鏈表概念及結構
概念:鏈表是一種物理存盤結構上非連續、非順序的存盤結構,資料元素的邏輯順序是通過鏈表中的指標鏈接次序實作的 ,

- 鏈式結構在邏輯上是連續的,但是在物理上不一定連續
- 現實中的結點一般都是從堆上申請出來的
- 從堆上申請的空間,是按照一定的策略來分配的,兩次申請的空間可能連續,也可能不連續
實際上鏈表的結構非常多樣,組合起來有8種鏈表結構,
1.單向或雙向
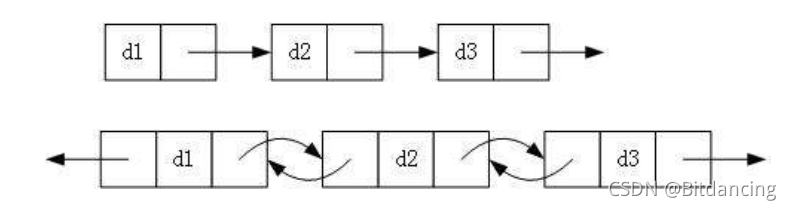
2.帶頭或者不帶頭
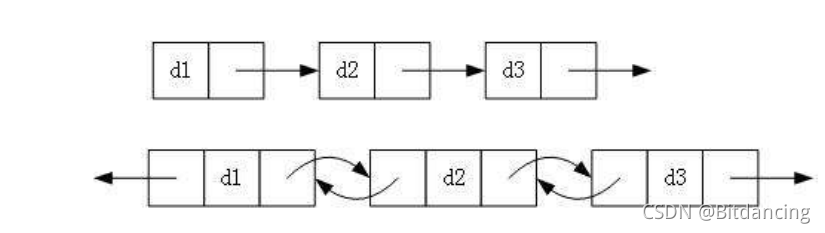
3. 回圈與非回圈
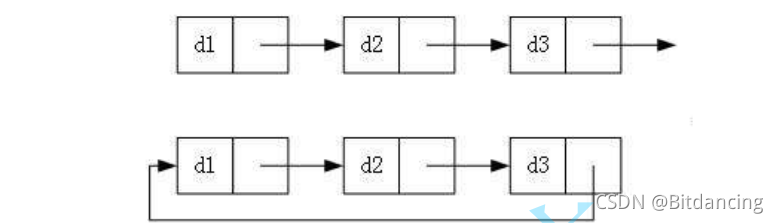
本文介紹的是 無頭單向非回圈鏈表,
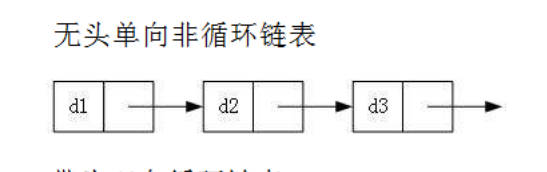
無頭單向非回圈鏈表:結構簡單,一般不會單獨用來存資料,實際中更多是作為其他資料結構的子結構,如哈希桶、圖的鄰接表等等,另外這種結構在筆試面試中出現很多,
SListNode結點結構體
鏈表是由一個一個結點鏈接起來的,所以在創建一條鏈表前,首先要創建一個結點,結點由兩部分組成:資料域和指標域,
typedef int SLTDataType;
typedef struct SListNode {
SLTDataType data;
struct SListNode* next;
}SLTNode;
函式介面
// 動態申請一個結點
SLTNode* BuySListNode(SLTDataType x);
// 單鏈表列印
void SListPrint(SLTNode* phead);
// 單鏈表尾插
void SListPushBack(SLTNode** pphead, SLTDataType x);
// 單鏈表頭插
void SListPushFront(SLTNode** pphead, SLTDataType x);
// 單鏈表尾刪
void SListPopBack(SLTNode** pphead);
// 單鏈表頭刪
void SListPopFront(SLTNode** pphead);
// 單鏈表查找
SLTNode* SListFind(SLTNode* phead, SLTDataType x);
// 單鏈表在pos位置之后插入x
void SListInsertAfter(SLTNode* pos, SLTDataType x);
// 單鏈表洗掉pos位置之后的值
void SListEraseAfter(SLTNode* pos);
// 單鏈表的銷毀
void SListDestroy(SLTNode** pphead);
下面對以上功能進行實作,
列印單鏈表
列印單鏈表,需要從頭指標指向的位置開始,依次向后列印,直到指標指向NULL,結束列印,
void SListPrint(SLTNode* phead) {
SLTNode* cur = phead;
while (cur != NULL) {
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
單鏈表尾插
void SListPushBack(SLTNode** pphead, SLTDataType x) {
assert(pphead);
SLTNode* newnode = BuySListNode(x);
if (*pphead == NULL) {
*pphead = newnode;
}
else {
SLTNode* tail = *pphead;
while (tail->next != NULL) {
tail = tail->next;
}
tail->next = newnode;
}
}
注意:
- 此處的
assert(pphead);是為了防止傳入的不是二級指標, - 對單鏈表增加一個結點時,都要用到申請一個新的結點,所以我們不妨把該功能封裝成一個函式,
SLTNode* BuySListNode(SLTDataType x) {
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL) {
printf("malloc fail\n");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
單鏈表頭插
void SListPushFront(SLTNode** pphead, SLTDataType x) {
SLTNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
單鏈表尾刪
注意點:
- 需要二級指標
- 對空鏈表,一個結點,兩個及兩個以上的結點分情況討論
void SListPopBack(SLTNode** pphead) {
assert(*pphead != NULL);
// 一個結點
if ((*pphead)->next == NULL) {
free (*pphead);
*pphead = NULL;
}
else {
// 兩個及兩個以上結點
SLTNode* tail = *pphead;
while (tail->next->next != NULL) {
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}
單鏈表頭刪
注意:
- 需要判斷是否為空鏈表,
- 更新頭指標
void SListPopFront(SLTNode** pphead) {
assert(*pphead != NULL);
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
查找結點
遍歷一遍鏈表,找到則回傳當前結點,否則回傳 NULL,
SLTNode* SListFind(SLTNode* phead, SLTDataType x) {
for (SLTNode* cur = phead; cur != NULL; cur = cur->next) {
if (cur->data == x) {
return cur;
}
}
return NULL;
}
單鏈表在pos位置之后插入x
這里首先引出一個問題,為什么需要選擇在pos之后插入,而不是在pos之前插入呢?
其實是有原因的,如果只是在pos之后插入,無需遍歷鏈表就可以操作;如果要在pos之前進行插入,需要遍歷一遍鏈表,然而時間開銷大(相比),O(N),
注意點
- 判斷是否屬于尾插
- 插入結點的順序 !!! 不可顛倒
newnode->next = pos->next;
pos->next = newnode;
void SListInsertAfter(SLTNode* pos, SLTDataType x) {
SLTNode* newnode = BuySListNode(x);
if (pos->next == NULL) {
// 尾插
pos->next = newnode;
}
else {
newnode->next = pos->next;
pos->next = newnode;
}
}
單鏈表洗掉pos位置之后的值
void SListEraseAfter(SLTNode* pos) {
assert(pos && pos->next);
SLTNode* next = pos->next->next;
free(pos->next);
pos->next = NULL;
pos->next = next;
}
單鏈表銷毀
注意
單鏈表的銷毀需要對結點進行逐個銷毀,
為什么???
就憑他是一個一個在堆上開辟出來的,不像動態開辟的順序表,在記憶體里是一段連續的記憶體空間,如果只對鏈表進行 free(*pphead)操作,是會造成記憶體泄漏的!!!
void SListDestroy(SLTNode** pphead) {
SLTNode* cur = *pphead;
while (cur) {
SLTNode* next = cur->next;
free(cur);
cur = next;
}
*pphead = NULL;
}
最后…
其實單鏈表沒有那么可怕,可怕的是老師上課講的稀里糊涂(狗頭保命hhh),大家只要想象成火車的一節節車廂就好啦~~~
小汽車,嘟嘟嘟!!!
最后,如果喜歡博主的話,不妨點個關注哦! 碼文不易,感恩?( ′・?・` )比心
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/333791.html
標籤:其他