hadoop偽分布式安裝教程:
在安裝hadoop之前我們需要做一些準備作業:
- 準備好一臺linux的的虛擬機(本人使用的是centos 8)
- 準備好一些安裝資源包:
jdk:國內鏡像源下載
hadoop:國內鏡像源下載
XshellH和Xftp:官網下載 - jdk和hadoop的部署
- 因為hadoop是Java撰寫的,因此子啊部署hadoop時,一定要把JDK配置好
- hadoop共有3種模式:完全分布式(集群分布模式)、偽分布式模式、本地運行模式,
- 本文部署的是偽分布模式,完全分布式比較復雜,后期可能會作出一個此類的教程
- SSH免密登錄
- 啟動hadoop
- 關閉hadoop
1.虛擬機的安裝相信大家已經安裝成功了,但是我們一定要注意自己的網路一定要可以和外界相通,通過ping www.baidu.com可以查看自己的網路是否暢通 ,在這里筆者不進行詳細的描述,此臺Linux的hostname為hadoop200且IP地址為192.168.56.200,
2.下載對應的資源包,本人采用的是jdk為1.8版本,hadoop為3.1.3版本,可以到對應的鏈接進行下載,
3.我們打開linux,使用Xshell進行遠程連接,在/opt目錄中創建兩個檔案夾:software和module(在這里我們使用root用戶),在對應的位置輸入IP地址進行遠程連接,
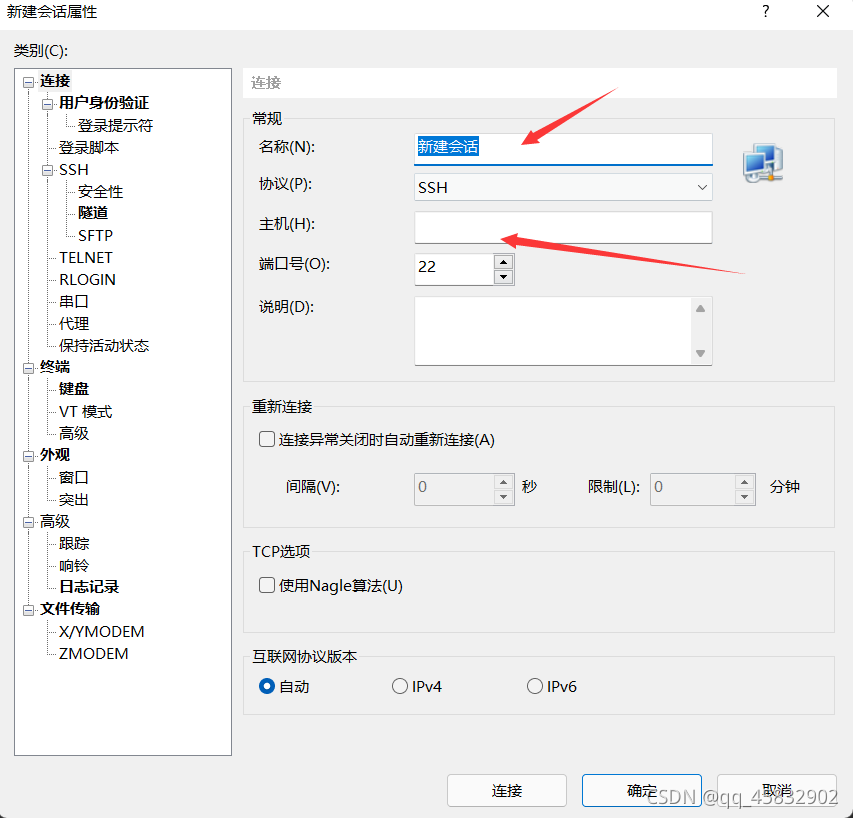
cd /opt/
mkdir software
mkdir module
接著我們使用Xftp傳輸jdk和hadoop,上傳到linux/opt/software中
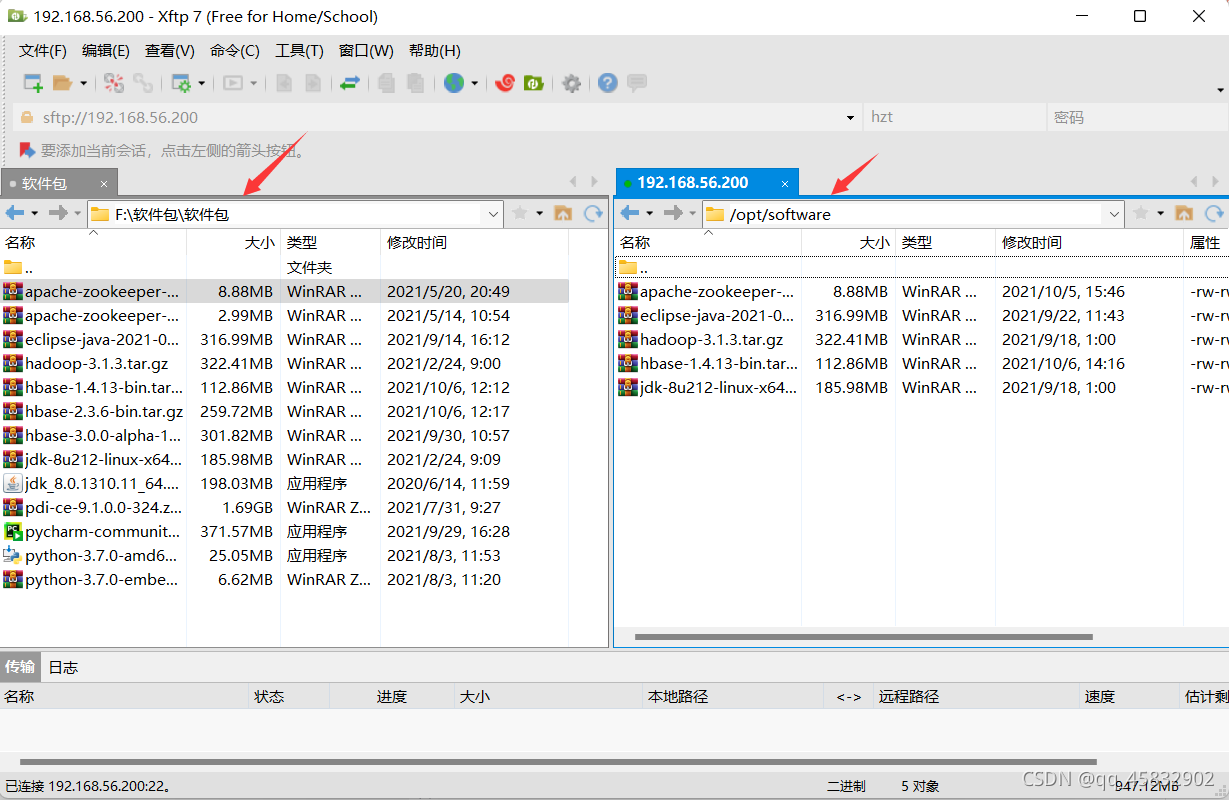
然后我們開始解壓jdk和hadoop,目標位置為/opt/module
# 解壓jdk
tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module/
# 解壓hadoop
tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/
接下來配置jdk和hadoop的環境變數
vim /etc/profile.d/my_env.sh
加入以下變數:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk-8u212 # 此變數為你解壓jdk的目錄
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3 # 此變數為你解壓hadoop目錄
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
下一步 `source /etc/profile
在命令列輸入java和hadoop,查看是否成功配置環境變數,
在hadoop的官方檔案中我們需要配置2個XML檔案:
etc/hadoop/core-site.xml(注意是hadoop目錄下的etc!)/etc/hadoop/hdfs-site.xml(同上)
將下列配置復制到你的XML檔案中
- core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<!----下面為你解壓hadoop的目錄注意后面有該目錄的hadoop/tmp---->
<value>file:/opt/module/hadoop-3.1.3/hadoop/tmp</value>
<description>Abase for other temporary directories,</description>
</property>
<property>
<name>fs.defaultFS</name>
<!----下面的變數(hadoop200)修改為你的主機名--->
<value>hdfs://hadoop200:9000</value>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/module/hadoop3.1.3/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/module/hadoop-3.1.3/tmp/dfs/data</value>
</property>
</configuration>
基本配置已經完成,在啟動hadoop中的hdfs時需要格式化namenode
hdfs namenode -format
# 出現successful 即可
然后進入hadoop的/sbin目錄使用
start-dfs.sh和stop-dfs.sh進行啟動和關閉
···
在啟動hdfs時需要配置一下SSH免密登錄
cd /
ssh-keygen -t rsa # 然后3次回車
然后進入到.ssh目錄中,將公鑰檔案 id_rsa.pub 中的檔案內容復制到想同檔案下的 authorized_keys 檔案中
cat id_rsa.pub >> authorized_keys
完成SSH免密配置之后,我們可以啟動hdfs,通過
jps查看hdfs的行程

可能出現的問題
- 問題一:
大家在使用其他用戶的時候可能會出現權限的問題,我們通過root權限賦予其權限
chmod 777 -R /opt/module/
2.問題二:
在使用root的權限開啟時可能會出現一下錯誤:
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
我們只需要更新2個組態檔start-dfs.sh、stop-dfs.sh即可:
在shell腳本中加入一下內容:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
本人才疏學淺,初識大資料,用心整理的文章(本人的處女作),希望可以幫助一些迷茫的同學,當然本文可能會出現錯誤,希望大家隨時指正,謝謝大家!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/333630.html
標籤:其他
上一篇:資料倉庫技術選型
下一篇:Redis異步佇列與延時佇列