Spark 初識
從今天開始我們進入資料倉庫的查詢引擎篇了,前面我們已經寫了大量的文章介紹Hive,具體你可以看hive 的專欄,而且關于工具這一塊我們的重點就在hive 上,后面關于spark、presto、impala、clickHouse的介紹都不會像前面這樣細了,因為我們的重點是在數倉建設的方法論上面,而不是工具上面,

Spark是什么
Spark 是一種高效且多用途的集群計算平臺,換句話說,Spark 是一種開源的,大規模資料處理引擎,它提供了一整套開發 API,包括流計算、機器學習或者SQL,Spark 支持批處理和流處理,批處理指的是對大規模資料一批一批的計算,計算時間較長,而流處理則是一條資料一條資料的處理,處理速度可達到秒級,
Spark 集成了許多大資料工具,例如 Spark 可以處理任何 Hadoop 資料源,也能在 Hadoop 集群上執行,大資料業內有個共識認為,Spark 只是Hadoop MapReduce 的擴展(事實并非如此),如Hadoop MapReduce 中沒有的迭代查詢和流處理,然而Spark并不需要依賴于 Hadoop,它有自己的集群管理系統,更重要的是,同樣資料量,同樣集群配置,Spark 的資料處理速度要比 Hadoop MapReduce 快10倍左右,這主要是因為spark 強大的設計和對計算的優化,
Spark 的一個關鍵的特性是資料可以在記憶體中迭代計算,提高資料處理的速度,雖然Spark是用 Scala開發的,但是它對 Java、Scala、Python 和 R 等高級編程語言提供了開發介面,
Apache Spark演變
2009年,Spark 誕生于伯克利大學的AMPLab實驗室,最初 Spark 只是一個實驗性的專案,代碼量非常少,屬于輕量級的框架,
2010年,伯克利大學正式開源了 Spark 專案,
2013年,Spark 成為了 Apache 基金會下的專案,進入高速發展期,第三方開發者貢獻了大量的代碼,活躍度非常高,
2014年,Spark 以飛快的速度稱為了 Apache 的頂級專案,
2015年至今,Spark 在國內IT行業變得愈發火爆,大量的公司開始重點部署或者使用 Spark 來替代MapReduce、Hive、Storm 等傳統的大資料計算框架,
為什么使用Spark
Spark 誕生之前,在大資料處理領域,并沒有一個通用的計算引擎,
離線批處理使用 Hadoop MapReduce
流處理需要使用 Apache Storm
即時查詢使用 Impala 或者 Tez
執行圖計算使用 Neo4j 或者 Apache Giraph
而Spark囊括了離線批處理、流處理、即時查詢和圖計算4大功能,
早期我們任務spark 是MR 替代品,這是因為MR 對資料集的處理并不高效,這主要體現在迭代演算法和互動式查詢,這兩種場景下,如果能將資料保存到記憶體中都將極大的提高效率,從而避免每次都需要從HDFS 上將資料讀取出來,
Spark組件
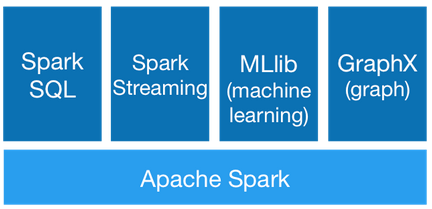
Spark提供了6大組件:
- Spark Core
- Spark SQL
- Spark Streaming
- Spark MLlib
- Spark GraphX
- SparkR
這些組件解決了使用Hadoop時碰到的特定問題,
Spark Core
將分布式資料抽象為彈性分布式資料集(RDD),實作了應用任務調度、RPC、序列化和壓縮,并為運行在其上的上層組件提供API,所有Spark的上層組件(如:Spark SQL、Spark Streaming、MLlib、GraphX)都建立在Spark Core的基礎之上,它提供了記憶體計算的能力,因此,Spark Core是分布式處理大資料集的基礎,
Spark SQL
Spark Sql 是Spark來操作結構化資料的程式包,可以讓我使用SQL陳述句的方式來查詢資料,Spark支持 多種資料源,包含 Hive 表,parquest以及JSON等內容,
Spark Streaming
除了處理動態資料流,Spark Streaming 還能開發出強大的互動和資料查詢程式,事實上,在處理動態資料流時,流資料會被分割成微小的批處理,這些微小批處理將會在Spark Core上按時間一個一個執行,且速度非常快,
Spark MLlib
Spark MLlib 封裝了很多高效的機器學習演算法,它是資料科學最熱門的選擇,因為它是在記憶體處理資料的,非常有效的提高資料迭代演算法的性能,
Spark GraphX
Spark GraphX一個建立在Spark之上大規模處理圖資料的計算引擎,
SparkR
SparkR 是一個 R 語言包,它提供了輕量級的方式使得可以在 R 語言中使用 Apache Spark,在Spark 1.4中,SparkR 實作了分布式的 data frame,支持類似查詢、過濾以及聚合的操作(類似于R中的data frames:dplyr),但是這個可以操作大規模的資料集,
pySpark
是spark 提供的python 的api,而且最新的spark 將引入pandas 的api ,這算是對資料作業者的又一大福音,
spark 在數倉的應用
因為我們的課程是針對數倉的,所以我們這里介紹一下spark 在數倉里的應用,這主要是我們將spark作為一個高性能的查詢引擎來使用,也就是說我們ETL 的作業可以使用spark 完成,但是這里的意思不是事說我們就不需要Hive 了,因為我們的數倉表涉及到大量的元資料,而spark 需要操作這些表就需要這些元資料,所以說在數倉里面我們的spark還是依賴Hive 的元資料的,
這里需要說明一下,spark本身事可以單獨使用的,不需要依賴Hadoop,不需要依賴Hive,但是因為我們需要操作Hive 的表,所以依賴Hive,還有一點就是我們的Hive現在支持多種查詢引擎,默認的就是MR,也就是我們俗稱的Hive on MR,初次之外我們的Hive 還支持 TEZ 和 Spark 引擎,
數倉里使用Spark ,一般指的是使用Spark 的批計算,主要就是Spark-SQL, 這里我們強調的是主要,如果你學習了我們前面的文章的話,就知道我現在所在的公司里還是用到了Spark的Grap以及Spark 的其他的組件,
總結
Spark 作為一個批流一體的的計算引擎,雖然流計算上存在一定的缺陷,但是在當時的技術背景下它具有顛覆性的意義,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/333634.html
標籤:其他
上一篇:2021精選 Java后端面試題資料大全 SpringBoot,Kafka,Mysql,Redis等PDF資料,實戰專案,阿里巴巴,騰訊,位元組,京東,美團,滴滴,Bilibili面試經歷,實用干貨