作者主頁(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文網址:https://blog.csdn.net/HiWangWenBing/article/details/120896296
目錄
第1章 卷積神經網路基礎
1.1 卷積神經發展與進化史
1.2 卷積神經網路的核心要素
1.3 卷積神經網路的描述方法
1.4 人工智能三巨頭 + 華人圈名人
第2章 GoogleNet網路概述
2.1 概述
2.2 Christian Szegedy(克里斯蒂安·塞格迪)其人
2.3 googLeNet提出的動機與背景
2.4 googLeNet特點與更新
2.5 inception的本意
第3章 GoogLeNet網路組成單元
3.1 GoogLeNet基本、核心組成單元Inception的結構介紹 - 原始版本
3.2 GoogLeNet基本、核心組成單元Inception的結構介紹 - 改進版本
3.3 什么是1x1卷積核?
3.4 1x1卷積核的意義與作用
第4章 GoogLeNet網路結構分析
4.1 inception網路結構:橫向表示法
4.2 inception網路結構:縱向表示法
4.3 不同子版本的比較
4.4 網路結構分析
4.5 輔助分類器
第1章 卷積神經網路基礎
1.1 卷積神經發展與進化史
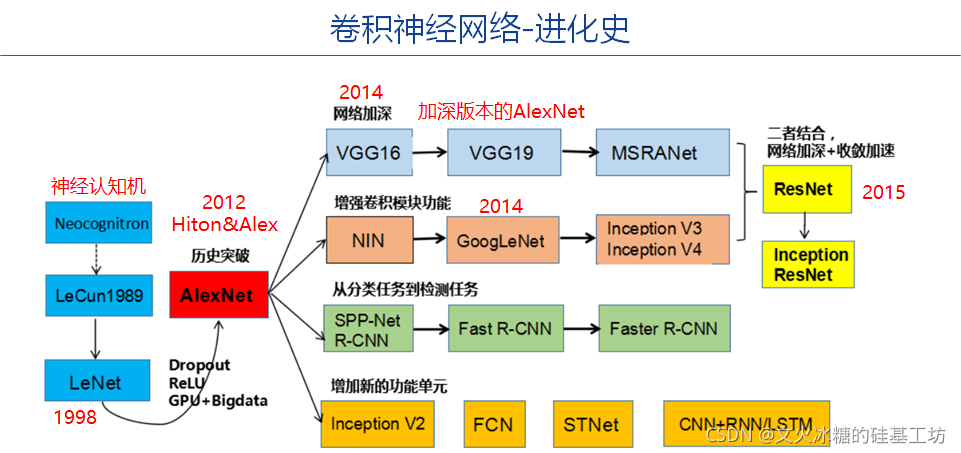
AlexNet是深度學習的起點,后續各種深度學習的網路或演算法,都是源于AlexNet網路,
[人工智能-深度學習-31]:卷積神經網路CNN - 常見卷積神經網路綜合比較大全_文火冰糖(王文兵)的博客-CSDN博客作者主頁(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客本文網址:第1章 人工智能發展的3次浪潮1.1人工智能的發展報告2011-2020資料來源:清華大學、中國人工智能學會《人工智能的發展報告2011-2020》,賽迪研究院、人工智能產業創新聯盟《人工智能實踐錄》,中金公司研究部? 第一次浪潮(1956-1974年):AI思潮賦予機器邏輯推理能力,伴隨著“人工智能”這一新興概念的興起,人們對AI的未來充滿了想象,人工智能迎來第一次發展浪潮,這.https://blog.csdn.net/HiWangWenBing/article/details/120835303
1.2 卷積神經網路的核心要素
[人工智能-深度學習-27]:卷積神經網路CNN - 核心概念(卷積、滑動、填充、引數共享、通道)_文火冰糖(王文兵)的博客-CSDN博客作者主頁(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客本文網址:目錄第1章 卷積中的“積”的定義第2章 卷積中的“卷”的定義第3章 填充第4章 單個卷積核的輸出第5章 多個卷積核的輸出第6章 卷積對圖形變換第7章 池化層第8章 全連接的dropout第1章 卷積中的“積”的定義第2章 卷積中的“卷”的定義stride:反映的每次移動的像素點的個數,第3章 填充...https://blog.csdn.net/HiWangWenBing/article/details/120806277
1.3 卷積神經網路的描述方法
[人工智能-深度學習-28]:卷積神經網路CNN - 網路架構與描述方法_文火冰糖(王文兵)的博客-CSDN博客作者主頁(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客本文網址:目錄第1章 什么是卷積神經網路第2章 卷積神經網路的描述方法第3章 卷積神經網路的本質第4章 卷積神經網路的總體框框第5章卷積神經網路的發展與常見型別與分類第6章 常見的卷積神經網路6.1 AlexNet6.2 VGGNet6.3 GoogleNet: inception結構6.4 google net6.5 ResNet第7章 常見圖形訓練庫第1.https://blog.csdn.net/HiWangWenBing/article/details/120806599
1.4 人工智能三巨頭 + 華人圈名人

Yoshua Bengio、Yann LeCun、Geoffrey Hinton共同獲得了2018年的圖靈獎,
杰弗里·埃弗里斯特·辛頓(Geoffrey Everest Hinton),計算機學家、心理學家,被稱為“神經網路之父”、“深度學習鼻祖”,Hinton是機器學習領域的加拿大首席學者,是加拿大高等研究院贊助的“神經計算和自適應感知”專案的領導者,是蓋茨比計算神經科學中心的創始人,目前擔任多倫多大學計算機科學系教授,2013年3月,谷歌收購 Hinton 的公司 DNNResearch 后,他便隨即加入谷歌,直至目前一直在 Google Brain 中擔任要職,
Yoshua Bengio是蒙特利爾大學(Université de Montréal)的終身教授,任教超過22年,是蒙特利爾大學機器學習研究所(MILA)的負責人,是CIFAR專案的負責人之一,負責神經計算和自適應感知器等方面,又是加拿大統計學習演算法學會的主席,是ApSTAT技術的發起人與研發大牛,Bengio在蒙特利爾大學任教之前,是AT&T貝爾實驗室 & MIT的機器學習博士后,
Yann LeCun,擔任Facebook首席人工智能科學家和紐約大學教授,1987年至1988年,Yann LeCun是多倫多大學Geoffrey Hinton實驗室的博士后研究員,
第2章 GoogleNet網路概述
2.1 概述
VGG模型是2014年ILSVRC競賽的第二名,而第一名是GoogLeNet,
GoogLeNet, 由稱為inception,之所以能夠戰勝VGG, 這是因為它引入了一種全新的深度學習結構,該網路結構是由Google的Christian Szegedy于2014年提出的,因此稱為GoogLeNet,
據說之所以取名GoogLeNet而不是GoogleNet是為了向CNN的開山之作LeNet致敬,
GoogLeNet從Google公司的角度明確了該網路的歸屬,而Inception則從這個全新網路的內在本質特征來明確了該網路區別于其他網路的特性,
在這之前的AlexNet、VGG等結構都是通過增大網路的深度(層數)來獲得更好的訓練效果,但層數的增加會帶來很多負作用,比如overfit、梯度消失、梯度爆炸等,
GoogLeNet(Inception)則通對網路結構進行改造來提升訓練結果,改造后的結構,能更高效的利用計算資源,在相同的計算量下能提取到更多的特征,從而提升訓練結果,
從網路的深度和寬度兩個方面都有所增加,該網路是一個22層的卷積神經網路,要比VGGNet的19層更深,然后,其網路引數和浮點數計算量都遠遠小于VGG19網路,
2.2 Christian Szegedy(克里斯蒂安·塞格迪)其人
Christian Szegedy谷歌的資深研究科學家,現在Google從事人工智能領域的研究,
GoogLeNet獲得了2014年ImageNet挑戰賽(ILSVRC14)的第一名,VGG獲得了第二名,
2.3 googLeNet提出的動機與背景
提高神經網路性能的最直接的方法就是增加其規模,這包括:
- 增加網路深度:網路的層數,
- 每一層的寬度:神經元的數量,
但是,這種簡單的方法有一些問題:比如引數大量增加、過擬合overfit、梯度消失、梯度爆炸等,
解決這些問題的方法就是:在增加網路深度和寬度的同時減少引數,這就引入了稀疏連接,將全連接變成稀疏連接,但是全連接變成稀疏連接后實際計算量并不會有質的提升,因為大部分硬體是針對密集矩陣計算優化的,稀疏矩陣雖然資料量少,但是計算所消耗的時間卻很難減少,
有沒有一種方法:既能保持網路結構的稀疏性,又能利用密集矩陣的高計算性能,GoogLeNet就是基于此提出的,
2.4 googLeNet特點與更新
(1)1 * 1卷積核的使用:發現更細微的特征
(2)同一個層,可以使用多個不同長度的卷積核:發現不同尺度的特征,區域+更寬+更寬的特征
能夠綜合不同尺寸的特征,
(3)增加層數:發現更多抽象層次的宏觀特征(20層左右是極限)
(4)Inception(感知器)的引入:不同大小卷積核的組合
2.5 inception的本意

Inception源于一部知名的電影:盜夢空間,
Inception的英文是:(機構、組織等的)開端,創始,這里是指多維視角單元,
第3章 GoogLeNet網路組成單元
3.1 GoogLeNet基本、核心組成單元Inception的結構介紹 - 原始版本
Inception就是把多個卷積或池化操作,放在一起組裝成一個網路模塊,設計神經網路時以模塊為單位去組裝整個網路結構,模塊如下圖所示:
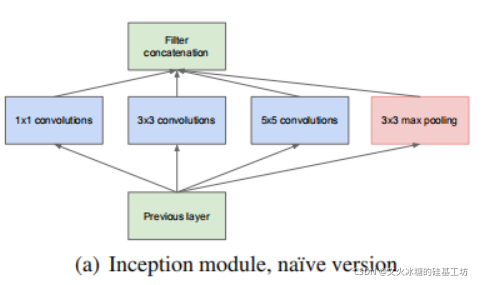
在未使用這種方式的網路之前,我們一層往往只使用一種操作,比如卷積或者池化,而且卷積操作的卷積核尺寸也是固定大小的,
但是,在實際情況下,在不同尺度的圖片里,需要不同大小的卷積核,這樣才能使性能最好,或者或,對于同一張圖片,不同尺寸的卷積核的表現效果是不一樣的,因為他們的感受野不同,
所以,我們希望讓網路自己去選擇,Inception便能夠滿足這樣的需求,一個Inception模塊中并列提供多種卷積核的操作,網路在訓練的程序中通過調節引數自己去選擇使用,
同時,由于網路中都需要池化操作,所以此處也把池化層并列加入網路中,
3.2 GoogLeNet基本、核心組成單元Inception的結構介紹 - 改進版本
我們在上面提供了一種Inception的結構,存在很多問題,是不能夠直接使用的,
首要問題就是引數太多,導致特征圖厚度太大,
為了解決這個問題,作者在其中加入了1X1的卷積核,改進后的Inception結構如下圖:
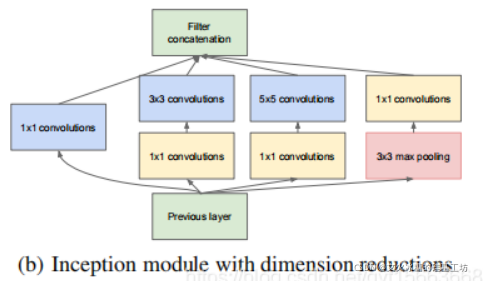
這樣做有兩個好處:
首先:是大大減少了引數量,
其次,是增加的1X1卷積后面也會跟著有非線性激勵,這樣同時也能夠提升網路的表達能力,
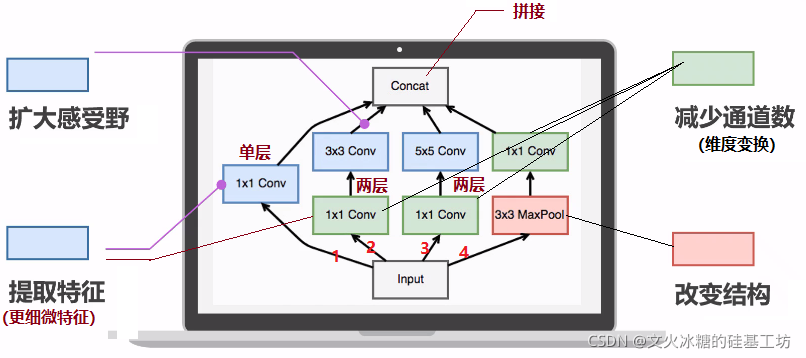
(1)4個并行流
(2) 最大2層串聯
(3)步長為1
(4)GoogLeNet是Inception結構的堆疊,而不是卷積核的堆疊,
3.3 什么是1x1卷積核?
1x1卷積核,又稱為網中網(Network in Network).
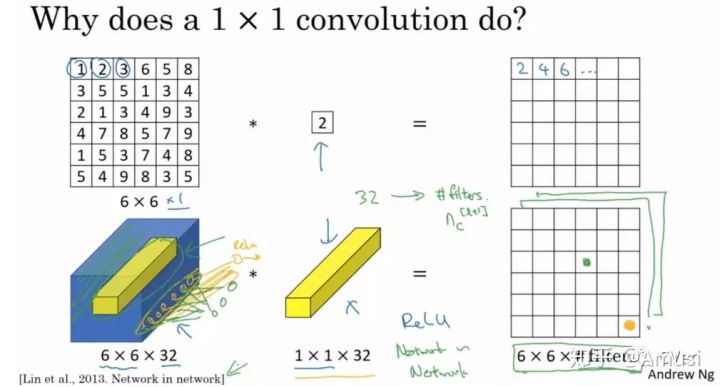
這里通過一個例子來直觀地介紹1x1卷積,輸入6x6x1的矩陣,這里的1x1卷積形式為1x1x1,即為元素2,輸出也是6x6x1的矩陣,但輸出矩陣中的每個元素值是輸入矩陣中每個元素值x2的結果,

上述情況,并沒有顯示1x1卷積的特殊之處,那是因為上面輸入的矩陣channel為1,所以1x1卷積的channel也為1,這時候只能起到升維的作用,這并不是1x1卷積的魅力所在,
讓我們看一下真正work的示例,當輸入為6x6x32時,1x1卷積的形式是1x1x32,當只有一個1x1卷積核的時候,此時輸出為6x6x1,此時便可以體會到1x1卷積的實質作用:降維,當1x1卷積核的個數小于輸入channels數量時,即降維[3],
注意,下圖中第二行左起第二幅影像中的黃色立方體即為1x1x32卷積核,而第二行左起第一幅影像中的黃色立方體即是要與1x1x32卷積核進行疊加運算的區域,
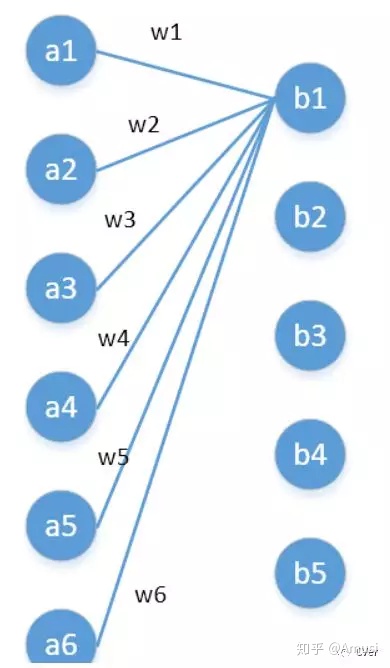
其實1x1卷積,可以看成一種全連接(full connection),
第一層有6個神經元,分別是a1—a6,通過全連接之后變成5個,分別是b1—b5,第一層的六個神經元要和后面五個實作全連接,本圖中只畫了a1—a6連接到b1的示意,可以看到,在全連接層b1其實是前面6個神經元的加權和,權對應的就是w1—w6,到這里就很清晰了,
第一層的6個神經元其實就相當于輸入特征里面那個通道數:6,而第二層的5個神經元相當于1*1卷積之后的新的特征通道數:5,
w1—w6是一個卷積核的權系數,若要計算b2—b5,顯然還需要4個同樣尺寸的卷積核[4],
備注:1x1卷積一般只改變輸出通道數(channels),而不改變輸出的寬度和高度
3.4 1x1卷積核的意義與作用
(1)降維/升維
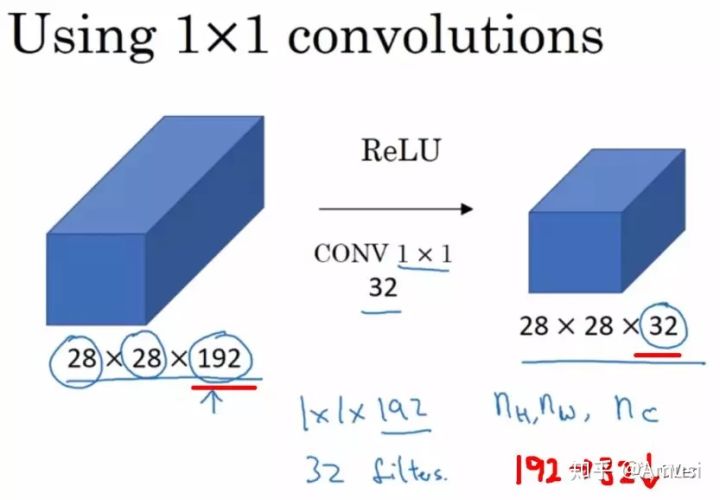
(2) 更加精細的特征提取:精細到每個像素,
第4章 GoogLeNet網路結構分析
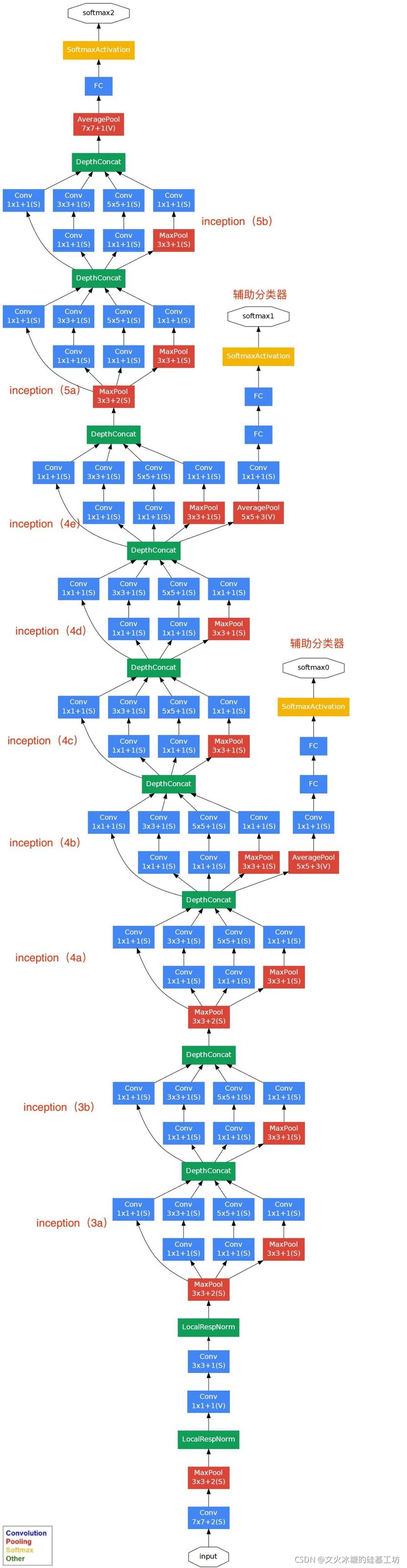
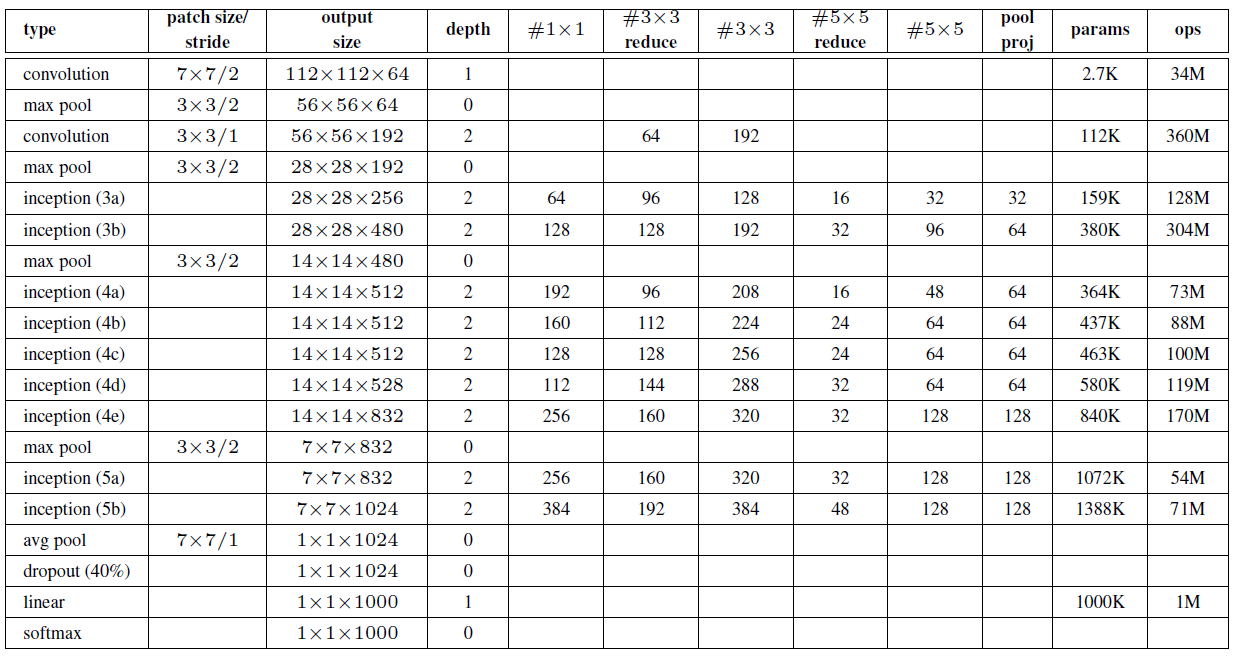
4.1 inception網路結構:橫向表示法
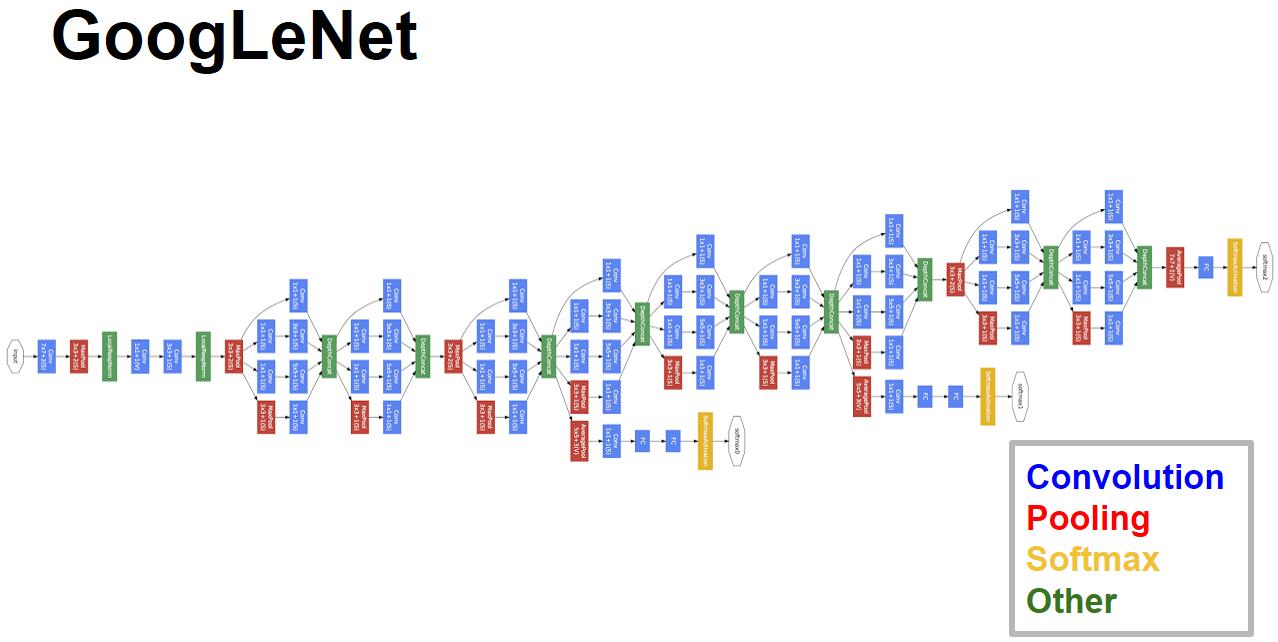
4.2 inception網路結構:縱向表示法
4.3 不同子版本的比較
Inception有眾多的子版本,
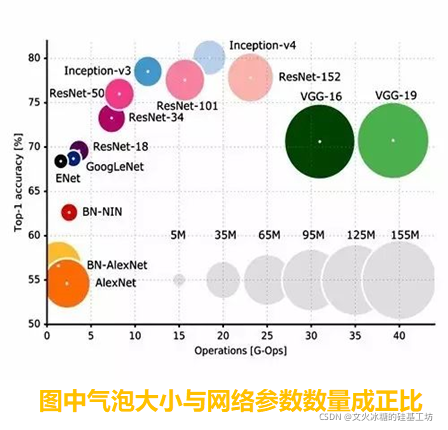
在眾多網路中,Inception-3的引數少,準確率高的特點,
Inception-4雖然比Inception-3準確率高一點點,但引數也多出不少,
從準確率看和引數量來看,ResNet相對于Inception-3并沒有優勢,
4.4 網路結構分析
(1)GoogLeNet采用了模塊化的結構(Inception結構),方便增添和修改;
(2)網路最后采用了average pooling(平均池化)來代替第一層全連接層(分類前的第二層全連接保留),該想法來自NIN(Network in Network),據說,這樣可以將準確率提高0.6%,
(3)雖然移除了全連接,但是網路中依然使用了Dropout ;
(4)為了避免梯度消失,網路額外增加了2個輔助的softmax用于向前傳導梯度(輔助分類器)
對于前三點都很好理解,下面我們重點看一下第4點,
4.5 輔助分類器
這里的輔助分類器只是在訓練時使用,防止主梯度消失,在正常預測時會被去掉,
當主梯度消失時,可以永輔助分離器,檢查是否需要進一步訓練,調參,
輔助分類器促進了更穩定的學習和更好的收斂,往往在接近訓練結束時,輔助分支網路開始超越沒有任何分支的網路的準確性,達到了更高的水平,
疑問:
能否把輔助分類器應用到正常的預測中,進行分層預測?
作者主頁(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文網址:https://blog.csdn.net/HiWangWenBing/article/details/120896296
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/333951.html
標籤:AI