大家好,我是@jxwd(健祥無敵~~~~哈哈)
寫在前面
各位小伙伴還在為C語言的學習而苦惱嘛?
還在為沒有知識體系而煩心嘛?
別急,因為~~~~
接下來的兩個多月,我會持續推出C語言的有關知識內容,都是滿滿的干貨,從零基礎開始哦~,循序漸進😀,直至將C中知識基本全部學完🐂,關注我?,訂閱專欄 0基礎C語言保姆教學,就可以持續讀到我的文章啦😀🐕~~~~
本文為萬字長文,滿滿干貨,為防止找不到,可以收藏再看呦😀
本文為第二節~~~
文章在看本章節前,請確保已經掌握了第一節的內容呦,不懂的歡迎在評論區留言~~~~
jxwd,讓你服氣,拒絕水文,從我做起!
本節定位:初步了解認識一下C中的知識,所有的知識都是點到為止,
目的是能夠看懂別人寫的代碼,不要求自己能夠寫出非常標準的代碼;是在接下來章節的介紹中筆者的舉例讀者可以更好的接受,比如在函式的介紹中我們會用到指標,
所有的知識點我們都會在接下來的章節一一詳細介紹
所以,讀者在閱讀本章的時候,只需要知道有這么個東西,并且能夠理解筆者所說的含義即可,
本節我們將沿著上一節介紹:
本節內容有:
目錄
1、 資料型別
1-1 資料的創建
1-2 資料的列印
1-3 資料的大小
2、常量和變數
2-1 變數的分類、作用域和生命周期
2-1-1區域變數:
2-1-2 全域變數:
2-1-3 變數的作用域和生命周期
2-1-4 變數的使用
2-2 常量
2-2-1 常量的型別
3、陣列
3-1 陣列的宣告
3-2 陣列的初始化
3-3 陣列的訪問
4、字串
5、轉義字符
6、代碼注釋
7、函式
8、選擇陳述句
9、回圈陳述句
10、運算子
10-1 下標參考、函式呼叫和結構成員
10-2 算術運算子
10-3 移位運算子
10-4 位運算子
10-5 邏輯運算子
10-6 賦值運算子
10-7 關系運算子
10-8 條件運算子
10-9 單目運算子(只對一個數或陳述句操作的叫單目運算子)
10-9-1 ! 邏輯反操作 (很簡單,就是如果陳述句為真,那前面加上!陳述句就變成了假)
10-9-2 - 負值
+ 正值
10-9-3 & 取地址
10-9-4 sizeof
10-9-5 -- 前置、后置--
++ 前置、后置++
10-9-6 * 定義指標(解參考)
10-9-7(型別) 強制型別轉換,
11、常見關鍵字
11-1 auto
11-2 break與continue
11-3 extern
11-4 static
11-4-1 修飾函式
11-4-2 修飾全域變數
11-4-3 修飾區域變數
11-5 typedef
11-6 define
12、指標
13、結構體
13-1 結構體的創建
13-2 結構體成員的訪問
14、*動態記憶體分配初步
注:上述帶*的內容可以不用在本節掌握,讀者可以在這里當作一種視野拓展,以滿足讀者的好奇心,
C語言除了以上內容,筆者還會給大家介紹
檔案操作 和 編譯鏈接,
但這兩部分比較復雜,我們本節不提,如果想看,歡迎訂閱專欄,關注@jxwd,這樣就能第一時間看到我更新的文章啦,
(雖然是萬字長文,而且有二三十張配圖,但我敢說沒幾個人能認認真真從頭看到尾😀![]() )
)
話不多說,我們開始,
還記得我們在上一節輸出了第一個C程式,那么,讀者應該掌握C語言的基本程式框架,
當然,如果不記得了,我們可以在這里再次重復一下,用一張圖片來表示就行,如下圖:
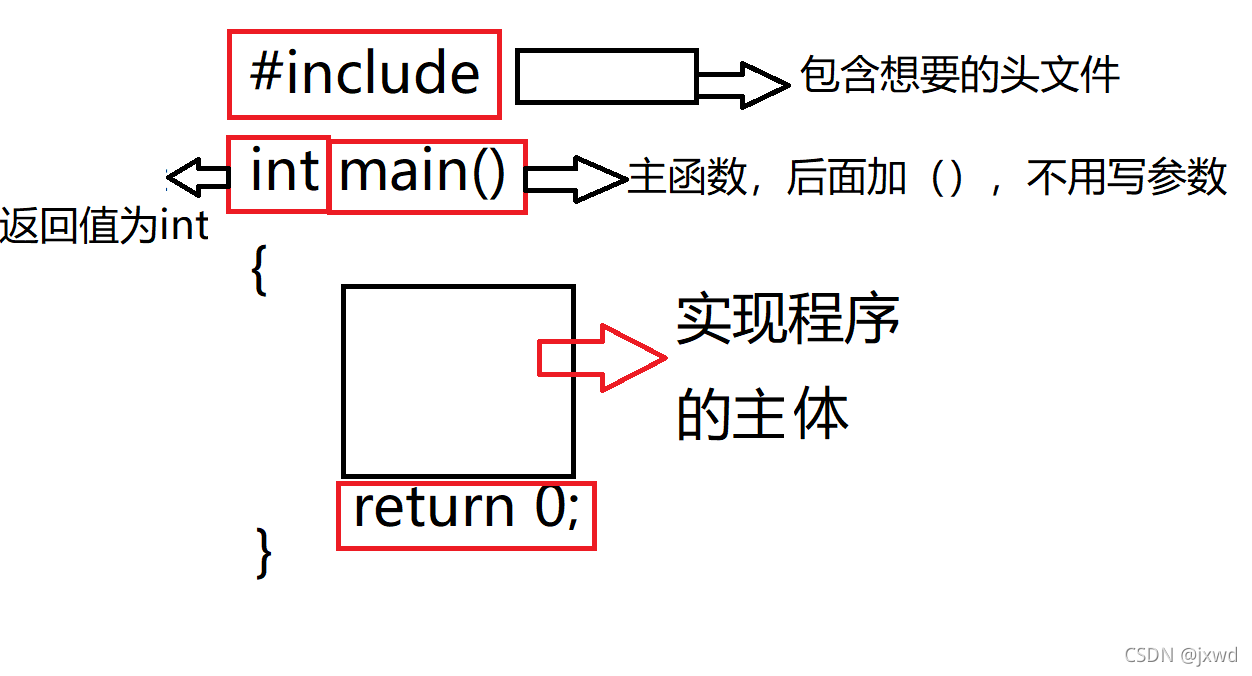
1、 資料型別
資料型別是固定大小記憶體的別名
常見的資料型別有哪些呢?
char 字符型
int 整形
long (int) 長整型
long long (int) 更長的整形
short (int) 短整型
float 單精度浮點型
double 雙精度浮點型
注明一下:在這里,可以通俗的理解:
①字符型為鍵盤上能敲出的任意一個單個字符,
②整形為正數,浮點型為小數,
那這些型別是干什么的,怎么用呢?(建議初學者講筆者所有的代碼在自己的編譯器上自行操作一遍,實操很重要!)
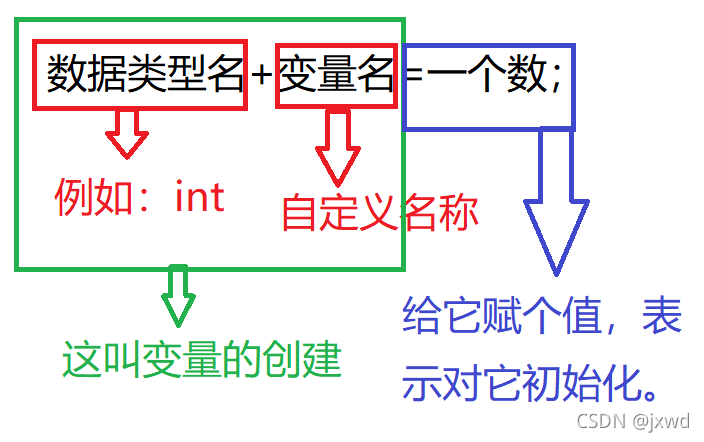
1-1 資料的創建

像這樣,我們分別將上述每一個型別都創建了一下,并且將其初始化了,所以,像上述的創建方式,可以總結為: 資料型別名+ 自定義型別名,給它賦了一個值(這里的10.2f仍然是一個數,我們下面會講)意為給它初始化了一下,
1-2 資料的列印
我們來看下面一段代碼:(為了使讀者得到更多的練習,筆者在此盡量以截圖的形式來呈現代碼)
代碼敲完后,按ctrl+(fn)+f5
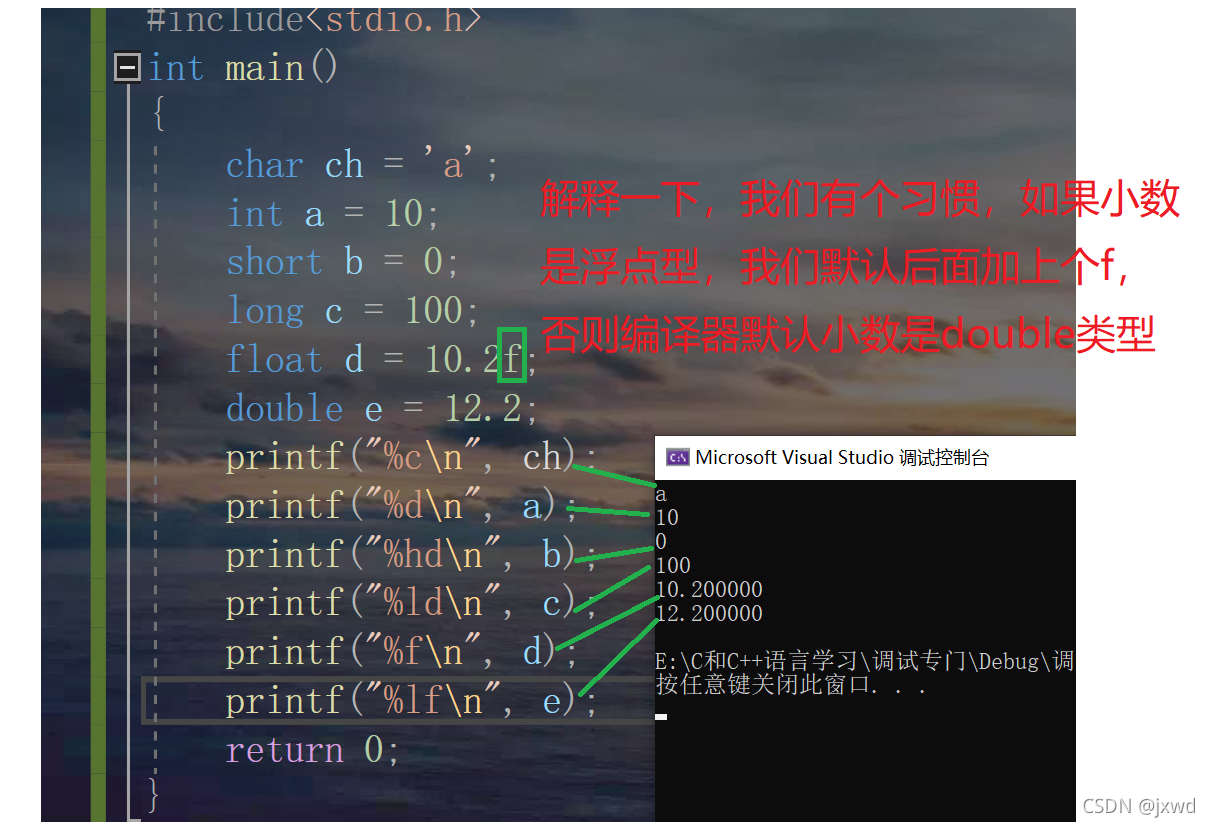
如圖,我們將上圖的六個資料列印出來,得到了相對應的六個資料,
我們發現這樣幾個規律:
①在printf函式(即列印函式)中,都是以類似于(“%() ”, );列印出來的,
②每一行的型別不同,列印時%后面跟的字母也不相同,
③每一個printf中都含有一個'\n',它表示換行,(否則,列印出的形式將會是如下的形式:)
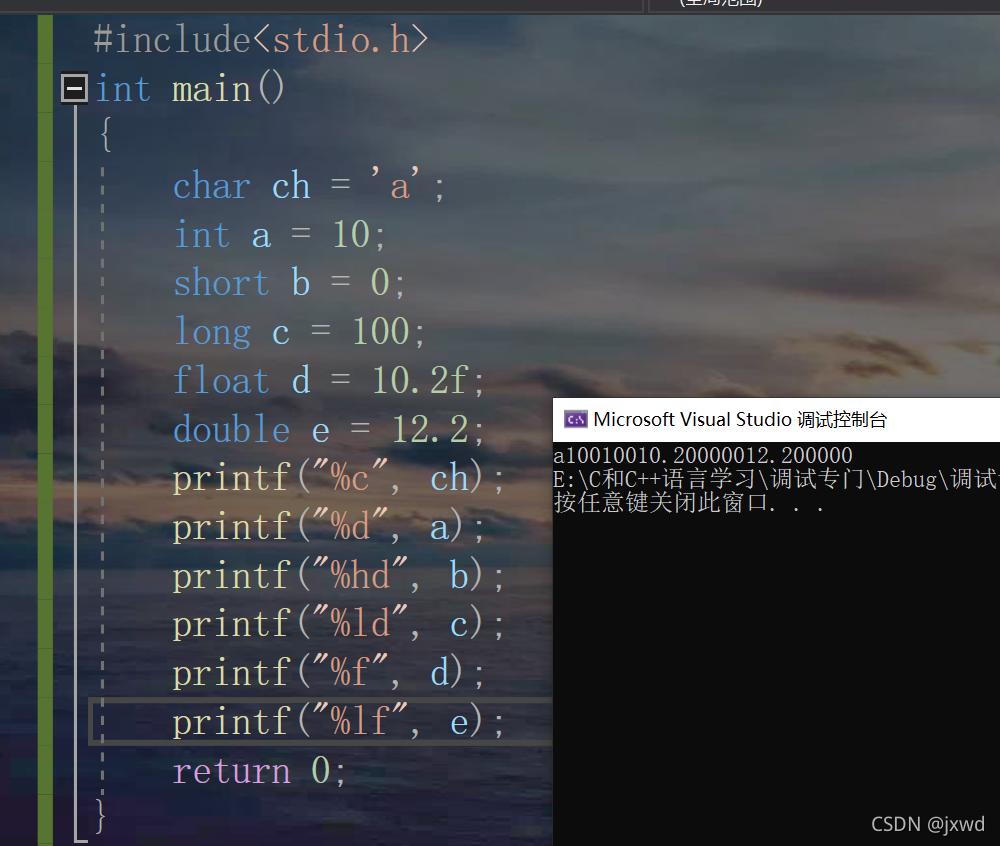 很挫是不是,,,,,,,
很挫是不是,,,,,,,
我們提一下%后面的字母是什么意思:
在C語言中,列印型別需要遵守一定的規則,就是在列印前需要先告訴編譯器你列印的是什么型別,%d代表我后面要列印整形;%hd表示我后面要列印short型別;%f表示我后面要列印float型別....其他類推,
在前面告訴完編譯器要打的型別后,還要再在后面寫入要列印的變數名字(就是說要列印誰的值)
附:部分%后面跟著不同字母的不同含義:(如果讀者對部分不理解可以先放一放)
| %c | 列印char (字符型別) |
| %d | 列印int(整形) |
| %f | 列印float(單精度浮點型) |
| %lf | 列印double(雙精度浮點型) |
| %p | 列印地址 |
| %s | 列印字串 |
| %u | 無符號的十進制形式列印整形 |
| %x | 以十六進制形式列印 |
| %o | 以八進制形式列印 |
1-3 資料的大小
每一種型別的資料的大小又是多少呢?
我們用一個C語言中的關鍵字:sizeof來實作這個功能,其中sizeof的含義是求某個資料型別所占空間的大小,單位是位元組,比如sizeof(int)就是指int 的資料所占的記憶體大小,
我們來看下面一段代碼:
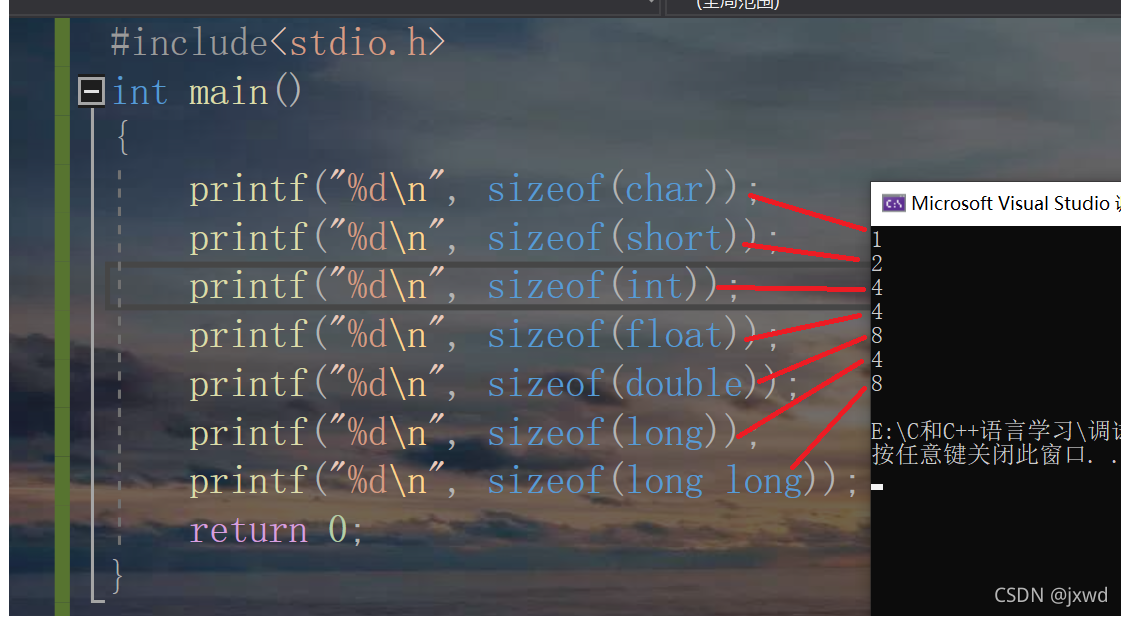
如圖,我們可以看到,char型別的大小是1個位元組;short型別的是2個位元組;int 型別的是占4個位元組;float也是4個位元組....(注:long在有的編譯環境下不是4個位元組,而是8個位元組)
在這里,我們需要補充一個硬知識:
計算機存盤資料示意二進制的形式存盤,每一個0或者1占據一個位元位,
一個位元組=8個位元位;
一個kb=1024個字節;
一個MB=1024個kb;
一個GB=1024個MB;
一個TB=1024個GB;.......
而在我們上文中所說,int占4個的是位元組,char占1個的是位元組....
這樣說,可能對于位元組的大小理解得更加深刻點吧,,,,,,
好,關于資料型別就先給大家介紹到這里,大家只要會創建、會列印,知道它們占據空間的大小就行,
2、常量和變數
第一個問題還是要問:
什么叫變數?
· 變數,顧名思義就是可以改變的量,
像我們上面所說的創建的變數,即a,b,c,d,e,ch,它們都稱之為變數,
因為它們所表示的值都可以改變,比如,我可以讓a+1,也可以讓b-1,讓c等于50等等,這個并不難理解,
2-1 變數的分類、作用域和生命周期
變數分為:區域變數和全域變數,
2-1-1區域變數:
定義于區域的變數,
這里的區域指的是在函式的內部中宣告的,例如:


左上圖中, 這里的a定義于main函式的內部,可以認為,它是一個區域變數,
同樣的道理,在由上圖中,我們的add是一個函式(函式具體的細節我們后面討論,現在知道它是一個函式)中的b也就是一個區域變數,
2-1-2 全域變數:
作用于整個專案的變數,
例如:(如下圖)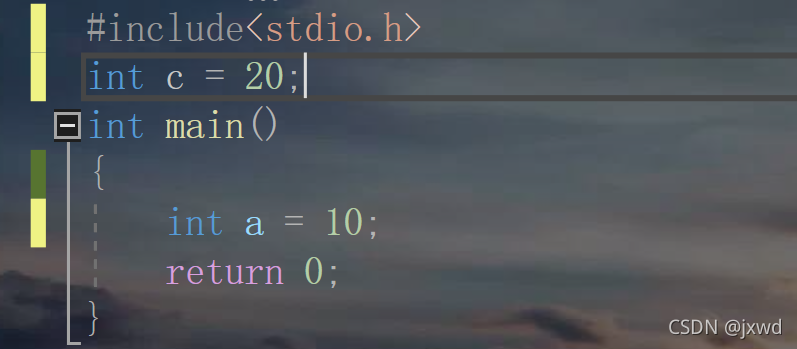
這里的c就是全域變數, 在全域范圍內定義的變數,
區域變數和全域變數類似于整體和區域的關系,
當區域變數和全域變數的名稱沖突時,區域優先,(相當于區域又重新定義了一次)
例如:
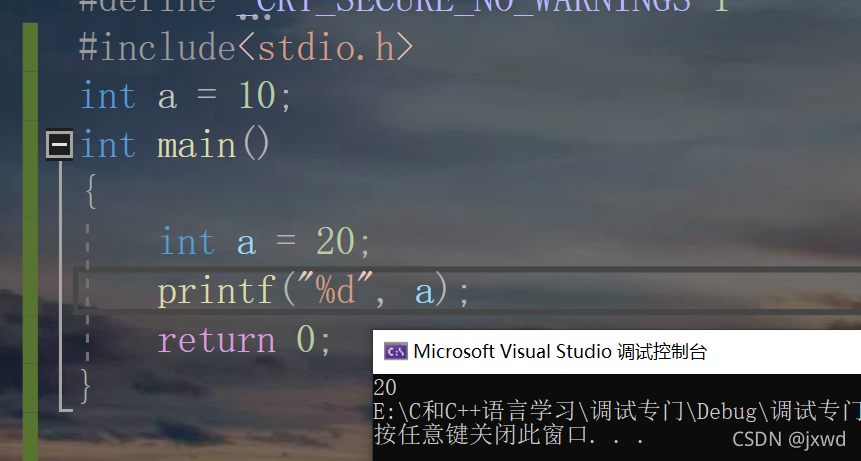
看,列印出來的就是20,
因為在printf這個地方,區域的a是優先于全域的,
2-1-3 變數的作用域和生命周期
1、對于全域變數來說,變數的作用域為整個專案工程,生命周期與專案的執行周期相同,
2、對于區域變數來說,其作用域為其所在的整個函式,生命周期為其所定義之時起,至函式運行結束后終止,(函式運行結束后,該變數所會被銷毀,所占用的空間會還給記憶體)
我們通俗的說一下,全域變數在整個專案運行的程序中一直存在,并且一直可以用,但是全域變數在出了所定義的它的函式之后便銷毀,便不再存在,
2-1-4 變數的使用
我們以輸入輸出來學習變數的使用,
我們來完成這樣一個任務:
輸入兩個數,并列印這兩個數,
我們把樣例代碼給出,讀者可以自行去打著試一下:
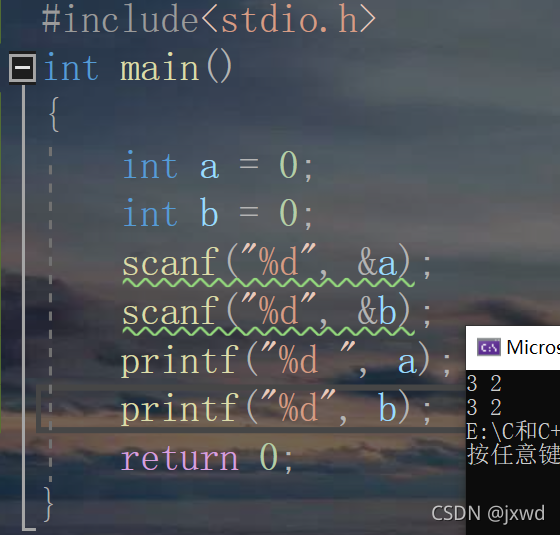
讀者可以看到,我們在這里引入了一個新的函式scanf,
scanf函式是一個輸入函式,用于輸入資料,它的用法與printf相似,類似于(“%() ”, );但是有的讀者已經注意到,我們在變數的前面加了一個&,它在這里的意思是取地址,原因是我們輸入是要對變數a,b所在的地址進行輸入,如果不加上這個&,編譯會報錯,
打完代碼后,我們按住ctrl+(fn)+f5,讓代碼運行,
我們在控制臺輸入3 2(注意兩個數字間有一個空格)
然后我們可以看到,在螢屏上輸出了兩個數字3 2,(輸出中間之所以有空格,是因為第一個%d后面我們加了一個空格)
這就是標準輸入輸出!
關于scanf會報錯(注意是報錯不是報警告)如何解決,推薦大家看一個視頻介紹,看完后就知道該如何解決了,
【C語言學習問題】VS2013編譯器對函式不安全報錯的解決辦法_嗶哩嗶哩_bilibili
那什么叫常量呢?
2-2 常量
常量,是指在給出值以后,不可以再被修改的量,(注意:這里我們所說的值是一個廣泛的概念)
2-2-1 常量的型別
在目前的階段,我們接觸到的常量有如下四種型別,
1、直接定義的數值常量,
2、const 修飾的常變數,
3、#define定義的常量,
4、列舉型別常量,
我們接下來舉幾個栗子:
第一種:直接定義的數值常量,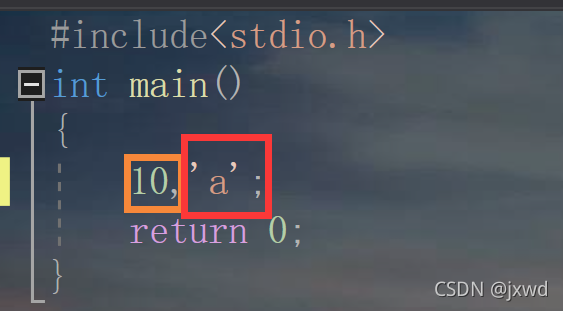
像這樣,10表示一個數值常量;而字符‘a'表示一個字符常量,它們都是我們直接定義的數值常量,
第二種:const 修飾的常變數,來看:
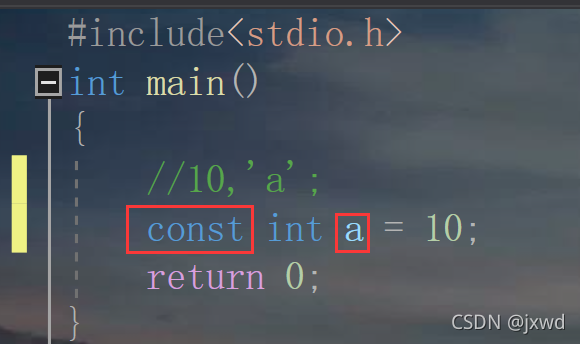
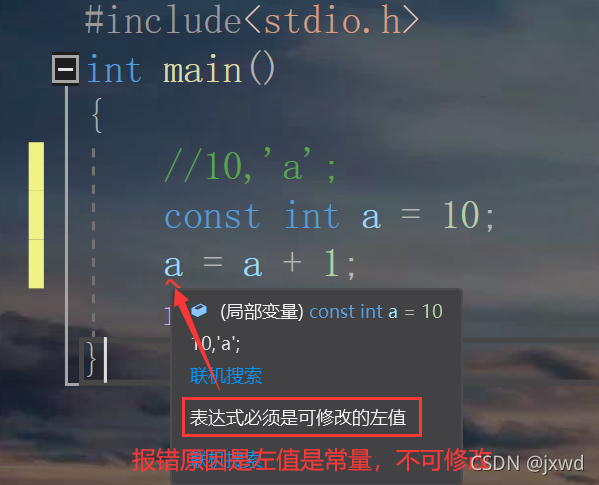
像這樣,前面由const修飾的變數a,就變成了常(變)量,常變數保留的變數的某些特征,但是它具有的常量的性質,其值不可以被修改,
在普通情況下,我們均將其當作一個常量,比如,我讓a+1,然后重新復制給a,這個時候,編譯器就會報錯:(如下圖所示)
第三種:#difine定義的常量:(就是我們所說的宏常量)
例如:(如下圖)
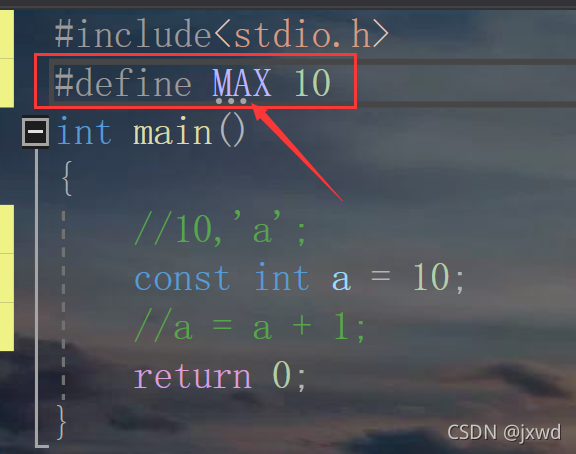
在這里,MAX就是一個常量,它的值為10,如果列印出來,可以看到,控制臺上顯示的為10:(如下圖)
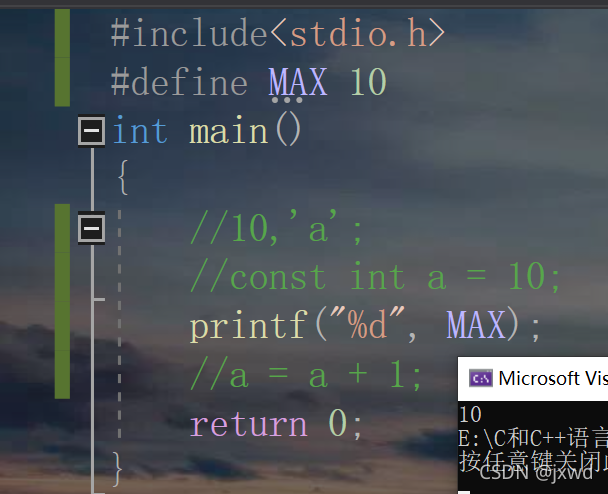
同樣的道理,如果將其值修改,我們會看到編譯器會報錯,
第四種:列舉型別常量,
對于列舉型別,我們要用到一個關鍵字enum,即通過enum來將常量一一列舉出來,來舉一個栗子:
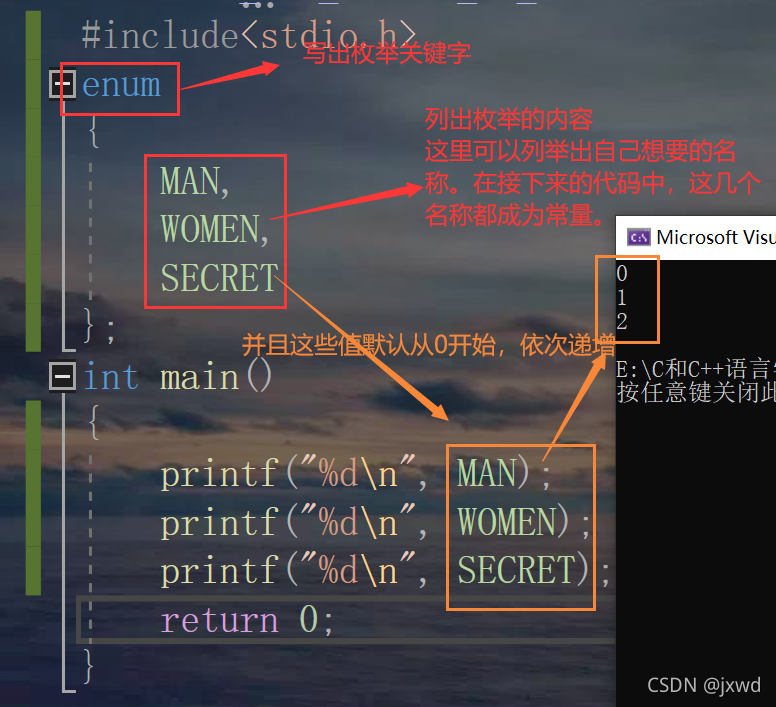
從上面我們可以看出,我們在列舉型別中給出所要給的量的名稱(我們這里列舉的是男,女,保密,當然,你想列舉什么就列舉什么),那么它們就將成為常量;
*(它們的值默認從0開始,以此往下遞增,(提一嘴,因為它們代表的值是整形,所以我們可以用%d來去列印))
注:標記*表示在這里可以不用了解,看不懂沒有關系,我們在接下來的內容中會詳細介紹的,
我們接著往下說:
3、陣列
陣列就是把型別相同的元素放在一起,形成一個的集合
3-1 陣列的宣告
陣列的宣告方式是這樣的:

例如,我們可以這樣宣告一個陣列:(如下圖)
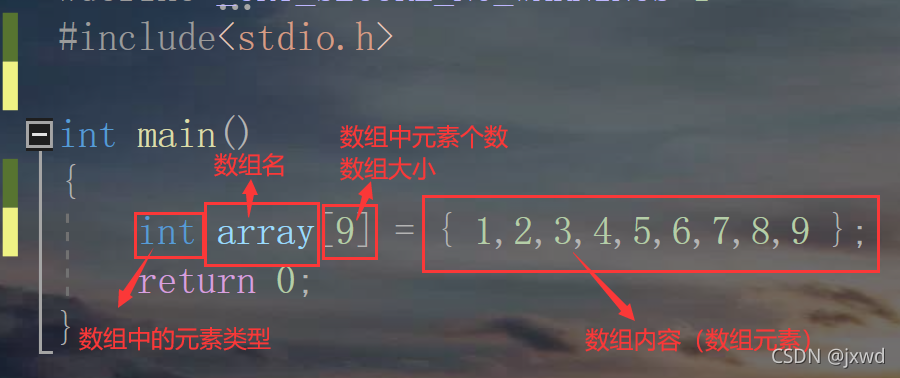 1、這里的int的意思是陣列中元素的型別全部都是int;
1、這里的int的意思是陣列中元素的型別全部都是int;
2、array是陣列名,你想起什么都可以
3、[9]表示陣列中有9個元素
4、{1,2.....,9 }表示陣列的元素(你想給什么都可以,但前提是元素都要是你前面所宣告的型別)
3-2 陣列的初始化
像我們上面那樣,在宣告的時候,給它的元素全部列舉了出來,就是陣列初始化的一種形式,
這種把陣列的元素一一列舉出來的初始化方式,稱為陣列的完全初始化,
另外一種陣列初始化的方式,稱為不完全初始化,
比如:
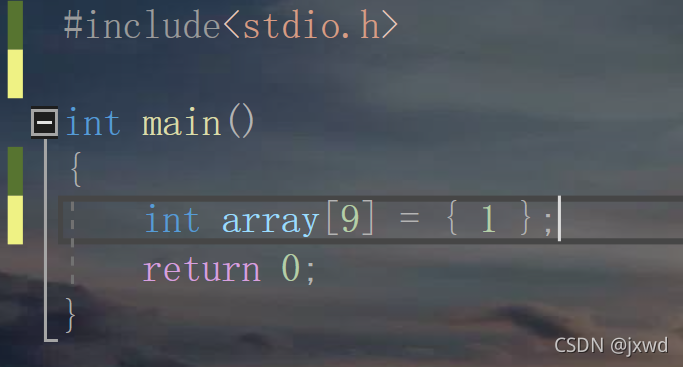
這表示什么呢?
表示陣列的第一個元素為1,剩下的8個元素都是0,
3-3 陣列的訪問
那我怎么樣才可以拿到(訪問)陣列的某個元素呢?
我們以上面的 int array[9]={1,2,3,4,5,6,7,8,9}; 為例:
首先,陣列的每一個元素都是有下標的,而且是從零開始,然后直至最后一個元素,依次遞增,如圖:
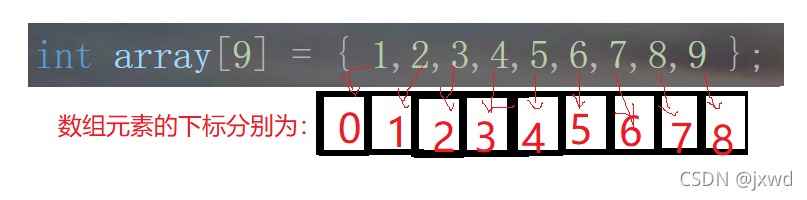
那么,我們在訪問的時候,是以陣列元素下標的形式來訪問的,
比如,我想訪問數字2,那么我就可以用array[1]來訪問,
那現在,我們把它列印出來:
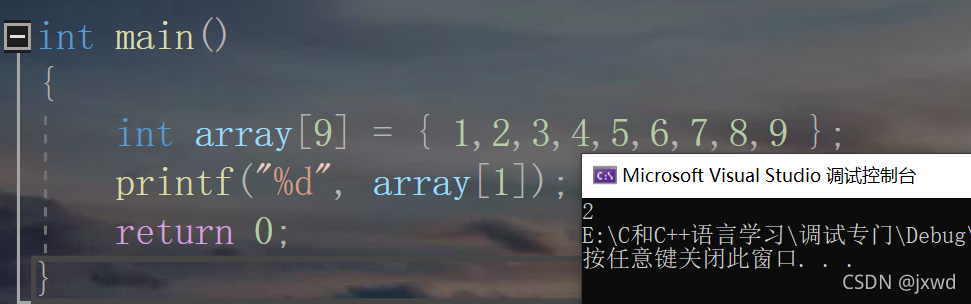
其它的元素訪問規則以此類推即可,
注意:在這里要強調一下,陣列中的元素型別一定要相同,
4、字串
字串,字面意思,就是指字符和字符在一起形成一個串
字串一般會用雙引號引起來,而不是單引號,
比如 “abcde” 就是一組字串,
在C語言中,沒有單獨的專門用來宣告字串的型別,所以我們把它放在字符陣列中去宣告,舉個栗子:(如下圖)

這便是一個字串,
我們來分析一下:

我們可以把字串理解為一個特殊的陣列,或者就是一種字符陣列,
注意:
在每個字串的后面,其實還隱藏這一個'\0',
它不算到字串的長度中,但是卻占據一個單位的空間,
比如,上文提到的字串"abcdef",它的字串長度是多少呢?(如下圖)

(如上圖)
也就是說,這個字串長度為6,
我們可以來驗證一下,
驗證時,需要引入一個庫函式:strlen,它用來計算字串的長度,計算的原理是從字串的第一個字符開始,一個一個向后遍歷,直至遇到'\0'為止,計算'\0'前面的字符個數,用它需要引頭檔案<string.h>
看下面的栗子:
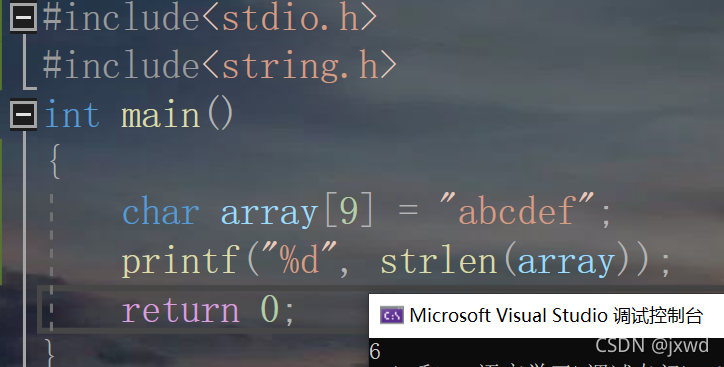
可以看出,該字串的長度為6,而字符'\0'是不計入字串長度中去的,
5、轉義字符
我們輸入這樣一行代碼:
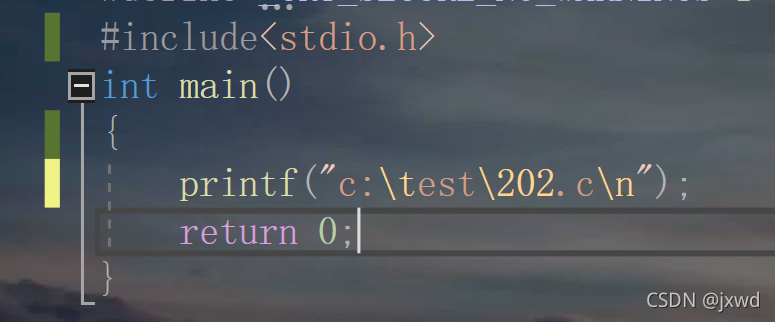
我們讓代碼運行,來看一看會輸出個什么樣的東西
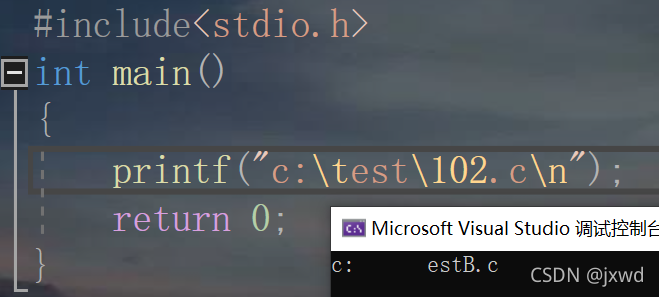
一堆亂碼?
其實不是,
那為什么會輸出這么個鬼東西?
這就與轉移字符有關系了,
在這里,編譯器在遇到’\t‘后將其轉義,不再是原本含義,而是轉變為水平制表符,相當于一個tab鍵縮進的長度,大概相當于4個空格(多少個空格可以自己改),
而\102也是一個轉義字符,它是102是八進制數字,它輸出的為八進制數 102 在系統中所代表的ASCII碼值,
\n也是一個轉義字符,它的意思是換行,我們之前提到過的,
在這里我們提一下ASCII碼,它的全稱為美國資訊交換標準碼,它實際上是一個字符-數字轉換表,即我們在計算機中,給定一個數字,它在記憶體中其實還對應著一個字符,同樣的道理,我們在計算機中輸入一個字符,它在記憶體中其實還對應著一個數字,而其所遵循的轉換的規則就是ASCII碼表(注意:該數字是有范圍的),現我們把ASCII碼表給出
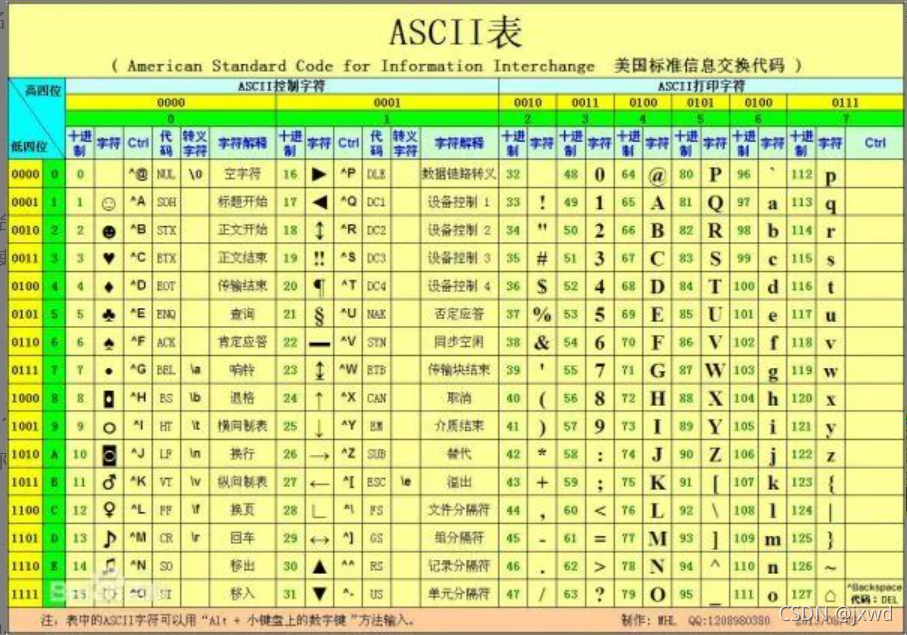
\102轉換為十進制就是8^2+2=66,而在上面的表中我們可以看到它所代表的字符為B![]()
好,我們再回到轉義字符上來,
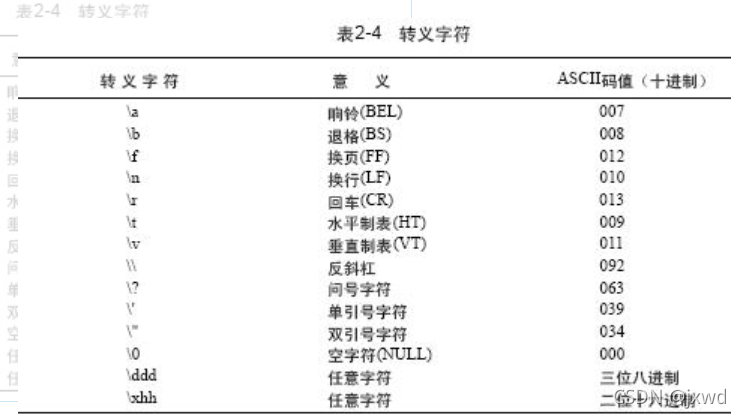
這就是相關的字符相關的轉移,
當編譯器遇到\a時,電腦會響一下,\b表示退格,\f表示換頁...重點需要注意的時\n; \t; \ddd;\xhh;
\n表示換行;\t表示水平制表符(相當于一個tab);
需要指出的是,\xhh指的是打出\x后再在后面加兩個十六進制數所對應的值;而\ddd則表示\后面加三個八進制數所對應的值(我們剛剛提到過)
那么,我們就可以解釋一下剛剛為什么列印出來那么一堆亂七八糟的東西了

其中,轉義字符算一個字符,
那好,我們看一下下面的這一串字符的字符長度是多少:
\1133\138\test\\.c\n
答案是12;你算對了嗎?
為什么是12?
根據我們上面說的,

需要注意的是,我們沒有把\138放在一起,因為\ddd是八進制,數字只能有0~7,是不能有8的,
好,轉義字符我們就說到這,
6、代碼注釋
先行的代碼有兩種注釋方式,
第一種,是C風格的注釋方式:用/* */;
第二種,是C++風格的注釋方式,C99后流行,用 \\;(如下圖)
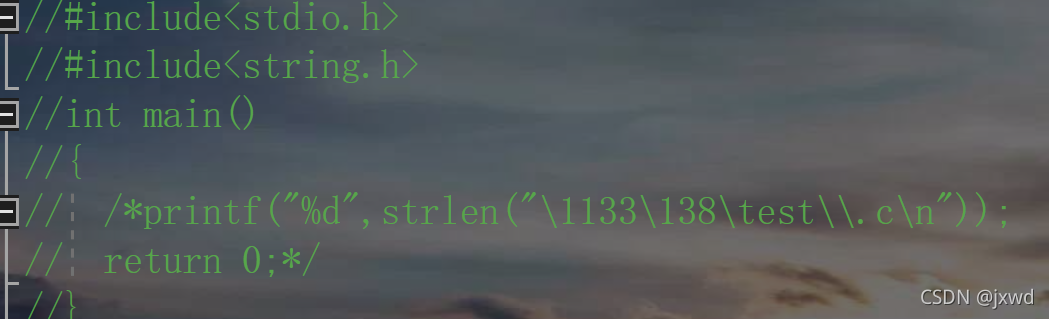
當然,/* */這種注釋方式是有一定的缺點的:即不可以嵌套,請看:(下圖)
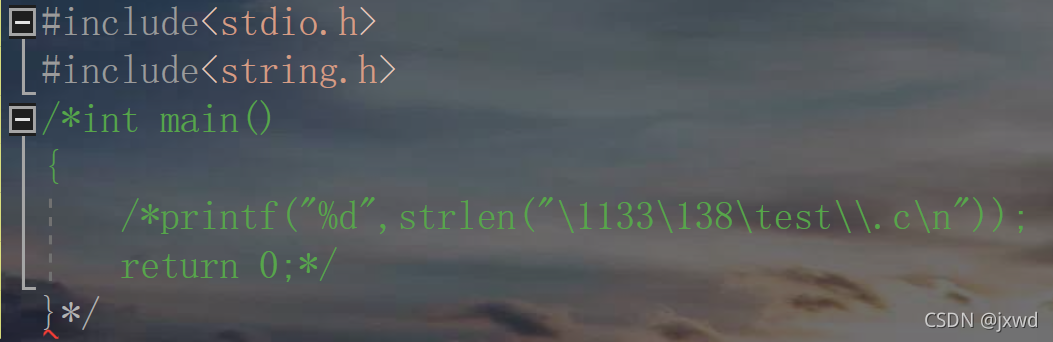
我們先把main函式里面的注釋掉,再想在外面注釋的時候,我們發現,后面的括號并沒有被注釋掉,
7、函式
函式是C中最重要的一個部分,可以說,一個程式是由若干個函陣列成的,那么函式到底是什么?它到底怎么用?我們今天在這里先稍微地提一下,讀者只需清楚什么是函式就好,我們今天只是簡單的介紹一下,不深入,不發散,
首先,函式有兩種,一種是庫函式,一種是自定義函式,
我們用的printf;scanf;strlen都是庫函式,也叫內置函式,包括我們常常提到的main也是一個函式,可以這么理解,庫函式是別人為你寫好的,然后打包封裝到像<stdio.h>這樣的頭檔案中去,你用#include表示包含這個頭檔案,那么你就可以去用這個頭檔案中定義的所有函式,
我們再來講講自定義函式:
我們想要用一個函式,只需要把函式的名字寫出來,然后打上括號,把函式的名字寫進去就行,就像這樣ADD(a,b),我們將在下面的實體中給大家演示:
現在,
我們來寫一個最簡單的函式——相加函式,就是把兩個函式加起來,
我們先把主函式(main)寫出來:

ADD(a,b)就是函式呼叫的意思,也就是說,我要呼叫這個函式,經過什么程序和操作我暫時不關心,但結果是通過這個函式,我把我傳進去的a,b兩個數加了起來,得到了它們兩個數的和,然后我用sum來接受這個ADD函式回傳來的和,(也就是這個值)
上述所描述的就是函式的呼叫,再說的直白一點,就是用了函式的方法,
那么,我們現在再來看看如何實作這個函式:(也就是得到這個值所經歷的程序是什么)
函式實作的基本架構是這個樣子的:
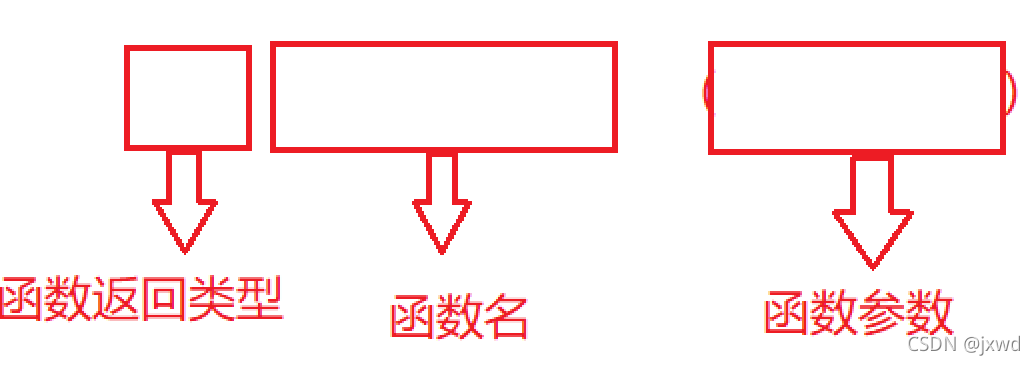
我們仍然以上面的函式為例:
上面的函式我們可以寫成:
int ADD(int a,int b)
{
int c=a+b;
return c;
}這樣,我們就實作了這個函式,
我們先來講講這每一部分都代表這什么:

好,我們再在整體的代碼中來看一遍,將代碼怎么執行的說一遍,
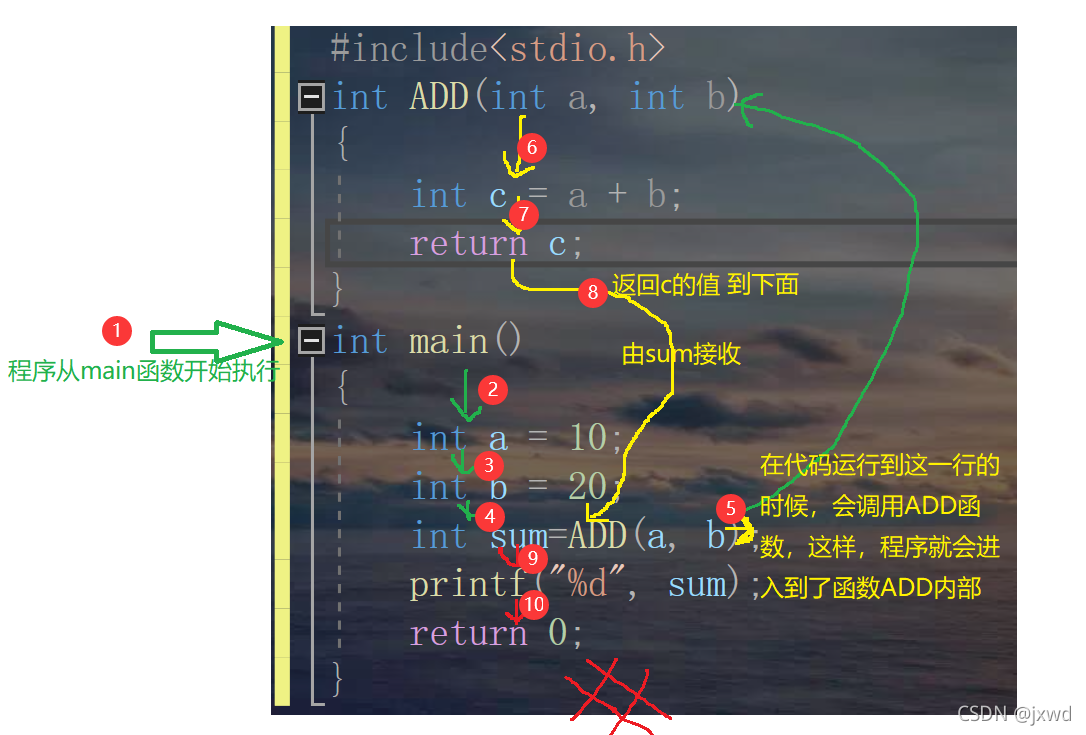
所以,列印出來的值應當為30,
需要說明一下的是,我們最好把要用的函式寫在main函式的上面,因為如果寫在main函式下面,編譯器在呼叫這個函式之前并沒有見過這個函式,這樣就會報錯或者報警告,除非在前面進行一下宣告,就像這樣:
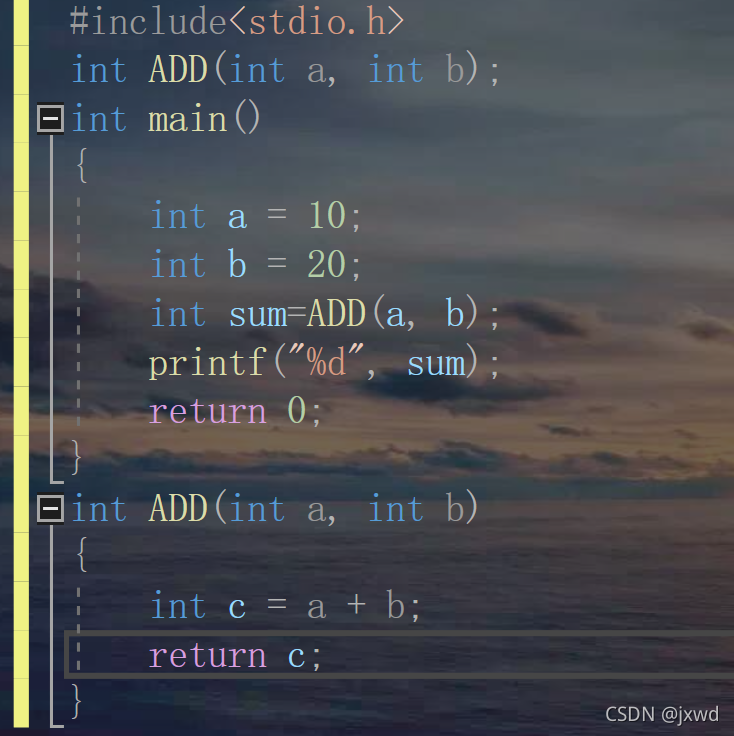
也是可以的,
好,就此打住,函式我們今天就了解到這, 讀者只需要了解函式是什么,怎么創建的就可以,
8、選擇陳述句
選擇陳述句,一般來說有switch和if兩種比較常見的選擇陳述句的形式,我們今天還是點到為止,只介紹一下if的選擇陳述句,
if選擇陳述句的基本結構是這個樣子的,

這里的else if也不一定要有,如果只是A和B中間的選擇,直接用if else就行,
我們現在來舉一個簡單的栗子: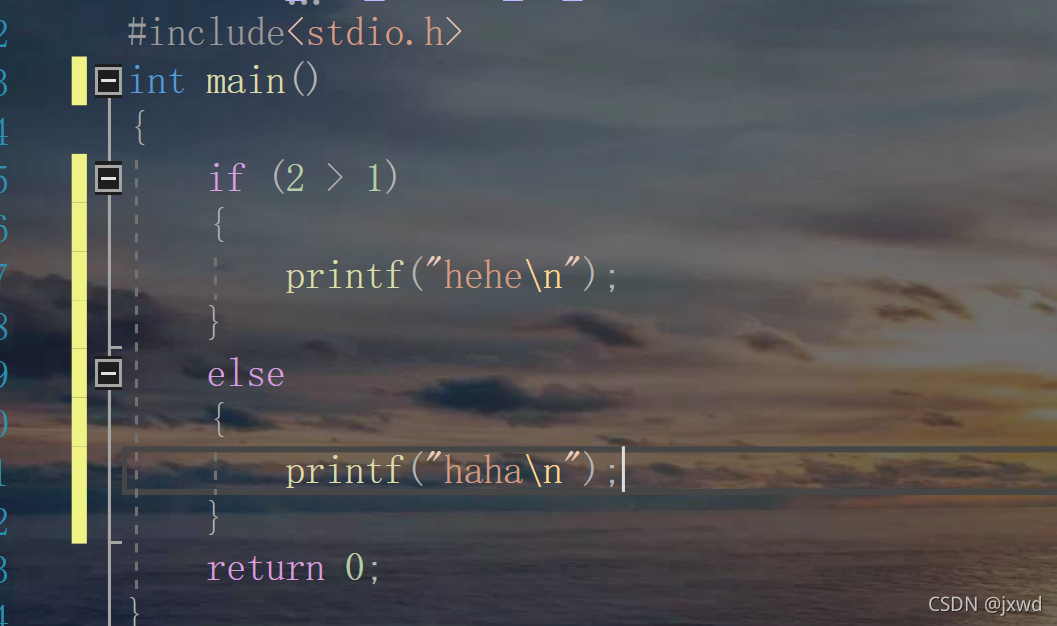
各位認為列印出來的是haha還是hehe?
我們來把代碼運行的流程演示一遍:(如下圖)

如果用流程圖表示,好像是這個樣子的:
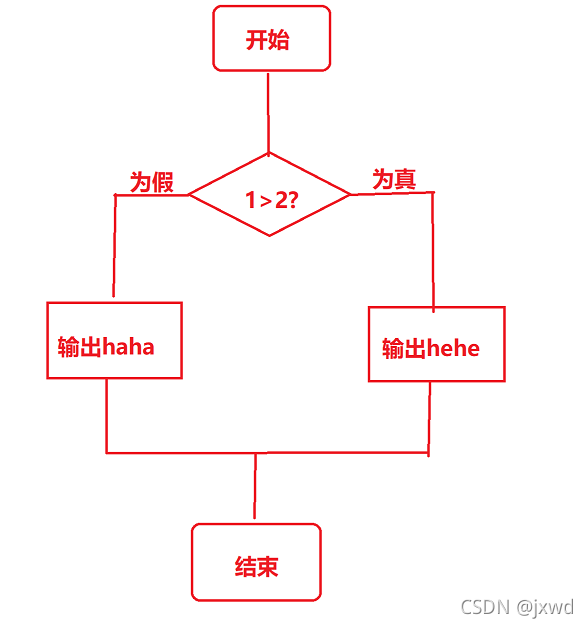
ps:如果按照標準,輸出框應該用平行四邊形畫,但我的畫圖板好像找不到平行四邊形,不過無所謂,湊合著看吧😀,明白意思就行哈,
那我現在給兩個數,然后比較出一個較大的數輸出在螢屏上,可以怎么弄?
很簡單,可以這樣實作:
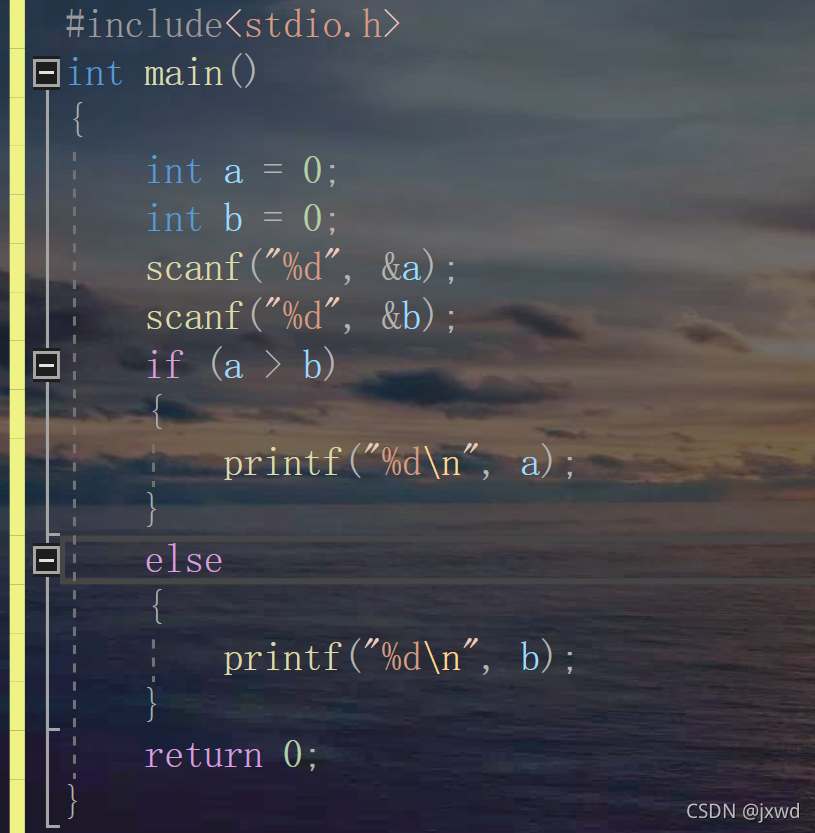
這就是選擇陳述句,
9、回圈陳述句
如果我想輸出10句hello world,難道我要打10個printf嗎?有沒有更好的辦法呢?
答案是肯定有的,這個時候,就可以借助我們回圈陳述句的功能來實作,
先說一下,回圈陳述句體中,共有三種主要回圈方式,分別是for回圈;while回圈;do while回圈,今天在這里,由本章的定位所決定,我們只是簡單了解一下它們,我們只簡單的介紹一下while回圈(還有一個原因就是如果今天都講了以后就沒有內容寫了嗚嗚嗚~~~~~)
while回圈的框架時是這樣的:

來看這么一條代碼:
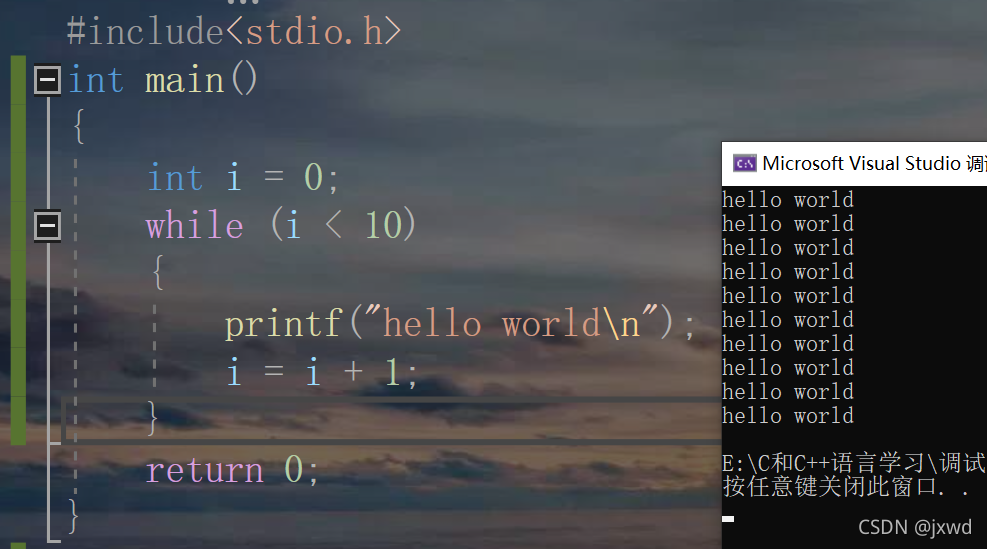
這就是回圈陳述句的功能,這里我們用的就是while回圈,while回圈的回圈程序是這個樣子的(我們用上圖的例子來分析)
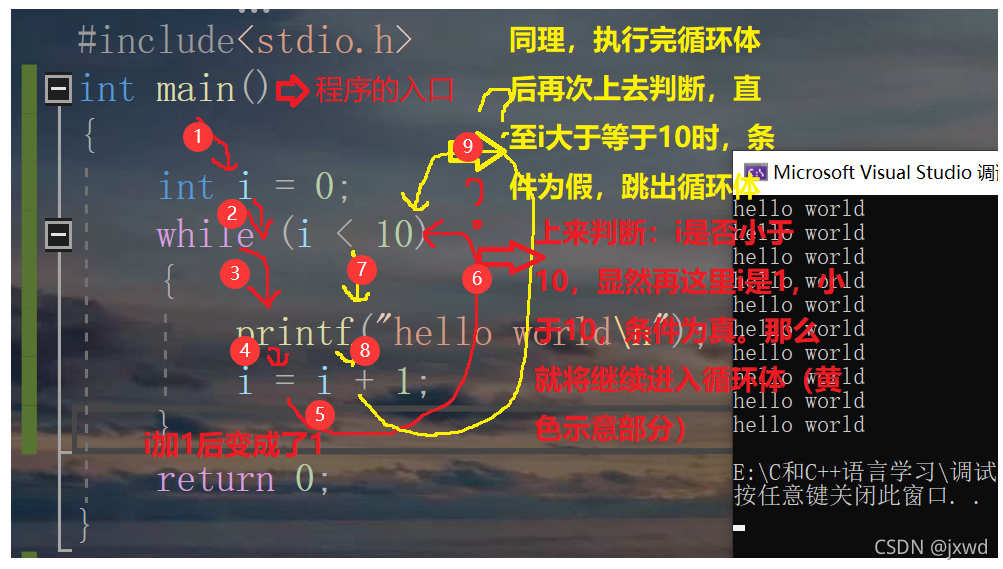
所以說,回圈就是重復的執行一件事情,直至滿足了某些條件,才可以跳出回圈,
我們關于回圈目前就先了解到這里,
10、運算子
什么叫運算子?
它就像預設好的一個運算子號,我用了這個符號,我就能實作某種目的,
聽著可能有點抽象,
我們用具體的運算子來解釋:
10-1 下標參考、函式呼叫和結構成員
主要是指 [ ] ( ) . ->這四種,
我們先講一下前兩種,后兩種我們放在底下的結構體知識里面來說(往下翻,在下面講到),
[ ]主要用于陣列中;
( )主要用于函式中,
比如,我們上面在說陣列時陣列的訪問是通過array[2]來實作的,這里的[ ]就是下標參考,可用于陣列訪問,
同樣的道理,我們在說函式的時候講到寫一個函式的名稱然后在后面打括號,這里的括號就是我們所說的運算子,
10-2 算術運算子
+ - * / %
這個就是普通的 加減乘除 取模 ,提一嘴,%表示取模,就是取余數,
比如5%2=1;需要注意的是,%不可以用于小數的運算,只能用于整數(用專業的話說,只能用于整型)
10-3 移位運算子
<< >>
我們之前介紹過,資料使用二進制存盤,一個0或者1占據著一個位元位,而且一個整型有4個位元組(32個位元位),那么, << 和 >> 是在二進制上進行的操作,其中<<代表左移,>>代表右移,
我們舉個栗子來說明一下:

這是怎么一回事?這運算子到底怎么用?我們來詳細介紹一下:

同理,>>表示向右移位,<< 或 >> 后面跟上幾,表示移動幾位,
有關其它的細節,我們以后再聊,讀者在此只需知道它們是什么意思就行,
10-4 位運算子
& ^ | ~
它們仍然是對數字的二進制位上進行操作的,
其中&位按位與;|表示按位或;^表示按位異或 ; ~表示按位取反, (前面都是對兩個數操作得到一個新的數,而 ~ 是對于一個數進行操作的)
什么意思呢?
我們以1表示真,0表示假,那么:
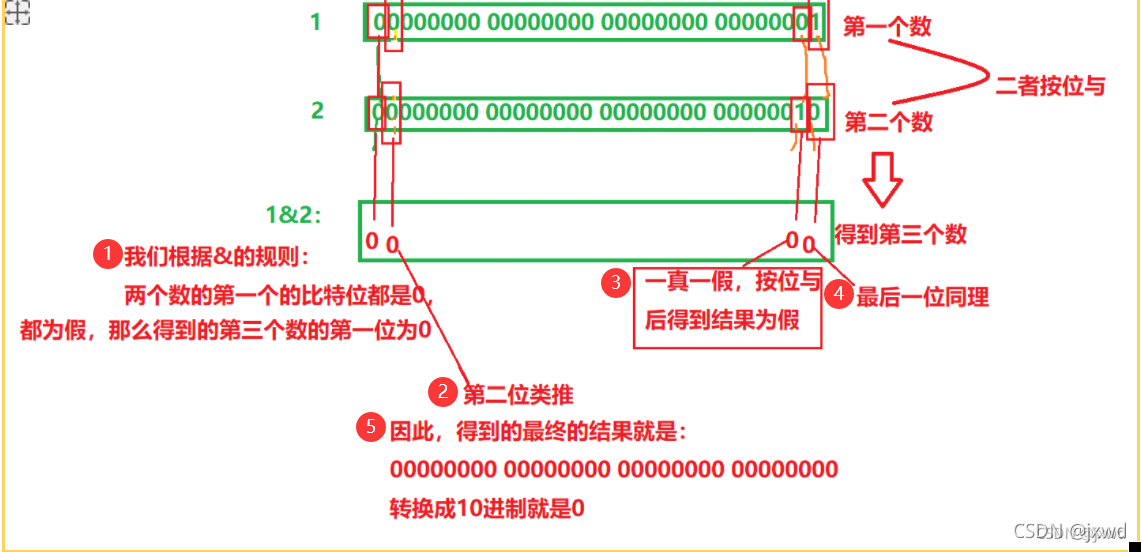
&的規則:兩個數的某一位都為真,得到的這一位才是真,
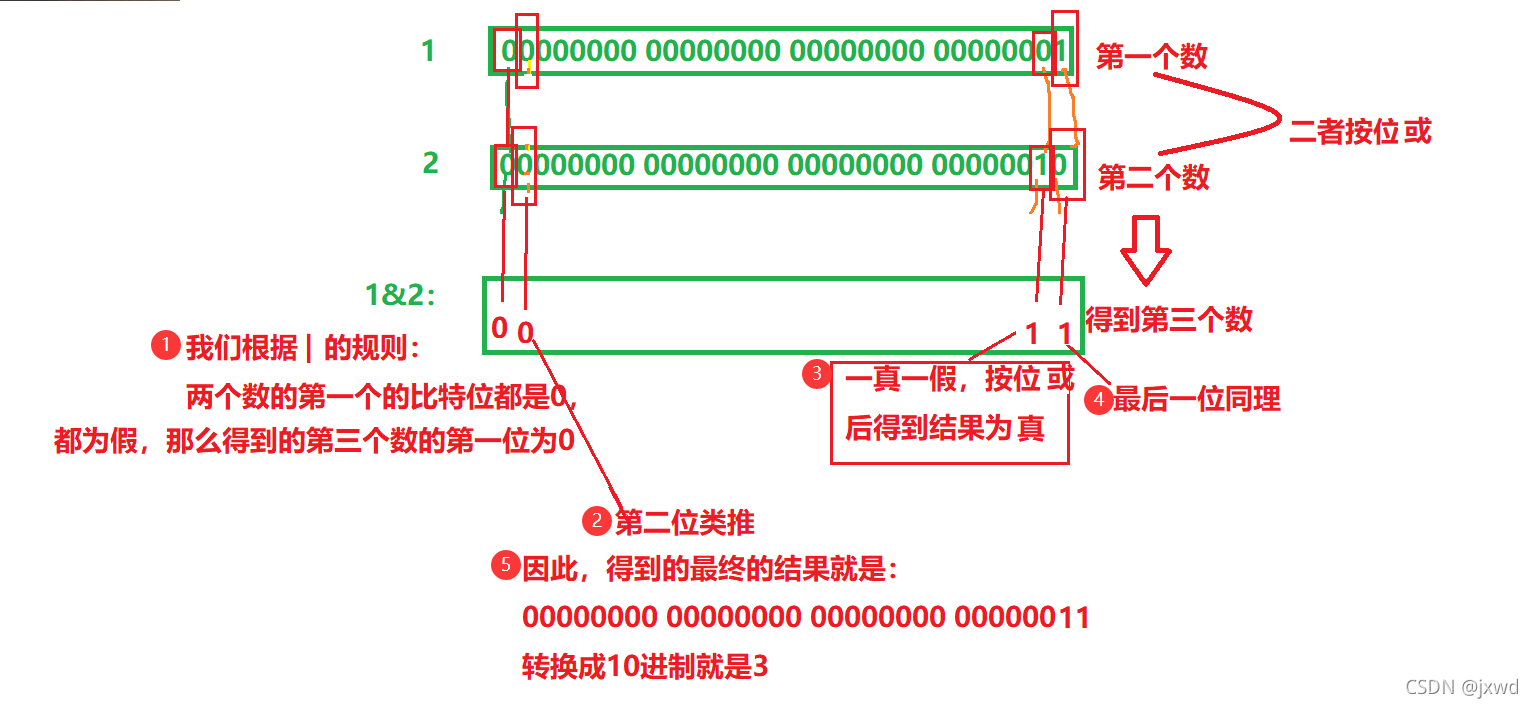
|的規則:兩個數的某一位只要有一個為真,得到的這一位就是真,
^的規則:兩個數的某一位相同則得到的這一位為假,相同則得到的這一位真,
~的規則:一位一位看,真變假,假變真,
是不是很抽象不易理解?
那好,我們來分別舉個栗子:
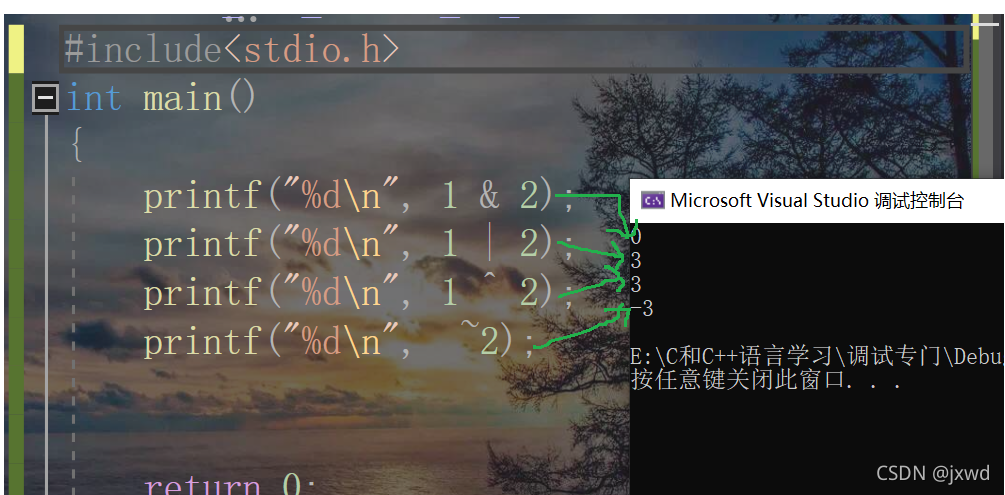
我們現在來分析一下為什么這樣的數:
首先分析1&2:(如下圖)
 同樣的邏輯分析1|2:(如下圖)
同樣的邏輯分析1|2:(如下圖)
那么1^2呢?
我們還是以剛剛說的數為例:
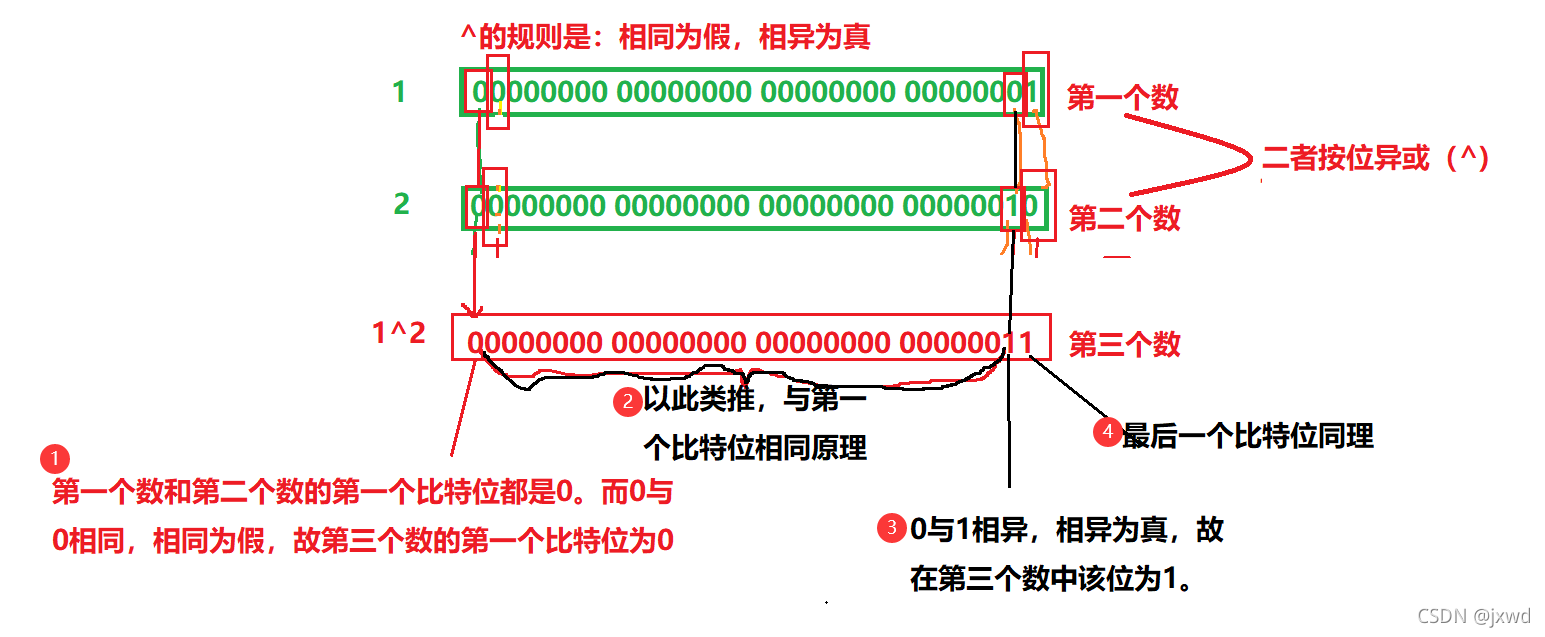
轉換為10進制后就是3
最后一個,~呢?
這個其實很簡單的,不用畫圖都能說明白,
還是上面那個例子:
2的二進制數為 00000000 00000000 00000000 00000010;
對每一位取反為11111111 11111111 11111111 11111101;實際上,這個數就是-3,至于它為什么是-3,我們以后再講,
讀者在此只要知道上面4種運算子的運算規則就可以了,
10-5 邏輯運算子
&& ||
&&表示并且
我們舉個例子:

&&的左右兩邊都有一個條件判斷,
兩邊的條件必須都為真,if判斷才為真,否則一假即假,這就和我們高中所學的這個很像(我不會打,就畫了一個,,,,別介意,,哈哈)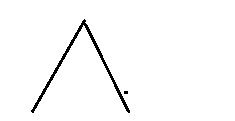
那么我們上面的條件判斷的最終結果就為假嘍,因為1是不大于2的;1>2該陳述句判斷為假,那么整條陳述句的判斷都為假,
| | 表示或者,就和我們高中所學的這個很像(我又畫了一個,哈哈哈),和&&一樣的道理,我在這里就不贅述了,以免有人嫌我太羅嗦,,,,,
10-6 賦值運算子
= += -= *= /= &= ^= |= >>= <<=
具體什么意思?
=的意思不是等于,而是賦值,像a=3;這樣一條陳述句,是說把3的值賦給a;
+=的意思就是自己加上一個數,然后再把得到的值賦給自己,
-=同理,自己先減去一個數,然后再把得到的值賦給自己,
其余的都是一樣的道理,讀者只需類比就行,
我們來通過例子的方式再說明一下:
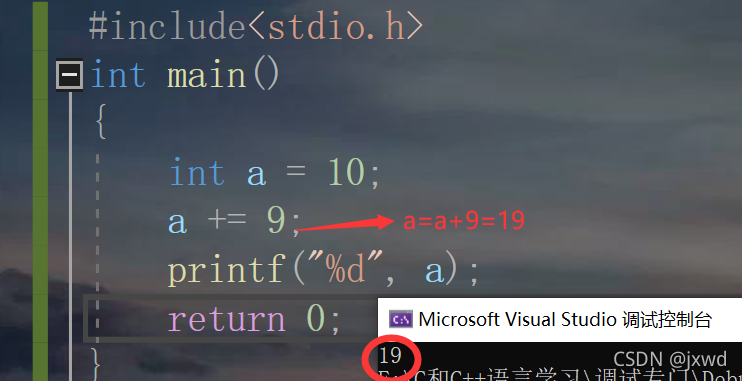
a一開始是10,那么+=9相當于自增9,所以這時候列印a,得到的值就是19,
其他的同理了,筆者就不在此一一列舉了,讀者可以選擇性的在編譯器中嘗試一下,
10-7 關系運算子
> < >= <= == !=
它們都是用于判斷兩個數之間的關系的,
前面四個沒什么好說的,分別為大于、小于、大于等于、小于等于,
我們強調一下后面兩個:
==用來判斷是否等于,請看下面的代碼:

這里的sum==30就是判斷是否相等的陳述句,意為:如果sum等于30,那么輸出hehe;否則,輸出haha,
在這里,應該輸出hehe,因為sum就是等于30,
切忌!判斷是否相等時兩個=,即==,一個=表示賦值,不是判斷是否相等!
那么我們以同樣的邏輯來理解!=就比較簡單了,!=意為不等于,(如下圖)
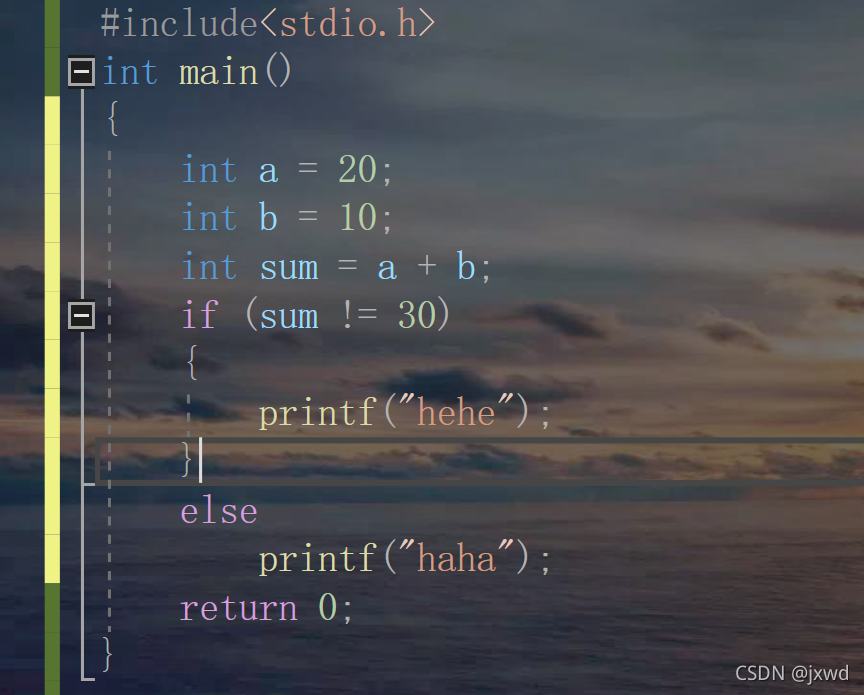
如圖,這是,我們輸出的應當就為haha了,因為sum就是30,判斷陳述句sum!=30為假,那么進入else陳述句中,列印haha,
10-8 條件運算子
exp1?exp2:exp3(注:每個exp代表一條陳述句)
它的意思是:
exp1為真嗎?如果為真,則回傳exp2的值;如果為假,則回傳exp3的值,
我們仍然通過一個簡單的栗子來說明:

顯然,上面的陳述句回傳的應當是b的值,所以列印出來的應當是b的值,也就是30,
10-9 單目運算子(只對一個數或陳述句操作的叫單目運算子)
! 邏輯反操作
- 負值
+ 正值
& 取地址
sizeof 運算元的型別長度(以位元組為單位)
~ 對一個數的二進制按位取反
-- 前置、后置--
++ 前置、后置++
* 間接訪問運算子(解參考運算子)
(型別) 強制型別轉換
我們挑幾個來說:
10-9-1 ! 邏輯反操作 (很簡單,就是如果陳述句為真,那前面加上!陳述句就變成了假)
注:在計算機中,默認0為假,非0為真,
舉個栗子:
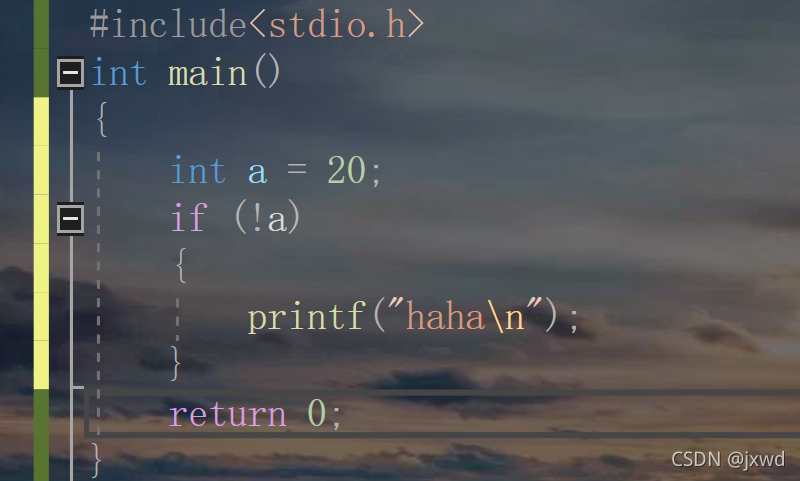
請問其能不能輸出haha?
答案是否定的,
因為a為非0,為真,那么!a就變成了假,if里面的就進不去啦,所以就不能輸出haha了,
10-9-2 - 負值
+ 正值
需要注意一下,這兩個可以作為單目運算子,就是在一個數前面加個+ - ,比如,3我可以寫成+3(不過得到的結果一樣的效果),我也可以寫成-3(就變成了一個負數),很好理解的,
10-9-3 & 取地址
我們剛剛在scanf中用到過,我們會在下文中介紹指標的時候再詳細說,
10-9-4 sizeof
這與上文所說到的strlen很像,但又不完全相同(后面的章節會具體說到二者的聯系和區別),它是一個運算子,其作用是取得一個物件(資料型別或者資料物件)的長度(即占用記憶體的大小,以byte為單位),我們在前面計算資料型別的大小的時候用到了它,
10-9-5 -- 前置、后置--
++ 前置、后置++
這四個可以看成一組,
++的意思是自增一,--的意思是自減一,
比如,我原本i是5,我現在i++;那么i就變成了6;同理,如果i--就變成了4(i原本是5的情況下),
那前置和后置又有什么區別呢?
在這里,讀者記住一點即可:前置++,先加加在運算,后置++,先運算再++, --同理,
我們用例子的方式理解一下:
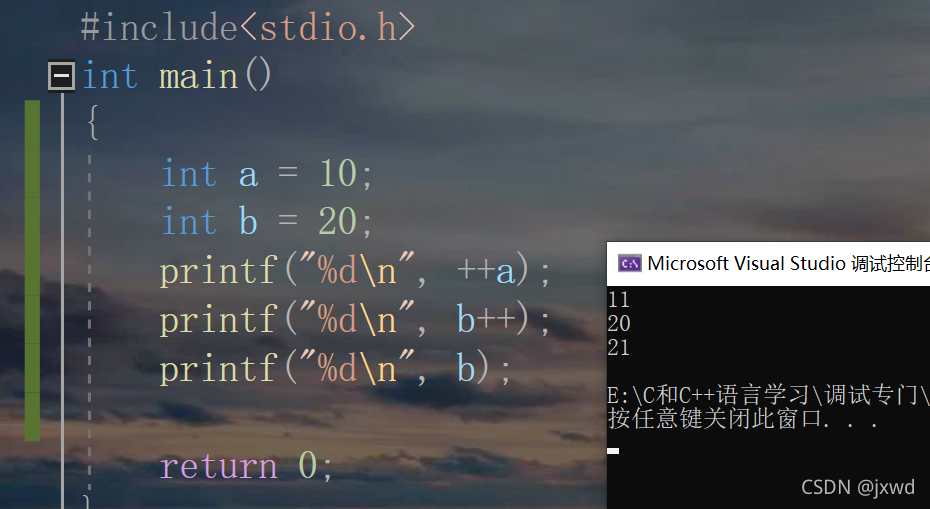
如上圖所示:
在列印第一個a的時候,先將a自增,再列印出來,所以,列印到螢屏上的數為10+1=11,
在列印b的時候(看第二個printf),++為后綴,那么遵循先使用,后加加的原則,先使用則列印出來,列印出來的數就是20;然后再自增,我們這個時候再次列印b的值,發現它已經變成了21,這是因為其在上面列印后++的緣故,
10-9-6 * 定義指標(解參考)
運算子我們在下面的指標詳細介紹;
10-9-7(型別) 強制型別轉換,
就是在一個型別的前面加上一個括號后,把原來的資料型別強制轉換為括號里面的資料型別,
我們來舉個例子吧:
比如:int a=10;
好,我現在想把它轉換為float型別,那么就只需要這樣:
(float) a;
除了單目運算子,還有雙目(比如*;/等等)、三目運算子(exp1?exp2:exp3),只不過這些運算子我們都在上文提過了,然后還有就是關于運算子的優先級的問題,算術運算子 > 關系運算子 > && > || > 條件運算子 > 賦值運算子,進一步詳細地介紹我們會放在后面的運算子詳解的章節中繼續為大家介紹,關注我的文章更新哈~~~~具體我們以后再提,
讀者在這個時候了解這么多已經夠了,因為本章我們是初始C語言,
11、常見關鍵字
要說到C語言的關鍵字,那真不少,
auto break continue switch case default const char do double else enum extern float for goto if int long register return short signed sizeof static struct typedef union unsigned void volatile while
上面的都是的,而且有很大一部分都是非常常見的,不過大家不用擔心,常見就說明用的多,用的多了自然就會了,
我們挑幾個來說說(所有的我們都會講到,只不過有的我們已經在上文提到,有的將會在下文講解時提到,現在我們挑幾個來專門說說)
11-1 auto
它可以根據給它賦值的型別,自動為其創建變數的型別,
比如:int a=30; auto b=a;用法比較簡單,
11-2 break與continue
它們可以認為是一對,
break是用于終止所在的回圈,而continue是指跳過當前的一次回圈,
我們來舉個例子:
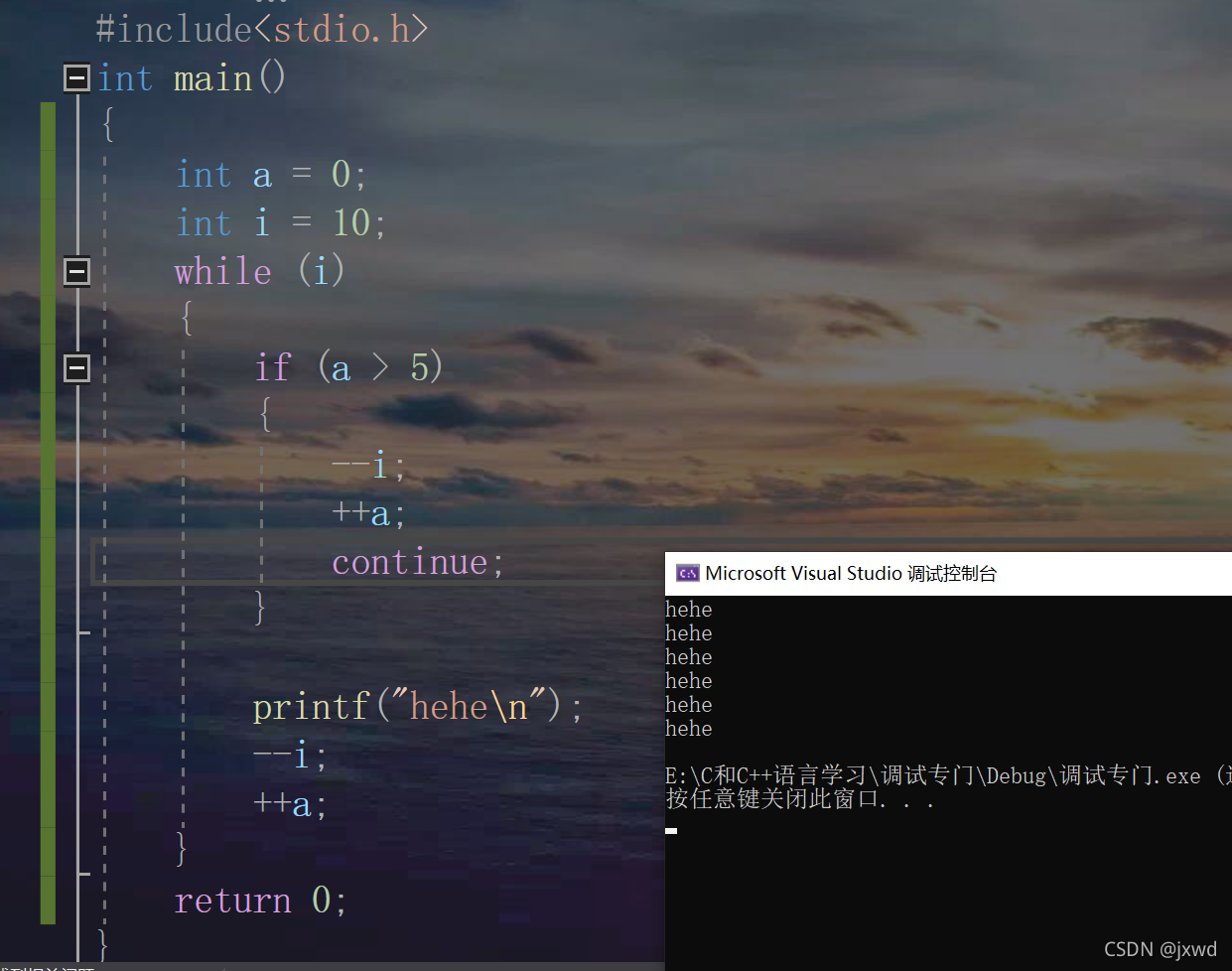
我們可以看到,螢屏上列印了6個hehe,不是10個hehe,原因?
我們來分析一下:
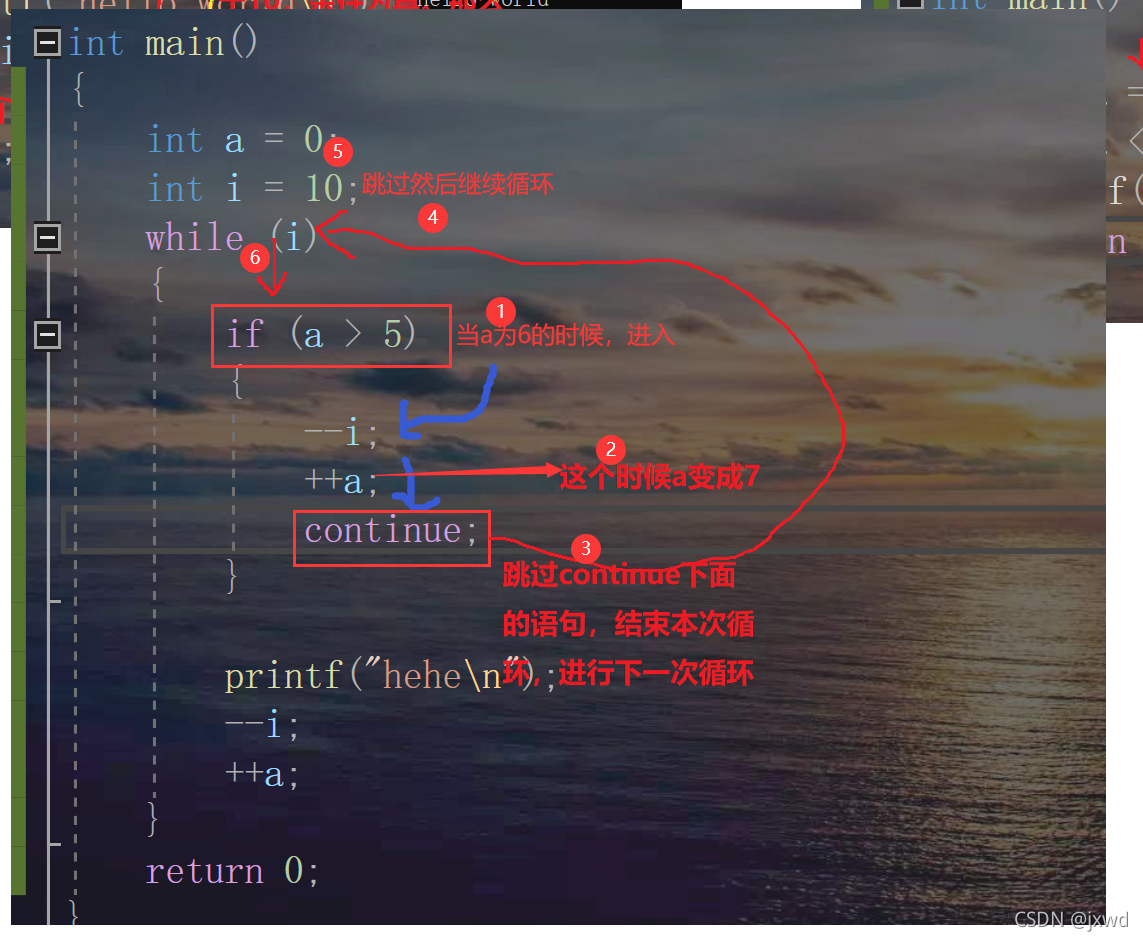
那么如果我把continue改成break呢?
那就直接跳出回圈體,根本不會再跳到上面繼續回圈了,
就是說,遇到break,該層回圈整個就到此結束了,就是這個意思,
11-3 extern
它用于外部宣告的時候使用,
這里簡單了解一下,
舉個簡單的例子:
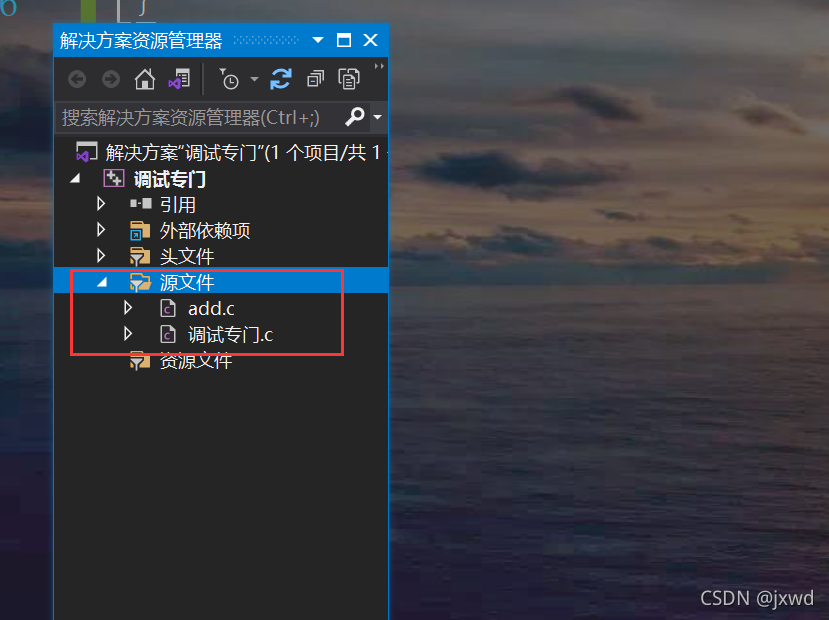
我創建了兩個源檔案(當然,源檔案的名字最好是用英文,不要學我喲~~~~~)
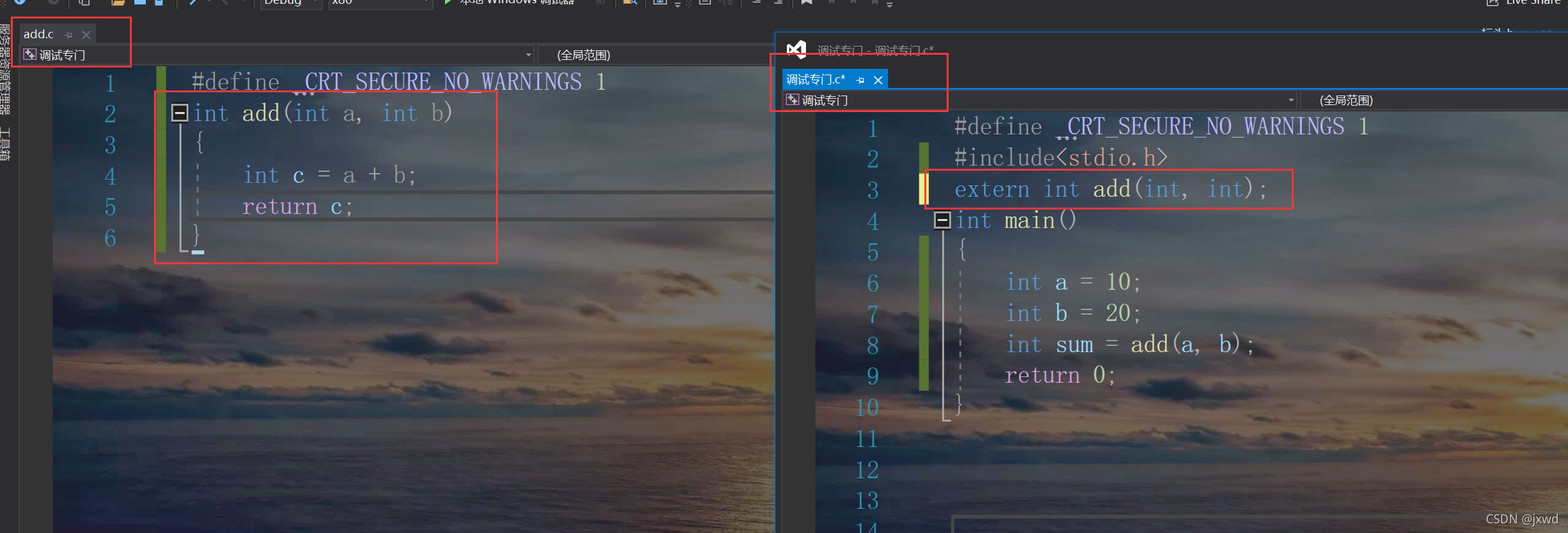
我在一個檔案中寫了add函式的具體實作,在另外一個檔案中如果直接呼叫add,肯定會報錯,如果,我們加了一個extern,就不會報錯了,
也就是說,用了extern,我可以使用外部的函式,
11-4 static
它意為靜態的
它可以用來修飾函式、全域變數和區域變數
11-4-1 修飾函式
我們還是剛剛上面的那個例子:
如果我在add.c檔案中加上一個static,編譯器就會報錯:如圖:
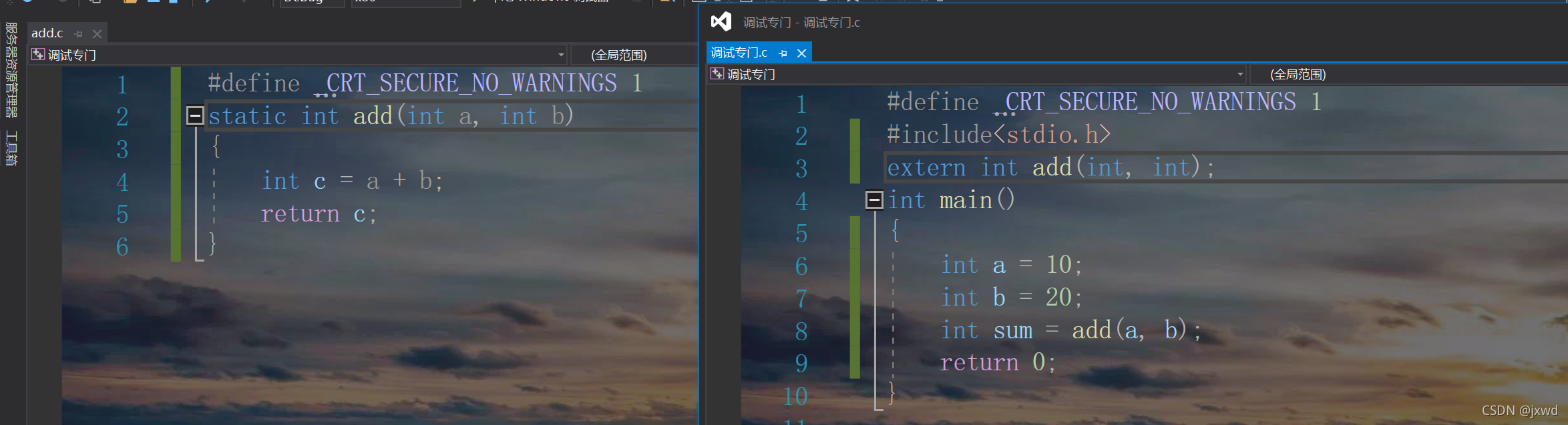
運行:

根據報錯,意思是add無法決議,編譯器不知道它是什么,說明我們在add.c中的函式不管用了,這是因為static修飾的緣故,使得add.c中的函式add無法作為另一個檔案的外部鏈接來使用,也就是說,我加了static,我的函式只能在我的這個檔案中用,別的檔案想用,就不行了,
11-4-2 修飾全域變數
和修飾函式其實一樣的道理,就是讓其無法在外部被使用,實際上是在鏈接這一步的時候斷了,
(但讀者在此可以不用知道這么多,簡單了解一下其可以實作的作用即可)
11-4-3 修飾區域變數
來看:
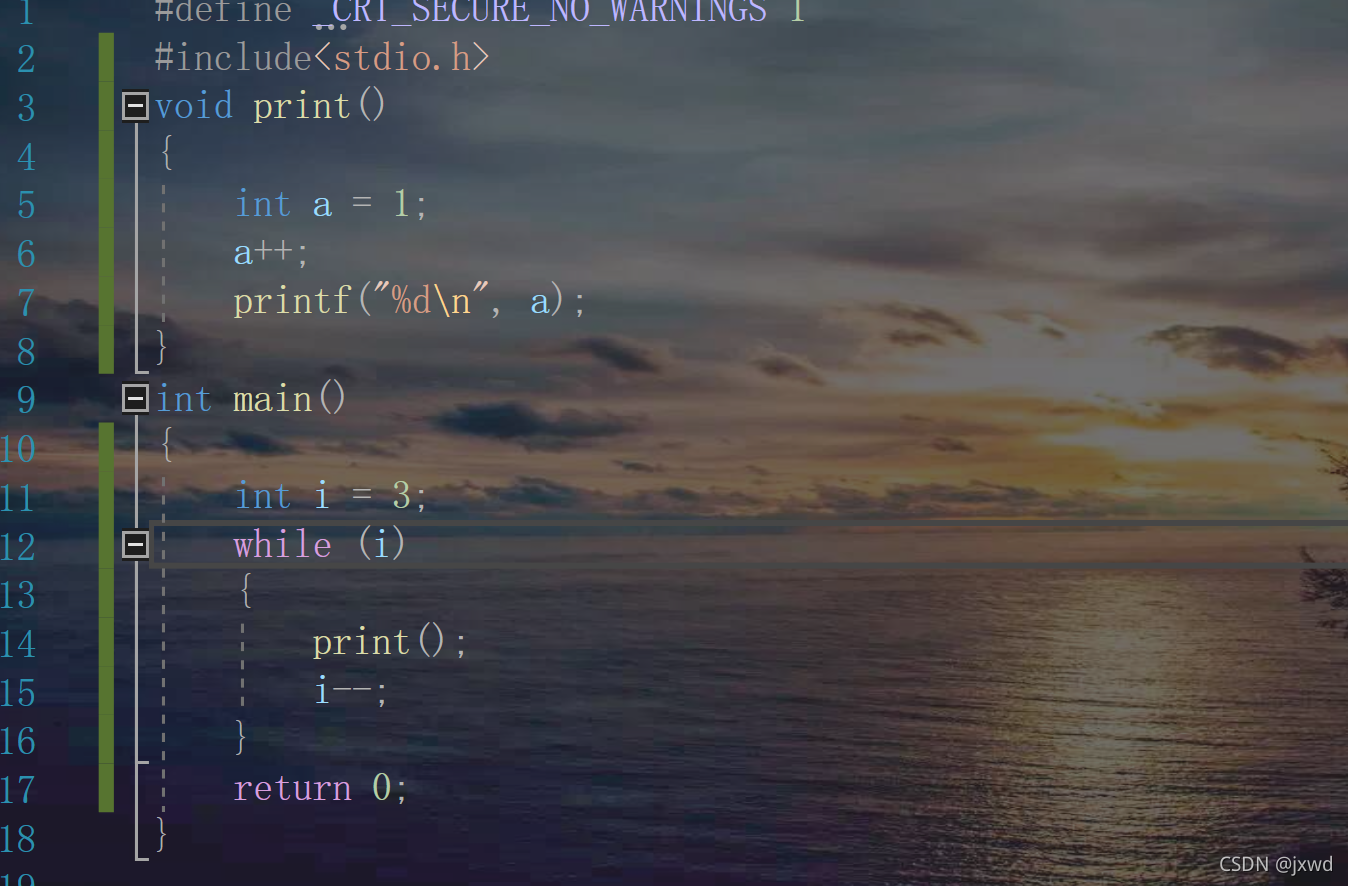
請問,這段代碼會最后列印出來什么?
答案是三個2,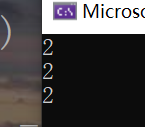
那我在int a 的前面加上一個static,看看會怎樣?
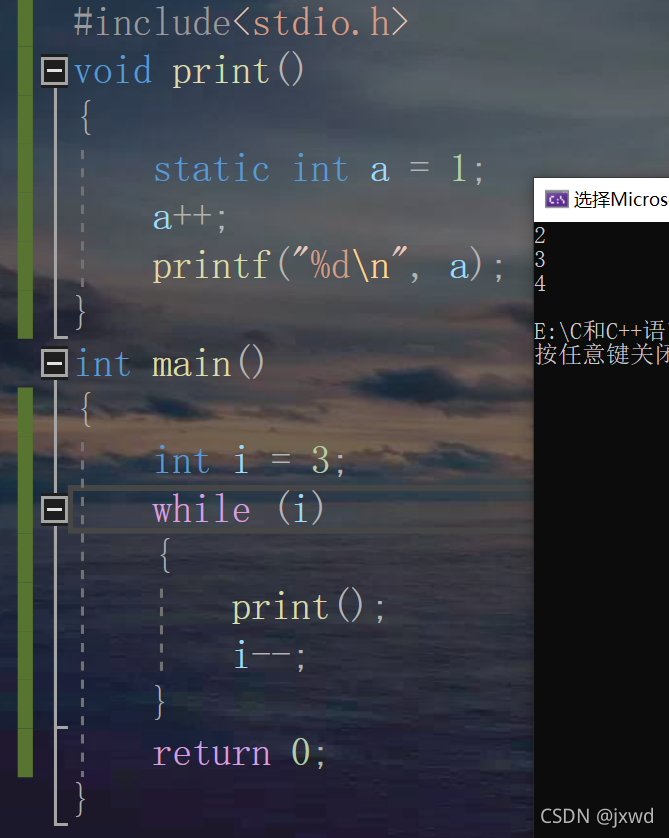
輸出的就是2 3 4,
為什么?
因為當a被static修飾后,再次進入print函式的時候,便不會再次創建,可以通俗的理解為:成為了一個靜態的量,
所以,a++會被一直執行,但是int a=1卻會跳過了,它只會被創建一次,
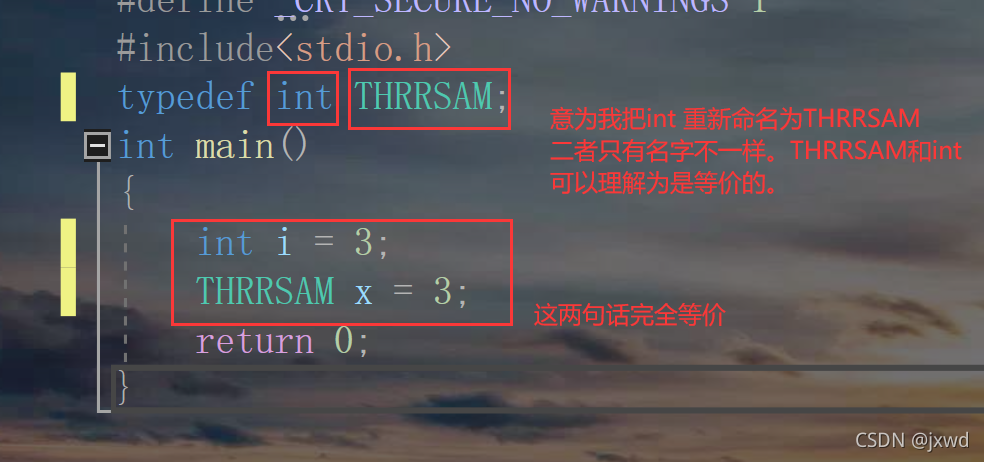
11-5 typedef
它意為重命名,
比如:(舉個小李子)
11-6 define
它意為定義,
它可以這樣用: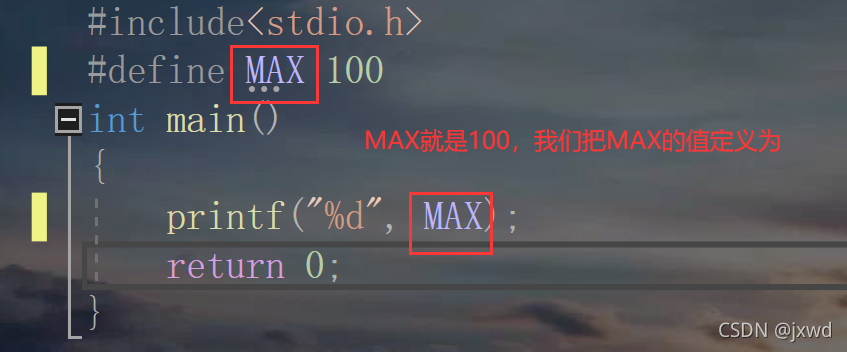
這是#define的數字宏定義,至于函式宏,我們以后再講,
至于其他的關鍵字,我們會陸陸續續講到,讀者只需要在我們講到這些東西的時候,知道它是關鍵字就可以了,
12、指標
指標其實并沒有想象中的那么復雜,它是在記憶體上的一個運算子,
既然是在記憶體上的運算子,那么了解指標之前,我們就有必要來了解一下什么是記憶體,
首先,記憶體可以理解為一塊一塊連續的區域,用于存放資料使用,
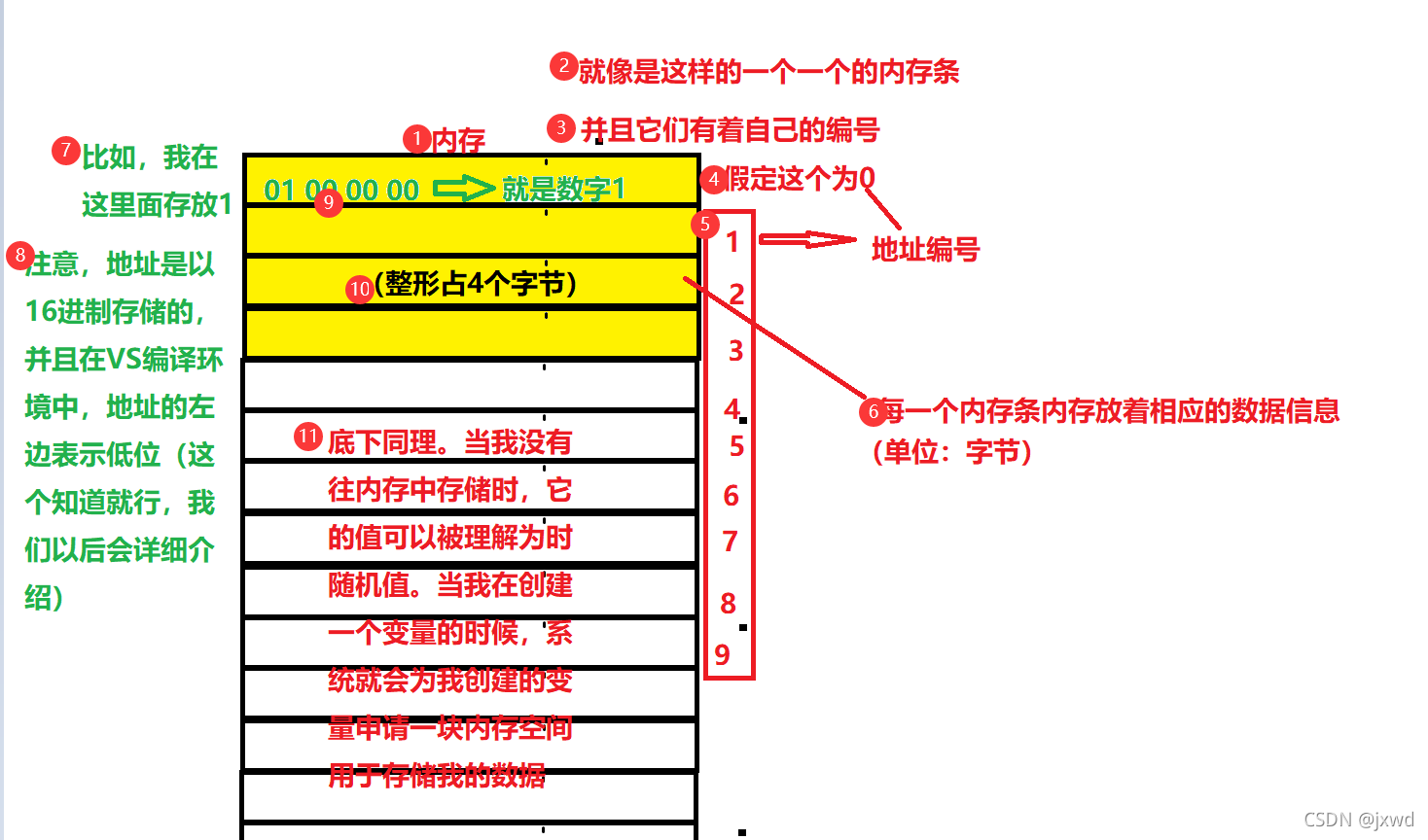
像上圖那樣,可以理解為當我在創建的變數時,我需要向作業系統申請一定大小的空間,
而地址就是為這些記憶體進行了編號,
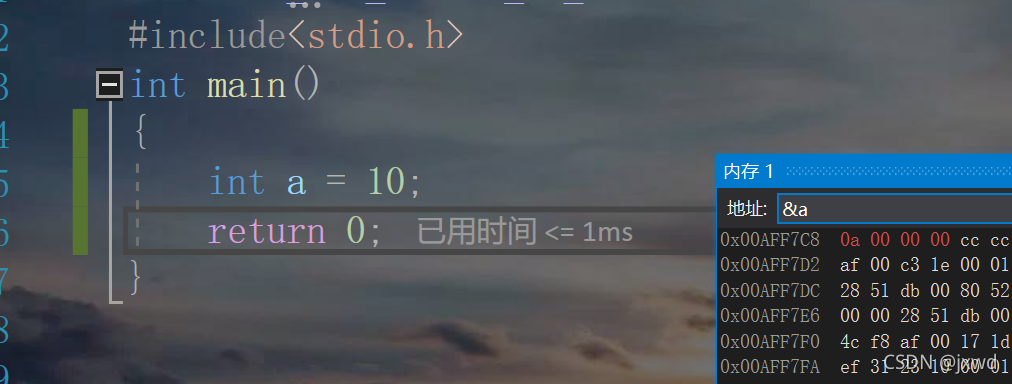
我們創建一個變數后,按f11除錯,然后選中
在上面的地址框內輸入&a,回車;再按兩下f11;可以看到a的資料為 0a 00 00 00 因為是16進制,0a剛剛好就是表示16(后面的0表示高位,相當于十進制中的百位千位等,這個我們以后再說),再這里,我們以肉眼可見的方式看到了a的地址:
0x00AFF7C8(就在0a 00 00 00的左邊,灰色的字)
那好,說完了記憶體和地址,我們就該談談指標是什么了,
指標,其實某種意義就是地址,
我們還是以上面的例子繼續說:
a的地址現在我們已經拿到了,是0x00AFF7C8,那么,這個地址的就是指標,它存盤著a這個變數的值,也就是說,0x00AFF7C8就是變數a的指標,
那指標變數是個什么東西?通俗的來說,就是用來存放指標的,就是存放0x00AFF7C8這個地址的,我們用 * 來表示
那具體來說是怎么使用的呢?來看下圖:
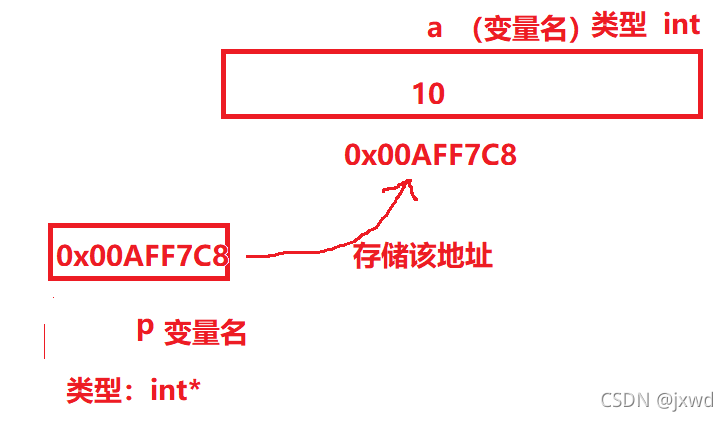
我們在寫代碼的時候,可以這樣來寫:

int* p = & a; 可以這么理解(如上圖(代碼圖上面那個))
創建一個變數,變數名是p,型別是int*(指標型別),&a(注意,這個時候取地址的作用就顯現出來了,這里就是意為取出a的地址),即取出a的地址,然后用剛剛創建的變數p來接收,
這就是指標的創建即初始化,
那我現在想要訪問指標變數里的地址所存盤的資料,我應該怎么辦呢?那就應該用解參考運算子,解參考運算子依然是 * ,它是這么用的,
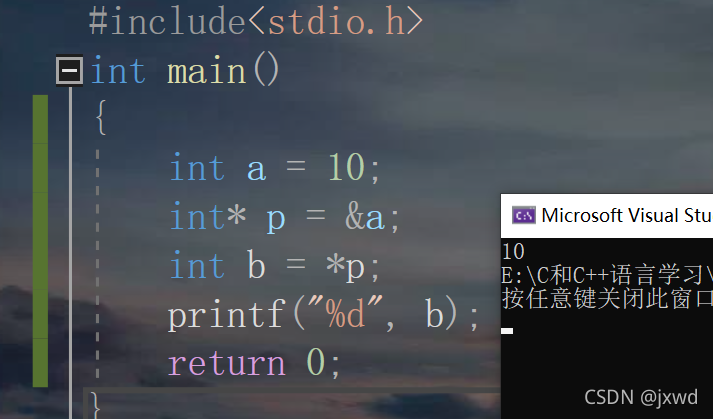
這里int b=*p; 它的含義可以這樣理解:
①*p表示對指標變數p進行解參考,就是說用我手里存放的指標變數p,找到指標變數p所存的地址,通過這個地址來訪問其存盤的資料的值,
②把這個值賦給b,
③當我們列印b時,結果輸出10,(如上圖)
我們暫且就先介紹這么多,我們這次先來簡單認識一下指標,讀者在此只需要知道指標是什么,怎么創建、怎么解參考就可以,
到后面的指標詳解這一章節的時候,筆者會為大家詳細的介紹有關指標的所有內容,
13、結構體
我們在說陣列的時候,明確強調過,必須時相同的型別才可以放在陣列里,那么不同型別呢?可以這樣理解,對于不同型別,我們就放在結構體里面,
說到結構體,我們會用到一個關鍵字(struct)
結構體(struct)是由一系列具有相同型別或不同型別的資料構成的資料集合,也叫結構,
有了結構體,C語言便擁有了描述復雜型別的能力,
13-1 結構體的創建
那結構體時怎么創建的呢?
我們用關鍵字struct來完成
請看下面一段代碼: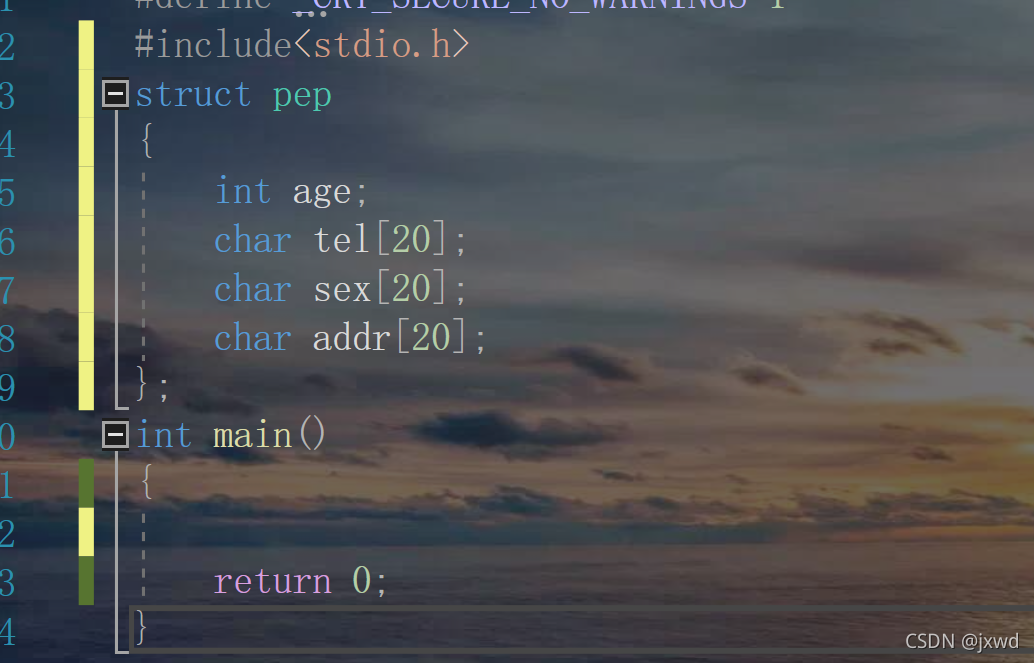
這里的struct pep就是結構體,它是一種型別,類比于int,
在這個結構體中,我們用大括號把要創建的型別集中起來,尾部要打上分號,
然后,在大括號里面創建上我們想要創建的型別,在這個大括號里面,可以創建不同的型別,比如int char 等,
那么,我們在接下來如何創建一個結構體變數呢?
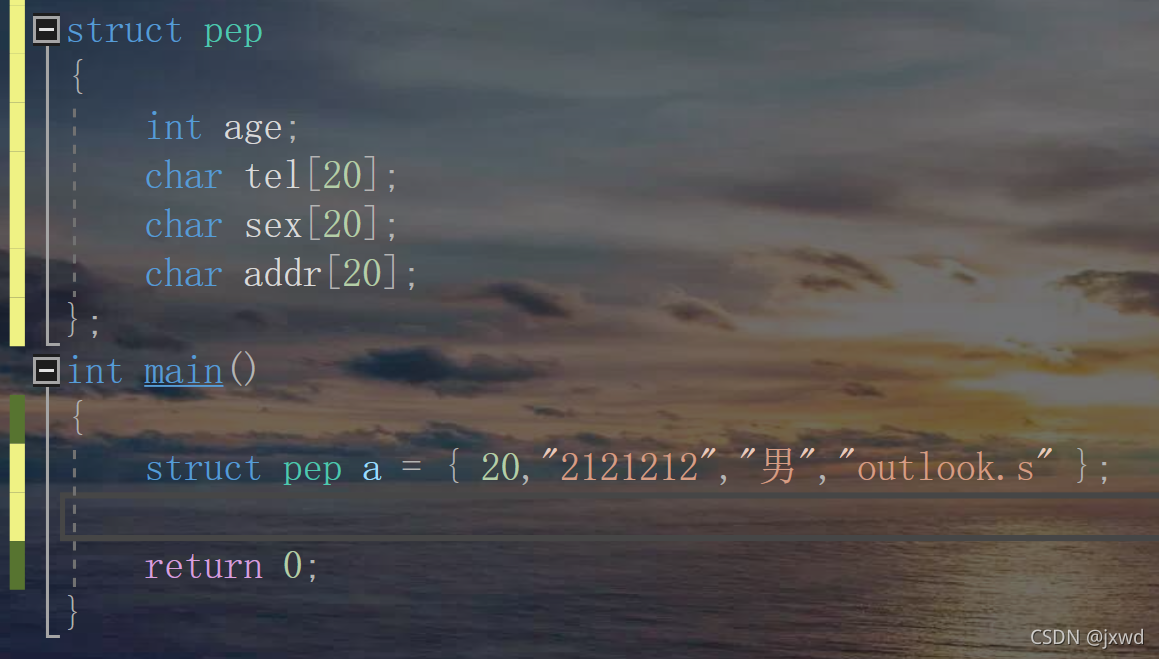
看,像這樣,我們就創建了一個結構體變數a,可以理解它的型別就是struct pep,
在這么一個結構體中,我們對其中的四種型別分別進行了初始化,(注意要對應)也就是說,變數a里面的20就相當于age型別,2121212就相當于是char型別的陣列,存放在以陣列名為tel的陣列中,其它同理,
13-2 結構體成員的訪問
我創建好了,該如何訪問呢?
這個時候,就用到了我們之前跳過去沒有說的兩個運算子: . 和 ->,(二者用一個就行)
比如,我像列印age變數里的值,該怎么做?
很簡單,像下面這樣:
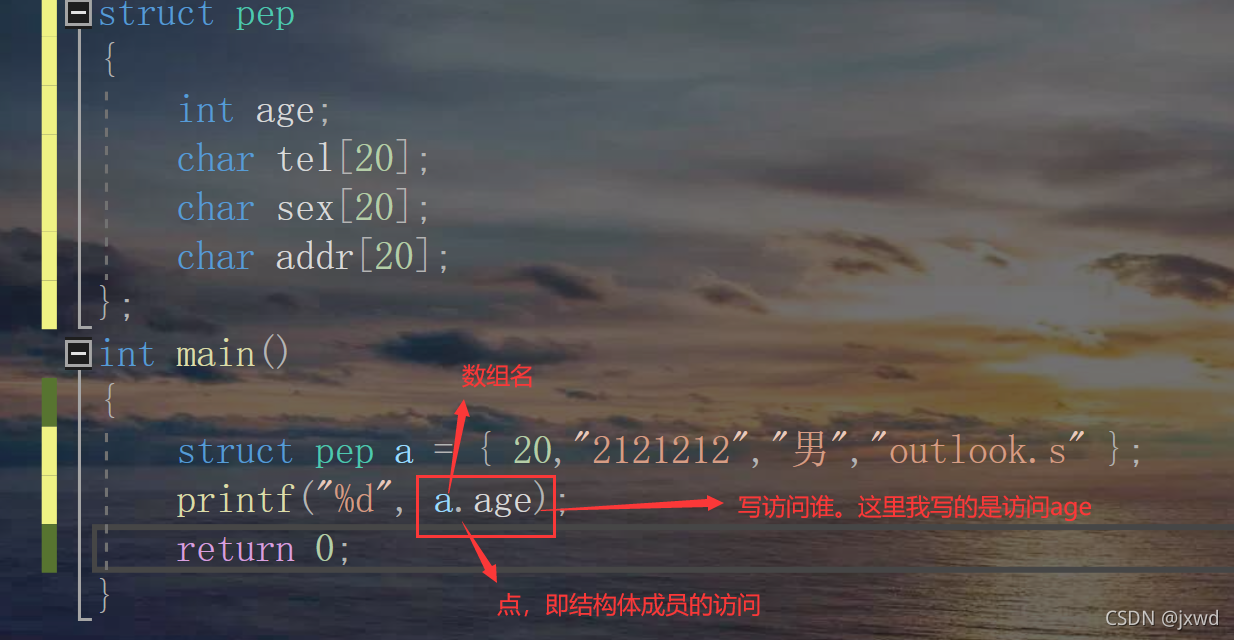
還有一種方式:(我用這種方式示范列印tel)
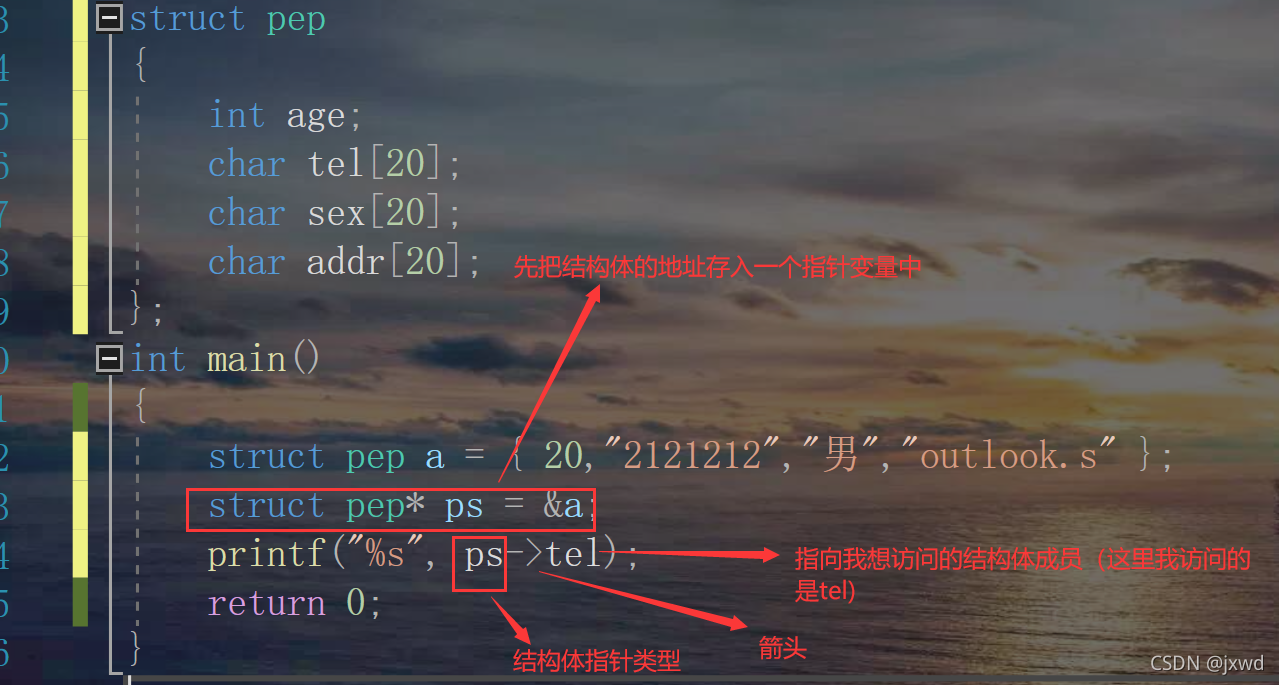
如上圖,這就是結構體成員訪問的兩種方式,
14、*動態記憶體分配初步
對于這一塊,我們現在只需要知道什么叫動態記憶體分配,因為如果講的過于深入一些初學者可能接受不了,于是,我們就在這里提一下,
為什么要有動態分配?
很簡單,因為我們在創建陣列的時候,它是一個靜態的,不能根據我的需求來去開辟記憶體空間的大小,開辟的多了或者少了都不好,因此,就有了都太開辟空間的概念,通過動態開辟,向記憶體申請一塊連續的空間,并且保證了開辟空間的大小不會浪費,也不會不夠用,
動態記憶體分配,我們用到函式malloc(當然還有calloc realloc,大同小異,我們今天不講),它的運用規則是malloc(size)(size表示空間大小)
它回傳的是一個指標,型別為void*
所以,我們可以通過這樣創建一個動態陣列:
int* ps = ( int * ) malloc ( 100 );
這樣,我就創建了一個記憶體大小為100的動態陣列,
那么這個空間又是在哪個地方來開辟的呢?答案是在堆區,
(如下圖)
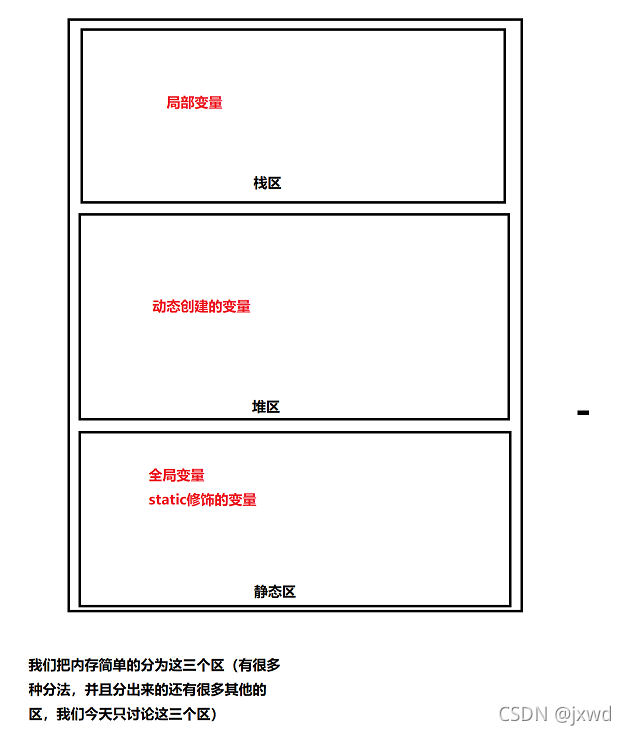
如圖所示,我們的區域變數的創建是在堆疊區,動態創建的變數是在堆區,我們上面所提到的全域變數的創建以及static修飾的變數的創建都是在靜態區,
在堆疊區的變數用完之后,系統會自動識訓,不需要程式員手動釋放,但在堆區則恰恰相反:我們需要用free函式來將我們創建的動態空間釋放,否則將會造成記憶體泄漏,
用free釋放完之后,還記得要把首元素的指標指向空指標,因為free是無法將指標本身釋放掉的,
好了,關于動態記憶體分配我們暫時了解到這,
更多的還是等到后面的文章中再說吧,
本節完~~~~
訂閱專欄,關注我@jxwd,就能第一時間看到我更新的文章啦~~~
拜拜啦各位~~~~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/333772.html
標籤:其他
上一篇:釋放std::thread*堆分配的記憶體的正確方式是什么?
下一篇:二叉樹的定義和性質