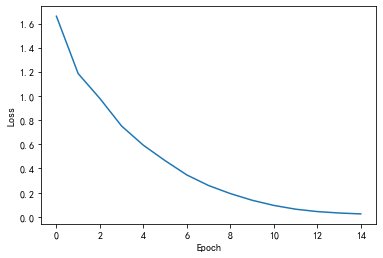
Predicted: oeeol, Epoch [1/15] loss = 1.371
Predicted: ollll, Epoch [2/15] loss = 1.122
Predicted: ollll, Epoch [3/15] loss = 0.980
Predicted: ollll, Epoch [4/15] loss = 0.849
Predicted: ohlll, Epoch [5/15] loss = 0.703
Predicted: ohlol, Epoch [6/15] loss = 0.543
Predicted: ohlol, Epoch [7/15] loss = 0.386
Predicted: ohlol, Epoch [8/15] loss = 0.269
Predicted: ohlol, Epoch [9/15] loss = 0.180
Predicted: ohlol, Epoch [10/15] loss = 0.113
Predicted: ohlol, Epoch [11/15] loss = 0.075
Predicted: ohlol, Epoch [12/15] loss = 0.051
Predicted: ohlol, Epoch [13/15] loss = 0.036
Predicted: ohlol, Epoch [14/15] loss = 0.026
Predicted: ohlol, Epoch [15/15] loss = 0.019
七、LSTM網路
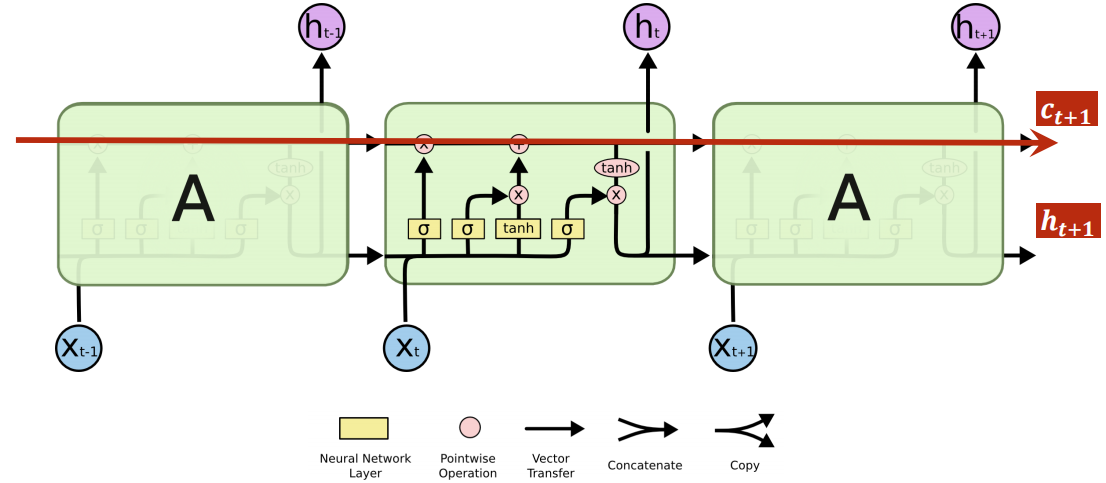
初學LSTM可以先不理很多教程說的××門(可解釋性問題),
可以參考nn.LSTM官方檔案:https://pytorch.org/docs/stable/nn.html#lstm
八、介于RNN和LSTM:GRU
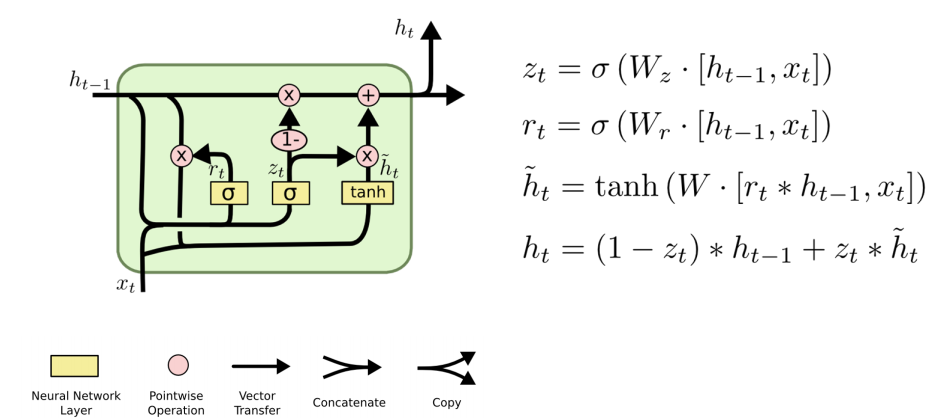
可以參考nn.LSTM官方檔案:https://pytorch.org/docs/stable/nn.html#gru
Reference
(1)https://www.bilibili.com/video/BV1Y7411d7Ys?p=12
(2)pytorch官方檔案embedding類
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/333573.html
標籤:AI
上一篇:R語言使用pheatmap繪制熱力圖(資料歸一化、行列聚類、注釋、文字角度、字體)
下一篇:青衿之志,履踐致遠