
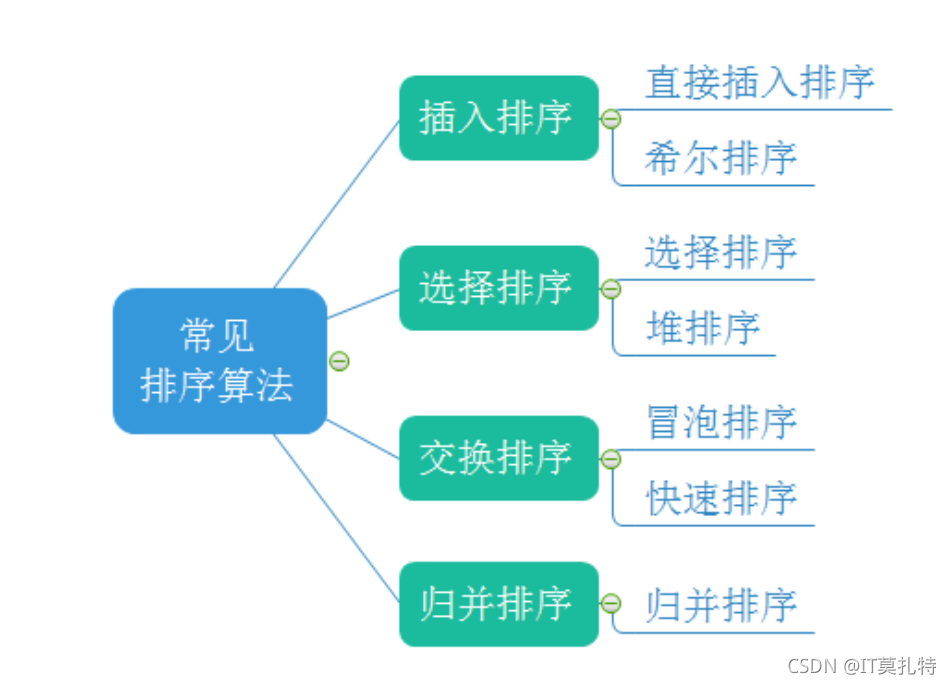
目錄
- 1.排序的概念及其運用
- 2.常見排序演算法的實作
- 插入排序
- 希爾排序
- 選擇排序
- 堆排
- 冒泡排序
- 快排
- hoare版本
- 挖坑法
- 前后指標法
- 快排時間復雜度分析:
- 快排的優化:
- 1、三數取中
- 2、小區間優化
- 快排非遞回實作
- 歸并排序
- 歸并復雜度分析
- 歸并的非遞回
- 非比較排序
- 計數排序
- 絕對映射和相對映射
- 3.排序演算法復雜度及穩定性分析
1.排序的概念及其運用
排序:
所謂排序,就是使一串記錄,按照其中的某個或某些關鍵字的小,遞增或遞減的排列起來的操作,
穩定性:
假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次序保持不變,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,則稱這種排序演算法是穩定的;否則稱為不穩定的,
內部排序:
資料元素全部放在記憶體中的排序,
外部排序:
資料元素太多不能同時放在記憶體中,根據排序程序的要求不能在內外存之間移動資料的排序
2.常見排序演算法的實作
插入排序
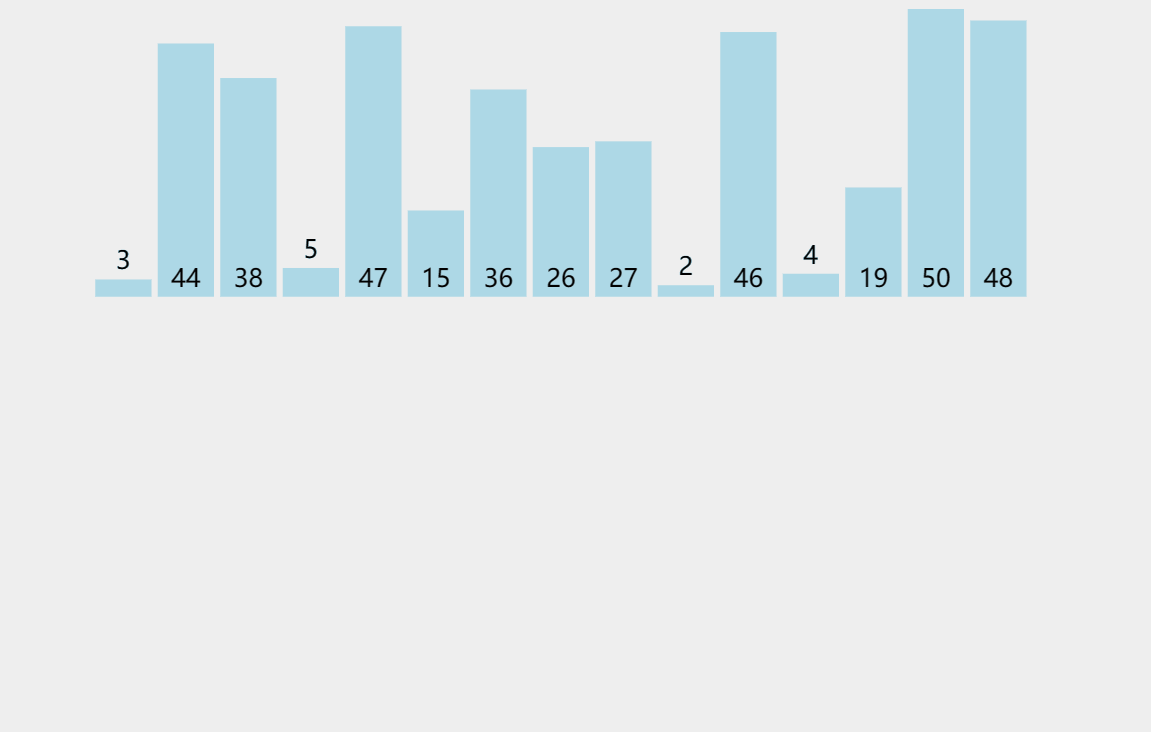
1、從圖中觀察的現象是如果后一個數不比前一個數小,那就不需要插入,不插入的動作就是break出回圈
2、如果前面的數都比pos值大,那么就將前n個數都往后挪動,直到比pos值小或者相等就停止,可以用回圈控制,這里防止越界需要再加判斷
插入排序的基本思想:其基本思想是:
把待排序的記錄按其關鍵碼值的大小逐個插入到一個已經排好序的有序序列中,直到所有的記錄插入完為止,得到一個新的有序序列 ,
代碼
//插入排序,升序
void InsertSort(int* arr, int n)
{
int i = 0;
while (i < n - 1)
{
int end = i;
int tmp = arr[end + 1];
while (end >= 0)
{
if (arr[end] > tmp)
{
arr[end + 1] = arr[end];
end--;
}
else
{
break;
}
}
//由于end是后置--所以當到達合適的位置時,需要+1
arr[end + 1] = tmp;
i++;
}
}
直接插入排序的特性總結:
- 元素集合越接近有序,直接插入排序演算法的時間效率越高,反之越低
- 時間復雜度:O(N^2)
- 空間復雜度:O(1),它是一種穩定的排序演算法
- 穩定性:穩定
希爾排序
希爾排序法又稱縮小增量法,
希爾排序法的基本思想是:
先選定一個整數,把待排序陣列中所有元素分成個組,所有距離為gap的元素分在同一組內,并對每一組內的元素進行排序,然后,重復上面分組和排序的作業,當到達=1時,所有元素在統一組內排好序,
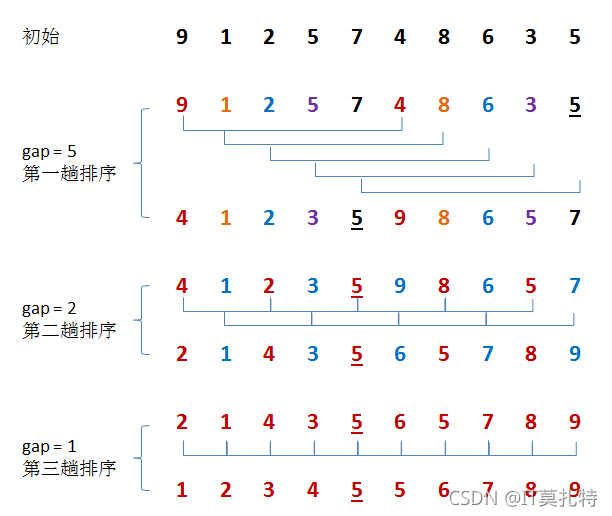
從圖中觀察到的現象:
1、gap越大越不接近有序,但是挪動的更快
2、gap越小越接近有序,挪動的越慢
3、gap為1時,已經很接近有序了,直接插入排序,gap不為1時就是預排序的程序,讓陣列接近于有序,接近有序后直接插入排序的效率會更高
代碼
//希爾排序
void ShellSort(int* arr, int n)
{
int gap = n;
while (gap > 1)
{
//控制gap值的變化,讓陣列接近有序,gap == 1就可以直接插入排序
gap = (gap / 3 + 1);
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = arr[end + gap];
while (end >= 0)
{
if (arr[end] > tmp)
{
arr[end + gap] = arr[end];
end -= gap;
}
else
{
break;
}
}
arr[end + gap] = tmp;
}
}
}
時間復雜度分析:
最壞的情況,逆序,gap很大的時候–》 O(N),當gap很小時本來應該是O(N * N),但是經過前面的預排序,陣列已經已經很接近有序的,所以間隔為gap的插入排序可以理解為很接近O(N),而再看外回圈影響回圈次數的陳述句,gap = (gap / 3 + 1);,
當 gap / 3 / 3 / 3 … == 1,展開之后是 3 ^ x = gap,所以外層while回圈執行的次數就是x次,
那么演算法的整體時間復雜度就是O(log 3 (N) * N),
log 3 (N),以3為底N的對數
選擇排序
選擇排序的基本思想:
在每次遍歷陣列的程序中一次回圈選兩個下標找出最大和最小值的下,將大的交換到右邊,小的交換到左邊
//選擇排序
void selectSort(int* arr, int n)
{
int left = 0;
int right = n - 1;
while (left < right)
{
int MaxIndex = left, MinIndex = left;
for (int i = left; i <= right; i++)
{
if (arr[MaxIndex] < arr[i])
MaxIndex = i;
else
MinIndex = i;
}
//將大的值交換到右邊,小的值交換到左邊
Swap(&arr[left],&arr[MinIndex]);
//防止max被換走
if (MaxIndex == left)
{
MaxIndex = MinIndex;
}
Swap(&arr[right], &arr[MaxIndex]);
left++;
right--;
}
}
- 時間復雜度:O(N^2)
- 空間復雜度:O(1)
- 穩定性:不穩定
堆排
博主之前已經在堆實作這一章講解過了,如果需要細致學習的請點擊鏈接,這里就不再敘說了,需要注意的是排升序要建大堆,排降序建小堆
堆排教程.

代碼:
//向下調整
void AdjustDown(int* arr, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
if(child + 1 < n && arr[child + 1] > arr[child])
{
child++;
}
else if (arr[child] > arr[parent])
{
Swap(&arr[child],&arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//堆排
void HeapSort(int* arr, int n)
{
for(int i = (n - 1 - 1) / 2 ; i >= 0; i--)
{
AdjustDown(arr, n, i);
}
int end = n - 1;
while (end >= 0)
{
Swap(&arr[end--],&arr[0]);
AdjustDown(arr,end,0);
}
}
冒泡排序
冒泡排序的基本思想:
就是根據序列中兩個記錄鍵值的比較結果來對換這兩個記錄在序列中位置,交換排序的特點是:將鍵值較大的記錄向序列的尾部移動,鍵值較小的記錄向序列的前部移動,
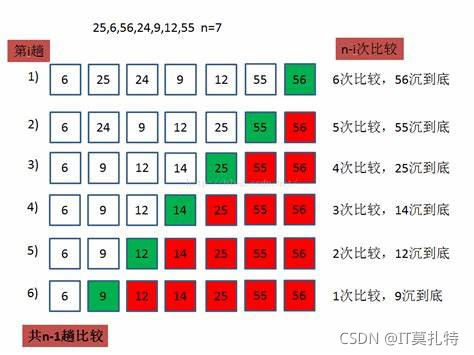
兩兩相比較,將小的交換到前面大的交換到后面,排序n個元素只需要比較n - 1趟,每冒泡一趟少比較一個元素
//冒泡排序
void bubblesort(int* arr, int n)
{
int end = 0;
for (end = n; end > 0; end--)
{
int flag = 0;
int j = 0;
for (j = 1; j < end; j++)
{
if (arr[j - 1] > arr[j])
{
Swap(&arr[j - 1] ,&arr[j]);
flag = 1;
}
else
{
break;
}
}
if (!flag)
break;
}
}
- 時間復雜度:O(N^2)
- 空間復雜度:O(1)
- 穩定性:穩定
快排
快速排序是Hoare于1962年提出的一種二叉樹結構的交換排序方法,其基本思想為:任取待排序元素序列中的某元素作為基準值,按照該排序碼將待排序集合分割成兩子序列,左子序列中所有元素均小于基準值,右子序列中所有元素均大于基準值,然后最左右子序列重復該程序,直到所有元素都排列在相應位置上為止,
hoare版本
程序:
1、單趟排序選出key,通常情況下key的位置都是選擇在陣列下標為0的位置,最左邊,最右邊都可以
2、將小的值交換到左邊,將大的值交換到右邊,最終把key放到正確的位置,保證左邊的值要比key小,右邊的值要比key大
左右指標法:
左邊的哨兵找比key大的值,右邊的哨兵找比key小的值
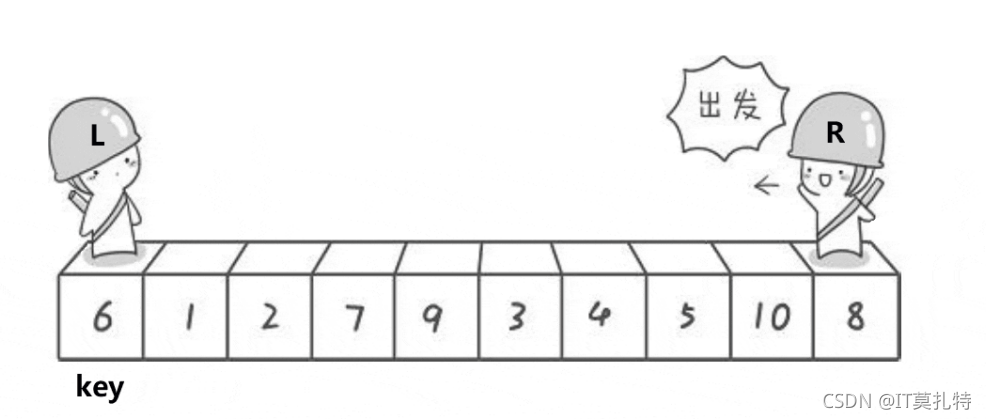
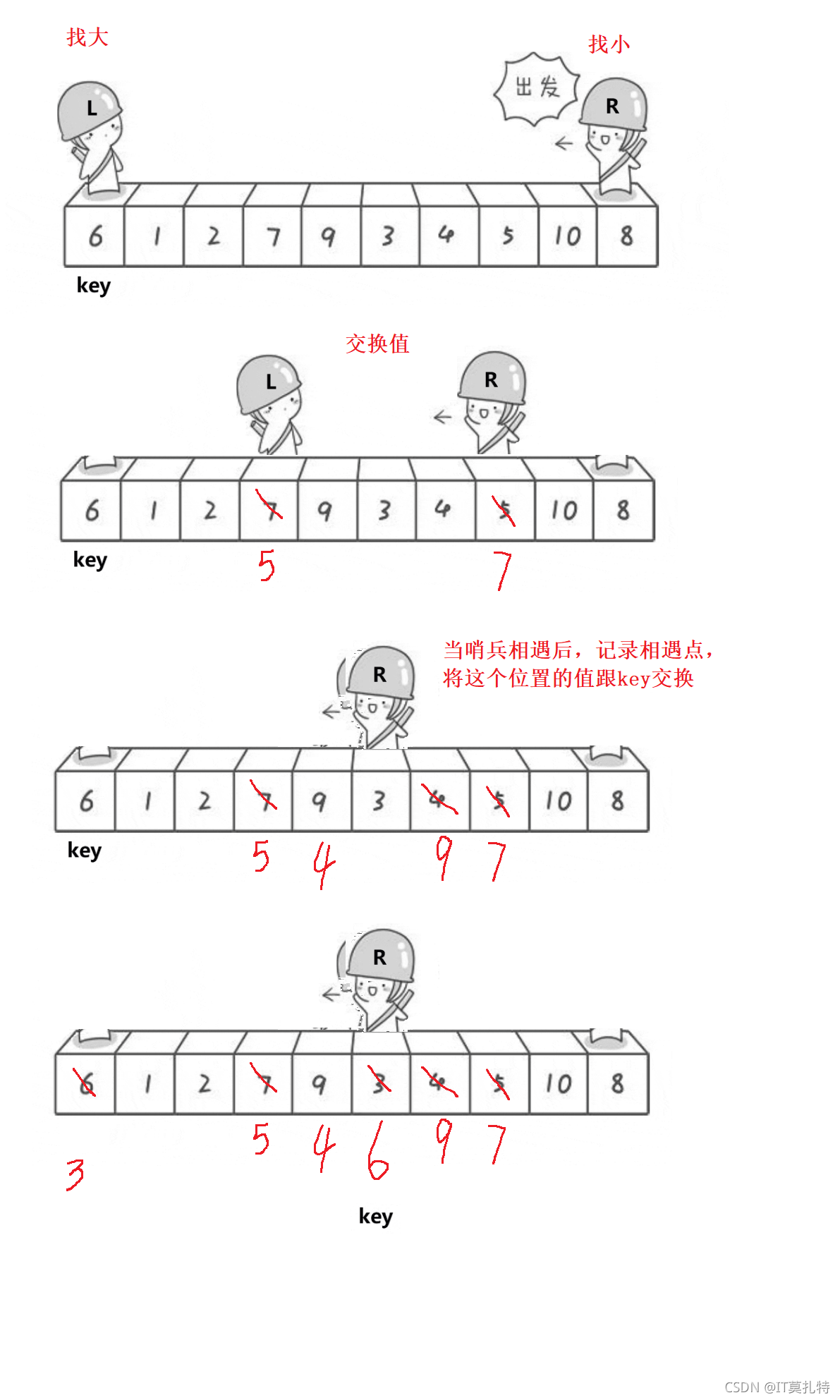
觀察到的現象是一次單趟排序后,key的左邊值都比key要小,key右邊的值都要比key大,這樣就已經達成了初步有序的目的了
if (begin >= end)
{
return;
}
int left = begin, right = end;
int key = left;
while (left < right)
{
//右找小,left < right防止升序的情況下出現越界
while (left < right && arr[right] >= arr[key])
{
right--;
}
//左找大
while (left < right && arr[left] <= arr[key])
{
left++;
}
//交換,將比key小的值換到左邊,比key大的值換到右邊
Swap(&arr[left], &arr[right]);
}
int meet = left;
//確定key的位置
Swap(&arr[left], &arr[key]);
QuickSort(arr,begin, meet - 1);
QuickSort(arr, meet + 1, end);
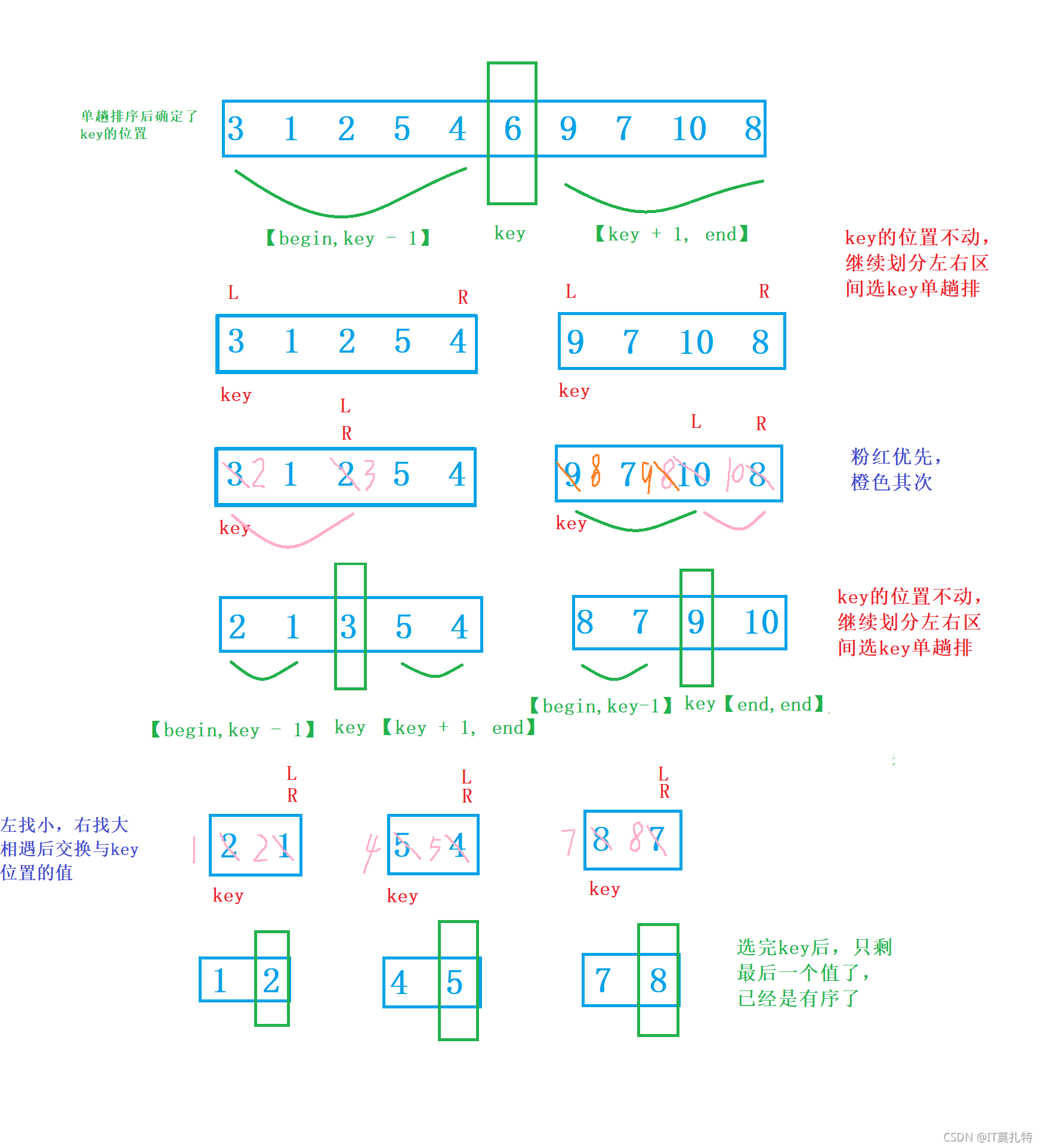
挖坑法
基本思想:
將第一個位置選做key,這樣就形成了天然的坑位,右邊去找比key小的值,找到后將值填充到坑位中,自己成為新坑,左去找大,找到后將值放到右邊的坑中,自己成為新的坑,反復直到相遇,相遇點也是一個坑位,將key的值放到坑中,這樣單趟排就已經確定key值的位置了
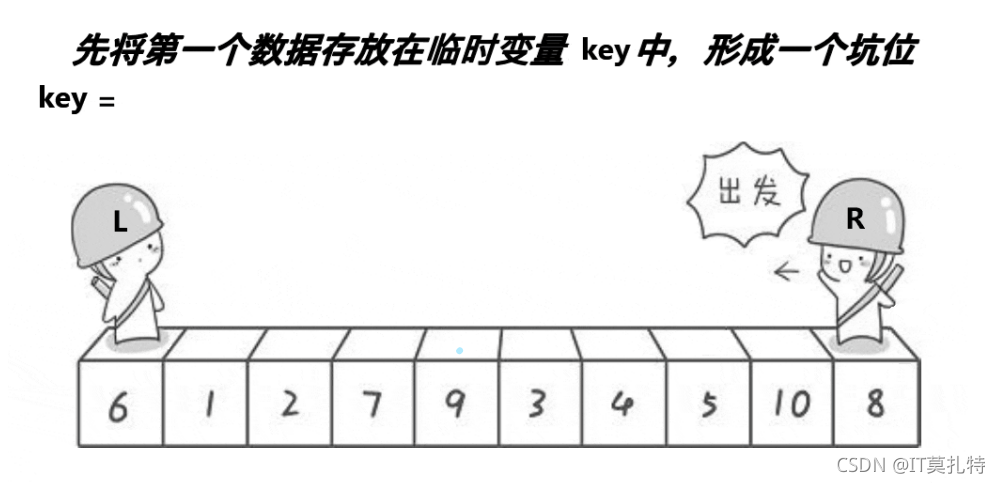
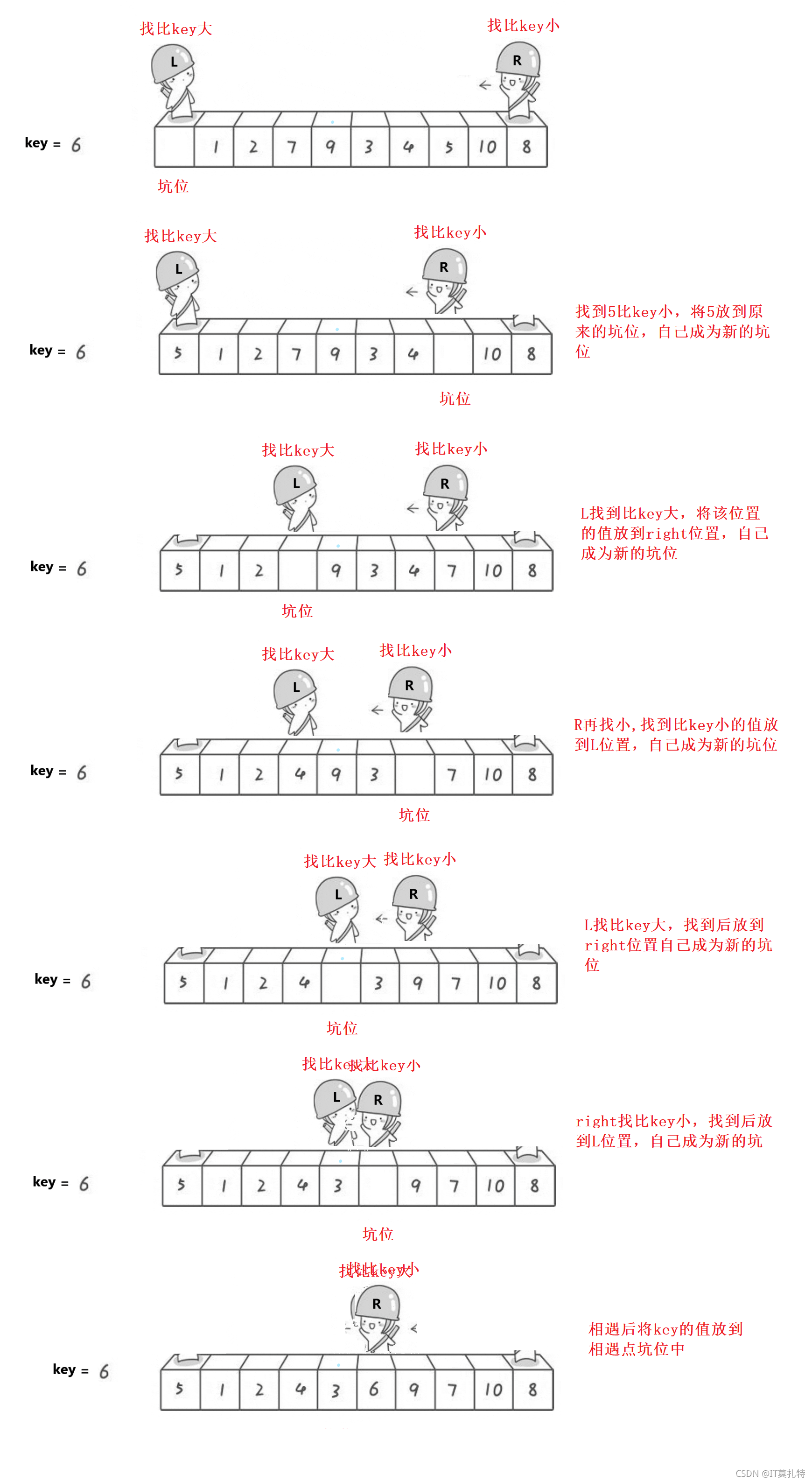
初步單趟排就已經確定了,并且key也放到它正確的位置了,key的左邊比他小,右邊比他大
//挖坑法
void QuickSort(int* arr, int begin, int end)
{
if (begin >= end)
{
return;
}
int left = begin, right = end;
//將第一個資料存放在臨時變數中,成為一個天然坑位
int key = arr[left];
while (left < right)
{
//找小
while (left < right && arr[right] >= key)
right--;
//找到小的將小的放到左邊坑,右邊成為新的坑位
arr[left] = arr[right];
//找大
while (left < right && arr[left] <= key)
left++;
//找到大的將大的放到右邊坑,左邊成為新的坑位
arr[right] = arr[left];
}
//選key,將key值放到相遇點的位置
arr[left] = key;
int meet = left;
//左區間單趟排
QuickSort(arr, begin,meet - 1);
//右區間單趟排
QuickSort(arr, meet + 1, end);
}
前后指標法
基本思想:
雙指標,定義prev和cur開始一前一后,cur去找比key小的值,找到后++prev,再交換cur和prev它們的值,直到陣列遍歷完,最后一下交換key位置的值和prev位置的值,這樣就確定了key值的位置
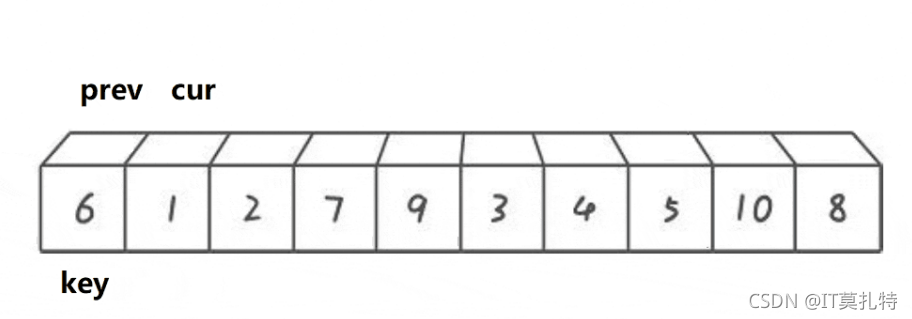
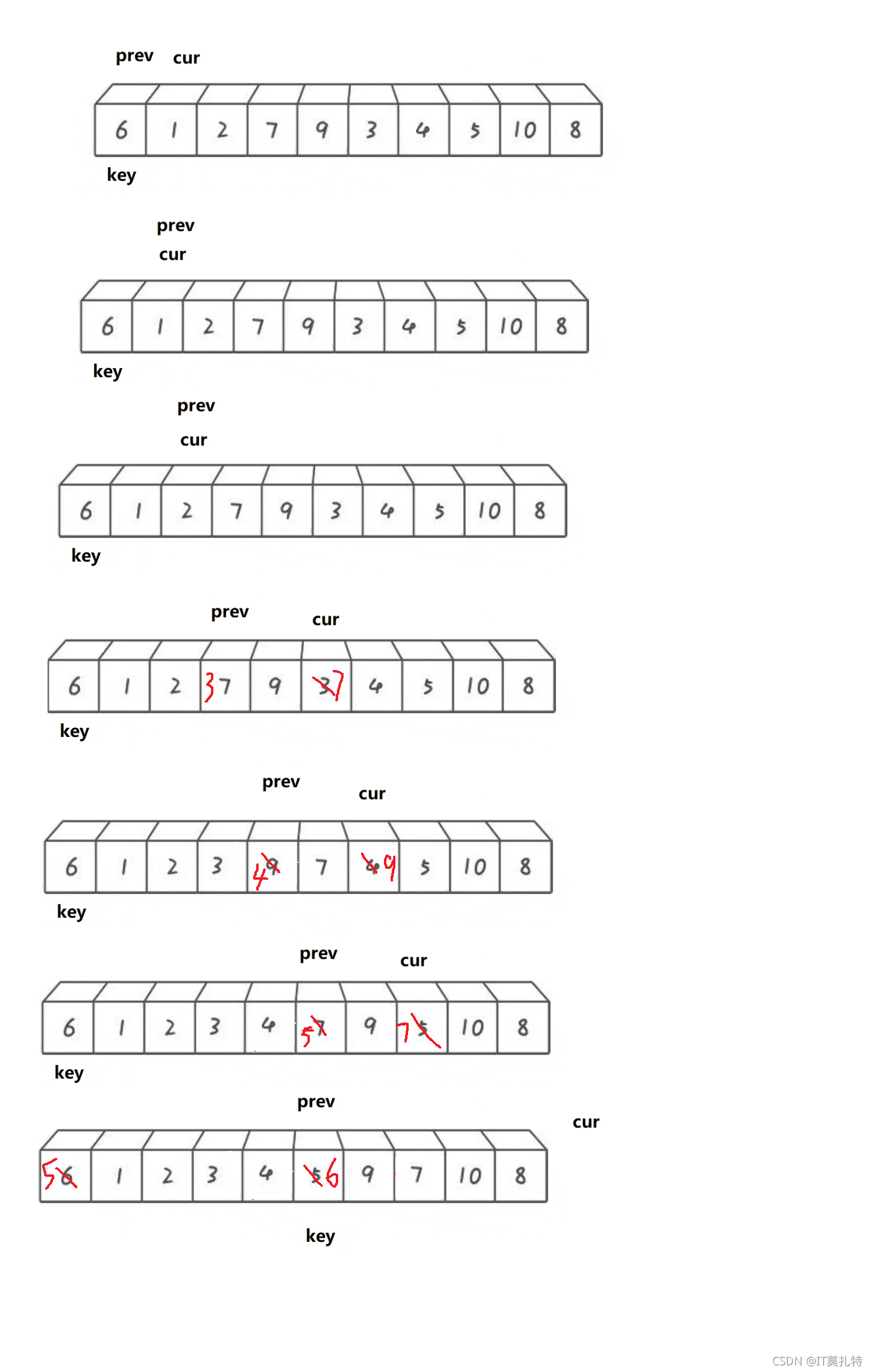
//前后指標法
void __QuickSort(int* arr, int begin, int end)
{
if (begin >= end)
{
return;
}
int prev = begin - 1;
int cur = begin;
int key = begin;
while (cur <= end)
{
while (arr[cur] < arr[key] && ++prev != cur)
{
Swap(&arr[cur], &arr[prev]);
}
cur++;
}
Swap(&arr[prev],&arr[key]);
_QuickSort(arr, begin, prev - 1);
_QuickSort(arr, prev + 1, end);
}
快排時間復雜度分析:
先考慮理想情況:
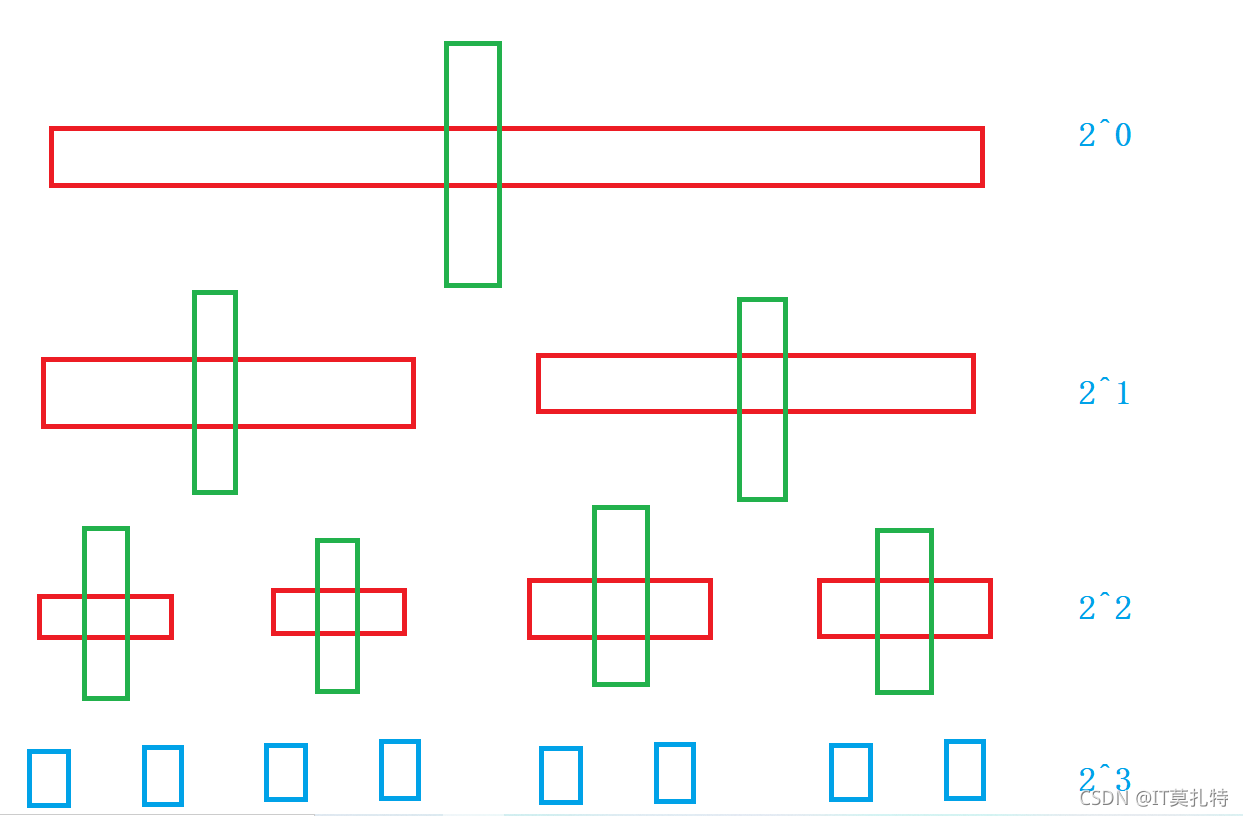
從圖中我們可以看出快排的單趟排不管是右遇左,還是左遇右,合計起來也只能走陣列長度N次,每選一個key值劃分左右區間,單趟排確定key值的位置,不斷遞回劃分左右區間,遞回的深度是以2^N遞增的,所以它的時間復雜度是O(N * log N)
考慮最壞情況:
如果陣列已經是有序的了,那么不管是右遇左,還是左遇右每次都得走n-1步才能選出key的位置,那么它的執行次數就是一個等引數列了,所以時間復雜度就是O(N^2),怎么優化呢?
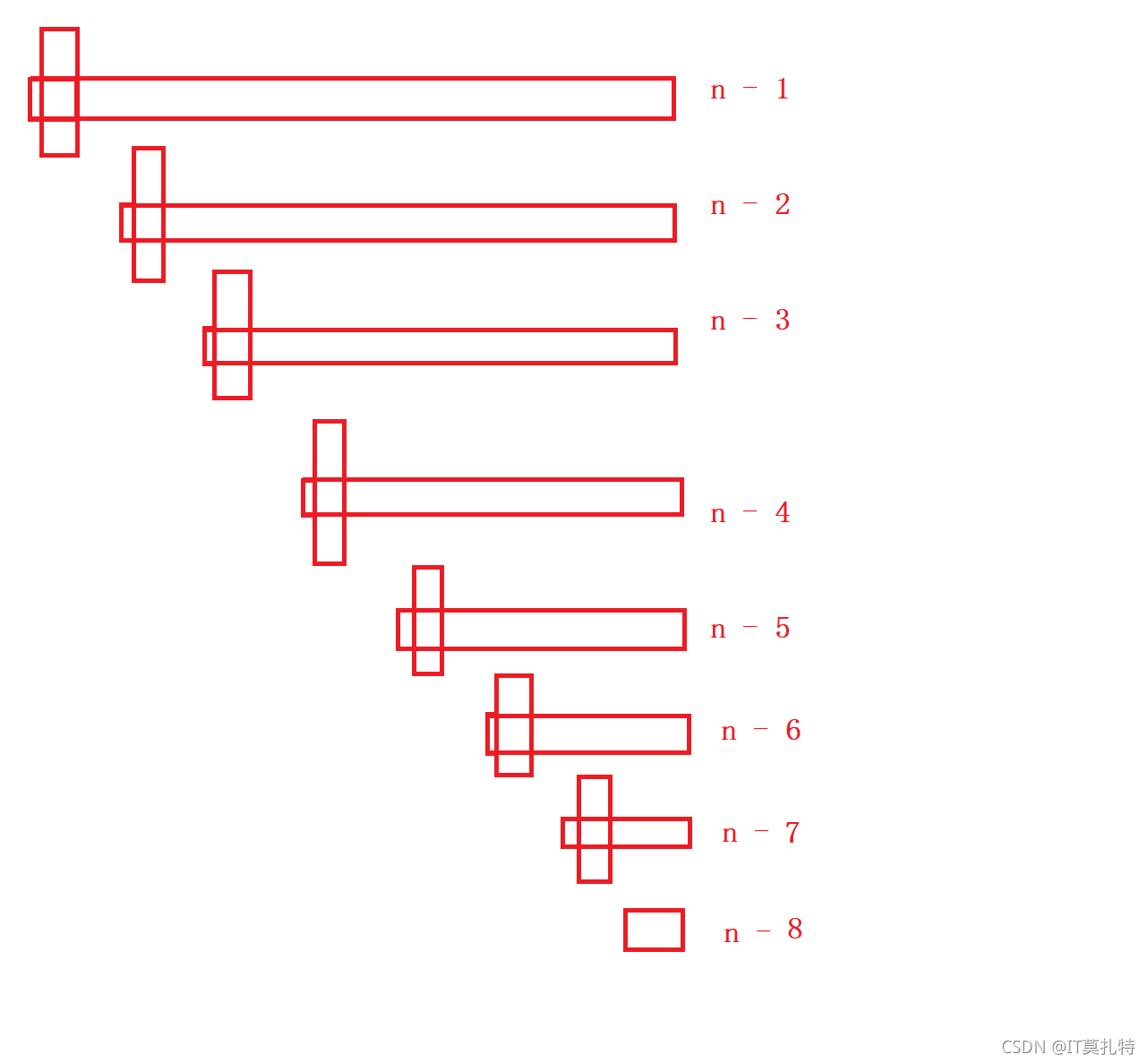
快排的優化:
針對快排得優化:
思考:對快排影響最大的是選的key,如果key越接近中位數越接近二分,效率越高
1、三數取中
找出這個區間中的中位數,使每次選key都為中位數,那么不用考慮有序這種惡劣的情況出現了
//三數取中
int GetMidIndex(int* arr, int left, int right)
{
int mid = (left + right) >> 1;
if (arr[left] < arr[mid])
{
if (arr[mid] < arr[right])
{
return mid;
}
else if (arr[left] > arr[right])
{
return left;
}
else
{
return right;
}
}
else //arr[left] > arr[mid]
{
if (arr[mid] > arr[right])
{
return mid;
}
else if (arr[left] < arr[right])
{
return left;
}
else
{
return right;
}
}
}
2、小區間優化
當每一個區間遞回下去的時候只剩20個數了(官方參考),就可以考慮不再遞回換用插入排序,接近于有序插入排序的效果會更好一些,而且遞回 也是有消耗的,能節省就節省一些
if (end - begin > 10)
{
QuickSort(arr, begin, meet - 1);
QuickSort(arr, meet + 1, end);
}
else
{
InsertSort(arr + begin, end - begin + 1);
}
完整的代碼:
//快速排序
void QuickSort(int* arr, int begin, int end)
{
if (begin >= end)
{
return;
}
int MidIndex = GetMidIndex(arr, begin, end);
int left = begin, right = end;
Swap(&arr[MidIndex], &arr[left]);
int key = left;
while (left < right)
{
while (left < right && arr[right] >= arr[key])
{
right--;
}
while (left < right && arr[left] <= arr[key])
{
left++;
}
Swap(&arr[left], &arr[right]);
}
int meet = left;
Swap(&arr[left], &arr[key]);
if (end - begin > 20)
{
QuickSort(arr, begin, meet - 1);
QuickSort(arr, meet + 1, end);
}
else
{
InsertSort(arr + begin, end - begin + 1);
}
}
快排非遞回實作
為什么會有非遞回的版本呢,有些場景遞回解決不了的問題于是就需要非遞回登場了
非遞回實作思想:由于C語言庫并沒有堆疊,所以需要自己動手實作一個堆疊,如果需要相關代碼的可以點擊這個鏈接: 堆疊實作.要想實作非遞回并不難,只需要理解好快排的遞回原理,快排的遞回思想是,對一段區間單趟排,選key,確定好key的位置,再對key的左區間遞回遞回單趟排,key的右區間遞回單趟排,不斷地分裂,確定key的位置,只剩一個值了,這樣一來陣列就有序了,讀者有沒有發現,其中描述的兩個步驟無非就是選key和對一段區間進行單趟排序,直到只剩一個值了,就可以是有序的,所以只需要用堆疊模擬遞回的程序,將一段區間用堆疊保存起來,取區間出來單趟排,再選key的位置,不斷劃分左右區間,最終只剩一個值了,陣列就是有序的了
//單趟排序,回傳key
int parsort(int* arr, int begin, int end)
{
//三數取中
int MidIndex = GetMidIndex(arr, begin, end);
int left = begin, right = end;
Swap(&arr[MidIndex], &arr[left]);
int key = left;
while (left < right)
{
//右找小,left < right防止升序的情況下出現越界
while (left < right && arr[right] >= arr[key])
{
right--;
}
//左找大
while (left < right && arr[left] <= arr[key])
{
left++;
}
//交換
Swap(&arr[left], &arr[right]);
}
int meet = left;
Swap(&arr[left], &arr[key]);
return meet;
}
//快排非遞回實作
void QuickSortNonR(int* arr, int begin, int end)
{
Stack st;
StackInit(&st);
StackPushBack(&st, begin);
StackPushBack(&st, end);
while (!StackEmpty(&st))
{
//取出右區間
int right = StackTop(&st);
StackPop(&st);
//取出左區間
int left = StackTop(&st);
StackPop(&st);
//單趟排,選出key
int keyi = parsort(arr, left, right);
//入左區間
if (left < keyi - 1)
{
StackPushBack(&st, left);
StackPushBack(&st, keyi - 1);
}
//入右區間
if (keyi + 1 < right)
{
StackPushBack(&st, keyi + 1);
StackPushBack(&st, right);
}
}
}
快排特性總結:
- 時間復雜度:O(N*logN)
- 空間復雜度:O(logN)
- 穩定性:不穩定
歸并排序
基本思想:
歸并排序(MERGE-SORT)是建立在歸并操作上的一種有效的排序演算法,該演算法是采用分治法(Divide andConquer)的一個非常典型的應用,將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序,若將兩個有序表合并成一個有序表,稱為二路歸并, 歸并排序核心步驟:
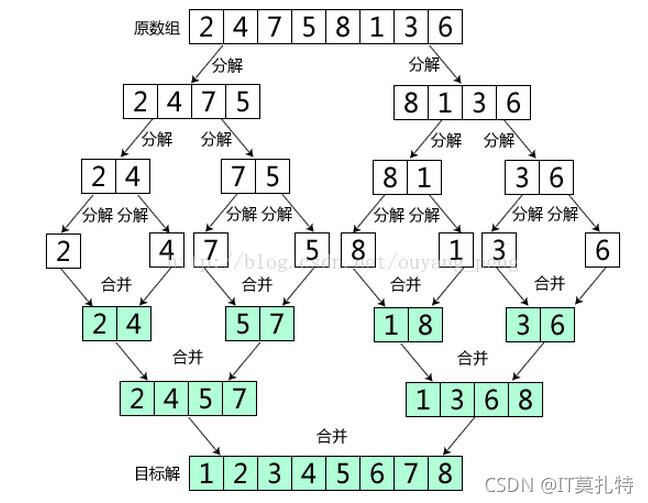
選出中間的位置,去遞回左區間和右區間當它們只剩一個值的時候就不需要再遞回,將左右區間中較小的值拷貝到臨時陣列,再將臨時陣列的值拷貝會原陣列,這樣子區間就有序了,
簡單點來說就是想讓整個區間有序就必須不斷地拆分子區間,讓子區間先有序了,再來歸并子區間讓整個區間就有序了,下圖用不同的顏色標識每一段區間,當小區間歸并后又會替換成另一種新的顏色
歸并和快排的區別:同屬于O(N * log N)時間復雜度的演算法,但是歸并的空間復雜度卻是O(N),因為需要開辟一個額外的陣列用來歸并使其有序,當然快排是選key再分治遞回左右區間,可見他是一種前序遍歷思想,根–>左–>右,而歸并不同于快排的是他是不斷地拆分左右區間,使左右區間只剩一個值了,看成有序,再來對左右區間歸并,讓這段子區間有序,左–>右–>根所以歸并是一種后序思想,
實作代碼:
//歸并排序
void MergerSort(int* arr, int begin, int end,int *tmp)
{
if (begin >= end)
{
return;
}
int mid = (begin + end) >> 1;
MergerSort(arr,begin, mid,tmp);
MergerSort(arr, mid + 1, end, tmp);
//當左右區間拆分到只有一個值的時候,就可以歸并
int begin1 = begin, begin2 = mid + 1;
int i = begin;
while (begin1 <= mid && begin2 <= end)
tmp[i++] = arr[begin1] < arr[begin2] ? arr[begin1++] : arr[begin2++];
while (begin1 <= mid)
tmp[i++] = arr[begin1++];
while (begin2 <= end)
tmp[i++] = arr[begin2++];
int dest = i;
for (i = 0; i < dest; i++)
{
arr[i] = tmp[i];
}
}
歸并復雜度分析
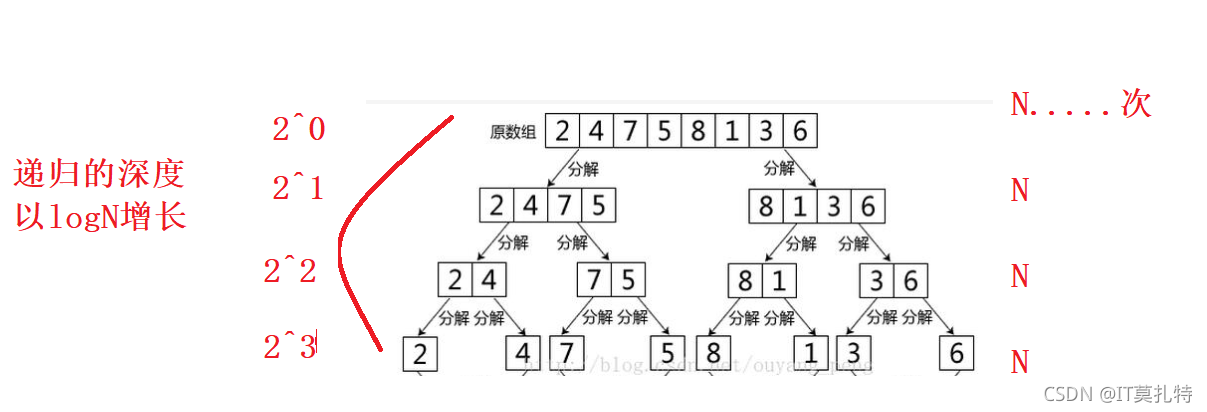
可以從圖中看到的對N個元素會被分解出N次,每一層都有N個元素,遞回的深度是呈logN增長的,所以歸并的時間復雜度是O(N * log N),但是歸并唯一遺憾的是它的空間復雜度卻是O(N),因為他要開辟一個額外的臨時陣列,
歸并的非遞回
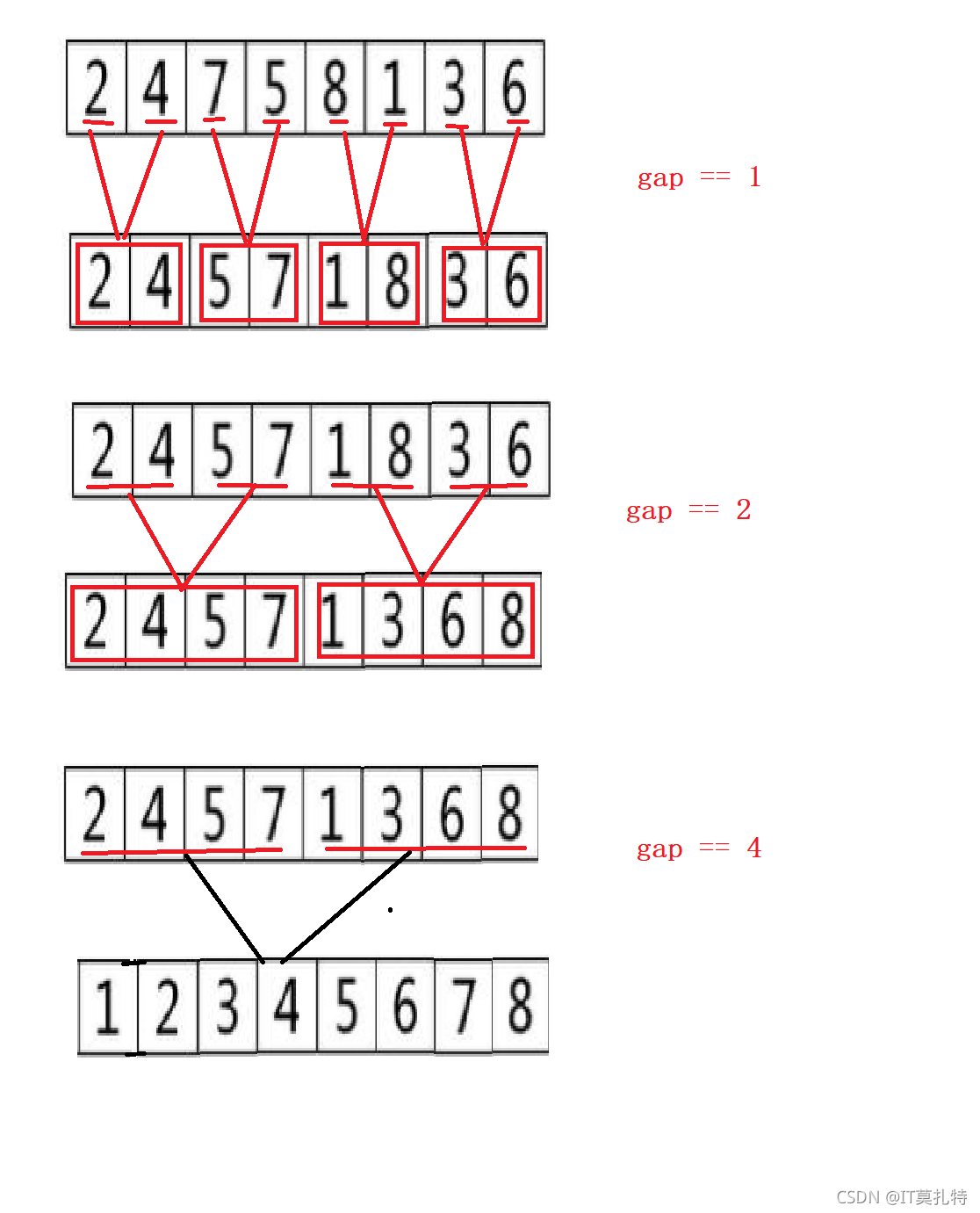
再使用遞回的時候由于是后序遍歷思想,所以需要將左右區間分解成一個值的時候才開始往回退歸并,而現在換用回圈就不需要考慮這個區間是不是只剩一個值了,可以通過調整gap來控制排序程序,gap表示的是區間中有幾個元素個數,當然這里畫的是滿了,后面還是一些其他情況也會一 一講解
控制gap的大小,對這兩段區間進行歸并,i從0開始
左區間【i ,i + gap - 1】,右區間【i + gap,i + 2 * gap - 1】
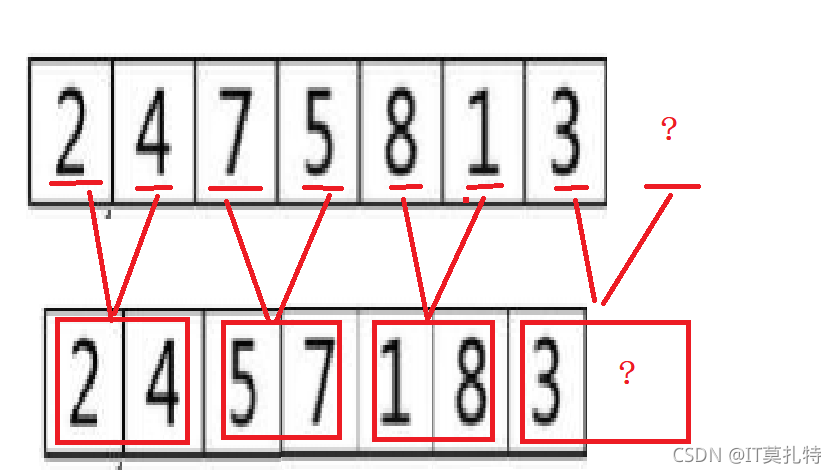
考慮惡劣的情況
1、第二個區間并不存在
當gap == 1的時候,但是右區間如果沒有的話直接不歸跳出回圈防止訪問越界
如果右區間并不存在
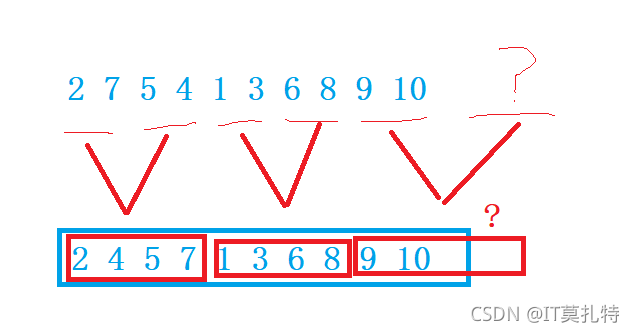
右區間存在但不夠gap個,結束位置可能存在越界,需要修正
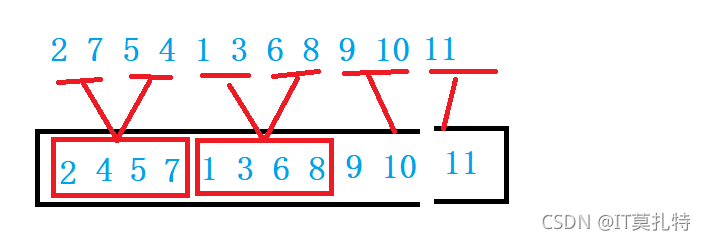
左區間不夠gap個
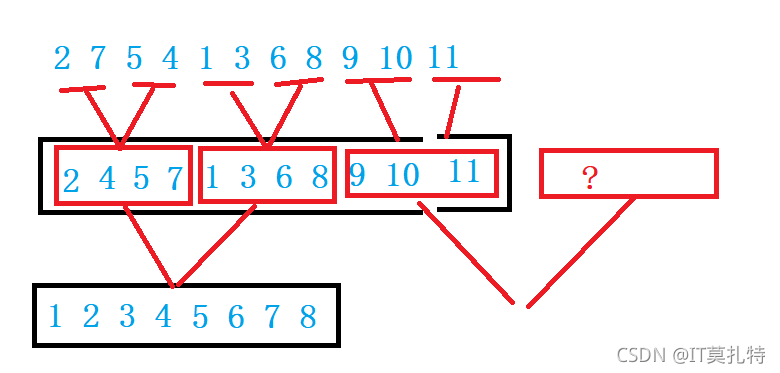
總結:
1、最后一個小組歸并時,第二個小區間不存在,不需要再歸并
2、最后一個小組歸并時,第二個小區間存在,第二個區間不夠gap個
3、最后一個小組歸并時,第一個小區間不夠gap個,不需要歸并,
void _Merger(int* arr, int begin1, int end1,int begin2, int end2, int* tmp)
{
int i = begin1;
while (begin1 <= end1 && begin2 <= end2)
tmp[i++] = arr[begin1] < arr[begin2] ? arr[begin1++] : arr[begin2++];
while (begin1 <= end1)
tmp[i++] = arr[begin1++];
while (begin2 <= end2)
tmp[i++] = arr[begin2++];
int dest = i;
for (i = 0; i < dest; i++)
{
arr[i] = tmp[i];
}
}
//歸并非遞回實作
void MergerSortNonR(int* arr, int *tmp,int n)
{
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1,
begin2 = i + gap, end2 = i + 2 * gap - 1;
//右區間不存在
if (begin2 >= n)
{
break;
}
//右區間存在但是不夠gap個
if (end2 >= n)
{
end2 = n - 1;
}
//歸并這段區間讓他有序
_Merger(arr,begin1, end1,begin2, end2,tmp);
}
gap *= 2;
}
}
歸并排序特新總結:
- 歸并的缺點在于需要O(N)的空間復雜度,歸并排序的思考更多的是解決在磁盤中的外排序問題,
- 時間復雜度:O(N*logN)
- 空間復雜度:O(N)
- 穩定性:穩定
非比較排序
計數排序
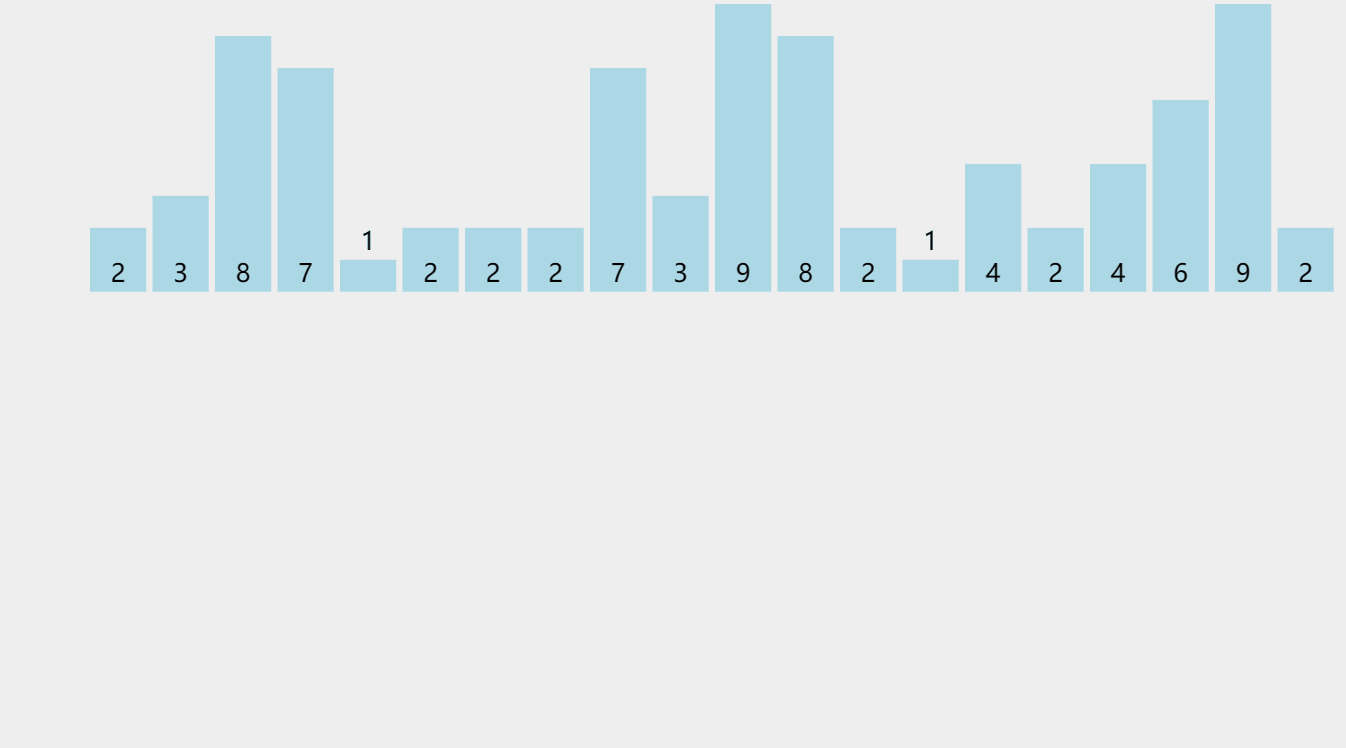
觀察到的現象:
1、統計相同元素出現次數,時間復雜度O(N)
2、根據統計的結果將序列回收到原來的序列中
3、需要開辟一個臨時陣列用來存放資料,空間復雜度O(N)
當然如果資料量大了,需要開辟的臨時陣列可能就會更大了,這些都是有消耗的,怎么解決呢?
先來了解兩個概念
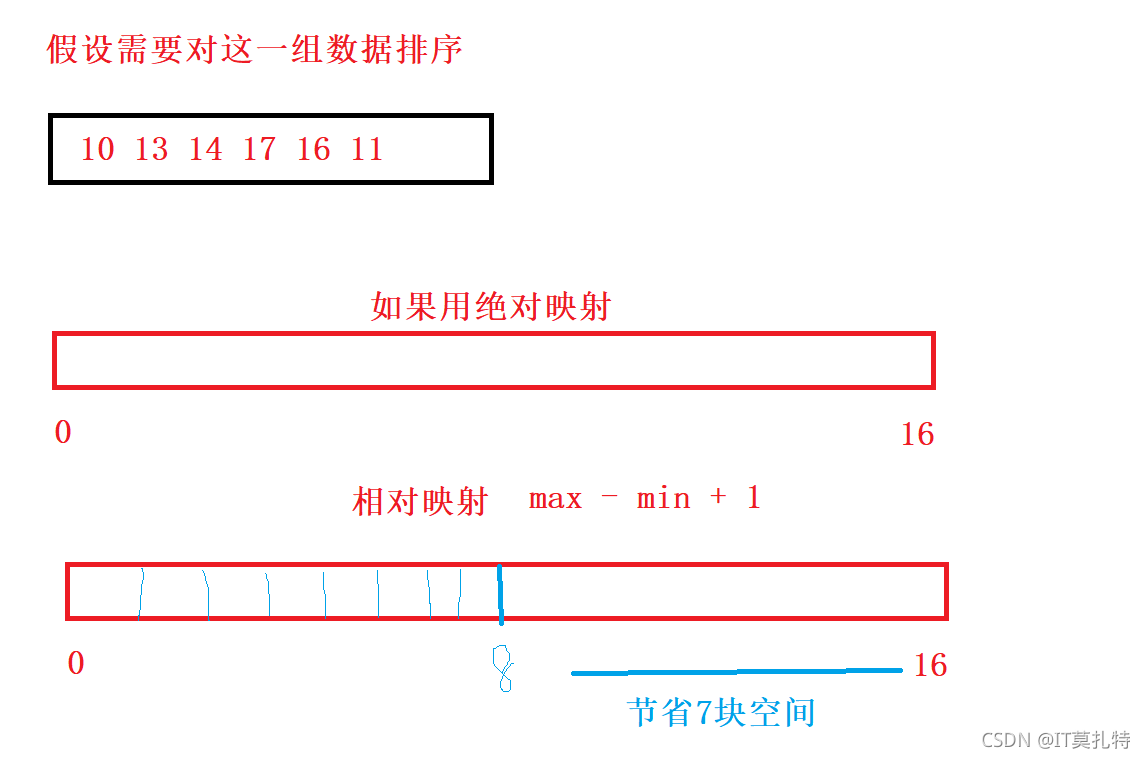
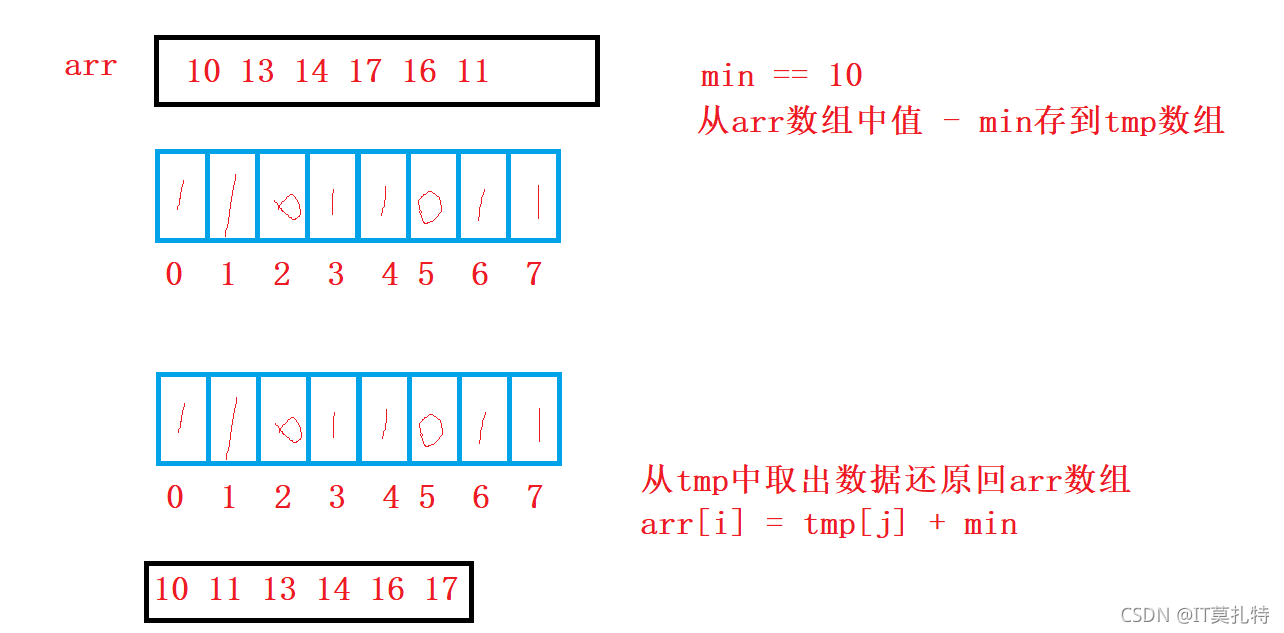
絕對映射和相對映射
絕對映射:統計出每個數出現的次數,A[i]的值對應count陣列位置的值++
for(int i = 0; i < n; i++)
count[A[i]]++
相對映射:
//計數排序
void CountSort(int* arr, int n)
{
int max = arr[0], min = arr[0];
for (int i = 0; i < n; i++)
{
if (arr[i] > max)
max = arr[i];
else if (arr[i] < min)
min = arr[i];
}
int range = max - min + 1;
int* tmp = (int *)malloc(sizeof(int) * range);
assert(tmp);
memset(tmp, 0, sizeof(int) * range);
for (int i = 0; i < n; i++)
{
//記錄原值相對于最小值的位置
tmp[arr[i] - min]++;
}
int i = 0;
for (int j = 0; j < range; j++)
{
while (tmp[j]--)
{
//還原出原值的位置
arr[i++] = j + min;
}
}
}
總結:
計數排序不管是用相對映射還是絕對映射都行,只不過用絕對映射會存在一定的浪費,而相對不會
1、時間復雜度O(N + range)
2、空間復雜度O(range)
3、計數排序只適合一組資料,資料的范圍比較集中,如果范圍集中,效率是很高的,但是局限性也在這里,并且只適合整數
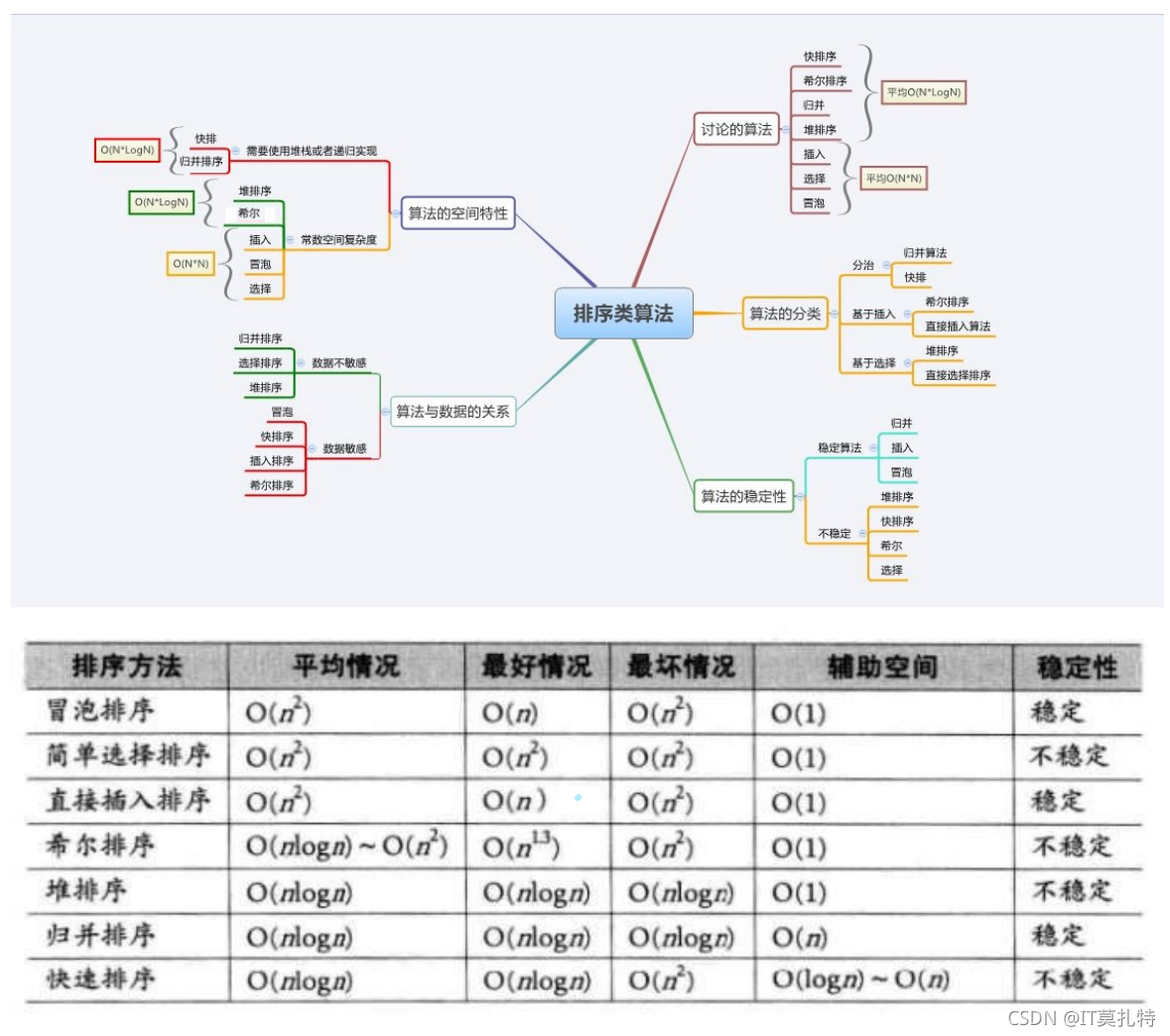
3.排序演算法復雜度及穩定性分析

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/333800.html
標籤:其他
下一篇:PyTorch學習Lesson4